


GaussDB高智能--自治运维技术 日志分析
日志是产品最重要的基础运维数据之一,它是一种文本数据,一般由时间戳和文本消息(等级、常量、其余变量)组成,实时记录了业务的运行状态。因此凡是能够打印日志的设备,理论上均可以通过分析日志,进行故障预测、亚健康检测、故障定界定位等维护活动。
对故障诊断任务而言,日志相较指标有着诊断代码段级别故障,支持对程序执行逻辑的跟踪,捕捉故障细节的优势,并且很多时候是唯一可用的故障诊断数据源。
GaussDB的日志分析功能主要是将非结构化的日志流,转换为时序数据,而后天然地与异常检测等机制进行对接,便于整合完整的异常诊断能力。日志分析功能包括两个关键部分,一个是日志采集模块,另一个是日志分析模块,这两个部分都在日志采集端实现,其整体模块结构图如下:
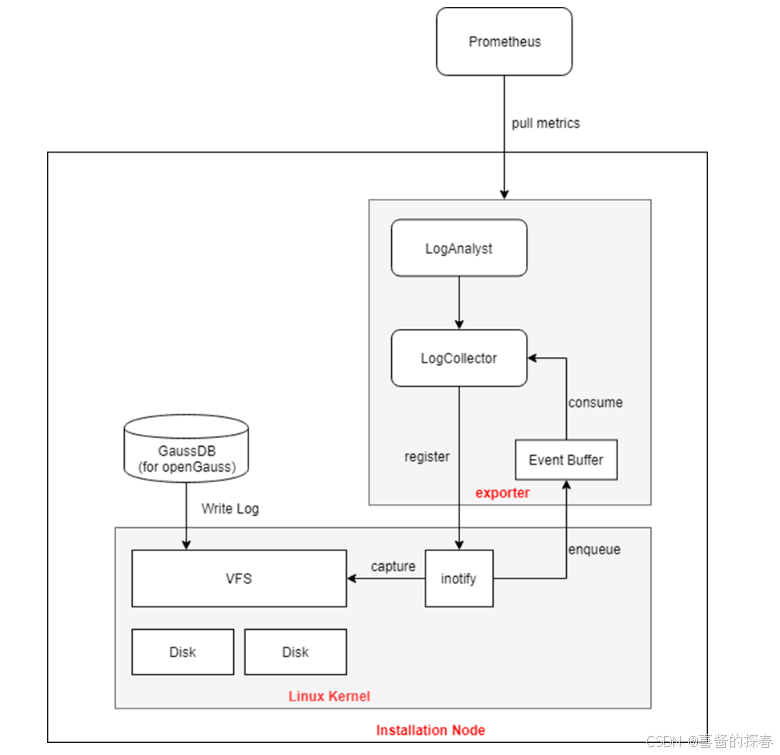
日志采集和分析的步骤如下:
(1)启动本功能的exporter, 利用Linux的inotify系统调用,监听日志写入事件;
(2)GaussDB数据库实例向被监听的日志文件目录写入日志;
(3)exporter 通过inotify系统调用,获知日志写入事件,exporter的LogCollector子模块从日志文件目录中读取被写入的日志文件内容;
(4)exporter的LogAnalyst模块获取写入的日志文件内容,并对其进行量化整理;
(5)时序数据库访问exporter,LogAnalyst将已经量化好的日志指标项返回时序数据库。 日志分析功能在具体实现上,主要包括离线学习模块和在线检测模块两部分,其设计流程图如下图所示:
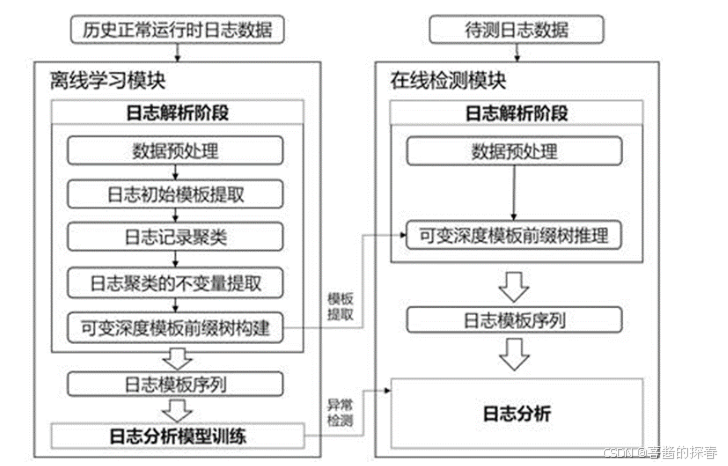
其中离线学习模块具体有以下步骤:
(1)日志解析阶段数据预处理:根据预设正则表达式去除噪声变量和拆分日志记录文本字符串得到单词列表,如日志记录“2020 04 23 17:01:11 INFO getGraceTime, customerID: lisi4, bpID: d1, graceTime:0”通过正则表达式替换customerID信息为通配符‘’,并拆分字符和驼峰词命名词得到三部分,分别是时间:“2020 04 23 17:01:11”,等级:“INFO”,“单词列表”:['get', 'grace', 'time', ',', 'customer', 'id', ':', '', ',', ‘bp’, 'id', ':', 'd1hg123', 'grace', 'time', ':', '0'];日志初始模板提取:这里关键词指日志常量部分,一般来讲常用英文,通过关键词词典,这里使用了维基百科语料出现频率前10000且含有字母数目超过2的纯英文单词加上业务专有术语作为关键词词典,将上述单词列表里非关键词替换为通配符,得到日志初始模板['get', 'grace', 'time', ',', 'customer', 'id', ':', '', ',', ‘bp’, 'id', ':', '', 'grace', 'time', ':', ''];日志记录聚类:相同日志初始模板的日志记录会被聚类为一个日志集合,比如日志记录“getGraceTime, customerID: lisi4, bpID: