

软件逆向 --- 修改安卓so
要想修改so是一件非常困难的事情,目前没有类似工具,下面只是实现思路,具体实现方法正在尝试。一个可靠的方法等价替换,我们将所有函数的是输出和输入进行模拟可以实现替换原有so文件
方法一:十六进制编辑(直接字节修改法)
这是最直接但也是最危险的方法。它相当于用记事本打开一个程序,直接修改它的机器码。
-
适用场景:
-
进行极微小的修改,例如将一个条件跳转指令反转(如
BNE改为BEQ)。 -
将某些指令“抹掉”(用
NOP指令覆盖)。 -
你已经精确知道要修改的字节和替换后的字节。
-
-
优点: 快速、直接,不需要复杂的工具链。
-
缺点:
-
极易出错,一个字节的错误就可能导致整个程序崩溃。
-
无法增加或减少代码,因为这会破坏文件中所有的地址引用。
-
需要你手动计算或查询指令对应的机器码(Opcode)。
-
-
所需工具:
-
反汇编器: IDA Pro, Ghidra, Cutter/Radare2 (用于定位代码)。
-
十六进制编辑器: HxD (Windows), 010 Editor (跨平台), Hex Fiend (macOS)。
-
操作步骤:
-
定位代码:
-
使用 IDA Pro 或 Ghidra 打开你的
.so文件。 -
在反汇编视图中,找到你想要修改的函数和指令。
-
记下这条指令的 虚拟地址(Virtual Address, VA)。例如,地址是
00008D54。
<p align="center">图:在 IDA Pro 中找到指令地址</p>
-
-
计算文件偏移(File Offset):
-
程序在内存中的地址(VA)和在文件中的地址(Offset)通常是不同的。你需要将 VA 转换成文件偏移量才能在 Hex 编辑器中定位。
-
最简单的方法是在 IDA Pro 的 "Hex View" 窗口中,右键点击 VA 地址,选择 "Jump to file offset",IDA 会自动帮你跳转。
-
手动计算公式通常是:
File Offset = VA - ImageBase - SectionVA + SectionRawOffset。对于初学者,使用工具自动转换更可靠。
-
-
获取原始和目标机器码:
-
在 IDA Pro 中,切换到 Hex View,你可以看到
00008D54地址对应的机器码字节。假设你想修改的指令是CMP R0, #1,它的机器码可能是38 28。 -
假设你想把它改成
MOV R0, #1,你需要知道这条新指令的机器码。你可以通过 IDA 的汇编功能(Edit -> Patch program -> Assemble)输入新指令,IDA 会告诉你对应的机器码,或者使用在线 ARM 转换工具。假设MOV R0, #1的机器码是01 20。
-
-
执行修改:
-
用 HxD 或其他十六进制编辑器打开
.so文件。 -
跳转到你计算出的文件偏移量。
-
你会看到原始的字节序列(例如
38 28)。 -
直接用键盘输入新的字节(
01 20)来覆盖它。 -
保存文件。
-
-
测试:
-
将修改后的
.so文件放回 APK,重新打包、签名,然后安装测试。
-
方法二:使用 IDA/Ghidra 直接 Patch(推荐方法)
这是最常用且相对安全的方法,利用强大工具的内置功能来修改汇编代码。
-
适用场景:
-
修改现有指令。
-
进行小范围的代码逻辑变更。
-
比方法一更安全,因为工具会帮你处理机器码转换。
