
论文速读记录 | 2025年4月
待读论文不能超过2篇
Efficient Off-Policy Meta-Reinforcement Learning via Probabilistic Context Variables
- 来源:师弟推荐(ICML2019)
- bair blog
- Openreview
- keynotes:1、meta-learning之所以可行,是因为不同的任务之间存在共性结构,比如拧瓶盖和转动门把手都涉及用手抓住物体和旋转手腕。通过训练学习到的agent只需要一些新任务的trial就能成功适应。2、meta-training阶段,需要大量来自不同任务的数据,且大多数meta-RL方法都是on-policy,即训练和测试数据同分布,使得meta-training 更加Inefficient. 利用off-policy data for meta-training比较challenging.
- 目标:achieve both meta-training efficiency and rapid adaption.
- 方法:integrates online inference of probabilistic context variables wit existing off-policy RL algorithms.(probabilistic embeddings for actor-critic RL,PEARL)
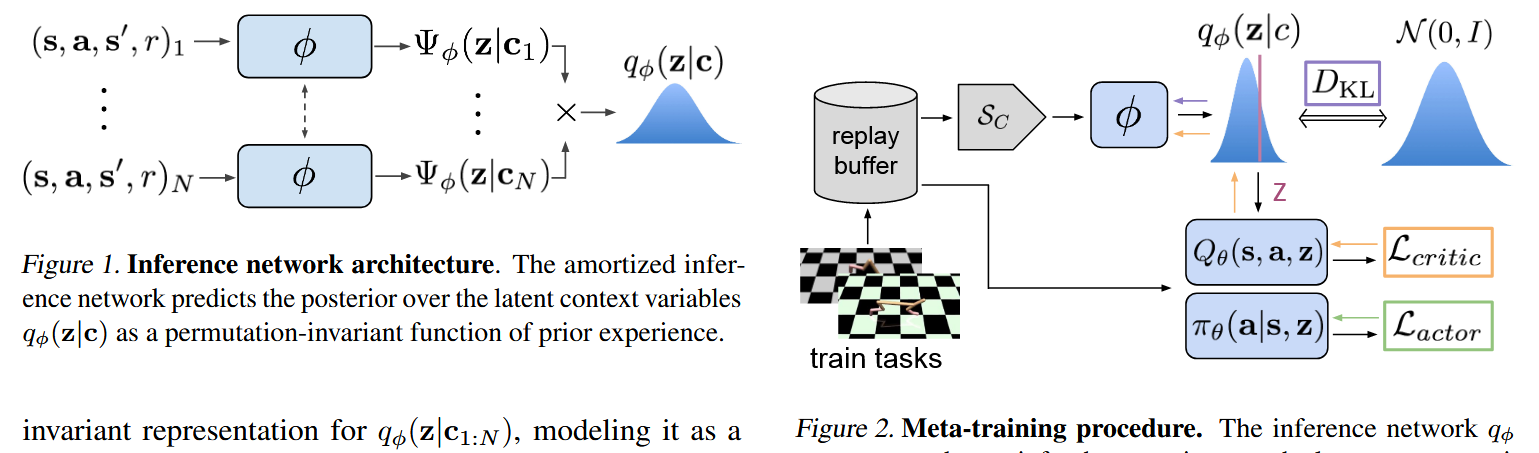
- 主要内容:为了利用off-policy数据,训练一个inference network(MLP输出高斯分布的均值和方差)\(q_{\phi}(z|c)\),其中c是context信息,\(c^{\Tau}_{1:N}={...,(s_n,a_n,r_n,s'_n)...}\),z是从c中提取的任务重要共性结构信息,即c的latent context表示,这里训练数据不是trajectory,而是unordered transistions。将这个推理网络与soft Actor-critic算法结合,\(Q_{\theta}(s,a,z),\pi_{\theta}(a|s,z)\)。在训练时,三个网络一起训练。由此,在推理时,使用训练好的inference network推断新任务的分布,再将其使用AC算法求解。

VariBAD: A Very Good Method for Bayes-Adaptive Deep RL via Meta-Learning
- 来源:ICLR2020
- openreview
- github
Goal Representations for Instruction Following: A Semi-Supervised Language Interface to Control
- 来源:bair blog (CORL2023)
- bair blog
- open review
- 之前工作:it is difficult to train robots to follow language instructions. Approaches like language-conditioned behavioral cloning (LCBC) train policies to directly imitate expert actions conditioned on language, but require humans to annotate all training trajectories and generalize poorly across scenes and behaviors.
