
ai导论
-
机器学习的定义:利用经验数据和算法来反复训练机器,获得一种处理数据的模型,然后机器可以利用这个模型对新的输入进行数据计算,得到预测结果。
-
机器学习三大要素:经验数据 模型 算法
数据驱动模型选择,算法决定模型训练效率,三者相互制约。 -
人工智能系统的三个关键要素: 算法 数据 计算能力
-
人工智能寒冬出现的原因:
- 计算能力不足
- 数据量匮乏
- 专家系统成本高
-
1956,达特茅斯会议首次提出“人工智能”
-
机器学习分为:监督学习,无监督学习,半监督学习,强化学习
-
机器学习工作过程:
- 数据预处理(清洗,转换,归一化,格式化)
- 模型选择(如:监督学习选择线性回归,随机森林回归(回归算法)或者决策树,逻辑回归(分类算法))
- 训练优化(调节参数使得损失函数min,如:梯度下降)
- 部署评估
-
知识图谱:以图结构储存知识,由节点和边构成
-
图像识别的基本步骤
- 图像输入
- 预处理(灰度化,放缩,降噪)
- 特征提取(SIFT,HOG,CNN)(边缘,角点,纹理模式)
- 特征匹配
- 结果输出
-
文本分类流程:
- 数据集预处理
- 文本分词器
- 特征表示
- 分类器训练
-
生成式ai典型提示词:角色设定,任务要求,输出格式
-
过拟合:训练集表现好,在测试集上泛化能力差
-
监督学习:回归问题(房价预测,co2浓度预测,股票价格预测),分类问题(垃圾邮件分类,图片分类)
-
CNN卷积神经网络适合图像处理
-
RNN循环神经网络适合文本,音频,视频处理
-
RNN:一种反馈型神经网络。信号传播可用有向图表示,指向其他神经元
或指向自己来反馈 -
语音识别和声纹识别的区别:
- 目的不同:前者为了识别语音内容,将人类语音转化为相应文字或者执行相关的指令(语音输入文字,智能音箱),后者为了识别说话人的身份(生物识别技术的一种)
- 测试重点不同:前者测试重点为声音的录入,内容识别的准确性,后者测试重点为:是否会被相似特征声音攻击
-
树突:接受外界信号
-
突触:输出信号的部位
-
逻辑回归预测结果只有两种
-
二分类问题:逻辑回归
-
像素:组成图片的基本单元
-
一般专家系统包含5个部分
-
语料库:文本集合
-
监督学习表示机器的数据是:带标签
-
自然语言理解:文字理解,口语理解
-
一个汉字===2字节
-
BP神经网络:神经网络层相邻层之间的各个神经元全连接
-
降维算法分为:主成分分析法,因子分析法
-
知识表示方法:
- 谓词逻辑表示法
- 产生式表示法
- 框架表示法
-
单个MP模型中,非线性函数是核心
-
朴素贝叶斯算法:
- 以贝叶斯理论和特征条件独立假设构成的
- 分类基础:特征条件独立
- “朴素”是特征条件独立的假设
-
分类问题:投票
-
回归问题:取平均值
-
随机森林的随机性:数据随机性,特征值随机性
-
无监督学习:处理无标签数据,通过聚类、降维等方法挖掘数据内在模式,如 K-means 聚类顾客分群。
- 聚类:将相似的数据点聚在一起
- 降维:保留数据信息,减少复杂度,降噪
34. K-means聚类算法 - 定义:将数据集划分为若干簇(K个),不断调整,使得组间差异最大,组内差异最小,本质是“数据分组”
- 计算方法:欧几里得距离
- 算法步骤:
1. 初始化:随机选择K个簇中心
2. 分配样本:将每个样本分配到最近中心
3. 更新中心:计算每个簇内样本均值,作为中心
4. 迭代收敛:重复2-3步,直到中心不再变化||达到最大迭代次数 - 优缺点:
- 优点:简单高效,适合凸形簇数据,广泛应用于分群任务;
- 缺点:需预设 K 值,对初始中心敏感,无法处理非凸簇和噪声。
35. 主成分分析(PCA) - 主成分分析:基于线性代数特征值分解,将高维数据投影到低维空间,保证数据相似度,揭示数据变化方向。
- 为什么对数据标准化:
- 消除量纲影响(如身高 cm 和体重 kg 的尺度差异)
- 协方差矩阵计算要求数据均值为 0,标准化确保特征在相同尺度下比较。
-
监督学习算法:线性回归、逻辑回归、决策树、随机森林、支持向量机( SVM )、K 近邻算法 ( KNN)、神经网络等 无监督学习算法:K 均值聚类、层次聚类、主成分分析( PCA)、异常检测等。
-
如何消除过拟合:
- 交叉验证
- 数据质量与预处理技术(正道)
-
感知机历史:1957,罗森布特拉斯提出的首个可训练的神经网络,用于二分类任务(逻辑回归)(如:黑白图像识别)
-
感知机局限:只可以处理线性可分数据(无法解决异或问题)-->后来引入激活函数(非线性)
-
标志神经网络从理论走向实践:感知机的发明
-
什么是感知机:首个可训练的二分类神经网络,通过线性组合 + 阶跃函数实现分类,仅能处理线性可分数据。
-
词向量(便于计算文本相似度):词的特征分布,是NLP模型层与层之间进行信息传递的数据形式
-
词向量:数字编码,词嵌入:NPL网络间数据存在形式
-
计算文本相似度

