


GaussDB数据库SQL系列:SQL与ETL实践深度解析
GaussDB数据库SQL系列:SQL与ETL实践深度解析
一、ETL核心概念与GaussDB适配性
1.1 ETL技术演进
传统ETL:基于ETL工具(如Informatica)的离线批处理
现代ETL:SQL流批一体(Flink+GaussDB协同)
GaussDB优势:原生支持分布式并行ETL处理,兼容标准SQL接口
1.2 GaussDB ETL架构
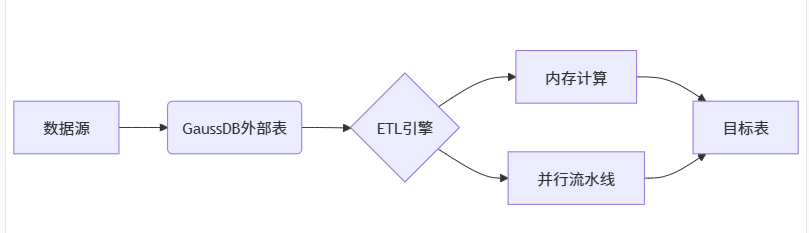
二、ETL核心技术实现
2.1 数据抽取策略
全量抽取
-- 使用COPY命令高速导入
COPY (SELECT * FROM src_table)
TO PROGRAM 'gzip > /data/backup.sql.gz'
WITH (FORMAT CSV, HEADER);
增量抽取
-- 基于SCN日志捕获(Oracle兼容)
SELECT * FROM orders
WHERE scn > (SELECT MAX(scn) FROM etl_checkpoint);
-- 基于时间戳增量
SELECT * FROM logs
WHERE log_time > NOW() - INTERVAL '1 hour';
实时流处理
-- 创建逻辑复制槽
SELECT * FROM pg_create_logical_replication_slot('cdc_slot', 'pgoutput');
-- 流式消费
BEGIN;
FETCH 1000 FROM cdc_stream;
PERFORM process_stream_data();
COMMIT;
2.2 数据转换引擎
数据清洗
-- 复杂数据脱敏
UPDATE raw_data
SET phone = REGEXP_REPLACE(phone, '(\d{3})\d{4}(\d{4})', '\1****\2'),
email = NULLIF(email, '')
WHERE data_quality_flag = 'DIRTY';
关系型转换
-- JSON数据结构化
SELECT
jsonb_extract_path_text(event_data, 'user_id')::BIGINT AS user_id,
(event_data->>'amount')::NUMERIC(10,2) AS transaction_amount
FROM raw_events;
窗口函数应用
-- 计算用户行为漏斗
WITH funnel AS (
SELECT
user_id,
MAX(CASE WHEN event_type = 'view' THEN event_time END) AS view_time,
MAX(CASE WHEN event_type = 'cart' THEN event_time END) AS cart_time,
MAX(CASE WHEN event_type = 'purchase' THEN event_time END) AS purchase_time
FROM user_events
GROUP BY user_id
)
SELECT
COUNT(*) FILTER (WHERE view_time IS NOT NULL) AS views,
COUNT(*) FILTER (WHERE cart_time IS NOT NULL) AS carts,
COUNT(*) FILTER (WHERE purchase_time IS NOT NULL) AS buys
FROM funnel;
2.3 数据加载模式
分区表加载
-- 并行写入分区表
INSERT INTO sales_partitioned
PARTITION (sale_date = CURRENT_DATE)
SELECT * FROM staging_sales
WHERE sale_date = CURRENT_DATE;
-- 自动合并小文件
ALTER TABLE logs SET (autovacuum_enabled = true, toast.autovacuum_vacuum_scale_factor = 0.2);
双写校验机制
-- 事务型双写
BEGIN;
INSERT INTO target_table SELECT * FROM staging_table;
INSERT INTO etl_audit (record_count)
SELECT COUNT(*) FROM staging_table;
COMMIT;
三、高阶ETL场景实战
- 数据湖ETL架构
-- 创建外部表访问OSS数据
CREATE FOREIGN TABLE oss_orders (
order_id BIGINT,
user_id INT,
amount NUMERIC
) SERVER oss_options OPTIONS (
endpoint 'oss-cn-hangzhou.aliyuncs.com',
path '/orders/'
);
-- 执行跨存储ETL
INSERT INTO warehouse.orders
SELECT * FROM oss_orders
WHERE amount > 1000
CONCURRENTLY;
- 实时数仓增量更新
-- 创建变更数据捕获视图
CREATE MATERIALIZED VIEW cdc_view
REFRESH MATERIALIZED ON DEMAND
AS
SELECT
CASE WHEN operation = 'U' THEN 'UPDATE'
