

逆向工程 --- 一个helloworld项目的安卓so库开始分析
有些人一直认为汇编淘汰了,没有必要去分析,这里我要说明一下,我们分析汇编不是用汇编去编程而是认识一个函数的底层逻辑有助于我们逆向分析恶意软件的执行流程从而查杀木马。
分析一个开源代码,支持多种cpu方便分析不同cpu架构
https://github.com/jp1017/HelloJni/tree/master
这里分析分为三步走,
第一步分析所有的ida反编译的函数汇编和对应的c源码,用gemini反编译生成的
第二步分析全局的所有处理函数的其他区域含义
第三步分析虚拟地址和实际文件位置之间,汇编和二进制之间的关联
第四步分析不同指令集架构的反编译代码和他们间有什么区别
第五步比较不同反编译工具之间的差异
但是不分析异常处理段,专业性态强,作用不大
开始前我们要直到一个概念elf文件的段和节,
映射关系示意图
+-------------------------+ | ELF 文件 | | | | +---------------------+ | | | 段 (LOAD) | | → 程序头表描述 | | +-----+ +---------+ | | | | |.text| | .rodata | | | ← 多个节合并为一个段 | | +-----+ +---------+ | | | +---------------------+ | | | | +---------------------+ | | | 节头表 | | → 描述所有节(如.text, .data)这里 | +---------------------+ | +-------------------------+
-
节是链接视图(Linking View)的单元,用于构造程序逻辑。
-
段是执行视图(Execution View)的单元,用于内存加载。
-
链接器将节按权限分组,打包成段供操作系统加载。

各个段的详细解释
我们从上到下逐一解释:
有两个load段。这里我的理解是加载器通用段,这两个段权限不同
你看到的 LOAD 行不是段,而是程序头(Program Header) 的一部分,它告诉操作系统加载器:“请把从地址 A 到地址 B 的这些段(比如 .plt, .text, .rodata)一起加载到内存,并设置权限为 R-X”。通常会有一个用于代码(R-X)的 LOAD 和一个用于数据(RW-)的 LOAD。
1. .plt (Procedure Linkage Table - 程序链接表)
-
通俗解释:大楼的总机/前台。当你需要找一个不住在这栋楼里的人(调用外部共享库的函数,比如 printf),你都要先联系总机。
-
作用:专门用来处理对外部共享库函数(如 libc.so 里的 printf、scanf)的调用。它实现了一种叫做“延迟绑定”的优化,即只有在函数第一次被调用时,才去查找它的真实地址。
-
权限 :可读(Read)、可执行(Execute)。因为它是代码,所以必须能执行。
-
对应源码:任何对标准库或其它动态链接库函数的调用。
#include <stdio.h> int main() { printf("Hello, World!"); // 对 printf 的调用会经过 .plt return 0; }
2. .text (Text Segment - 代码段)
-
通俗解释:大楼的核心功能区,比如办公室、会议室。这里是员工(CPU)真正干活的地方。
-
作用:存放程序的主体可执行代码。你编写的所有函数、逻辑(if/else、for/while 循环等)编译后的机器指令都在这里。
-
权限 :可读、可执行。这是最核心的代码,必须能执行,但通常不允许在运行时修改,以防被篡改。
-
对应源码:你自己编写的所有函数。
int add(int a, int b) { // add 函数的机器码在 .text return a + b; } int main() { // main 函数的机器码也在这里 int result = add(5, 3); return 0; }
3. .rodata (Read-Only Data - 只读数据段)
-
通俗解释:大楼里的标语、门牌、不可更改的规章制度。
-
作用:存放程序中只读的常量数据。
-
权限 :只读。操作系统会阻止任何试图修改这块内存的尝试,有助于捕获 bug 和提升安全性。
-
对应源码:字符串字面量、const 修饰的常量等。
const int VERSION = 1; // VERSION 的值 1 存在 .rodata void print_message() { // "Welcome user" 这个字符串本身存在 .rodata printf("Welcome user\n"); }
.eh_frame和.eh_frame_hdr是 ELF(可执行与可链接格式)文件中的关键节区(sections),主要用于异常处理和栈回溯(stack unwinding)。它们遵循 DWARF 调试格式规范,是支持 C++ 异常处理(如try/catch)和生成函数调用栈的核心机制。
4. .init_array & .fini_array (初始化/终止数组)
-
通俗解释:
-
.init_array:大楼的**“开门营业前准备工作”清单**。
-
.fini_array:大楼的**“关门歇业后收尾工作”清单**。
-
-
作用:
-
.init_array 存放一个函数指针列表,这些函数会在 main 函数之前被自动调用。
-
.fini_array 也存放一个函数指针列表,这些函数会在 main 函数之后(或程序退出时)被自动调用。
-
-
权限 :可读、可写(DATA)。它们本身是数据(函数指针数组)。
-
对应源码:在 C++ 中,全局对象的构造函数和析构函数会分别用到它们。在 C 中,可以用特殊属性来指定。
// (GCC/Clang specific) void startup_func() __attribute__((constructor)); // 指针会进 .init_array void cleanup_func() __attribute__((destructor)); // 指针会进 .fini_array void startup_func() { printf("Program starting...\n"); } void cleanup_func() { printf("Program exiting...\n"); }
5. .got.plt (Global Offset Table - 全局偏移表)
-
通俗解释:总机(.plt)旁边放的电话本。
-
作用:与 .plt 紧密配合。这个“电话本”里存放着外部函数的真实内存地址。第一次调用时,总机(.plt)发现电话本里是空的,就去查找真实地址,然后写到这个本子上。以后再调用,直接查本子就行了。
-
权限 :可读、可写。必须是可写的,因为动态链接器需要在运行时把解析到的函数真实地址填进去。
-
对应源码:间接地被所有外部函数调用使用。
6. .data (Data Segment - 数据段)
-
通俗解释:大楼里初始状态就被写上内容的白板。上面的内容可以随时擦写修改。
-
作用:存放程序中已初始化的全局变量和静态变量。这些变量在程序开始时就有一个非零的初始值。
-
权限 :可读、可写。程序需要能随时读写这些变量的值。
-
对应源码:
int global_counter = 100; // global_counter 存放在 .data 段 static bool is_ready = true; // is_ready 也存放在 .data 段 void func() { static int call_count = 1; // call_count 也在这里 call_count++; }
7. .bss (Block Started by Symbol)
-
通俗解释:大楼里预留的一块块空白的场地。施工队(OS 加载器)在开业前会把这些场地打扫干净(清零)。
-
作用:存放未初始化或初始化为 0 的全局变量和静态变量。
-
特殊之处:为了节省可执行文件在磁盘上的空间,.bss 段在文件中只记录“需要多大空间”,而不实际存储那些 0。当程序被加载到内存时,操作系统才会分配这块内存并将其全部填为 0。
-
权限 :可读、可写。
-
对应源码:
char buffer[1024]; // 未初始化的全局数组,在 .bss static int global_status; // 未初始化的静态变量,在 .bss (默认值为0)
表格总结
| 段名 | 通俗比喻 | 存放内容 | 源码对应 |
| .plt | 总机/前台 | 调用外部函数的跳转代码 | printf(), scanf() 等库函数调用 |
| .text | 核心功能区 (办公室) | 程序的机器指令 | main() 和所有你写的函数、循环、判断语句 |
| .rodata | 不可变的标语/规章制度 | 只读常量数据 | "Hello World", const int a = 5; |
| .data | 写有初始内容的白板 | 初始化过的全局/静态变量 | int global = 10; static int x = 1; |
| .bss | 预留的空白场地 | 未初始化或0初始化的全局/静态变量 | char buffer[1024]; static int y; |
| .got.plt | 总机的电话本 | 外部函数的真实地址 | 间接被所有库函数调用使用 |
| .init_array | 开业前准备清单 | main 前调用的函数指针 | C++全局对象构造函数, __attribute__((constructor)) |
| .fini_array | 歇业后收尾清单 | main 后调用的函数指针 | C++全局对象析构函数, __attribute__((destructor)) |
| 名称 | 通俗比喻 (大楼功能区) | 作用 |
| extern | 外部联系人名录 | 列出了程序需要从外部(其他动态库)导入的符号(函数或变量)。IDA 将它们集中显示在这个伪段中。 |
| abs | 绝对地址标记 | 存放具有绝对地址的符号,这些符号不属于任何一个常规段。通常用于调试信息或特殊用途的符号。 |
我们发现ida没有展示节的定义,稍后分析
第一步分析所有的ida反编译的函数汇编和对应的c源码,用gemini反编译生成的
.text:000003F0 ; ===========================================================================
.text:000003F0
.text:000003F0 ; Segment type: Pure code
.text:000003F0 ; Segment permissions: Read/Execute
.text:000003F0 _text segment para public 'CODE' use32
.text:000003F0 assume cs:_text
.text:000003F0 ;org 3F0h
.text:000003F0 assume es:nothing, ss:nothing, ds:_data, fs:nothing, gs:nothing
.text:000003F0
.text:000003F0 ; =============== S U B R O U T I N E =======================================
.text:000003F0
.text:000003F0
.text:000003F0 sub_3F0 proc near ; DATA XREF: .fini_array:off_1EB4↓o
.text:000003F0
.text:000003F0 var_1C = dword ptr -1Ch
.text:000003F0
.text:000003F0 ; __unwind {
.text:000003F0 push ebx
.text:000003F1 call sub_4A0
.text:000003F6 add ebx, (offset off_1FE8 - $)
.text:000003FC lea esp, [esp-18h]
.text:00000400 lea eax, (off_2000 - 1FE8h)[ebx]
.text:00000406 mov [esp+1Ch+var_1C], eax ; void *
.text:00000409 call ___cxa_finalize
.text:0000040E lea esp, [esp+18h]
.text:00000412 pop ebx
.text:00000413 retn
.text:00000413 ; } // starts at 3F0
.text:00000413 sub_3F0 endp
.text:00000413
.text:00000413 ; ---------------------------------------------------------------------------
.text:00000414 align 10h
// 由链接器/加载器提供的特殊句柄,用于唯一标识当前的动态共享对象(DSO),也就是这个.so文件。
// 在汇编中,它的地址是通过 lea eax, (off_2000 - 1FE8h)[ebx] 计算得到的。
extern "C" void* __dso_handle;
// 声明 C++ ABI 标准库中的一个外部函数。
// 这个函数负责执行所有通过 __cxa_atexit 注册的析构函数/清理函数。
extern "C" void __cxa_finalize(void* dso);
/**
* @brief 库的终结函数 (Library Finalizer)。
*
* 这个函数的地址被放在 .fini_array 中,当库被卸载时由系统调用。
* 它的唯一工作就是调用 __cxa_finalize,以确保所有全局/静态C++对象的
* 析构函数都能被正确执行。
*/
void sub_3F0()
{
// 调用 C++ 运行时清理函数,并传入当前库的句柄。
__cxa_finalize(__dso_handle);
}
.text:00000420 sub_420 proc near ; DATA XREF: sub_440+22↓o
.text:00000420
.text:00000420 arg_0 = dword ptr 4
.text:00000420
.text:00000420 ; __unwind {
.text:00000420 lea esp, [esp-0Ch]
; 1. 函数开始,在栈上分配 12 字节(0xC)的空间。
; 这可能是为了栈对齐或为之后的函数调用预留空间,尽管在这里没有被直接使用。
.text:00000424 mov eax, [esp+0Ch+arg_0]
; 2. 获取传递给本函数的第一个参数。
; - `arg_0` 是 4,所以它访问 [esp + 0xC + 4] = [esp + 0x10]。
; - 由于函数开始时 esp 减了 0xC,所以 [esp + 0x10] 正好是调用本函数之前栈顶往下第4个字节,
; 即第一个参数的位置。
; - 这个参数被加载到 eax 寄存器。
.text:00000428 test eax, eax
; 3. 检查 eax 的值是否为 0。
; `test reg, reg` 是一个高效的检查寄存器是否为0的方法。
; 如果 eax 是 0,CPU的零标志位(ZF)会被设置为1。
.text:0000042A jz short loc_42E
; 4. "Jump if Zero"。如果上一步的 test 指令结果为0(即 eax 是 NULL),
; 就直接跳转到函数末尾的 loc_42E,跳过函数调用。
.text:0000042C call eax
; 5. 如果 eax 不为0,就执行这条指令。
; `call eax` 将 eax 寄存器中的值当作一个地址,并跳转到该地址执行代码。
; 这本质上是一次间接的函数调用。
.text:0000042E
.text:0000042E loc_42E: ; CODE XREF: sub_420+A↑j
.text:0000042E lea esp, [esp+0Ch]
; 6. 函数清理。将栈指针恢复到调用本函数之前的状态,释放之前分配的12字节。
.text:00000432 retn
; 7. 函数返回。
.text:00000432 ; } // starts at 420
.text:00000432 sub_420 endp
// 这是一个回调函数,当它被注册到 atexit 后,在程序退出时被调用。
// 它接收一个参数(通常是'this'指针),如果该参数不为NULL,则将其作为函数指针调用。
// 对应于: sub_420
void exit_callback(void* func_ptr) {
if (func_ptr) {
// 将 func_ptr 转换为一个无参函数指针并调用
((void (*)())func_ptr)();
}
}
.text:00000440 ; =============== S U B R O U T I N E =======================================
.text:00000440
.text:00000440
.text:00000440 ; int __cdecl sub_440(void *)
.text:00000440 sub_440 proc near
.text:00000440
.text:00000440 lpfunc = dword ptr -1Ch
.text:00000440 obj = dword ptr -18h
.text:00000440 lpdso_handle = dword ptr -14h
.text:00000440 arg_0 = dword ptr 4
.text:00000440
.text:00000440 ; __unwind {
.text:00000440 push ebx
.text:00000441 call sub_4A0
.text:00000446 add ebx, (offset off_1FE8 - $)
.text:0000044C lea esp, [esp-18h]
.text:00000450 lea eax, (off_2000 - 1FE8h)[ebx]
.text:00000456 mov [esp+1Ch+lpdso_handle], eax ; lpdso_handle
.text:0000045A mov eax, [esp+1Ch+arg_0]
.text:0000045E mov [esp+1Ch+obj], eax ; obj
.text:00000462 lea eax, (sub_420 - 1FE8h)[ebx]
.text:00000468 mov [esp+1Ch+lpfunc], eax ; lpfunc
.text:0000046B call ___cxa_atexit
.text:00000470 lea esp, [esp+18h]
.text:00000474 pop ebx
.text:00000475 retn
.text:00000475 ; } // starts at 440
.text:00000475 sub_440 endp
.text:00000475
这段汇编代码定义了一个函数(sub_440),其核心作用是使用 __cxa_atexit 注册一个全局/静态对象的析构函数。以下是逐行解析和功能说明:
函数原型(逆向还原)
c
// 注册全局对象析构函数
void register_destructor(void* obj) {
__cxa_atexit(
destructor_function, // 析构函数指针 (sub_420)
obj, // 要析构的对象指针 (参数 arg_0)
dso_handle // DSO 句柄 (off_2000)
);
}
关键操作解析
初始化位置无关代码(PIC)
assembly
push ebx
call sub_4A0 ; 获取当前指令地址
add ebx, (offset off_1FE8 - $) ; 设置 EBX = GOT 基址
用于支持动态库加载(Position Independent Code)
ebx 最终指向全局偏移表(GOT)的基地址
准备 __cxa_atexit 参数
assembly
lea eax, (off_2000 - 1FE8h)[ebx] ; dso_handle = &off_2000
mov [esp+1Ch+lpdso_handle], eax ; 参数3: DSO 句柄
mov eax, [esp+1Ch+arg_0] ; 获取输入参数 obj
mov [esp+1Ch+obj], eax ; 参数2: 对象指针
lea eax, (sub_420 - 1FE8h)[ebx] ; destructor = sub_420
mov [esp+1Ch+lpfunc], eax ; 参数1: 析构函数指针
三个参数按从右到左压栈:
dso_handle:动态库标识(通常为 __dso_handle)
obj:要析构的对象指针(函数参数 arg_0)
destructor_function:析构函数(此处为 sub_420)
调用注册函数
call ___cxa_atexit ; 注册析构函数
清理栈并返回
lea esp, [esp+18h] ; 释放栈空间
pop ebx ; 恢复寄存器
retn ; 返回
核心作用
此函数完成以下关键操作:
动态计算地址
通过 PIC 技术计算出:
析构函数 sub_420 的实际地址
DSO 句柄 off_2000 的实际地址
destructor_addr = ebx + (sub_420 - 0x1FE8)
dso_handle_addr = ebx + (off_2000 - 0x1FE8)
注册析构流程
调用 __cxa_atexit 注册三元组:
(sub_420, obj, off_2000)
当程序退出时,系统会自动调用:
sub_420(obj); // 执行对象的析构
典型应用场景
在 C++ 全局/静态对象构造完成后,编译器自动生成此类代码:
// 假设有全局对象
MyClass global_obj;
// 编译器隐式插入的伪代码
void _GLOBAL__I() {
// 1. 构造对象
global_obj.MyClass();
// 2. 注册析构 (即此汇编函数)
register_destructor(&global_obj);
}
栈帧布局图解
text
高地址
|------------|
| 返回地址 | <- 函数调用时压入
|------------|
| 保存的 EBX | <- push ebx
|------------|
| 局部变量区 | <- lea esp, [esp-18h]
| - lpfunc | [esp+0] ; 析构函数指针
| - obj | [esp+4] ; 对象指针
| - dso | [esp+8] ; DSO 句柄
|------------| <- 当前 ESP
低地址
.text:00000480 ; =============== S U B R O U T I N E =======================================
.text:00000480
.text:00000480 ; Attributes: noreturn
.text:00000480
.text:00000480 sub_480 proc near ; CODE XREF: JNI_OnLoad:loc_5AF↓p
.text:00000480 ; __unwind {
.text:00000480 push ebx
.text:00000481 call sub_4A0
.text:00000486 add ebx, (offset off_1FE8 - $)
.text:0000048C lea esp, [esp-8]
.text:00000490 call ___stack_chk_fail
.text:00000490 sub_480 endp
.text:00000490
.text:00000495 ; ---------------------------------------------------------------------------
.text:00000495 lea esp, [esp+8]
.text:00000499 pop ebx
.text:0000049A retn
.text:0000049A ; } // starts at 480
.text:0000049A ; ---------------------------------------------------------------------------
.text:0000049B align 10h
.text:00000480 ; Attributes: noreturn
; 1. IDA 注释:noreturn。这是一个非常重要的属性,意味着这个函数一旦被调用,就永远不会返回到调用它的地方。
.text:00000480 sub_480 proc near ; CODE XREF: JNI_OnLoad:loc_5AF↓p
; 2. IDA 注释:被 JNI_OnLoad 函数调用。这说明 JNI_OnLoad 函数启用了栈保护。
.text:00000480 ; __unwind {
.text:00000480 push ebx
.text:00000481 call sub_4A0
.text:00000486 add ebx, (offset off_1FE8 - $)
; 3. 标准的位置无关代码 (PIC) 设置。
; 虽然这个函数会立即终止程序,但编译器仍然按照标准流程生成了PIC代码,
; 以确保对 `___stack_chk_fail` 的调用是位置无关的。
.text:0000048C lea esp, [esp-8]
; 4. 在栈上分配8字节空间。这可能是为了满足调用约定或栈对齐要求。
.text:00000490 call ___stack_chk_fail
; 5. **核心调用**。调用 `___stack_chk_fail` 函数。
; 这个函数是libc或编译器运行时库的一部分。它的工作是:
; - 打印一条错误消息到 stderr,例如 "*** stack smashing detected ***: terminated"。
; - 调用 abort() 来立即终止整个程序。
.text:00000490 sub_480 endp
; 函数在这里结束。注意,没有 `pop ebx` 或 `retn`,因为 `___stack_chk_fail` 不会返回。
// 声明外部的、由标准库提供的栈检查失败处理函数。
// 这个函数被标记为 __attribute__((noreturn)),告诉编译器它不会返回。
extern void __stack_chk_fail(void) __attribute__((noreturn));
/**
* @brief 栈检查失败的本地处理函数。
*
* 这是一个由编译器生成的包装器,用于在检测到栈缓冲区溢出时,
* 调用标准的 ___stack_chk_fail 函数来终止程序。
*
* 此函数永远不会返回。
*/
void sub_480(void) __attribute__((noreturn))
{
// 直接调用标准库函数来处理错误并终止程序。
__stack_chk_fail();
}
.text:000004A0 ; =============== S U B R O U T I N E =======================================
.text:000004A0
.text:000004A0
.text:000004A0 sub_4A0 proc near ; CODE XREF: sub_3F0+1↑p
.text:000004A0 ; sub_440+1↑p ...
.text:000004A0 ; __unwind {
.text:000004A0 mov ebx, [esp+0]
.text:000004A3 retn
.text:000004A3 ; } // starts at 4A0
.text:000004A3 sub_4A0 endp
.text:000004A3
.text:000004A3 ; ---------------------------------------------------------------------------
.text:000004A4 align 10h
.text:000004B0
这段汇编代码的功能非常特殊,直接用 C 语言来表达其作用有点困难,因为它利用了 call 指令的底层机制。如果非要写成 C,它看起来会像一个“获取并返回调用者下一条指令地址”的黑魔法函数,但实际上它在 C 层面没有直接的对应物。我们就能在任何内存中读取出绝对地址
// 函数名: sub_4A0
// 功能: PIC(位置无关代码)辅助函数,用于获取当前指令指针到 ebx 寄存器。
// 在C代码中不可见,由编译器自动生成。
void sub_4A0() {
// __asm__ ("mov ebx, [esp]; ret");
}
PLT GOT段分析
我们简单分析后发现
在txt中call调转到plt段-》pltgot段-》extern段,注意extern段实际并不存在只是ida方便内存映射显示的位置,pltgot段虽然地址指向extern但是实际指向plt的调用函数的下一条指令
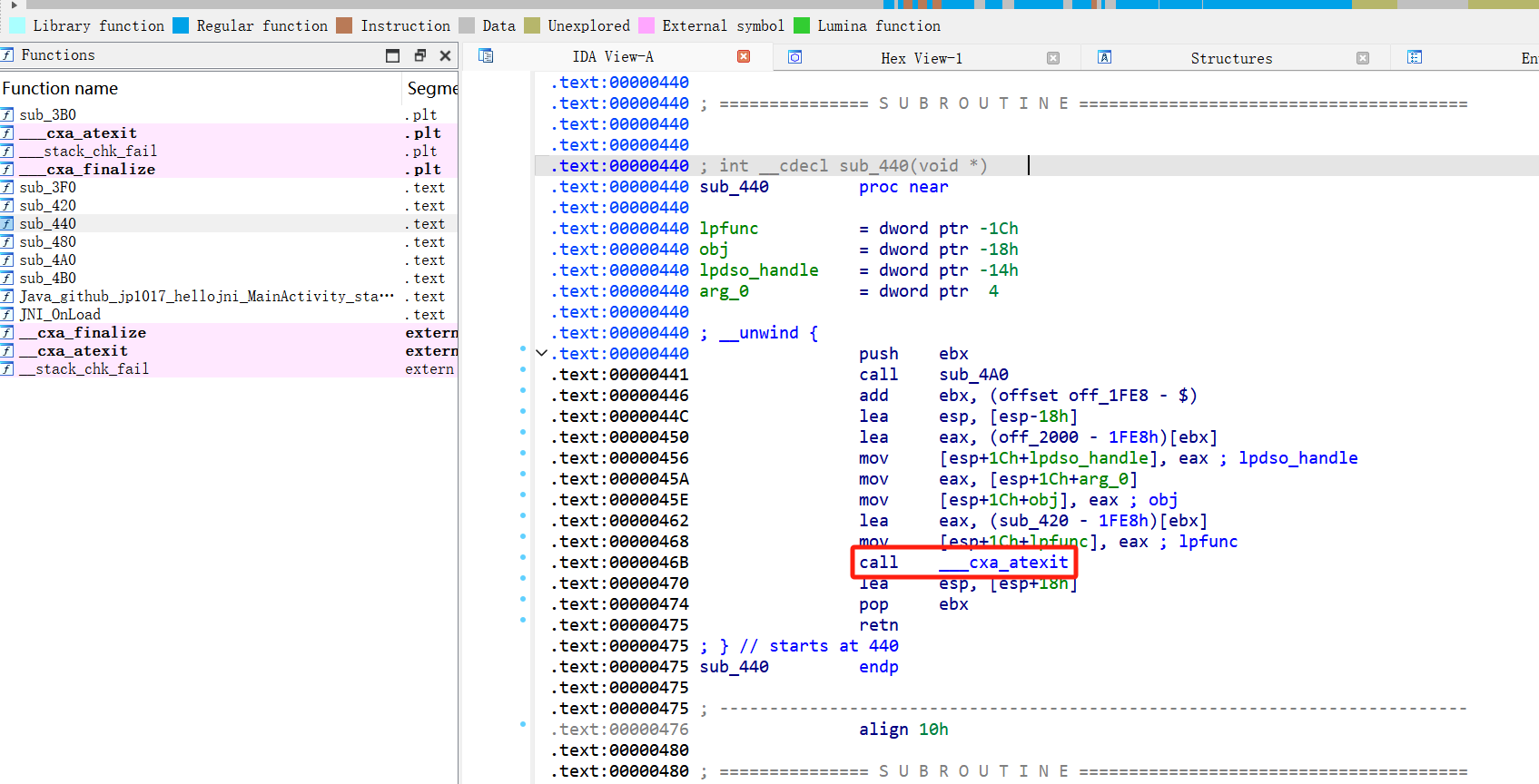
sub_440 中对 ___cxa_atexit 的调用为起点,一步步追踪并分析 .plt、.got.plt 和 extern 段之间的关系。
核心问题:为什么这么复杂?
当 sub_440 调用 ___cxa_atexit 时,这个函数并不在 libhello_jni.so 内部,而是在一个外部的系统库中(比如 libc.so 或 libstdc++.so)。编译器在编译 libhello_jni.so 时,并不知道 ___cxa_atexit 将来会被加载到内存的哪个确切地址。
因此,不能直接 call <一个固定的地址>。动态链接机制通过引入 PLT(过程链接表) 和 GOT(全局偏移表) 这两个中间层来解决这个问题。
故事的主角们
在我们的追踪旅程中,有以下几个关键角色:
-
调用者 (: 我们故事的起点。
-
PLT 桩函数 (: 一个小小的代码“跳板”。
-
GOT 条目 (: 一本可以被修改的“地址簿”,记录着 ___cxa_atexit 的地址。
-
PLT 解析器 (: PLT内部的通用“接线员”,负责求助动态链接器。
-
动态链接器 (: 操作系统的一部分,是真正的“百事通”,知道所有函数的真实地址。
-
段: 仅仅是 IDA 在反汇编时用来标记某个符号是外部的,它本身在最终的可执行文件中没有实体作用,更像是一个注释。
追踪开始:从 call 指令出发
我们将模拟程序第一次和第二次调用 ___cxa_atexit 的全过程。
场景一:应用程序的第一次 call ___cxa_atexit (慢速路径)
-
起点:
Generated assembly.text:0000046B call ___cxa_atexit这条 call 指令的目标并不是 ___cxa_atexit 的真实地址,而是它的 PLT 桩函数地址。所以,这条指令实际上是 call .plt:000003C0。
-
第1站:
Generated assembly
程序流程跳转到地址 0x3C0:.plt:000003C0 ___cxa_atexit proc near .plt:000003C0 jmp ds:__cxa_atexit_ptr ; 实际是 jmp dword ptr [0x1FF4]这个桩函数非常简单,只有一个 jmp 指令。它要去 0x1FF4 这个地址取出一个值,然后跳转到那个值所代表的地址。0x1FF4 正是 ___cxa_atexit 在 GOT 中的条目。
-
第2站:
Generated assembly
我们来看 0x1FF4 在程序刚加载时的初始状态。.got.plt:00001FF4 __cxa_atexit_ptr dd offset __cxa_atexitIDA 的 offset __cxa_atexit 在这里可能会产生误导。在延迟绑定(Lazy Binding)。
Generated assembly
我们看 .plt 段中 jmp 后面的指令是什么:.plt:000003C6 push 0所以,0x1FF4 处此刻存放的值是 0x000003C6。因此 jmp dword ptr [0x1FF4] 的结果就是跳转到 0x3C6。
-
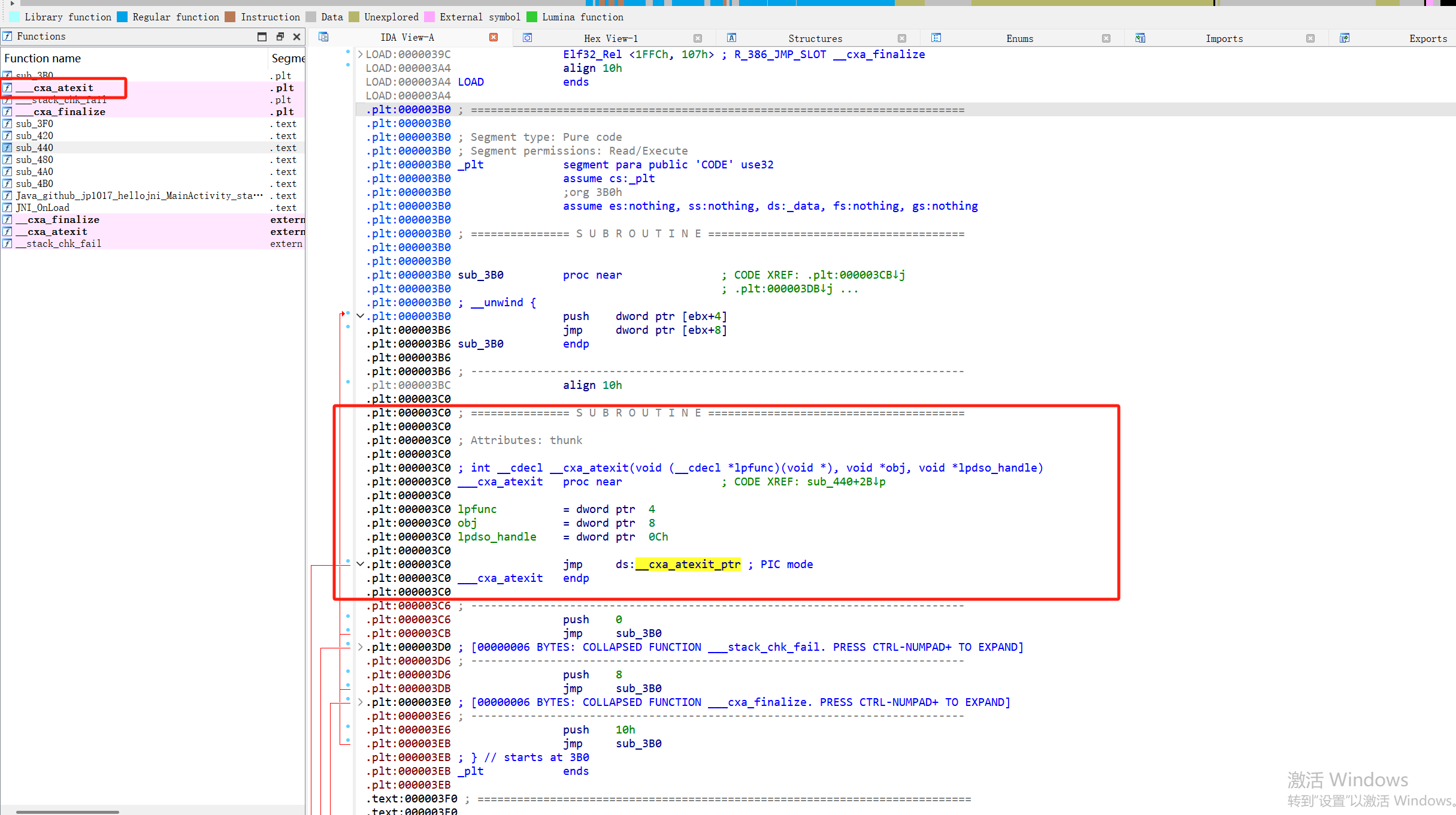
第3站: .plt 段的解析逻辑
Generated assembly
程序流程到达了 0x3C6:.plt:000003C6 push 0 ; 压入一个立即数 0。这是该函数在重定位表中的索引/ID。 .plt:000003CB jmp sub_3B0 ; 跳转到 PLT 的通用解析器。push 0 是为了告诉接下来的解析器:“我需要你帮我解析第0个函数”。然后它跳转到通用的“接线员” sub_3B0。
-
第4站: PLT 通用解析器 (sub_3B0)
Generated assembly.plt:000003B0 sub_3B0 proc near .plt:000003B0 push dword ptr [ebx+4] ; 压入一个指向动态链接信息的指针 (库的唯一标识) .plt:000003B6 jmp dword ptr [ebx+8] ; 跳转到动态链接器的核心函数(通常是 _dl_runtime_resolve)sub_3B0 的任务是准备好调用动态链接器所需的所有信息,然后把控制权完全交给它。
-
最终站: 动态链接器的工作和 GOT 的回填
-
动态链接器(ld.so)现在被激活了。它从栈上拿到函数ID(0)和库的标识。
-
它查看 .rel.plt (在你的文件中是 JMPREL at LOAD:0000038C) 重定位表,找到与ID 0 对应的条目,知道要查找的符号是 __cxa_atexit。
-
它在所有已加载的库中搜索,最终在 libc.so 或 libstdc++.so 中找到了 __cxa_atexit 的真实内存地址。
-
【最关键的一步】 链接器将这个真实地址写回到 .got.plt 的 0x1FF4 位置,覆盖掉原来的 0x000003C6。
-
链接器直接跳转到 __cxa_atexit 的真实地址,完成本次调用。
-
场景二:第二次 call ___cxa_atexit (快速路径)
-
起点: sub_440 再次 call ___cxa_atexit
和之前一样,跳转到 PLT 桩函数 0x3C0。 -
第1站: .plt 段的桩函数
Generated assembly -
第2站: .got.plt 段 (状态已改变!)
