

maxkb使用手册
如何提高知识库命中率
80%的原因是知识库解析文档不规范,剩下的可能是因为嵌入式模型的原因
文档分段尽可能保持每段文字 独立和完整性。
生成的关联问题可以增加命中率。分段标题不能作为命中依据。这里需要优化为关联问题,去除没有用的标题。每段标题应该是有一级 二级 三级 在一个标题内。
解析规范建议:
md文件是最推荐的格式,系统会将md格式转换为问答对表的格式。
txt格式,先用ai转化为带有标题标准的md格式,在导入。注意选中标题就是问题,ai生成一个问题。
word格式,转化为有标题的文档,然后转换。建议使用mineru工具转换为md
pdf解析如果是纯文本pdf就直接上传,如果是图片加文字的复杂pdf,需要使用minerU工具转md格式和图片文件夹,将这两个打包zip上传,这里解析的方法太繁琐需要优化代码
excel解析因为没有表头解析效果差,建议表保存在word中,并附上描述性文字。让每条数据都有自己的表头,这样检索的数据才有意义。同时添加丰富的问题示例增大命中率
ppt格式,建议使用mineru工具转换为md
例如,给下表添加描述文字保存在word
目前公租房项目主要包含 前置流程修改项目,发票记录项目,变更发票项目,优化驾驶舱项目,住宅项目,轧账项目,数电发票项目,OA退款项目,台账租金项目,台账项目,流水项目,产品化项目,商业项目,财务项目,楼宇项目,培训项目。这些项目目前都是处于运营状态,符合条件的市民可以申请处于“空置”状态的房源。所有“在租”房源,都是已经出租的房源,不可以申请。
所有项目的“在租”或者“空置”的房源统计如下面的表格:
| 项目 | 房屋或房源状态 | 数量 |
|---|---|---|
| 前置流程修改项目 | 在租 | 5 |
| 前置流程修改项目 | 空置 | 15 |
| 发票记录项目 | 在租 | 8 |
| 发票记录项目 | 空置 | 12 |
| 变更发票项目 | 在租 | 8 |
| 变更发票项目 | 空置 | 13 |
| 优化驾驶舱项目 | 在租 | 12 |
| 优化驾驶舱项目 | 空置 | 8 |
| 住宅项目 | 在租 | 29 |
| 轧账项目 | 空置 | 40 |
| 住宅项目 | 空置 | 10 |
| 数电发票项目 | 在租 | 48 |
| 数电发票项目 | 空置 | 29 |
| OA退款项目 | 在租 | 7 |
| OA退款项目 | 空置 | 13 |
| 台账租金项目 | 在租 | 5 |
| 台账租金项目 | 空置 | 15 |
| 台账项目 | 空置 | 10 |
| 台账项目 | 已锁定 | 1 |
| 台账项目 | 在租 | 9 |
| 流水项目 | 在租 | 7 |
| 流水项目 | 空置 | 13 |
| 产品化项目 | 在租 | 19 |
| 产品化项目 | 已锁定 | 2 |
| 产品化项目 | 空置 | 30 |
| 商业项目 | 空置 | 14 |
| 财务项目 | 空置 | 72 |
| 轧账项目 | 在租 | 23 |
| 楼宇项目 | 在租 | 22 |
| 楼宇项目 | 空置 | 10 |
| 培训项目 | 在租 | 21 |
| 培训项目 | 空置 | 7 |
| 培训项目 | 已锁定 | 2 |
| 财务项目 | 在租 | 3 |
| 商业项目 | 在租 | 9 |
| 商业项目 | 已锁定 | 1 |
在该表格里可以查询每个项目的“在租”或“空置”状态房源。
同时用ai生成几个问题,可以增大命中率
空置和在租的总数是多少
有没有项目的空置房源数量远高于其在租房源数量?
在公租房项目中,有没有项目的房源已经全部处于“已锁定"状态?
有多少个项目的空置房源数量超过了在租房源数量?
各个项目中,在租房源数量最多的是哪一个项目?
目前公租房项目中,空置房源数量最多的项目是哪一个?
