深度学习中对 Encoder、Decoder 的解惑
对 encoder 和 decoder 的深入理解来源于我学习 Transformer 时一直以来存在的一个疑问,其来源于一种说法:BERT 模型就是 Transformer 的 encoder,而 GPT 就是 Transformer 的 decoder。
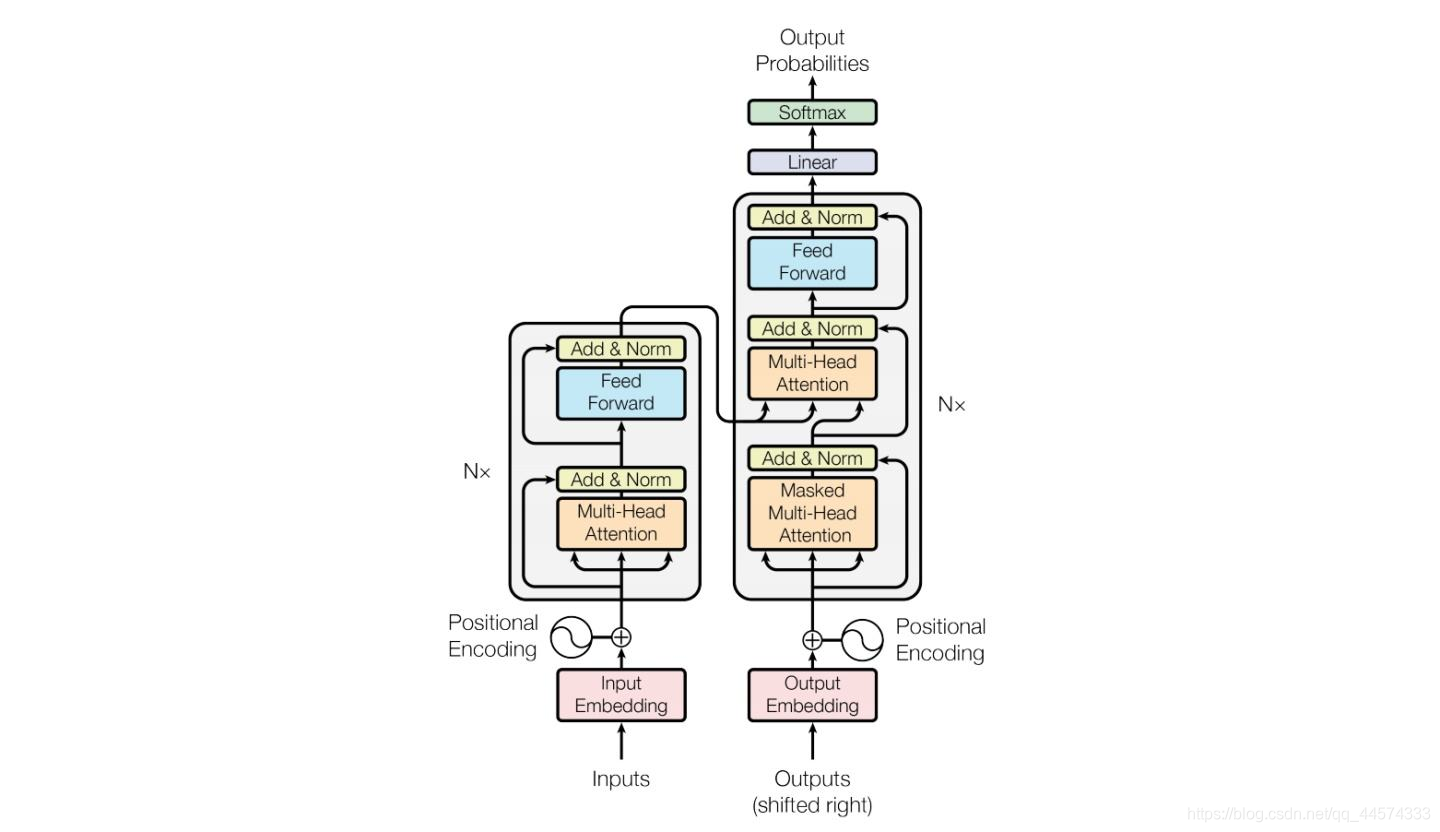
然而这种不严谨的说法让我十分费解:既然 encoder 被称为编码器,那它的作用是将明文转换成密文,即将人可以理解的信息转化为隐变量,那为什么 BERT 输入与输出均是明文,不仅可以完成完形填空和纠错任务,甚至还能实现文本生成?
