
Flink源码解析(十)——Flink On Yarn客户端提交过程解析
一、Flink On Yarn三种客户端作业提交模式
1、方式一、Per-Job 模式
作业提交命令行方式:./bin/flink run -t yarn-per-job -d -ynm FlinkAppName -Dyarn.application.name=FlinkRetention -c com.dake.FlinkAppName ${JarFileDir}/FlinkStudy.jar xxx
Per-Job模式在Flink系统中已处于Deprecated状态,后续不推荐使用。
2、方式二、Session模式
(1)、 ./bin/yarn-session.sh -jm <jm-memory> -tm <tm-memory> -s <slots-per-taskmanager> -z <zk-namespace> -nm <app-name> -d
(2)、 ./bin/flink run -c com.dake.FlinkAppName -yid application_1602374521458_0001 ${JarFileDir}/FlinkStudy.jar xxx
3、方式三、Application模式
./bin/flink run-application -t yarn-application -Dparallelism.default=3 -Djobmanager.memory.process.size=2048m -Dtaskmanager.memory.process.size=4096m -Dyarn.application.name=FlinkAppName -Dtaskmanager.numberOfTaskSlots=3 -c com.dake.FlinkAppName ${JarFileDir}/FlinkStudy.jar xxx
4、三种提交模式对比