这一次,当 CPU 去 0x1FF4 地址取值时,它取到的不再是 0x3C6,而是由动态链接器在上一步回填的、__cxa_atexit 的真实地址! -
直达目的地
jmp 指令直接将程序流程跳转到了外部库中 ___cxa_atexit 的真实代码处。整个第3、4、5、6步的慢速路径被完全跳过。
总结关系
-
.text -> .plt: 任何对外部函数的调用,第一跳都是从主代码跳到PLT中的对应桩函数。
-
.plt -> .got.plt: PLT桩函数通过 jmp [address] 指令,无条件地信任并使用GOT表中的地址。
-
.got.plt -> 动态链接器 (第一次): GOT表的初始值指向PLT的解析逻辑,从而触发动态链接器。
-
动态链接器 -> .got.plt: 动态链接器找到真实地址后,会修改GOT表的内容,完成“回填”。
-
.got.plt -> 真实函数 (后续调用): 一旦GOT表被回填,它就直接指向了最终的目标函数地址。
-
extern: 只是一个给反汇编器看的“路牌”,告诉我们“这个符号在别处定义”,它帮助IDA理解交叉引用,但在运行时机制中不扮演主动角色。
这个精妙的 PLT/GOT 机制,通过一个可写的 .got.plt 数据段和一个只读的 .plt 代码段的配合,实现了高效、安全的延迟绑定,是现代动态链接的核心。
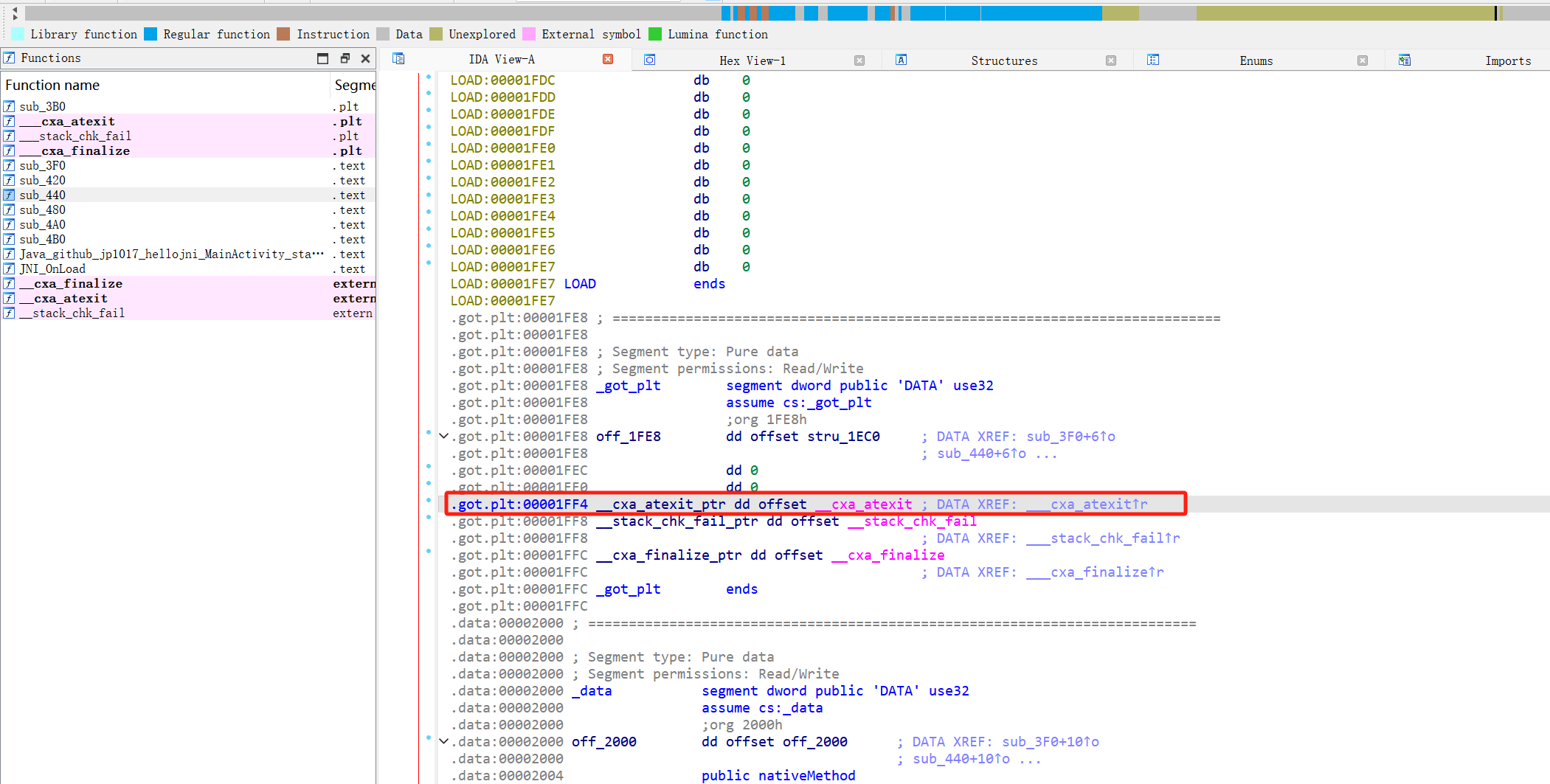
简短回答:
你看到的 18 20 00 00 (即小端序地址 0x00002018) 是静态链接器(在创建 .so 文件时)放置的一个临时占位符。这个占位符的真正意义在于,它与一条重定位记录(Relocation Record)(在加载 .so 文件时):“请在运行时,将这个位置的值修改为 __cxa_atexit 的真实地址”。
详细分步解析
我们来追踪一下地址 0x1FF4 处的值在不同阶段的“生命周期”。
阶段 1:在 .so 文件中(静态链接后,你现在看到的样子)
当你用IDA打开 libhello_jni.so 文件时,你看到的是静态链接器 (ld) 生成的结果。
-
静态链接器的困境:链接器在构建 libhello_jni.so 时,它知道代码需要调用 __cxa_atexit,但它不知道这个函数在未来的运行环境中会位于何处。它无法将最终地址写入文件。
-
静态链接器的解决方案:
-
它在 .got.plt 的 0x1FF4 位置放一个占位符。在这里,它选择的值是 0x00002018。为什么是这个值?因为在IDA的视图中,它将所有外部符号(extrn)放在了从 0x2014 开始的区域,而 __cxa_atexit 正好被分配在 0x2018:
生成的程序集extern:00002018 ; int __cdecl _cxa_atexit(...) extern:00002018 extrn __cxa_atexit:near所以IDA很智能地将 dd 0x2018 显示为 dd offset __cxa_atexit。
-
最关键的一步:它在文件的重定位表中创建一条记录。让我们在你的文件中找到这条记录:
生成的程序集LOAD:0000038C ; ELF JMPREL Relocation Table LOAD:0000038C Elf32_Rel <1FF4h, 207h> ; R_386_JMP_SLOT __cxa_atexit谨慎使用代码 with caution.组装这条记录 Elf32_Rel <1FF4h, 207h> 的意思是:
-
Offset (1FF4h): 请关注文件内偏移量为 0x1FF4 的位置。
-
信息 (207h):
-
高24位 (0x02) 是符号表索引,指向 __cxa_atexit 这个符号。
-
低8位 (0x07) 是重定位类型 R_386_JMP_SLOT。
-
-
-
这条记录就像一张便签贴,上面写着:“嘿,动态链接器!当你加载我的时候,请处理 0x1FF4 这个地址。你需要找到 __cxa_atexit 的真实地址,并根据 R_386_JMP_SLOT 规则来更新这个位置。”
阶段 2:程序被加载到内存时(动态链接器接管)
当你的安卓应用启动并加载 libhello_jni.so 时,系统的动态链接器 (/system/bin/linker 或 ld.so) 开始工作。
-
读取重定位表:动态链接器会扫描 .rel.plt (JMPREL) 段,看到了我们上面提到的那条记录。
-
执行延迟绑定 (Lazy Binding) 初始化:对于 R_386_JMP_SLOT 这种类型,动态链接器会执行“延迟绑定”的初始化。它并不会立即去查找 __cxa_atexit 的真实地址。相反,它会做以下事情:
-
它将地址 0x1FF4 处的值从占位符 0x00002018 修改为 PLT 解析逻辑的入口地址。
-
这个入口地址就是 PLT 桩函数中 jmp 指令的下一条指令的地址,在你的文件中是 0x03C6 (即 push 0 指令的地址)。
-
所以,在第一次调用前,0x1FF4 的值变成了 0x000003C6。
-
阶段 3:第一次调用 __cxa_atexit 时
-
代码执行 call .plt:___cxa_atexit。
-
PLT 桩函数执行 jmp dword ptr [0x1FF4]。
-
由于 0x1FF4 的值是 0x03C6,程序跳转到 push 0; jmp sub_3B0,最终调用动态链接器来解析地址。
-
动态链接器找到 __cxa_atexit 的真实地址(例如,内存中的 0xB7ABCDEF)。
-
最终的回填:动态链接器将这个真实地址 0xB7ABCDEF 再次写入到 0x1FF4 位置,覆盖掉 0x03C6。
阶段 4:后续调用 __cxa_atexit 时
-
代码再次执行 call .plt:___cxa_atexit。
-
PLT 桩函数执行 jmp dword ptr [0x1FF4]。
-
这次,0x1FF4 的值已经是 0xB7ABCDEF,所以程序直接跳转到函数的真实地址,实现了快速调用。
总结
18 20 00 00 (即 0x00002018) 仅仅是文件在磁盘上时的初始占位符。这个值本身在运行时没有直接意义,它的存在是为了配合重定位表,引导动态链接器在程序加载和首次调用时,完成一系列的地址修改和解析操作,最终将 GOT 表中的这个条目指向函数在内存中的真实地址。
E8 D2 FF FF FF 为什么表示.text:00000409 call ___cxa_finalize
E8 D2 FF FF FF 这5个字节之所以表示 .text:00000409 call ___cxa_finalize,是因为它遵循了 x86 架构中 “相对近调用”(Near Relative Call) 的指令编码规则。
我们来一步步分解这5个字节:
第1步:识别操作码 (Opcode)
-
E8: 这是 x86 指令集里 CALL rel32 指令的操作码。
-
CALL: 告诉CPU这是一个函数调用。
-
rel32: 表示这个调用后面跟着一个 32位的相对偏移量(relative offset)。这个偏移量是有符号的,意味着可以向前跳转(负数),也可以向后跳转(正数)。
-
第2步:解码操作数 (Operand)
-
D2 FF FF FF: 这就是那个32位的相对偏移量。
-
小端序 (Little-Endian): 在 x86 架构中,多字节数据是以“小端序”存储的,即低位字节在前,高位字节在后。所以我们需要把它反过来读,才能得到真正的数值:0xFFFFFFD2。
-
二进制补码 (Two's Complement): 0xFFFFFFD2 是一个32位的有符号整数。由于它的最高位是1(F的二进制是1111),所以它表示一个负数。
要计算它的十进制值,我们可以用标准的方法:-
所有位取反: 0xFFFFFFD2 -> 0x0000002D
-
结果加 1: 0x0000002D + 1 = 0x0000002E
-
所以,0xFFFFFFD2 代表的数值是 -0x2E (十六进制) 或 -46 (十进制)。
-
-
第3步:计算目标地址
这是最关键的一步。相对调用的偏移量是相对于 。
-
call 指令的地址:
生成的程序集.text:00000409 call ___cxa_finalize这条指令本身位于地址 0x00000409。
-
call 指令的长度:
这条指令由 E8 (1字节) 和 D2 FF FF FF (4字节) 组成,总长度为 5字节。 -
下一条指令的地址:
因此,下一条指令的地址是 0x00000409 + 5 = 0x0000040E。
CPU 的call指令的取指后,会指向这个地址。 -
最终计算:
目标地址 = 下一条指令的地址 + 相对偏移量
目标地址 = 0x40E + (-0x2E)
目标地址 = 0x40E - 0x2E
目标地址 = 0x03E0
第4步:验证结果
现在,我们去你的反汇编代码里查找地址 0x03E0 是什么:
生成的程序集
.plt:000003E0 ; =============== S U B R O U T I N E =======================================
.plt:000003E0 ; ...
.plt:000003E0 ; int __cdecl __cxa_finalize(void *)
.plt:000003E0 ___cxa_finalize proc near ; CODE XREF: sub_3F0+19↓p完全正确!地址 0x03E0 正是 ___cxa_finalize 这个PLT桩函数的入口地址。
总结:为什么用相对地址?
这种编码方式的核心优势在于位置无关代码 (Position-Independent Code, PIC)。
-
call 指令 (0x409) 和它的目标 ___cxa_finalize (0x3E0) 之间的距离 (-0x2E字节) 是一个固定不变的常量。
-
当这个 .so 动态库被加载到内存中时,操作系统可能会给它分配一个任意的基地址,比如 0xA0000000。
-
那么,call 指令的实际地址就变成了 0xA0000409,___cxa_finalize 的实际地址就变成了 0xA00003E0。
-
我们再用相对寻址的方式计算一次: (0xA0000409 + 5) + (-0x2E) = 0xA000040E - 0x2E = 0xA00003E0。
-
结果依然正确!
因为偏移量是相对的,所以无论整个代码块被移动到内存的哪个位置,这个 call 指令永远都能正确地跳转到目标,而代码本身不需要被修改。这就是动态库能够在不同进程中共享和运行的基础。
.plt:000003B0 sub_3B0 proc near ; 定义一个名为 sub_3B0 的子程序,这是 PLT[0]
.plt:000003B0 push dword ptr [ebx+4] ; 压入一个参数给动态链接器。
; ebx 指向 GOT。
; [ebx+4] 存放的是一个识别模块的 ID (link_map)。
; 作用:告诉动态链接器是谁在请求解析。
.plt:000003B6 jmp dword ptr [ebx+8] ; 无条件跳转到动态链接器的解析函数。
; [ebx+8] 存放着解析函数的地址。
; 作用:启动地址解析过程。
.plt:000003B6 sub_3B0 endp ; 子程序结束
; ...
.plt:000003BC align 10h ; 内存对齐指令。
; 作用:确保接下来的代码或数据从一个 16 (0x10) 字节的倍数的地址开始。
; 目的:这是一种性能优化,CPU 读取对齐的内存地址会更快。
好的,我们来详细解释一下这段汇编代码的作用。
这串代码是一个非常典型的 PLT (Procedure Linkage Table) 入口,它的核心作用是实现 Linux/Unix 系统下动态链接中的延迟绑定 (Lazy Binding)。
简单来说,当你的程序第一次调用一个外部共享库(比如 libc.so)里的函数(比如 printf)时,这个 PLT 条目就会被执行,它的任务是找到 printf 的真实地址,然后“记住”它,下次再调用时就可以直接跳转了。
整体功能:动态链接的“电话总机”
想象一下,你的程序在编译时并不知道 printf 函数究竟在内存的哪个位置。PLT 和 GOT (Global Offset Table) 就像一个电话总机系统:
-
第一次打电话 (调用函数):你拨打 printf 的分机号(调用 PLT 条目)。总机(PLT 代码)发现没有记录 printf 的直线电话(真实地址),于是它去查询电话本(动态链接器),找到直线电话后,记录下来,并帮你接通。
-
以后再打电话:你再次拨打 printf 的分机号,总机直接查看记录,并立即帮你转接到直线电话,不再需要查电话本了。
这个过程就是“延迟绑定”,它能加快程序的启动速度,因为只有在函数被实际调用时,系统才去查找它的地址。
分步代码详解
你的代码片段 sub_3B0 通常是 PLT 表中的第一个条目,被称为 PLT[0]。它是一个公共的、为所有未解析函数服务的解析器入口。
sub_3B0 proc near
-
sub_3B0: 这是反汇编工具(如 IDA Pro)为这个地址 0x3B0 处的子程序自动命名的。
-
proc near: 声明这是一个“近过程”,意味着调用和返回都在同一个代码段内。
1. push dword ptr [ebx+4]
-
关键点: 在 Position-Independent Code (PIC) 中,ebx 寄存器通常被约定用来指向 GOT (Global Offset Table) 的基地址。
-
[ebx+4]: 这是 GOT 表的第二个条目(GOT[1])。它里面存放的是一个指向本模块信息(link map)的指针,这个信息对于动态链接器解析函数地址至关重要。
-
push ...: 将这个“模块标识符”压入栈中。这等于是在告诉接下来要调用的解析函数:“嘿,是这个模块需要你帮忙找一个函数地址。”
2. jmp dword ptr [ebx+8]
-
[ebx+8]: 这是 GOT 表的第三个条目(GOT[2])。在程序加载时,动态链接器会把它自己的一个核心函数的地址填到这里。这个函数通常叫做 _dl_runtime_resolve。
-
jmp ...: 无条件跳转到 _dl_runtime_resolve 函数。
完整的调用流程 (第一次调用)
假设你的程序要调用 printf,实际流程是这样的:
-
call printf@plt: 你的代码实际上是调用 printf 在 PLT 中的一个特定条目,而不是直接调用 sub_3B0。
-
条目: 这个条目通常包含两条指令:
-
jmp dword ptr [GOT_entry_for_printf]: 跳转到 printf 对应的 GOT 条目里存储的地址。在第一次调用时,这个地址指向下一条指令。
-
push <offset>: 将一个唯一的偏移量(printf 的重定位偏移)压入栈。这个偏移量告诉解析器具体要找的是哪个函数。
-
jmp sub_3B0: 跳转到你提供的这段公共解析代码。
-
-
执行 :
-
push dword ptr [ebx+4]: 压入模块标识符。
-
jmp dword ptr [ebx+8]: 跳转到动态链接器的 _dl_runtime_resolve 函数。
-
-
动态链接器工作:
-
_dl_runtime_resolve 函数从栈上拿到模块标识符和函数偏移量。
-
它根据这些信息查找 printf 的真实内存地址。
-
最关键的一步:它用 printf 的真实地址覆盖 GOT_entry_for_printf 原来的内容。
-
最后,它直接跳转到 printf 的真实地址去执行。
-
后续调用流程
第二次调用 printf 时:
-
call printf@plt: 再次调用 printf 在 PLT 中的条目。
-
jmp dword ptr [GOT_entry_for_printf]: 这一次,printf 对应的 GOT 条目里已经是它真实的地址了。所以这条 jmp 指令会直接跳转到 ,完全绕过了后面所有的解析步骤。
align 10h 的作用
-
align 10h: 这是一个汇编器伪指令,而不是一条 CPU 指令。
-
10h 是十六进制的 16。
-
作用: 它告诉汇编器/链接器,确保下一条指令或数据的起始地址是 16 字节对齐的。也就是说,地址的最后一位十六进制数必须是 0(例如 0x...0, 0x...10, 0x...20)。
为什么需要对齐?
为了性能。CPU 从内存中读取数据和指令不是一个字节一个字节地读,而是以一个“块”(称为缓存行,Cache Line,通常是 32 或 64 字节)为单位。如果一条指令或一个数据结构被对齐到合适的边界(如 16 字节),可以保证它不会跨越两个缓存行。如果跨越了,CPU 可能需要两次内存访问才能获取完整内容,从而降低了执行效率。代码对齐是一种常见的性能优化手段。
总结
| 代码/指令 | 作用 | 目的 |
| sub_3B0 (PLT[0]) | PLT 的公共解析存根 | 作为所有未解析函数的统一跳转目标,调用解析器 |
| push [ebx+4] | 将模块标识符(GOT[1])压入栈 | 为动态链接器提供解析所需的上下文信息 |
| jmp [ebx+8] | 跳转到动态链接器的解析函数(_dl_runtime_resolve,地址在 GOT[2]) | 启动真正的函数地址查找过程 |
| align 10h | 将后续代码的地址按 16 字节对齐 | 提升 CPU 读取指令的效率,是一种性能优化 |
这个“模块标识符”在技术上是一个指向 struct link_map 数据结构的指针。可以把它想象成是加载到内存中的每个模块(可执行文件或共享库)的“身份证”或“档案”。
模块标识符 (link_map) 里面有什么?
一个简化的 link_map 结构包含以下关键信息:
-
l_name: 模块的文件名路径(例如 "/lib/x86_64-linux-gnu/libc.so.6")。
-
l_addr: 模块在内存中的加载基地址。操作系统加载 .so 文件时,会把它放到一个随机的内存地址,这个字段记录的就是那个起始地址。
-
l_ld: 指向模块自身的动态节 ( 的指针。这是最关键的部分!动态节就像是模块的“目录”,里面包含了指向其他重要表的指针,比如:
-
符号表 (Symbol Table): 记录了本模块定义和需要引用的所有函数/变量名(如 "printf")。
-
字符串表 (String Table): 存放所有符号名称的实际字符串。
-
重定位表 (Relocation Table): 记录了哪些地方(比如 GOT 表项)需要被动态链接器填充地址。
-
-
, : 指向前一个和后一个模块 link_map 的指针,形成一个双向链表。动态链接器通过这个链表可以遍历所有已加载的模块。
举例说明:为什么需要这个“身份证”
假设你的程序 my_app 依赖两个共享库:libA.so 和 libc.so。
-
my_app (主程序)
-
libA.so (你自己的一个库)
-
libc.so (C 标准库,提供 printf)
当 my_app 启动时,动态链接器 (ld.so) 会把这三个模块都加载到内存中,并为它们分别创建一个 link_map 实例,然后将这些实例链接成一个链表。
场景:
-
调用请求 : my_app 执行 call <printf@plt>。
-
跳转到 PLT[0]: 经过 PLT[n] 的跳转,最终执行流到达了我们分析的那段代码 (sub_3B0)。
-
push dword ptr [ebx+4]:
-
此时,ebx 指向的是 的 GOT 表。
-
[ebx+4] 存放的是指向 的 的指针。
-
这条指令把 my_app 的“身份证”压入了栈中。
-
-
jmp dword ptr [ebx+8]: 跳转到动态链接器。
现在,动态链接器开始工作。它拿到了什么信息?
-
从栈上:它拿到了 my_app 的 link_map 指针(模块标识符)。
-
从另一个栈上参数(由 PLT[n] 推入):它知道了需要解析的符号是 printf。
动态链接器的工作流程,就像一个图书管理员被问询:
-
“谁在问?”: 链接器查看收到的 link_map 指针。“哦,是 my_app(l_name: "/path/to/my_app")需要帮助。”
-
“他要找什么?”: 链接器查看 my_app 的重定位表(通过 my_app 的 link_map -> l_ld -> 重定位表找到)。“啊,他需要符号 printf,并且需要把地址填回到他自己的 GOT 表的某个位置。”
-
“我去哪里找?”: printf 不是 my_app 自己定义的。链接器需要去其他模块里寻找。它如何知道其他模块在哪?很简单,通过 my_app 的 link_map 中的 l_next 指针,开始遍历整个 。
-
先检查 libA.so。链接器访问 libA.so 的 link_map,查看它的符号表。没找到 printf。
-
继续遍历,下一个是 libc.so。链接器访问 libc.so 的 link_map,查看它的符号表。找到了!
