

软件开发 --- LLM基础知识
知识库匹配度太差
80%的原因是知识库解析文档不规范,剩下的可能是因为嵌入式模型的原因
文档分段尽可能保持每段文字 独立和完整性。
解析规范建议:
md文件是最推荐的格式
word解析要用正则匹配
pdf解析要用pdf转md格式,将转化好的文字和图片打包上传
excel解析因为没有表头解析效果差,建议表保存在word中,并附上描述性文字。让每条数据都有自己的表头,这样检索的数据才有意义。同时添加丰富的问题示例增大命中率
例如,给下表添加描述文字
目前公租房项目主要包含 前置流程修改项目,发票记录项目,变更发票项目,优化驾驶舱项目,住宅项目,轧账项目,数电发票项目,OA退款项目,台账租金项目,台账项目,流水项目,产品化项目,商业项目,财务项目,楼宇项目,培训项目。这些项目目前都是处于运营状态,符合条件的市民可以申请处于“空置”状态的房源。所有“在租”房源,都是已经出租的房源,不可以申请。
所有项目的“在租”或者“空置”的房源统计如下面的表格:
| 项目 | 房屋或房源状态 | 数量 |
|---|---|---|
| 前置流程修改项目 | 在租 | 5 |
| 前置流程修改项目 | 空置 | 15 |
| 发票记录项目 | 在租 | 8 |
| 发票记录项目 | 空置 | 12 |
| 变更发票项目 | 在租 | 8 |
| 变更发票项目 | 空置 | 13 |
| 优化驾驶舱项目 | 在租 | 12 |
| 优化驾驶舱项目 | 空置 | 8 |
| 住宅项目 | 在租 | 29 |
| 轧账项目 | 空置 | 40 |
| 住宅项目 | 空置 | 10 |
| 数电发票项目 | 在租 | 48 |
| 数电发票项目 | 空置 | 29 |
| OA退款项目 | 在租 | 7 |
| OA退款项目 | 空置 | 13 |
| 台账租金项目 | 在租 | 5 |
| 台账租金项目 | 空置 | 15 |
| 台账项目 | 空置 | 10 |
| 台账项目 | 已锁定 | 1 |
| 台账项目 | 在租 | 9 |
| 流水项目 | 在租 | 7 |
| 流水项目 | 空置 | 13 |
| 产品化项目 | 在租 | 19 |
| 产品化项目 | 已锁定 | 2 |
| 产品化项目 | 空置 | 30 |
| 商业项目 | 空置 | 14 |
| 财务项目 | 空置 | 72 |
| 轧账项目 | 在租 | 23 |
| 楼宇项目 | 在租 | 22 |
| 楼宇项目 | 空置 | 10 |
| 培训项目 | 在租 | 21 |
| 培训项目 | 空置 | 7 |
| 培训项目 | 已锁定 | 2 |
| 财务项目 | 在租 | 3 |
| 商业项目 | 在租 | 9 |
| 商业项目 | 已锁定 | 1 |
在该表格里可以查询每个项目的“在租”或“空置”状态房源。
同时用ai生成几个问题,可以增大命中率
空置和在租的总数是多少
有没有项目的空置房源数量远高于其在租房源数量?
在公租房项目中,有没有项目的房源已经全部处于“已锁定"状态?
有多少个项目的空置房源数量超过了在租房源数量?
各个项目中,在租房源数量最多的是哪一个项目?
目前公租房项目中,空置房源数量最多的项目是哪一个?