由bin/flink.sh脚本可知,客户端提交过程统一由org.apache.flink.client.cli.CliFrontend入口类触发。Per-Job模式和Session模式下Flink应用main方法都会在客户端运行。客户端解析生成JobGraph后会将依赖项和JobGraph序列化后的二进制数据一起发往集群上。当客户端机器上有大量作业提交时,这两种模式会导致客户端承受较大带宽压力。为解决该问题,Application模式将Flink应用main方法触发过程后置到JobManager生成过程中,以此将带宽压力分散到集群各节点上。
exec "${JAVA_RUN}" $JVM_ARGS $FLINK_ENV_JAVA_OPTS "${log_setting[@]}" -classpath "`manglePathList "$CC_CLASSPATH:$INTERNAL_HADOOP_CLASSPATHS"`" org.apache.flink.client.cli.CliFrontend "$@"
二、Application模式提交过程解析
本小节以Application提交模式为例,说明客户端提交Flink作业过程。由上可知CliFrontend为客户端进程入口类,其main(...)入参主要包括run-application、-t yarn-application、-c com.dake.FlinkAppName等。
1、CliFrontend入口类调用链路如下:
CliFrontend.main(...)
CliFrontend.mainInternal(...)
CliFrontend.parseAndRun(...)
CliFrontend.runApplication(...)
ApplicationClusterDeployer.run(...)
其中CliFrontend.mainInternal(...)方法会解析flink-conf.yaml文件,生成作业执行时需要的配置项,新建CliFrontend实例。构造函数中新建DefaultClusterClientServiceLoader实例并赋值成员变量clusterClientServiceLoader。该成员负责生成Yarn Client信息。
