第三次作业
1.天气网站爬取图片
1.1代码实现
单线程
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
def imageSpider(start_url):
try:
urls=[]
req=urllib.request.Request(start_url,headers=headers)
data=urllib.request.urlopen(req)
data=data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
images = soup.select("img")
for image in images:
try:
src = image["src"]
url = urllib.request.urljoin(start_url, src)
if url not in urls:
urls.append(url)
print(url)
download(url)
except Exception as err: print(err)
except Exception as err:
print(err)
def download(url):
global count
try:
count=count+1
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
req = urllib.request.Request(url,headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
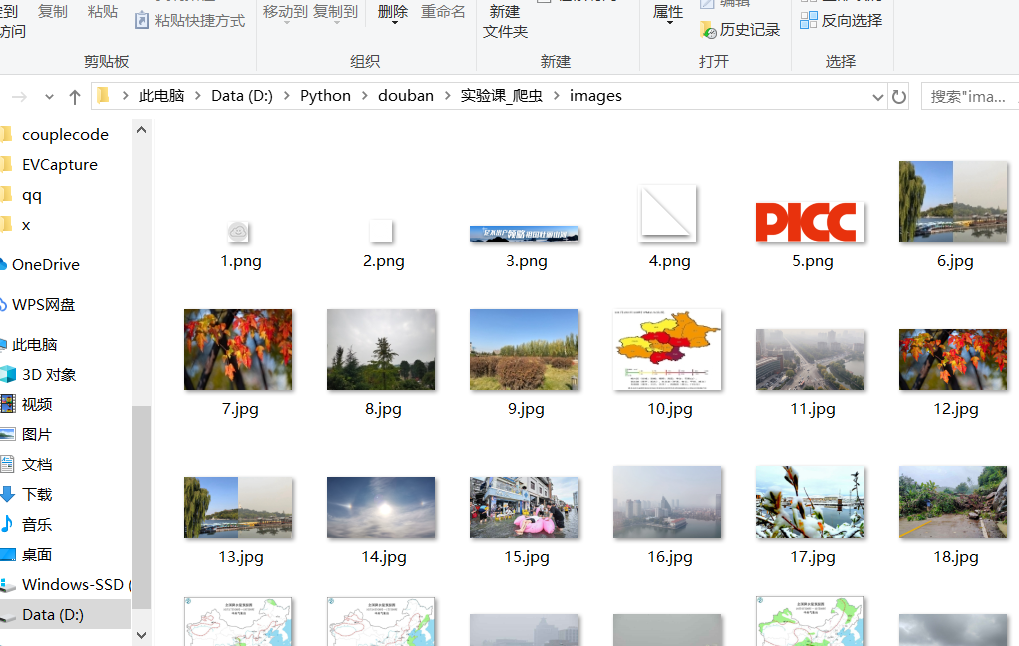
fobj = open("images\\" + str(count) + ext, "wb")
fobj.write(data)
fobj.close()
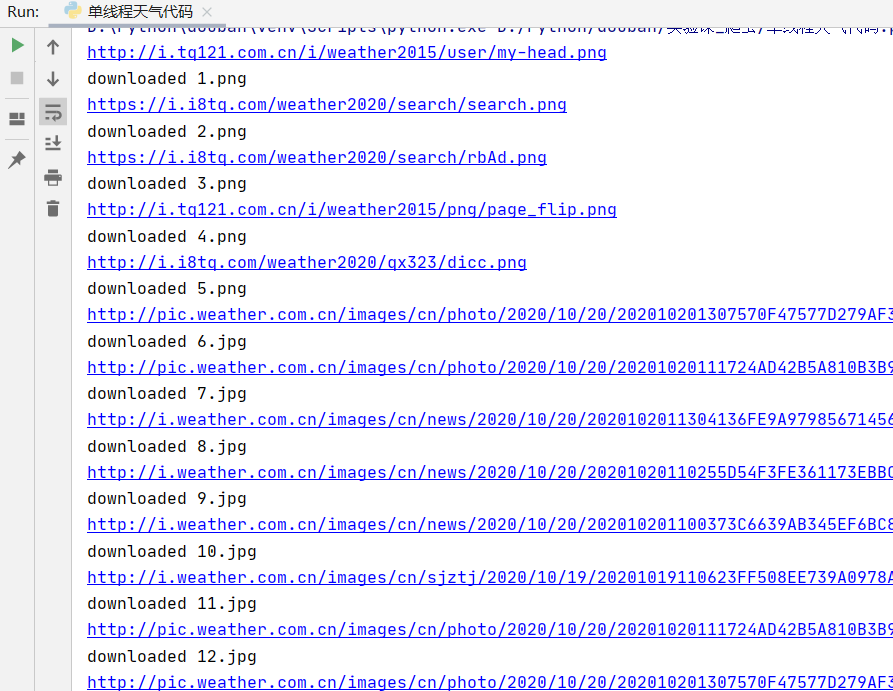
print("downloaded " + str(count) + ext)
except Exception as err:
print(err)
start_url="http://www.weather.com.cn/weather/101280601.shtml"
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
count=0
imageSpider(start_url)
多线程
"""
图像爬取的多线程实现
"""
from bs4 import BeautifulSoup
from bs4 import UnicodeDammit
import urllib.request
import threading
import time
def imageSpider(start_url):
global thread
global count
try:
urls = []
req = urllib.request.Request(start_url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "html.parser")
images1 = soup.select("img")
for image in images1:
try:
src = image["src"]
url = urllib.request.urljoin(start_url, src)
if url not in urls:
urls.append(url)
print(url)
count = count + 1
T = threading.Thread(target=download, args=(url, count))
T.setDaemon(False)
T.start()
thread.append(T)
except Exception as err:
print(err)
except Exception as err:
print(err)
def download(url, count):
try:
count=count+1
if (url[len(url) - 4] == "."):
ext = url[len(url) - 4:]
else:
ext = ""
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req, timeout=100)
data = data.read()
fobj = open("D:\Python\douban\实验课_爬虫\weather\\" + str(count) + ext, "wb")
fobj.write(data)
fobj.close()
print("downloaded " + str(count) + ext)
except Exception as err:
print(err)
print("More Threads Craw JPG Images")