在线爬取功能。这个不好用,会爬取html语法,其实用户只是关系的是内容。
在录制完成后需要手动测试命中率的最终效果
函数用法
用法1:联网搜索
联网搜索的是先方法有第三方集成api,百度或必应api,或者自己实现一个搜索引擎
创建一个函数
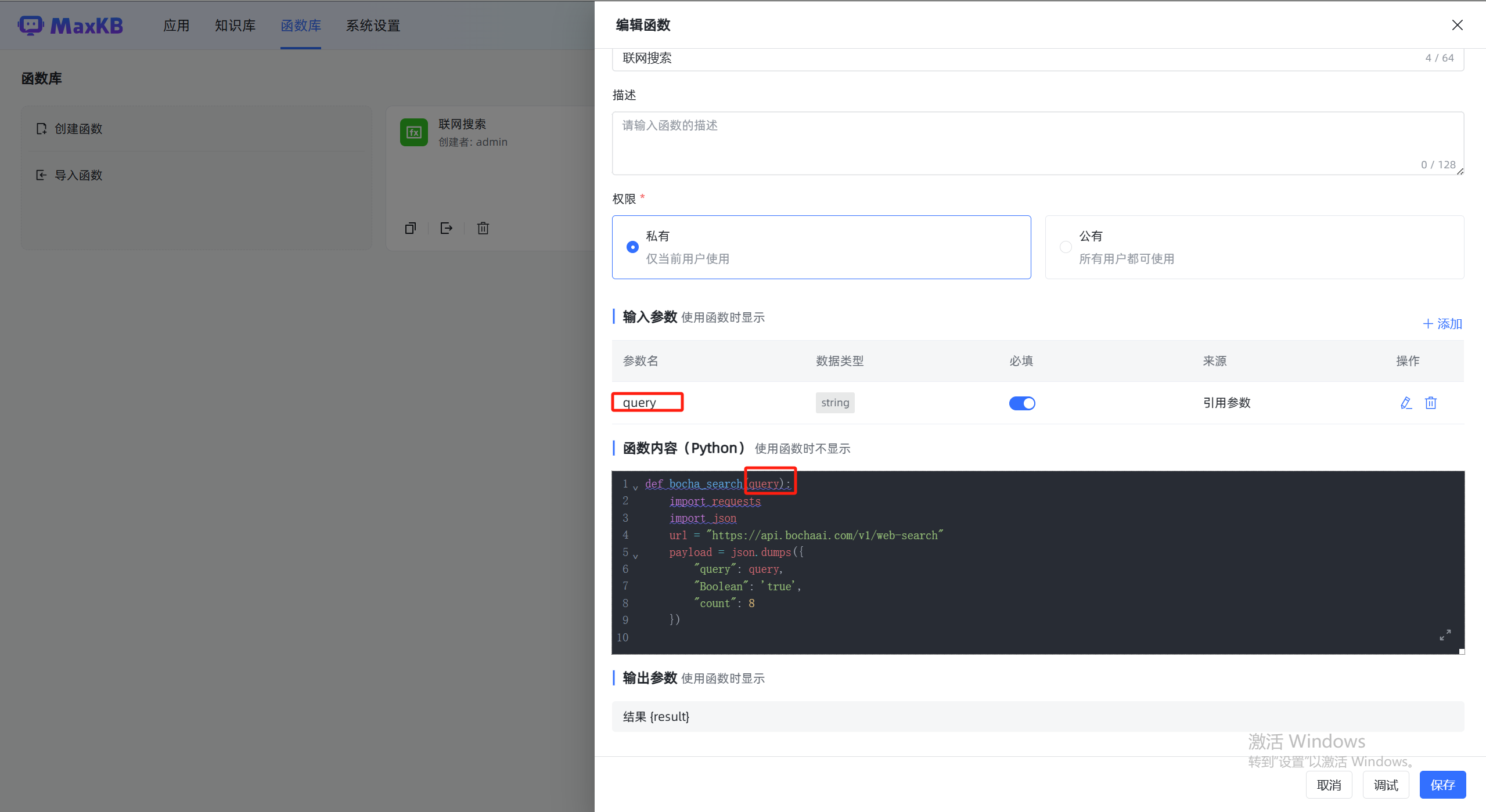
函数详情
def bocha_search(query): import requests import json url = "https://api.bochaai.com/v1/web-search" payload = json.dumps({ "query": query, "Boolean": 'true', "count": 8 }) headers = { 'Authorization': 'Bearer sk-32097786d7f54a409714810b7298aeb9', #鉴权参数,示例:Bearer xxxxxx,API KEY请先前往博查AI开放平台(https://open.bochaai.com)> API KEY 管理中获取。 'Content-Type': 'application/json' } response = requests.request("POST", url, headers=headers, data=payload) return response.json()
这里没有过多处理,直接输出json给模型
用法2: 文生图、文生视频
在docker安装
pip install zhipuai
函数定义:
文生图
def generate_image_from_text(text): from zhipuai import ZhipuAI # 替换为您的 ZhipuAI API 密钥 client = ZhipuAI(api_key = "30099c8**************" ) # 填写自己的APIKey response = client.images.generations( model = "cogview-3" , # 填写需要调用的模型编码 prompt = text, ) print (response.data[ 0 ].url) url = response.data[ 0 ].url return f ''
文生视频
import time def generate_video_from_text(text): from zhipuai import ZhipuAI # 替换为您的 ZhipuAI API 密钥 client = ZhipuAI(api_key="30099c8a9f7******************") # 请填写您自己的APIKey response = client.videos.generations( model="cogvideox",# 填写需要调用的模型编码 prompt=text, ) task_id = response.id task_status = '' get_cnt = 0 while task_status != 'SUCCESS' and task_status != 'FAILED' and get_cnt <= 200: result_response = client.videos.retrieve_videos_result(id=task_id) print(result_response) task_status = result_response.task_status time.sleep(2) get_cnt += 1 if task_status == 'SUCCESS': url = result_response.video_result[0].url print(result_response.video_result[0].url) return f'<video controls width=500 height=300 src="{url}" frameborder="0" scrolling="no" allowfullscreen="true" alt="占位视频"></video>' else: return '任务成功但未找到视频结果'