CliFrontend.runApplication(...)方法会新建ProgramOptions实例,ProgramOptions.entryPointClass成员值是flink命令行-c选项指定的Flink应用入口类com.dake.FlinkAppName,后面会以反射的形式触发main()方法调用。entryPointClass值会赋值给ApplicationConfiguration.applicationClassName成员变量,如下图。
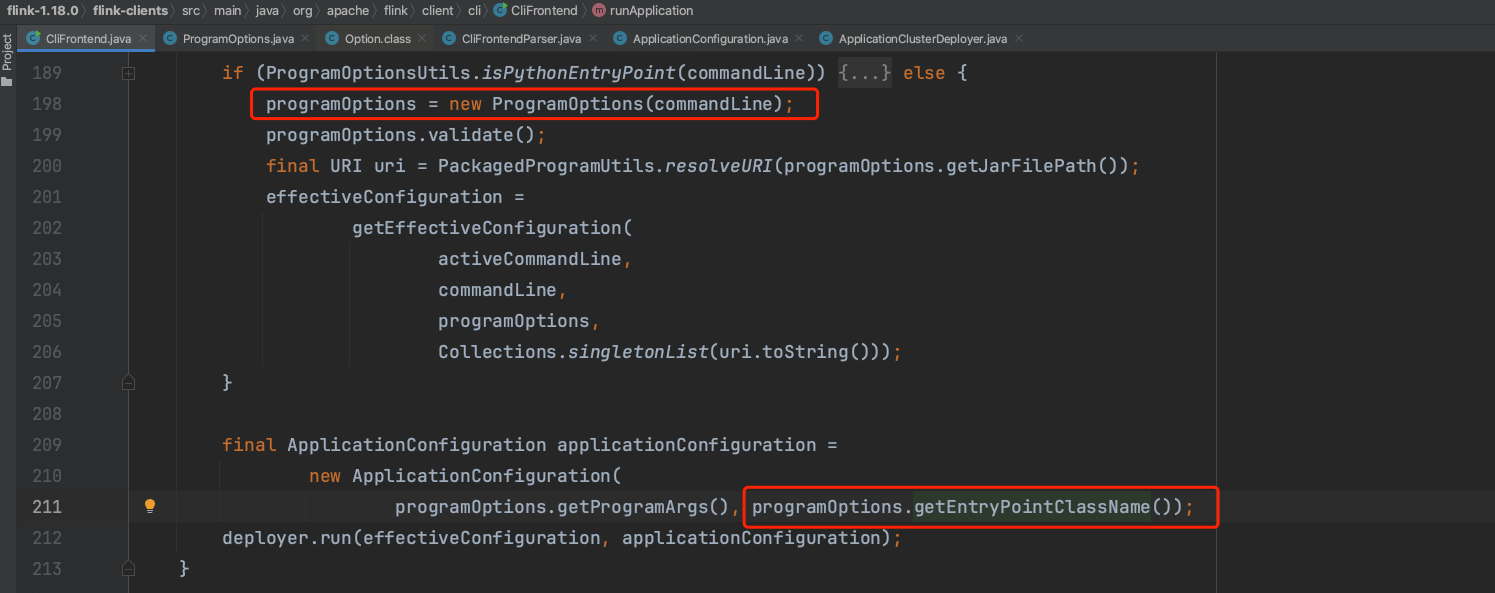


deployer.run(...)方法负责加载Yarn Application模式客户端信息等。
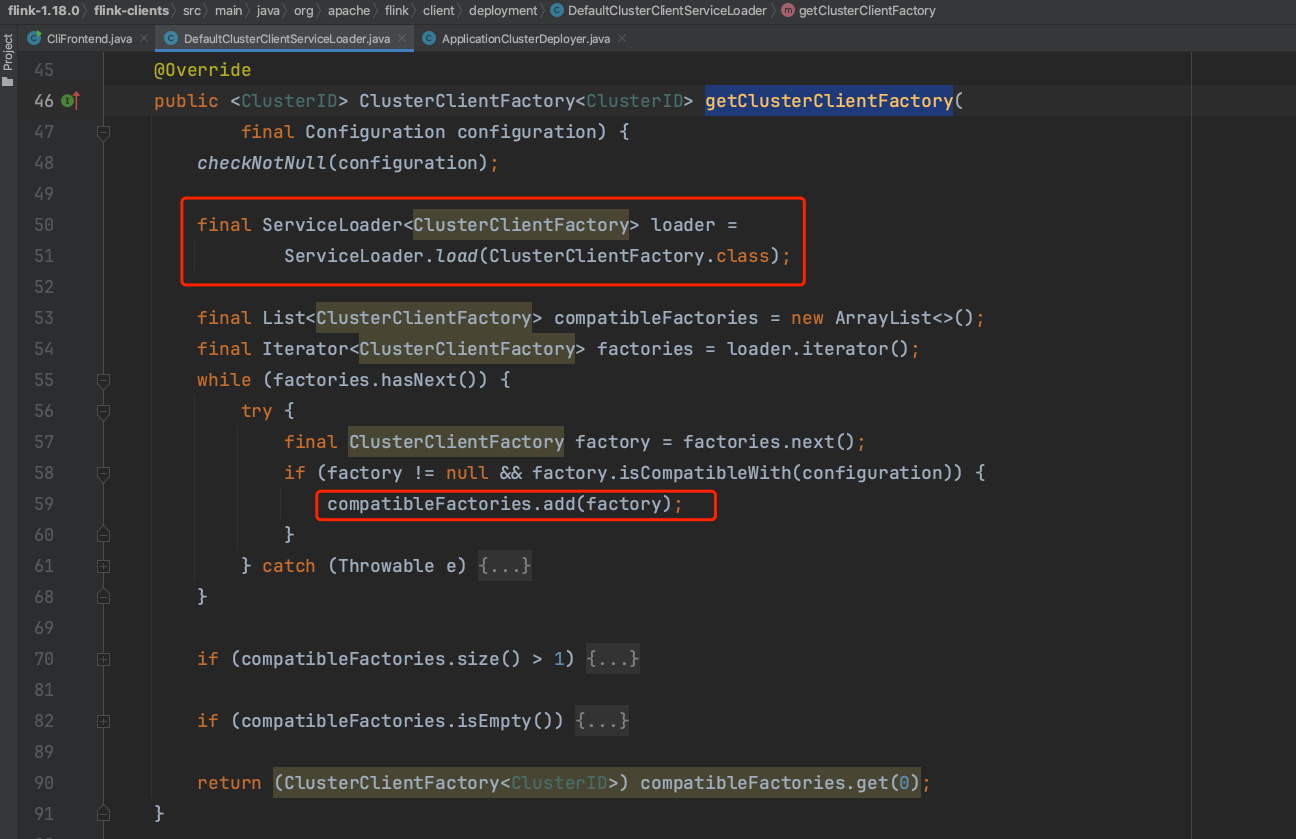
由DefaultClusterClientServiceLoader.getClusterClientFactory(...)方法可知,ServiceLoader会判断所有ClusterClientFactory.isCompatibleWith()返回值为true的ClusterClientFactory类实例。Flink系统Yarn Application模式下ClusterClientFactory类体系isCompatibleWith()方法为true的可选项只有YarnClusterClientFactory,因此DefaultClusterClientServiceLoader.getClusterClientFactory(...)方法返回YarnClusterClientFactory实例。YarnClusterClientFactory实例负责生成Yarn Client信息继而提交Flink作业。
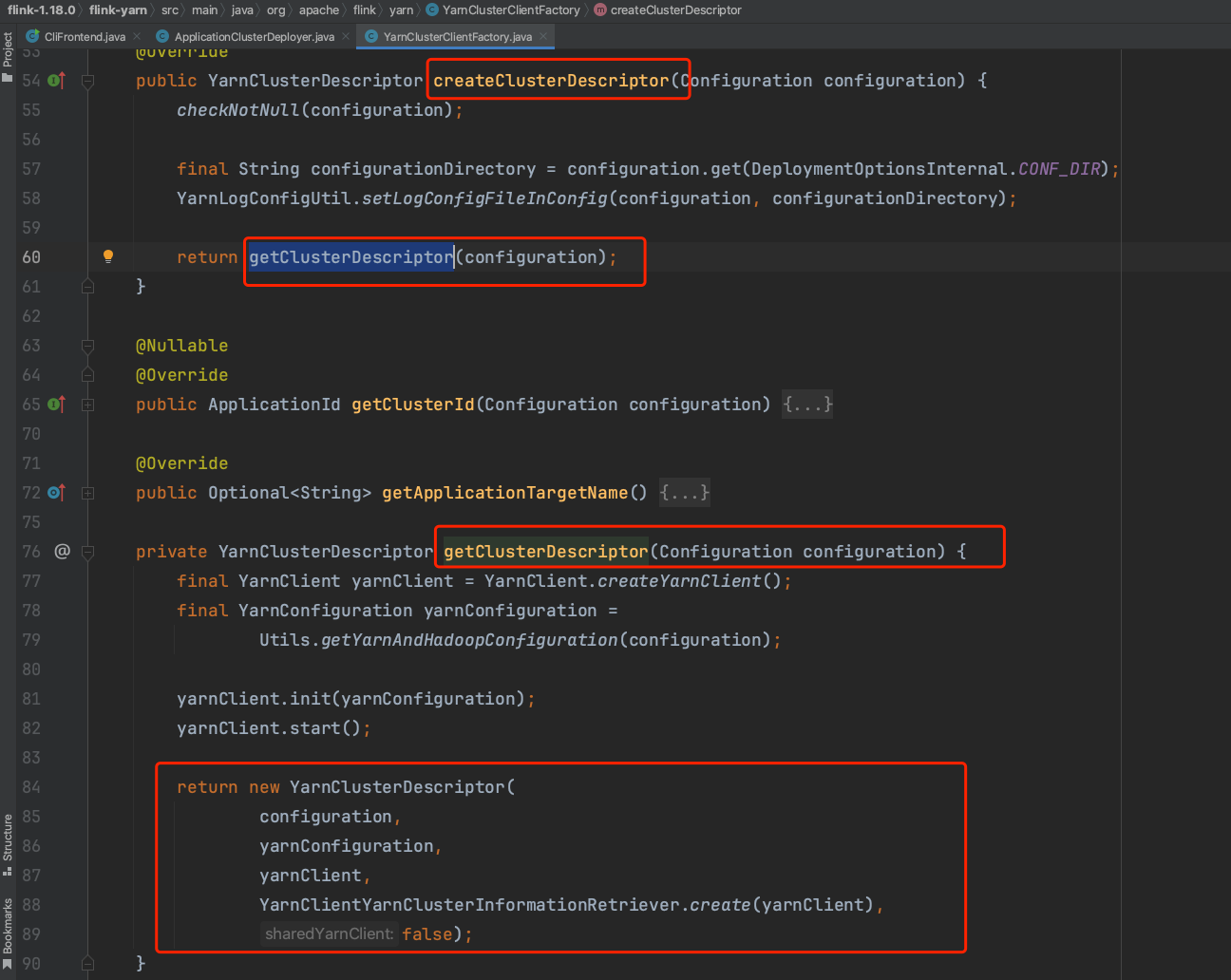