大语言模型怎么记住上下文的
其实目前模型都没有记忆功能,记忆的实现是单次请求中包含之前的历史对话数据。比如:
{“你叫小明”}
{“你叫什么”}
这两数据同时提交给模型,模型依据上下文得出答案
什么是token
一个token就是一个分词,一个分词可以是 我,我的,苹果,朋友等等,一个分词是大模型的语言的最小单位
为什么回答一半就停止输出了
token输出配置小导致的。
如何精确控制输出的字数
在系统提示词中添加下面示例
-
回答要求:
- 请使用中文回答用户问题
- "请用100字字左右的篇幅回答,包含3-5个要点"
"请按以下格式回答:
【引用】显示每个引用的文章名称
【总结】(100字)
这里注意如果我们直接说限制多少字,可能不会有有效,但是按照固定格式就可以精准控制
什么是多路召回”
通俗解释
想象你是一个图书管理员,用户问:“我想找一本主角是侦探的悬疑小说,但不要太血腥”。传统的单一路径召回可能只依赖关键词“侦探+悬疑”,但大语言模型支持的多路召回会这样做:
-
第一路召回:直接匹配关键词(“侦探”“悬疑”)
→ 找到《福尔摩斯探案集》 -
第二路召回:用LLM理解深层需求(“不要太血腥”)
→ 过滤掉《沉默的羔羊》,召回《东方快车谋杀案》 -
第三路召回:LLM生成相似语义的扩展词(“推理”“反转结局”)
→ 找到《无人生还》 -
第四路召回:结合用户历史数据(用户曾喜欢“日式轻推理”)
→ 召回《嫌疑人X的献身》
最终将多路结果融合推荐,既满足显性需求,又挖掘隐性偏好。
大语言模型支持的“多路召回”,本质是让机器像人类一样多维度思考:既看字面意思,又揣摩深层需求;既用数据统计,也靠逻辑推理。它解决了传统召回策略的“机械性”短板,尤其擅长处理模糊表达、长尾需求和复杂上下文场景。未来随着多模态LLM的发展,召回维度将进一步扩展(如语音、3D模型),成为智能系统的核心基础设施。
每个模型特点
-
长文本分析 → Kimi/Claude
-
多模态生成 → 通义千问/Gemini
-
代码开发 → DeepSeek/GPT-4
RAG与知识库原理
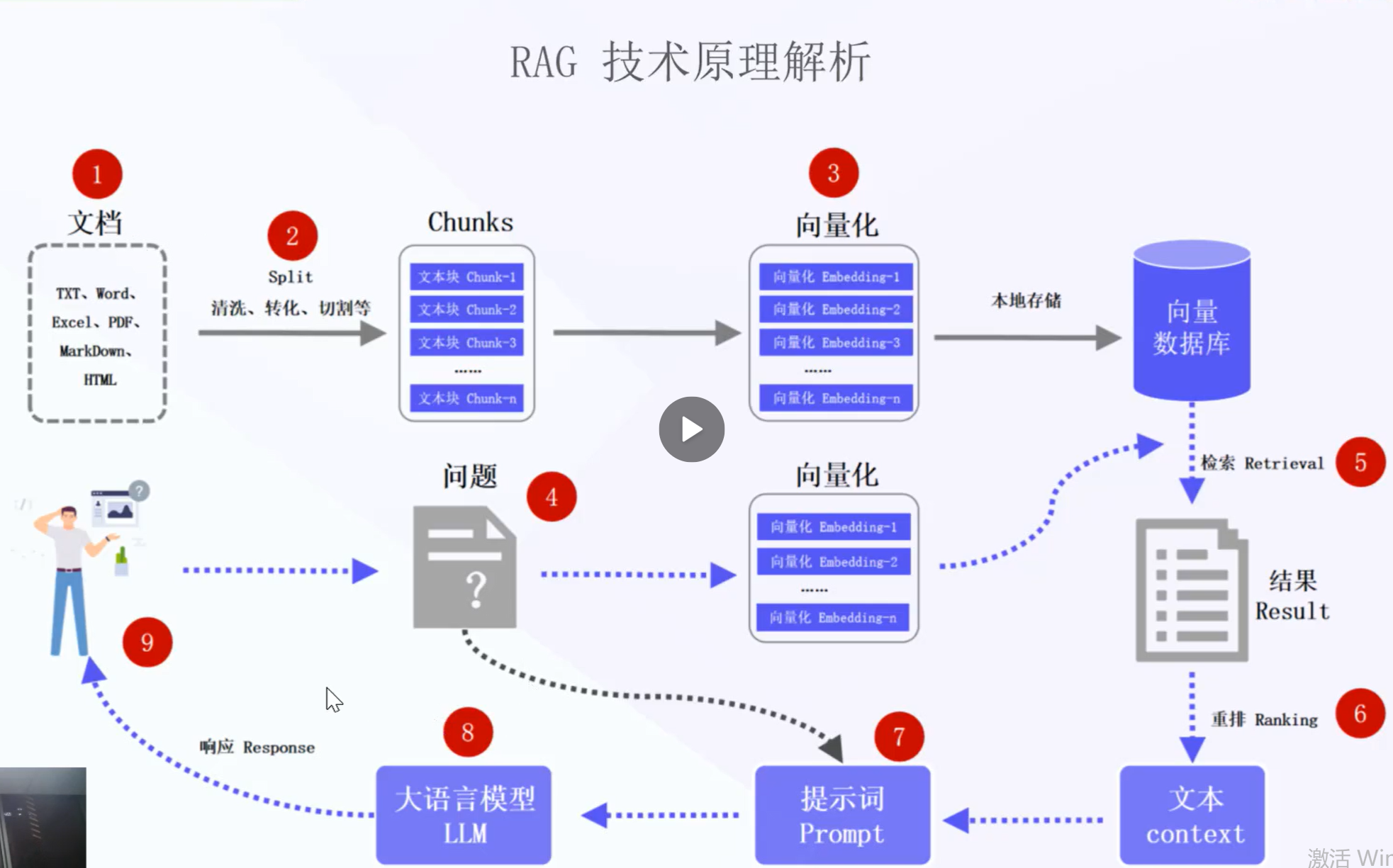
知识库的底层原理,
知识库就是用户上次的文档解析为了向量数据库,之后用户提问的问题会在数据库中匹配,命中后会提取文档数据发送给deepseek,下面是一个知识库和deepseek的底层原理
我的知识库
天水呱呱:天水传统风味小吃,被誉为 “秦州第一美食”。呱呱是用当地特产的荞麦粉制成,呈深褐色或黑色,口感独特,有筋道、柔软、爽滑的特点。食用时,将呱呱切成小块,配上辣子油、芝麻酱、芥末、蒜泥、醋、盐等调料,味道酸辣可口,回味无穷。? 天水浆水面:以浆水做汤,加上葱花、香菜等制作而成的一种面条。浆水是用芹菜、白菜等蔬菜发酵制成的,富含乳酸菌,有开胃健脾、清热解暑的功效。浆水面面条细长,汤味酸爽,吃起来清爽可口,是天水人夏季消暑的首选美食。? 天水酿皮:分为两种,一种是水洗酿皮,一种是高担酿皮。水洗酿皮口感软嫩,高担酿皮口感筋道。酿皮一般搭配面筋、黄瓜丝、豆芽等,再浇上辣椒油、醋、蒜汁等调料,色泽鲜亮,味道香辣,深受当地人喜爱。? 天水猪油盒:是一种用猪油、面粉制成的特色面食。其制作工艺独特,先将面粉用开水烫熟,再加入猪油、葱花、花椒粉等调料揉成面团,制成饼状,放入平底锅中煎至两面金黄。猪油盒外皮酥脆,内瓤绵软,香味浓郁。? 天水麻食子:又称 “圪垯”,是一种形似猫耳朵的面食。将面粉加水揉成面团,切成小块,搓成中间薄、边缘厚的麻食子形状,然后与土豆、胡萝卜、豆腐等食材一起煮成汤面。麻食子口感爽滑,汤鲜味美,营养丰富。
