【机器学习】第二节-模型评估与选择-模型评估方法
思路总结
1.评价指标联系:
混淆矩阵-> 查准率、查全率->PR图->F1系数
问题总结
1.训练划分数据集的方法有哪些?各自区别和适用场景?
2.评价模型好坏的指标有哪些?
3.宏F1和微F1的区别和适用场景?
4.模型方差和偏差受哪些因素影响?
5.欠拟合和过拟合的区别?
6.可以根据混淆矩阵分析的指标有哪些?
一、经验误差与过拟合
- 精度
1-错误率 - 误差/误差期望
模型输出与样本真实值之间的差异
| 误差类型 | 说明 |
|---|---|
| 训练/经验误差 | 模型在训练集上的误差 |
| 泛化误差 | 模型在新样本上的误差 |
- 过拟合与欠拟合
| 过拟合/过配 | 欠拟合/欠配 |
|---|---|
| 在训练集表现好,在测试集和验证集表现差 | 在训练集、测试集表现都差 |
| 训练集误差低,测试集误差高 | 训练集误差高 |
- 度量指标
损失函数
二、模型选择方法
三个关键问题:
如何获得测试结果? → 评估方法
如何评估性能优劣? → 性能度量
如何判断实质差别? → 比较检验
https://cloud.tencent.com/developer/article/1783976
对于一个任务,为了从候选模型中选择最佳模型,需要一些方法作为标准。
理想的解决方案是选择泛化误差最小的候选模型,但现实上无法直接获得泛化误差,因为未来数据是未知的;而训练误差会因为过拟合的存在不适合作为标准。
因此,采用以下标准:\[测试误差\approx泛化误差 \]通常说来,测试误差的平均值或者说期望就是泛化误差
下文介绍三种实验估计方法,不同的实验估计方法有不同的数据划分方式,再进一步计算测试误差均值,这里主要指的是对学习器的泛化误差的评估。
专家样本
专家样本=训练集+测试集
训练集S+测试集T:互斥互补(S∩T=Φ, D=S∪T)
训练集和测试集独立同分布且互斥
分层采样 stratified samlping
避免样本类别差异大,数据分布也差异大而产生偏差。
选择方法总结
| 序号 | 选择方法 | 说明 | 缺点 | 优点 |
|---|---|---|---|---|
| 1 | 单次留出法 | 如训练集:测试集的比例是8:2 | 不稳定 | --- |
| 2 | 多次留出法 | 对专家样本随机进行100次训练集/测试集划分,评估结果取平均 | 模型评估结果与训练集、测试集比例有关 | --- |
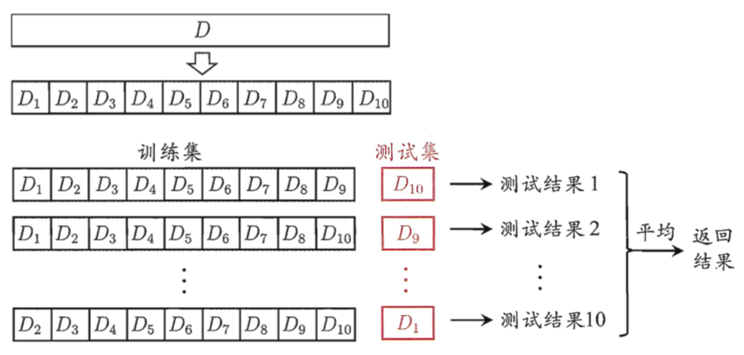
| 3 | k折交叉验证 | 分层采样划分为K份互斥子集 k-1个子集作为训练集,1份作为测试集,轮流训练k次,返回k个测试结果的均值 |
--- | |
| 4 | 留一法 | k=m,即样本总数 每个样本都被当做测试样本 |
不适用于大样本,较耗时 |
适用于小样本或数据较缺乏时 最接近原始样本的分布 |
| 5 | P次K折交叉验证 | 对数据集进行P次划分,每次都进行k折交叉验证 | 最大化利用数据 模型效果会更加接近模型的真实泛化误差 |
计算量较大 |
| 6 | 自助法 | 包外估计 | 与原始数据偏差较大 | 适用于数据集较小、集成学习中 |
1.留出法
合理划分、保持比例
(1)分层采样
