
面向对象第一单元作业总结
写在前面
经过一个单元的学习,我对于面向对象的思想有了一个基本的了解,在每次作业的编写和重构过程中,我的编写思路和风格都发生了巨大的变化。可以说,这一系列的作业让我受益匪浅,让我从一个只会面向过程的小白逐渐走上了面向对象的正道。
另外,在本次博客的写作中,我运用IntelliJ旗舰版的Diagrams功能绘制类图,用MetricsReloaded插件进行代码复杂度分析。
一、个人程序结构分析
第一次作业
我的第一次作业,平心而论,还没有进入面向对象的层次,仍然保留着许许多多c语言程序设计时的习惯。在第一次作业的设计中,我的主观设计思想就是将需要求导的每一项都化简为ax^b的形式,而后使用hashmap保存形如(a,b)的二元组,通过手动求导转换得到对应的导函数并进行输出。我将程序分为Mainclass-Expression-Item三级,通过Mainclass进行输入输出,在Expression中通过正则表达式匹配其中的项并传入Item类中,在Item类中再将项通过正则表达式划分为一个个因子,对它们进行化简合并,得到相应保存二元组的hashmap。而后,由得到的二元组表进行求导,得到对应导函数的二元组序列,并返回到Expression类中,在Expression类的求导函数中将返回的所有二元组序列合并为一个序列再返回到Mainclass进行输出。这样做的好处就是不必进行额外的化简操作,通过手动对ax^b进行求导直接就可以得到化简结果。然而,在这一构思中,我并没有很好的用到面向对象的思想,程序的可扩展性也不佳。
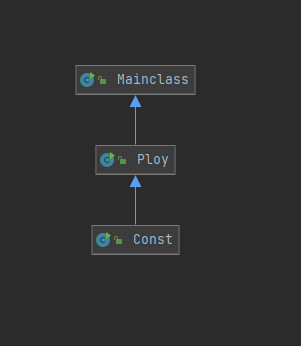
可以看出,第一次作业中三个类是完全直线性的关系,表达式由上到下传入,再由下到上的求导输出。使用Mainclass进行读入操作和最后的print操作,在后面两个类中对表达式和各个项进行求导。
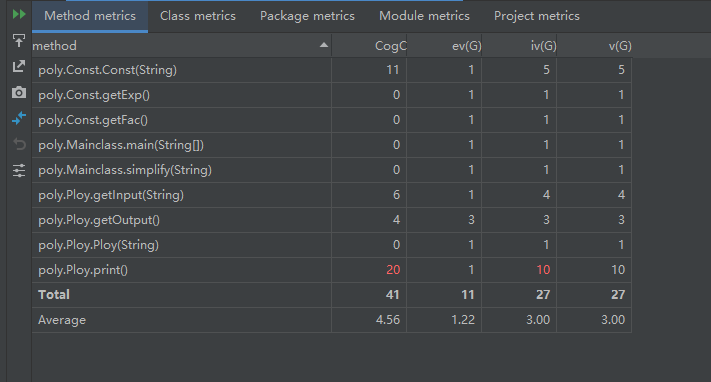
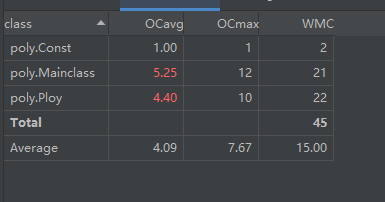
