【文本挖掘】(四)信息抽取
问题引入
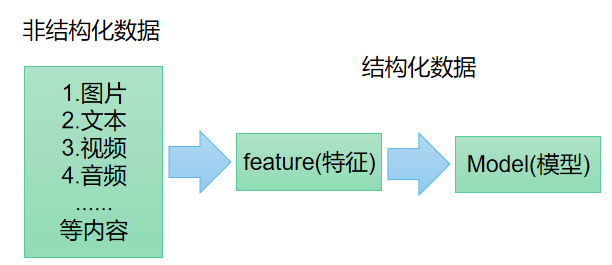
有哪些方法能从非结构化文本中提取结构数据?或识别文本中描述的实体和关系?
特征选择
- 卡方统计法
- 递归式特征消除法
- 岭回归
信息抽取
概念
从文本中抽出实体、关系、事件等事实信息,并将自然语言数据转换为结构化数据。
文本抽取到的四类基本元素:
- 实体:人、公司、地址等
- 属性:人的头衔、人的年龄等
- 关系:公司和员工之间的雇佣关系等
- 事件:两个公司间的联谊
实现顺序:
- 分词
- 词性标注
- 命名实体识别Named Entity Recognition NER
- 关系识别搜索文本中不同实体间可能的关系
实体识别
命名实体识别
graph LR
A(命名实体识别)-->B(命名实体)
A-->C(实现方法)
A-->J(实现流程)
B(命名实体)-->D(三大类)
B(命名实体)-->E(七小类)
D-->F(实体类)
D-->G(时间类)
D-->H(数字类)
E-->I(人名、机构名、地名、时间、日期、货币、百分比)
C-->P(基于规则和词典)
C-->Q(基于统计)
C-->R(混合)
P-->S(指示词、方向词、中心词、标点符号等)
Q-->T(隐马尔可夫 HMM)
Q-->U(最大熵 ME)
Q-->V(支持向量机 SVM)
Q-->W(条件随机场 CRF)
J-->X(<p align="left">1.分词<br>2.对分词进行标签标注<br>3.抽取标签标注的分词<br>4.组成命名实体)
开放域实体识别
基于已知实体的语义特征去搜索日志中识别出命名的实体,然后进行聚类。
不限实体类别,给定种子,根据种子提取更多同类实体,如:
给定种子<中国,美国,俄罗斯>
找出其他国家<德国,英国,法国..>
graph LR
A(开放域实体抽取方法)-->B(基于查询日志的抽取方法)
A-->C(基于网页的抽取方法)
A-->E(融合多个数据源的抽取方法)
这部分内容信息较少,待补充
关系抽取
将实体和实体间的关系构成一个三元组,如:
输入文本: 张三毕业于清华大学,工作在福州。
抽取结果:(张三,毕业于,清华大学)(张三,工作在,福州)
graph LR
A(关系抽取方法)-->B(基于规则)
B-->C(<p align="left">优点:比较准确;无需训练数据<br>缺点:人力成本高)
A-->E(有监督学习)
E-->F(原理:训练一个二分类判断两个实体间是否存在关系)
A-->G(半监督/无监督学习)
G-->H(Bootstrapping)
G-->I(Distantsupervision)
案例
一:正则表达式抽取结构化信息
import re
import pandas as pd
data='''
张华考上了北京大学
丽萍进了中等技术学校
韩梅梅进了百货公司
他们都有光明的前途
'''
regex=r'(.*)[考|进].*了(.*)'
mylist=[]
for line in data.split('\n'):
mysearch=re.search(regex,line)
if mysearch:
name=mysearch.group(1)
dest=mysearch.group(2)
mylist.append((name,dest))
df=pd.DataFrame(mylist)
df.columns=['姓名','去向']
print(df)
二:dateuitl+正则表达式抽取日期实体
# -*- coding:utf-8 -*-
# @project: transcoding_stopword.py
# @filename: 时间实体识别.py
# @author: GaGim-H
# @github: https://github.com/GaGim-H
# @time: 2024/05/22 19:15
import re
from datetime import datetime, timedelta
from dateutil.parser import parse
import jieba.posseg as psg
UTIL_CN_NUM = {
'零': 0, '一': 1, '二': 2, '三': 3, '四': 4, '五': 5, '六': 6,
'七': 7, '八': 8, '九': 9, '0': 0, '1': 1, '2': 2, '3': 3, '4': 4,
'5': 5, '6': 6, '7': 7, '8': 8, '9': 9
}
UTIL_CN_UNIT = {'十': 10, '百': 100, '千': 1000, '万': 10000}
# 文本转换成数字
def cn2dig(src):
if src == "":
return None
# 匹配数字
m = re.match("\d+", src)
if m:
return int(m.group(0))
rsl = 0
unit = 1
for item in src[::-1]:
if item in UTIL_CN_UNIT.keys():
unit = UTIL_CN_UNIT[item]
elif item in UTIL_CN_NUM.keys():
num = UTIL_CN_NUM[item]
rsl += num * unit
else:
return None
if rsl < unit:
rsl += unit
return rsl
# 文本转换成数字
def year2dig(year):
res = ""
for item in year:
if item in UTIL_CN_NUM.keys():
res = res + str(UTIL_CN_NUM[item])
else:
res = res + item
m = re.match("\d+", res)
if m:
if len(m.group(0)) == 2:
return int(datetime.today().year / 100) * 100 + int(m.group(0))
else:
return int(m.group(0))
else:
return None
def parse_datetime(msg):
if msg is None or len(msg) == 0:
return None
try:
# 使用时间自动识别库
dt = parse(msg, fuzzy=True)
return dt.strftime("%Y-%m-%d %H:%M:%S")
except Exception as e:
# 使用正则表达式识别
m = re.match(
r"([0-9零一二三四五六七八九十]+年)?([0-9一二三四五六七八九十]+月)?"
r"([0-9一二三四五六七八九十]+[号日])?([上中下五晚早]+)?"
r"([0-9零一二三四五六七八九十百]+[点:\.时])?([0-9零一二三四五六七八九十百]+分?)?([0-9零一二三四五六七八九十百]+秒)?"