在分类任务的数据划分中,要尽可能保持样本类别比例相似,因此,保留类别比例的采样方式称为分层采样(stratified samlping),如果训练集和测试集的类别比例差异较大,则会因为数据分布的差异而引起偏差
(2)单次留出法
弊端:只做一次分割,它对训练集、验证集和测试集的样本数比例,还有分割后数据的分布是否和原始数据集的分布相同等因素比较敏感。
单次留出法的结果通常不太稳定,因此,使用留出法时,一般采用若干次划分,重复进行实验评估后取平均值作为留出法的评估结果,即多次留出法
(3)多次留出法
多次留出法:如对专家样本随机进行100次训练集/测试集划分,评估结果取平均
缺点:模型评估结果与训练集和测试集比例有关
2.交叉验证
(1)k折交叉验证
- 将专家样本通过分层采样等份划分为份个互斥子集,且每个互斥自己尽可能保持数据分布的一致性,轮流用K-1份子集用于训练,1份子集个用于测试,这样即可进行k次训练和测=试,最终返回k个测试结果的均值;
- k常用取值为10,或5、20;
- 当k=m,则为留一法;
k 折交叉验证通过对 k 个不同分组训练的结果进行平均来减少方差,
因此模型的性能对数据的划分就不那么敏感。
第一步,不重复抽样将原始数据随机分为 k 份。
第二步,每一次挑选其中 1 份作为测试集,剩余 k-1 份作为训练集用于模型训练。
第三步,重复第二步 k 次,这样每个子集都有一次机会作为测试集,其余机会作为训练集。
在每个训练集上训练后得到一个模型,
用这个模型在相应的测试集上测试,计算并保存模型的评估指标,
第四步,计算 k 组测试结果的平均值作为模型精度的估计,并作为当前 k 折交叉验证下模型的性能指标。
k 一般取 10,
数据量小的时候,k 可以设大一点,这样训练集占整体比例就比较大,不过同时训练的模型个数也增多。
如120条数据,分成10份,每份含12条数据;分成12份,每份含10条数据;
即k越大,数据集越小
数据量大的时候,k 可以设小一点。
(2)留一法
即当k=m即样本总数,每次的测试集都只有一个样本,要进行 m 次训练和预测
这个方法用于训练的数据只比整体数据集少了一个样本,因此最接近原始样本的分布
但是训练复杂度增加了,训练m个模型的计算开销可能很大,因此不适用于数据集较大的情况
一般在数据缺乏时使用

(3)P次k折交叉验证
- 由于留一法不适用数据集较大,因为交叉验证法评估结果的稳定性和保真性取决于k,因此,需采用P次k折交叉验证,例如:10次10折交叉验证
也就是在10次不同的划分下进行10折交叉验证 - 该方法与留出法相似,如10次10折交叉验证和100次留出法次数相同
3.自助法/包外估计 bootstrapping
自助采样过程
Step1.对包含m个样本的数据集D,进行采样产生数据集D'
Step2.每次随机从D中挑选一个样本,将其拷贝放入D'中
Step3.步骤2重复m次,得到包含m个样本的数据集D'
自助采样特点
D'中有一部分重复样本
样本在m次采样中始终不被采到的概率为0.368
有36.8%的样本未出现在D'中
优点是训练集的样本总数和原数据集一样都是 m,并且仍有约 1/3 的数据没被采样而可以作为测试集(包外估计),对于样本数少的数据集,就不用再由于拆分得更小而影响模型的效果。
缺点是这样产生的训练集的数据分布和原数据集的不一样了,会引入估计偏差。
此种方法不是很常用,除非数据量真的很少。因此,该方法适用于数据集较小、难以有效划分训练/测试集时。
初始数据量足够时,常用留出法或交叉验证法。