-
-
计算真实地址: libc.so 的符号表只记录了 printf 相对于 libc.so 文件开头的偏移量。链接器需要用 libc.so 的加载基地址 (l_addr 字段,也记录在它的 link_map 中) 加上这个偏移量,才能得到 printf 在内存中的绝对地址。
-
更新请求者的信息: 链接器现在有了 printf 的真实地址。它需要把这个地址写回 my_app 的 GOT 表中。它知道写到哪里,因为这个信息记录在 my_app 的重定位表中。
总结
如果没有这个“模块标识符” (link_map),动态链接器就像一个失忆的管理员。它会收到一个匿名的请求:“请帮我找 printf 的地址”。但它会面临几个致命问题:
-
不知道为谁服务:它不知道是哪个模块发出的请求。
-
不知道上下文:它不知道应该去查询哪个模块的依赖关系和重定位表。
-
不知道结果送回哪里:即使找到了 printf 的地址,它也不知道应该更新哪个模块的 GOT 表。
因此,push dword ptr [ebx+4] 这条指令的核心作用就是:在请求动态链接器进行地址解析时,明确地传递自己的身份信息,为整个解析过程提供必要的上下文。
第二步分析全局的所有处理函数的其他区域含义
LOAD:00000000 ; LOAD:00000000 ; +-------------------------------------------------------------------------+ LOAD:00000000 ; | This file was generated by The Interactive Disassembler (IDA) | ; 此注释块由反汇编工具 IDA Pro 生成 LOAD:00000000 ; | Copyright (c) 2023 Hex-Rays, <support@hex-rays.com> | ; 版权信息 LOAD:00000000 ; +-------------------------------------------------------------------------+ LOAD:00000000 ; LOAD:00000000 ; Input SHA256 : 454CFD29FC4F51B40470FC0AA3BEDFDA676678346AF3FE23F4E042A78BEAA4FA ; 输入文件的 SHA256 哈希值 LOAD:00000000 ; Input MD5 : AE704E25BEA3A477F05327442125570D ; 输入文件的 MD5 哈希值 LOAD:00000000 ; Input CRC32 : 13FB67DD ; 输入文件的 CRC32 校验和 LOAD:00000000 LOAD:00000000 ; File Name : C:\...\libhello_jni.so ; 被分析的文件路径和名称 LOAD:00000000 ; Format : ELF for Intel 386 (Shared object) ; 文件格式:用于 Intel 386 架构的 ELF 共享对象(.so文件) LOAD:00000000 ; Needed Library 'liblog.so' ; 依赖库:需要安卓日志库 liblog.so LOAD:00000000 ; Needed Library 'libstdc++.so' ; 依赖库:需要C++标准库 LOAD:00000000 ; Needed Library 'libm.so' ; 依赖库:需要数学库 LOAD:00000000 ; Needed Library 'libc.so' ; 依赖库:需要C标准库 LOAD:00000000 ; Needed Library 'libdl.so ' ; 依赖库:需要动态链接库 LOAD:00000000 ; Shared Name 'libhello_jni.so' ; 此共享库的名称 LOAD:00000000 ; LOAD:00000000 LOAD:00000000 .686p ; 汇编指令:指定目标处理器为 80686 或更高版本 LOAD:00000000 .mmx ; 汇编指令:表示代码可能使用 MMX 指令集 LOAD:00000000 .model flat ; 汇编指令:使用扁平内存模型(32位保护模式下的标准模型) LOAD:00000000 .intel_syntax noprefix ; 汇编指令:使用 Intel 汇编语法,并且寄存器前不需要 '%' 前缀 ; =========================================================================== ; ELF 文件头 (ELF Header) - 描述了整个文件的基本属性 ; =========================================================================== LOAD:00000000 ; LOAD:00000000 ; Segment type: Pure code ; 段类型:纯代码段 LOAD:00000000 ; Segment permissions: Read/Execute ; 段权限:可读/可执行 LOAD:00000000 LOAD segment mempage public 'CODE' use32 ; 定义一个名为 LOAD 的段,32位模式 LOAD:00000000 assume cs:LOAD ; 假设代码段(CS)寄存器指向 LOAD 段 LOAD:00000000 assume es:nothing, ss:nothing, ds:_data, fs:nothing, gs:nothing ;假设其他段寄存器的指向 LOAD:00000000 dword_0 dd 464C457Fh ; ELF 魔数 (0x7F 'E' 'L' 'F'), 标识这是个 ELF 文件 LOAD:00000004 db 1 ; 文件类别, 1 表示 32 位 LOAD:00000005 db 1 ; 数据编码, 1 表示小端序 (Little-endian) LOAD:00000006 db 1 ; 文件版本, 始终为 1 LOAD:00000007 db 0 ; 操作系统/ABI, 0 表示 UNIX System V LOAD:00000008 db 0 ; ABI 版本 LOAD:00000009 db 7 dup(0) ; 定义7个字节的填充数据,用于对齐 LOAD:00000010 dw 3 ; 文件类型, 3 表示共享对象 (.so) LOAD:00000012 dw 3 ; 机器架构, 3 表示 Intel 80386 LOAD:00000014 dd 1 ; 文件版本, 始终为 1 LOAD:00000018 dd 0 ; 程序入口点地址。对于 .so 文件,此值为 0,因为入口由加载器决定 (如 JNI_OnLoad) LOAD:0000001C dd 34h ; 程序头表(PHT)在文件中的偏移地址 (52字节处) LOAD:00000020 dd 1148h ; 节头表(SHT)在文件中的偏移地址 LOAD:00000024 dd 0 ; 处理器特定标志,对于 x86 通常为 0 LOAD:00000028 dw 34h ; ELF 文件头自身的大小 (52字节) LOAD:0000002A dw 20h ; 程序头表中每个条目的大小 (32字节) LOAD:0000002C dw 8 ; 程序头表中的条目数量 (共8个) LOAD:0000002E dw 28h ; 节头表中每个条目的大小 (40字节) LOAD:00000030 dw 19h ; 节头表中的条目数量 (共25个) LOAD:00000032 dw 18h ; 节名节在节头表中的索引24 ; =========================================================================== ; 程序头表 (Program Header Table, PHT) - 指导操作系统如何将文件加载到内存 ; =========================================================================== LOAD:00000034 ; PHT Entry 0: 描述程序头表自身 LOAD:00000034 dword_34 dd 6 ; 类型: 6 (PT_PHDR), 表示这个条目描述的是程序头表本身 LOAD:00000038 dd 34h ; 文件偏移: 程序头表在文件中的位置 LOAD:0000003C dd offset dword_34 ; 虚拟地址: 加载到内存中的地址 LOAD:00000040 dd 34h ; 物理地址: (在嵌入式系统中重要) LOAD:00000044 dd 100h ; 文件大小: 程序头表在文件中的大小 (256字节) LOAD:00000048 dd 100h ; 内存大小: 加载到内存后的大小 LOAD:0000004C dd 4 ; 标志: 4 (PF_R), 表示可读 LOAD:00000050 dd 4 ; 对齐: 内存对齐要求 LOAD:00000054 ; PHT Entry 1: 第一个可加载段 (通常是代码段) LOAD:00000054 dd 1 ; 类型: 1 (PT_LOAD), 表示这是一个需要被加载到内存的段 LOAD:00000058 dd 0 ; 文件偏移: 从文件开头加载 LOAD:0000005C dd 0 ; 虚拟地址: 加载到内存的基地址 0 LOAD:00000060 dd 0 ; 物理地址: LOAD:00000064 dd 7C8h ; 文件大小: 在文件中的大小 LOAD:00000068 dd 7C8h ; 内存大小: 在内存中的大小 LOAD:0000006C dd 5 ; 标志: 5 (PF_R | PF_X), 表示可读、可执行 (代码段) LOAD:00000070 dd 1000h ; 对齐: 4KB 页面对齐 LOAD:00000074 ; PHT Entry 2: 第二个可加载段 (通常是数据段) LOAD:00000074 dd 1 ; 类型: 1 (PT_LOAD) LOAD:00000078 dd 0EB4h ; 文件偏移: 从文件的 0xEB4 处开始加载 LOAD:0000007C dd offset off_1EB4 ; 虚拟地址: 加载到内存的 0x1EB4 处 LOAD:00000080 dd 1EB4h ; 物理地址: LOAD:00000084 dd 15Ch ; 文件大小: LOAD:00000088 dd 15Ch ; 内存大小: LOAD:0000008C dd 6 ; 标志: 6 (PF_R | PF_W), 表示可读、可写 (数据段) LOAD:00000090 dd 1000h ; 对齐: 4KB 页面对齐 LOAD:00000094 ; PHT Entry 3: 动态链接信息段 LOAD:00000094 dd 2 ; 类型: 2 (PT_DYNAMIC), 包含动态链接所需的信息 LOAD:00000098 dd 0EC0h ; 文件偏移: LOAD:0000009C dd offset stru_1EC0 ; 虚拟地址: LOAD:000000A0 dd 1EC0h ; 物理地址: LOAD:000000A4 dd 128h ; 文件大小: LOAD:000000A8 dd 128h ; 内存大小: LOAD:000000AC dd 6 ; 标志: 6 (PF_R | PF_W), 可读写 LOAD:000000B0 dd 4 ; 对齐: LOAD:000000B4 ; PHT Entry 4: 注释段 LOAD:000000B4 dd 4 ; 类型: 4 (PT_NOTE), 包含附加信息,如编译器版本 LOAD:000000B8 dd 134h ; 文件偏移: LOAD:000000BC dd offset dword_134 ; 虚拟地址: LOAD:000000C0 dd 134h ; 物理地址: LOAD:000000C4 dd 24h ; 文件大小: LOAD:000000C8 dd 24h ; 内存大小: LOAD:000000CC dd 4 ; 标志: 4 (PF_R), 可读 LOAD:000000D0 dd 4 ; 对齐: LOAD:000000D4 ; PHT Entry 5: GNU 异常处理帧 LOAD:000000D4 dd 6474E550h ; 类型: 0x6474E550 (PT_GNU_EH_FRAME), 用于C++异常处理 LOAD:000000D8 dd 774h ; 文件偏移: LOAD:000000DC dd offset unk_774 ; 虚拟地址: LOAD:000000E0 dd 774h ; 物理地址: LOAD:000000E4 dd 54h ; 文件大小: LOAD:000000E8 dd 54h ; 内存大小: LOAD:000000EC dd 4 ; 标志: 4 (PF_R), 可读 LOAD:000000F0 dd 4 ; 对齐: LOAD:000000F4 ; PHT Entry 6: GNU 栈信息 LOAD:000000F4 dd 6474E551h ; 类型: 0x6474E551 (PT_GNU_STACK), 描述栈是否可执行 (这里不可执行) LOAD:000000F8 dd 0 ; 文件偏移: LOAD:000000FC dd 0 ; 虚拟地址: LOAD:00000100 dd 0 ; 物理地址: LOAD:00000104 dd 0 ; 文件大小: LOAD:00000108 dd 0 ; 内存大小: LOAD:0000010C dd 6 ; 标志: 6 (PF_R | PF_W), 表示栈可读写 LOAD:00000110 dd 0 ; 对齐: LOAD:00000114 ; PHT Entry 7: GNU 只读数据段重定位后保护 LOAD:00000114 dd 6474E552h ; 类型: 0x6474E552 (PT_GNU_RELRO), RELRO保护相关 LOAD:00000118 dd 0EB4h ; 文件偏移: LOAD:0000011C dd offset off_1EB4 ; 虚拟地址: LOAD:00000120 dd 1EB4h ; 物理地址: LOAD:00000124 dd 14Ch ; 文件大小: LOAD:00000128 dd 14Ch ; 内存大小: LOAD:0000012C dd 6 ; 标志: 6 (PF_R | PF_W) LOAD:00000130 dd 4 ; 对齐: ; =========================================================================== ; 其他 ELF 元数据节区 ; =========================================================================== ; ELF 注释条目 (Note Entry) LOAD:00000134 dword_134 dd 4 ; 名称大小: "GNU" 字符串长度为 4 (含\0) LOAD:00000138 dd 14h ; 描述大小: 20字节 LOAD:0000013C dd 3 ; 类型: 3 (NT_GNU_BUILD_ID), 表示这是一个唯一的构建ID LOAD:00000140 aGnu db 'GNU',0 ; 名称: "GNU" LOAD:00000144 db ... ; 描述: 20字节的构建ID哈希值,用于唯一标识此次编译产物 ; ELF 符号表 (Symbol Table) - 定义串表与程序中的实体(函数、变量、数据等)之间的映射关系,并为链接(静态链接和动态链接)以及调试提供关键信息。 LOAD:00000158 Elf32_Sym <0> ; 符号表第一个条目,固定为空 LOAD:00000168 Elf32_Sym <...> ; 符号: __cxa_finalize (用于C++的全局对象析构) LOAD:00000178 Elf32_Sym <...> ; 符号: __cxa_atexit (用于注册C++退出时调用的函数) LOAD:00000188 Elf32_Sym <...> ; 符号: __stack_chk_fail (栈保护失败时调用的函数) LOAD:00000198 Elf32_Sym <...> ; 符号: Java_..._staticRegFromJni (一个JNI函数) LOAD:000001A8 Elf32_Sym <...> ; 符号: JNI_OnLoad (JNI库的标准入口函数) LOAD:000001B8 Elf32_Sym <...> ; 符号: nativeMethod (一个本地方法) LOAD:000001C8 Elf32_Sym <...> ; 符号: _edata (已初始化数据段的结束位置) LOAD:000001D8 Elf32_Sym <...> ; 符号: __bss_start (未初始化数据段的开始位置) LOAD:000001E8 Elf32_Sym <...> ; 符号: _end (程序数据段的结束位置) ; ELF 字符串表 (String Table) - 存放所有字符串,如符号名、库名 LOAD:000001F8 byte_1F8 db 0 ; 空字符串,通常是字符串表的第一个条目 LOAD:000001F8 ; (续上一行) LOAD:000001F9 aCxaFinalize db '__cxa_finalize',0 ; C++ ABI函数名,用于在库卸载时执行全局析构函数 LOAD:00000208 aLibc db 'LIBC',0 ; 符号版本名,用于版本控制 LOAD:0000020D aLibcSo db 'libc.so',0 ; 依赖的C标准库文件名 LOAD:00000215 aLibhelloJniSo db 'libhello_jni.so',0 ; 本共享库的文件名 LOAD:00000225 aCxaAtexit db '__cxa_atexit',0 ; C++ ABI函数名,用于注册在库卸载时调用的函数 LOAD:00000232 aStackChkFail db '__stack_chk_fail',0 ; 栈保护函数名,当检测到栈溢出时被调用 LOAD:00000243 aJavaGithubJp10 db 'Java_github_jp1017_hellojni_MainActivity_staticRegFromJni',0 ; 静态注册的JNI函数名,遵循Java_包名_类名_方法名格式 LOAD:00000243 ; (续上一行) LOAD:0000027D aJniOnload db 'JNI_OnLoad',0 ; JNI标准函数,当VM加载此库时首先调用,常用于动态注册native方法 LOAD:00000288 aNativemethod db 'nativeMethod',0 ; 一个本地方法名,很可能在JNI_OnLoad中被动态注册 LOAD:00000295 aEdata db '_edata',0 ; 链接器符号,标记已初始化数据段(.data)的结束位置 LOAD:0000029C aBssStart db '__bss_start',0 ; 链接器符号,标记未初始化数据段(.bss)的开始位置 LOAD:000002A8 aEnd db '_end',0 ; 链接器符号,标记程序段的结束位置 LOAD:000002AD aLiblogSo db 'liblog.so',0 ; 依赖的安卓日志库文件名 LOAD:000002B7 aLibstdcSo db 'libstdc++.so',0 ; 依赖的C++标准库文件名 LOAD:000002C4 aLibmSo db 'libm.so',0 ; 依赖的数学库文件名 LOAD:000002CC aLibdlSo db 'libdl.so',0 ; 依赖的动态链接库文件名 LOAD:000002D5 align 4 ; 按4字节对齐 LOAD:000002D8 ; ELF 哈希表 (.hash) LOAD:000002D8 elf_hash_nbucket dd 3 ; 定义哈希桶(bucket)的数量为3 LOAD:000002DC elf_hash_nchain dd 0Ah ; 定义哈希链(chain)的条目数量为10 LOAD:000002E0 elf_hash_bucket dd 7, 9, 8 ; 哈希桶数组,用于快速定位符号 LOAD:000002EC elf_hash_chain dd 4 dup(0), 2, 1, 4, 3, 5, 6 ; 哈希链数组,用于处理哈希冲突和链接同义词
符号查找系统工作原理
1. 桶数组:区域起始点
桶0 桶1 桶2 ↓ ↓ ↓ [ 7 ] [ 9 ] [ 8 ] ← 从符号表第7/9/8号开始查找
2. 链数组:符号间的连接关系
符号索引: 0 1 2 3 4 5 6 7 8 9
链数据: [0,0,0,0,2,1,4,3,5,6]
│ │ │ │ │ │ │ │ │ └─ 9号符号的下一个是6号
│ │ │ │ │ │ │ │ └── 8号的下一个是5号
│ │ │ │ │ │ │ └──── 7号的下一个是3号
│ │ │ │ │ │ └────── 6号的下一个是4号
│ │ │ │ │ └──────── 5号的下一个是1号
│ │ │ │ └────────── 4号的下一个是2号
│ │ │ └──────────── 3号的下一个是0(结束)
│ │ └────────────── 2号的下一个是0(结束)
│ └──────────────── 1号的下一个是0(结束)
└────────────────── 0号的下一个是0(结束)
三桶十链的完整结构
桶0路径 (入口索引=7)
7 → chain[7]=3 → chain[3]=0 (结束) 路径:符号7 → 符号3
桶1路径 (入口索引=9)
9 → chain[9]=6 → chain[6]=4 → chain[4]=2 → chain[2]=0 (结束) 路径:符号9 → 符号6 → 符号4 → 符号2
桶2路径 (入口索引=8)
8 → chain[8]=5 → chain[5]=1 → chain[1]=0 (结束) 路径:符号8 → 符号5 → 符号1
实际符号表对应关系
假设符号表内容:
| 符号索引 | 符号名 |
|---|---|
| 0 | (未使用) |
| 1 | read |
| 2 | write |
| 3 | open |
| 4 | close |
| 5 | lseek |
| 6 | mmap |
| 7 | printf |
| 8 | scanf |
| 9 | malloc |
那么哈希表建立的查找路径:
桶0:printf(7) → open(3) 桶1:malloc(9) → mmap(6) → close(4) → write(2) 桶2:scanf(8) → lseek(5) → read(1)
查找示例:找"read"
-
计算桶号:
hash("read") % 3 = 2→ 去桶2 -
查看入口:
桶2起始索引=8 → 符号8是"scanf"(不是) -
沿链查找:
-
chain[8]=5 → 符号5是"lseek"(不是)
-
chain[5]=1 → 符号1是"read"(找到!)
-
只需 3步 就找到目标,而线性扫描需要 8步 (从0到8)
这些数字就像快递仓库的"智能标签系统":
bucket= 货架入口编号
chain= 包裹上的"下一个包裹"指示标签
共同实现从 无序集合 到 高效网络 的转变
; ELF GNU 符号版本表 - 用于处理库版本兼容性问题 LOAD:00000314 dw 0 ; 默认0 LOAD:00000316 dw 2 ; __cxa_finalize 符号需要版本2(来自LIBC) GNU Symbol Version Table (.gnu.version节) 是一个与动态符号表 (.dynsym节) 一一对应的数组。这意味着,版本表中的第 N 个条目,描述的是符号表中的第 N 个符号。 LOAD:00000318 dw 2 ; __cxa_atexit@@LIBC LOAD:0000031A dw 2 ; __stack_chk_fail@@LIBC LOAD:0000031C dw 1 ; global symbol: Java_github_jp1017_hellojni_MainActivity_staticRegFromJni LOAD:0000031E dw 1 ; global symbol: JNI_OnLoad LOAD:00000320 dw 1 ; global symbol: nativeMethod LOAD:00000322 dw 1 ; global symbol: _edata LOAD:00000324 dw 1 ; global symbol: __bss_start LOAD:00000326 dw 1 ; global symbol: _end 一句话总结 dw 2:凡是标 2 的,都是 libhello_jni.so 依赖的外部函数。它不仅告诉系统需要这个函数,还精确指定了需要哪个版本(LIBC版),从而保证了兼容性,防止程序因库版本不匹配而崩溃。 总结 列表项 标签 通俗解释 Java...staticRegFromJni, JNI_OnLoad, ... dw 1 “我提供这些”:这是我 libhello_jni.so 自己的产品,我向外提供。 __cxa_finalize, __cxa_atexit, ... dw 2 “我需要这些”:这些是我要从 libc.so 订购的零件,并且必须是 LIBC 这个特定版本。 ; ELF GNU 符号版本需求 - 定义本库依赖的外部符号版本 LOAD:00000344 ; ELF GNU Symbol Version Requirements LOAD:00000344 Elf32_Verneed <1, 1, offset aLibcSo - offset byte_1F8, 10h, 0> ; "libc.so" LOAD:00000354 Elf32_Vernaux <50D63h, 0, 2, offset aLibc - offset byte_1F8, 0> ; "LIBC" ; ELF GNU 符号版本需求表 (.gnu.version_r) ; ----------------------------------------------------------------- ; 第一部分:文件需求结构 (Elf32_Verneed),描述需要哪个文件。 ; ----------------------------------------------------------------- LOAD:00000344 dw 1 ; vn_version (版本号);此字段的值固定为1。 LOAD:00000346 dw 1 ; vn_cnt (所需版本数量);表示本文件("libc.so")需要1个特定的版本信息。 LOAD:00000348 dd offset aLibcSo - offset byte_1F8; vn_file (文件名偏移);指向字符串表中 "libc.so" 的偏移地址。 LOAD:0000034C dd 10h ; vn_aux (辅助入口偏移);从本结构开始(0x344)到第一个辅助版本结构(0x354)的偏移量,即16字节。 LOAD:00000350 dd 0 ; vn_next (下一个文件需求偏移);值为0,表示这是清单上的最后一个文件。 ; ----------------------------------------------------------------- ; 第二部分:版本需求辅助结构 (Elf32_Vernaux),描述需要什么版本。 ; ----------------------------------------------------------------- LOAD:00000354 dd 50D63h ; vna_hash (版本名哈希值);字符串 "LIBC" 的ELF哈希值,用于动态链接器快速查找。 LOAD:00000358 dw 0 ; vna_flags (标志位);通常为0,表示无特殊标志。 LOAD:0000035A dw 2 ; vna_other (版本索引号);【关键】定义了版本索引号为 "2"。因此,任何在符号版本表(.gnu.version)中使用索引2的符号,都要求是这个 "LIBC" 版本。 LOAD:0000035C dd offset aLibc - offset byte_1F8; vna_name (版本名偏移);指向字符串表中 "LIBC" 的偏移地址。 LOAD:00000360 dd 0 ; vna_next (下一个版本需求偏移);值为0,表示对于libc.so文件,这是唯一需要的版本。 ; ELF REL 重定位表 - 用于修正数据引用的地址 (也称为 .rel.dyn 节) LOAD:00000364 Elf32_Rel <1EB4h, 8> ; R_386_RELATIVE: 需要对 0x1EB4 地址进行相对地址重定位 LOAD:0000036C Elf32_Rel <2000h, 8> ; R_386_RELATIVE LOAD:00000374 Elf32_Rel <2004h, 8> ; R_386_RELATIVE LOAD:0000037C Elf32_Rel <2008h, 8> ; R_386_RELATIVE LOAD:00000384 Elf32_Rel <200Ch, 8> ; R_386_RELATIV REL 表就是一本“内部地址修正手册”,它告诉动态链接器:“嘿,我代码里有几个指针,它们指向的是我自己内部的东西。现在我们被加载到 0xXXXXXXXX 这个基地址了,请你帮我把这些指针的值都更新一下,让它们指向正确的绝对地址。” 分析 Elf32_Rel <1EB4h, 8> Elf32_Rel <r_offset, r_info> 1. r_offset -> 1EB4h: “哪个指针需要修正?” 含义:这个值 1EB4h 指明了需要被修正的那个指针变量在库文件中的位置。 链接器的工作:动态链接器会找到 (加载基地址 + 1EB4h) 这个内存位置。这个位置上存储着一个需要被修正的地址值。 2. r_info -> 8: “如何修正?” 含义:这个值 8 (十六进制是 0x08) 被分解为两部分。 重定位类型 (低8位): 0x08 (十进制为 8)。在x86架构下,8 代表 R_386_RELATIVE。这告诉链接器,这是一个相对地址重定位。 符号表索引 (高24位): 0x00。这是关键! 索引为0意味着**“不需要去符号表里查找任何名字”**。修正所需的所有信息(即原始的相对偏移)已经存在于 1EB4h 这个位置本身了。 ; ELF JMPREL 重定位表 - 用于修正PLT跳转的地址 (函数调用) 也称为 .rel.plt 节 LOAD:0000038C Elf32_Rel <1FF4h, 207h> ; R_386_JMP_SLOT __cxa_atexit: 需要修正 __cxa_atexit 函数在GOT表中的地址,1FF4h就是__cxa_atexit的外部地址,207h 重定位类型 (低8位): 0x07 (十进制为 7)。在x86架构下,7 就代表 R_386_JMP_SLOT。这告诉链接器,这是一个针对函数跳转的重定位,需要查找函数地址并填入GOT。这与注释完全吻合。 符号表索引 (高24位): 0x02 (十进制为 2)。这个数字 2 是一个索引,指向 动态符号表 (.dynsym)。 LOAD:00000394 Elf32_Rel <1FF8h, 307h> ; R_386_JMP_SLOT __stack_chk_fail: 修正 __stack_chk_fail 的地址 LOAD:0000039C Elf32_Rel <1FFCh, 107h> ; R_386_JMP_SLOT __cxa_finalize: 修正 __cxa_finalize 的地址 LOAD:000003A4 align 10h ; 对齐: 确保后续地址是16字节对齐 LOAD:000003A4 LOAD ends ; LOAD段定义结束 ; LOAD段结束 ; =========================================================================== ; .rodata 段 (Read-Only Data) - 存放只读数据,主要是字符串常量 ; =========================================================================== .rodata:000005B4 ; Segment type: Pure data ; 段类型:纯数据 .rodata:000005B4 ; Segment permissions: Read ; 段权限:只读 .rodata:000005B4 _rodata segment dword public 'CONST' use32 ; 定义 _rodata 段 .rodata:000005B4 assume cs:_rodata ; 假设 cs 寄存器指向 _rodata 段 .rodata:000005B4 ;org 5B4h ; 原始起始地址 .rodata:000005B4 unk_5B4 db 0E5h, ... ; 一个未识别的字节序列,可能是一个加密/混淆的字符串或数据。被 sub_4B0 函数引用。 ... .rodata:000005CC db 0 ; 字符串结束符 .rodata:000005CD unk_5CD db 0E9h, ... ; 另一个未识别的字节序列。被 JNI 函数引用。 ... .rodata:000005E5 db 0 ; 字符串结束符 .rodata:000005E6 aDynamicregfrom db 'dynamicRegFromJni',0 ; 字符串: "dynamicRegFromJni",用于动态注册 JNI 方法。 .rodata:000005F8 aLjavaLangStrin db '()Ljava/lang/String;',0 ; 字符串: "()Ljava/lang/String;",这是 JNI 方法签名,表示一个无参数、返回 String 对象的方法。 .rodata:0000060D align 10h ; 对齐: 确保地址是16字节对齐 .rodata:00000610 aGithubJp1017He db 'github/jp1017/hellojni/MainActivity',0 ; 字符串: "github/jp1017/hellojni/MainActivity",这是 JNI 寻找的 Java 类路径。 .rodata:00000610 _rodata ends ; _rodata 段定义结束
核心概念:这是做什么的?
在你开始看每一行之前,最重要的是理解这两段数据(.eh_frame 和 .eh_frame_hdr)的整体用途。
-
目的:它们是用来实现 异常处理(Exception Handling) 和 栈回溯(Stack Unwinding) 的。
-
场景:想象一下你的C++代码里有一个 try...catch 块,或者程序崩溃了需要生成一个函数调用栈(call stack)的报告。当异常被抛出或程序崩溃时,系统需要知道如何安全地“撤销”当前函数的-操作,返回到调用它的上一个函数,然后再撤销上一个函数,一步步地回溯,直到找到能处理异常的 catch 块或者程序终止。这个“撤销”的过程就叫栈回溯。
-
作用:这两段数据就是“栈回溯说明书”。.eh_frame 详细记录了每个函数是如何设置其栈帧(保存寄存器、分配局部变量等)的,这样系统就知道如何反向操作来拆解它。.eh_frame_hdr 是 .eh_frame 的一个“索引”或“目录”,能让系统快速地找到特定函数对应的“说明书”。
这些数据由编译器自动生成,遵循一种名为 DWARF 的标准格式。
.eh_frame 段的详细解释
.eh_frame (Exception Handling Frame) 包含了一系列的记录,主要有两种:
-
CIE (Common Information Entry):通用信息条目。它是一个“模板”,定义了适用于多个函数的通用规则,比如寄存器大小、返回地址存储在哪等。一个 .eh_frame 段通常只有一个或少数几个CIE。
-
FDE (Frame Description Entry):帧描述条目。它对应一个具体的函数,包含了该函数的起始地址、代码长度,并引用一个CIE模板,然后补充该函数独有的栈操作指令。
第一个记录:CIE (通用信息模板)
这是一个所有后续函数描述(FDE)都会引用的模板。
生成的程序集
.eh_frame:00000634 ; ===========================================================================
.eh_frame:00000634
.eh_frame:00000634 ; Segment type: Pure data
.eh_frame:00000634 ; Segment permissions: Read
.eh_frame:00000634 _eh_frame segment dword public 'CONST' use32
.eh_frame:00000634 assume cs:_eh_frame
.eh_frame:00000634 ;org 634h
.eh_frame:00000634 db 14h ; --- CIE 记录开始 ---
.eh_frame:00000635 db 0
.eh_frame:00000636 db 0
.eh_frame:00000637 db 0 ; }-> 记录长度 (不含自身): 0x14 = 20 字节。
.eh_frame:00000638 db 0 ; --- CIE 标识符 ---
.eh_frame:00000639 db 0
.eh_frame:0000063A db 0
.eh_frame:0000063B db 0 ; }-> 0x00000000 表示这是一个CIE记录,而不是FDE。
.eh_frame:0000063C db 1 ; -> 版本号: 1
.eh_frame:0000063D db 7Ah ; z ; --- "增强"字符串 (Augmentation String) ---
.eh_frame:0000063E db 52h ; R ; }-> "zR",一个以null结尾的字符串。'z'表示有增强数据,'R'表示FDE中的指针是PC相对的。
.eh_frame:0000063F db 0 ; }-> 字符串结束符 (null)。
.eh_frame:00000640 db 1 ; -> 代码对齐因子 (Code Alignment Factor): 1。指令地址需要乘以这个数。
.eh_frame:00000641 db 7Ch ; | ; -> 数据对齐因子 (Data Alignment Factor): -4。栈偏移量需要乘以这个数。(SLEB128编码)
.eh_frame:00000642 db 8 ; -> 返回地址寄存器的编号: 8。
.eh_frame:00000643 db 1 ; -> "增强"数据的长度: 1 字节 (因为前面有 'z')。
.eh_frame:00000644 db 1Bh ; -> "增强"数据本身: 0x1B,定义了FDE中指针的编码方式 (PC相对,4字节有符号数)。
.eh_frame:00000645 db 0Ch ; --- 初始栈帧规则 (CFI - Call Frame Instructions) ---
.eh_frame:00000646 db 4 ; }-> DW_CFA_def_cfa r4, 4: 定义CFA (Canonical Frame Address,可以理解为栈帧基准) 为 寄存器4(ESP) + 4。
.eh_frame:00000647 db 4
.eh_frame:00000648 db 88h ; -> DW_CFA_offset r8, 1: 定义寄存器8(返回地址)保存在 CFA - (1 * 4) = CFA - 4 的位置。
.eh_frame:00000649 db 1
.eh_frame:0000064A db 0 ; -> 对齐字节,填充到4字节边界。
.eh_frame:0000064B db 0 ; -> 对齐字节。 --- CIE 记录结束 ---第二个记录:第一个 FDE (函数帧描述)
这个记录描述了第一个函数的栈信息。
生成的程序集
.eh_frame:0000064C db 14h ; --- FDE #1 记录开始 ---
.eh_frame:0000064D db 0
.eh_frame:0000064E db 0
.eh_frame:0000064F db 0 ; }-> 记录长度: 0x14 = 20 字节。
.eh_frame:00000650 db 1Ch ; --- CIE 指针 ---
.eh_frame:00000651 db 0
.eh_frame:00000652 db 0
.eh_frame:00000653 db 0 ; }-> 指向CIE的偏移量: 0x1C。计算方式: 0x650 - 0x1C = 0x634,正好是上面CIE的起始地址。
.eh_frame:00000654 db 0CCh ; --- 函数信息 ---
.eh_frame:00000655 db 0FDh
.eh_frame:00000656 db 0FFh
.eh_frame:00000657 db 0FFh ; }-> 函数起始地址 (PC-relative offset): 这是一个相对偏移,指向函数代码的开始。
.eh_frame:00000658 db 13h ; -> 函数代码长度: 0x13 = 19 字节。
.eh_frame:00000659 db 0
.eh_frame:0000065A db 0
.eh_frame:0000065B db 0
.eh_frame:0000065C db 0 ; -> "增强"数据长度: 0 (这个FDE没有额外的增强数据)。
.eh_frame:0000065D db 44h ; D ; --- 描述函数内部栈变化的指令 (CFI) ---
.eh_frame:0000065E db 0Eh ; }-> (这部分是CFI指令,描述函数执行过程中,程序计数器(PC)和栈指针(SP)如何变化)
.eh_frame:0000065F db 10h
.eh_frame:00000660 db 4Eh ; N
.eh_frame:00000661 db 0Eh
.eh_frame:00000662 db 4
.eh_frame:00000663 db 0 ; -> 对齐字节。 --- FDE #1 记录结束 ---后续的 FDE 记录
接下来的所有条目,直到 .eh_frame_hdr 开始前,都是类似的 FDE 记录,每一个都对应程序中的一个不同函数。它们的结构和上面解释的 FDE #1 完全一样,只是具体的值(如函数地址、长度和栈变化指令)不同。
生成的程序集
; --- FDE #2 开始于 0x664 (长度 0x1C) ---
.eh_frame:00000664 db 1Ch
...
; --- FDE #3 开始于 0x688 (长度 0x24) ---
.eh_frame:00000688 db 24h ; $
...
; --- FDE #4 开始于 0x6A8 (长度 0x24) ---
.eh_frame:000006A8 db 24h ; t ; (原文误为74h, 应该是24h)
...
; --- FDE #5 开始于 0x6CC (长度 0x1C) ---
.eh_frame:000006C8 db 1Ch ; (原文误为94h, 应该是1Ch)
...
; (等等... 直到最后一个FDE)注:反汇编器有时会错误地将数据解析为ASCII字符(如
.eh_frame_hdr 段的详细解释
.eh_frame_hdr (Exception Handling Frame Header) 是 .eh_frame 段的辅助部分,它像一本书的目录,能让系统非常快速地找到某个函数对应的 FDE,而无需从头到尾扫描整个 .eh_frame。
生成的程序集
.eh_frame_hdr:00000774 ; ===========================================================================
.eh_frame_hdr:00000774
.eh_frame_hdr:00000774 ; Segment type: Pure data
.eh_frame_hdr:00000774 ; Segment permissions: Read
.eh_frame_hdr:00000774 _eh_frame_hdr segment dword public 'CONST' use32
.eh_frame_hdr:00000774 assume cs:_eh_frame_hdr
.eh_frame_hdr:00000774 ;org 774h
.eh_frame_hdr:00000774 unk_774 db 1 ; -> 版本号: 1
.eh_frame_hdr:00000775 db 1Bh ; -> .eh_frame 指针的编码格式 (pcrel, sdata4 - PC相对,4字节有符号数)。
.eh_frame_hdr:00000776 db 3 ; -> FDE 数量的编码格式 (udata4 - 4字节无符号数)。
.eh_frame_hdr:00000777 db 3Bh ; ; ; -> 搜索表的编码格式 (pcrel, sdata4 - PC相对,4字节有符号数)。
.eh_frame_hdr:00000778 db 0BCh ; --- 指向 .eh_frame 段开头的指针 ---
.eh_frame_hdr:00000779 db 0FEh
.eh_frame_hdr:0000077A db 0FFh
.eh_frame_hdr:0000077B db 0FFh ; }-> 相对偏移量。计算: 0x778 + (-0x144) = 0x634。正确指向 .eh_frame 的开头。
.eh_frame_hdr:0000077C db 9 ; --- FDE 的总数 ---
.eh_frame_hdr:0000077D db 0
.eh_frame_hdr:0000077E db 0
.eh_frame_hdr:0000077F db 0 ; }-> 总共有 9 个 FDE 记录。搜索表 (Search Table)
这是 .eh_frame_hdr 最核心的部分。它是一个排好序的列表,每一项包含两个信息:函数的起始地址和指向其 FDE 的指针。系统可以通过二分查找在这个表里快速定位。
生成的程序集
.eh_frame_hdr:00000780 db 3Ch ; < ; --- 搜索表条目 #1 ---
.eh_frame_hdr:00000781 db 0FCh
.eh_frame_hdr:00000782 db 0FFh
.eh_frame_hdr:00000783 db 0FFh ; }-> [键] 函数的起始地址 (相对偏移)。
.eh_frame_hdr:00000784 db 0D4h
.eh_frame_hdr:00000785 db 0FFh
.eh_frame_hdr:00000786 db 0FFh
.eh_frame_hdr:00000787 db 0FFh ; }-> [值] 指向该函数FDE的指针 (相对偏移)。
.eh_frame_hdr:00000788 db 7Ch ; | ; --- 搜索表条目 #2 ---
.eh_frame_hdr:00000789 db 0FCh
.eh_frame_hdr:0000078A db 0FFh
.eh_frame_hdr:0000078B db 0FFh ; }-> [键] 下一个函数的起始地址。
.eh_frame_hdr:0000078C db 0F0h
.eh_frame_hdr:0000078D db 0FEh
.eh_frame_hdr:0000078E db 0FFh
.eh_frame_hdr:0000078F db 0FFh ; }-> [值] 指向其FDE的指针。
...