我的问题
天水呱呱
向量匹配完成后,会将文档放在system系统提示词中,等待回答
{"model": "deepseek-r1:8b", "messages": [
{"role": "system", "content": "
你是一名智能助手。请概括知识库的内容来回答问题。请列出知识库中的数据并详细回答。当知识库中的所有内容都与问题无关时,您的答案必须包括一句话:"知识库中没有您要找的答案!” 答案需要考虑聊天记录。
这里是知识库:
------
文档: 天水美食.txt \n
相关片段如下:\n
1. 天水呱呱:天水传统风味小吃,被誉为 “秦州第一美食”。呱呱是用当地特产的荞麦粉制成,呈深褐色或黑色,口感独特,有筋道、柔软、爽滑的特点。食用时,将呱呱切成小块,配上辣子油、芝麻酱、芥末、蒜泥、醋、盐等调料,味道酸辣可口,回味无穷\n
2. 。?\r\n天水酿皮:分为两种,一种是水洗酿皮,一种是高担酿皮。水洗酿皮口感软嫩,高担酿皮口感筋道。酿皮一般搭配面筋、黄瓜丝、豆芽等,再浇上辣椒油、醋、蒜汁等调料,色泽鲜亮,味道香辣,深受当地人喜爱\n
3. 。?\r\n天水浆水面:以浆水做汤,加上葱花、香菜等制作而成的一种面条。浆水是用芹菜、白菜等蔬菜发酵制成的,富含乳酸菌,有开胃健脾、清热解暑的功效。浆水面面条细长,汤味酸爽,吃起来清爽可口,是天水人夏季消暑的首选美食\n
4. 。?\r\n天水猪油盒:是一种用猪油、面粉制成的特色面食。其制作工艺独特,先将面粉用开水烫熟,再加入猪油、葱花、花椒粉等调料揉成面团,制成饼状,放入平底锅中煎至两面金黄。猪油盒外皮酥脆,内瓤绵软,香味浓郁\n
5. 。?\r\n天水麻食子:又称 “圪”,是一种形似猫耳朵的面食。将面粉加水揉成面团,切成小块,搓成中间薄、边缘厚的麻食子形状,然后与土豆、胡萝卜、豆腐等食材一起煮成汤面。麻食子口感爽滑,汤鲜味美,营养丰富\n\n\n
------\n\n
文档: 天水历史文化.txt \n
相关片段如下:\n
1. 天水的起源:天水是华夏文明和中华民族的重要发祥地,传说人文始祖伏羲氏诞生于此,其创八卦、结网罟、取火种、造书契等,开启了中华文明的先河。女娲抟土造人、炼石补天的传说也在这里广为流传。?\r\n先秦时期:天水属秦国领地,秦武公十年(公元前 688 年),秦国在今甘谷县设置县,这是中国历史上最早设立的县之一,标志着天水地区正式纳入秦国版图\n
2. 。?\r\n秦汉时期:秦朝统一后,天水地区成为连接中原与西北的交通要道,在巩固边疆、促进民族融合方面发挥了重要作用。汉朝时期,天水是丝绸之路的重要节点,商贸往来频繁,文化交流活跃。?\r\n三国时期:天水成为魏蜀争夺的战略要地,诸葛亮六出祁山,多次在此用兵\n