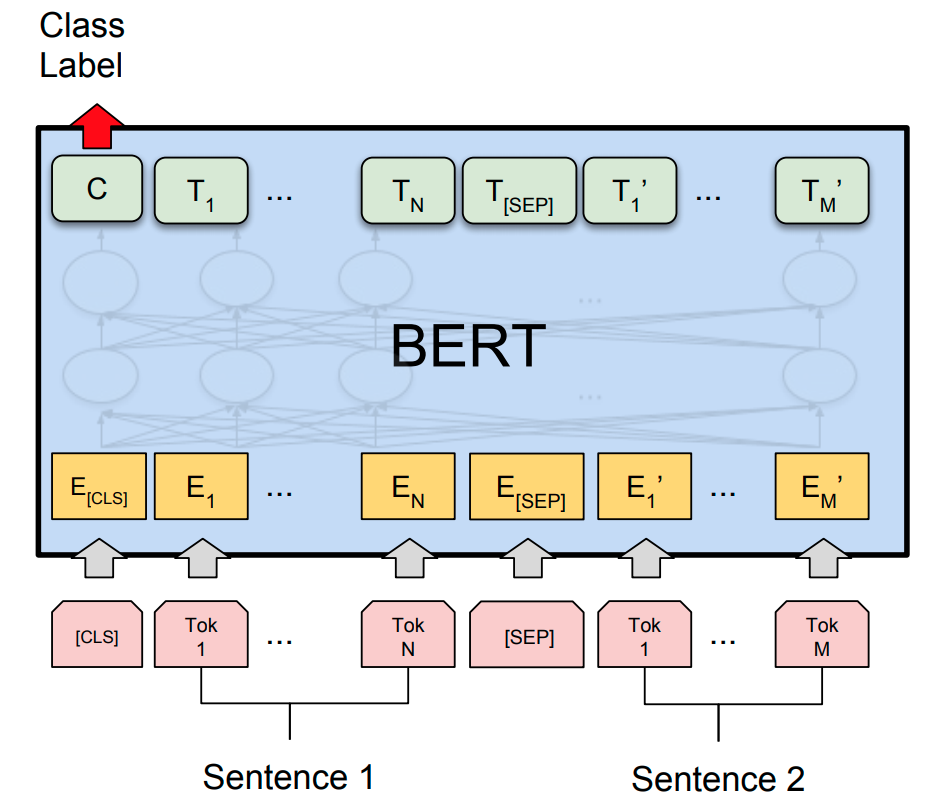
同样的问题,既然 decoder 被称为解码器,那它是将密文转换成明文,而 GPT 输入的 prompt 和回答的文本均是明文,这又是为什么?难道说 BERT 训练的时候,输出的隐变量被计算成了每种文字的概率值,每次推理的时候都是正向遍历一遍语料库,挑选概率最大的文字填进 mask ?再联系上下文正向遍历语料库找出中间填词,一旦概率最大的预测值与当前中间的文字不符便做出修改?那这样每次都要遍历一遍语料库,岂不是时间复杂度爆炸了,更别提生成任务了。。。那 GPT 更费解了,人家输入是个隐变量,而我输入是 prompt 明文,这更矛盾了。。。

纠正的说法应该是:BERT 模型使用了 Transformer 的 encoder 部分的网络结构,它并非 Transformer 的 encoder 本身,encoder 的输入是明文,输出是隐变量,而 BERT 是在 Transformer 