01 大数据概述
1.用图表描述Hadoop生态系统的各个组件及其关系。
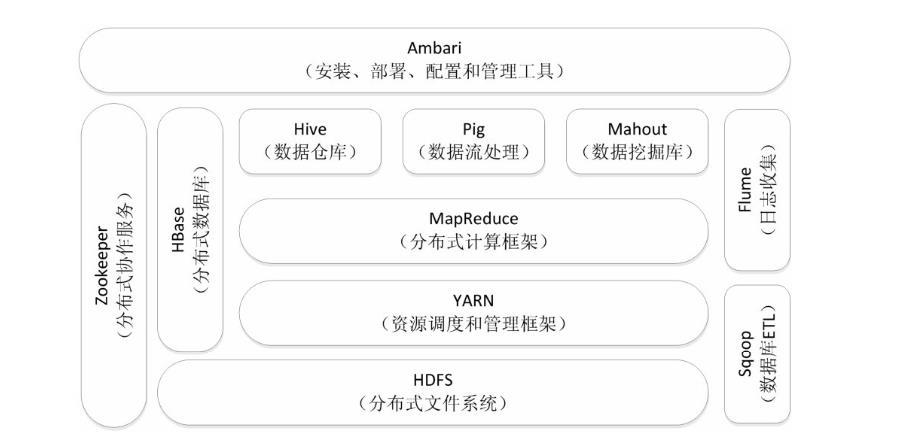
MapReduce:主要由Google Reduce而来,它简化了大型数据的处理,是一个并行的,分布式处理的编程模型。
YARN的全称是Yet-Another-Resource-Negotiator。Yarn可以运用在S3|Spark等上。hadoop2.0它是基于YARN框架构建的。
HDFS:它是由Google File System而来,全称是Hadoop Distributed File System,是Hadoop的分布式文件系统,有许多机器组成的,可以存储大型数据文件。它是由NameNode和DataNode组成,NameNode可以配置成HA(高可用),避免单点故障。一般用Zookeeper来处理。两个NameNode是同步的。
Hive:它是Hadoop的数据仓库(DW),它可以用类似SQL的语言HSQL来操作数据,很是方便,主要用来联机分析处理OLAP(On-Line Analytical Processing),进行数据汇总|查询|分析。
HBase:它是由Google BigTable而来。是Hadoop的数据库。HBase底层还是利用的Hadoop的HDFS作为文件存储系统,可以利用Hadoop的MR来处理HBase的数据,它也通常用Zookeeper来做协同服务。
Zookeeper:它是一个针对大型分布式系统的可靠协调系统,在Hadoop|HBase|Strom等都有用到,它的目的就是封装好复杂易出错的关键服务,提供给用户一个简单|可靠|高效|稳定的系统。提供配置维护|分布式同步|名字服务等功能,Zookeeper主要是通过lead选举来维护HA或同步操作等
Pig:它提供一个引擎在Hadoop并行执行数据流。它包含了一般的数据操作如join|sort|filter等,它也是使用MR来处理数据。
Mahout:它是机器学习库。提供一些可扩展的机器学习领域经典算法的实现,目的是帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐算法等。
2.阐述Hadoop生态系统中,HDFS, MapReduce, Yarn, Hbase及Spark的相互关系。
HDFS
传统的文件系统是单机的,不能横跨不同的机器。HDFS(Hadoop Distributed FileSystem)的设计本质上是为了大量的数据能横跨成百上千台机器,但是你看到的是一个文件系统而不是很多文件系统。
HDFS是Hadoop体系中数据存储管理的基础,它是一个高度容错的系统,能检测和应对硬件故障,在低成本的通用硬件上运行。HDFS简化了文件的一次性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适用带有数据集的应用程序。HDFS提供一次写入多次读取的机制,数据以块的形式,同时分布存储在不同的物理机器上。
比如你说我要获取/hdfs/tmp/file1 的数据,你引用的是一个文件路径,但是实际的数据存放在很多不同的机器上。你作为用户,不需要知道这些,就好比在单机上你不关心文件分散在什么磁道什么扇区一样。HDFS 为你管理这些数据。
MapReduce
虽然 HDFS 可以为你整体管理不同机器上的数据,但是这些数据太大了。一台机器读取成 T上P的数据,也许需要好几天甚至好几周。如果要用很多台机器处理,就面临了如何分配工作,如果一台机器挂了如何重新启动相应的任务,机器之间如何互相通信交换数据以完成复杂的计算等等。