CliFrontend.runApplication(...)方法会调用ApplicationClusterDeployer.run(...)方法,接着调用YarnClusterClientFactory.createClusterDescriptor(...)方法。createClusterDescriptor(...)方法会新建YarnClient实例,YarnClient实例负责在客户端提交Flink应用程序。最后新建YarnClusterDescriptor实例并返回。
ApplicationClusterDeployer.run(...)方法最后会执行YarnClusterDescriptor.deployApplicationCluster(...)方法。
2、YarnClusterDescriptor.deployApplicationCluster(...)方法调用过程如下:
(1)、YarnClusterDescriptor.deployApplicationCluster(...);进行一些配置和检查,并调用deployInternal(...)方法。
(2)、YarnClusterDescriptor.deployInternal(...);
该方法第三个入参YarnApplicationClusterEntryPoint.class.getName()可代表随笔一中Yarn框架第一步涉及的ApplicationMaster程序。在方法中进行一些用户权限认证、配置参数检查、yarn队列检查等操作,通过YarnClient实例新建YarnClientApplication实例,进行yarn资源参数检查,最后调用startAppMaster(...)方法。
(3)、YarnClusterDescriptor.startAppMaster(...);该方法比较长,但理解起来简单,总体来说就是通过YarnClient提交新建的Application信息,向Yarn:ResourceManager通信,启动上述ApplicationMaster过程。
1)、首先是初始化文件系统。
2)、ApplicationSubmissionContext appContext = yarnApplication.getApplicationSubmissionContext();Yarn应用新建应用提交上下文信息
