linux day24最新(udp协议,socket协议,dhcp协议,dns协议,url地址,网络通信流程与数据包发送,网卡的工作原理以及丢包问题,ip地址分类)
今日内容:
1,网络协议(补充完,socket套接字)
2,网络通信的流程(完整流程,加强排错能力,还有怎么一步步把数据包拿到本地)
3,数据包的发送(dns的递归和迭代查询,最终都要从网卡往外发,mtu网卡最大传输单元,默认是1500字节,等数据超了,需要分片去发,cic循环校验问题,看懂网卡配置信息)
4,ip地址的子网划分(单纯的ip地址没有意义,需要搭配子网页码,算出网络地址,这个子网页码只要稍加改动,ip地址对应的网络地址就可能不一样。不一样的网络地址,即使连接在一个交换机上也无法通信,不需要自己分,但是linux需要自己配)
5,vlan(一个交换机,可以当多个交换机去用,和ip地址的子网划分一块去用,减少广播域,减少ip地址的浪费)
如:192.168.10.0~192.168.10.255,这中间,.0这个地址是本网段的地址,.1这个地址是本网段网关地址,.255是本网段的广播地址,所以就是从.2到.254这253个ip地址可以用,所以就可能出现一个局域网内需要的ip地址大于这个数,不够用,或者大幅小于这个数,造成ip地址的浪费。下面详细讲解为什么有的公司子网页码24位,或者32位等等。
6,实操部分
拓展:后面学到7层负载均衡,和4层负载均衡,就知道意思是解析到第几层,就是iso7层协议的知识内容。
复习:ip+mak+端口号=全世界范围内独一无二的一个应用软件
其实只需要ip地址和端口号,就可以找到全世界独一无二的一个应用软件,因为arp协议帮助把ip地址自动解析成mak地址。所以只需要拿到对方的ip和端口。
arp协议,局域网靠的是mak地址,目标mak是谁就把数据送给谁,而ip地址在局域网内,就是帮助找mak地址的。如果是局域网内的通信,和目标计算机就在一个局域网内,那么就是直接用对方的ip拿到对方的mak地址,接下来就可以进行通信。而如果和目标计算机不在同一个局域网内,那么就应该先拿到网关的mak地址,这时目标ip就应该是网关的ip地址,拿到网关mak地址后,那么源mak地址是自己,目标mak地址是网关,把数据包发给网关。在局域网内目标mak是谁,数据包就送给谁。arp协议在局域网内用的,目标ip是谁,就是问谁要mak地址。
tcp协议,三次握手,四次挥手,tcp协议为何安全,因为tcp协议,每发一个数据包出去,并不会立刻删除内存里的数据,而是等到对方给我回一个ack=1,确定对方收到,才会删除内存里的数据。不然的话,经过一段时间,就会再次发送数据包。tcp通信之前先创建双向链接,为什么建立连接需要三次,而断连接需要四次呢,因为建立链接的时候,中间的俩次并没有真正的数据需要传输,所以可以合并到一步,而断连接,假设客户端的发完数据了,发送断连接请求,服务端同意了,客户端到服务端的通路就断了,然后等服务端把数据也传送完了,给客户端发送断链接请求,客户端同意,那么服务端到客户端的链接就断了。必须进行4次,因为先发起的发完数据,但是可能对方给你传的数据还没有传完,所以不能一下断了,可能对方还没有把数据传完。
tcp协议的,三次握手,四次挥手,的状态图必须背会。
一,网络协议
1,udp协议:和tcp一样也是基于端口工作的协议,不过传输数据不可靠,但是快。
因为udp协议,传数据之前不需要建立链接,省去了建链接的环节,同时它把数据发完之后,不需要等对方回ack=1,发完数据之后,立刻把自己的内存空间清掉。这时候如果对方因为网络故障没收到数据,那这个数据就真的是丢了。也是基于端口工作的协议,客户端拿到服务端的端口就可以传输数据了。
应用软件都是基于传输层来工作的,所以应用软件要么是根据tcp协议工作的,要么是基于udp协议工作的,如果应用软件采用的是tcp协议工作的,先启动客户端软件,会朝着服务端发三次握手的请求,会直接报错,而udp因为不需要建链接,不需要对方回应,可以一直发数据,不会报错。
重要的数据,用tcp协议,平时大多数的都是采用tcp协议,如果是查询,那么用udp协议,因为即使网络出现问题,数据丢了,再查就行了,速度也更快。如果以后做集群,每台电脑时间必须统一,网上有一堆ntp服务器,客户端在自己电脑上,采用的就是udp协议。
udp协议不可靠的点,在于udp发送完数据,会立刻清理掉自己的内存。
udp协议传输快,是因为它省去了建链接的过程,同时不用等对方回应ack=1。
tcp协议的可靠,在于它传输完数据,不会立刻清理内存。
tcp协议传输慢,是因为它需要建链接,同时传输数据需要等对方回应ack=1。
2,socket
封装了传输层以及传输层以下的协议
应用程序但凡想要向外发送数据,只需要调用socket的功能即可。