该方法使用场景在集成学习中,如随机森林。

三、性能度量
对学习器的泛化性能进行评估,不仅需要有效可行的实验估计方法,还需
要有衡量模型泛化能力的评价标准,这就是性能度量
性能度量是衡量模型泛化能力的评价标准,反映了任务需求
使用不同的性能度量往往会致不同的评判结果
1.回归任务:均方误差
用于评价回归任务
2.分类任务
(1)错误率与精度
错误率:
精度:
(2)查准率与查全率
查准率/准确率(precision):
P = TP/(TP+FP)
查全率/召回率/灵敏度/真正率(recall):
R = TP/(TP+FN)
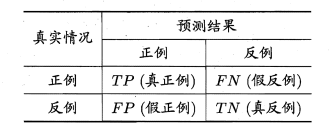
根据样本总数=TP+FP+TN+FN,查全率和查准率是一对矛盾变量,一般查准率高,查全率低;查准率低,查全率高;在一些简单任务中,可能两者都高
(3)平衡点BEP:P-R曲线图/PR图(查准率-查全率曲线)
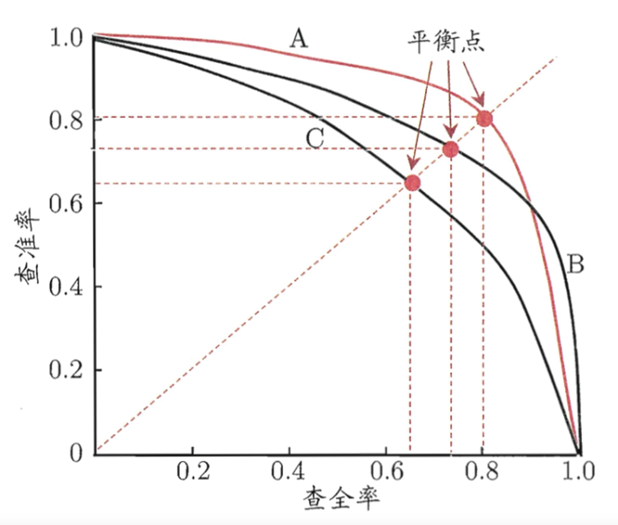
注:P-R图一般为非光滑非单调曲线
曲线下面积与平衡点(BEP)
(1)若一个学习模型的P-R曲线完全包住另一个学习模型的P-R曲线,则前者的性能优于后者。即查全率相同的情况下,查准率越高模型的泛化性能越好,如模型A优于模型B。
(2)若两个学习模型的P-R曲线互相交叉,则可通过“平衡点”(Break-Event Point,简称BEP)来评价模型的优劣,BEP是"查准率=查全率"的数值。由上图可知,模型A的平衡点大于模型B的平衡点,即模型A优于B。
(3) 由于BEP过于简化,更常用的是F1度量:
F1越大,性能越好。
(4)F1系数
(4-1)综合查准率与查全率(调和平均/常用公式)
(4-2)更一般的形式(加权调和平均)
(4-3)算术平均
(4-4)几何平均
(4-5)宏查准率、宏查全率、宏F1
对多次训练/测试生成的多个混淆矩阵进行平均
(4-6)微查准率、微查全率、微F1
(4-7)宏F1与微F1的区别
ROC与AUC(真正例率、假正例率)
PR曲线:
x:查准率 y:查全率
ROC曲线:
x:真正例率 y:假正例率
代价曲线/代价敏感错误率
一些判断错误的任务会造成一些损失和出现代价,比如医疗诊断的失误,可能会导致失去生命;门禁错误地允许陌生人进入,可能会造成严重地安全事故。对该类错误可称为“非均等代价”。
可根据任务的领域知识设定代价矩阵
与混淆矩阵的区别是,混淆矩阵隐式设定了均等代价,直接计算错误次数,并没用考虑不同错误会造成不同后果;
在非均等代价下,ROC曲线无法直接反应学习器的期望总体代价,而是用代价曲线代替。
四、偏差与方差
测试误差能代表泛化误差吗?
详见周志华:《机器学习》2.4比较检验
泛化错误率的构成:偏差+方差+噪声
偏差:模型输出与真实值的偏离程度,刻画了算法的拟合能力,偏差衡量测试结果的精密度。
方差:同样大小的训练集的变动导致的学习性能的变化,即数据扰动造成的影响。方差表示数据的稳定性。
噪声:当前学习器所能达到的泛化误差的下限
偏差大:拟合不足/欠拟合;方差大:过拟合
详见周志华:《机器学习》2.5偏差与方差
测试集小时,评估结果的方差较大;(测试集小->过拟合->方差大)
训练集小时,评估结果的偏差较大;(训练集小->欠拟合->偏差大)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号