3)、获取yarn.provided.lib.dirs、yarn.provided.usrlib.dir参数指定的Yarn应用依赖文件。
4)、设置应用提交上下文信息,为applicationId设置高可用信息。
5)、收集用户jar文件,用户类路径信息。
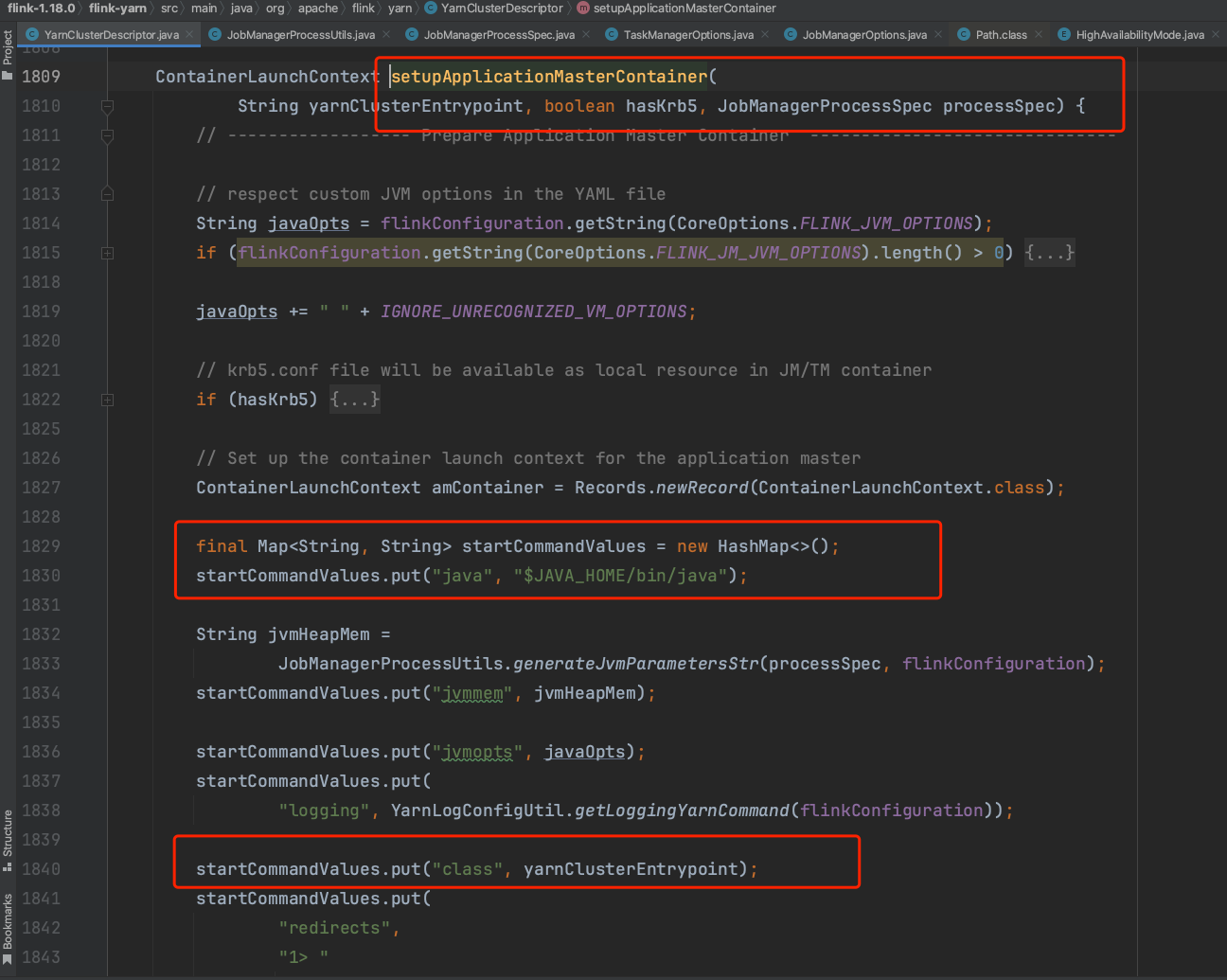
6)、在收集完上述一系列依赖文件后,final ContainerLaunchContext amContainer = setupApplicationMasterContainer(yarnClusterEntrypoint, hasKrb5, processSpec);负责设置启动ApplicationMaster的命令操作,如下图所示。
7)、给amContainer实例设置环境变量,最后将amContainer包含在appContext变量中。
8)、yarnClient.submitApplication(appContext);//代码最终触发YarnClient客户端提交信息,即随笔一中介绍Yarn框架的第一步的提交过程。Application模式下分析到此处依然未涉及到Flink应用main()方法的执行,而在Per-Job、Session模式下,CliFrontend会先触发Flink应用main(...)方法执行,生成StreamExecutionEnvironment执行环境、Transformation、StreamGraph、JobGraph,最后携带着JobGraph信息执行yarnClient.submitApplication()方法。由此可知Application提交模式下StreamGraph、JobGraph等信息是在YARN ApplicationMaster服务中生成的。