查询天气
import requests def get_weather_by_city_id(city_id): """ 通过城市ID获取天气信息 :param city_id: 城市ID,例如'101190101' :return: 响应内容 """ # 构造请求URL url = f"http://t.weather.sojson.com/api/weather/city/{city_id}" try: # 发送GET请求 response = requests.get(url) # 检查请求是否成功 if response.status_code == 200: # 解析并打印JSON响应 weather_data = response.json() print(weather_data) return weather_data else: print(f"请求失败,状态码: {response.status_code}") return None except requests.RequestException as e: print(f"请求错误: {e}")
执行sql
pip 安装: pip install mysql-connector-python 函数定义: import mysql.connector from mysql.connector import Error def execute_sql_query(query): """ :param query: 要执行的SQL查询 :return: 查询结果 """ connection = None result = None try: connection = mysql.connector.connect( host= "10.1.14.175", user= "root", passwd= "YTkzZDNiNDItZDcyNC******", database= "jumpserver" ) if connection.is_connected(): cursor = connection.cursor() cursor.execute(query) # 对于SELECT查询,我们使用fetchall()来获取所有结果 # 对于INSERT、UPDATE、DELETE等,你可以通过cursor.rowcount来获取影响的行数 if query.upper().startswith('SELECT'): result = cursor.fetchall() else: connection.commit() # 确保更改被提交到数据库 result = cursor.rowcount # 获取影响的行数 except Error as e: print(f"Error while connecting to MySQL {e}") finally: if connection.is_connected(): cursor.close() connection.close() print("MySQL connection is closed") return result
生图
