


GaussDB关键技术原理:高弹性之hashbucket段页式
GaussDB关键技术原理:高弹性之hashbucket段页式
hashbucket位于段页式的下层,将段页式的文件组bucket化分片,如下图6所示
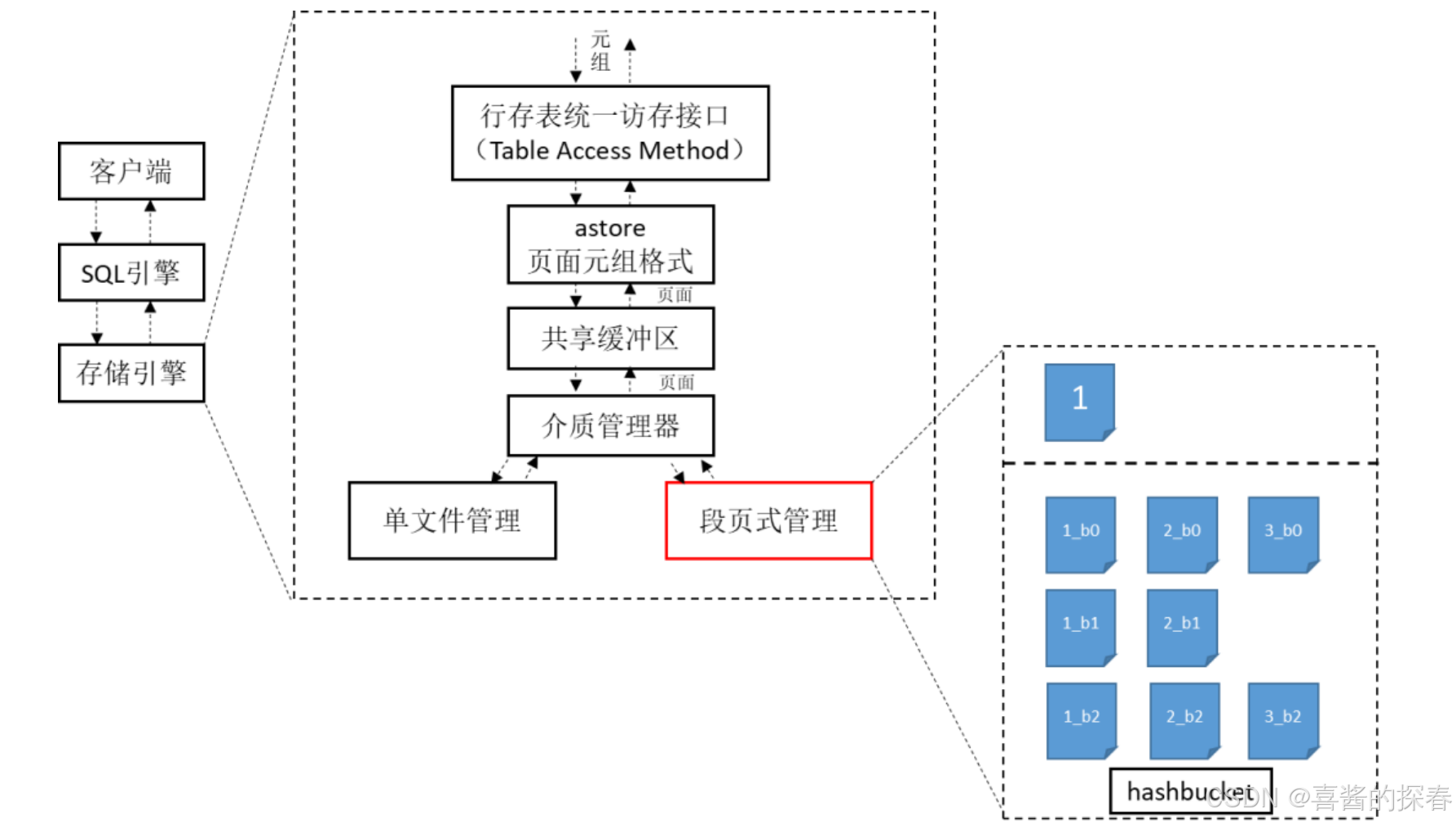
hashbucket表的bucket桶个数固定为1024个。每个DN分片拥有的bucket数量为1024/DN分片数量个。将上一章节介绍的段页式文件(1-5号)进行切片,拥有相同hash值的数据存在一组bucket段页式文件中,命名方式为文件编号_bucketid_[vm/fsm],其中1号小bucket段页式文件仍然存储元数据信息,主要是SegmentHeader,管理属于bucket 0的数据Extent;2号小bucket段页式文件存储真正的用户数据。因此以tablespace为粒度,每个库的每个tablespace拥有1024组1-5号bucket段页式文件。
hashbucket表与段页式的寻址方式类似,在系统表pg_class的relfilenode表示1号段页式文件中的一个页面号,表示最上层的元数据管理页面,通过如下结构体实现:
typedef struct BktMainHead { uint64 magic;
XLogRecPtr lsn;
BlockNumber bkt_main_head_map[BUCKETMAPLEN];
} SegmentHead;
其中,bkt_main_head_map是4字节*1024的数组,下标表示hashbucket桶的编号,内容表示小段页式文件中SegmentHeader所在的页面号。