-
-
优点:
-
所见即所得,直接在汇编代码上修改。
-
工具自动完成汇编到机器码的转换。
-
不易犯低级错误。
-
-
缺点:
-
同样不适合增加或删除代码,本质上还是原地替换。
-
-
所需工具:
-
IDA Pro (带有 Hex-Rays 反编译器更佳)
-
Ghidra (免费且强大的替代品)
-
操作步骤 (以 IDA Pro 为例):
-
定位代码:
-
用 IDA Pro 打开
.so文件,等待分析完成。 -
导航到你想要修改的汇编指令。
-
-
进行 Patch:
-
将光标定位到要修改的指令行。
-
点击菜单
Edit -> Patch program -> Assemble。 -
会弹出一个对话框,里面显示了当前的汇编指令。
-
在对话框中输入你的新汇编指令,例如将
BNE loc_12345修改为BEQ loc_12345或者NOP。 -
点击 "OK",IDA 会自动用新指令的机器码替换旧的。被修改的代码行会以不同颜色高亮显示。
<p align="center">图:使用 IDA 的 Assemble 功能进行 Patch</p>
-
-
保存修改:
-
仅仅在 IDA 数据库里修改是不够的,你需要将更改应用到原始文件。
-
点击菜单
Edit -> Patch program -> Apply patches to input file...。 -
选择创建备份或直接覆盖原文件。
-
保存后,你的
.so文件就已经被修改了。
-
-
测试:
-
将修改后的
.so文件放回 APK,重新打包、签名并测试。
-
方法三:代码注入(Code Cave / 代码洞注入法)
当你需要增加代码时,上述方法就不再适用。你需要找到一块“空地”来存放你的新代码,然后让原始代码跳转过来执行。
-
适用场景:
-
需要增加新的功能逻辑,而不仅仅是修改。
-
原始函数空间太小,无法在原地完成修改。
-
-
优点:
-
可以实现复杂逻辑的添加。
-
-
缺点:
-
技术上最复杂,需要对 ELF 文件格式和 ARM 汇编有深入理解。
-
寻找和利用代码洞需要技巧。
-
-
所需工具:
-
IDA Pro / Ghidra
-
ARM 汇编器 (如
keystone-engine) -
十六进制编辑器
-
操作步骤:
-
寻找代码洞 (Code Cave):
-
代码洞是文件中一块连续的、未被使用的、且有执行权限的区域。通常是一长串
00字节。 -
在 IDA 中,你可以滚动寻找
.text段末尾或其他段中的大片00区域。记下这个洞的起始地址。
-
-
编写并汇编你的新代码 (Payload):
-
用 ARM 汇编写出你想要添加的功能。例如,一段打印日志或修改寄存器值的代码。
-
关键: 在你的新代码执行完毕后,必须包含两部分: a. 执行被你覆盖掉的原始指令。 b. 一个无条件跳转,跳回到原始代码中被覆盖指令的下一条指令,以确保程序能继续正常执行。
-
使用
keystone这样的库或在线工具,将你的汇编代码转换成十六进制机器码。
-
-
注入 Payload:
-
使用十六进制编辑器或 IDA 的 Patch 功能,将你生成的机器码写入之前找到的代码洞中。
-
-
创建跳转 (Hook):
-
回到你想要修改的原始代码位置。
-
用一条跳转指令(例如
B <代码洞地址>或BL <代码洞地址>)覆盖掉原始的一条或几条指令。B是简单跳转,BL是带链接的跳转(会把返回地址存入LR寄存器),根据需要选择。 -
