基于docker的spark-hadoop分布式集群之二: 环境测试
在上一章《环境搭建》基础上,本章对各个模块做个测试
Mysql 测试
1、Mysql节点准备
为方便测试,在mysql节点中,增加点数据
进入主节点
docker exec -it hadoop-maste /bin/bash
进入数据库节点
ssh hadoop-mysql
创建数据库
create database zeppelin_test;
创建数据表
create table user_info(id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,name VARCHAR(16),age INT);
增加几条数据,主键让其自增:
insert into user_info(name,age) values("aaa",10);
insert into user_info(name,age) values("bbb",20);
insert into user_info(name,age) values("ccc",30);
2、Zeppelin配置
配置驱动及URL地址:
default.driver ====> com.mysql.jdbc.Driver
default.url ====> jdbc:mysql://hadoop-mysql:3306/zeppelin_test
使zeppelin导入mysql-connector-java库(maven仓库中获取)
mysql:mysql-connector-java:8.0.12
3、测试mysql查询
%jdbc
select * from user_info;
应能打印出先前插入的几条数据。
Hive测试
本次使用JDBC测试连接Hive,注意上一节中,hive-site.xml的一个关键配置,若要使用JDBC连接(即TCP模式),hive.server2.transport.mode应设置为binary。
1、Zeppelin配置
(1)增加hive解释器,在JDBC模式修改如下配置
default.driver ====> org.apache.hive.jdbc.HiveDriver
default.url ====> jdbc:hive2://hadoop-hive:10000
(2)添加依赖
org.apache.hive:hive-jdbc:0.14.0
org.apache.hadoop:hadoop-common:2.6.0
2、测试
Zeppelin增加一个note
增加一个DB:
%hive
CREATE SCHEMA user_hive
%hive
use user_hive
创建一张表:
%hive
create table if not exists user_hive.employee(id int ,name string ,age int)
插入数据:
%hive
insert into user_hive.employee(id,name,age) values(1,"aaa",10)
再打印一下:
%hive
select * from user_hive.employee
所有的操作,都是OK的。
另外,可以从mydql中的hive.DBS表中,查看到刚刚创建的数据库的元信息:
%jdbc
select * frmo hive.DBS;
如下:
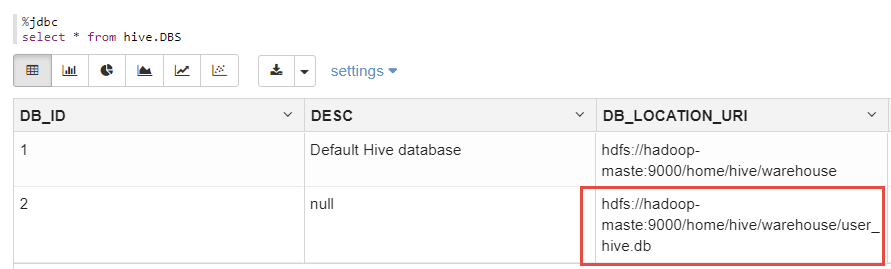
上图显示了刚刚创建的DB的元数据。
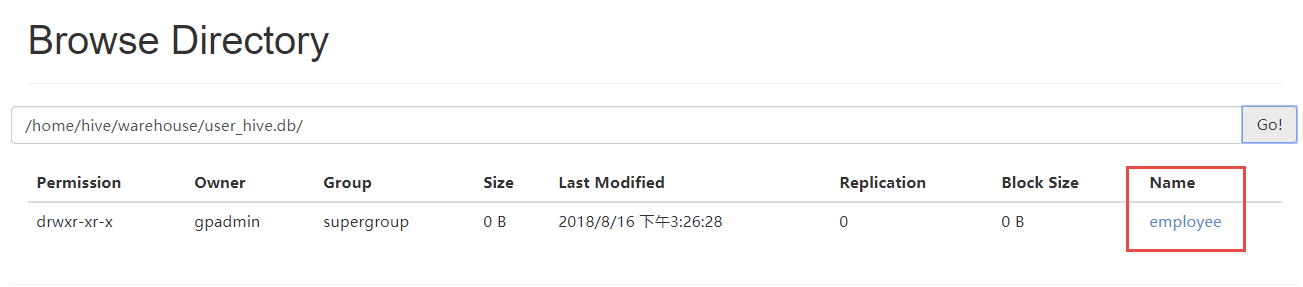