的 encoder 结构的输出位置输出明文;同理 GPT 模型使用了 Transformer decoder 部分的网络结构,它并非 Transformer 的 decoder 本身,decoder 的输入是隐变量,输出是明文,而 GPT 是在 Transformer decoder 结构的输入位置输入文本,而非隐变量。
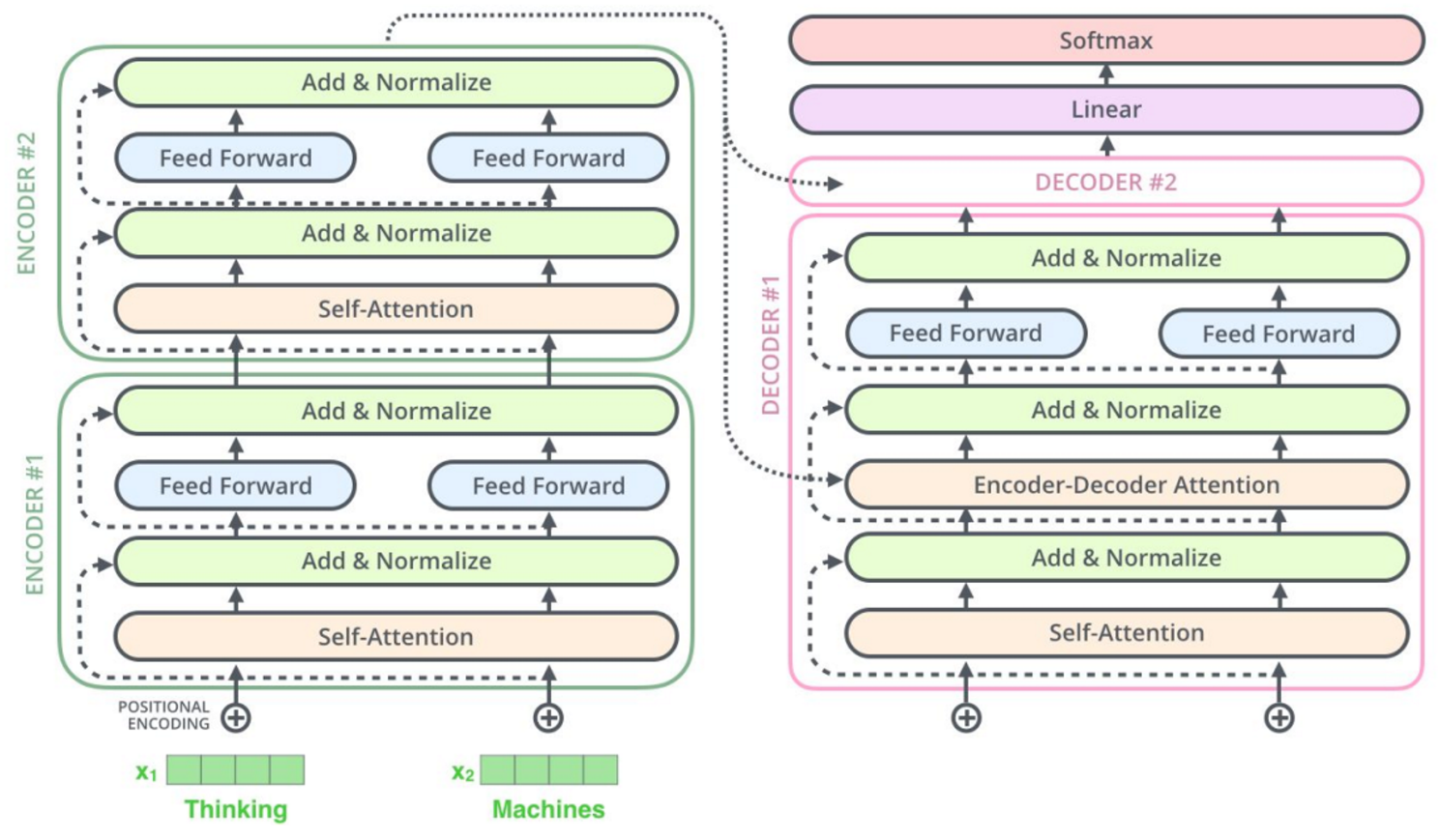
更具体来说可以这么理解:使用了多层完整 Transformer encoder-decoder 结构的预训练大模型案例 T5 语言大模型,端到端来看,其 encoder 与 decoder 之间的中间变量为隐变量,对人类而言的确是不可读的黑盒数据,然而 BERT 和 GPT 并不能分别理解成只砍掉了 decoder 和 只砍掉了 encoder 的 T5!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号