; (后面跟着剩下的7个条目,结构完全相同,直到 0x7C7 结束)总结
-
.eh_frame: 像一本详细的“汽车修理手册”,每一章(FDE)都教你如何拆解一个特定型号的发动机(函数栈帧)。它还有一个通用工具和规则介绍(CIE)。
-
.eh_frame_hdr: 像这本书的“目录”,按发动机型号(函数地址)排序,告诉你去第几页找对应的修理说明(FDE地址)。有了这个目录,你就不需要一页一页地翻书了。
这两部分协同工作,为现代编程语言的异常处理和调试功能提供了底层的支持。
; ===========================================================================
; .init_array 和 .fini_array 段 - 初始化与终止函数表
; ===========================================================================
.fini_array:00001EB4 ; ELF 终止函数表
.fini_array:00001EB4 _fini_array segment ... ; 定义 _fini_array 段
.fini_array:00001EB4 off_1EB4 dd offset sub_3F0 ; 存放一个函数指针,指向 sub_3F0。这个函数将在库被卸载时调用。
.fini_array:00001EB8 db ... ; 填充字节
.fini_array:00001EBB _fini_array ends ; _fini_array 段结束
.init_array:00001EBC ; ELF 初始化函数表
.init_array:00001EBC _init_array segment ... ; 定义 _init_array 段
.init_array:00001EBC align 10h ; 对齐
.init_array:00001EBC _init_array ends ; _init_array 段结束 (此文件中为空,表示没有在 main 之前的初始化函数)
; ===========================================================================
; .dynamic 段 (在IDA中显示为LOAD段的一部分) - 动态链接信息
; ===========================================================================
.dynamic 节 - 动态链接的“说明书”
这个节区包含了一系列的键值对,动态链接器 (ld.so) 读取这些信息来了解如何链接这个共享库,比如它依赖哪些其他库,重定位表在哪里等。
Generated assembly
LOAD:00001EC0 ; ELF Dynamic Information ; .dynamic 节的开始,包含了所有动态链接所需的信息
LOAD:00001EC0 ; ===========================================================================
LOAD:00001EC0 ; Segment type: Pure data ; 段类型:纯数据
LOAD:00001EC0 ; Segment permissions: Read/Write ; 段权限:可读/可写 (加载器在启动时会修改部分内容)
LOAD:00001EC0 LOAD segment mempage public 'DATA' use32 ; 定义一个名为 LOAD 的段
LOAD:00001EC0 assume cs:LOAD ; 假设代码段(CS)寄存器指向 LOAD 段
LOAD:00001EC0 ;org 1EC0h ; 原始起始地址
LOAD:00001EC0 stru_1EC0 Elf32_Dyn <3, <1FE8h>> ; 标记(DT_PLTGOT): 告诉动态链接器,全局偏移表(.got.plt)的地址位于 0x1FE8。
LOAD:00001EC8 Elf32_Dyn <2, <18h>> ; 标记(DT_PLTRELSZ): PLT相关重定位条目(.rel.plt)的总大小为 0x18 (24) 字节。
LOAD:00001ED0 Elf32_Dyn <17h, <38Ch>> ; 标记(DT_JMPREL): 指向PLT的重定位表(.rel.plt)的地址,位于 0x38C。这里存放了所有需要延迟绑定的函数信息。
LOAD:00001ED8 Elf32_Dyn <14h, <11h>> ; 标记(DT_PLTREL): 指定PLT重定位使用的条目类型为 17 (REL类型)。
LOAD:00001EE0 Elf32_Dyn <11h, <364h>> ; 标记(DT_REL): 指向数据重定位表(.rel.dyn)的地址,位于 0x364。
LOAD:00001EE8 Elf32_Dyn <12h, <28h>> ; 标记(DT_RELSZ): 数据重定位表的总大小为 0x28 (40) 字节。
LOAD:00001EF0 Elf32_Dyn <13h, <8>> ; 标记(DT_RELENT): 每个数据重定位条目的大小为 8 字节。
LOAD:00001EF8 Elf32_Dyn <6FFFFFFAh, <5>> ; 标记(DT_RELCOUNT): 相对重定位条目的数量为 5 个。
LOAD:00001F00 Elf32_Dyn <6, <158h>> ; 标记(DT_SYMTAB): 指向符号表的地址,位于 0x158。
LOAD:00001F08 Elf32_Dyn <0Bh, <10h>> ; 标记(DT_SYMENT): 每个符号表条目的大小为 16 字节。
LOAD:00001F10 Elf32_Dyn <5, <1F8h>> ; 标记(DT_STRTAB): 指向字符串表的地址,位于 0x1F8。
LOAD:00001F18 Elf32_Dyn <0Ah, <0DDh>> ; 标记(DT_STRSZ): 字符串表的总大小为 221 字节。
LOAD:00001F20 Elf32_Dyn <4, <2D8h>> ; 标记(DT_HASH): 指向哈希表的地址,位于 0x2D8,用于快速查找符号。
LOAD:00001F28 Elf32_Dyn <1, <0B5h>> ; 标记(DT_NEEDED): 指示该库依赖于 liblog.so。加载器会确保这个库也被加载。
LOAD:00001F30 Elf32_Dyn <1, <0BFh>> ; 标记(DT_NEEDED): 依赖于 libstdc++.so。
LOAD:00001F38 Elf32_Dyn <1, <0CCh>> ; 标记(DT_NEEDED): 依赖于 libm.so。
LOAD:00001F40 Elf32_Dyn <1, <15h>> ; 标记(DT_NEEDED): 依赖于 libc.so。 所需库的名字在字符串表的第 15h 个字节处 (索引)
LOAD:00001F48 Elf32_Dyn <1, <0D4h>> ; 标记(DT_NEEDED): 依赖于 libdl.so。
LOAD:00001F50 Elf32_Dyn <0Eh, <1Dh>> ; 标记(DT_SONAME): 定义了本共享库自己的名字,即 "libhello_jni.so"。
LOAD:00001F58 Elf32_Dyn <1Ah, <1EB4h>> ; 标记(DT_FINI_ARRAY): 指向终止函数数组的地址,这些函数在库卸载时调用。
LOAD:00001F60 Elf32_Dyn <1Ch, <8>> ; 标记(DT_FINI_ARRAYSZ): 终止函数数组的大小为 8 字节。
LOAD:00001F68 Elf32_Dyn <19h, <1EBCh>> ; 标记(DT_INIT_ARRAY): 指向初始化函数数组的地址,这些函数在库加载后、main执行前调用。
LOAD:00001F70 Elf32_Dyn <1Bh, <4>> ; 标记(DT_INIT_ARRAYSZ): 初始化函数数组的大小为 4 字节。
LOAD:00001F78 Elf32_Dyn <10h, <0>> ; 标记(DT_SYMBOLIC): (已废弃的标志)。
LOAD:00001F80 Elf32_Dyn <1Eh, <0Ah>> ; 标记(DT_FLAGS): 包含各种标志,如 BIND_NOW, TEXTREL 等。
LOAD:00001F88 Elf32_Dyn <6FFFFFFBh, <1>> ; 标记(DT_FLAGS_1): 附加标志位,如 NOW, GLOBAL, NODELETE。
LOAD:00001F90 Elf32_Dyn <6FFFFFF0h, <314h>> ; 标记(DT_VERSYM): 指向符号版本表的地址。
LOAD:00001F98 Elf32_Dyn <6FFFFFFCh, <328h>> ; 标记(DT_VERDEF): 指向此库定义的版本信息的地址。
LOAD:00001FA0 Elf32_Dyn <6FFFFFFDh, <1>> ; 标记(DT_VERDEFNUM): 此库定义的版本数量。
LOAD:00001FA8 Elf32_Dyn <6FFFFFFEh, <344h>> ; 标记(DT_VERNEED): 指向此库依赖的版本信息的地址。
LOAD:00001FB0 Elf32_Dyn <6FFFFFFFh, <1>> ; 标记(DT_VERNEEDNUM): 此库依赖的版本数量。
LOAD:00001FB8 Elf32_Dyn <0> ; 标记(DT_NULL): 动态节的结束标记。动态链接器读到这里就知道信息结束了。
... ; (后续为填充字节,用于对齐)
LOAD:00001FE7 LOAD ends ; LOAD段结束
你可以把这两行看作是给动态链接器(就是那个负责把你程序跑起来的系统组件)的两份**“特别说明”或者“行为准则”**。
第一行:DT_FLAGS - 基本的“游戏规则”
Generated assembly
LOAD:00001F80 Elf32_Dyn <1Eh, <0Ah>> ; 标记(DT_FLAGS): 包含各种标志
Use code with caution.
Assembly
这行设置了最基本的操作规则。它的值是 0Ah,也就是十六进制的 10。在计算机里,这通常是一个“位掩码”,代表多个规则的组合。
0x0A (十六进制) = 10 (十进制) = 8 + 2。这表示它同时开启了两个规则:
规则 0x02 (DF_TEXTREL):
技术含义: TEXTREL 的意思是“文本段(代码段)有重定位”。
通俗解释: 这是一条“安全警告”。它告诉链接器:“注意!我的代码区(.text)可能不是完美的,你可能需要在加载我的时候,直接动手修改我的机器指令。”
为什么不好: 通常,代码区加载到内存后应该是“只读”的,防止被黑客篡改。如果需要修改它,操作系统就必须暂时给它“可写”权限。这就像你把办公室的门禁临时关掉,任何人都能进去涂改文件,存在安全风险。这通常是由于一些老的代码或者特殊的汇编写法导致的。
规则 0x08 (DF_SYMBOLIC):
技术含义: SYMBOLIC 链接。
通俗解释: 这是一条“优先规则”。它说:“如果我的代码里需要调用一个函数(比如 log),请优先使用我自己内部定义的版本,不要去主程序或其他库里找。”
影响: 这是一种比较旧的链接方式,可以避免一些版本冲突,但有时也会导致意外的行为,因为你可能期望它调用的是一个外部更新的版本。
一句话总结 DT_FLAGS: 这份说明书告诉链接器,这个库有点“老派”,存在安全隐患(代码段可写),并且链接时有点“特立独行”(优先用自己的函数)。
第二行:DT_FLAGS_1 - 附加的“现代化安全条例”
Generated assembly
LOAD:00001F88 Elf32_Dyn <6FFFFFFBh, <1>> ; 标记(DT_FLAGS_1): 附加标志位
Use code with caution.
Assembly
这行是第一份规则的补充说明,通常包含更现代、更安全的设置。它的值是 1。
1 代表只开启了一个规则:
规则 0x1 (DF_1_NOW):
技术含义: BIND_NOW,立即绑定。
通俗解释: 这是一条“勤快模式”或者“安全优先”的规则。它告诉链接器:“别偷懒了!不要等到我第一次调用 printf 时才去找它的地址。现在,立刻,马上,把我需要的所有外部函数的地址一次性全部找好,填到我的地址簿(GOT表)里!”
这么做的好处:
安全性 (最重要!): 一旦链接器在程序启动时把所有地址都填写完毕,它就可以把整个地址簿(.got.plt)上锁,设为“只读”。这样,黑客在程序运行过程中就无法篡改这个地址簿来劫持函数调用了。这个安全特性叫做 Full RELRO。
性能可预见性: 程序启动会慢一点点(因为要一次性干完所有活),但好处是,程序运行中第一次调用任何外部函数时,都不会有因为查找地址而造成的微小卡顿。
一句话总结 DT_FLAGS_1: 这份补充条例表明,这个库非常注重安全,它宁愿在启动时多花一点时间,也要确保“地址簿”在程序运行期间是绝对安全的、不可篡改的。
综合来看
这两条规则放在一起看,描绘了一个有趣的画像:
这个 libhello_jni.so 库,一方面因为某些代码原因,被迫开启了不安全的 TEXTREL 标志;但另一方面,它又主动开启了非常安全的 BIND_NOW 标志来加固它的 GOT 表。
.got.plt 节 - 动态链接的“地址簿”
这是全局偏移表(Global Offset Table)的一部分,专门用于过程链接表(PLT)。它像一个可以随时更新的地址簿,存放着外部函数的真实地址。
.got.plt:00001FE8 ; ===========================================================================
.got.plt:00001FE8 ; Segment type: Pure data ; 段类型:纯数据
.got.plt:00001FE8 ; Segment permissions: Read/Write ; 段权限:可读/可写,因为链接器需要修改它
.got.plt:00001FE8 _got_plt segment dword public 'DATA' use32 ; 定义 _got_plt 段
.got.plt:00001FE8 assume cs:_got_plt ; 假设 CS 寄存器指向 _got_plt 段
.got.plt:00001FE8 ;org 1FE8h ; 原始起始地址
.got.plt:00001FE8 off_1FE8 dd offset stru_1EC0 ; GOT[0]: GOT表的第一项。它指向动态信息段(.dynamic)的地址(0x1EC0),这是动态链接器工作的基础。
.got.plt:00001FEC dd 0 ; GOT[1]: GOT表的第二项。动态链接器会在这里写入一个指向本模块link_map的指针,用于解析符号。
.got.plt:00001FF0 dd 0 ; GOT[2]: GOT表的第三项。动态链接器会在这里写入它自己的符号解析函数(_dl_runtime_resolve)的地址。
.got.plt:00001FF4 __cxa_atexit_ptr dd offset __cxa_atexit ; GOT条目 for __cxa_atexit: 初始时指向PLT跳板代码,第一次调用后,动态链接器会用__cxa_atexit的真实地址覆盖这里。
.got.plt:00001FF8 __stack_chk_fail_ptr dd offset __stack_chk_fail ; GOT条目 for __stack_chk_fail: 同样,用于延迟绑定__stack_chk_fail函数。
.got.plt:00001FFC __cxa_finalize_ptr dd offset __cxa_finalize ; GOT条目 for __cxa_finalize: 用于延迟绑定__cxa_finalize函数。
.got.plt:00001FFC _got_plt ends ; _got_plt 段结束
; ===========================================================================
; .data 段 - 已初始化的可读写数据
//例如 C/C++ 源码
int init_global = 42; // 已初始化的全局变量 -> .data
static int static_init = 100; // 已初始化的静态变量 -> .data
; ===========================================================================
.data:00002000 off_2000 dd offset off_2000 ; 一个指向自身的指针,可能用于某些PIC代码技巧
.data:00002004 public nativeMethod ; 导出 nativeMethod 符号
.data:00002004 nativeMethod dd offset aDynamicregfrom ; nativeMethod 是一个结构体(JNINativeMethod),其 name 字段指向 'dynamicRegFromJni' 字符串
.data:00002008 dd offset aLjavaLangStrin ; 该结构体的 signature 字段指向 "()Ljava/lang/String;"
.data:0000200C dd offset sub_4B0 ; 该结构体的 fnPtr 字段指向函数 sub_4B0
; ===========================================================================
; .bss 段 - 未初始化的可读写数据
// 例如 C/C++ 源码
int uninit_global; // 未初始化的全局变量 -> .bss
static int static_uninit; // 未初始化的静态变量 -> .bss
; ===========================================================================
.bss:00002010 ; Segment type: Zero-length ; 段类型:零长度(在文件中不占空间)
.bss:00002010 _bss segment ... ; 定义 _bss 段
.bss:00002010 unk_2010 label byte ; .bss 段的开始标签,所有未初始化的全局/静态变量都在这里
.bss:00002010 _bss ends ; _bss 段结束
; ===========================================================================
; extern 段 - 外部符号声明
核心原因:extern 段是反汇编工具(如 IDA Pro)为了方便你阅读而创建的一个“虚拟标签”或“伪段”,它本身并不是程序文件结构里真实存在的部分。
; ===========================================================================
extern:00002014 ; Segment type: Externs ; 段类型:外部引用
extern:00002014 extrn __cxa_finalize:near ; 声明 __cxa_finalize 是一个外部函数
extern:00002018 extrn __cxa_atexit:near ; 声明 __cxa_atexit 是一个外部函数
extern:0000201C extrn __stack_chk_fail:near ; 声明 __stack_chk_fail 是一个外部函数
; ===========================================================================
; abs 段 - 绝对地址符号 用于声明程序中关键内存位置的标签。
; ===========================================================================
abs:00002020 ; Segment type: Absolute symbols ; 段类型:绝对符号
abs:00002020 public _edata ; 导出 _edata 符号
abs:00002020 _edata = 2010h ; 定义 _edata 符号的绝对地址为 0x2010, 即 .data 段的结束
abs:00002024 public __bss_start ; 导出 __bss_start 符号
abs:00002024 __bss_start = 2010h ; 定义 __bss_start 符号的绝对地址为 0x2010, 即 .bss 段的开始
abs:00002028 public _end ; 导出 _end 符号
abs:00002028 _end = 2010h ; 定义 _end 符号的绝对地址为 0x2010, 即 .bss 段的结束 (因为此文件bss为空)
abs:00002028 end ; 汇编文件结束
通俗解释每个符号的作用:
_edata(数据段结束)
地址:0x2010
含义:表示程序初始化数据(如全局变量)的结束位置
示例:假设你有一个初始化的全局数组 int data[10] = {1,2,3...},这个数组的最后一个字节就在 _edata 处
__bss_start(BSS段开始)
地址:同样 0x2010
含义:标记未初始化数据段的起点(例如未赋值的全局变量)
示例:声明但未初始化的全局变量 int buffer[100]; 会从这里开始分配内存
_end(程序内存结束)
地址:还是 0x2010
含义:标识整个程序内存的终点(代码+数据+BSS的总结束位置)
特殊说明:由于本例中三个地址相同,说明该程序没有实际未初始化数据(BSS段为空)
为什么需要这些符号?(实际应用场景)
内存清零初始化
程序启动时,系统会根据 __bss_start 和 _end 的地址范围,自动将未初始化变量清零(这就是为什么未初始化的全局变量默认是0)。
动态内存分配起点
内存分配器(如 malloc)会将 _end 作为堆内存的起始点,后续的堆空间都从这个地址之后开始分配。
链接器定位
链接器在组合多个模块时,通过这些符号精确计算每个段的边界。
第三步分析虚拟地址和实际文件位置之间,汇编和二进制之间的关联

IDA内存布局
7F 45 4C 46 01 01 01 00 00 00 00 00 00 00 00 00 .ELF............ 03 00 03 00 01 00 00 00 00 00 00 00 34 00 00 00 ............4... 48 11 00 00 00 00 00 00 34 00 20 00 08 00 28 00 H.......4. ...(. 19 00 18 00 06 00 00 00 34 00 00 00 34 00 00 00 ........4...4... 34 00 00 00 00 01 00 00 00 01 00 00 04 00 00 00 4............... 04 00 00 00 01 00 00 00 00 00 00 00 00 00 00 00 ................ 00 00 00 00 C8 07 00 00 C8 07 00 00 05 00 00 00 ................ 00 10 00 00 01 00 00 00 B4 0E 00 00 B4 1E 00 00 ................ B4 1E 00 00 5C 01 00 00 5C 01 00 00 06 00 00 00 ....\...\....... 00 10 00 00 02 00 00 00 C0 0E 00 00 C0 1E 00 00 ................ C0 1E 00 00 28 01 00 00 28 01 00 00 06 00 00 00 ....(...(....... 04 00 00 00 04 00 00 00 34 01 00 00 34 01 00 00 ........4...4... 34 01 00 00 24 00 00 00 24 00 00 00 04 00 00 00 4...$...$....... 04 00 00 00 50 E5 74 64 74 07 00 00 74 07 00 00 ....P錿 dt...t... 74 07 00 00 54 00 00 00 54 00 00 00 04 00 00 00 t...T...T....... 04 00 00 00 51 E5 74 64 00 00 00 00 00 00 00 00 ....Q錿 d........ 00 00 00 00 00 00 00 00 00 00 00 00 06 00 00 00 ................ 00 00 00 00 52 E5 74 64 B4 0E 00 00 B4 1E 00 00 ....R錿 d........ B4 1E 00 00 4C 01 00 00 4C 01 00 00 06 00 00 00 ....L...L....... 04 00 00 00 04 00 00 00 14 00 00 00 03 00 00 00 ................ 47 4E 55 00 C2 45 72 A9 2D FD 36 CC B2 DD A6 30 GNU.翬 r....滩 荭 0 BF EE 10 A2 41 68 E9 16 00 00 00 00 00 00 00 00 款 . h.......... 00 00 00 00 00 00 00 00 01 00 00 00 00 00 00 00 ................ 00 00 00 00 12 00 00 00 2D 00 00 00 00 00 00 00 ........-....... 00 00 00 00 12 00 00 00 3A 00 00 00 00 00 00 00 ........:....... 00 00 00 00 12 00 00 00 4B 00 00 00 E0 04 00 00 ........K....... 2F 00 00 00 12 00 0B 00 85 00 00 00 10 05 00 00 /............... A4 00 00 00 12 00 0B 00 90 00 00 00 04 20 00 00 ............. .. 0C 00 00 00 11 00 14 00 9D 00 00 00 10 20 00 00 ............. .. 00 00 00 00 10 00 F1 FF A4 00 00 00 10 20 00 00 ............. .. 00 00 00 00 10 00 F1 FF B0 00 00 00 10 20 00 00 ............. .. 00 00 00 00 10 00 F1 FF 00 5F 5F 63 78 61 5F 66 .........__cxa_f 69 6E 61 6C 69 7A 65 00 4C 49 42 43 00 6C 69 62 inalize.LIBC.lib 63 2E 73 6F 00 6C 69 62 68 65 6C 6C 6F 5F 6A 6E c.so.libhello_jn 69 2E 73 6F 00 5F 5F 63 78 61 5F 61 74 65 78 69 i.so.__cxa_atexi 74 00 5F 5F 73 74 61 63 6B 5F 63 68 6B 5F 66 61 t.__stack_chk_fa 69 6C 00 4A 61 76 61 5F 67 69 74 68 75 62 5F 6A il.Java_github_j 70 31 30 31 37 5F 68 65 6C 6C 6F 6A 6E 69 5F 4D p1017_hellojni_M 61 69 6E 41 63 74 69 76 69 74 79 5F 73 74 61 74 ainActivity_stat 69 63 52 65 67 46 72 6F 6D 4A 6E 69 00 4A 4E 49 icRegFromJni.JNI 5F 4F 6E 4C 6F 61 64 00 6E 61 74 69 76 65 4D 65 _OnLoad.nativeMe 74 68 6F 64 00 5F 65 64 61 74 61 00 5F 5F 62 73 thod._edata.__bs 73 5F 73 74 61 72 74 00 5F 65 6E 64 00 6C 69 62 s_start._end.lib 6C 6F 67 2E 73 6F 00 6C 69 62 73 74 64 63 2B 2B log.so.libstdc++ 2E 73 6F 00 6C 69 62 6D 2E 73 6F 00 6C 69 62 64 .so.libm.so.libd 6C 2E 73 6F 00 00 00 00 03 00 00 00 0A 00 00 00 l.so............ 07 00 00 00 09 00 00 00 08 00 00 00 00 00 00 00 ................ 00 00 00 00 00 00 00 00 00 00 00 00 02 00 00 00 ................ 01 00 00 00 04 00 00 00 03 00 00 00 05 00 00 00 ................ 06 00 00 00 00 00 02 00 02 00 02 00 01 00 01 00 ................ 01 00 01 00 01 00 01 00 01 00 01 00 01 00 01 00 ................ 5F E4 F8 0E 14 00 00 00 00 00 00 00 1D 00 00 00 _澍 ............. 00 00 00 00 01 00 01 00 15 00 00 00 10 00 00 00 ................ 00 00 00 00 63 0D 05 00 00 00 02 00 10 00 00 00 ....c........... 00 00 00 00 B4 1E 00 00 08 00 00 00 00 20 00 00 ............. .. 08 00 00 00 04 20 00 00 08 00 00 00 08 20 00 00 ..... ....... .. 08 00 00 00 0C 20 00 00 08 00 00 00 F4 1F 00 00 ..... .......... 07 02 00 00 F8 1F 00 00 07 03 00 00 FC 1F 00 00 ................ 07 01 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ FF B3 04 00 00 00 FF A3 08 00 00 00 00 00 00 00 ................ FF 25 F4 1F 00 00 68 00 00 00 00 E9 E0 FF FF FF .%....h....猷 ... FF 25 F8 1F 00 00 68 08 00 00 00 E9 D0 FF FF FF .%....h....樾 ... FF 25 FC 1F 00 00 68 10 00 00 00 E9 C0 FF FF FF .%....h....槔 ... 53 E8 AA 00 00 00 81 C3 F2 1B 00 00 8D 64 24 E8 S瑾 ...伱 ....峝 $. 8D 83 18 00 00 00 89 04 24 E8 D2 FF FF FF 8D 64 崈 ......$枰 ...峝 24 18 5B C3 00 00 00 00 00 00 00 00 00 00 00 00 $.[............. 8D 64 24 F4 8B 44 24 10 85 C0 74 02 FF D0 8D 64 峝 $魦 D$.吚 t..袓 d 24 0C C3 8D B6 00 00 00 00 8D BC 27 00 00 00 00 $.脥 .....嵓 '.... 53 E8 5A 00 00 00 81 C3 A2 1B 00 00 8D 64 24 E8 S鑊 ...伱 ....峝 $. 8D 83 18 00 00 00 89 44 24 08 8B 44 24 20 89 44 崈 ....塂 $.婦 $ 塂 24 04 8D 83 38 E4 FF FF 89 04 24 E8 50 FF FF FF $.崈 8.....$鑀 ... 8D 64 24 18 5B C3 8D 76 00 8D BC 27 00 00 00 00 峝 $.[脥 v.嵓 '.... 53 E8 1A 00 00 00 81 C3 62 1B 00 00 8D 64 24 F8 S.....伱 b...峝 $. E8 3B FF FF FF 8D 64 24 08 5B C3 90 8D 74 26 00 .....峝 $.[脨 峵 &. 8B 1C 24 C3 90 8D B4 26 00 00 00 00 00 00 00 00 ..$脨 嵈 &........ 53 E8 EA FF FF FF 81 C3 32 1B 00 00 8D 64 24 E8 S桕 ...伱 2...峝 $. 8D 8B CC E5 FF FF 8B 44 24 20 8B 10 89 4C 24 04 崑 体 ..婦 $ ..塋 $. 89 04 24 FF 92 9C 02 00 00 8D 64 24 18 5B C3 90 ..$.挏 ...峝 $.[脨 53 E8 BA FF FF FF 81 C3 02 1B 00 00 8D 64 24 E8 S韬 ...伱 ....峝 $. 8D 8B E5 E5 FF FF 8B 44 24 20 8B 10 89 4C 24 04 崑 邋 ..婦 $ ..塋 $. 89 04 24 FF 92 9C 02 00 00 8D 64 24 18 5B C3 90 ..$.挏 ...峝 $.[脨 56 53 E8 89 FF FF FF 81 C3 D1 1A 00 00 8D 64 24 VS鑹 ...伱 ....峝 $ DC 8B 44 24 30 8D 4C 24 18 65 8B 35 14 00 00 00 軏 D$0峀 $.e...... 89 74 24 1C 31 F6 8B 10 C7 44 24 08 04 00 01 00 塼 $.1鰦 .荄 $..... 89 4C 24 04 89 04 24 FF 52 18 85 C0 75 5A 8B 44 塋 $...$.R.吚 uZ婦 24 18 8D 8B 28 E6 FF FF 8B 10 89 4C 24 04 89 04 $.崑 (.....塋 $... 24 FF 52 18 8B 54 24 18 8D B3 1C 00 00 00 8B 0A $.R.婽 $.嵆 ...... C7 44 24 0C 01 00 00 00 89 74 24 08 89 44 24 04 荄 $.....塼 $.塂 $. 89 14 24 FF 91 5C 03 00 00 B8 04 00 01 00 8B 74 ..$.慭 ........媡 24 1C 65 33 35 14 00 00 00 75 14 8D 64 24 24 5B $.e35....u.峝 $$[ 5E C3 8D B6 00 00 00 00 B8 FF FF FF FF EB DF E8 ^脥 ..........脒 . CC FE FF FF E5 8A A8 E6 80 81 E6 B3 A8 E5 86 8C 烃 ..鍔 ㄦ €佹 敞 鍐 . E8 B0 83 E7 94 A8 E6 88 90 E5 8A 9F 00 E9 9D 99 璋 冪 敤 鎴 愬 姛 .闈 . E6 80 81 E6 B3 A8 E5 86 8C E8 B0 83 E7 94 A8 E6 鎬 佹 敞 鍐 岃 皟 鐢 ㄦ 88 90 E5 8A 9F 00 64 79 6E 61 6D 69 63 52 65 67 垚 鍔 ..dynamicReg 46 72 6F 6D 4A 6E 69 00 28 29 4C 6A 61 76 61 2F FromJni.()Ljava/ 6C 61 6E 67 2F 53 74 72 69 6E 67 3B 00 00 00 00 lang/String;.... 67 69 74 68 75 62 2F 6A 70 31 30 31 37 2F 68 65 github/jp1017/he 6C 6C 6F 6A 6E 69 2F 4D 61 69 6E 41 63 74 69 76 llojni/MainActiv 69 74 79 00 14 00 00 00 00 00 00 00 01 7A 52 00 ity..........zR. 01 7C 08 01 1B 0C 04 04 88 01 00 00 14 00 00 00 .|.............. 1C 00 00 00 CC FD FF FF 13 00 00 00 00 44 0E 10 ....听 .......D.. 4E 0E 04 00 1C 00 00 00 34 00 00 00 84 FD FF FF N.......4...匌 .. 24 00 00 00 00 41 0E 08 83 02 4F 0E 20 52 0E 08 $....A....O. R.. 41 C3 0E 04 1C 00 00 00 54 00 00 00 B4 FD FF FF A.......T...待 .. 36 00 00 00 00 41 0E 08 83 02 4F 0E 20 64 0E 08 6....A....O. d.. 41 C3 0E 04 1C 00 00 00 74 00 00 00 D4 FD FF FF A.......t...札 .. 1B 00 00 00 00 41 0E 08 83 02 4F 0E 10 49 0E 08 .....A....O..I.. 41 C3 0E 04 10 00 00 00 94 00 00 00 D4 FD FF FF A...........札 .. 04 00 00 00 00 00 00 00 1C 00 00 00 A8 00 00 00 ................ D0 FD FF FF 2F 00 00 00 00 41 0E 08 83 02 4F 0E 旋 ../....A....O. 20 5D 0E 08 41 C3 0E 04 1C 00 00 00 C8 00 00 00 ]..A........... E0 FD FF FF 2F 00 00 00 00 41 0E 08 83 02 4F 0E 帻 ../....A....O. 20 5D 0E 08 41 C3 0E 04 2C 00 00 00 E8 00 00 00 ]..A...,....... F0 FD FF FF A4 00 00 00 00 41 0E 08 86 02 41 0E 瘕 .......A....A. 0C 83 03 4F 0E 30 02 7E 0A 0E 0C 41 C3 0E 08 41 ...O.0.~...A...A C6 0E 04 47 0B 00 00 00 24 00 00 00 18 01 00 00 ...G....$....... 60 FC FF FF 40 00 00 00 00 0E 08 46 0E 0C 4A 0F `...@......F..J. 0B 74 04 78 00 3F 1A 3B 2A 32 24 22 00 00 00 00 .t.x.?.;*2$".... 00 00 00 00 01 1B 03 3B BC FE FF FF 09 00 00 00 .......;件 ...... 3C FC FF FF D4 FF FF FF 7C FC FF FF F0 FE FF FF <.......|...瘙 .. AC FC FF FF D8 FE FF FF CC FC FF FF 10 FF FF FF ..佝 ..厅 ...... 0C FD FF FF 30 FF FF FF 2C FD FF FF 50 FF FF FF ....0...,...P... 3C FD FF FF 64 FF FF FF 6C FD FF FF 84 FF FF FF <...d...l....... 9C FD FF FF A4 FF FF FF 滮 ...... F0 03 00 00 00 00 00 00 00 00 00 00 ............ 03 00 00 00 E8 1F 00 00 02 00 00 00 18 00 00 00 ................ 17 00 00 00 8C 03 00 00 14 00 00 00 11 00 00 00 ................ 11 00 00 00 64 03 00 00 12 00 00 00 28 00 00 00 ....d.......(... 13 00 00 00 08 00 00 00 FA FF FF 6F 05 00 00 00 ...........o.... 06 00 00 00 58 01 00 00 0B 00 00 00 10 00 00 00 ....X........... 05 00 00 00 F8 01 00 00 0A 00 00 00 DD 00 00 00 ................ 04 00 00 00 D8 02 00 00 01 00 00 00 B5 00 00 00 ................ 01 00 00 00 BF 00 00 00 01 00 00 00 CC 00 00 00 ................ 01 00 00 00 15 00 00 00 01 00 00 00 D4 00 00 00 ................ 0E 00 00 00 1D 00 00 00 1A 00 00 00 B4 1E 00 00 ................ 1C 00 00 00 08 00 00 00 19 00 00 00 BC 1E 00 00 ................ 1B 00 00 00 04 00 00 00 10 00 00 00 00 00 00 00 ................ 1E 00 00 00 0A 00 00 00 FB FF FF 6F 01 00 00 00 ...........o.... F0 FF FF 6F 14 03 00 00 FC FF FF 6F 28 03 00 00 ...o.......o(... FD FF FF 6F 01 00 00 00 FE FF FF 6F 44 03 00 00 ...o.......oD... FF FF FF 6F 01 00 00 00 00 00 00 00 00 00 00 00 ...o............ 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 ................ 00 00 00 00 00 00 00 00 C0 1E 00 00 00 00 00 00 ................ 00 00 00 00 18 20 00 00 1C 20 00 00 14 20 00 00 ..... ... ... .. 00 20 00 00 E6 05 00 00 F8 05 00 00 B0 04 00 00 . .............. ?? 00 00 00 00 00 00 00 00 00 00 00 00 ? ............ 10 20 00 00 10 20 00 00 10 20 00 00 . ... ... ..