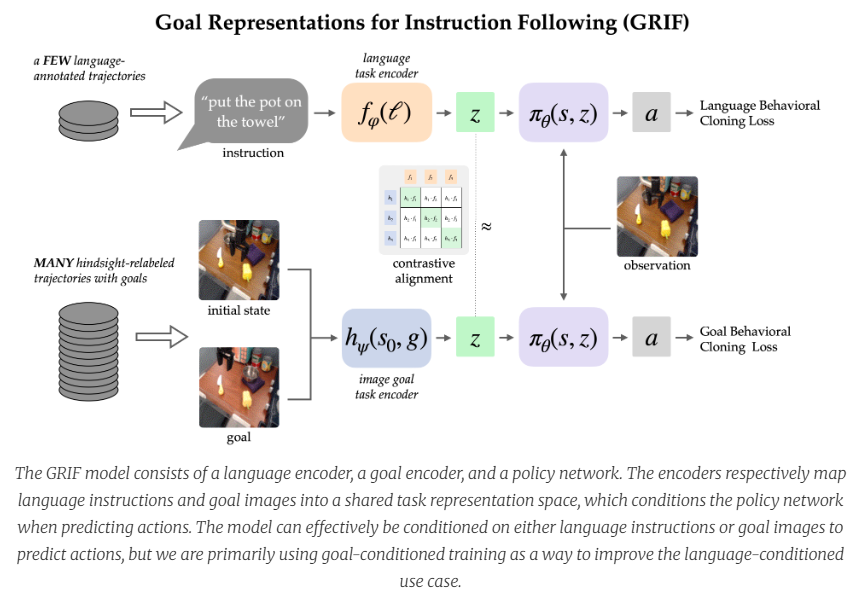
- 主要内容:之前的研究有将目标语言表示与图像变化对齐学习目标表征(representation),使用这个encoder+策略网络输出结果。对齐部分是基于改进的clip模型。这样做借鉴了多模态融合的思想。训练阶段是language-conditioned behavioral cloning (LCBC) and goal-conditioned behavioral cloning (GCBC)共同作用。
Vintix: Action Model via In-Context Reinforcement Learning
- 来源:arxiv
- hugging face
Emergence of in-context reinforcement learning from noise distillation
- 来源:Vintix (ICML2024)
- arxiv
- 主要内容
- 这篇文章主要关注ICRL领域数据集构建的问题,即降低训练数据集构建开销
- 这篇文章的setting是在Dark room\Dark key-to-dorr\Water maze这三个task上训练通用智能体
- 这篇文章的Motivation是此前的ICRL方案如AD和DPT的数据集构建消耗过多计算资源
- AD:数据集由源RL算法在上千任务上训练得到agent,由其训练历史数据构成。AD训练目的是预测学习算法的下一个动作。(Data collection with RL algorithms).训练RL agnet 消耗资源
- DPT: 可以使用随机策略产生的数据集,但必须先获得optimal policy以获得最佳动作,训练目的是预测最终RL算法的最佳动作.(Data collection with optimal actions).但optimal policy有时很难获得,仍需要训练RL agent.(DPT的数据集是从哪里搞的?)
- 这篇文章主要采用的技术是向一个策略(最优或者次优)添加逐渐衰减的噪声,以模拟数据集逐渐提升的过程。基于AD思想提出了\({AD}^{\varepsilon}\)
- 对于最优策略,向给定策略中添加随机噪声,噪声水平用\(\varepsilon\)表示,初始时\(\varepsilon\)为1,结束时为0,agent在过程中有\(1-\varepsilon\)概率选择原策略action,\(\varepsilon\)概率选择随机策略。在每次action之后降低\(\varepsilon\)。我们使用 ε = 0(最佳可用策略)收集最后 10% 的数据,因为它提高了训练过程的稳定性。(有点疑问,这里的给定策略是从哪来的?)