常考:余弦相似度(正常操作)和广义Jaccard相似度
广义Jaccard相似度:- 已知词频(A.B/(A模方加B模方-A.B))
- 只看文本(AB共有个数)/(AB并集)

-
nlp经典模型
词袋模型,world2vec,seq2seq -
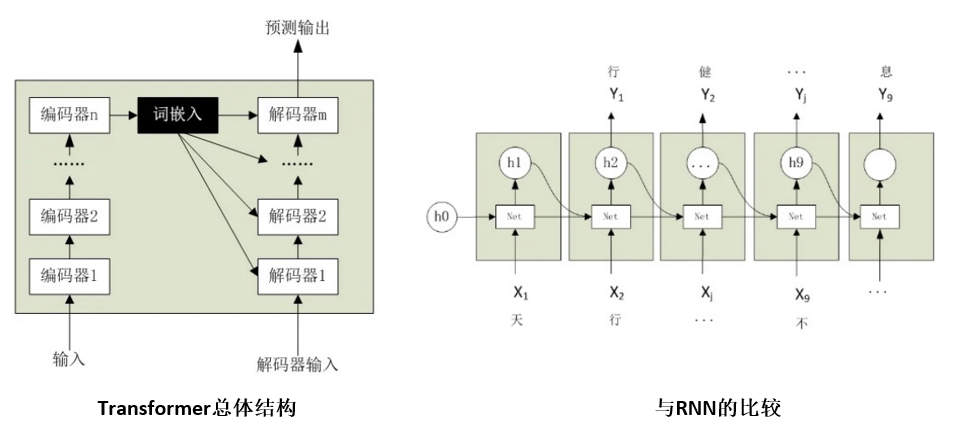
Transformer是一种基于注意力机制的序列模型,用自注意力机制来处理输入序列和输出序列,可以并行计算,提高计算效率
-
transformer技术特点:1,序列到序列的编码器-解码器,自回归语言生成技术2,自注意力机制
-
transformer 3种类型:BERT(结构只有编码器),GPT(结构只有解码器),6个T开头(编码器解码器都有)
-
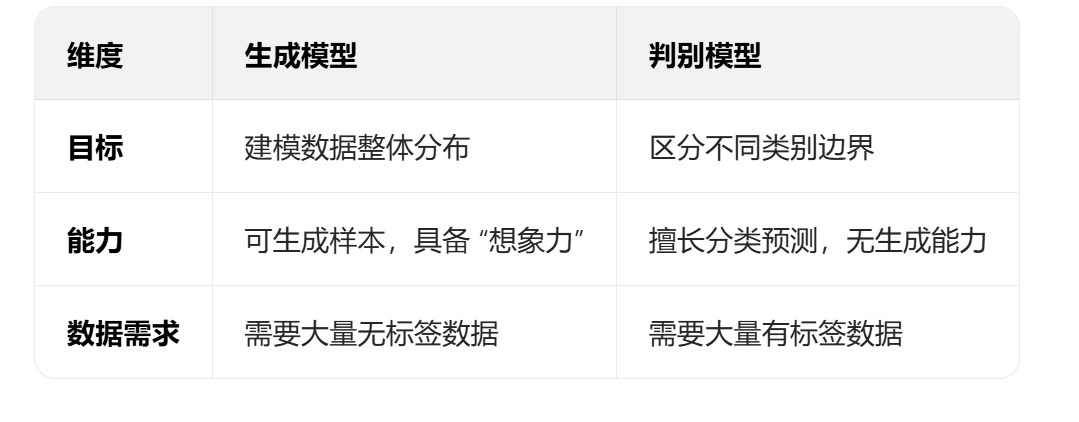
对比生成式与判别式模型:
生成式:学 “如何生成”(如根据 “春” 生成 “天”),需大量数据;
判别式:学 “如何判断”(如 “自” 后接 “强” 的概率),适合小数据(如朴素贝叶斯)。 -
Transformer 为何优于 RNN?
并行计算(RNN 需顺序处理,Transformer 可同时计算所有位置);
长距离依赖(注意力机制直接捕捉全局关联,RNN 依赖循环传递易丢失信息)。 -
编码器:输入向量
-
多头注意力机制:在实际应用中,特别是 Transformer 模型,通常会使用多
头自注意力。这意味着模型会并行地运行多个自注意力机制 -
自注意力机制:让模型在处理序列中的某个元素时,能够同时关注到序列中
的其他所有元素,并根据这些元素的相关性来调整当前元素的表示。 -
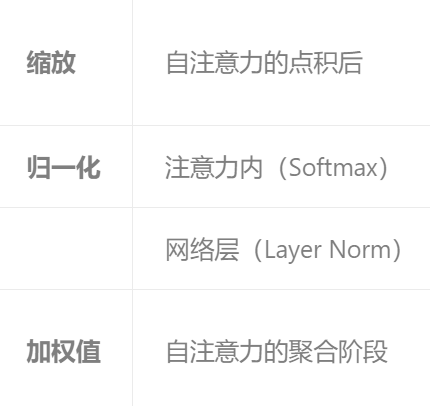
缩放 点积注意力:transformer自注意机制核心
-
归一化:Transformer 中的归一化分为 注意力内部的 Softmax 归一化 和 网络层的 Layer Normalization
-
加权值:Transformer 的自注意力通过 加权求和 聚合信息,“加权值” 是注意力的核心体现
-
-
KVCache 是一种 内存结构,用于存储 Transformer 自注意力层中 历史 token 的 Key 和 Value 张量(Query 是当前 token 的,每次变化,无法缓存)。避免自回归生成时,重复计算历史 token 的 Key 和 Value(否则每生成一个新 token,都要重新计算所有历史 token 的注意力,耗时极长)。
-
KVCache工作的两个阶段:1,预填充阶段(首次计算,无历史缓存,计算量大)2,推理阶段(生成新token)
-
KV Cache 的大小与 模型结构、序列长度、batch size 正相关
-
AIGC(人工智能生成内容):是指利用人工智能技术,使计算机自动 生成各种形式的内容,如文章、音乐、图片、视频等。
-
LLM(大语言模型):是专门用于执行NLP任务的语言模型
大的含义:训练数据大,参数规模大,耗资巨大 -
GAI(生成式人工智能):特指能生成全新内容的AI ,其生成的内容就是前面所提的AIGC , AIGC侧重内容生成的来源,而GAI侧重AI系统的功能特点
-
GAI:自回归生成技术随机性,不是搜索引擎
-
AGI(通用人工智能):GAI迭代成为AGI,机器能够完成人类能够完成的任何智力任 务的能力。
-
AGI仍然是一个理论上的概念,尚未有完全实现的案例
-
GPT(生成式预训练变换器):是一种基于Transformer结构的预训练模型。其系列模型包括GPT2 ,GPT3 ,GPT3.5 ,GPT4等
-
ChatGPT:采用GPT架构的聊天机器人
-
预训练(海量,无监督,目标是通用能力) :不针对特定任务,而是用大规模的数据训练模型,使其具 备各方面的基础能力,类似于我们人类的通识教育。
-
微调(小量,有监督,目标是任务适配)
-
DeepSeek V3:一个通用且高效的强大语言模型来处理各种文本生成、理解和
长文本任务。 -
DeepSeekR1:在复杂逻辑、数学和编程问题上的深度推理能力强,
展示其思考过程
区别:DeepSeekR1拥有思维链 -
思维链
- 一种让大型语言模型说出中间推理步骤的技术
- 目的:提升模型解决复杂推理问题(比如数学题、逻辑题)的能力
- 核心特点:可解释性,泛化性提升,提示词驱动
-
缩放定律:

-
RLHF(强化学习从人类反馈中对齐)
-
MOE(混合专家模型,Mixture of Experts)
-
RAG五步:查询解析,向量检索,文档过滤,上下文生成,答案整合
-
语言分割:分词方法:词级分词,字符级分词,子词级分词
-
提示词工程:通过设计输入文本(提示词)引导模型输出,无需更新参数,适合少样本场景。
-
提示词设计技巧:指令清晰化,示例提示,思维链提示
-
全参数微调:用下游任务数据更新预训练模型的所有参数,适合数据充足场景。
-
参数高效微调(PEFT)包括
- LoRA(低秩适配器):冻结预训练模型参数,仅训练少量适配器矩阵(如 1% 原参数),显著降低显存需求
- 其他方法:Prefix-Tuning(前缀微调)、QLoRA(量化 + LoRA),适用于消费级设备部署。
-

-
-
大模型的对齐就是确保大型语言模型(LLMs)的行为符合人类的意图、价值
观和道德标准。这不仅仅是让模型能理解和生成文本,更是要让它在执行任务时,
能够安全、有用且无害。可以把“对齐”想象成给一个拥有超高智商但可能缺乏社
会经验的孩子进行教育和引导,确保它不仅能解决复杂问题,还能以人类期望的
方式与世界互动

 浙公网安备 33010602011771号
浙公网安备 33010602011771号