# coding=utf-8 import json def get_echarts(): option = """ option = { title: { text: '专家库年龄分布图', subtext: '', left: 'center' }, tooltip: { trigger: 'item' }, legend: { orient: 'vertical', left: 'left' }, series: [ { name: 'Access From', type: 'pie', radius: '50%', data: [ { value: 1048, name: 'Search Engine' }, { value: 735, name: 'Direct' }, { value: 580, name: 'Email' }, { value: 484, name: 'Union Ads' }, { value: 300, name: 'Video Ads' } ], emphasis: { itemStyle: { shadowBlur: 10, shadowOffsetX: 0, shadowColor: 'rgba(0, 0, 0, 0.5)' } } } ] }; """ return json.dumps({'actionType': 'EVAL', 'option': option, 'style': {'height': '600px', 'width': '100%'}})
最后应用这个输出,即可渲染。
option 的值来自echart官方复制的。
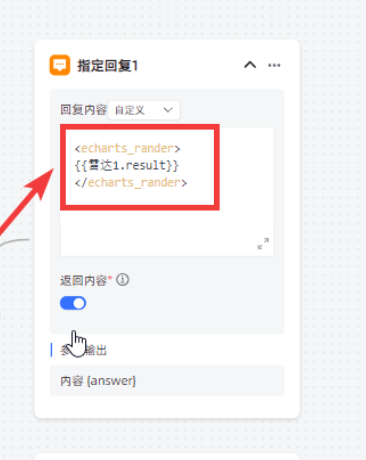
生图和表
option = { toolbox: { left:33, // top:10, feature: { dataView: { show: true, title: '数据视图', readOnly:true, lang: ['数据视图:', '返回'], // 按钮 contentToOption: function (opts) { $(".echarts_max").table2excel({ //下载jquery.table2excel.js,引入,$("#tempChart")是Echarts容器 exclude: ".noExl", //过滤位置的 css 类名, 有class = “noExl” 的行不被导出 filename: "消耗量表", // 文件名称 name: "Excel Document Name.xls", exclude_img: true, exclude_links: true, exclude_inputs: true }); }, optionToContent: function (opt) { // console.log(opt) //该函数可以自定义列表为table,opt是给我们提供的原始数据的obj。 可打印出来数据结构查看 var axisData = opt.xAxis[0].data; //坐标轴 var series = opt.series; //折线图的数据 var tdHeads = '<td style="margin-top:10px; padding: 0 15px">原料11</td>'; //表头 var tdBodys = ""; console.log(opt) series.forEach(function (item) { tdHeads += `<td style="padding:5px 15px">消耗22</td>`; }); var table = '<table border="1" style="margin-left:20px;border-collapse:collapse;font-size:14px;text-align:center;"><tbody><tr>'+tdHeads+'</tr>'; for (var i = 0, l = axisData.length; i < l; i++) { for (var j = 0; j < series.length; j++) { // console.log(i+"-"+j+":"+series[j].data[i]) if (series[j].data[i] == null) { tdBodys += `<td>${"-"}</td>`; } else { tdBodys += '<td>'+series[j].data[i]+'</td>'; } } table += '<tr><td style="padding: 0 15px">'+axisData[i]+'</td>'+tdBodys+'</tr>'; tdBodys = ""; } table += "</tbody></table>"; return table; }, }, magicType: {show: true, type: ['line', 'bar']}, restore: {show: true}, saveAsImage: {show: true} } }, xAxis: { type: 'category', data: ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun'] }, yAxis: { type: 'value' }, series: [ { data: [150, 230, 224, 218, 135, 147, 260], type: 'line' } ] };
渲染方式同上
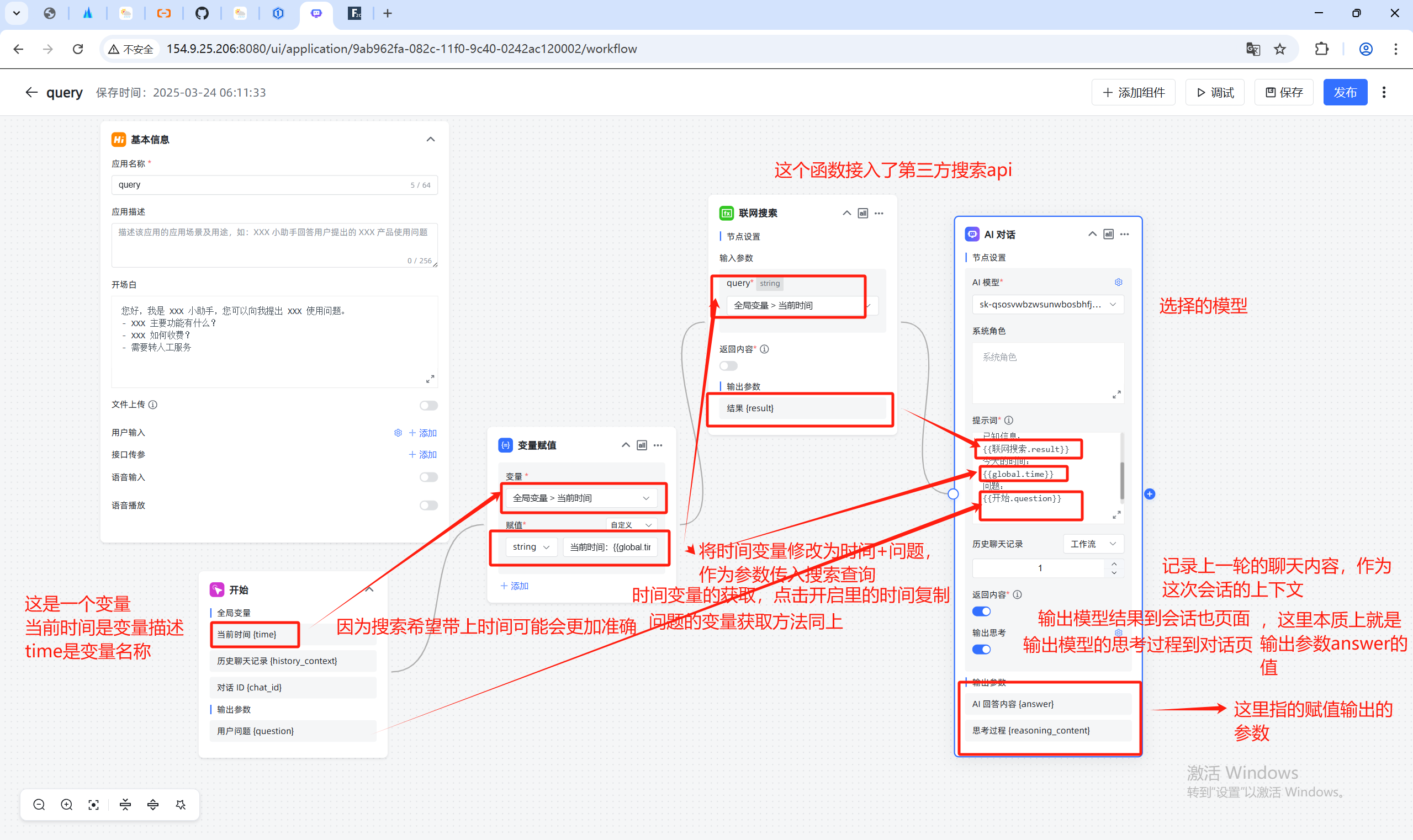
基于不同角色查询不同数据库的实现方法
个流程如下:
1. 基本架构
- 前端: 提供用户交互界面,支持全屏和浮窗两种嵌入模式
- 后端: SpringBoot Java 应用,提供权限验证和知识库访问的 API
- 函数组件: 两个关键函数用于权限处理
- : 获取用户权限
- : 权限验证
2. 工作流程
-
用户身份传递:
- 通过 URL 参数 传递用户身份标识
- 前端通过接口将身份信息传递给应用的全局变量
-
问题处理与权限判断:
- 用户提出问题
- AI 对话组件分析问题并确定所属知识库类别
- 调用 函数获取该用户有权访问的知识库列表
- 调用 函数判断用户是否有权访问相关知识库
-
知识库访问控制:
- 如果权限验证通过("包含"),将问题路由到相应知识库检索答案
- 如果权限验证失败("不包含"),返回预设的无权访问提示
-
响应返回:
- 系统从适当的知识库检索信息并返回答案
- 整个流程执行时间和token消耗会被记录(如执行详情图所示)
3. 技术实现特点
- 模块化设计: 将权限验证和知识库访问拆分为独立功能模块
- 可视化流程编排: 通过流程图形式配置业务逻辑,无需编写复杂代码
- 灵活的身份验证: 支持通过接口传参方式进行身份认证
- 多种集成方式: 提供iframe和脚本两种第三方集成方式
这个系统有效实现了根据用户角色限制知识库访问的功能,使不同用户只能查询与其权限相匹配的知识内容。
正则用法
文章标题是数字 ,
例如 1.1 标题
\d+\.+\d*\.*\d*\.*[a-zA-Z\s]*[\u4e00-\u9fa5,]+
如:一、标题
[一二三四五六七八九十]*[、][\u4e00-\u9fa5a-zA-Z]+
如:第一章 标题
[第][一二三四五六七八九十]+[章][ \u4e00-\u9fa5a-zA-Z]+
如:一、标题一 1.1 子标题
正则表达式:[一二三四五六七八九十|1-9]+[、|.][1-9]*[.]*[1-9]*[ \u4e00-\u9fa5a-zA-Z]+
收费功能
密码访问聊天窗口
未知作用


 浙公网安备 33010602011771号
浙公网安备 33010602011771号