MapReduce是第一代计算引擎。MapReduce是一种分布式计算模型,用以进行海量数据的计算。它屏蔽了分布式计算框架细节,将计算抽象成Map 和Reduce两部分,其中Map对数据集上的独立元素进行指定的操作,生成键-值对形式中间结果。Reduce则对中间结果中相同“键”的所有“值”进行规约,以得到最终结果。MapReduce非常适合在大量计算机组成的分布式并行环境里进行数据处理。
Spark
Tez和Spark是第二代计算引擎。除了内存 Cache 之类的新 feature,本质上来说,是让 Map/Reduce 模型更通用,让 Map 和 Reduce 之间的界限更模糊,数据交换更灵活,更少的磁盘读写,以便更方便地描述复杂算法,取得更高的吞吐量。
有了 MapReduce之后,程序员发现,MapReduce 的程序写起来真麻烦。之前的 Map Reduce 类似于汇编语言,那么现在的 spark 就类似于 python 了,功能和 Map Reduce 类似,但是对于开发人员更加的友好,更方便使用。
大数据处理框架,是Hadoop生态中发展迅速的成员。Spark的核心在于内存计算模型直指“同门产品”——MapReduce离线计算模型。MapReduce是单流程的优秀解决方案,在数据处理过程中每一步都要经过Map阶段和Reduce阶段,对于需要多流程计算和算法的用例来说,并非十分高效。作为一个批处理工具,MapReduce更适合做离线处理,而Spark是在内存中处理数据,可以处理实时数据。
MapRedcue先于Spark出现,也曾风骚一时。当初MapReduce选择磁盘,除了要保证数据存储安全之外,另一个主要原因是大容量内存的价格高昂,如果一开始就选择基于内存的解决方案,可能很难推广。而Spark的出现赶上了好时候,中大型公司有能力部署多台大内存机器,可以直接处理线上数据。
Hive
你希望有个更高层更抽象的语言层来描述算法和数据处理流程。于是就有了 Hive。
Hive 用 SQL 描述 MapReduce。它把脚本和 SQL 语言翻译成 MapReduce 程序,丢给计算引擎去计算,而你就从繁琐的 MapReduce 程序中解脱出来,用更简单更直观的语言去写程序了。之前直接利用 spark 需要处理 map 和 reduce 的过程对于使用者来说都是隐形的了,就像使用本地数据库一样使用大数据文件。
例如wordcount 任务来说,通过 hive,我们可以通过几句 SQL 语句就可以达到类似的目的。类似于:
select word, count(*) from word_table group by word;
SqarkSQL 和 Hive on Spark
自从数据分析人员开始用 Hive 分析数据之后,它们发现,Hive 在 MapReduce 上跑,很慢!
它们的设计理念是,MapReduce 慢,但是如果我用新一代通用计算引擎 Tez 或者 Spark 来跑 SQL,那我就能跑的更快。而且用户不需要维护两套系统。
Yarn
有了这么多乱七八糟的工具,都在同一个集群上运转,大家需要互相尊重有序工作。所以另外一个重要组件是,调度系统,现在最流行的是 Yarn。
Yarn它是一个通用资源管理系统,可为上层应用提供统一的资源管理和调度,它的引入为集群在利用率、资源统一管理和数据共享等方面带来了巨大好处。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号