3、上一小节讲述到YarnClient提交过程,Yarn:ResourceManager收到ApplicationMaster信息后,会通知NodeManager分配Container并启动ApplicationMaster程序,即上面讲的YarnApplicationClusterEntryPoint程序。此小节着重分析YarnApplicationClusterEntryPoint涉及的Flink应用main(...)方法启动过程,YarnApplicationClusterEntryPoint整体启动过程在后面随笔中详细讲解。
(1)、由下图可知在YarnApplicationClusterEntryPoint.main(...)方法中调用getPackagedProgram(...)方法生成Flink应用入口类main(...)方法信息,后面通过反射方式触发Flink应用main(...)方法执行。
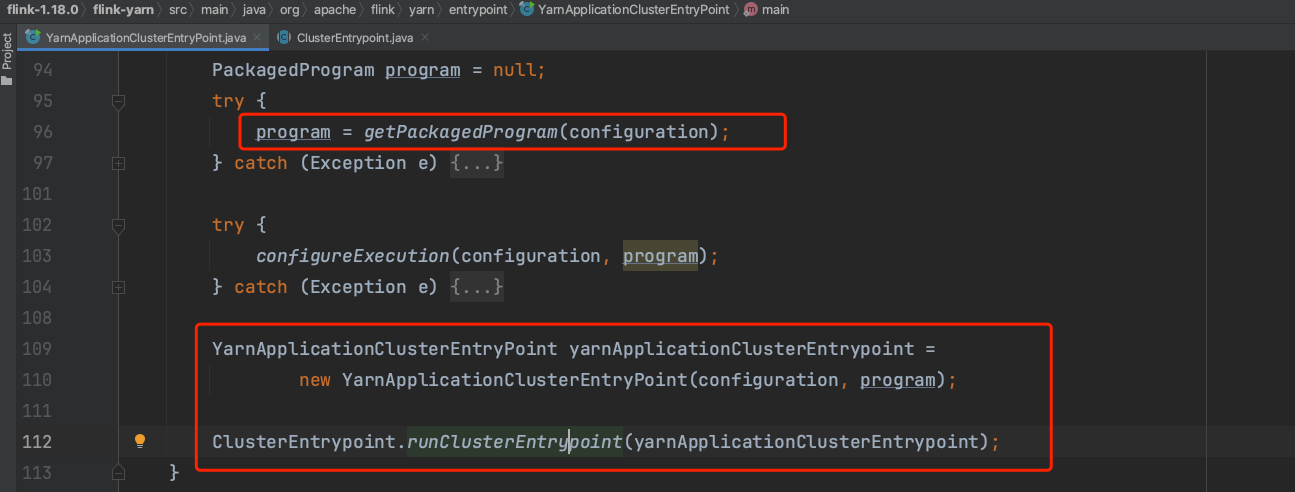
(2)、ClusterEntrypoint.runClusterEntrypoint(...)方法的调用链路如下:
ClusterEntrypoint.runClusterEntrypoint(...)
ClusterEntrypoint.startCluster(...)
ClusterEntrypoint.runCluster(...)
ClusterEntrypoint.initializeServices(...)
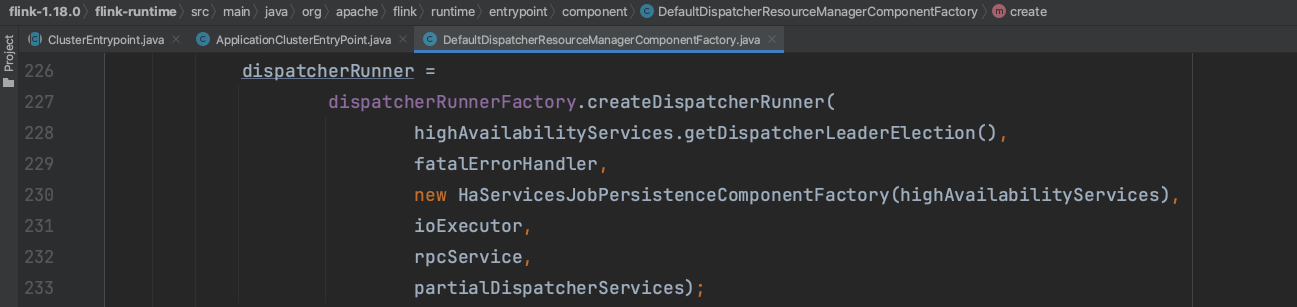
DispatcherResourceManagerComponent clusterComponent = dispatcherResourceManagerComponentFactory.create(...);
其中dispatcherResourceManagerComponentFactory变量的实际类型是DefaultDispatcherResourceManagerComponentFactory,其初始化信息如下:
ApplicationClusterEntryPoint.createDispatcherResourceManagerComponentFactory(){
new DefaultDispatcherResourceManagerComponentFactory{
