spss基本使用
整个spss界面分为数据视图、变量视图和输出文档。
一、关于变量
1.变量名称不可重复;变量中的英文字母不区分大小写;变量中不能出现空格、括号、逗号等特殊字符;不可使用保留字
2.变量类型常用的有数值、日期和字符串
3.标签是对变量名称的解释说明,一般变量名称越简洁越好,而标签可对变量对名称做详细解释
4.值一般在该变量有有限个值的情况下使用,例如性别用1表示男2表示女,满意度用1-5不同级别的数值表示。
设置值之后,如果数据视图的视图->值标签勾选,对应的值会显示为值对应的标签,不勾选则显示值,例如1表示男2表示女,勾选则显示男或女否则显示1或2
5.设置缺失值表示在做统计时,将变量值等于该缺失值的记录当作无效记录处理。
6.度量标准
- 名义:无序分类变量,表示的变量值是离散的,一般用来代表某物的一个属性,不具有顺序和大小,例如性别
- 序号:有序分类变量,表示变量的值是离散的但是值之间有顺序关系,一般是用来定义等级差别的,例如满意度
- 度量:连续变量,表示变量的值通常是连续的,不仅可以进行排序而且还能进行加减,例如工资
二、常用操作
1.数据->选择个案
选择:默认选择全部个案,还可按条件或随机样本数选择
选择后的处理:默认在未被选择的个案序号上画斜线,后续统计时不统计该部分,也可将选定的个案复制到新的数据集,或者直接删除未选定个案(使用前建议保存原数据)
数据->加权个案,可选定变量作为频率变量
2.数据->拆分文件,不会生成新的文件,只在统计结果输出上有区别
默认是分析所有个案,结果不做拆分和分类
拆分文件并比较组:会按照分组变量一起输出结果
拆分文件并按组组织输出:会按照分组变量单独输出每个结果
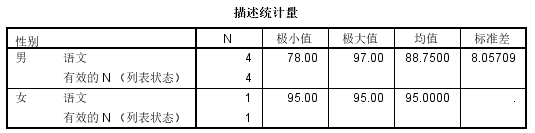
例如按照性别对语文成绩进行描述统计,3种方式的输出结果如下图所示


数据->合并文件->添加个案,即添加记录
数据->合并文件->添加变量,即添加变量
3.转换->替换缺失值
默认使用序列的均值进行替换,也可使用线性插值法和点处的线性趋势进行替换
也可使用临近点的均值和临近点的中位数来进行替换缺失值,这两种方法需要指定临近点的个数
4.分类汇总,会生成新的列
分组变量:即分类依据的变量
变量摘要:即分类后对哪些变量进行汇总,汇总函数默认为均值,名称为变量名称_mean,可自行选择汇总函数和汇总产生的列名称
5.数据统计
转换->计算变量,会生成新的列
可对多个变量进行统计,例如统计多门学科的均值、各种类型工资的总和
转换->对个案内的值计数,会生成新的列
统计指定变量满足条件的变量个数
6.重新编码
转换->重新编码为不同变量,会生成新的列
对指定变量按照值的范围划分为不同的等级,例如将成绩为60分以下的划为不合格90分以上的划为优秀
转换->重新编码为相同变量,与重新编码为不同变量类似,但是不会生成新的列,而是直接替换原变量的值
转换->自动重新编码,系统会自动进行范围划分和等级设定
三、基本的统计分析
1.t检验
位置:分析->比较均值
作用:比较两个平均数的差异是否显著
使用前提:主要用于样本含量较小(例如n < 30)、总体标准差σ未知的正态分布。当样本较小时,要求样本取自正态总体;做两样本均数比较时,要求两样本的总体方差相等。
单样本t检验:检验单样本均值与确定的总体均值是否存在显著性差异,例如检验2018年的平均工资与2015年的平均工资(已知值)的差异
独立样本t检验:检验两个独立的样本的均值是否存在显著性差异,例如检验男性平均工资与女性平均工资的差异
配对样本t检验:检验两个配对样本是否存在存在显著性差异,例如检验本次学生成绩与上次成绩的差异
2.方差分析,即F检验
位置:分析->非参数检验->旧对话框
作用:检验自变量对观测变量的显著影响
使用前提:数据总体呈正态分布,多组样本的方差要齐性,各个观测值相互独立
单因素方差分析:检验一个自变量对一个观测变量的显著影响,分析->比较均值->单因素ANOVA
- LSD:最小显著差法,t检验的简单变形
- Bonferroni:在LSD的基础上改进,比LSD更严格
- Tukey:
双因素方差分析:检验两个自变量对一个观测变量的显著影响,分析->一般线性模型->单变量(指一个因变量) (一般模型选择默认的全因子,对比选择简单,两两比较选择自变量组别超过3的变量,选项估计均值选择overall、输出选择前3项)
多元方差分析:检验自变量对多个观测变量的显著影响,分析->一般线性模型->多变量
重复测量方差分析:例如测量饮酒在上午和下午对人的意识影响,分析->一般线性模型->重复度量
3.相关性分析
位置:分析->相关
作用:研究变量之间的相关关系
皮尔逊相关系数尽量要求样本数量大于30,而斯皮尔曼相关系数对样本数量无要求但精度没有皮尔逊系数高。
双变量:研究两个变量之间的相关性关系,例如研究各个市的专利数量与GDP的相关关系
偏相关:研究变量的控制变量在一定情况下变量的相关性关系,例如高校数量可能影响专利数量和GDP,则在将高校数量作为控制变量的基础上对专利和GDP进行相关性分析
距离:研究多个变量之间的距离,例如各个国家的资源的差距。
4.回归分析
回归分析是相关性分析更具体的分析。
步骤:1提出回归模型假设,即获取样本,确定自变量和因变量
2.获取数据建立回归方程
3.确定回归方程
4.回归方程检验,包括回归方程的显著性、回归方程的拟合度检验、回归系数的显著性检验
5.关联分析
包括关联规则挖掘和序列模式挖掘,
作用:在数据中挖掘重复出现概率很高的模式或规则。
6.非参数检验
适用于小样本、或样本分布不满足正态分布、样本来自不同总体的检验;如果样本满足参数检验的条件,应优先使用参数检验。
- 检验效能低,这是由于对样本数据要求低
- 没有充分利用数据的全部信息,例如符号检验只考虑到成对数据的正负数量情况,而不考虑数据的大小
- 无法处理变量之间的交互作用
正态分布检验
分析->非参数检验->旧对话框-> 1-样本 K-S
分析->描述统计->探索,在绘制选项里勾选待检验的正态图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号