注意: 你覆盖的原始指令必须被记录下来,并在你的 Payload 中重新执行。
-
-
保存与测试:
-
保存所有修改,打包 APK 并进行严格测试。这个过程非常容易出错。
-
方法四:使用 Hook 框架(运行时修改法)
这是一种动态修改方法,它不直接修改磁盘上的 .so 文件,而是在程序运行时,在内存中修改代码逻辑。
-
适用场景:
-
开发非侵入性的 MOD 或插件。
-
需要进行复杂的逻辑注入,甚至用 C++ 或 Java/Kotlin 来实现新逻辑。
-
不想破坏原始 APK 的签名。
-
-
优点:
-
极其灵活和强大,可以在运行时动态开启或关闭。
-
无需关心文件偏移、代码洞等静态修改的麻烦事。
-
可以用高级语言编写 Hook 逻辑。
-
-
缺点:
-
通常需要 Root 权限或一个特殊的运行环境 (如 VirtualXposed)。
-
配置和环境设置相对复杂。
-
-
所需工具:
-
Frida: 当今最流行、最强大的动态插桩(Hook)框架。
-
Xposed / EdXposed / LSPosed: 经典的 ART Hook 框架。
-
操作思路 (以 Frida 为例):
-
环境准备:
-
在你的电脑上安装 Frida 工具 (
pip install frida-tools)。 -
在你的 Root 过的安卓设备或模拟器上运行
frida-server。
-
-
编写 Hook 脚本 (JavaScript):
-
你将在电脑上编写一个 JS 脚本来定义 Hook 逻辑。
-
首先,获取目标
.so模块的基地址。 -
然后,使用
Interceptor.attach来 Hook 目标函数的地址(基地址 + 函数偏移)。 -
在
onEnter回调中,你可以读取或修改传入函数的参数(存放在r0-r3等寄存器中)。 -
在
onLeave回调中,你可以读取或修改函数的返回值(存放在r0寄存器中)。 -
你甚至可以用
Interceptor.replace完全替换掉一个原生函数,用你自己的 JS 或 C 代码实现。
// 示例 Frida 脚本 // frida -U -f com.example.app -l hook.js Interceptor.attach(Module.findExportByName("libtarget.so", "Java_com_example_MainActivity_stringFromJNI"), { onEnter: function(args) { // args[0] 是 JNIEnv*, args[1] 是 jobject console.log("Hooked function entered!"); }, onLeave: function(retval) { console.log("Original return value: " + retval); // 修改返回值 // retval.replace(ptr(new_string_address)); // 替换为一个新的 jstring console.log("Return value modified!"); } }); -
-
执行 Hook:
-
在电脑上运行命令,将脚本注入到目标 App 进程中。Frida 会自动处理内存的修改。
-
总结对比
|
方法 |
难度 |
适用场景 |
能否增/删代码? |
优点 |