分析后发现节没有展示,只有010editor识别了
-
SHN_UNDEF:未定义节区
-
note.gnu.build-id:GNU工具链生成的唯一构建ID,用于调试和版本追踪。
-
dynsym:动态链接符号表,存储动态链接所需的函数/变量符号信息。
-
dynstr:动态链接字符串表,存储
dynsym中符号名称的字符串数据。 -
hash:符号哈希表,加速动态链接器对符号的查找过程。
-
gnu.version:存储动态符号的版本定义信息。
-
gnu.version_d:记录共享库的版本定义信息。
-
gnu.version_r:存储共享库的版本依赖关系。
-
rel.dyn:全局数据重定位表,用于动态重定位数据引用。
-
rel.plt:函数重定位表,用于动态重定位函数调用。
-
plt:过程链接表,实现延迟绑定(lazy binding)机制。
-
text:主代码段,包含程序的可执行指令。
-
rodata:只读数据段,存储常量(如字符串字面量)。
-
en_frame:异常处理框架信息(通常为
.eh_frame),支持栈展开。 -
en_frame_hdr:异常处理框架的索引头(通常为
.eh_frame_hdr),加速异常处理。 -
fini_array:析构函数指针数组,程序退出时执行。
-
init_array:构造函数指针数组,程序启动时执行。
-
dynamic:动态链接信息表,包含动态链接器所需的关键元数据。
-
got:全局偏移表,存储全局变量和静态数据的地址。
-
got.plt:PLT专用全局偏移表,存储动态链接函数的实际地址。
-
data:已初始化数据段,存储可读写的全局/静态变量。
-
bss:未初始化数据段,存储零初始化的全局/静态变量。
-
comment:注释信息,通常包含编译器版本等元数据。
-
note.gnu.gold-version:Gold链接器生成的版本信息。
-
shstrtab:节区名称字符串表,存储所有节区名称的字符串数据。
下面我们来逐一解释这个为 .note.gnu.build-id 节准备的“目录条目”中的每个字段:
各字段含义详解
1. s_name / s_name_off / s_name_str (节名称)
-
s_name_off: Bh: 这是存储在文件中的原始值。它不是节的名称本身,而是一个偏移量。Bh 是十六进制的 11。它指向一个特殊的地方——节头字符串表(.shstrtab),告诉我们从这个表的第 11 个字节开始,就是本节的名称。
-
s_name_str[19]: .note.gnu.build-id: 这是工具帮你根据 s_name_off 查找到的实际字符串内容。所以这个节的正式名称是 .note.gnu.build-id。[19] 表示这个名字字符串(包含结尾的空字符 \0)占用了 19 个字节。
2. `s_type: SHT_NOTE`s_type: SHT_NOTE (7) (节类型)
-
定义了这个节存放的是什么类型的内容。
-
SHT_NOTE 表示这是一个“注解”或“笔记”节。它通常用来存放一些不直接参与程序执行,但对工具(如链接器、调试器)很有用的附加信息。这里的 .note.gnu.build-id 就是 GNU 工具链添加的一个“笔记”,内容是程序的唯一构建ID。
3. s_flags: ALLOC (节标志)
-
这是一个标志位,用来说明节的属性。
-
ALLOC (Allocate) 是一个非常重要的标志,它告诉操作系统加载器:当程序运行时,必须为这个节分配内存,并把它从文件加载到内存里。没有这个标志的节(比如调试信息节)在程序运行时通常不会被加载。
4. s_addr: 0x00000134 (内存地址)
-
如果 s_flags 中有 ALLOC 标志,这个字段就指明了当节被加载到内存后,它应该位于哪个虚拟内存地址。
-
这里,.note.gnu.build-id 节将被加载到进程虚拟地址空间的 0x134 处。
5. s_offset: 134h (文件偏移)
-
指明了这个节的数据内容在文件中的起始位置。
-
134h 是十六进制的 0x134。这意味着从文件开头数 0x134 个字节,就是 .note.gnu.build-id 节实际数据的开始。
-
注意: 在这个例子中 s_addr 和 s_offset 的值恰好相同,这在一些简单的、非位置无关(non-PIE)的可执行文件中很常见,表示文件布局和内存布局在起始部分是对应的。
6. s_size: 36 (节大小)
-
指明了这个节在文件中占用了多少字节。
-
这里表示 .note.gnu.build-id 节的数据大小为 36 字节。
7. s_link: 0 和 s_info: 0 (链接与信息)
-
这两个字段的含义取决于 s_type。
-
对于某些类型的节(如符号表 .symtab),s_link 会指向其关联的字符串表,s_info 则有其他特定含义。
-
但对于 SHT_NOTE 类型的节,这两个字段通常不使用,所以值为 0。
8. s_addralign: 4 (地址对齐)
-
规定了节的对齐要求。
-
值为 4 意味着这个节的起始地址(s_addr)必须是 4 的倍数,即需要 4 字节对齐。这对性能和某些硬件平台的指令要求至关重要。0x134 (十进制的308) 是 4 的倍数,符合要求。
9. s_entsize: 0 (条目大小)
-
如果一个节包含一个由许多固定大小的条目组成的表(例如,节头表本身或符号表),这个字段就会指明每个条目的大小。
-
由于 .note.gnu.build-id 节的内容不是一个固定大小的条目表,所以这个字段为 0。
10. s_data[36] (节数据预览)
-
这是分析工具提供的便利功能,它预览了该节在文件中的实际数据。[36] 确认了其大小与 s_size 字段相符。那个 ╝ 字符是工具试图将不可打印的二进制数据显示为文本时出现的乱码。
总结
这个节头条目完整地描述了 .note.gnu.build-id 节的所有元信息:它是一个需要加载到内存(地址 0x134)、4字节对齐的、包含36字节“笔记”信息的区域,其具体数据存放在文件的
通俗精炼解释
这张图展示的是一个共享库(.so 文件)或可执行文件的 “动态符号表” ( 的目录信息。
可以把这个表想象成一个**“进出口清单”**:
-
出口 (Export): 它列出了这个文件能提供给其他程序使用的所有“公共资源”(主要是函数和全局变量)。
-
进口 (Import): 它也列出了这个文件需要从其他库(比如系统库)中“借用”的资源。
这个清单是给动态链接器(程序启动时负责把程序和它依赖的库连接起来的系统组件)看的。动态链接器通过查阅这个清单,才能正确地将不同模块之间的函数调用和变量访问连接起来。
各字段含义详解
这是一个为 .dynsym 节准备的节头条目,我们来逐一分析它的字段:
1. s_name: .dynsym (节名称)
-
节的名称是 .dynsym,即 Dynamic Symbol Table(动态符号表)。
2. s_type: SHT_DYNSYM (11) (节类型)
-
节的类型是 SHT_DYNSYM,明确指出这里存放的是一个动态符号表。这个表包含了动态链接所必需的最少符号信息。它比完整的符号表(.symtab)要小,因为它只包含全局符号、未定义符号等动态链接所需的符号。
3. s_flags: ALLOC (节标志)
-
ALLOC: 同样,这个标志告诉加载器,在程序运行时必须将此节加载到内存中。因为动态链接器在程序启动时需要读取和解析这个表。
4. s_addr: 0x00000158 和 s_offset: 158h (内存地址与文件偏移)
-
s_addr: 此节在内存中的虚拟地址是 0x158。
-
s_offset: 此节在文件中的偏移量是 0x158。
-
动态链接器会在内存的 0x158 地址处找到这个表。
5. s_size: 160 (节大小)
-
整个动态符号表的大小是 160 字节。
6. s_entsize: 16 (条目大小)
-
这是一个非常重要的字段。它说明 .dynsym 是一个由固定大小条目组成的表,其中每个条目(即一个符号的定义)占用 16 字节。
-
我们可以通过 s_size / s_entsize 计算出这个表里有多少个符号:160 / 16 = 10。所以,这个动态符号表里定义了 10 个符号。
7. s_link: 3 (链接信息)
-
这个字段对于符号表至关重要。它不直接指向数据,而是提供一个索引。
-
对于 SHT_DYNSYM 类型的节,s_link 指向与此符号表关联的**字符串表(String Table)**在节头表中的索引。
-
值为 3 意味着:要查找这个符号表中任何一个符号的名字(比如函数名 printf),你需要去看节头表中的第 3 个条目所描述的那个节(通常是 .dynstr),符号表里的条目会给你一个到那个字符串表里的偏移量。
8. s_info: 1 (附加信息)
-
这个字段也很有用。对于 SHT_DYNSYM,s_info 指明了第一个非局部(non-local)符号在符号表中的索引。
-
符号表通常会将局部符号(只在文件内部可见)放在前面,全局符号和弱符号(外部可见)放在后面。
-
值为 1 意味着:这个符号表中的第 0 个符号是局部符号,从第 1 个符号开始(直到最后一个)都是全局或弱符号。这能帮助链接器快速跳过所有局部符号,直接处理用于外部链接的符号。
9. s_addralign: 4 (地址对齐)
-
此节的内存地址必须是 4 的倍数。0x158 (十进制 344) 是 4 的倍数,满足对齐要求。
10. s_data[160] (节数据预览)
-
预览了构成这张 160 字节符号表的原始二进制数据。
总结
这个节头条目精确地定义了一个动态符号表:它是一个包含 10 个符号的列表,每个符号描述占 16 字节,总大小为 160 字节。要查找这些符号的名字,需要去节头表索引为 3 的字符串表里寻找。并且,这个符号列表里从第 1 个符号开始就是对外部可见的全局符号。这个表是实现动态链接的核心数据结构。
这张图描述的是一个**“快速查找手册”**的目录信息,这个手册是专门为 .dynsym(动态符号表,即“进出口清单”)服务的。
可以这样理解:
-
.dynsym 是一本完整的电话簿,按顺序记录了所有可供外部使用的函数/变量。
-
如果要在几千个条目里找一个叫 printf 的函数,从头到尾翻会很慢。
-
.hash 节就是这本电话簿的**“拼音/部首索引页”。它提供了一种快速的哈希算法,让你能通过函数名(如 极大地加快了查找速度**。
所以,.hash 节存在的唯一目的就是优化动态链接器查找符号的性能。
各字段含义详解
这是一个为 .hash 节准备的节头条目,我们来逐一分析它的字段:
1. s_name: .hash (节名称)
-
节的名称是 .hash,表明它是一个符号哈希表。
-
注意: 这是一个比较传统的哈希表格式。现代的 ELF 文件通常会使用一个更高效的 .gnu.hash 节来替代或补充它。
2. s_type: SHT_HASH (5) (节类型)
-
节的类型是 SHT_HASH,明确指出这是一个用于符号查找的哈希表。
3. s_flags: ALLOC (节标志)
-
ALLOC: 同样,这个节必须在程序运行时被加载到内存中,因为动态链接器需要用它来执行符号解析。
4. s_addr: 0x000002D8 和 s_offset: 2D8h (内存地址与文件偏移)
-
s_addr: 哈希表在内存中的虚拟地址是 0x2D8。
-
s_offset: 哈希表在文件中的偏移量是 0x2D8。
5. s_size: 60 (节大小)
-
整个哈希表结构的大小是 60 字节。
6. s_entsize: 4 (条目大小)
-
这个字段指明哈希表是由固定大小的条目组成的,每个条目占用 4 字节(通常是一个32位整数)。
-
我们可以计算出这个哈希表由 60 / 4 = 15 个 4 字节的整数构成。
7. s_link: 2 (链接信息)
-
这是 .hash 节最关键的字段之一。它指明了这个哈希表是为哪个符号表服务的。
-
值为 2 意味着:这个哈希表是为节头表(Section Header Table)中索引为 2 的那个节所描述的符号表而创建的。
-
根据上下文,这个索引为 2 的节几乎可以肯定是 .dynsym(动态符号表)。动态链接器通过这个 s_link 字段,就知道该用这个哈希表去加速哪个符号表的查找。
8. s_info: 0 (附加信息)
-
对于 SHT_HASH 类型的节,这个字段没有被使用,因此其值为 0。
9. s_addralign: 4 (地址对齐)
-
此节的内存地址必须是 4 的倍数。0x2D8 (十进制 728) 是 4 的倍数,满足对齐要求。
10. s_data[60] (节数据预览)
-
这是哈希表 60 字节的原始数据预览。这个数据内部通常包含三个部分:
-
nbucket (1个整数): 哈希桶的数量。
-
nchain (1个整数): 链表的元素数量,通常等于其关联的符号表中的符号数量。
-
buckets 数组 (nbucket 个整数): 哈希桶数组。
-
chains 数组 (nchain 个整数): 用于解决哈希冲突的链表数组。
-
总结
这个节头条目定义了一个符号哈希表,它是一个大小为 60 字节、由 15 个 4 字节整数组成的辅助数据结构。它的核心作用是通过 s_link 字段关联到 ,为动态链接器提供一个快速的、基于哈希的查找机制,以提高符号解析的效率。
这张图描述的是一个**“符号版本标签表”**的目录信息。它与我们之前看到的 .dynsym(动态符号表)是“配套”使用的。
可以这样理解:
-
.dynsym 是一个函数的清单,比如 printf, strcpy 等。
-
.gnu.version 是一个与该清单一一对应的版本号列表。
想象一下,.dynsym 是公司所有员工(符号)的花名册。而 .gnu.version 就是另一份并排的表格,记录了每个员工属于哪个项目版本(比如 "Project Phoenix v1.0", "Legacy Support v2.2")。
它的核心作用是:
当一个程序被编译时,它不仅记录了需要 printf 这个函数,还记录了它需要的是哪个版本的 printf(比如 GLIBC_2.0 版本)。当程序运行时,动态链接器会检查这份版本表,确保提供的 printf 版本不低于程序所要求的版本。这极大地增强了库的向后兼容性,防止因库升级导致老程序崩溃的问题。
各字段含义详解
这是一个为 .gnu.version 节准备的节头条目,我们来逐一分析它的字段:
1. s_name: .gnu.version (节名称)
-
节的名称是 .gnu.version,表明这是一个 GNU 符号版本节。
2. s_type: SHT_GNU_versym (1879048191) (节类型)
-
SHT_GNU_versym (Symbol Version) 是一个 GNU 扩展类型,专门用于存放符号版本信息。
-
这个节本质上是一个数组,数组中的每个元素都对应于 .dynsym 符号表中的一个符号。
3. s_flags: ALLOC (节标志)
-
ALLOC: 同样,此节必须在运行时加载到内存中,供动态链接器进行版本检查。
4. s_addr: 0x00000314 和 s_offset: 314h (内存地址与文件偏移)
-
s_addr: 此版本数组在内存中的虚拟地址是 0x314。
-
s_offset: 此版本数组在文件中的偏移量是 0x314。
5. s_size: 20 (节大小) 和 s_entsize: 2 (条目大小)
-
s_size: 整个版本数组的大小是 20 字节。
-
s_entsize: 数组中每个元素的大小是 2 字节 (ElfN_Half)。
-
关键信息: 我们可以通过这两个值计算出数组的长度:s_size / s_entsize = 20 / 2 = 10。
-
这意味着这个版本数组有 10 个条目。这与我们之前分析的 .dynsym 表中恰好有 10 个符号是完全吻合的。这表明了它们之间严格的一对一关系:.gnu.version 数组的第 N 个条目,就是 .dynsym 符号表中第 N 个符号的版本信息。
6. s_link: 2 (链接信息)
-
这是极其关键的字段。对于 SHT_GNU_versym 节,s_link 指向它所版本化的符号表在节头表中的索引。
-
值为 2 意味着:这个版本数组是为节头表索引为 2 的那个节(也就是 .dynsym 符号表)服务的。这个链接关系明确地告诉了动态链接器,如何将版本信息与具体的符号对应起来。
7. s_info: 0 (附加信息)
-
对于 SHT_GNU_versym 类型的节,此字段未使用,值为 0。
8. s_addralign: 2 (地址对齐)
-
此节的内存地址必须是 2 的倍数。这与条目大小 s_entsize 为 2 字节是匹配的,确保了每个条目都能被高效地访问。
9. s_data[20] (节数据预览)
-
预览了构成这个版本数组的 20 字节原始数据。这 20 字节实际上是 10 个 16位的整数。每个整数是一个索引,指向另一个版本定义表(.gnu.version_r),从而查到具体的版本字符串(如 "GLIBC_2.4")。
总结
这个节头条目定义了一个符号版本数组,它包含了 10 个 2 字节的条目。它通过 s_link 字段紧密地与 ,为 .dynsym 中的每一个符号都打上了一个版本标签。这个机制是现代 Linux/GNU 系统实现强大而灵活的共享库版本控制的基础。
通俗精炼解释
这张图描述的是一个**“版本名称定义表”的目录信息。如果说 解释“标签2”到底是什么**的说明书。
可以这样理解:
-
.dynsym: 员工花名册。
-
.gnu.version: 一张并排的表,写着“张三:标签1”,“李四:标签2”,“王五:标签1”。
-
.gnu.version_d: 版本定义字典,上面写着:
-
标签 1 = "LEGACY_API_V1.0"
-
标签 2 = "NEW_API_V2.0"
-
所以,.gnu.version_d (d for definition) 的作用就是定义这个共享库自己提供了哪些版本。动态链接器通过查阅这个表,就能知道每个版本标签对应的具体版本字符串是什么。
各字段含义详解
这是一个为 .gnu.version_d 节准备的节头条目,我们来逐一分析它的字段:
1. s_name: .gnu.version_d (节名称)
-
节的名称是 .gnu.version_d,即 GNU Version Definition(GNU 版本定义)节。
2. s_type: SHT_GNU_verdef (1879048189) (节类型)
-
SHT_GNU_verdef 是一个 GNU 扩展类型,专门用于存放版本定义结构体的数组。
3. s_flags: ALLOC (节标志)
-
ALLOC: 同样,此节必须在运行时加载到内存中,供动态链接器使用。
4. s_addr: 0x00000328 和 s_offset: 328h (内存地址与文件偏移)
-
s_addr: 此版本定义表在内存中的虚拟地址是 0x328。
-
s_offset: 此版本定义表在文件中的偏移量是 0x328。
5. s_size: 28 (节大小)
-
整个版本定义表的大小是 28 字节。
6. s_entsize: 0 (条目大小)
-
这是一个非常关键的细节。值为 0 意味着这个节中的条目是可变长度的。
-
不像符号表那样每个条目大小都固定,版本定义结构体 (verdef) 后面可以跟不同数量的辅助结构体 (verdaux),所以没有统一的条目大小。
7. s_link: 3 (链接信息)
-
对于 SHT_GNU_verdef 节,s_link 指向存放版本名称字符串的那个字符串表在节头表中的索引。
-
值为 3 意味着:要查找这个节中定义的版本名称(如 "MYLIB_V1.0"),你需要去节头表中索引为 3 的那个节(通常是 .dynstr)里寻找。
8. s_info: 1 (附加信息)
-
对于 SHT_GNU_verdef 节,s_info 指明了这个节中包含多少个版本定义结构体 (。
-
值为 1 意味着:这个共享库只定义了一个版本。这在简单的库中很常见,它可能只导出一个版本,比如 "MYLIB_V1"。
9. s_addralign: 4 (地址对齐)
-
此节的内存地址必须是 4 的倍数,以确保结构体能被正确访问。
10. s_data[28] (节数据预览)
-
预览了构成这个版本定义表的 28 字节原始数据。这 28 字节内部包含了 1 个 verdef 结构体和可能的 verdaux 结构体,它们一起定义了那个唯一的版本信息,包括版本号、标志以及指向版本字符串的偏移量。
总结
这个节头条目定义了一个版本定义表。它告诉我们:
-
这个共享库总共定义了 1 个版本 (s_info: 1)。
-
这些定义信息总共占了 28 字节 (s_size: 28)。
-
要查找这个版本的具体名字(字符串),需要去节头表索引为 3 的字符串表中查找 (s_link: 3)。
这个表与 .gnu.version 节协同工作,完成了从“符号”到“版本号”,再到“版本名”的完整映射,构成了 GNU 符号版本控制系统的核心。
这个最终部分,.gnu.version_r,完成了 GNU 符号版本化拼图。它是 GNU 版本化符号的对应部分
通俗精炼解释
这张图描述的是一个**“版本依赖需求清单”**的目录信息。如果说 .gnu.version_d 是这个共享库(比如 mylib.so)声明“我能提供这些版本的函数”,那么 .gnu.version_r 就是它声明“我需要从其他库(比如 libc.so)获得这些版本的函数”。
可以这样理解:
-
.gnu.version_d (definition): 是这个库的**“产品目录”**,列出了它能提供的产品及其版本。
-
.gnu.version_r (requirement): 是这个库的**“采购清单”**,列出了它要正常工作所必须从其他供应商那里采购的零件,并且对零件的版本有明确要求。
它的核心作用是:
记录本文件依赖于哪些外部共享库,以及需要这些库提供哪些具体的版本。当动态链接器加载程序时,它会检查这份“采购清单”,确保所有需要的库都存在,并且版本都符合要求,否则就会报错并拒绝运行程序。这保证了程序的依赖关系是正确和满足的。
各字段含义详解
这是一个为 .gnu.version_r 节准备的节头条目,我们来逐一分析它的字段:
1. s_name: .gnu.version_r (节名称)
-
节的名称是 .gnu.version_r,即 GNU Version Requirement(GNU 版本需求)节。
2. s_type: SHT_GNU_verneed (1879048190) (节类型)
-
SHT_GNU_verneed 是一个 GNU 扩展类型,专门用于存放版本需求结构体的数组。
3. s_flags: ALLOC (节标志)
-
ALLOC: 同样,此节必须在运行时加载到内存中,供动态链接器进行依赖检查。
4. s_addr: 0x00000344 和 s_offset: 344h (内存地址与文件偏移)
-
s_addr: 此版本需求表在内存中的虚拟地址是 0x344。
-
s_offset: 此版本需求表在文件中的偏移量是 0x344。
5. s_size: 32 (节大小)
-
整个版本需求表的大小是 32 字节。
6. s_entsize: 0 (条目大小)
-
值为 0,同样表示这个节中的条目是可变长度的。一个对外部库的版本需求 (verneed 结构) 后面可以跟不同数量的具体版本需求 (vernaux 结构)。
7. s_link: 3 (链接信息)
-
对于 SHT_GNU_verneed 节,s_link 指向存放被依赖的库文件名和版本字符串的那个字符串表在节头表中的索引。
-
值为 3 意味着:要查找这个节中需求的库名(如 "libc.so.6")和版本名(如 "GLIBC_2.4"),你需要去节头表中索引为 3 的那个节(通常是 .dynstr)里寻找。
8. s_info: 1 (附加信息)
-
对于 SHT_GNU_verneed 节,s_info 指明了这个节中包含多少个版本需求结构体 (,也就是依赖了多少个不同的外部共享库。
-
值为 1 意味着:这个文件只依赖于 1 个需要进行版本检查的外部共享库。
9. s_addralign: 4 (地址对齐)
-
此节的内存地址必须是 4 的倍数。
10. s_data[32] (节数据预览)
-
预览了构成这个版本需求表的 32 字节原始数据。这 32 字节内部通常包含 1 个 verneed 结构体(指明了依赖的库文件名,如 libc.so.6)和至少 1 个 vernaux 结构体(指明了需要该库提供的具体版本,如 GLIBC_2.4)。
总结
这个节头条目定义了一个版本需求表。它告诉我们:
-
这个文件对 1 个外部共享库有版本依赖 (s_info: 1)。
-
描述这些依赖关系的数据总共占了 32 字节 (s_size: 32)。
-
依赖的库名和版本名字符串,存储在节头表索引为 3 的字符串表中 (s_link: 3)。
这个表是保证程序能够正确链接和运行的关键,它确保了所有外部依赖项的版本都符合编译时的预期。
.rel.dyn,是动态链接中最基本的部分之一。我们来分解一下。
通俗精炼解释
这张图描述的是一个**“动态重定位表”的目录信息。可以把它想象成一张“地址修补清单”**,是专门给动态链接器(程序启动时的“装配工”)看的。
这是什么意思呢?