3. 。著名的街亭之战就发生在天水境内,马谡因违背诸葛亮作战指令,导致蜀军在街亭惨败。?\r\n隋唐时期:天水地区经济繁荣,文化昌盛。佛教盛行,麦积山石窟在这一时期得到大规模开凿和修缮,其精美的佛像和壁画展现了当时高超的艺术水平\n\n
以上就是知识库。\n\n
### Query:\n
天水呱呱"},
{"role": "user", "content": "天水呱呱"}], "stream": true, "format": "", "options": {"temperature": 0.1, "num_predict": 6777, "top_p": 0.3, "presence_penalty": 0.4, "frequency_penalty": 0.7}, "keep_alive": -1}
大语言模型的GPU内存估算
一、核心计算公式
M = (P × 4GB / (32/Q)) × 1.2
变量说明:
-
M:GPU内存需求(GB)
-
P:模型参数量(以B为单位,如7B模型则P=7)
-
Q:加载模型的量化位数(如FP16则Q=16,INT8则Q=8)
-
1.2:预留20%内存余量(兼容中间计算、缓存等开销)
二、计算步骤示例
以 Qwen2-7B-Instruct 模型(7B参数)加载为 8bit量化 为例:
-
基础参数量计算
7B参数 × 4字节(FP32原生) = 28GB -
量化压缩计算
28GB ÷ (32bit/Q) = 28GB ÷ 4 = 7GB
(32/Q为压缩倍数,Q=8时压缩4倍) -
附加内存余量
7GB × 1.2 = 8.4GB
三、在线工具快速估算
推荐使用工具简化计算:
-
模型内存计算器
(输入参数P、量化位宽Q即可生成结果) -
Hugging Face工具
Model Memory Usage
四、实际工程注意事项
| 因素 | 影响说明 | 建议处理方案 |
|---|---|---|
| 长文本输入 | 长序列增加KV缓存内存占用 | 按输入长度预估缓存需求 |
| 并发请求 | 多批次推理需叠加内存 | 按并发数扩大余量系数 |
| 响应速度 | 大Batch可能需更多显存 | 平衡吞吐与显存限制 |
| 框架开销 | PyTorch等框架额外占用10%-20% | 总需求建议按理论值×1.5-2 |
五、通用参考表
| 模型规模 | FP32原生需求 | FP16加载需求 | INT8加载需求 |
|---|---|---|---|
| 7B | 28GB | 14GB | 8.4GB |
| 13B | 52GB | 26GB | 15.6GB |
| 70B | 280GB | 140GB | 84GB |
六、总结建议
-
理论值为下限:实际部署需按场景叠加余量(通常预留1.5-2倍)。
-
量化权衡:低精度(如4bit)可进一步省内存,但可能影响输出质量。
-
硬件选择:A100/H100支持FP8优化,4090适合中小模型+低精度场景。
通过公式快速估算后,建议结合压测验证真实内存占用,确保生产环境稳定性。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号