WHEN operation = 'I' THEN 'INSERT'
ELSE 'DELETE' END AS dml_type,
changed_data.*
FROM changelog_stream;
-- 实时更新维度表
MERGE INTO dim_product AS target
USING cdc_view AS source
ON (target.product_id = source.product_id)
WHEN MATCHED AND source.dml_type = 'U' THEN
UPDATE SET price = source.price
WHEN NOT MATCHED THEN
INSERT (product_id, price) VALUES (source.product_id, source.price);
- 图计算ETL
-- 社交网络关系分析
SELECT
id,
sum(CASE WHEN rel_type = 'follow' THEN 1 ELSE 0 END) AS followers,
sum(CASE WHEN rel_type = 'friend' THEN 1 ELSE 0 END) AS friends
FROM social_graph
GROUP BY id
HAVING sum(CASE WHEN rel_type = 'friend' THEN 1 ELSE 0 END) > 100;
四、性能优化秘籍
- 并行处理配置
-- 设置并行度
SET max_parallel_workers_per_gather = 8;
-- 分区剪枝优化
EXPLAIN ANALYZE
SELECT * FROM sales
WHERE sale_date BETWEEN '2023-01-01' AND '2023-01-31'
AND region = 'East';
- 内存管理技巧
-- 调整work_mem参数
SET work_mem = '256MB';
-- 使用临时表分段处理
CREATE TEMP TABLE temp_stage AS
SELECT * FROM raw_data
WHERE MOD(row_number, 100) = 0;
-- 批量提交事务
DO $$
DECLARE
batch_size INT := 50000;
BEGIN
FOR i IN 1..100 LOOP
INSERT INTO target_table
SELECT * FROM staging_table
LIMIT batch_size OFFSET i*batch_size;
COMMIT;
END LOOP;
END
$$;
- 存储优化方案
-- 列存表加速分析
CREATE TABLE fact_table (
log_id BIGSERIAL,
event_time TIMESTAMPTZ,
user_id INT
) WITH (orientation = column);
-- 数据压缩配置
ALTER TABLE logs SET (compression = lz4);
五、质量管控体系
- 数据校验规则
-- 基数校验
SELECT
COUNT(DISTINCT user_id) AS src_distinct,
COUNT(DISTINCT user_id) FILTER (WHERE is_valid) AS tgt_distinct
FROM staging_data;
-- 范围校验
SELECT * FROM transactions
WHERE amount < 0 OR amount > 1000000;
- 异常处理机制
-- 错误捕获存储过程
CREATE OR REPLACE FUNCTION etl_wrapper()
RETURNS VOID AS $$
DECLARE
error_msg TEXT;
BEGIN
BEGIN
PERFORM complex_etl();
EXCEPTION WHEN OTHERS THEN
GET STACKED DIAGNOSTICS error_msg = MESSAGE_TEXT;
INSERT INTO etl_errors (error_time, message)
VALUES (NOW(), error_msg);
RAISE NOTICE 'ETL failed: %', error_msg;
END;
END;
$$ LANGUAGE plpgsql;
六、最佳实践建议
- 架构设计原则
分层处理:ODS → DWD → DWS → ADS
血缘追踪:维护元数据血缘关系
版本控制:SQL脚本Git化管理 - 性能基准指标
场景 单节点吞吐量 扩展性系数
全量数据加载 500GB/hour 线性扩展
实时流处理 10万条/秒 弹性伸缩
复杂转换计算 200万行/分钟 亚线性扩展 - 监控体系构建
-- ETL健康度监测
SELECT
job_name,
status,
duration_seconds,
rows_processed,
error_count
FROM etl_monitoring
WHERE start_time > NOW() - INTERVAL '1 hour';
总结
GaussDB SQL ETL方案具备三大核心价值:
统一接口:通过标准SQL实现全链路ETL
智能优化:自动识别执行计划瓶颈
生态兼容:无缝对接Kafka、Flink等现代数据栈


 浙公网安备 33010602011771号
浙公网安备 33010602011771号