缺点 |
|---|---|---|---|---|---|
|
十六进制编辑 |
★★★☆☆ |
极微小修改 (NOP, 改标志位) |
否 |
快速直接 |
极易出错,功能有限 |
|
IDA/Ghidra Patch |
★★☆☆☆ |
修改指令、改变逻辑分支 |
否 |
安全、直观、常用 |
无法增加代码 |
|
代码洞注入 |
★★★★★ |
增加新功能、复杂逻辑 |
是 |
功能强大,静态永久 |
极其复杂,易出错 |
|
Hook 框架 |
★★★★☆ |
动态分析、插件开发、复杂注入 |
是 (在内存中) |
极其灵活,可逆 |
需要 Root,环境复杂 |
对于初学者,强烈建议从 方法二:使用 IDA/Ghidra 直接 Patch 开始练习。当你需要增加代码时,再深入研究 方法三 和 方法四。
具体讨论一下为什么我们不能直接嵌入汇编代码
比如我在两个代码只有一个字符串不一样,几乎每个地方都会轻微发生变化,主要影响的是地址
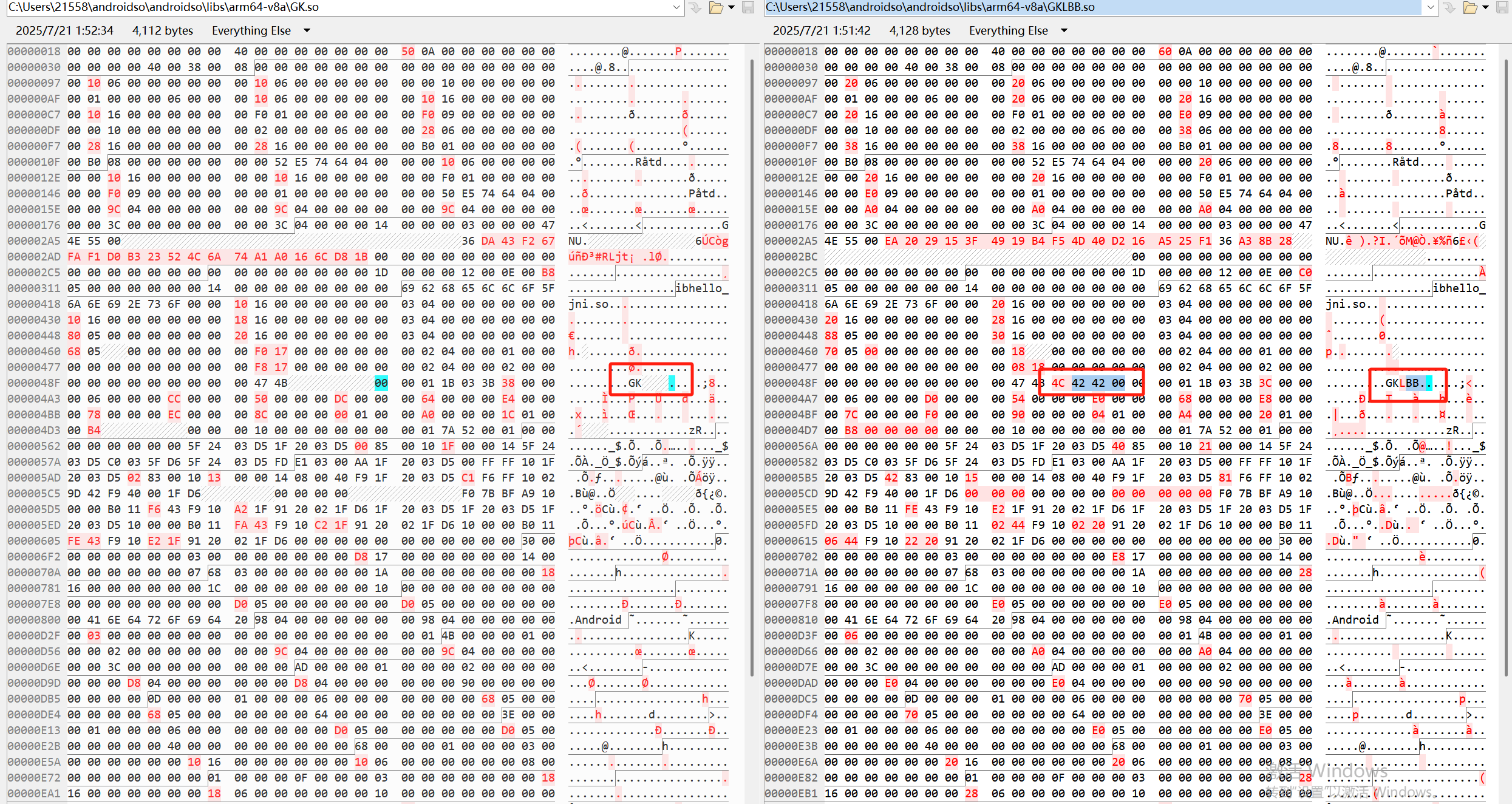
好的,这是一个非常好的问题,它揭示了编译和链接过程中的一个核心概念:二进制文件不是一个简单的字节序列,而是一个高度结构化、内部引用错综复杂的系统。
当你仅仅修改了一个字符串,从 "GK" 变为 "GKLBB",你不仅仅是替换了几个字节,而是改变了数据段的大小。这个大小的改变(从3字节 G K \0 变为6字节 G K L B B \0)会引发一系列连锁反应,导致文件中许多看似无关的部分都发生变化。
下面我们根据你提供的截图,逐步分析这些连锁变化的原因。
1. 直接修改:数据段中的字符串内容
这是最直观的变化。
-
文件
-
在地址 0x48D 附近,我们可以看到十六进制 47 4B,其右侧的ASCII表示为 .GK.。这正是字符串 "GK"。
-
-
文件
-
在相同位置附近,我们可以看到十六进制 47 4B 4C 42 42,ASCII表示为 .GKLBB.。
-
这个变化使 .rodata (只读数据) 段的大小增加了3个字节。
-
这个大小的改变是后续所有连锁反应的根源。
2. 连锁反应 1:文件偏移量 (File Offsets) 的变化
ELF 文件格式包含许多指向文件内其他位置的指针,这些指针被称为“文件偏移量”。当字符串 "GK" 变长后,它之后的所有数据在文件中的位置都向后移动了3个字节(或者更多,取决于对齐)。因此,所有指向这些移动后数据的偏移量都必须由链接器重新计算和更新。
-
证据:ELF头中的节区头表偏移量 (
-
ELF文件的头部(文件最开始的部分)包含了指向“节区头表”(Section Header Table)的偏移量。这个表描述了文件中所有段(如 .text, .data 等)的位置和大小。
-
在arm64-v8a架构中,e_shoff 位于文件偏移 0x28 处。
-
GK.so: 0x28 处的值是 40 0E 00 00 00 00 00 00,小端序表示偏移量为 0x0E40。
-
GKLBB.so: 0x28 处的值是 60 0E 00 00 00 00 00 00,小端序表示偏移量为 0x0E60。
-
分析:节区头表的位置因为文件中间数据增多而被向后推移了 0x20 (32) 字节。这证明了链接器重新计算了整个文件布局,而不仅仅是简单地移动数据。
-
3. 连锁反应 2:PC相对寻址导致的代码变化