从复杂度上来看,第一次作业的复杂度不很乐观,Ploy类的复杂度主要来自对下面每一个项进行求导时进行的多次遍历,而Mainclass的复杂度是因为将所有的静态方法都放在了Mainclass中,导致过于繁杂。
第二次作业
第二次作业应该是我对于面向对象思想的一个小尝试,通体来说,额,有点失败。。。。。。在这次作业中,我为每一种因子创建了一个类,对于类与类之间的传递信息的四元组也创建了一个单独的类。这一阶段,我对于面向对象的理解仍然停留在创造更多的类上。本次作业是对第一次作业的延续,我通过把每一个项都化简为ax^bsin(x)^ccos(x)^d的形式,然后保存四元组进行求导运算。
在第二次作业的过程中,我对于正则表达式进行了充分的尝试,但是在了解到java8的正则表达式不支持递归时,我认识到不可能通过正则表达式来解决项中包含嵌套的括号的情况,因此,我转而使用正则表达式匹配符合条件的'+',使用它分割表达式内的项,再使用'*'来分割项中的因子,从而起到第一次作业中正则表达式的作用。

(最多只能构建各个因子以及项的正则表达式,对于整个表达式而言,无法处理嵌套括号的情况)

这是第二次作业的类图,为每一个因子创建了一个类储存本身的信息,上层仍是使用Item-Poly两级来对表达式和项进行求导,借由Mainclass进行输入输出。为了在类与类之间传递信息方便,使用Tetrad类保存一个诸如(a,b,c,d)的四元组。
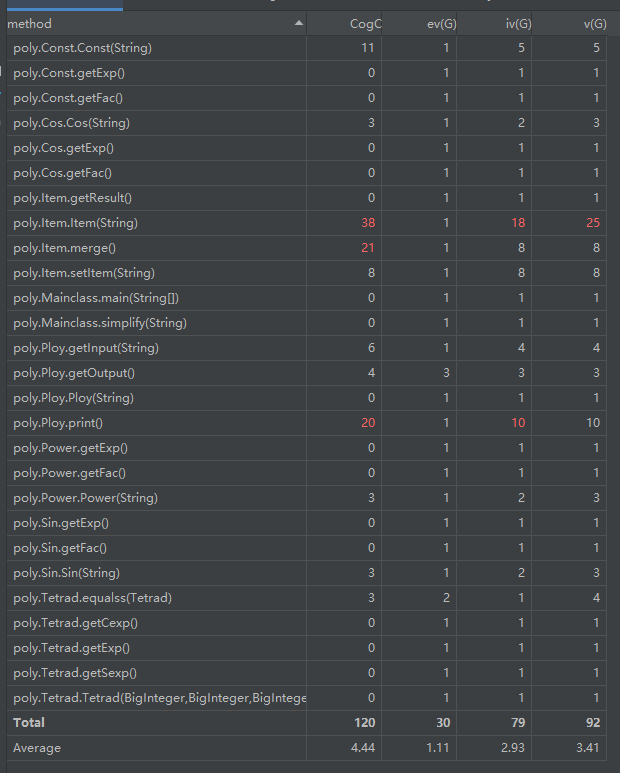

由上图可以看出,复杂度过多的部分主要来自于Item类和Poly类中的print函数,Item类需要直接进行求导操作,进行了多次循环和判定,而print函数主导形成输出的字符串,为了实现导数的化简,进行了大量的特判。
第三次作业
由于第三次作业中sin和cos中允许包含表达式,原来四元组的形式无法满足现在的需求,因此我选择了重构。从这一次作业开始,我才算初步领悟了面向对象的思想。通过读入表达式,将表达式转化为表达式树,然后递归求导的方式获得表达式的导数,我解决了本次作业中的求导的需求。我首先设置了一个Operation的抽象类,并以此为基础通过继承的方式建立了各个因子以及各种运算的类,将求导和t输出完全封装到了对应的类中,然后在Main函数中进行对于错误格式的判断和输入,实现了输入输出和运算的分离。