d1, graceTime:0”与另一个日志记录“getGraceTime, customerID: zhangsan123, bpID: ss2, graceTime:0”的日志初始模板都是['get', 'grace', 'time', ',', 'customer', 'id', ':', '', ',', ‘bp’, 'id', ':', '', 'grace', 'time', ':', ''],因此这两条日志记录会被聚类在同一个日志集合里;日志聚类的不变量提取:对于同一日志集合里多条日志记录的单词列表相同位置的不变量提取日志模板,如对上述日志集合对应的单词列表['get', 'grace', 'time', ',', 'customer', 'id', ':', '', ',', ‘bp’, 'id', ':', '', 'grace', 'time', ':', '']和['get', 'grace', 'time', ',', 'customer', 'id', ':', '', ',', ‘bp’, 'id', ':', '', 'grace', 'time', ':', ''],通过相同位置的两两比较,保留其中不变量,变化的单词位置则替换为通配符‘*’,最后得到该日志集合里日志记录的日志模板“getGraceTime, customerID: *, bpID: *, graceTime:0”;可变深度模板前缀树构建:以日志模板诸的每个单词(包括常量和通配符)为节点构建可变深度模板前缀树,逐个插入上述过程中得到的日志模板,建立单词列表到日志模板的映射,可以在线对日志单词列表推理其日志模板。其中可变深度指单个通配符节点允许匹配更多或更少的单词,从而能实现在线提取变长变量的日志记录的模板。
(2)日志分析模型的训练上述离线学习模块是与数据库日志结构和内容相关的,功能在发布时,会自带一个小的预训练模型。此模型的训练和使用过程对用户是透明的,用户无需任何额外操作。
(3)在线检测模块日志解析阶段的数据预处理:与离线学习模块一致,根据预设正则表达式去除噪声变量和拆分日志记录文本字符串得到单词列表;日志解析阶段的可变深度模板前缀树推理:通过模板前缀树匹配单词列表,将每个日志记录的单词列表映射到日志模板。如果出现变量数量有变化的日志,如“2020 04 23 17:01:11 INFO getGraceTime, customerID: lisi4,zhangsan3, bpID: d1, graceTime:0”,可变深度模板前缀树会允许单个通配符节点“”匹配更多的单词(这个例子里则是“lisi4”和“zhangsan3”)提取出日志模板['get', 'grace', 'time', ',', 'customer', 'id', ':', '', ',', ‘bp’, 'id', ':', '*', 'grace', 'time', ':', '0']。另外如果前缀树无法搜索到相应日志模板,则代表该日志模板为离线学习数据里没有出现过,会被标记为新增异常日志。 日志分析时,对已经在内存中模板化后的日志进行分析处理,提取我们希望使用的日志模板,进行指标量化。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号