当编译器生成一个共享库(.so)或可执行文件时,它并不知道外部函数(如 printf)或全局变量最终会被加载到内存的哪个确切地址。于是,编译器就在需要这些地址的地方先留下一个占位符或标记(通常是0)。
.rel.dyn 这张清单就记录了所有这些标记的位置。它的每一项都像一条指令:
“喂,装配工!请到内存地址
程序启动时,动态链接器就会逐一执行这份清单上的所有任务,把所有占位符都“修补”成正确的运行时地址。这个过程就叫做重定位(Relocation)。
各字段含义详解
这是一个为 .rel.dyn 节准备的节头条目,我们来逐一分析它的字段:
1. s_name: .rel.dyn (节名称)
-
节的名称是 .rel.dyn。
-
rel: 代表 Relocation(重定位)。
-
dyn: 代表 Dynamic(动态),说明这些重定位操作是在程序运行时由动态链接器完成的。
-
-
注意: 还有一种常见的类型是 .rela.dyn。rel 和 rela 的区别在于,rela 类型的条目里包含一个明确的“加数”(addend),而 rel 类型的加数是隐式存储在被修改的位置上的。
2. s_type: SHT_REL (9) (节类型)
-
节的类型是 SHT_REL,明确指出这是一个重定位表,并且其条目不包含显式的加数。
3. s_flags: ALLOC (节标志)
-
ALLOC: 此节必须加载到内存中,因为动态链接器需要在运行时读取并处理其中的每一条重定位指令。
4. s_addr: 0x00000364 和 s_offset: 364h (内存地址与文件偏移)
-
s_addr: 此重定位表在内存中的虚拟地址是 0x364。
-
s_offset: 此重定位表在文件中的偏移量是 0x364。
5. s_size: 40 (节大小) 和 s_entsize: 8 (条目大小)
-
s_size: 整个重定位表的大小是 40 字节。
-
s_entsize: 表中每个条目(一条重定位指令)的大小是 8 字节。
-
关键信息: 我们可以通过这两个值计算出重定位条目的数量:s_size / s_entsize = 40 / 8 = 5。
-
这意味着这张“修补清单”上总共有 5 条任务需要动态链接器去完成。
6. s_link: 2 (链接信息)
-
这是极其关键的字段。重定位条目需要知道它要解析的是哪个符号(比如 printf)。这个字段就告诉链接器去哪里找符号信息。
-
对于 SHT_REL 节,s_link 指向其关联的符号表在节头表中的索引。
-
值为 2 意味着:要解析这个重定位表中的符号,需要去查阅节头表索引为 2 的那个节(也就是我们之前分析过的 .dynsym 动态符号表)。
7. s_info: 0 (附加信息)
-
对于 SHT_REL 节,如果它只对某一个特定节进行重定位(比如 .rel.plt 只重定位 .plt),那么 s_info 会包含那个被重定位节的索引。
-
值为 0 通常意味着这个重定位表可能作用于多个节(比如修改 .got 表中的条目),没有一个单一的目标节。
8. s_addralign: 4 (地址对齐)
-
此节的内存地址必须是 4 的倍数。
9. s_data[40] (节数据预览)
-
预览了构成这个重定位表的 40 字节原始数据。这 40 字节包含了 5 个 8 字节的 Elf_Rel 结构体,每个结构体都包含两个核心信息:
-
r_offset: 要修补的内存位置。
-
r_info: 包含了要引用的符号在 .dynsym 表中的索引,以及重定位的类型(如何进行修补)。
-
总结
这个节头条目定义了一份包含 5 条指令的动态重定位清单。动态链接器在程序启动时会读取这份清单,并根据节头表索引为 2 的 .dynsym 符号表提供的信息,对程序内存中的 5 个不同位置进行地址“修补”,从而完成对外部函数和变量的正确链接。这是实现动态链接不可或缺的一步。
。这是 .rel.plt 部分,这是一个专门且非常重要的重定位部分。它是惰性函数绑定的核心机制。
通俗精炼解释
这张图描述的是一个**“懒加载函数地址修补清单”**的目录信息。它与我们之前看到的 .rel.dyn 有点像,但用途更专一、更智能。
可以把它想象成一个**“客服首次呼叫转接指南”**:
-
当你的程序第一次调用一个外部函数,比如 printf 时,它实际上并不知道 printf 在哪里。
-
于是,这次调用会被“转接”到一个叫 PLT (Procedure Linkage Table,过程链接表) 的特殊地方。
-
PLT 里的代码会请求动态链接器(“总机客服”)去查找 printf 的真实地址。
-
.rel.plt 就是这份**“转接指南”,它告诉动态链接器:“用户想找的是 直接修改**成一个跳转到 printf 真实地址的指令。”
这样做的好处(懒加载 - Lazy Binding)是:
只有当一个函数第一次被调用时,系统才会花时间去查找它的地址。如果一个函数在程序整个运行期间都没被用到,那系统就永远不会去查找它,从而加快了程序的启动速度。从第二次调用开始,由于 PLT 已经被修改,调用会直接、快速地跳转到真正的函数,不再需要“客服转接”。
各字段含义详解
这是一个为 .rel.plt 节准备的节头条目,我们来逐一分析它的字段:
1. s_name: .rel.plt (节名称)
-
节的名称是 .rel.plt,明确指出这是一个专门为 PLT (Procedure Linkage Table) 服务的重定位节。
2. s_type: SHT_REL (9) (节类型)
-
节的类型是 SHT_REL,与 .rel.dyn 一样,是一个重定位表。
3. s_flags: ALLOC|INFO_LINK (节标志)
-
ALLOC: 此节必须加载到内存中。
-
INFO_LINK: 这是一个非常重要的标志!它表明 s_info 字段有一个特殊的含义。它意味着这个重定位节的操作只针对一个特定的目标节,而这个目标节的索引就保存在 s_info 字段里。
4. s_addr: 0x0000038C 和 s_offset: 38Ch (内存地址与文件偏移)
-
s_addr: 此重定位表在内存中的虚拟地址是 0x38C。
-
s_offset: 此重定位表在文件中的偏移量是 0x38C。
5. s_size: 24 (节大小) 和 s_entsize: 8 (条目大小)
-
s_size: 整个重定位表的大小是 24 字节。
-
s_entsize: 每个重定位条目的大小是 8 字节。
-
关键信息: 我们可以计算出条目数量:s_size / s_entsize = 24 / 8 = 3。
-
这意味着这个文件中有 3 个外部函数是通过 PLT 进行懒加载调用的。
6. s_link: 2 (链接信息)
-
与 .rel.dyn 一样,这个字段指向其关联的符号表在节头表中的索引。
-
值为 2 意味着:要解析这 3 个重定位条目分别对应哪个函数符号,需要去查阅节头表索引为 2 的那个节(即 .dynsym 动态符号表)。
7. s_info: 10 (附加信息)
-
这是本节最关键的字段之一。由于 s_flags 中有 INFO_LINK 标志,这个字段不再是通用的信息,而是特指此重定位表要作用的目标节的索引。
-
值为 10 意味着:这份包含 3 条指令的“修补清单”,其所有操作都是为了修改节头表中索引为 10 的那个节内部的数据。
-
毫无疑问,节头表中索引为 10 的节就是 .plt 节本身。这个字段精确地将 .rel.plt 和 .plt 绑定在了一起。
8. s_addralign: 4 (地址对齐)
-
此节的内存地址必须是 4 的倍数。
9. s_data[24] (节数据预览)
-
预览了构成这个重定位表的 24 字节原始数据,即 3 个 Elf_Rel 结构体。
总结
这个节头条目定义了一份包含 3 条指令的、专门用于懒加载的重定位清单。它告诉动态链接器:
-
有 3 个外部函数需要进行懒加载解析。
-
这些函数的符号信息在节头表索引为 2 的 .dynsym 表中。
-
所有重定位操作(地址修补)的目标都位于节头表索引为 10 的 .plt 节中。
这个机制是现代操作系统优化程序启动性能和动态链接效率的核心技术之一。
通俗精炼解释
这张图描述的是**“过程链接表 (Procedure Linkage Table)”** 的目录信息。这不再是清单或说明书,而是一小段可以实际执行的程序代码。
继续我们之前的“客服中心”比喻:
-
.rel.plt 是“首次呼叫转接指南”。
-
.plt 就是那个**“客服呼叫转接中心”本身**。它是一套自动化的程序,每一部“分机”(每个 PLT 条目)都对应一个外部函数。
它的工作流程是:
-
当你的程序调用 printf,它实际是跳转到 .plt 里为 printf 准备的那段“分机代码”。
-
这段代码会触发动态链接器(总机)去查找 printf 的真实地址。
-
找到后,动态链接器会修改一个地方(通常是 .got.plt 表),让它直接指向 printf。
-
从此以后,再调用 printf 时,这段“分机代码”就会直接把你转接到 printf 的真实地址,速度飞快。
所以,.plt 是一个可执行的“代码跳板”,它的存在使得“用到才去查找地址”的懒加载策略成为可能。
各字段含义详解
这是一个为 .plt 节准备的节头条目,我们来逐一分析它的字段:
1. s_name: .plt (节名称)
-
节的名称是 .plt,即 Procedure Linkage Table(过程链接表)。
2. s_type: SHT_PROGBITS (1) (节类型)
-
节的类型是 SHT_PROGBITS。这表示这个节包含的是“程序数据”,在这里特指机器指令代码。这与之前看到的 SHT_REL(重定位表)或 SHT_DYNSYM(符号表)等元数据节完全不同。
3. s_flags: ALLOC|EXECINSTR (节标志)
-
这是本节最核心、最重要的标志。
-
ALLOC: 必须加载到内存中。
-
EXECINSTR: (Execute Instructions) 这个标志告诉操作系统,存放在这个内存区域的数据是可执行的指令。操作系统和 CPU 会允许代码跳转到这个区域并执行。没有这个标志,任何试图执行 .plt 中代码的尝试都会导致程序因权限错误而崩溃(例如,段错误 Segfault)。
4. s_addr: 0x000003B0 和 s_offset: 3B0h (内存地址与文件偏移)
-
s_addr: PLT 代码在内存中的虚拟地址是 0x3B0。
-
s_offset: PLT 代码在文件中的偏移量是 0x3B0。
5. s_size: 64 (节大小)
-
整个 PLT 节的代码总共占用了 64 字节。
6. s_entsize: 4 (条目大小)
-
对于 SHT_PROGBITS 类型的代码节,这个字段的含义不如数据表那么严格。虽然这里标明为 4,但 PLT 的条目(stub)在不同架构下通常是 12 或 16 字节。这个字段在这里可以理解为代码的最小指令对齐单位。
7. s_link: 0 和 s_info: 0 (链接与信息)
-
对于 SHT_PROGBITS 类型的节,这两个字段通常不使用,所以值为 0。
8. s_addralign: 16 (地址对齐)
-
此节的内存地址必须是 16 的倍数。对代码进行 16 字节对齐是一种常见的性能优化手段,可以更好地利用 CPU 的指令缓存。
9. s_data[64] (节数据预览)
-
预览了构成 PLT 的 64 字节原始机器代码。分析工具无法将它们显示为可读字符,所以显示为乱码(��)。这些二进制数据就是 CPU 实际执行的跳转和调用指令。
总结
这个节头条目定义了一段大小为 64 字节、16 字节对齐的、可执行的机器代码。这段代码就是过程链接表 (PLT),它作为动态链接中函数调用的“跳板”,与 .rel.plt 节紧密合作,共同实现了高效的懒加载(Lazy Binding)机制,以优化程序的启动性能。
通俗精炼解释
这张图描述的是程序**“大脑”或“引擎”**的目录信息,也就是 .text 节。
可以把它想象成:
-
如果整个程序是一辆车,那么 .text 节就是发动机本身。
-
如果整个程序是一本菜谱,那么 .text 节就是所有菜品的核心烹饪步骤。
简单来说,.text 节存放的是程序的主体代码。你编写的所有 C/C++ 函数(比如 main()、你自定义的各种函数等)在被编译器转换成计算机能直接运行的机器指令后,就存储在这里。
它是程序的核心逻辑,是真正“干活”的部分。最重要的特征是,它被标记为**“可执行”**,意味着 CPU 被允许读取并运行这里的指令。
各字段含义详解
这是一个为 .text 节准备的节头条目,我们来逐一分析它的字段:
1. s_name: .text (节名称)
-
节的名称是 .text,这是存放程序可执行指令的传统标准名称。
2. s_type: SHT_PROGBITS (1) (节类型)
-
节的类型是 SHT_PROGBITS,与 .plt 节一样,表明这个节包含的是由程序(编译器)定义的数据。在这种情况下,它特指编译后的机器代码。
3. s_flags: ALLOC|EXECINSTR (节标志)
-
这是至关重要的标志,定义了这个节的性质。
-
ALLOC: 告诉加载器,在程序运行时必须将此节加载到内存中。
-
EXECINSTR: (执行
4. s_addr: 0x000003F0 和 s_offset: 3F0h (内存地址与文件偏移)
-
s_addr: 程序的主体代码在内存中的起始虚拟地址是 0x3F0。
-
s_offset: 这段代码在文件中的起始偏移量是 0x3F0。
5. s_size: 452 (节大小)
-
这个程序所有编译后的主体代码总共占用了 452 字节。这是一个相当小的程序。
6. s_link: 0 和 s_info: 0 (链接与信息)
-
对于 SHT_PROGBITS 类型的节,这两个字段没有特定用途,所以值为 0。
7. s_addralign: 16 (地址对齐)
-
此节的内存地址必须是 16 的倍数。代码对齐是现代 CPU 的一项重要性能优化,有助于提高指令缓存的命中率和指令获取的效率。
8. s_entsize: 0 (条目大小)
-
值为 0。因为 .text 节中的内容是连续的指令流,而不是由固定大小的条目组成的表(比如符号表)。函数和指令的长度是可变的。
9. s_data[452] (节数据预览)
-
预览了构成 .text 节的 452 字节原始机器代码。分析工具试图将其显示为文本,因此出现了乱码 (S瑾)。
总结
这个节头条目定义了整个程序的核心执行部分:一个大小为 452 字节、16 字节对齐、并且拥有执行权限的机器代码块。当程序运行时,CPU 的指令指针(PC 寄存器)会指向这个区域内的某个地址(通常是 _start 或 main 函数的入口点),然后开始逐条执行指令,驱动整个程序的运行。
通俗精炼解释
这张图描述的是程序的**“只读数据区”**的目录信息。
可以把它想象成一块刻在程序里的**“石碑”或“永久公告牌”**:
-
只读 (Read-Only): 程序在运行时可以读取上面的内容,但绝对不允许修改。任何试图往这块“石碑”上刻新字的行为都会被操作系统立即阻止,并导致程序崩溃。
-
数据 (Data): 上面刻着的是程序需要的常量数据。最常见的就是字符串字面量(比如 printf("Hello, World!"); 里的 "Hello, World!")、const 修饰的全局变量、switch-case 语句的跳转表等。
它的核心作用是:
-
安全: 将常量数据放在一个只读区域,可以防止程序因 bug 或恶意攻击意外地修改了它们,从而保证程序的稳定性和安全性。
-
优化: 编译器和链接器可以对这块区域进行优化。例如,如果你的代码里有 10 个地方都用到了字符串 "error",链接器可以只在 .rodata 里存放一份,让所有 10 个地方都指向它,从而节省空间。
各字段含义详解
这是一个为 .rodata 节准备的节头条目,我们来逐一分析它的字段:
1. s_name: .rodata (节名称)
-
节的名称是 .rodata,即 Read-Only Data(只读数据)。
2. s_type: SHT_PROGBITS (1) (节类型)
-
节的类型是 SHT_PROGBITS,表明这个节包含的是由程序(编译器)定义的原始数据。
3. s_flags: ALLOC|MERGE|STRINGS (节标志)
-
这是非常关键的一组标志。
-
ALLOC: 此节必须加载到内存中。
-
MERGE: 这是一个链接器优化标志。它告诉链接器,这个节中的内容是可以合并的。如果链接器发现有多个相同的常量(比如多个源文件里都有 "some string"),它会把它们合并成一个,以减小最终文件的大小。
-
STRINGS: 这个标志告诉链接器,MERGE 标志适用的数据是以空字符(。链接器知道如何根据空字符来识别和比较单个字符串。
4. s_addr: 0x000005B4 和 s_offset: 5B4h (内存地址与文件偏移)
-
s_addr: 此只读数据区在内存中的虚拟地址是 0x5B4。
-
s_offset: 此只读数据区在文件中的偏移量是 0x5B4。
5. s_size: 128 (节大小)
-
这个只读数据区总共占用了 128 字节。
6. s_link: 0 和 s_info: 0 (链接与信息)
-
对于 SHT_PROGBITS 类型的节,这两个字段通常不使用。
7. s_addralign: 4 (地址对齐)
-
此节的内存地址必须是 4 的倍数。
8. s_entsize: 1 (条目大小)
-
当 MERGE 和 STRINGS 标志被设置时,这个字段指明了构成字符串的基本元素的大小。
-
值为 1 意味着字符串是由 1 字节的字符组成的(例如 ASCII 或 UTF-8)。
9. s_data[128] (节数据预览)
-
预览了构成 .rodata 节的 128 字节原始数据。图中显示的乱码是因为分析工具试图用某种编码(如 GBK)来解释这些二进制数据或非标准编码的字符串。
总结
这个节头条目定义了一个大小为 128 字节的只读数据区。它被加载到内存后,会受到操作系统的写保护,确保其内容不会被篡改。其中的字符串等常量数据可以被链接器合并去重,以优化程序体积。这个节是存放程序中所有常量数据的标准位置,对程序的安全和效率至关重要。
这是 .eh_frame 部分,对于支持异常处理和调试的现代编程语言来说是关键组件。
通俗精炼解释
这张图描述的是程序的**“异常处理框架”或“栈回溯说明书”**的目录信息。
可以把它想象成一套为程序中的每个函数准备的**“紧急疏散预案”**:
-
当程序运行时,一个函数调用另一个函数,就像在盖一座楼,一层一层往上加(这叫“调用栈”)。
-
如果在高层楼的某个房间里突然“着火”了(即发生了异常,比如 C++ 中的 throw 或者一个严重的错误),程序不能直接崩溃,而是需要安全地、一层一层地“疏散”下来,直到找到一个“消防站”(即 catch 块或者其他错误处理器)。
-
.eh_frame 就是这份详细的“疏散预案”。它精确地记录了如何拆解每一层楼(即每个函数的栈帧):如何恢复寄存器的值、如何调整栈指针、如何找到上一层楼的返回地址等。
它的核心作用是:
-
实现 C++ 异常处理: 当 throw 被调用时,运行时系统会查阅这份“说明书”来安全地“展开”(unwind)调用栈,销毁沿途创建的局部对象,直到找到匹配的 catch 块。
-
支持调试器: 当你在调试器中设置断点并查看“调用堆栈”(Call Stack)时,调试器就是通过读取 .eh_frame 来弄清楚函数是如何一层层调用的,从而为你展示清晰的调用链。
-
其他语言特性: 一些其他语言的特性(如 longjmp)也可能依赖于这些信息来正确地恢复程序状态。
各字段含义详解
这是一个为 .eh_frame 节准备的节头条目,我们来逐一分析它的字段:
1. s_name: .eh_frame (节名称)
-
节的名称是 .eh_frame,即 Exception Handling Frame(异常处理帧)。
2. s_type: SHT_PROGBITS (1) (节类型)
-
节的类型是 SHT_PROGBITS,表明它包含的是由编译器生成的、有特定格式的程序数据。其内部格式通常遵循 DWARF (Debugging With Attributed Record Formats) 标准。
3. s_flags: ALLOC (节标志)
-
ALLOC: 此节必须在程序运行时被加载到内存中。因为异常可能在任何时刻发生,运行时系统需要随时能够访问这份“说明书”来处理它们。这与那些只在链接或调试时才需要的节(如 .comment 或 .debug_info)不同。
4. s_addr: 0x00000634 和 s_offset: 634h (内存地址与文件偏移)
-
s_addr: 这份“说明书”在内存中的虚拟地址是 0x634。
-
s_offset: 这份“说明书”在文件中的偏移量是 0x634。
5. s_size: 320 (节大小)
-
整个异常处理框架数据的大小是 320 字节。
6. s_link: 0 和 s_info: 0 (链接与信息)
-
对于 SHT_PROGBITS 类型的节,这两个字段通常不使用。
7. s_addralign: 4 (地址对齐)
-
此节的内存地址必须是 4 的倍数。
8. s_entsize: 0 (条目大小)
-
值为 0。这表明 .eh_frame 内部的记录是可变长度的。这是因为不同函数的“疏散预案”复杂程度不同:一个简单的函数可能只需要几个字节的描述,而一个复杂的函数(分配了大量栈空间、保存了多个寄存器)则需要更长的描述。
9. s_data[320] (节数据预览)
-
预览了构成 .eh_frame 的 320 字节原始数据。这些数据是一种紧凑的、面向机器的字节码,用于指导栈回溯过程,所以当被当作文本显示时会是乱码(▒)。
总结
这个节头条目定义了一个大小为 320 字节的数据块,它是在程序运行时必须存在的**“栈回溯说明书”**。它为系统提供了一套规则,用于在发生异常或进行调试时,能够安全、正确地解析当前的调用栈。没有这个节,现代 C++ 的异常处理机制将无法工作,调试器也无法提供准确的函数调用回溯。
通俗精炼解释
这张图描述的是**“.eh_frame 节的头部索引”**的目录信息。
继续我们之前的“紧急疏散预案”的比喻:
-
.eh_frame 是一本非常厚、非常详细的**“紧急疏散预案手册”**,里面包含了所有函数的疏散方案。
-
当发生异常时,如果从头到尾一页一页地翻这本厚手册来找当前函数的方案,会非常慢。
-
.eh_frame_hdr (hdr for Header) 就是这本厚手册的**“目录”或“索引页”。它是一个排好序的小表格,可以让你通过二分查找**等快速算法,迅速定位到 .eh_frame 手册中对应当前函数的疏散方案在哪一页。
它的核心作用是:
极大地加速异常处理和栈回溯时的查找速度。 有了它,系统就不再需要线性扫描整个 .eh_frame,而是可以通过一个快速的索引查找,直接跳转到需要的信息处。
各字段含义详解
这是一个为 .eh_frame_hdr 节准备的节头条目,我们来逐一分析它的字段:
1. s_name: .eh_frame_hdr (节名称)
-
节的名称是 .eh_frame_hdr,即 Exception Handling Frame Header
2. s_type: SHT_PROGBITS (1) (节类型)
-
节的类型是 SHT_PROGBITS,表明它包含的是由编译器生成的、有特定格式的程序数据。
3. s_flags: ALLOC (节标志)
-
ALLOC: 此节必须在程序运行时被加载到内存中。因为它是一个性能优化的关键部分,运行时系统会优先使用它来查找异常处理信息。
4. s_addr: 0x00000774 和 s_offset: 774h (内存地址与文件偏移)
-
s_addr: 这个索引表在内存中的虚拟地址是 0x774。
-
s_offset: 这个索引表在文件中的偏移量是 0x774。
5. s_size: 84 (节大小)
-
整个索引表的大小是 84 字节。这比 .eh_frame(320 字节)要小得多,体现了它作为索引的紧凑性。
6. s_link: 0 和 s_info: 0 (链接与信息)
-
对于 SHT_PROGBITS 类型的节,这两个字段通常不使用。
7. s_addralign: 4 (地址对齐)
-
此节的内存地址必须是 4 的倍数。
8. s_entsize: 0 (条目大小)
-
值为 0。.eh_frame_hdr 的结构是固定的头部信息,后跟一个查找表,它不是一个由统一大小条目组成的简单数组,所以此字段为0。
9. s_data[84] (节数据预览)
-
预览了构成 .eh_frame_hdr 的 84 字节原始数据。这些数据内部包含:
-
一个版本号。
-
一个指向 .eh_frame 节起始位置的指针。
-
一个计数值,说明查找表中有多少个条目。
-
一个已排序的查找表,每个条目包含一个函数的起始地址和其在 .eh_frame 中对应记录的偏移量。
-
这些数据是二进制格式,所以显示为乱码。
-
总结
这个节头条目定义了一个大小为 84 字节的查找索引,它专门为 .eh_frame 节服务。它的存在是为了优化性能,允许运行时系统(如异常处理器或调试器)通过高效的二分查找来快速定位一个特定函数在 .eh_frame 中的栈回溯信息,而不是进行缓慢的线性扫描。对于性能敏感的应用程序,这个小小的索引节至关重要。
.fini_array 和 .init_array。它们处理程序的初始化和清理逻辑。
通俗精炼解释
这张图描述的是程序的**“构造函数列表” (.init_array)** 和 “析构函数列表” ( 的目录信息。
可以把它们想象成一个复杂设备的**“开机自检清单”和“关机流程清单”**:
-
.init_array (初始化数组 - Initialization Array)
-
是什么:一个函数指针列表,记录了所有需要在 main 函数执行之前自动调用的函数。
-
比喻:这就是**“开机自检清单”**。当你按下电源键后,设备会先检查内存、加载驱动、初始化网络... 这些都是在你能开始使用设备(运行 main)之前必须完成的准备工作。在C++中,全局对象的构造函数就会被放在这里。
-
-
.fini_array (终结数组 - Finalization Array)
-
是什么:一个函数指针列表,记录了所有需要在程序正常退出时(如从 main 返回或调用 exit())自动调用的函数。
-
比喻:这就是**“关机流程清单”**。当你选择关机时,设备会保存设置、关闭文件、释放资源... 这是一个有序的清理过程。在C++中,全局对象的析构函数就会被放在这里。
-
核心作用:
提供一个标准化的机制,让程序或库能够在核心逻辑执行前后,自动执行必要的初始化和清理代码,这对于管理资源和维持程序状态至关重要。
.fini_array 节头详解
-
s_name: .fini_array: 节名称,终结数组。
-
s_type: SHT_FINI_ARRAY (15): 专门的类型,表明这是一个存放终结函数的数组。
-
s_flags: WRITE|ALLOC:
-
ALLOC: 必须加载到内存中。
-
WRITE: 可写。这是因为在某些动态链接场景下,加载器可能需要修改这个列表。
-
-
s_addr: 0x00001EB4, s_offset: EB4h: 内存地址和文件偏移。
-
s_size: 8: 表的大小是 8 字节。假设这是一个32位程序,一个函数指针占4字节,那么这个列表里包含了 8 / 4 = 2 个终结函数。
-
s_addralign: 4: 4字节对齐,符合指针大小。
-
s_entsize: 0: 虽然它是一个数组,但标准定义中这个字段对于 INIT/FINI_ARRAY 可以为0。实际的条目大小由地址大小决定(32位系统为4,64位系统为8)。
.init_array 节头详解
-
s_name: .init_array: 节名称,初始化数组。
-
s_type: SHT_INIT_ARRAY (14): 专门的类型,表明这是一个存放初始化函数的数组。
-
s_flags: WRITE|ALLOC: 同样是可写、需分配。
-
s_addr: 0x00001EBC, s_offset: EBCh: 内存地址和文件偏移。
-
s_size: 4: 表的大小是 4 字节。这意味着这个列表里只包含 4 / 4 = 1 个初始化函数。
-
s_addralign: 4: 4字节对齐。
-
s_entsize: 0: 同上。
总结
这张图展示了两个关键的节头定义:
-
.fini_array: 定义了一个包含 2 个函数指针的列表,这些函数将在程序退出时被自动调用,用于执行清理工作。
-
.init_array: 定义了一个包含 1 个函数指针的列表,这个函数将在 main 函数开始前被自动调用,用于执行初始化设置。
这两个数组是现代C/C++程序实现全局构造和析构、以及其他自动设置/清理功能的基石。
.dynamic 部分是动态链接的核心。它是动态链接器用来查找所需所有内容的中央目录。
通俗精炼解释
这张图描述的是程序的**“动态链接总目录”**的元信息。
可以把它想象成一个程序的**“动态链接信息中心”或一个“机场航班信息大屏”**。这个“大屏”上列出了所有与动态链接相关的重要信息:
-
登机口 (Gates): 指向其他重要表格的地址,比如:
-
“符号表在 0x158 地址” (DT_SYMTAB)
-
“哈希索引在 0x2D8 地址” (DT_HASH)
-
“字符串表在 0x... 地址” (DT_STRTAB)
-
-
航班信息 (Flight Info): 各种关键参数,比如:
-
“本程序需要哪些共享库?” (DT_NEEDED)
-
“字符串表有多大?” (DT_STRSZ)
-
“符号表每个条目多大?” (DT_SYMENT)
-
它的核心作用是:
作为动态链接的唯一入口点。当程序启动时,动态链接器首先找到这个 .dynamic 节。然后,它会像读航班大屏一样,从这个节里读取所有它需要的信息(比如其他节的地址、大小、依赖库等),然后根据这些信息去完成符号解析、重定位等所有后续的动态链接工作。
没有 .dynamic 节,动态链接就无从下手,程序将无法运行。
各字段含义详解
这是一个为 .dynamic 节准备的节头条目,我们来逐一分析它的字段:
1. s_name: .dynamic (节名称)
-
节的名称是 .dynamic,表明它包含动态链接信息。
2. s_type: SHT_DYNAMIC (6) (节类型)
-
节的类型是 SHT_DYNAMIC,专门用于存放动态链接的“键值对”数组。
3. s_flags: WRITE|ALLOC (节标志)
-
ALLOC: 必须加载到内存中。
-
WRITE: 可写。这可能看起来有点奇怪,但动态链接器有时需要在加载过程中修改 .dynamic 节中的某些条目(例如,DT_DEBUG 条目的值可能会被调试器修改以进行通信)。
4. s_addr: 0x00001EC0 和 s_offset: EC0h (内存地址与文件偏移)
-
s_addr: “动态链接总目录”在内存中的虚拟地址是 0x1EC0。
-
s_offset: 它在文件中的偏移量是 0xEC0。
5. s_size: 296 (节大小) 和 s_entsize: 8 (条目大小)
-
s_size: 整个动态链接信息表的大小是 296 字节。
-
s_entsize: 表中每个条目的大小是 8 字节 (在32位系统上)。
-
关键信息: 我们可以计算出条目数量:s_size / s_entsize = 296 / 8 = 37。
-
这意味着这个“总目录”里有 37 条键值对信息。每个键值对(Elf32_Dyn 结构)包含一个标签(tag,如 DT_NEEDED)和一个值(value,如指向 "libc.so.6" 字符串的偏移量)。
6. s_link: 3 (链接信息)
-
这是极其关键的字段。.dynamic 节中很多条目的“值”部分是字符串的偏移量(比如依赖的库名)。这个字段就告诉链接器去哪里找这些字符串。
-
对于 SHT_DYNAMIC 节,s_link 指向其关联的字符串表在节头表中的索引。
-
值为 3 意味着:要查找这个“总目录”中所有条目里用到的字符串(如 DT_NEEDED 指向的库名),需要去查阅节头表索引为 3 的那个节(也就是 .dynstr 动态字符串表)。
7. s_info: 0 (附加信息)
-
对于 SHT_DYNAMIC 节,此字段未使用,值为 0。
8. s_addralign: 4 (地址对齐)
-
此节的内存地址必须是 4 的倍数。
9. s_data[296] (节数据预览)
-
预览了构成 .dynamic 节的 296 字节原始数据。这些数据就是 37 个 Elf32_Dyn 结构体,它们共同构成了动态链接的中央枢纽。
总结
这个节头条目定义了一个包含 37 条键值对的动态链接总目录。它是动态链接器工作的起点和指南。通过解析这个节,动态链接器可以找到所有其他必要的节(如符号表、字符串表、重定位表等),了解程序的依赖关系,并最终完成将程序和其依赖库“组装”在一起的全部工作。它是所有可执行文件和共享库中实现动态链接的最核心的数据结构。
.got 和 .got.plt。它们是我们所见到的"代码"部分的"数据"对应部分(.rel.dyn
通俗精炼解释
这张图描述的是**“全局偏移量表” (.got)** 和一个与 PLT 配套的特殊部分 .got.plt 的目录信息。这些表是地址的“中转站”,是动态链接的核心数据结构。
可以这样理解:
-
.got (Global Offset Table - 全局偏移量表)
-
是什么: 一个存放外部全局变量地址的表格。当你的代码需要访问一个定义在其他库中的全局变量时,它不会直接去访问,而是先来 .got 表查一下这个变量的真实地址。
-
比喻: 就像一个**“办公室门牌号与实际位置对应表”**。你知道要找“市场部”,但不知道它在几楼几号。你先去大厅的指示牌(.got 表)上查找,“市场部” -> “3楼301室”。程序启动时,动态链接器会负责把这个指示牌上的所有条目都填写正确。
-
-
.got.plt (GOT for PLT)
-
是什么: 一个专门为 .plt(过程链接表)服务的、存放外部函数地址的表格。
-
比喻: 这是“客服首次呼叫转接”机制的核心数据板。
-
首次呼叫 : .got.plt 中 printf 对应的条目里存放的是一条“请转接总机”的指令。
-
总机找到地址后: 动态链接器会把 printf 的真实地址直接写回到 ,覆盖掉原来的“转接指令”。
-
再次呼叫 : 程序通过 .plt 跳转时,会直接从 .got.plt 中加载到 printf 的真实地址并跳转过去,实现了快速调用。
-
-
核心作用:
.got 和 .got.plt 提供了一个间接层。代码不直接引用绝对地址,而是通过引用这个表中的条目来访问外部符号。这使得动态链接器可以在程序启动时(或首次使用时)才将真实的地址填入表中,从而实现了位置无关代码 (PIC) 和懒加载。
.got 节头详解
-
s_name: .got: 节名称,全局偏移量表。
-
s_type: SHT_PROGBITS (1): 包含程序数据。
-
s_flags: WRITE|ALLOC:
-
ALLOC: 必须加载到内存。
-
WRITE: 至关重要。这个表必须是可写的,因为动态链接器需要在运行时把解析到的真实地址写入到这个表中。
-
-
s_addr: 0x00001FE8, s_offset: FE8h: 内存
-
s_size: 0: 这是一个非常有趣的点。在这里,.got 的大小显示为 0。这通常意味着在这个特定的编译单元中,没有引用需要通过 .got 解析的外部全局变量。所有的地址引用都通过 .got.plt(针对函数)或其他方式解决了。 和 ,这个条目可能只是一个占位符,实际的 GOT 内容紧跟在后面,并被计入了 .got.plt 的大小中。
.got.plt 节头详解
-
s_name: .got.plt: 节名称,为 PLT 服务的全局偏移量表。
-
s_type: SHT_PROGBITS (1): 包含程序数据。
-
s_flags: WRITE|ALLOC: 同样,必须可写,用于实现懒加载。
-
s_addr: 0x00001FE8, s_offset: FE8h: 注意,这里的地址和偏移与 这证实了它们在内存中是连续的,甚至可以看作是同一个数据块的不同逻辑部分。链接器和加载器通常将它们视为一个整体。
-
s_size: 24: 表的大小是 24 字节。
-
前 3 个条目(12字节,对于32位系统)通常有特殊用途,由动态链接器自己使用。
-
后面的条目(24 - 12 = 12 字节)对应于需要懒加载的外部函数。每个条目占 4 字节,所以 12 / 4 = 3。这与我们之前在 .rel.plt 中看到的 3 个重定位条目完全对应!