但是,这一设计也有很大不足,主要体现在对于错误格式表达式的判定上。我使用有限状态机的方式进行判错,产生了许多需要特判的情况,降低了程序的可靠性,同时也较大的增加了程序的复杂度,得不偿失。
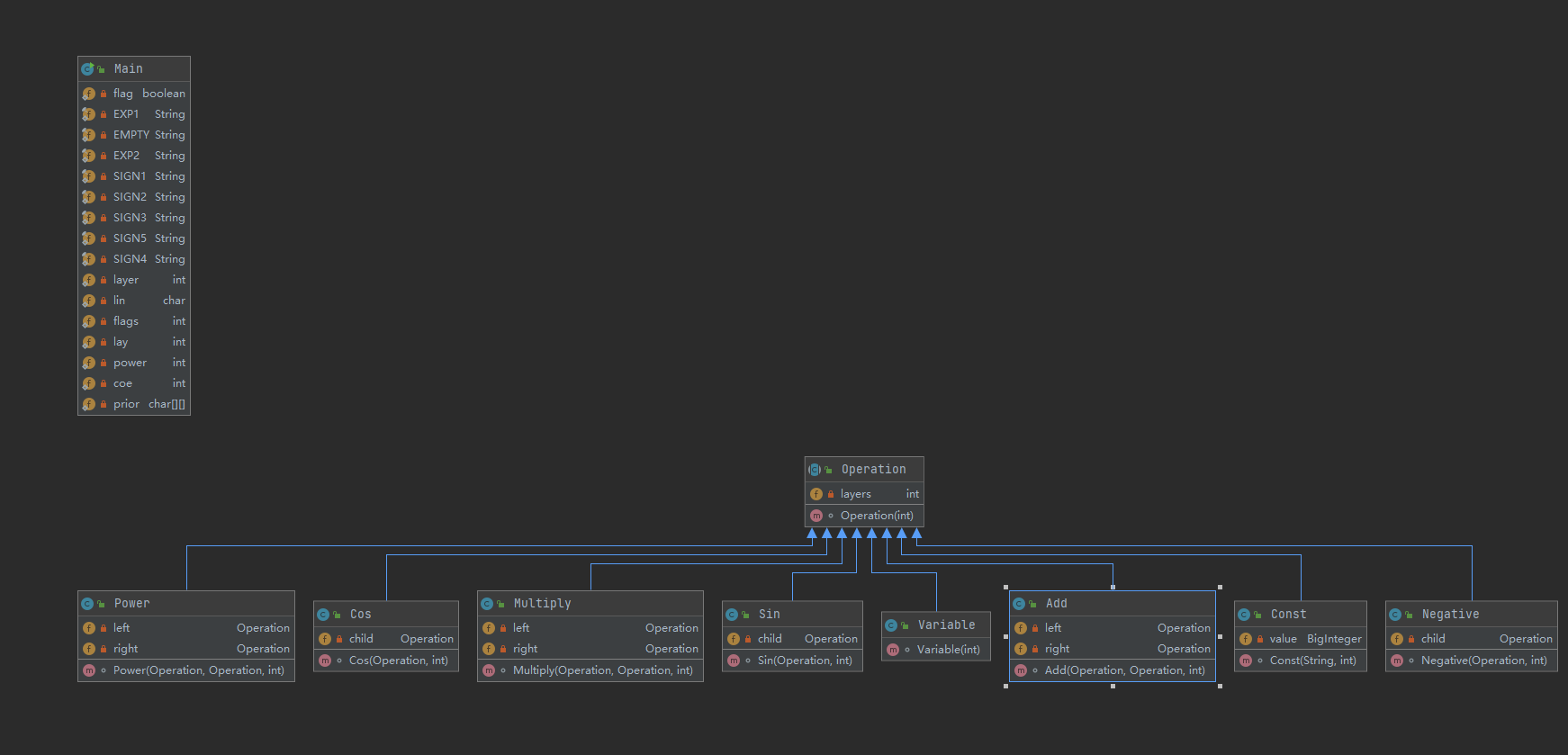
第三次作业的类图相对扁平,所有的因子类都继承于一个抽象类Operation,将求导和toString方法分割到各个因子类之中,由Main进行输入输出,判错以及建立表达式树的过程。
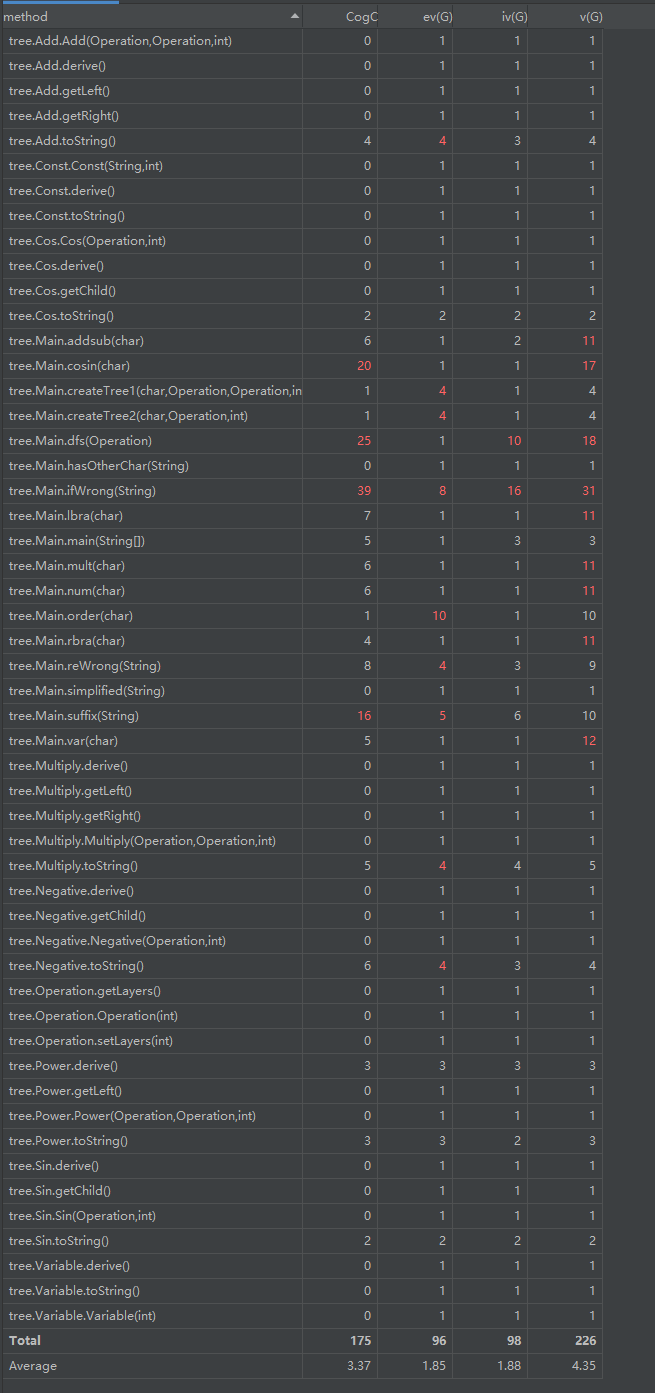
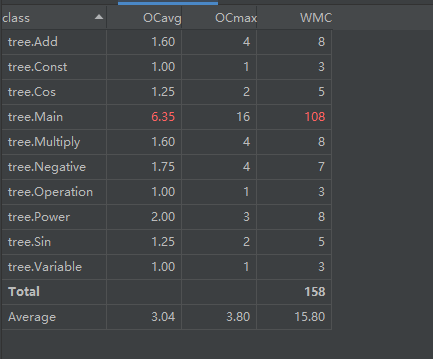
第三次作业中复杂度几乎全部来自于Main函数,具体一点是都来自于判断错误的表达式的环节,我使用了有限状态机的方式进行判错,需要遍历输入字符串并进行大量特判,极大的影响了复杂度。由于时间紧张,我在如何判断错误的表达式的方法上没能思考清楚就进行了代码的编写,导致了这一不良现象的发生。
二、个人程序bug分析
第一次作业的bug出现在读题和理解问题上。由于没有完全理解题目,忽略了可能出现的三个加号或减号连续出现的情况,造成了错误。
第二次作业的bug问题较大,由于对于括号的处理方式有欠缺,导致我的程序对于符号和括号直接相邻的情况无法做出正确的判断,同时,我还犯了一个很低级的也是初学者非常容易出现的错误------在迭代循环中对arraylist的内容进行remove,导致了runtimeerror。
第三次作业的bug出现在对于错误格式的判断上,由于我使用有限状态机的方式进行判断,需要特判的情况太多,漏掉了指数中出现幂函数不合法的情况,导致强测有一个点没有过。
在三次作业的bug中,我总结到,容易出现bug的地方一般都是进行特判的地方和特殊情况之处,因此,我认为特判情况越少的方法,一般都是更加优秀的情况,这一方法一般代码也更加优美易读。
三、互测策略概述