登录Hadoop管理后台,应也能看到该文件信息(容器环境将Hadoop的50070端口映射为宿主机的51070)
http://localhost:51070/explorer.html#/home/hive/warehouse/user_hive.db
可以看到,user_hive.db/employee下,有刚刚创建的数据文件,如下:
分布式测试
在上一节基础上,进入主从节点,可以看到,在相同的目录下,都存在有相同的数据内容,可见上一节对于hive的操作,在主从节点是都是生效的。操作如下:
主节点:
root@hadoop-maste:~# hdfs dfs -ls /home/hive/warehouse/user_hive.db/employee
Found 1 items
-rwxr-xr-x 2 gpadmin supergroup 9 2018-08-15 11:36 /home/hive/warehouse/user_hive.db/employee/000000_0
从节点:
root@hadoop-node1:~# hdfs dfs -ls /home/hive/warehouse/user_hive.db/employee
Found 1 items
-rwxr-xr-x 2 gpadmin supergroup 9 2018-08-15 11:36 /home/hive/warehouse/user_hive.db/employee/000000_0
测试 Spark 操作 hive
通过spark向刚才创建的user_hive.db中写入两条数据,如下:
import org.apache.spark.sql.{SQLContext, Row}
import org.apache.spark.sql.types.{StringType, IntegerType, StructField, StructType}
import org.apache.spark.sql.hive.HiveContext
//import hiveContext.implicits._
val hiveCtx = new HiveContext(sc)
val employeeRDD = sc.parallelize(Array("6 rc 26","7 gh 27")).map(_.split(" "))
val schema = StructType(List(StructField("id", IntegerType, true),StructField("name", StringType, true),StructField("age", IntegerType, true)))
val rowRDD = employeeRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).toInt))
val employeeDataFrame = hiveCtx.createDataFrame(rowRDD, schema)
employeeDataFrame.registerTempTable("tempTable")
hiveCtx.sql("insert into user_hive.employee select * from tempTable")
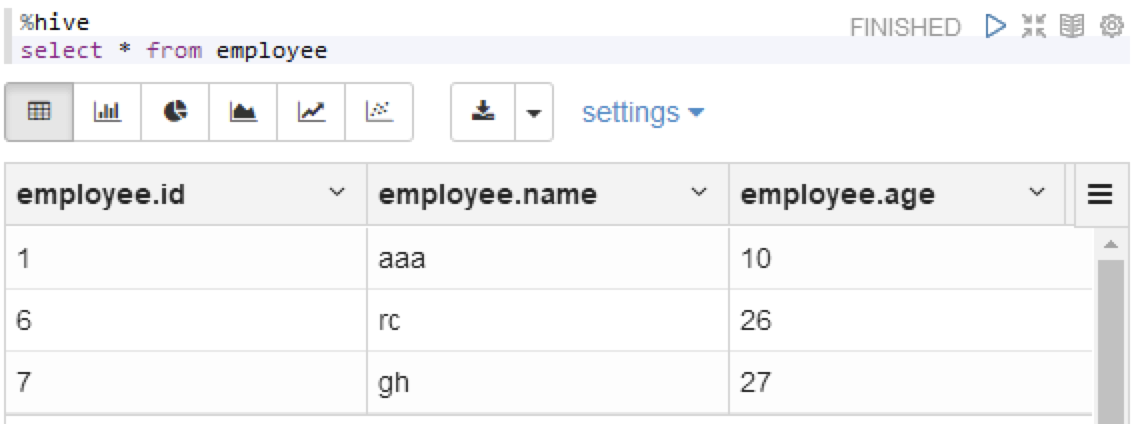
运行之后,查一下hive
%hive
select * from employee
可以看到,数据已经写进文件中了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号