各个层的协议非常稳定,所以对于开发而言,主要是管好应用层的事情,把自己有限的精力放在开发上面去,对于应用层以下的简单了解就行,有没有人可以帮开发把下面的每一层协议都封装好,开发效率就会提高,这一层就是socket层,它把应用层以下全部封装好,开发写好应用,但凡需要往外发数据,就调用socket功能就可以,socket就会开始封装每一层,往外发。socket就是一串代码,写到应用代码里就行。
期中架构里的软件都是基于sockte套接字写出来的,又称为套接字软件,每个软件都有服务端和客户端,有些软件不用它的客户端,直接用浏览器就行,也就是bs架构的,但是他们都是套接字软件。以后学的一个软件mysql,只要一启动,mysql.sock文件,它本身就是一个套接字。
3,dhcp(动态获取各种ip地址,作为了解)
想实现网络通信,每台主机必须配备四个要素
1,本机ip地址
2,子网页码
3,网关的ip地址
4,dns的ip地址
获取这四个要素的俩种方式
1,静态获取(公司里都是手动配置的,集群ip应该是固定的)
即手动配置
2,dhcp获取 ,自动获取的,dhcp有一个地址池,配在路由器里面,路由器上集成dhcp软件,发过去,路由器会回一个地址,但是有租约时间。
动态获取dhcp的流程:
刚刚开机,只有mak地址,是如何找到dhcp,因为不知道它的ip,又怎么跟它把ip地址要到的。
自己的电脑里默认就有这个的dchp软件,而服务端在路由器上集成的,等于它就是一个基于网络通信的cs架构的软件,现在就等于是客户端给服务端要各种ip信息,所以现在封了一个dhcp的包,包的内容就是要各种ip信息,应用层的信息,现在要往传输层交,而这里的传输层,用的是udp协议,封装了一个udp头,dhcp源端口是自己,默认是68,而dhcp服务端的端口默认是67,交给网络层,封ip头,自己的ip地址不知道,现在要的就是ip地址,所以这里源ip使用的是一个特殊ip地址 0.0.0.0,而目标ip也不知道,也是使用特殊地址255.255.255.255,再封装以太网协议的头,源mak是自己的mak,对方mak不指定,所以也用特殊mak地址,FF-FF-FF-FF-FF-FF,发出去以后到交换机的位置,交换机物理层把二进制汇总成数据链路层的包,拆以太网头,看到源mak是发送者的,看到目标mak地址是FF,交换机立马知道一件事,应该广播出去,然后所有的机器都会拆到网络层,也就是拆ip头,发现源ip,0.0.0.0,目标ip是255.255.255.255,这时候只有路由器知道是给它的包,再拆tcp头,发现源端口是68,目标端口是67,立马把它交给对应端口的dhcp,dhcp拆开最后的一个包,得知对方想要ip的信息,然后返回过去,并且还有租约时间。现在dhcp都集成在路由器上,但是其实可以专门用一台机器去配置。
拓展:ssh默认端口是22,dns默认端口53
拓展:但凡要上网,必须要有,ip地址,mak地址,端口。端口默认是操作系统分配好的,也可以自己分配,mak地址直接在自己网卡上不需要配置,所以它们都属于自带的。再有就是需要ip地址,子网页码,如果数据包想往外发,还需要网关的ip地址,子网页码,用来问网关的mak地址,还有dns的ip地址,用来解析域名。
上网就是把请求上传到服务器上,然后服务器解析一样,把你想要的资源给在浏览器上显示出来。理论上应该拿到服务端的ip,mak,端口,而mak有arp协议自动解析出来,所以只需要ip和端口。但是如果是这样,大量网站的ip,端口都需要记住,非常麻烦,这时候有个软件dns,专门帮忙记住,它用域名对应dns,因为域名好记。每个域名都对应一个ip。
4,dns (domain name sever):服务端端口默认53,域名
这个软件管理着一个文件,一个域名对应一个ip地址
为什么要有这个软件:
理论上讲,如果拿浏览器去要访问一个服务端,一定要拿到这个服务端的ip地址和端口,如果真的是这样用户太难记住,而用户记域名更好记,dns把域名和ip的对应关系放在一个地方放着,当用户想要访问一个网站的服务器,用户只需要输入域名,如:www.baidu.com,这时候浏览器帮用户向dns服务端发一个dns请求,dns服务端会把www.baidu.com的ip地址返回给浏览器,这样用户只需要输入域名,就非常好记。按理来说,还应该需要端口,但是如果使用的是浏览器访问服务端,说明是bs架构的应用软件,那么只能遵守应用层的协议规定,大部分都是采用htpp协议,默认的端口号都是80,bs架构的应用端口号必须起80,但是这样也挺好,不用记端口号。
dns的查询走的是udp协议。
dns主从同步走的是tcp协议。(防止dns宕机,输入域名,无法上网,本地备份了一份对应关系,要保证数据安全性,所以使用tcp协议。)
dns查询分俩种查询,递归查询和迭代查询。
拓展:www.baidu.com.
