import csv
# 读数据
file_path = r'data\EmailData.txt'
EmailData = open(file_path,'r',encoding='utf-8')
Email_data = []
Email_target = []
csv_reader = csv.reader(EmailData,delimiter='\t')
# 将数据分别存入数据列表和目标分类列表
for line in csv_reader:
Email_data.append(line[1])
Email_target.append(line[0])
EmailData.close()
# 把无意义的符号都替换成空格
Email_data_clear = []
for line in Email_data:
# line :'Go until jurong point, crazy.. Available only in bugis n great world la e buffet...'
# 每一行都去掉无意义符号并按空格分词
for char in line:
if char.isalpha() is False:
# 不是字母,发生替换操作:
newString = line.replace(char," ")
tempList = newString.split(" ")
# 将处理好后的一行数据追加到存放干净数据的列表
Email_data_clear.append(tempList)
# 去掉长度不大于3的词和没有语义的词
Email_data_clear2 = []
for line in Email_data_clear:
tempList = []
for word in line:
if word != '' and len(word) > 3 and word.isalpha():
tempList.append(word)
tempString = ' '.join(tempList)
Email_data_clear2.append(tempString)
Email_data_clear = Email_data_clear2
# 将数据分为训练集和测试集
from sklearn.model_selection import train_test_split
x_train,x_test,y_train,y_test = train_test_split(Email_data_clear2,Email_target,test_size=0.3,random_state=0,stratify=Email_target)
# 建立数据的特征向量
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer()
X_train = tfidf.fit_transform(x_train)
X_test = tfidf.transform(x_test)
print(type(X_train),type(X_test))
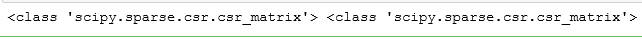
# 观察向量
import numpy as np
X_train = X_train.toarray()
X_test = X_test.toarray()
X_train.shape

# 输出不为0的列
for i in range(X_train.shape[0]):
for j in range(X_train.shape[1]):
if X_train[i][j] != 0:
print(i,j,X_train[i][j])

# 提取特征值
tfidf.get_feature_names()[630:650]

#建立模型
from sklearn.naive_bayes import GaussianNB
gnb = GaussianNB()
module = gnb.fit(X_train,y_train)
y_predict = module.predict(X_test)
# 输出模型分类的各个指标 from sklearn.metrics import classification_report
cr = classification_report(y_predict,y_test)
print(cr)