- 对于次优策略,\(\varepsilon\)初始仍为1,但最后并不下降到0,这使得最后的策略仍然包含有噪声,因而不是最佳的。
- 对于衰减速率(Learning Pace),证明了衰减速率对agent会产生影响,过快的衰减速率会导致收敛变快,但也可能错失探索更好动作的机会,过慢的衰减速率有可能导致无法或者有困难学习到数据集中的提升。
- 本文的实验主要针对三个场景
- In-context RL可以从noise-generated trajectories中产生
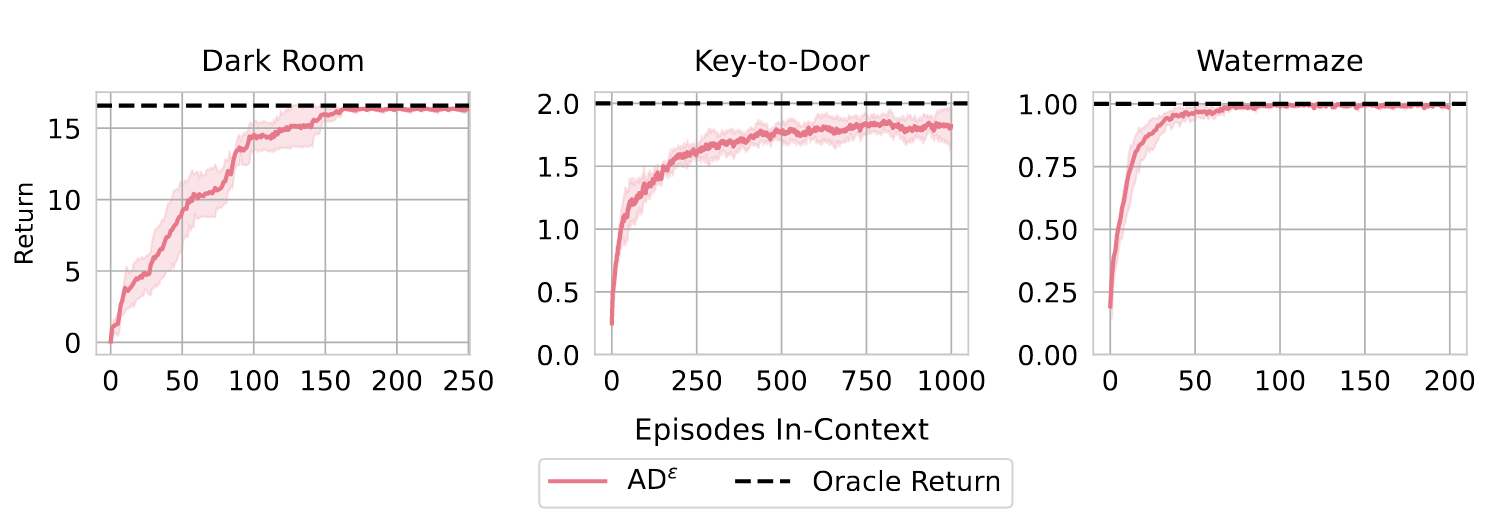
- ICRL可以从次优策略中学习,并超过它们
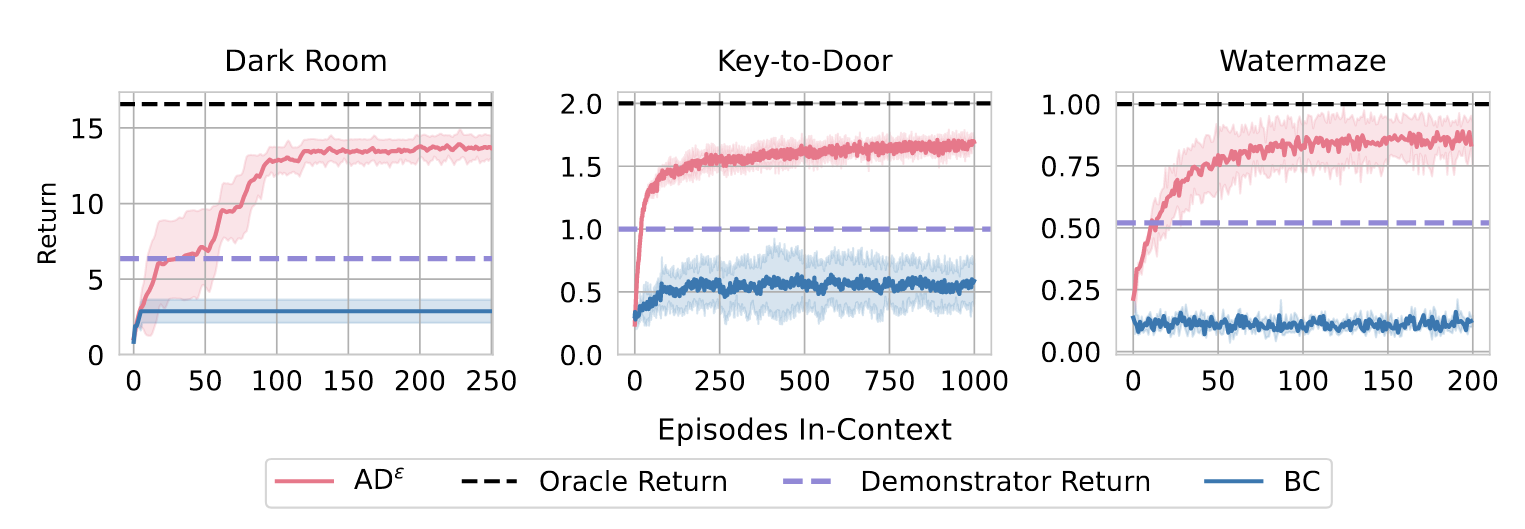
- ICRL可以从噪声数据集中解决基于像素环境的实验(如water-maze)
- 次优数据集的质量(即次优程度——通过\(varepsilon\)控制)会影响agent。过低的策略质量会导致agent无法学习如何解决后面的阶段问题(如Dark-key-to-door)
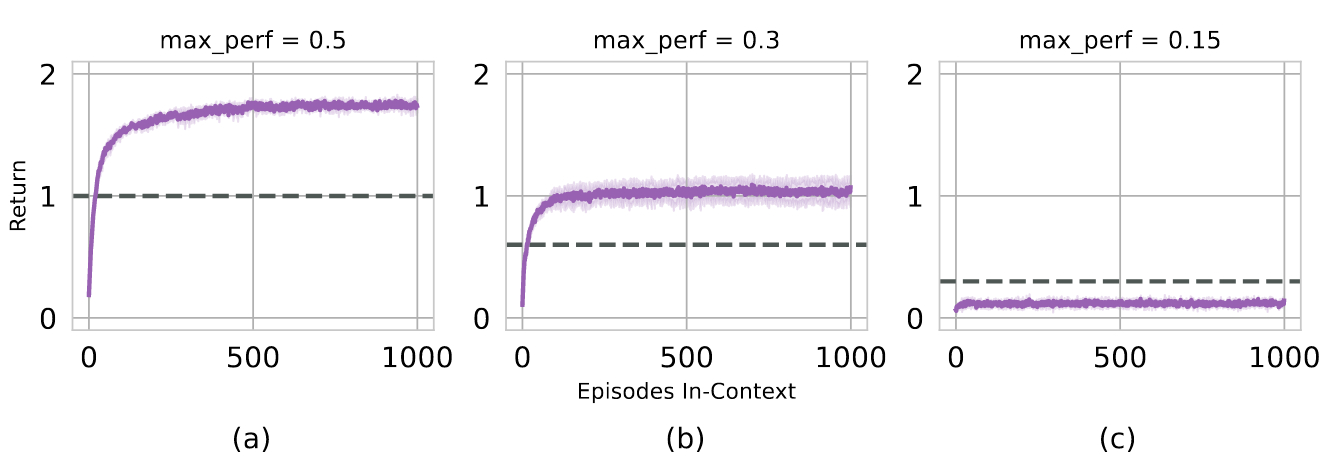
- learning pace会对agent产生影响。
- In-context RL可以从noise-generated trajectories中产生
- 这篇文章在ICRL数据集构建上做出了简化计算消耗的贡献,只要有给定策略就可以通过不同的随机加噪产生不同的任务训练轨迹,无需单独训练RL agent
When Do Transformers Shine in RL? Decoupling Memory from Credit Assignment
-
来源:NIPS2023 Oral
-
这篇文章讲了什么内容:
- 这篇文章想解决什么问题?
Transformer 在RL中取得了巨大的成功,但其原因没有得到深究。作者认为有必要探究在RL相关的两个重要指标——Memory(决定agent能利用多少历史信息)和Credit assignment(发现哪些动作值得分配奖励)受益于Tranformer的引入。 - 想研究的内容有什么难点?
1、缺少可以量化的指标。2、benchimark:Atari 和 mujoco 需要minimal memory 和 short-term credit assignment,产生了即时reward;另外 Dark key-to-door在midterm memory 和 credit assignment之间存在争议。 - 文章如何解决上面的问题?
1、提出memory length和credit-assignment length的数学定义。2、提出了Pasive and Active T-mazes可编辑环境,这个环境将memory和crdit-assignment区分开来。 - 本文的主要method:
- 这篇文章想解决什么问题?

 浙公网安备 33010602011771号
浙公网安备 33010602011771号