在互测中,我采用使用特殊值和临界值进行测试的方法。第一次作业中,我利用python的sympy库建立了一个随机生成数据并进行测试的脚本,但是由于数据太随机,导致了很难试出错误。因此我采用自己构造数据的方式,在第一次和第二次作业中,我使用x**-1和-sin(x)两个特殊值成功hack掉了5名同学。对于临界值的测试,我则围绕题目要求的长度和指数大小的条件进行测试,通过构建多层括号的测试数据,hack掉了两名输出过长的同学。
关于结合代码测试的方法,我首先会把代码通读一遍(主要针对判断特别多的同学),观察他的特判有没有不合适之处,有没有对于输出零的情况进行特判,然后构造相应的特殊样例。这种情况主要和特殊判例有关。
四、重构经历总结
在第一次作业中,我仅仅进行了一次重构,是为了解决原来的架构无法解决三角函数内含表达式的情况,因为我没有使用原方法写出第三次作业,因此无法进行对照。但是,通过在第三次作业中的重构,我发现使用类似递归下降加表达式树求导的方式,在迭代开发中十分方便,第二次到第三次作业甚至只需要修改几十行代码即可完毕,十分方便。由此可见,使用正确的方法完成任务,事半功倍。
五、个人心得体会
在第一次作业的编写和学习中,我的体会很深,主要集中在以下几个方面:
首先,跟优秀的展示代码对比后,虽然思路大体一致,但是在一些细节设计上还是有很大的差距,比如字符串的预处理方式,因子中方法的构造方式,try-catch结构等,另外,在互测中,发现有一位大佬每次使用系统alert输出运算的中间步骤,输出划分的项和因子,给我以很大震撼,通过这种方式,不但可以使得计算过程清晰易懂,还可以使得调试过程更加简单,并为今后的多线程调试创造条件。因此,多阅读他人优秀的代码,对于提高自身有很大作用。
其次,我觉得我最大的问题还是对代码测试的积极性不足。太过于依赖中测数据进行debug,有点为了完成任务才debug,没有那种为了自己的代码臻于完美而不断优化的积极性。每一次代码的测试都特别依靠系统中测,从而给我自己的代码测试造成了很不好的影响。
再次就是架构的问题,一个优秀的架构真的是可以事半功倍的!!!因此,多花些时间在架构的构建上,将所有的细节都想明白再编写相应的代码,不要心急,对于代码的编写尤其重要。
最后,我深刻的感受到了同学之间交流讨论的重要性,通过讨论,每个人的方法都可以不断优化,还可以学习到许许多多不同的思路,对于我们的学习,对于编写代码思路的进步有着重要的意义。