-
总结
这张图展示了实现地址无关性和动态链接的两个核心数据表:
-
.got: 用于存放外部全局变量的运行时地址。
-
.got.plt: 用于存放外部函数的运行时地址,并且是实现懒加载机制的关键。
这两个表在内存中是可写的,由动态链接器在程序启动或首次调用时填充。它们提供了一个间接寻址的“中转站”,是所有现代动态链接系统和安全机制(如 GOT an PLT hijacking)的核心目标。
通俗精炼解释
这张图描述的是程序的**“已初始化数据区”**的目录信息。
可以把它想象成一块**“出厂时就写好默认值,但随时可以擦写修改的白板”**:
-
已初始化 (Initialized): 这块“白板”在程序启动时,就已经被填上了你在代码中指定的非零初始值。例如,你写的 int global_counter = 100;,那个 100 就存放在这里。
-
可写 (Writable): 与 .rodata(只读数据区,像石碑)不同,程序在运行期间可以随时修改这块“白板”上的内容。比如,global_counter 的值可以从 100 变成 101。
它与其它数据区的区别:
-
vs. : .rodata 是只读的(常量),.data 是可读可写的。
-
vs. : .bss 是未初始化的或初始化为零的变量区(一个空的、干净的白板),而 .data 存放的是有具体非零初始值的变量。
核心作用:
存放所有已初始化的全局变量和静态变量,这些变量构成了程序的初始状态,并且可以在程序运行过程中被修改。
各字段含义详解
这是一个为 .data 节准备的节头条目,我们来逐一分析它的字段:
1. s_name: .data (节名称)
-
节的名称是 .data,这是存放已初始化可写数据的标准名称。
2. s_type: SHT_PROGBITS (1) (节类型)
-
节的类型是 SHT_PROGBITS,表明这个节包含的是由程序(编译器)定义的原始数据。在这里,就是变量的初始值。
3. s_flags: WRITE|ALLOC (节标志)
-
这是本节最关键的标志。
-
ALLOC: 必须加载到内存中。
-
WRITE: 这个标志告诉操作系统,这个内存区域是可写的。这是它与 .rodata 最根本的区别。程序可以合法地修改这部分内存中的数据。
4. s_addr: 0x00002000 和 s_offset: 1000h (内存地址与文件偏移)
-
s_addr: 此数据区在内存中的起始虚拟地址是 0x2000。
-
s_offset: 此数据在文件中的起始偏移量是 1000h (十六进制的 4096)。
-
重要观察点: 这里的内存地址和文件偏移量不同 (0x2000 vs 0x1000)。这非常常见,通常是由于内存对齐(Memory Alignment)造成的。链接器在组织最终的可执行文件时,会将不同的段(Segment)对齐到内存页(通常是 4096 字节)的边界,以提高内存管理的效率。加载器会从文件的 0x1000 处读取数据,然后将其放置到内存的 0x2000 地址。
5. s_size: 16 (节大小)
-
所有已初始化的、非零的全局/静态变量加起来总共占用了 16 字节。这可能对应着,比如说,4 个 4 字节的整数。
6. s_link: 0 和 s_info: 0 (链接与信息)
-
对于 SHT_PROGBITS 类型的节,这两个字段通常不使用。
7. s_addralign: 4 (地址对齐)
-
此节的内存地址必须是 4 的倍数。这对于保证对齐访问 4 字节的变量(如 int 或指针)至关重要。
8. s_entsize: 0 (条目大小)
-
值为 0。.data 节是一块连续的数据,而不是由固定大小的条目组成的表。
9. s_data[16] (节数据预览)
-
预览了构成 .data 节的 16 字节原始数据,即那些变量的初始值。
总结
这个节头条目定义了程序的已初始化可写数据区。它是一个大小为 16 字节的数据块,包含了程序中所有具有非零初始值的全局变量和静态变量。它的**可写(WRITE)**属性是其核心特征,允许程序在运行时动态地改变其状态。
我们已经到达了三个基本数据部分的最后一个:.bss。这一部分有一个非常有趣且重要的优化。
通俗精炼解释
这张图描述的是程序的**“未初始化数据区”**的目录信息。.bss 是 "Block Started by Symbol" 的缩写。
可以把它想象成一张**“内存预订单”**:
-
当你在代码中定义一个未初始化的全局变量(如 int global_array[1000];)或一个初始化为零的静态/全局变量(如 static int counter = 0;)时,编译器会记下:“这个程序运行时需要一块 4000 字节的内存给 global_array。”
-
但是,为了让程序文件尽可能小,它并不会在文件里真的写入 4000 个零。那太浪费磁盘空间了。
-
相反,它只是在 .bss 这张“预订单”上记下一笔:需要 X 字节的内存。
-
当程序启动时,操作系统加载器看到这张“预订单”,就会在内存里开辟一块相应大小的、干净的区域,并自动将其全部填充为零。
核心作用与区别:
-
作用: 存放所有未初始化的或初始化为零的全局变量和静态变量。
-
vs. : .data 节存放的是有具体非零初始值的变量,这些初始值必须存储在程序文件中。.bss 节的变量初始值都是零,所以不需要在文件中存储,从而极大地减小了可执行文件的大小。
各字段含义详解
这是一个为 .bss 节准备的节头条目,我们来逐一分析它的字段:
1. s_name: .bss (节名称)
-
节的名称是 .bss,这是存放未初始化可写数据的标准名称。
2. s_type: SHT_NOBITS (8) (节类型)
-
这是本节最最关键的特征。
-
SHT_NOBITS 的字面意思是“没有比特位”。它明确地告诉加载器,这个节在可执行文件中不占用任何空间。它只是一条元信息,一个占位符。
3. s_flags: WRITE|ALLOC (节标志)
-
ALLOC: 虽然在文件中没有空间,但在程序运行时,必须在内存中为它分配空间。
-
WRITE: 这块内存区域是可写的,因为它们是变量。
4. s_addr: 0x00002010 和 s_offset: 1010h (内存地址与文件偏移)
-
s_addr: 程序加载后,这块被清零的内存区域将从虚拟地址 0x2010 开始。通常,它会紧跟在 .data 节的后面。
-
s_offset: 即使节类型是 SHT_NOBITS,它仍然有一个逻辑上的文件偏移。这个偏移量通常等于前一个数据节(.data)的结束位置,但它并不指向任何实际数据。
5. s_size: 0 (节大小)
-
这是一个非常重要的观察点。这个 s_size 字段代表了 .bss 节在内存中应该占用的大小。
-
在这个具体的例子中,大小为 0。这说明这个特定的程序没有任何未初始化或零初始化的全局/静态变量。如果代码中有一个 int my_bss_var;,那么这里的 s_size 就会是 4。如果有一个 char buffer[1024];,s_size 就会是 1024。
6. s_link: 0 和 s_info: 0 (链接与信息)
-
这两个字段对于 .bss 节没有特定用途。
7. s_addralign: 1 (地址对齐)
-
此节的内存地址对齐要求是 1 字节(即无特殊对齐要求)。如果其中包含需要更严格对齐的变量(如 int),链接器会将其提升到更大的值(如 4)。
8. s_entsize: 0 (条目大小)
-
值为 0,因为它不是一个由固定大小条目组成的表。
总结
这个节头条目定义了程序的未初始化数据区。它的核心特征是 SHT_NOBITS 类型,这使得它在可执行文件中不占用空间,从而达到了优化文件大小的目的。程序加载时,操作系统会根据 s_size 字段在内存中分配一块空间,并将其内容全部清零。在这个特定的例子中,.bss 的大小为 0,表明程序中没有这类变量。
这个 .comment 部分是一个简单、信息性的部分,相当不同
通俗精炼解释
这张图描述的是程序的**“注释”或“标签”信息**的目录。
可以把它想象成一件衣服上的**“制造标签”**:
-
这个标签上写着:“制造商:GCC 编译器,版本号:11.2.0”。
-
这个信息对于衣服本身的功能(保暖、美观)完全没有影响。你穿衣服时,根本用不到这个标签。
-
但是,这个标签对于你想了解这件衣服的来源、或是厂商需要追踪产品时,却很有用。
它的核心作用是:
在可执行文件中嵌入一些元数据(Metadata),通常是用来标识编译器的版本或其他构建工具的信息。这个节不会被加载到内存中,也不会被程序执行。它纯粹是供开发者或工具(如 readelf)查看,以便了解这个文件是如何被构建出来的。
各字段含义详解
这是一个为 .comment 节准备的节头条目,我们来逐一分析它的字段:
1. s_name: .comment (节名称)
-
节的名称是 .comment,表明它包含注释信息。
2. s_type: SHT_PROGBITS (1) (节类型)
-
节的类型是 SHT_PROGBITS,表明它包含的是由程序(在这里是编译器/链接器)定义的原始数据。
3. s_flags: MERGE|STRINGS (节标志)
-
MERGE: 告诉链接器,如果多个被链接的目标文件都包含相同的注释字符串,可以只保留一份,以减小最终文件的大小。
-
STRINGS: 指明了这些可合并的数据是空字符结尾的字符串。
-
最关键的观察点: 这个标志字段缺少了 这是它与 .data, .text 等节最根本的区别。
4. s_addr: 0x00000000 (内存地址)
-
这是本节最核心的特征之一。
-
值为 0 意味着这个节不会被映射到程序的虚拟地址空间中。
-
因为它没有 ALLOC 标志,所以操作系统加载器会完全忽略这个节,不会为它分配任何运行时内存。
5. s_offset: 1010h (文件偏移)
-
这个节在可执行文件中的起始偏移量是 1010h。
-
这表明,虽然 .comment 节不占用运行时内存,但它确实占用了磁盘上的文件空间。
6. s_size: 38 (节大小)
-
这个注释节在文件中占用了 38 字节。
7. s_link: 0 和 s_info: 0 (链接与信息)
-
对于 .comment 节,这两个字段没有特定用途。
8. s_addralign: 1 (地址对齐)
-
对齐要求是 1 字节,即无特殊对齐要求。
9. s_entsize: 1 (条目大小)
-
与 STRINGS 标志相对应,指明字符串是由 1 字节的字符组成的。
10. s_data[38] (节数据预览)
-
预览了构成 .comment 节的 38 字节原始数据。如果你用工具查看这部分内容,通常会看到类似 "GCC: (GNU) 11.2.0" 这样的字符串。
总结
这个节头条目定义了一个大小为 38 字节的注释信息块。它的核心特征是不包含 ,因此它只存在于磁盘上的可执行文件中,而不会在程序运行时被加载到内存中。它的唯一作用是记录一些构建信息(如编译器版本),对程序的执行逻辑、性能和内存占用没有任何影响,是一个纯粹的、供人或工具查阅的“标签”。
.note.gnu.gold-version 部分是另一个信息性、非必要的部分,类似于 .comment,但更
通俗精炼解释
这张图描述的是一个由 GNU 留下的**“版本签名”**的目录信息。
可以把它想象成一件名贵家具上的**“工匠印记”**:
-
大多数家具可能只有个普通的“制造标签”(这好比是 .comment 节,标明了通用工具如 GCC 的版本)。
-
但如果这件家具是由一位著名的工匠(比如 链接器,一个比传统链接器 ld 更快、更新的工具)制作的,他可能会留下自己独特的印记。
-
.note.gnu.gold-version 就是这个独特的“工匠印记”。它明确地告诉我们:“这个程序文件是由 gold 链接器组装的,并且这是它的版本号。”
它的核心作用是:
纯粹是信息性的。它帮助开发者或工具识别出这个可执行文件是由 gold 链接器生成的,而不是由传统的 ld 链接器。这在排查一些与链接器行为相关的、非常微妙的 bug 时可能很有用。与 .comment 节一样,它不会被加载到内存中,对程序的运行没有任何影响。
各字段含义详解
这是一个为 .note.gnu.gold-version 节准备的节头条目,我们来逐一分析它的字段:
1. s_name: .note.gnu.gold-version (节名称)
-
节的名称非常具体:
-
.note: 表明这是一个“笔记”或“注解”节。
-
.gnu: 表明这是 GNU 工具链的一个扩展。
-
.gold-version: 明确指出内容是关于 链接器的版本信息。
-
2. s_type: SHT_NOTE (7) (节类型)
-
节的类型是 SHT_NOTE,这是一种标准的、用于存放附加信息的节类型,其内部有特定的格式(通常包含一个名称、描述符大小和描述符本身)。
3. s_flags: UNKNOWN (节标志)
-
分析工具显示为 UNKNOWN,这通常意味着标志字段的值是 0。
-
最关键的信息是:这里没有 。这意味着这个节是一个“非分配”节。
4. s_addr: 0x00000000 (内存地址)
-
这是本节的核心特征。值为 0 并且没有 ALLOC 标志,再次确认了这个节不会被操作系统加载器映射到内存中。它只存在于磁盘上的文件中。
5. s_offset: 1038h (文件偏移)
-
这个“印记”在可执行文件中的起始偏移量是 1038h。
6. s_size: 28 (节大小)
-
这个“印记”在文件中占用了 28 字节。
7. s_link: 0, s_info: 0, s_entsize: 0 (链接、信息、条目大小)
-
对于这种简单的笔记节,这些字段通常不使用,所以值为 0。
8. s_addralign: 4 (地址对齐)
-
Note 节通常要求 4 字节对齐。
9. s_data[28] (节数据预览)
-
预览了构成这个笔记节的 28 字节原始数据。其内部会包含一个名称(如 "GNU")和一个描述符(gold 链接器的版本字符串),这些二进制数据被当作文本显示时会是乱码。
总结
这个节头条目定义了一个大小为 28 字节的信息性笔记。它的核心特征是不被加载到内存(s_flags 无 ALLOC 标志,s_addr 为 0),其唯一作用是在文件中标记出生成此文件的 。这对于诊断链接器相关的特定问题非常有用,但对程序的正常执行逻辑和性能完全没有影响。
通俗精炼解释
这张图描述的是**“节名大字典”的目录信息。可以把它想象成是整本书(程序文件)的“章节标题专用字典”**。
-
我们之前看到的节头表(Section Header Table),它列出了关于每个章节(如 .text, .data)的所有信息(大小、位置等)。
-
但是,为了节省空间和保持结构清晰,总目录里并不直接写上 "text" 或 "data" 这样的章节标题。
-
取而代之的是,总目录里只记录一个“页码”,比如“标题请查阅字典第 5 页”。
-
.shstrtab 就是这本**“章节标题专用字典”**。它是一个连续的字符串列表,包含了所有章节的名称,如 .text, .data, .bss, .rodata 等等。
它的核心作用是:
作为所有节名称的中央存储库。任何需要知道节名称的地方(主要是节头表本身)都通过一个指向这个“字典”的偏移量来引用名称。这使得整个结构更加规整和高效。
各字段含义详解
这是一个为 .shstrtab 节准备的节头条目。.shstrtab 是 "Section Header String Table" 的缩写。
1. s_name: .shstrtab (节名称)
-
节的名称是 .shstrtab。有趣的是,这个节的名称本身也存储在这个节里面。
2. s_type: SHT_STRTAB (3) (节类型)
-
节的类型是 SHT_STRTAB (String Table),明确指出这个节的内容是一个字符串表。其格式就是一个个以空字符(\0)结尾的字符串连接在一起。
3. s_flags: UNKNOWN (节标志)
-
分析工具显示为 UNKNOWN,这通常意味着标志字段的值是 0。
-
最关键的信息是:这里没有 ALLOC 标志。这意味着这个节是一个“非分配”节,它不会被加载到内存中。
4. s_addr: 0x00000000 (内存地址)
-
这是本节最核心的特征。值为 0 并且没有 ALLOC 标志,再次确认了这个节不会被操作系统加载器映射到内存中。它只对需要解析文件结构的工具(如链接器、readelf、调试器)有意义。
5. s_offset: 1054h (文件偏移)
-
这个“节名大字典”在可执行文件中的起始偏移量是 1054h。当 readelf 这样的工具需要显示节名称时,它会从文件的这个位置开始读取字符串。
6. s_size: 241 (节大小)
-
整个字符串表在文件中占用了 241 字节。
7. s_link: 0 和 s_info: 0 (链接与信息)
-
对于字符串表节,这两个字段没有特定用途。
8. s_addralign: 1 (地址对齐)
-
对齐要求是 1 字节,即无特殊对齐要求,因为字符串是字节流。
9. s_entsize: 0 (条目大小)
-
值为 0。这是因为字符串表中的“条目”(即每个节名称)是可变长度的(".bss" 和 ".comment" 的长度就不同)。因此,不存在一个固定的条目大小。
10. s_data[241] (节数据预览)
-
预览了构成 .shstrtab 的 241 字节原始数据。如果你用十六进制查看器看这里,你会看到类似 \0.text\0.data\0.bss\0.rodata\0... 这样的内容,即所有节名称由空字符分隔开。
总结
这个节头条目定义了一个大小为 241 字节的节名字符串表。它的核心特征是仅存在于文件中,不占用运行时内存。它是理解 ELF 文件结构的基础,因为整个节头表都依赖它来查找并显示每个节的名称。ELF 文件头中有一个专门的字段 (e_shstrndx) 指向这个节的索引,以便工具能第一时间找到这个“字典”。
通俗精炼解释
这张图展示的是动态符号表( 中的第 0 个条目。根据 ELF(可执行与可链接格式)标准,符号表中的第一个条目是一个特殊的、保留的“空条目”。
可以把它想象成:
-
一本电话簿(符号表)的第 0 页。
-
这一页是故意留白的,上面写着“此页无效”。
-
或者,它是一个数据库表格中的**“空记录”或“NULL”条目**。
它的核心作用是:
作为一个无效的占位符。在 ELF 文件中,很多地方需要用一个索引来引用符号表中的条目。如果某个地方不需要引用任何有效符号,它就会使用索引 0。系统看到索引 0,就知道这是一个无效引用,从而避免了错误。
例如,一个没有基类的 C++ 对象的符号信息,其“基类”字段可能会引用这个索引为 0 的空符号。
各字段含义详解
这是动态符号表 symtab[0] 的详细内容:
1. dynamic_symbol_table / symtab[10] / symtab[0]
-
dynamic_symbol_table: 正在查看的是动态符号表。
-
symtab[10]: 提示这个符号表总共有 10 个条目(索引从 0 到 9)。
-
symtab[0]: 当前正在查看的是索引为 0 的第一个条目。
2. sym_name: <Undefined> / sym_name_off: 0h
-
sym_name_off: 符号名称在字符串表(.dynstr)中的偏移量。值为 0。
-
sym_name: 根据标准,字符串表中偏移量为 0 的位置是一个空字符串。因此,这个符号没有名字。分析工具将其显示为 <Undefined>。
3. sym_value: 0x00000000
-
符号的值。对于函数或变量,这通常是它们的地址。对于这个空条目,它没有值,所以为 0。
4. sym_size: 0
-
符号的大小。对于函数,是函数代码的大小;对于变量,是变量类型的大小。对于这个空条目,大小为 0。
5. sym_info: STB_LOCAL | STT_NOTYPE
-
这是一个包含了绑定信息 (Binding) 和类型信息 (Type) 的 8 位字段。
-
sym_info_bind: 绑定信息是 STB_LOCAL。这意味着这个符号是局部的,只在当前文件内部可见,不会被导出用于外部链接。
-
sym_info_type: 类型信息是 STT_NOTYPE。这意味着这个符号没有指定的类型(它既不是函数,也不是变量,也不是文件等)。
-
结合起来,STB_LOCAL | STT_NOTYPE 是一个空符号的典型特征。
6. sym_other: 0
-
一个保留字段,通常包含符号的可见性信息。对于这个空条目,值为 0。
7. sym_shndx: 0
-
Section Header Index。这个字段指明了该符号定义在哪个节中。
-
值为 0 (或 SHN_UNDEF),表示这个符号是未定义的或与任何特定的节无关。这是空条目的标准值。
总结
这张图展示了 ELF 文件中动态符号表的第一个、索引为 0 的条目。这是一个特殊用途的、内容全为零或“无”的空符号。它不代表任何实际的函数或变量,其存在的唯一目的就是作为一个保留的、无效的占位符,用于 ELF 文件中那些需要引用一个“空符号”的场景。
这是一个非常经典且核心的动态链接问题!你的观察力非常敏锐,直接命中了懒加载(Lazy Binding)机制的要害。
简单来说:文件中的值是“占位符”,而内存中的值是程序运行时由动态链接器填写的“真实地址”。
这个“从占位符到真实地址”的转变,正是动态链接和懒加载机制的精髓所在。
下面我们用一个通俗的比喻和详细的技术步骤来解释这个过程。
通俗比喻:需要时才问路的导航系统
想象一下,你的程序是一个准备出发送货的司机,.got.plt 是你的导航仪地址簿。
-
出厂设置 (文件中的值)
-
导航仪里存着三个地址:__cxa_atexit, __stack_chk_fail, __cxa_finalize。
-
但你并不知道这三个地址的具体位置,所以导航仪的出厂设置(即文件中的值,如 C6 03 00 00 -> 0x3C6)并不是最终地址。
-
它记录的其实是:“如果你要去 ”
-
这个 0x3C6 的位置,就在 .plt(过程链接表)节里,是一段专门用来“问路”的跳板代码。
-
-
第一次送货 (第一次调用函数)
-
当你的程序第一次需要调用 __cxa_atexit 时,它遵循导航仪的指示,跳转到了 0x3C6。
-
0x3C6 的代码启动了“问路”程序,它会呼叫动态链接器(相当于“导航总台”)。
-
动态链接器查找所有已加载的库(比如 libc.so),找到了 __cxa_atexit 的真实地址,假设是 0x2018。
-
-
更新导航仪 (内存中的值)
-
这是最关键的一步!动态链接器在找到真实地址 0x2018 后,会做一件事:
-
它会直接修改导航仪地址簿中 __cxa_atexit_ptr 这一项,把原来的“问路指令地址”0x3C6 覆盖成真实的送货地址 0x2018。
-
这时,如果你查看内存,就会看到 __cxa_atexit_ptr 的值变成了 18 20 00 00 -> 0x2018。
-
然后,它直接把你的车引导到 0x2018,完成第一次送货。
-
-
以后再送货 (后续调用)
-
当程序第二次需要调用 __cxa_atexit 时,它再次查看导航仪。
-
这次,地址簿里记录的已经是真实地址 !
-
于是,程序直接就开到 0x2018,不再需要经过“问路”的中间步骤,速度飞快。
-
技术细节分解
| 状态 (State) | .got.plt 中的值 (Value in .got.plt) | 含义 (Meaning) |
| 在文件中 (On Disk) | C6 03 00 00 (即 0x3C6) | 占位符地址 (Placeholder): 这是一个指向 .plt 节中对应函数“跳板代码”的指针。这段代码的唯一作用就是触发动态链接器去解析真实地址。 |
| 在内存中 (In Memory, after first call) | 18 20 00 00 (即 0x2018) | 真实函数地址 (Real Address): 这是 __cxa_atexit 函数在被加载到内存的 libc.so 中的实际入口地址。动态链接器已经找到了它,并用它覆盖了原来的占位符。 |
总结
你看到的这两个不同的值,完美地展示了**懒加载(Lazy Binding)**的全过程:
-
文件中的值 ( 是为了实现“懒”——在没用到函数之前,不花时间去查找它的地址。它是一个初始的、指向解析程序的跳板地址。
-
内存中的值 ( 是“加载”的结果——在函数第一次被调用后,动态链接器找到了真实地址,并**“热修复”**了 .got.plt 表,使其直接指向目标。
这个机制极大地加快了程序的启动速度,因为程序启动时不需要解析成百上千个可能永远不会被调用的外部函数。这是现代操作系统中一项非常重要的性能优化。
第四步分析不同指令集架构的反编译代码和他们间有什么区别
分别针对x86_64和x86(Intel 386)架构的libhello_jni.so文件的区别。
这些区别并非源于原始逻辑的改变,而是由两种CPU架构的根本性差异所决定的。下面将从几个关键维度进行详细对比,并结合代码片段进行说明。
核心区别概览
| 特性 | x86_64 (64位, x8664.txt) | x86 (32位, tset.txt) | 分析 |
| 架构 | 64位 | 32位 | 根本区别,决定了以下所有差异。 |
| 指针/地址大小 | 8字节 (64-bit) | 4字节 (32-bit) | 所有地址和指针的存储空间翻倍。 |
| 寄存器 | 64位寄存器 (RAX, RBX, RDI, RSI...),数量更多 (R8-R15) | 32位寄存器 (EAX, EBX, EDI, ESI...),数量较少 | 64位架构提供了更宽、更多的寄存器,提高了运算效率。 |
| 函数调用约定 | System V AMD64 ABI (参数优先通过寄存器传递) | cdecl (参数通过栈传递) | 这是最显著的代码行为差异之一,极大影响了函数调用的汇编实现。 |
| 位置无关代码(PIC) | RIP相对寻址 | GOT表和EBX寄存器 | 64位架构的RIP相对寻址更高效、更简洁。 |
| 栈保护机制 | 使用 FS段寄存器 (fs:28h) | 使用 GS段寄存器 (gs:14h) | 保护机制(Stack Canary)相同,但实现细节因架构而异。 |
| ELF文件格式 | ELF64 | ELF32 | 文件头、节头表、程序头表等结构中的地址和大小字段都不同。 |
1. ELF文件格式和头部信息
最直观的区别体现在文件头。
x86_64 (
Generated assembly
LOAD:00000000 dword_0 dd 464C457Fh ; File format: \x7FELF
LOAD:00000004 db 2 ; File class: 64-bit
LOAD:00000012 dw 3Eh ; Machine: x86-64
LOAD:00000020 dq 40h ; PHT file offset (8-byte pointer)
LOAD:00000036 dw 38h ; PHT entry size (64-bit size)-
File class: 2 代表64位。
-
Machine: 3Eh (62) 代表 EM_X86_64。
-
Pointers/Offsets: 使用dq (define quad-word, 8字节) 定义,例如程序头表(PHT)的偏移量。
-
Entry Size: PHT和SHT(节头表)的条目尺寸更大,以容纳64位地址。
x86 (
Generated assembly
LOAD:00000000 dword_0 dd 464C457Fh ; File format: \x7FELF
LOAD:00000004 db 1 ; File class: 32-bit
LOAD:00000012 dw 3 ; Machine: Intel 386
LOAD:0000001C dd 34h ; PHT file offset (4-byte pointer)
LOAD:0000002A dw 20h ; PHT entry size (32-bit size)-
File class: 1 代表32位。
-
Machine: 3 代表 EM_386。
-
Pointers/Offsets: 使用dd (define double-word, 4字节) 定义。
-
Entry Size: 条目尺寸更小。
2. 寄存器和寻址
x86_64
-
使用64位寄存器,如 rax, rdi, rsi, rsp。
-
拥有额外的通用寄存器 r8 到 r15。
x86
-
使用32位寄存器,如 eax, edi, esi, esp。
-
通用寄存器数量较少。
这个区别贯穿始终,所有的数据操作、地址计算都基于各自的寄存器宽度。
3. 函数调用约定 (Calling Convention)
这是最核心、最影响代码生成的区别。
x86_64: 通过寄存器传递参数
遵循 System V AMD64 ABI,前6个整数/指针参数依次放入 RDI, RSI, RDX, RCX, R8, R9 寄存器。
在JNI_OnLoad中调用RegisterNatives时:
Generated assembly
; x8664.txt
.text:0000000000000671 mov ecx, 1 ; Arg4: numMethods -> RCX
.text:0000000000000676 mov rdx, cs:nativeMethod_ptr ; Arg3: methods -> RDX
.text:000000000000067D mov rsi, rax ; Arg2: clazz -> RSI
.text:0000000000000680 mov r8, [rdi] ; JNIEnv vtable pointer
.text:0000000000000683 call qword ptr [r8+6B8h] ; Arg1 (JNIEnv*) is already in RDI可以看到,参数被直接加载到指定的寄存器中,然后执行call指令。这种方式速度快,减少了对内存(栈)的访问。
x86: 通过栈传递参数
遵循 cdecl 约定,所有参数从右到左依次压入栈中。
在JNI_OnLoad中调用RegisterNatives时:
Generated assembly
; tset.txt
.text:00000570 mov [esp+2Ch+var_20], 1 ; Arg4: numMethods on stack
.text:00000578 mov [esp+2Ch+var_24], esi ; Arg3: methods on stack
.text:0000057C mov [esp+2Ch+var_28], eax ; Arg2: clazz on stack
.text:00000580 mov [esp+2Ch+var_2C], edx ; Arg1: JNIEnv* on stack
.text:00000583 call dword ptr [ecx+35Ch] ; ecx holds JNIEnv vtable pointer参数被逐个写入到栈上的特定位置。这种方式涉及多次内存写操作,相对较慢。
4. 位置无关代码 (Position-Independent Code - PIC)
共享库必须使用PIC,因为它被加载到内存的哪个位置是不确定的。两种架构实现PIC的方式截然不同。
x86_64: RIP-相对寻址
x86_64架构引入了基于指令指针寄存器 RIP 的相对寻址模式,非常适合PIC。
Generated assembly
; x8664.txt
.text:00000000000005A0 lea rdi, off_2000 ; void *
; IDA反汇编为了可读性显示为 off_2000, 实际机器码是 lea rdi, [rip+0x1A59]
; 它直接计算当前指令地址(RIP)与目标数据地址的偏移。这种方式非常简洁高效,不需要额外的寄存器。
x86: GOT表和基址寄存器 (EBX)
x86架构没有EIP相对寻址,必须采用一种间接方式。标准做法是:
-
通过一个 call/pop 技巧获取当前代码的地址。
-
计算出全局偏移表(GOT)的基地址,并存入一个基址寄存器(通常是ebx)。
-
通过 [ebx + 偏移] 来访问全局变量或函数。
Generated assembly
; tset.txt
.text:00000511 push ebx
.text:00000512 call sub_4A0 ; 1. 调用一个紧邻的地址
.text:00000517 add ebx, (offset off_1FE8 - $) ; 2. sub_4A0返回后, ebx里是GOT地址
...
