

Python爬虫脚本 ,Uni-APP复选框做出双向绑定 ,Net5工作流建模 。的一点经验
从业C#开发多年,现在也经常用到Python 做网络爬虫 ,用Uni-app做手机前端。攒了一点经验。供其他多语言开发程序员借鉴吧。
Python做爬虫和其他的方式做爬虫最大的区别应该在于. Python 可以将浏览器内核寄宿到程序里。例如Ie内核。火狐内核。google内核。然后可以模拟人对浏览器的操作。不是简单的发起HTTP请求然后解析页面就结束。而是可以在页面上进行多次点击操作。程序还能一直监听发生变化后的页面元素。
from selenium import webdriver from lxml import etree from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys
webdriver 是python 将浏览器寄宿到程序的框架。并且可以模拟用户的操作。也提供基本的HTML解析方式
selenium 是更深一层 操作浏览器和 解析HTML元素的框架。有时候 同一段代码 webdriver 解析不出来 selenium 就是能解析出来。可能底层优化的更好吧
etree 会将HTML 解析成对象。获取里面的属性。
三者结合使用或许效果更好。
options = webdriver.FirefoxOptions() fp = webdriver.FirefoxProfile() # fp.set_preference('browser.download.dir',Common.getSection('downfile')) fp.set_preference("browser.download.folderList",2) fp.set_preference("browser.download.manager.showWhenStarting",False) fp.set_preference("browser.helperApps.neverAsk.saveToDisk","application/zip,application/octet-stream") driver = webdriver.Firefox(firefox_profile=fp,options=options)
browser.download.dir 指的是下载路径
browser.download.manager.showWhenStarting 指的是下载是否弹出询问框
browser.helperApps.neverAsk.saveToDisk 指的是下载的文件类型 ,如果爬页面还要获取网页下载的zip,或者jpg。这里都要用逗号加上文件的类型。
driver.get("http://www.stbchina.cn/item.html#?itemId="+itemCode.strip())
driver.get 写入你要爬取的地址
如果顺利的话,你可以看到程序启动了火狐浏览器并跳到了对应的网址上
不想看到浏览器的话,插入一下代码
options.add_argument('--headless')
浏览器会被隐藏
element = WebDriverWait(driver, 10).until( EC.presence_of_element_located((By.ID, "YOU-iD")) )
这段代码会等待页面十秒钟。在十秒内将元素加载成功后才会继续往下执行代码
但是过了十秒以后。元素还没有加载成功。会走入异常
也可以简单粗暴的使用线程挂起的方式,Python 程序停止响应几秒钟,但是并不影响寄宿的浏览器去加载页面元素
time.sleep(int(3))
在页面加载成功以后可以使用各种方式解析元素,或者操作页面
html = etree.HTML(driver.page_source)
解析html页面元素通常使用xpath ,如果大家不想学习xpath表达式。浏览器提供简单粗暴的方法
listImg=html.xpath('//*[contains(@class,"formwork_img")]/img')
点击页面右键 检查, 会出现我们都熟悉的控制台,在Elements里选择dom节点右键 copy , 然后在右侧的弹出框里选择 copy xpath。你会发现浏览器将写好的xpath语法写入了你的剪切板
获取元素的属性可以用
itme.attrib["src"]
当变成树状结构以后基本就跟操作tree 差不多
操作页面的话可以用
script=driver.find_element_by_xpath("//a[contains(text(),'发票下载')]").get_attribute('onclick')
找到某一个a标签。文本为发票下载。发送点击事件。但是我更推荐使用js脚本。
driver.execute_script('$("#sqrqq").val("'+strTime+'")') driver.execute_script('$("#sqrqz").val("'+endTime+'")') driver.execute_script('searchXzqq()')
就像大家用js操作前端一样。比发送点击事件更加靠谱。因为经常点击事件没有响应。
Uni-APP 最近使用场景有涉及到复选框做购物车,但是我在官网搜了一遍复选框的案例。我似乎看到官方回答,目前还不支持双向绑定,于是我自己做了一个

<checkbox-group class="agreement_radio" @change="checkboxChange">
checkbox-group 可以作为顶级父节点,类似Body, 绑定点击事件
根节点包含循环的数据体。
![]()