以创建一张hashbucket表t1为例,寻址过程如下图7所示:
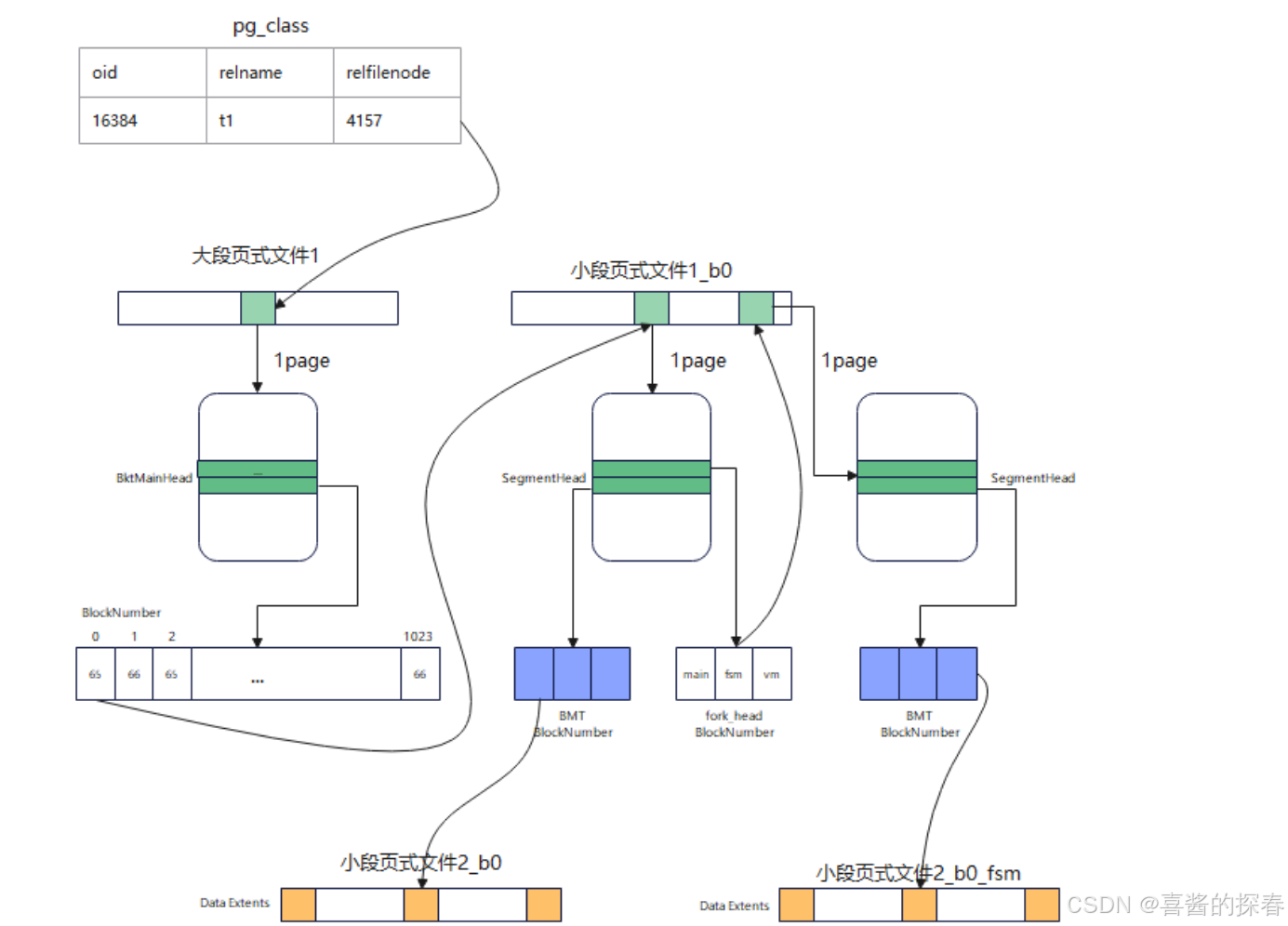
P1:通过pg_class的relfilenode能够访问到段页式1号文件中的BktMainHead页面4157。
P2:从BktMainHead的内容找到对应bucket 0 SegmentHeader所在的页面号,访问对应bucket 0的1号文件1_b0的页面65。
P3:通过页面1_b0的页面65的SegmentHeader记录的Extent位置信息存入对应的数据,或者根据传入的逻辑页面号翻译出要访问的物理页面位置。
P4:根据要访问的物理页面信息访问对应的bucket段页式文件2_b0。hashbucket的元数据管理采用上述方式主要为了后续扩容考虑,为了实现物理文件搬迁,我们需要直接把某个DN分片的bucket文件搬迁到新节点,为了保证文件搬迁后仍然可以寻址成功,需要在新DN build完元数据之后进行BktMainHead的更新,将即将搬迁至新节点的所有bucket 1号文件中的SegmentHeader所在的页面号更新到段页式1号文件的BktMainHead中。
hashbucket表的反向指针在bucket 1号文件中,SegmentHeader页面对应的反向指针存储的是1号段页式文件BktMainHead页面所在的页面号,因此需要在扩容期间基线数据搬迁完成时更新搬迁至新节点所有bucket 1号文件的SegmentHeader的反向指针。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号