dispatcherRunnerFactory:new DefaultDispatcherRunnerFactory{
dispatcherLeaderProcessFactoryFactory(configuration,dispatcherFactory,program):ApplicationDispatcherLeaderProcessFactoryFactory.create(configuration, SessionDispatcherFactory.INSTANCE, program)
};
resourceManagerFactory:YarnResourceManagerFactory.getInstance();
restEndpointFactory:JobRestEndpointFactory.INSTANCE;
}
}
DefaultDispatcherResourceManagerComponentFactory.create(...)通过下图一系列调用链路生成dispatcherRunner实例,dispatcherRunner实例负责dispatcher组件的高可用leader选举操作,而dispatcher组件负责触发Flink应用main(...)方法执行。
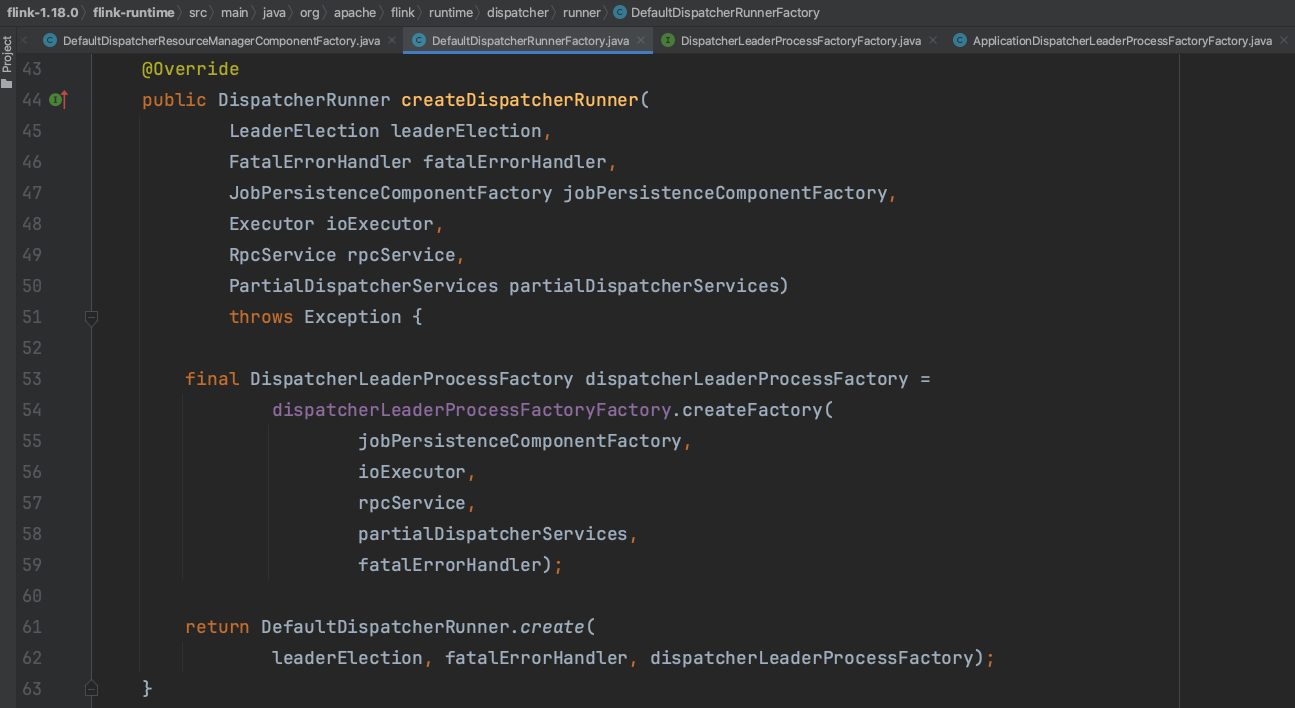
下图类文件DefaultDispatcherRunner中dispatcherRunner.start()触发dispatcher组件高可用Leader选举过程。
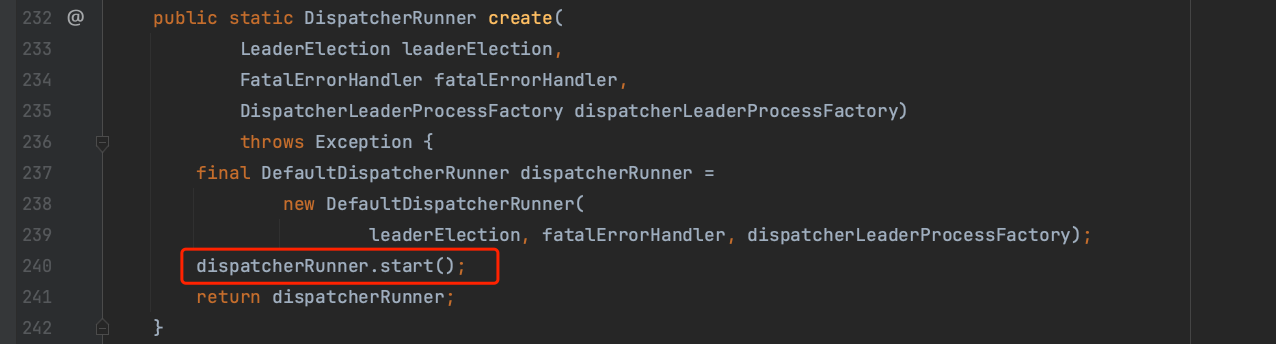
选举为leader的DefaultDispatcherRunner实例候选者在回调动作过程中会调用到下图的grantLeadership(...)方法,并在startNewDispatcherLeaderProcess(...)方法中生成dispatcherLeaderProcess,通过newDispatcherLeaderProcess::start方法启动dispatcherLeaderProcess实例。Leader候选者回调动作触发过程会在下一篇随笔中详细讲解,此处先这样理解。