,msg)
if m.group(0) is not None:
res = {
"year": m.group(1),
"month": m.group(2),
"day": m.group(3),
"hour": m.group(5) if m.group(5) is not None else '00',
'minute': m.group(6) if m.group(6) is not None else '00',
'second': m.group(7) if m.group(7) is not None else '00',
}
params = {}
# 遍历提取到的日期文字
for name in res:
if res[name] is not None and len(res[name]) != 0:
tmp = None
# 将日期文字转换成数字
if name == 'year':
tmp = year2dig(res[name][:-1])
else:
tmp = cn2dig(res[name][:-1])
if tmp is not None:
params[name] = int(tmp)
# 提取数字日期
target_date = datetime.today().replace(**params)
is_pm = m.group(4)
if is_pm is not None:
if is_pm == u'下午' or is_pm == u'晚上' or is_pm == '中午':
hour = target_date.time().hour
print("hour:",hour)
if hour<12:
target_date=target_date.replace(hour=hour+12)
return target_date.strftime("%Y-%m-%d %H:%M:%S")
else:
return None
# 判断日期是否有效
def check_time_valid(word):
m=re.match("%d+$",word)
if m:
if len(word)<=6:
return None
world=re.sub('[号|日]\d+$','日',word)
if world!=word:
return check_time_valid(world)
else:
return world
# 提取时间:解析句子,提取可能表示时间的词,并进行上下文拼接
def time_extract(txt):
time_res=[]
word=''
keyDate={'今天':0,'明天':1,'后天':2,'今日':0,'明日':1}
# print([ [k,v] for k,v in psg.cut(txt)])
for k,v in psg.cut(txt):
if k in keyDate:
if word!="":
time_res.append(word)
word=(datetime.today()+timedelta(days=keyDate.get(k,0))).strftime("%Y年%m月%d日")
elif word!='':
if v in ['m','t']:
word=word+k
else:
time_res.append(word)
word=''
elif v in ['m','t'] :
word=k
if word!='':
time_res.append(word)
result=list(filter(lambda x:x is not None,[ check_time_valid(w) for w in time_res]))
final_res=[ parse_datetime(w) for w in result]
return [ x for x in final_res if x is not None]
text1="中新网3月3日,据WTT世界乒联消息,WTT新加坡大满贯2023资格赛将于明日正式打响,3月7日至9日为资格赛,11日至19日为正赛。"
print(text1,time_extract(text1),sep=":")
三:使用pyhanlp和jieba提取命名实体
from pyhanlp import *
sentence=u'''今天是xxx等老一辈革命家为雷锋同志题词60周年,xxx***近日作出重要指示指出,雷锋的名字家喻户晓,雷锋的事迹深入人心,雷锋精神滋养着一代代中华儿女的心灵。党的十八大以来,xxx***对弘扬雷锋精神作出一系列重要论述,指导推动新时代学雷锋活动不断拓展内容、创新形式、丰富载体、涌现出一批又一批雷锋式先进集体和模范人物,为新时代伟大变革注入不竭精神动力。今天,党建网梳理了xxx***部分相关重要论述,邀您一起学习领会。'''
words=HanLP.segment(sentence)
for item in words:
print(item.word,item.nature)
# 关键词提取
keyword_list=HanLP.extractKeyword(sentence,5) #提取五个关键词
# 文本摘要
summary_list=HanLP.extractSummary(sentence,2) #提取文本中两个关键句作为摘要
# 依存句法分析
Denpency_lst=HanLP.parseDepency(sentence)
# 短句提取
phrase_list=HanLP.extractPhrase(sentence,5)
# 词性切分
analyzer=PerceptronLexicalAnalyzer()
segs=analyzer.analyze(sentence)
arr=str(segs).split(" ")
def get_result(arr):
re_list=[]
ner=['n','ns']
for x in arr:
temp=x.split("/")
if (temp[1] in ner):
re_list.append(temp[0])
return re_list
# 使用jieba
import jieba.analyse
# 词性切分
kw=jieba.analyse.extract_tags(sentence,allowPOS=('n','ns'))
kw01=jieba.analyse.textrank(sentence,allowPOS=('n','ns'))
for item in kw01:
print(item)
from pyhanlo import *
content="3月19日晚,WTT新加坡大满贯女双决赛上演中日对决——孙颖莎/王曼对阵日本组合伊藤美成/早田希娜,最终3-0完胜对手,取得WTT新加坡大满贯女双冠军。"
# 1. 分词标注
print(HanLP.segment(content))
# 2.添加自定义词典,用部分人名不能被正确分词
CustomDictionary.add("孙颖莎","nr 300")
CustomDictionary.insert("伊藤美诚",'nr 100')
CustomDictionary.add("中日对决","nz 1024 n 1")
print(HanLP.segment(content))
# 人名识别
segment=HanLP.newsSegment().enableNmaeRecognize(True)
name_list=[]
for i in segment.seg(conetent):
split_words=str(i).split('/')
word,tag=split_words[0],split_words[-1]
if tag=='nr':
name_list.append(word)
print(name_list)
# 地名识别ns HanLP.newSegment().enablePlaceRecognize(True)
# 机构名识别nt HanLP.newSegment().enableOrganizationRecognize(True)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号