.text:00000552 lea ecx, (aGithubJp1017He - 1FE8h)[ebx] ; 3. 使用ebx作为基址访问数据sub_4A0 的实现很巧妙:
Generated assembly
; tset.txt
.text:000004A0 sub_4A0 proc near
.text:000004A0 mov ebx, [esp+0] ; 把call指令压入的返回地址(即call的下一条指令地址)存入ebx
.text:000004A3 retn这个过程比x86_64的RIP相对寻址复杂得多,并且占用了一个宝贵的通用寄存器 EBX。
5. 栈保护机制 (Stack Canary / Stack Smashing Protection)
两个版本都启用了栈保护,以防止缓冲区溢出攻击。但它们从不同的地方获取"canary"(哨兵值)。
x86_64 (
Generated assembly
; JNI_OnLoad 函数开头
.text:000000000000063A mov rax, fs:28h ; 从 fs 段寄存器偏移 0x28 处获取canary
.text:0000000000000643 mov [rsp+18h+var_10], rax ; 存入栈中
; 函数结尾
.text:000000000000068F mov rcx, [rsp+18h+var_10]
.text:0000000000000694 xor rcx, fs:28h ; 检查canary是否被修改
.text:000000000000069D jnz short loc_6A7 ; 如果不为0, 跳转到__stack_chk_fail
.text:00000000000006A7 call ___stack_chk_fail-
使用 段寄存器,偏移量为 0x28。
x86 (
Generated assembly
; JNI_OnLoad 函数开头
.text:00000529 mov esi, large gs:14h ; 从 gs 段寄存器偏移 0x14 处获取canary
.text:00000530 mov [esp+2Ch+var_10], esi ; 存入栈中
; 函数结尾
.text:0000058E mov esi, [esp+2Ch+var_10]
.text:00000592 xor esi, large gs:14h ; 检查canary是否被修改
.text:00000599 jnz short loc_5AF ; 如果不为0, 跳转到__stack_chk_fail
.text:000005AF call sub_480 ; (sub_480最终会调用__stack_chk_fail)-
使用 段寄存器,偏移量为 0x14。
总结
尽管两个文件源于同一份代码,但它们在汇编层面展现了各自架构的鲜明特点。
-
x86_64版本 体现了现代CPU设计的优势:
-
更高效:通过寄存器传参,减少内存访问。
-
更简洁:RIP相对寻址使得位置无关代码的实现非常自然。
-
能力更强:64位寄存器能处理更大的数据,更多的寄存器减少了数据换入换出的开销。
-
-
x86版本 则展示了32位时代的经典实现方式:
-
依赖栈:函数调用严重依赖栈操作。
-
复杂的PIC:需要通过 call/pop 和 GOT 表来模拟位置无关性,代码更冗长且占用寄存器。
-
通过对比这两个文件,我们可以清晰地看到从32位到64位架构演进所带来的编译器和底层实现的巨大变革。这些差异是理解底层系统和性能优化的关键所在。
它能揭示出两种CPU架构在底层设计哲学上的根本差异。x86(tset.txt)和ARM(arm.txt)的汇编代码之所以看起来如此不同,主要源于以下几个核心原因。
其中,ARM版本中大量的“中间函数”主要是由其标准化的、基于表的异常处理和栈回溯(Unwinding)机制决定的。
我们先来看一个整体对比,然后深入解释为什么ARM有这么多辅助函数。
核心区别概览
| 特性 | x86 (CISC - 复杂指令集) | ARM (RISC - 精简指令集) |
| 设计哲学 | 一条指令完成复杂操作 (如内存计算)。 | 一条指令只做一件事 (Load/Store/Compute)。 |
| 内存访问 | 很多指令可以直接操作内存。 | 典型的 Load/Store 架构,必须先将数据加载到寄存器才能计算。 |
| 指令集 | 变长指令,功能强大。 | 定长指令,简单高效。有 ARM (32位) 和 Thumb (16位) 两种模式。 |
| PIC 实现 | 复杂的 call/pop + GOT表 + ebx 基址寄存器。 | 原生支持 PC 相对寻址。 |
| 函数调用 | 参数通过栈传递 (cdecl)。 | 参数优先通过寄存器 R0-R3 传递 (AAPCS)。 |
| 异常处理 | DWARF等机制,实现相对内聚。 | ARM EABI 异常处理机制,需要大量公开的辅助函数和数据表。 |
1. CISC vs. RISC:指令的“粒度”不同
这是最根本的区别。x86作为CISC,力求用最少的指令做最多的事;ARM作为RISC,则将复杂操作分解为多条简单指令。
示例:访问一个全局变量
-
x86 (:
生成的程序集; 1. 获取GOT基址到ebx (复杂的前戏) call sub_4A0 add ebx, (offset off_1FE8 - $) ; 2. 一条指令完成“基址+偏移量”寻址 lea eax, (off_2000 - 1FE8h)[ebx]谨慎使用代码 with caution.组装虽然前戏复杂,但一旦ebx就位,lea一条指令就能完成复杂的地址计算。
-
ARM (:
生成的程序集; 1. 将PC相对偏移加载到R0 LDR R0, =(unk_4000 - 0xDE0) ; 2. 将PC值与偏移相加,得到最终地址 ADD R0, PC, R0 ; unk_4000谨慎使用代码 with caution.组装ARM将这个过程分解为两步:加载偏移、执行加法。这体现了RISC的典型特征。
2. 函数调用约定 (ABI)
-
x86: 参数被压入栈中。调用者和被调用者通过栈来沟通。
-
ARM: 前4个参数直接放入 R0, R1, R2, R3 寄存器。这大大减少了内存访问,通常更快。
示例:调用
-
x86 (:
生成的程序集mov [esp+1Ch+lpdso_handle], eax ; 参数3放到栈上 mov [esp+1Ch+obj], eax ; 参数2放到栈上 mov [esp+1Ch+lpfunc], eax ; 参数1放到栈上 call ___cxa_atexit谨慎使用代码 with caution.组装 -
ARM (:
生成的程序集MOV R1, R0 ; 准备参数2 (obj) LDR R2, =... ; 准备参数3 (dso_handle) LDR R0, =... ; 准备参数1 (func) B __cxa_atexit ; 调用谨慎使用代码 with caution.组装参数直接在寄存器 R0, R1, R2 中准备好。
3. ARM特有的Thumb指令集
ARM处理器支持两种指令集模式:
-
ARM: 32位指令,功能更全,性能更高。
-
Thumb: 16位指令,功能稍弱,但代码密度高,可以减小程序体积。
在 arm.txt 中,你可以看到 CODE32 和 CODE16 这样的伪指令,以及 BX (Branch and Exchange) 指令,它们用于在两种模式间切换。这是x86所没有的特性。
4. 核心问题:为什么ARM有这么多“中间函数”?
答案:因为ARM EABI(嵌入式应用二进制接口)标准化了一套基于数据表的异常处理和栈回溯机制。 你看到的 __aeabi_unwind_*, _Unwind_*, __gnu_unwind_* 等大量函数,都是这个机制的运行时解释器和辅助工具。
这个机制是如何工作的?
-
数据表 (
-
编译器为每一个可能抛出异常或需要回溯的函数生成一小段元数据,存储在 .ARM.exidx(Exception Index Table)节中。
-
这个表中的每条记录都指向 .ARM.extab(Exception Table)中的具体“回溯指令”。这些指令不是真正的ARM汇编,而是一套紧凑的字节码,描述了如何撤销该函数的栈帧(例如,“从SP恢复R4-R7”、“将SP增加N字节”等)。
-
-
运行时解释器
-
当一个异常被抛出时,系统的异常处理库(通常是libunwind或libgcc的一部分)开始工作。
-
它首先调用 __gnu_Unwind_Find_exidx,根据当前的PC指针在 .ARM.exidx 表中找到对应的函数条目。
-
然后,它调用核心函数 __gnu_unwind_execute (sub_1A3A)。这个函数就像一个虚拟机,它读取 .ARM.extab 中的字节码,并解释执行这些回溯指令。
-
-
大量的辅助函数
-
__gnu_unwind_execute 在解释字节码时,会调用大量的辅助函数来完成具体操作。你看到的很多函数就是这些被调用的“工具人”:
-
sub_19EC: 从字节码流中解码下一条回溯指令。
-
(: 负责从栈上恢复(Pop)一组虚拟寄存器(Virtual Register Set)。
-
(: 负责设置虚拟寄存器的值。
-
(: 恢复核心通用寄存器。
-
__aeabi_unwind_cpp_pr0/pr1/pr2: 这些被称为“个性化例程”(Personality Routines)。它们包含了特定于语言(这里是C++)的逻辑,比如在回溯时是否需要调用析构函数、如何匹配catch块等。
-
-
为什么x86版本没有这么多?
x86也需要栈回溯(例如用于C++异常),但它的实现方式不同,且通常不依赖于在ABI层面标准化的、需要大量导出辅助函数来解释的字节码。x86通常使用 DWARF 调试信息来进行栈回溯,其运行时实现更为内聚,或者说,编译器没有选择将这么多内部辅助函数作为独立的、导出的符号链接到最终的库中。
总结
ARM版本之所以看起来更复杂、函数更多,是因为它将一套通用的、标准化的、基于表的异常处理运行时直接编译并链接进了这个小小的SO库中。这套运行时本身就由许多小函数构成,负责解释回溯指令、管理寄存器状态和执行特定于语言的清理逻辑。而x86版本的编译器则采用了不同的策略,其异常处理的实现细节没有以这种方式暴露出来。
这两个文件展示了为同一个原生库 (libhello_jni.so) 针对两种不同ARM架构编译出的结果。它们在功能上是等价的,但在底层的机器码、性能和兼容性上有显著的区别。
我将从一个高层总结开始,然后进行详细的逐项对比分析。
高层总结 (TL;DR)
ABI(应用程序二进制接口)版本:
-
armv7a.txt: 这是为 armeabi-v7a ABI 编译的版本。它针对的是 ARMv7-A 架构的处理器。这是一种更现代、性能更强的架构,支持硬件浮点运算、Thumb-2指令集和NEON高级SIMD指令集。
-
arm.txt: 这是为 armeabi ABI 编译的版本。它针对的是更古老的 ARMv5TE 架构。这是Android早期支持的最基础的ARM架构,兼容性非常广,但性能较差,缺少许多现代CPU的特性。
核心区别在于:
详细对比分析
下表总结了从文件头信息中提取的关键差异:
| 特性 | armv7a.txt (armeabi-v7a) | arm.txt (armeabi) | 分析 |
| 文件路径 | ...lib\armeabi-v7a\libhello_jni.so | ...lib\armeabi\libhello_jni.so | 最直接的证据。Android通过目录名来区分不同ABI的库。 |
| 目标架构 | ARMv7 | ARMv5TE | 根本性差异。ARMv7-A是Cortex-A系列处理器的基础,而ARMv5TE是更早的ARM9系列。 |
| 输入 SHA256 | 467EC... | 7149C... | 文件内容完全不同,因此哈希值也不同。 |
| GNU 构建 ID | CD72AB... | 3AAD98... | 确认这是两次独立的编译过程,使用了不同的编译目标。 |
| 代码/数据偏移 | .text: 0xDA8 | .text: 0xDD4 | 由于生成的指令不同,代码大小和布局也不同,导致所有段和符号的地址偏移都不同。 |
| 大小 | 0x110 字节 | 0x138 字节 | 异常处理表的大小不同,反映了函数结构和数量的细微差异。 |
深入技术细节分析
1. 目标CPU架构和指令集 (最核心的区别)
-
ARMv7-A (:
-
支持Thumb-2指令集:这是ARMv7-A最重要的特性之一。Thumb-2是一个可变长度的指令集,混合了16位和32位指令。它既有Thumb指令的高代码密度(节省空间),又有ARM指令的强大功能和性能。
-
证据:在 armv7a.txt 中,我们可以看到大量带有 .W (wide) 后缀的指令,如 PUSH.W, LDR.W, ADD.W。这些都是32位的Thumb-2指令,提供了更强的寻址能力和操作。例如,在sub_E76中:
-
支持硬件浮点运算 (VFP) 和 NEON:虽然这个简单的库可能没用到,但编译器可以生成利用这些硬件单元的指令,极大地提升数学和多媒体运算性能。
-
-
ARMv5TE (:
-
只支持ARM (32位定长) 和 Thumb-1 (16位定长) 指令集。编译器必须在这两者之间切换(通过BX指令)来平衡性能和代码大小。它没有Thumb-2那种无缝混合的能力。
-
证据:在 arm.txt 中,你看不到任何 .W 后缀的指令。函数要么是纯ARM指令(CODE32),要么是纯Thumb-1指令(CODE16)。例如,在 sub_EBA (功能上对应 armv7a.txt 的 sub_E76) 中:
这里的 PUSH 是一个标准的16位Thumb指令或32位ARM指令,一次能压入的寄存器范围有限。
-
2. 代码生成的效率和复杂性
由于指令集不同,编译器为完成相同逻辑生成的代码也不同。ARMv7-A的版本通常更简洁、更高效。
示例:
-
ARMv7-A 版本 (
Generated assembly.text:00000E32 LDR R3, [R0] .text:00000E34 LDR.W R5, [R3,#0x35C] ; 直接通过偏移量加载函数指针 .text:00000E38 MOVS R3, #1 .text:00000E3A BLX R5 ; 调用 RegisterNativesUse code with caution.Assembly这里使用 LDR.W 指令,它可以支持一个较大的立即数偏移量 (0x35C),直接从JNIEnv指针(在R3中)找到 RegisterNatives 函数的地址。
-
ARMv5TE 版本 (
Generated assembly.text:00000E66 MOVS R3, #0xD7 ; 加载偏移量的高位部分 .text:00000E6E LSLS R3, R3, #2 ; 计算实际偏移量 (0xD7 * 4 = 0x35C) .text:00000E70 LDR R5, [R0] ; R0是JNIEnv* .text:00000E76 LDR R5, [R5,R3] ; 通过基址+偏移量加载函数指针 .text:00000E78 MOVS R3, #1 .text:00000E7A BLX R5 ; 调用 RegisterNativesUse code with caution.Assembly这里因为Thumb-1的 LDR 指令无法处理大的立即数偏移,编译器必须用多条指令(MOVS, LSLS, LDR)来模拟这个操作。这显然比ARMv7-A的版本更慢,也更占用空间。
3. Switch-Case 的实现
-
ARMv7-A 版本 (
Generated assembly使用了 TBB.W (Table Branch Byte, Wide) 指令,这是一种高效的、基于跳转表的实现方式,专门用于switch-case语句。
-
ARMv5TE 版本 (
Generated assembly它调用了一个名为 __gnu_thumb1_case_uqi 的辅助函数。这是一个由编译器生成的工具函数,用来在不支持 TBB 指令的旧架构上模拟跳转表。这个过程比直接使用硬件指令要慢得多。
4. 函数调用和栈操作
-
ARMv7-A 版本: 频繁使用 PUSH.W/POP.W,可以一次性操作更多寄存器,包括LR。
-
ARMv5TE 版本: 使用 PUSH/POP,功能相对简单。在ARM模式下,甚至会使用 STMFD SP!, {...} 和 LDMFD SP!, {...} 这种更传统的栈操作指令。
结论与实际意义
这两个文件完美地展示了Android的ABI兼容策略。当你在Android项目中包含C/C++代码时,构建系统(如Gradle配合NDK)会为多个目标ABI生成不同的 .so 文件。
-
(: 会被安装在拥有ARMv7-A或更高版本CPU的设备上(现在绝大多数Android设备都属于此类)。这些设备可以运行利用Thumb-2等现代特性的、性能更高的代码。
-
(: 会被安装在非常老旧的、只支持ARMv5TE的设备上。虽然这些设备现在已经很少见了,但为了最大化兼容性,开发者有时仍会选择构建这个版本。
总而言之,这两个文件的区别是编译目标不同导致的。 它们在指令集、代码效率、性能和底层实现细节上存在着根本性的差异。
arm64.txt (AArch64) 中的函数数量远少于 armv7a.txt,其根本原因在于两者采用了完全不同的异常处理(Exception Handling)和栈回溯(Stack Unwinding)机制。
简而言之:ARMv7-A 依赖于大量编译到程序中的小型辅助函数来处理异常,而 AArch64 则采用了一种更现代、更标准化的、基于元数据(metadata)的方法,将这些功能交给了操作系统或C++运行时库中的通用回溯器来处理。
下面我们来详细分解这个原因:
1. ARMv7-A 的异常处理机制 (EABI)
在 armv7a.txt 中,你看到了大量以 __gnu_Unwind_、_Unwind_ 和 __aeabi_ 开头的函数,例如:
-
__gnu_Unwind_Save_VFP_D
-
__gnu_Unwind_Restore_VFP_D_16_to_31
-
__gnu_Unwind_Save_WMMXD
-
_Unwind_VRS_Pop
-
restore_core_regs
这些函数是做什么的呢?
-
EABI(嵌入式应用程序二进制接口)异常处理机制。它依赖于 .ARM.exidx 和 .ARM.extab 这两个特殊段
-
实现方式: 当异常(比如 C++ 的 throw)发生时,系统需要“回溯”调用栈,找到合适的 catch 块。为了做到这一点,它需要知道每个函数是如何修改栈指针以及保存了哪些寄存器的。
-
辅助函数: .ARM.exidx 表中包含了一系列紧凑的回溯指令(Unwinding Instructions)。这些指令非常简单,但对于复杂的操作(比如保存/恢复大量的浮点寄存器或SIMD寄存器),它们并不会自己执行,而是会调用一个预定义的辅助函数来完成。
这就是为什么 编译器在编译代码时,如果发现一个函数需要保存VFP(浮点)寄存器,它就会在异常处理表中生成一条指令,该指令指向 __gnu_Unwind_Save_VFP 这样的函数。这个函数必须被链接到最终的二进制文件中。不同的寄存器组合(VFP, WMMX, VFP_D_16_to_31 等)都需要各自独立的、专门的保存和恢复函数。
简单来说,ARMv7-A 的做法是“把工具随身带”——每个程序都内置了一套完整的、用于处理各种寄存器组合的工具函数。
2. AArch64 (ARMv8-A) 的异常处理机制 (DWARF-based)
在 arm64.txt 中,上述那些 __gnu_Unwind_... 函数几乎全部消失了。这是因为 AArch64 采用了更加标准化和强大的机制。
-
机制: AArch64 使用基于 DWARF 标准的异常处理框架。这个框架在很多其他架构(包括 x86-64)上也是标准。相关信息存储在 .eh_frame 和 .eh_frame_hdr 段中。
-
实现方式: 编译器不再生成指向具体辅助函数的指令,而是生成更详细的元数据(Metadata),这些元数据描述了栈帧的布局。它会精确地说明:
-
栈指针相对于函数入口移动了多少。
-
X30 (链接寄存器) 保存在栈的哪个位置。
-
X19-X29 这些被调用者保存的寄存器保存在栈的哪个位置。
-
浮点/SIMD寄存器保存在哪里。
-
-
通用回溯器: 当异常发生时,一个通用的系统级回溯器(通常在 libunwind 或类似的库中)会解析 .eh_frame 中的这些元数据。这个回溯器本身就包含了所有必要的逻辑,知道如何根据这些描述来恢复所有类型的寄存器,而不需要程序本身提供这些辅助函数。
简单来说,AArch64 的做法是“提供一份详细的说明书”——程序只提供描述如何恢复状态的元数据(
类比
-
ARMv7-A: 就像宜家给你发了一套家具零件,同时还给你配齐了所有专用工具(螺丝刀、扳手等,对应 __gnu_Unwind_... 函数)。你的包裹里既有零件又有工具。
-
AArch64: 就像宜家只给你发了一套家具零件,但附带了一份极其详细的通用组装说明书(对应 .eh_frame 元数据)。它相信你家里已经有了一套标准工具箱(对应系统回溯器),你可以看着说明书自己完成所有组装工作。
总结
| 对比项 | ARMv7-A (armv7a.txt) | AArch64 (arm64.txt) |
| 异常处理机制 | EABI 异常处理 | 基于 DWARF 的异常处理 |
| 核心数据段 | .ARM.exidx, .ARM.extab | .eh_frame, .eh_frame_hdr |
| 实现方法 | 通过回溯指令调用二进制文件中内嵌的辅助函数 | 通过元数据指导一个通用的系统回溯器 |
| 结果 | 二进制文件包含大量 __gnu_Unwind_... 等专用函数 | 二进制文件几乎不包含这些辅助函数,代码更干净 |
因此,arm64 版本中函数的减少,并不是功能的缺失,而是架构设计上的一次巨大进步。它将复杂的异常处理逻辑从每个应用程序中剥离出来,集中到系统库中,使得应用程序的二进制文件更小、更简洁,也更符合现代软件工程的模块化和标准化思想。
因为mips已经被淘汰这里简单分析
高层总结 (TL;DR)
这三个文件是同一个 JNI 库为三种不同 CPU 架构编译的版本,每种都有其独特的特性:
-
(: 32位 ARMv7-A 架构。现代32位移动设备的主流,使用 Thumb-2 可变长度指令集。
-
(: 32位 MIPS32 架构。一种经典的 RISC 架构,常见于嵌入式设备、路由器和一些早期的 Android 设备。
-
mips64.txt (mips64): 64 位 MIPS64 架构。
核心区别:
-
ARM vs MIPS: 这是两个完全不同的指令集家族。MIPS 以其简洁、规整的指令格式和“指令延迟槽”而闻名。
-
32位 vs 64位: 与 ARMv7/ARM64 的对比类似,MIPS/MIPS64 的主要区别在于寄存器宽度、地址空间大小和函数调用约定。
详细对比分析
下表总结了从文件头信息中提取的关键差异:
| 特性 | armv7a.txt (armeabi-v7a) | mips.txt (mips) | mips64.txt (mips64) |
| 文件路径 | ...lib\armeabi-v7a\ | ...lib\mips\ | ...lib\mips64\ |
| 架构 | ARMv7 | MIPS | MIPS64 |
| 文件格式 | ELF 32 位 | ELF 32- | ELF 64 位 |
| 机器类型 | ARM | MIPS | MIPS |
| ABI | aapcs | o32-cpic | n64-cpic |
| 指针/字长 | 32位 (4字节) | 32位 (4字节) | 64位 (8字节) |
| 指令集 | ARM / Thumb-2 | MIPS32 | MIPS64 (MIPS64r6) |
| 寄存器 | 16个 32位 GPRs | 32个 32位 GPRs | 32个 64位 GPRs |
| 关键特性 | Thumb-2, VFP/NEON | 指令延迟槽, $gp | 指令延迟槽, $gp, 64位操作 |
深入技术细节分析
1. 架构与指令集:ARM vs MIPS
这是最根本的区别。
-
ARMv7-A:
-
可变长度指令集 (Thumb-2): 混合使用16位和32位指令,代码密度高。
-
条件执行: 很多指令可以带条件码后缀(如 MOVEQ),减少分支。
-
无延迟槽: 分支指令执行后,下一条指令就是目标地址的指令。
-
-
MIPS (32-bit & 64-bit):
-
定长指令集: 所有指令都是32位宽,非常规整,易于CPU流水线处理。
-
指令延迟槽 (Branch Delay Slot): 这是MIPS最著名的特性。在跳转或分支指令之后的那条指令,总是在跳转发生之前被执行。这是早期RISC设计为了解决流水线暂停问题而采用的策略。
-
证据 (:
.text:00000560 jr $t9 ; __cxa_finalize .text:00000564 la $a0, _fdata # 这条指令在跳转前执行Use code with caution.Assembly这里的 la $a0, _fdata 指令位于 jr $t9 的延迟槽中。它会在程序跳转到 __cxa_finalize 之前被执行。
-
证据 (:
.text:000000000000096C jalr $t9 ; __cxa_finalize .text:0000000000000970 dla $a0, _fdata # 这条指令在跳转前执行Use code with caution.Assembly同样的概念,只是指令变成了64位版本。现代MIPS架构(如MIPS64r6)已经可以消除延迟槽,但为了兼容性,编译器仍然可能会生成它。
-
-
没有专用的状态寄存器: MIPS不像ARM那样有一个CPSR/APSR寄存器来存储标志位(零、负、进位等)。条件分支通常由 beq (Branch if Equal), bne (Branch if Not Equal) 等指令直接完成。
-
2. 寄存器与数据宽度:MIPS32 vs MIPS64
-
MIPS32 (:
-
有32个32位的通用寄存器 ($zero, $at, $v0-v1, $a0-a3, $t0-t9, $s0-s7, $k0-k1, $gp, $sp, $fp, $ra)。
-
指令操作的是32位数据,例如 lw (Load Word), sw (Store Word), addiu (Add Immediate Unsigned)。
-
-
MIPS64 (:
-
同样是32个通用寄存器,但它们现在是 64位宽。
-
指令操作的是64位数据,指令助记符通常会加上一个 d (doubleword) 前缀,例如 ld (Load Doubleword), sd (Store Doubleword), daddiu (Doubleword Add Immediate Unsigned)。
-
指针和地址都是64位的,所以ELF格式也变成了 ELF64。
-
3. 函数调用约定:O32 vs N64
-
MIPS O32 ABI (:
-
参数传递: 前 4 个整型/指针参数通过 $a0, $a1, $a2, $a3 传递。
-
栈操作: 使用32位指令,如 sw $ra, offset($sp) 保存32位的返回地址。
-
-
MIPS64 N64 ABI (:
-
参数传递: 前 8 个整型/指针参数通过 $a0 到 $a7 传递。这和AArch64一样,更多的寄存器参数传递可以显著提升性能。
-
栈操作: 使用64位指令,如 sd $ra, offset($sp) 保存64位的返回地址。
-
4. 位置无关代码 (PIC) 与全局指针 ($gp)
MIPS在实现共享库时,非常依赖 $gp (Global Pointer) 寄存器来高效地访问全局数据。
-
机制: 编译器会将所有需要重定位的小数据项(全局变量、静态变量地址等)集中存放在一个称为 (Global Offset Table) 的表中。在程序加载时,动态链接器会填充这个表。代码通过 $gp 寄存器(它指向.got表的中间位置)加上一个固定的短偏移来访问这些数据。
-
的初始化:
-
MIPS32 (:
.text:000005F0 li $gp, (off_11020+0x7FF0 - .) .text:000005F8 addu $gp, $t9Use code with caution.Assembly$t9 寄存器在MIPS调用约定中用于函数间调用,这里它保存了函数的地址。这两条指令利用当前PC值来计算出 $gp 的正确值。
-
MIPS64 (:
.text:0000000000000958 lui $gp, 2 .text:000000000000095C daddu $gp, $t9 .text:0000000000000964 daddiu $gp, -0x7930Use code with caution.Assembly64位下的 $gp 初始化更复杂,需要多条指令来构建64位的地址。但其原理是一样的:计算一个指向数据段特定区域的绝对地址。
-
这与 ARM 的 PC 相对寻址 (
结论
-
ARMv7a vs MIPS32: 两者都是32位架构,但指令集设计理念不同。ARMv7a 的 Thumb-2 指令集代码密度更高,而 MIPS32 的定长指令和延迟槽设计追求流水线效率。
-
MIPS32 vs MIPS64: 这是一个典型的32位到64位的升级。主要体现在:
-
数据通路加倍:寄存器和地址总线变为64位。
-
指令升级:增加了操作64位数据的 d* 系列指令。
-
调用约定优化:传递参数的寄存器从4个增加到8个,减少了栈的使用。
-
-
ARM64 vs MIPS64: 两者都是现代64位RISC架构,但仍保留了各自的特色。ARM64废除了条件执行和延迟槽,设计更现代;而MIPS64仍然保留了MIPS的经典设计(如延迟槽和对$gp的重度依赖),同时在其最新的r6版本中也引入了许多现代化改进。
总而言之,这三个文件展示了移动平台CPU架构的多样性,从主流的32/64位ARM到更小众但同样重要的MIPS世界。
它触及了ARM架构演进、ABI(应用程序二进制接口)设计以及编译链接工具链的底层工作原理。
我们来分步解答这个问题:
1. 为什么ARMv5 (AArch32) 会将异常处理信息“写入代码”?
首先,做一个小小的修正:异常处理信息并不是直接写入可执行的机器码(code)中,而是存放在一个紧邻代码段(.text)的、专门的数据段里。在IDA等反汇编工具中,由于它们物理上相邻,所以看起来像是“和代码在一起”。这两个关键的数据段是:
-
.ARM.exidx (异常索引表): 异常索引表。
-
.ARM.extab(异常表): 异常处理表。
核心原因:ARM EABI(异常处理应用程序二进制接口)的设计哲学
ARMv5/v7(即AArch32架构)的异常处理机制是其ABI的一部分,被称为 ARM EHABI。它的设计目标是在资源受限的嵌入式设备上做到极致的紧凑和高效。
-
紧凑性 (Compactness):
-
.ARM.exidx 为每个需要栈回溯的函数都创建一个8字节的条目。这个表是根据函数的地址排序的,所以可以通过二分查找快速定位。
-
这个8字节的条目包含了回溯此函数栈帧所需的所有信息,通常是一系列紧凑的字节码指令。例如,0xB0 ( finish )、0x80 0x80 ( pop {r4-r7, pc} ) 等。
-
对于简单的函数,这些字节码指令可以直接编码在8字节的条目内。对于复杂的函数(比如需要调用清理代码的),条目会包含一个指向 .ARM.extab 中更详细表的指针。
-
这种设计极大地节省了空间,因为大多数函数的栈回溯操作都很简单。
-
-
为什么靠近代码段 (
-
逻辑关联性: .ARM.exidx 表的内容与 .text 段中的函数一一对应且紧密相关。链接器在生成最终可执行文件时,将逻辑上相关的段放在一起是很自然的行为。
-
链接器效率: 链接器需要知道每个函数的起始地址来创建 .ARM.exidx 表。将它们放在一起可以简化链接过程。
-
运行时效率: 当异常发生时,运行时(unwinder)需要快速查找当前PC地址对应的函数及其回溯信息。如果 .text 和 .ARM.exidx 在内存中相距很远,可能会导致额外的缓存未命中或页错误,影响性能。
-
2. 为什么ARM64 (AArch64) 不会这样做?
AArch64采用了完全不同的异常处理和栈回溯机制,它基于 DWARF (Debugging With Attributed Record Formats) 标准。
-
标准化 (Standardization):
-
DWARF是一个通用的、跨平台的调试信息和栈回溯格式标准。它不仅仅用于ARM,也被x86-64、RISC-V等许多架构使用。采用DWARF使得工具链(GCC, Clang, GDB等)的实现更加统一和标准化。
-
-
独立的、更详细的数据段:
-
DWARF将回溯信息存储在 .eh_frame 和 .eh_frame_hdr 这两个专门的段中。
-
.eh_frame 的格式比ARM EHABI复杂得多,它不依赖于紧凑的字节码,而是使用一种更详细、更具描述性的表格化指令(CFA - Canonical Frame Address 指令)。
-
这种格式虽然占用的空间更大,但功能更强大,能够描述非常复杂的栈帧布局。
-
-
设计目标不同:
-
AArch64是为高性能计算设计的,内存大小和带宽不再是像ARMv5时代那样极为苛刻的限制。因此,设计上优先考虑的是标准化、功能强大和可扩展性,而不是极致的空间紧凑性。
-
由于 .eh_frame 是一个独立的、自成体系的段,链接器没有必要非得把它放在 .text 旁边。它通常被视为一种元数据(metadata),和其他元数据段放在一起。
-
总结对比:
| 特性 | ARMv5 (AArch32) | ARM64 (AArch64) |
| 机制名称 | ARM EHABI | DWARF |
| 关键段 | .ARM.exidx, .ARM.extab | .eh_frame, .eh_frame_hdr |
| 数据格式 | 紧凑的自定义字节码 | 标准化的、更详细的CFA指令表 |
| 设计哲学 | 空间效率优先,为嵌入式优化 | 标准化和功能性优先,适应高性能计算 |
| 典型布局 | 通常紧邻 .text 段 | 作为一个独立的元数据段 |
3. 对于ARMv5,我能不能强制将异常信息写入独立的段中?
答案是:可以的。
你可以通过自定义 链接器脚本 (Linker Script) 来实现这一点。链接器脚本是一个配置文件,它告诉链接器(ld)如何将输入文件(.o 文件)中的各个段(section)组合成最终输出文件(如 .so 或可执行文件)中的段。
如何操作:
-
创建一个链接器脚本文件,例如 my_linker.ld。
-
在脚本中,你可以定义输出文件的段布局。你可以创建一个新的段,比如 .my_exceptions,并显式地告诉链接器把所有输入文件中的 .ARM.exidx 和 .ARM.extab 放入这个新段。
示例链接器脚本 (
生成 ld
/* 默认的GNU ld脚本内容可以在 `ld --verbose` 中找到 */
SECTIONS
{
/* ... 其他段的定义,如 .text, .data, .bss ... */
.text :
{
*(.text .text.* .gnu.linkonce.t.*)
}
/* ... 其他段 ... */
/* 在这里定义一个独立的异常段 */
. = ALIGN(4);
.my_exceptions :
{
__ex_start = .; /* 定义一个符号标记段的开始 */
KEEP(*(.ARM.exidx*))
KEEP(*(.ARM.extab*))
__ex_end = .; /* 定义一个符号标记段的结束 */
}
/* ... 其他段 ... */
}-
在编译链接时使用这个脚本。在使用GCC或Clang时,通过 -T 选项指定链接器脚本:
生成的 bash
重要警告和注意事项:
-
破坏ABI约定: 虽然你可以移动这些段,但这可能会破坏标准的ARM EABI约定。运行时的异常处理器(unwinder),无论是库里的还是系统里的,都期望在标准的位置找到 .ARM.exidx 段。
-
运行时可能失效: 如果你移动了这些段,标准的异常处理机制很可能会失效,导致 try...catch、throw 以及其他依赖栈回溯的功能(如性能分析、调试)无法正常工作。
-
需要自定义加载器/运行时: 要想让移动后的异常段正常工作,你可能需要提供一个自定义的异常处理运行时,该运行时知道去你指定的 .my_exceptions 段查找信息。这通常是非常复杂且不推荐的做法。
结论: 从技术上讲,你可以通过链接器脚本强制改变ARMv5异常处理信息段的位置。但从实践上讲,除非你有非常特殊的需求(比如在特定类型的内存中加载这些信息)并且准备好处理随之而来的兼容性问题,否则强烈建议遵循标准的段布局。默认行为是经过精心设计的,能确保最大的兼容性和正确性。
我们发现下x86 64的代码更加简洁现代
第五步比较不同反编译工具之间的差异

 浙公网安备 33010602011771号
浙公网安备 33010602011771号