现代编译器经常使用PC相对寻址来加载数据。这意味着生成的机器码不是加载一个绝对地址,而是加载一个相对于当前指令指针(PC)的偏移量。
-
指令: LDR W8, =0x48D (伪代码,表示加载地址0x48D处的数据)
-
工作原理: 编译器会计算出 0x48D 相对于当前PC的距离,然后生成一条 LDR 指令来加载。
当数据段中字符串的位置发生变化时(即使只是因为前面的数据变长了),所有引用该字符串或其后数据的PC相对寻址指令都必须改变它们的立即数偏移量,这直接导致了 .text(代码)段的变化。
-
证据:代码段的差异
-
在地址 0x2AD 处,两边的机器码完全不同。
-
GK.so: DA 43 F2 67
-
GKLBB.so: EA 20 29 15
-
分析:这很可能是一条 LDR 或 ADR 指令,用于加载一个数据段中的地址。由于数据段的布局发生了变化,目标地址的相对偏移也变了,因此生成的机器码也必须改变。
-
4. 连锁反应 3:哈希表和符号表的变化
为了让动态链接器能够快速查找函数和变量(符号),ELF文件包含一个哈希表(.hash 或 .gnu.hash 段)。
-
工作原理: 哈希表是对符号字符串名称计算哈希值后构建的。
-
连锁反应:
-
文件内容的任何改变,都会导致链接器可能重新排列符号表(.dynsym)。
-
符号表项的顺序或地址的改变,会使得整个哈希表需要被重新计算。哈希值会完全不同。
-
-
证据:文件头部的哈希/符号相关区域
-
在截图的 0x000000C7 到 0x0000010F 区域,我们可以看到大量的差异。例如:
-
GK.so at 0xC7: F0 09
-
GKLBB.so at 0xC7: E0 09
-
分析:这些字节是动态链接信息的一部分,包含了符号表、字符串表和哈希表的各种偏移和索引。布局的微小变化导致了这些元数据的全面更新。
-
5. 连锁反应 4:调试和异常处理信息的变化
ARM64使用DWARF格式将调试和栈回溯(unwinding)信息存储在 .eh_frame 和 .eh_frame_hdr 段中。这些信息与代码的地址和栈操作指令紧密耦合。
-
连锁反应:
-
当代码段因为PC相对寻址等原因发生改变时,哪怕只是一条指令,函数的起始/结束地址、栈指针的修改方式等都可能变化。
-
因此,链接器必须重新生成几乎全部的DWARF调试和异常处理信息。这部分数据非常敏感,微小的代码变动都可能导致其内容面目全非。
-
-
证据:文件后半部分的大量差异
-
观察截图的后半部分,例如从 0x5CD 开始的区域。
-
GK.so: 9D 42 F9 40 1F D6 ...
-
GKLBB.so: 81 F6 FF 10 02 1F ...
-
分析:这部分区域的差异非常大,几乎没有相同的字节。这正是 .eh_frame 段,它的内容被完全重写了,以匹配新的代码布局。
-
总结
将一个二进制文件想象成一张由线连接起来的网。字符串是网上的一个节点,而文件头、偏移量、指针、哈希表、调试信息等都是连接节点的线。
当你把 "GK" 换成 "GKLBB" 时,你不仅替换了节点,还拉长了它。这张网为了保持自身的结构和正确性,链接器必须重新调整几乎所有连接线的长度和位置,甚至重新编织一大部分网。
这就是为什么一个看似微不足道的字符串长度变化,会导致整个二进制文件发生广泛而深刻的改变。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号