start_url = "http://www.weather.com.cn/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US;rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
count = 0
thread = []
time_start = time.time()
imageSpider(start_url)
for t in thread:
t.join()
print("the End")
time_end = time.time()
time_using = time_end - time_start
print("More Threads Craw JPG Images Time Using:", time_using, 's')


1.2心得体会
照着网上和书上的代码操作了一下,单线程和多线程的操作自己也看了研究了很久,最后才知道这两个的代码需要怎么写。
2.用scrapy完成上面的任务
2.1代码实现
import scrapy
from ..items import WeatherPhotoItem
from scrapy.selector import Selector
class Spider_weatherphoto(scrapy.Spider):
name = "spiderweatherphoto"
start_urls=["http://www.weather.com.cn/"]
def parse(self, response):
try:
data = response.body.decode()
selector = Selector(text=data)
s=selector.xpath("//img/@src").extract()
for e in s:
item=WeatherPhotoItem()
item["photo"] = [e]
yield item
except Exception as err:
print(err)
import scrapy
class WeatherPhotoItem(scrapy.Item):
photo = scrapy.Field()
class WeatherPhotoPipeline():
def process_item(self, item, spider):
return item
from scrapy import cmdline
cmdline.execute("scrapy crawl spiderweatherphoto -s LOG_ENABLED=False".split())
BOT_NAME = 'scrapy_weather'
SPIDER_MODULES = ['scrapy_weather.spiders']
NEWSPIDER_MODULE = 'scrapy_weather.spiders'
ROBOTSTXT_OBEY = True
ITEM_PIPELINES = {
'scrapy.pipelines.images.ImagesPipeline':1
}
IMAGES_STORE=r'D:\Python\douban\实验课_爬虫\weather'
IMAGES_URLS_FIELD='photo'

2.2心得体会
在自己看了视频和教程之后依然不是很会scrapy的使用,在雷明的教导下才能理解scrapy的具体实现的和操作,雷明yyds。
3.scrapy爬取股票
3.1代码块实现
import scrapy
import json
import re
from ..items import GupiaodataItem
class spider_gupiao(scrapy.Spider):
name = "spidergupiao"
start_urls = ["http://75.push2.eastmoney.com/api/qt/clist/get?&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&fid=f3&fs=m:1+t:2,m:1+t:23&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1602901412583%20Request%20Method:%20GET"]
def parse(self, response):
try:
sites = json.loads(response.text)
data = sites["data"]
diff = data["diff"]
print(len(diff))
for i in range(len(diff)):
item = GupiaodataItem()
item["mount"] = str(i)
item["code"] = str(diff[i]["f12"])
item["name"] = str(diff[i]["f14"])
item["lately"] = str(diff[i]["f2"])
item["zhangdiefu"] = str(diff[i]["f3"])