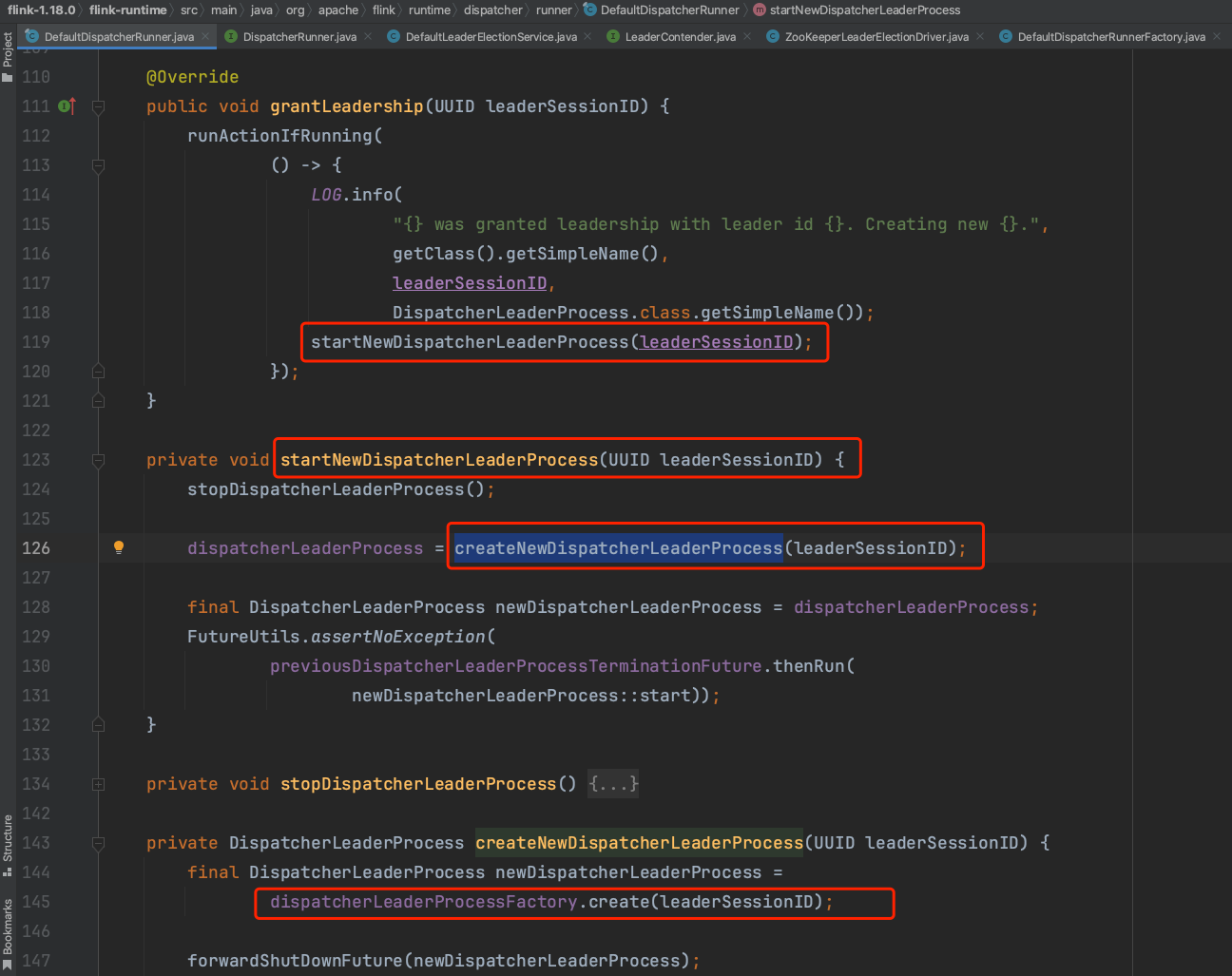
newDispatcherLeaderProcess的实际类型是SessionDispatcherLeaderProcess,下图所示通过父类的start()方法最后调用到该类的createDispatcher(...)方法。
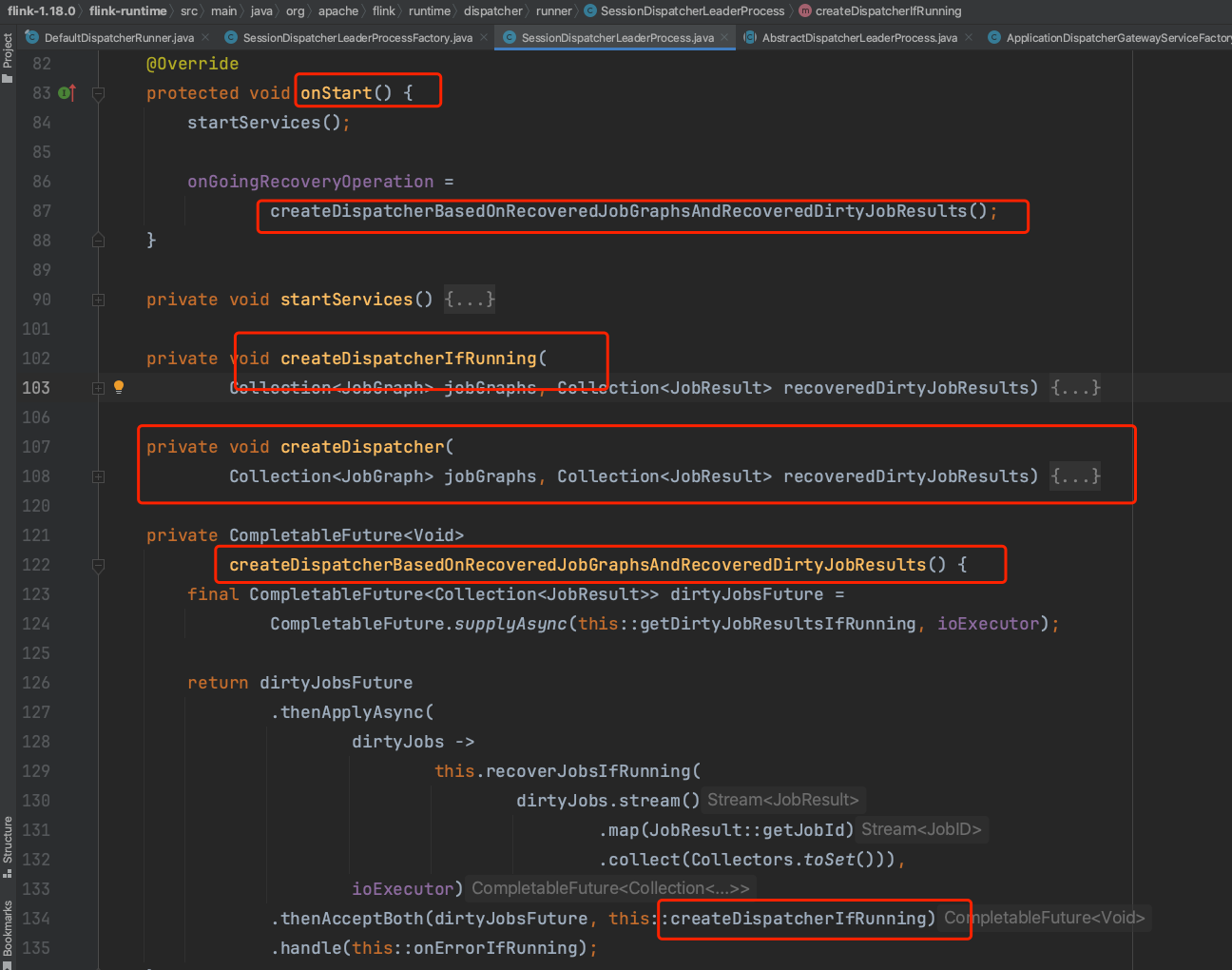
createDispatcher(...)方法会调用dispatcherGatewayServiceFactory.create(...)方法,dispatcherGatewayServiceFactory实际类型是ApplicationDispatcherGatewayServiceFactory。在dispatcherGatewayServiceFactory.create(...)方法中新建ApplicationDispatcherBootstrap实例时,通过以下方法调用链fixJobIdAndRunApplicationAsync(...) -> runApplicationAsync(...) -> runApplicationEntryPoint(...) -> ClientUtils.executeProgram(...) -> program.invokeInteractiveModeForExecution() -> callMainMethod(mainClass, args) -> mainMethod.invoke(null, (Object) args)触发Flink应用main(...)方法的执行,继而开始随笔二至随笔九的代码执行。
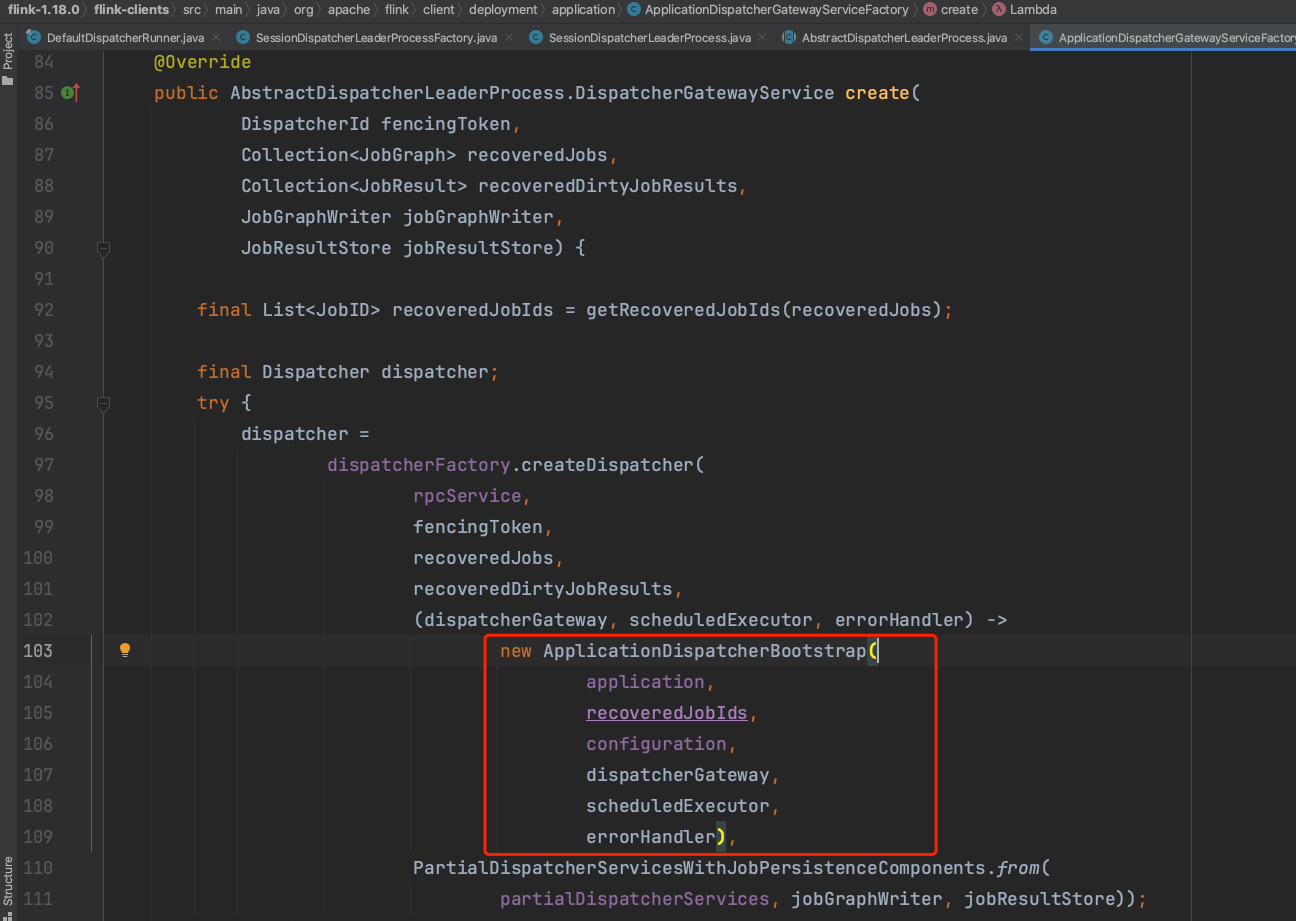
以上即为Flink On Yarn客户端作业提交过程的解析。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号