像这杨什么都可以包进去,它只是一个顶级父节点而已。每一个复选框包含一组数据。
Uni-app 目前的版本,哪怕你value 绑定了数据。checked 绑定了数据。在最后提交整个数组的时候,其实依旧不会改变绑定数组的checked.所以需要我们手动绑定。
再每次选中和取消复选框的时候触发事件 checkboxChange ,e.detail.value 是选中的数组的Value.被取消选中和没有选中的复选框是不会传递值的。而且不会改变绑定的数据。这多多少少有点不合适。在目前的版本。
所以当绑定数组和复选框改变事件的数据可以产生交集的时候。使用多重循环改变绑定数组的值。就可以双向绑定复选框和绑定数组了。
//整个购物车单条数据的选中和取消选中 checkboxChange: function(e) { // console.log(this.cart) var items = this.cart, values = e.detail.value; for (let b = 0; b < this.cart.length; b++) { for (let c = 0; c < this.cart[b].length; c++) { let continueArr = values.filter(item => { return item == this.cart[b][c].value; }) if (continueArr.length > 0) { this.cart[b][c].checked = true; } else { this.cart[b][c].checked = false; } //console.log("选中的值:" + continueArr) } } //console.log( this.cart) }
目前Net core 已经升级到了 NET 5 。以后既不是FrameWork 框架也不是Net core框架。其实底层也有Core的影子。
但是肯定不在通用老版的Net工作流框架了
于是百般无奈下自己琢磨了一套工作流思想和底层结构
一套后台可配置工作流
![]()

以及 APP前台审批
![]()
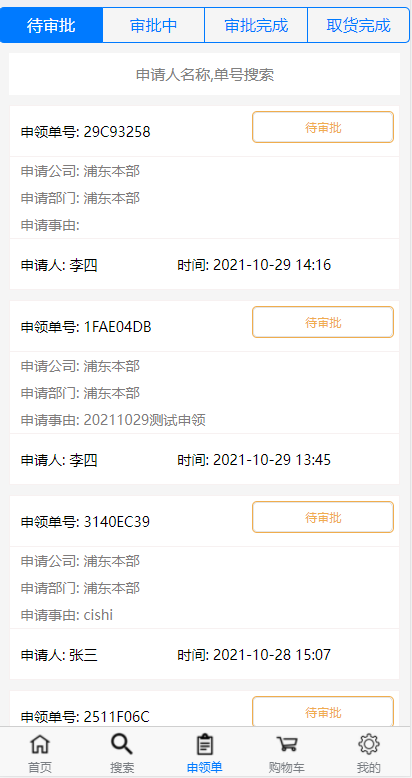
核心还是数据库的四张表
![]()

[WorkFlowTemplate]表如下,其实没什么用,只是为了在后台管理时可以区分每个工作流叫什么。

Guid 类似主键
Name 是这条工作流的名称
Type 是工作流的类型,比如 1=审批工作流 ,2=招标工作流
DepartmentId 是这个工作流挂在员工的部门Id。这个部门的人员发起的审批工作流直接走此工作流的审批链

[WorkFlowTemplateNode] 是此条工作流的审批链
Name表示这条审批链下此节点叫什么,
TempLateId 绑定到 WorkFlowTemplate的唯一表示主键下。
userList 存放此次审批节点的审批人集合。
TemplateType 审批节点的类型已经弃用了,当初定的是为1 需要此审批节点下全部人员通过,为0只要有一个人审批通过便算此审批节点通过。
Number 指的是此审批链下的第几个节点。为0是第一个审批节点,为1为2 以此类推。
工作流审批链就到此为止了,接下来是用户发起场景以及关联工作流
![]()

比如Order 表是用户发起申领物品的主表,
Reson 是用户申领的事由
OrderId 是此申领表的唯一主键
User_Sid 是用户唯一主键
其他不相关的申领详情表就略过了。。。。
当用户发起申请的时候,除了Order用户申领表,还有工作流任务关联表

这下用户发起的请求,关联的工作流以及审批链就串联起来了。
UserId 是谁发起的,
OrderId 关联那个申领单,
NodeId已弃用,
Gudi是当前用户关联工作流唯一主键
WorkId是关联的工作流
接下来是每一级审批链每一个审批人的相关信息

userId 是当前任务的审批人
TaskId 是用户关联工作流表 唯一主键,也就是上一张表的主键,
Desc 是备注,
attachment 是附件,
status 是审批状态,
NodeId 是 用户关联工作流表 次级审批的节点唯一主键 。用于判断这个人审批哪一环节。以及状态信息。

串联起来就是 先生成 WorkFlowTemplate 工作流模块流程,
然后WorkFlowTemplateNode绑定此模块的次级审批人物
接着 WorkFlow_Node 关联用户,申领信息,绑定工作流,
最后 WorkFlow_Task 绑定 在哪个工作流,在工作流的那个节点。 每一级审批人员的审批信息。
接口里关联用户,申领行为,发起审批。以及每一级审批的通过拒绝。以及扭转到下一级审批就不讲了,毕竟每个公司的业务不一致。这四张核心主表。就可以完成整个工作流的扭转。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号