item["zhangdiee"] = str(diff[i]["f4"])
item["chengjiaoliang"] = str(diff[i]["f5"])
item["chengjiaoe"] = str(diff[i]["f6"])
item["zhenfu"] = str(diff[i]["f7"])
item["zuigao"] = str(diff[i]["f15"])
item["zuidi"] = str(diff[i]["f16"])
item["jinkai"] = str(diff[i]["f17"])
item["zuoshou"] = str(diff[i]["f18"])
yield item
except Exception as err:
print(err)
import scrapy
class GupiaodataItem(scrapy.Item):
mount = scrapy.Field()
code = scrapy.Field()
name = scrapy.Field()
lately = scrapy.Field()
zhangdiefu = scrapy.Field()
zhangdiee = scrapy.Field()
chengjiaoliang = scrapy.Field()
chengjiaoe = scrapy.Field()
zhenfu = scrapy.Field()
zuigao = scrapy.Field()
zuidi = scrapy.Field()
jinkai = scrapy.Field()
zuoshou = scrapy.Field()
class GupiaoPipeline:
count = 0
def process_item(self, item, spider):
GupiaoPipeline.count += 1
# 控制输出格式对齐
tplt = "{0:^2}\t{1:^1}\t{2:{13}^4}\t{3:^5}\t{4:^6}\t{5:^6}\t{6:^6}\t{7:^10}\t{8:^10}\t{9:^10}\t{10:^10}\t{11:^10}\t{12:^10}"
try:
if GupiaoPipeline.count == 1: # count==1时,即第一次调用时新建一个txt文件,然后把item数据写到文件中
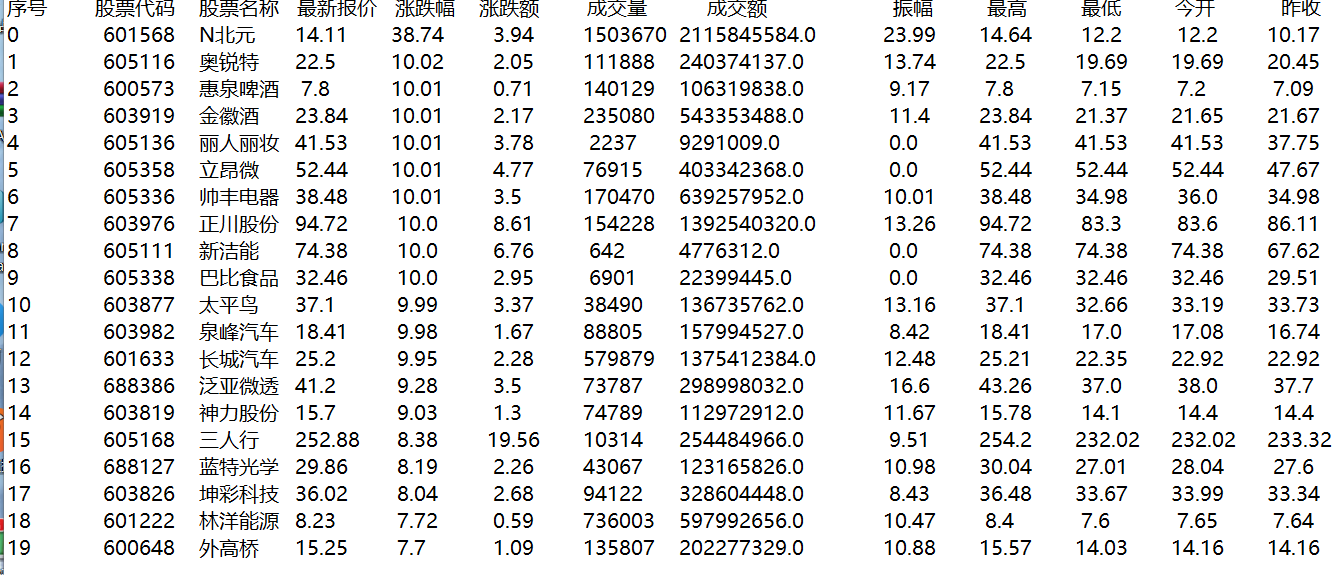
fobj = open("D:\Python\douban\实验课_爬虫\weather\data.txt", "wt") # 写入data.txt中
fobj.write("序号" + " 股票代码" + " 股票名称 " + " 最新报价 " + " 涨跌幅 " + " 涨跌额 " +
" 成交量 " + " 成交额 " + " 振幅 " + " 最高 " + " 最低 " + " 今开 " + " 昨收 " + "\n")
else: # 如果不是第一次调用count>1就打开已经存在的文件,把item的数据追加到文件中
fobj = open("D:\Python\douban\实验课_爬虫\weather\data.txt", "at")
# fobj.write("序号"+" 股票代码 "+" 股票名称 "+" 最新报价 "+"涨跌幅"+"涨跌额"+
# "成交量"+"成交额"+"振幅"+"最高"+"最低"+"今开"+"昨收"+"\n")
fobj.write(
tplt.format(item["mount"], item["code"], item["name"], item['lately'], item['zhangdiefu'],
item['zhangdiee'], item['chengjiaoliang'], item['chengjiaoe'], item['zhenfu'],
item['zuigao'], item['zuidi'], item['jinkai'], item['zuoshou'], chr(12288)))
fobj.write("\n")
fobj.close()
except Exception as err:
print(err)
return item
from scrapy import cmdline
cmdline.execute("scrapy crawl spidergupiao -s LOG_ENABLED=False".split())
BOT_NAME = 'gupiao'
SPIDER_MODULES = ['gupiao.spiders']
NEWSPIDER_MODULE = 'gupiao.spiders'
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'gupiao.pipelines.GupiaoPipeline': 300,
}
3.2心得体会
在经历和之前代码整理和再次查看的情况下,终于能够在相对独立的情况下(还是雷明教的)写了很多,最后做出的结果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号