【机器学习】第二节-模型评估与选择-性能度量、方差与偏差、比较检验
三个关键问题:
如何获得测试结果? → 评估方法
如何评估性能优劣? → 性能度量
如何判断实质差别? → 比较检验
思路总结
1.评价指标联系:
混淆矩阵-> 查准率、查全率->PR图->F1系数
一、性能度量
对学习器的泛化性能进行评估,不仅需要有效可行的实验估计方法,还需
要有衡量模型泛化能力的评价标准,这就是性能度量
性能度量是衡量模型泛化能力的评价标准,反映了任务需求
使用不同的性能度量往往会致不同的评判结果
1.回归任务:均方误差
用于评价回归任务
其中,Ⅱ表示示性函数
2.分类任务
(1)错误率与精度
错误率:
精度:
(2)查准率P与查全率R
查准率/准确率(precision):
P = TP/(TP+FP)
查全率/召回率/灵敏度/真正率(recall):
R = TP/(TP+FN)
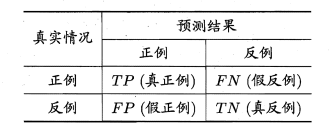
根据样本总数=TP+FP+TN+FN,查全率和查准率是一对矛盾变量,一般查准率高,查全率低;查准率低,查全率高;在一些简单任务中,可能两者都高
(3)平衡点BEP:P-R曲线图/PR图(查准率-查全率曲线)
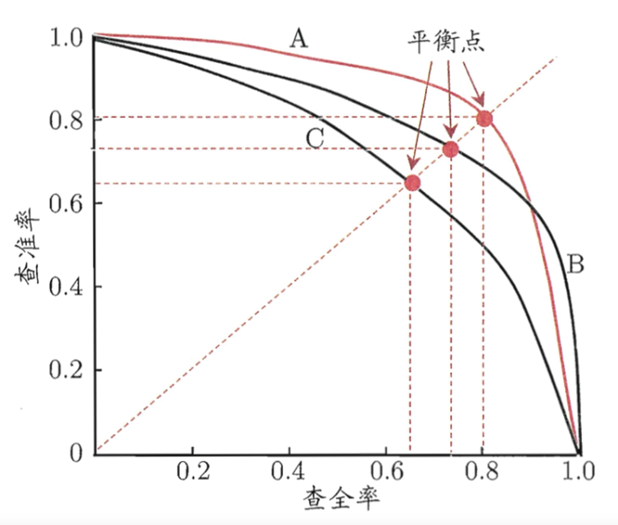
注:P-R图一般为非光滑非单调曲线
曲线下面积与平衡点(BEP)
(1)若一个学习模型的P-R曲线完全包住另一个学习模型的P-R曲线,则前者的性能优于后者。即查全率相同的情况下,查准率越高模型的泛化性能越好,如模型A优于模型B。
(2)若两个学习模型的P-R曲线互相交叉,则可通过“平衡点”(Break-Event Point,简称BEP)来评价模型的优劣,BEP是"查准率=查全率"的数值。由上图可知,模型A的平衡点大于模型B的平衡点,即模型A优于B。
(3) 由于BEP过于简化,更常用的是F1度量:
F1越大,性能越好。
(4)F1系数
(4-1)综合查准率与查全率(调和平均/常用公式)
(4-2)更一般的形式(加权调和平均)
(4-3)算术平均
(4-4)几何平均
(4-5)宏查准率、宏查全率、宏F1
对多次训练/测试生成的多个混淆矩阵进行平均
(4-6)微查准率、微查全率、微F1
(4-7)宏F1与微F1的区别
(5)ROC与AUC(真正例率、假正例率)
PR曲线:
x:查准率 y:查全率
ROC曲线:
x:真正例率 y:假正例率
(6)代价曲线/代价敏感错误率
一些判断错误的任务会造成一些损失和出现代价,比如医疗诊断的失误,可能会导致失去生命;门禁错误地允许陌生人进入,可能会造成严重地安全事故。对该类错误可称为“非均等代价”。
可根据任务的领域知识设定代价矩阵
与混淆矩阵的区别是,混淆矩阵隐式设定了均等代价,直接计算错误次数,并没用考虑不同错误会造成不同后果;
在非均等代价下,ROC曲线无法直接反应学习器的期望总体代价,而是用代价曲线代替。
二、偏差与方差
测试误差能代表泛化误差吗?
详见周志华:《机器学习》2.4比较检验
泛化错误率的构成:偏差+方差+噪声
偏差:模型输出与真实值的偏离程度,刻画了算法的拟合能力,偏差衡量测试结果的精密度。
方差:同样大小的训练集的变动导致的学习性能的变化,即数据扰动造成的影响。方差表示数据的稳定性。
噪声:当前学习器所能达到的泛化误差的下限
偏差大:拟合不足/欠拟合;方差大:过拟合
详见周志华:《机器学习》2.5偏差与方差
测试集小时,评估结果的方差较大;(测试集小->过拟合->方差大)
训练集小时,评估结果的偏差较大;(训练集小->欠拟合->偏差大)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号