. :代表根域名
com(cn等等):代表顶级域名
baidu:二级域名
www:对应的主机名
这个分级背后对应的知识点是什么呢,全世界有数不清的网站,没一个服务端都有一个域名,访问的时候是无数个的一个,本地的dns应该把全部域名都记下来,而且别人也要记,根本不可能实现,所以不能把全世界的域名,放在一个dns里,这么做文件超级大,每加一个网站,全球都要更新。所以全球有13台根dns服务器,里面只存顶级域名,如com,cn的地址,顶级域名服务器,只存二级域名的地址,而二级域名,记得是具体www的地址。这样就形参分层,分流结构,每台数据量都减小,更新也只更新对应级别的域名。所以百度,京东,淘宝,都去顶级y域花了钱的,才有的域名。只要你写好了域名,它就会在dns里加一个ip地址,别人就可以访问你的服务器。
每次查询都要从本地dns开始查,如果没有,问. ,.不知道,但是知道com知道,又去问com,com不知道,但是知道baidu知道,然后又去问baidu等等,迭代查询,然后下次本地dns就会缓存好。
拓展:开始很多访问比较慢,以后都有缓存,就非常快。尤其是针对外网。因为根dns服务器都在国外,如果新出来的ip地址,就需要跑国外,所以慢。
拓展:垂直扩展,就是给一台机器增加配置,横向扩展,性能提升,也可以防止单点故障。事实上,如果公司某一台机器崩溃了,应该紧张,如果是本身机器出现故障还好,如果是累死的,它的工作量,都分给了其他计算机,其他计算机也可能相继崩溃。
拓展:中国为什么不建根dns服务器,因为dns走的是udp协议,能稳定传输不丢包,既有自己的数据,还要有根dns的地址,最大512个字节,13台是最多,不好再增加
工作中一般不用自己搭dns。
浏览器访问dns查找顺序:
浏览器先从自己的dns缓存找-》去操作系统里找-》本地计算机hosts文件找(etc/hosts)-》lsp运营商dns缓存里找-》递归或者迭代搜索。
跟运维有关系的,主要是/etc/hosts和运营商dns(运营商的dns都是公开的),但是本地的hosts文件,优先级更高,如果修改了如:1.1.1.1 www.baidu.com,ping www.baidu.com,得出的ip就是1.1.1.1,如果删除修改,那么ping出来的就是运营商给的ip地址。在linux系统中,dns解析可以自己配置,就是在/etc/hosts这个文件里配置dns。
拓展:以后做集群,一种偷懒的办法,左边ip,右边域名随便写,如1.1.1.1 xxx
1.1.1.2 xxx 等等都写到/etc/hosts文件里去,然后这台计算机拿着域名去访问对方,但是有个关键,这个文件只在一台机器上,如果其他机器也行拿着域名去访问集群里的一台机器,把这个文件远程传给每台机器,大家用hosts,hosts放的是整个集群里的所有域名和ip的对应关系,大家都用hosts作为dns解析,以后配置可以用域名,如果一台机器ip地址变了,hosts这个文件更新一下,再发给所有机器,集群中的每一个软件的配置文件不需要动,因为用的是域名。也可以是使用dns,不过也有缺点,一个挂了全挂了。
二,网络通信的流程与数据包发送
uri和uil地址
我们就以一个浏览器为例子,首先浏览器是一个客户端套接字软件,工作在应用层,如果是访问一个网站,需要走htpp协议,例如https://home.cnblogs.com/u/ForceEdge-77,回车之后网址后面还跟了/u/ForceEdge-77,现在就是访问了一个博客,其实就是通过浏览器发一个请求过去,把想要的内容下载到本地,浏览器帮你打印到浏览器上。
怎么请求的:
uri 地址:统一资源标识符
url 地址:统一资源定位符,
ip加端口,可以找到世界上独一无二的基于网络通信的软件。
但是其实是要找到软件上某一个文件,或者图片,视频。都是一种资源,通过ip只是找到软件,但是还要找到众多资源中的想要的那一个资源。
uri就是这种想法
uil地址三部分构成 https://home.cnblogs.com/u/ForceEdge-77
http:// www.baidu.com:80 /u/ForceEdge-77
1.应用层http协议 2.ip和端口 3.文件路径(这里的根,并不是linux里的最顶级的/目录,而是/目录下专门管理软件的根目录。)
假设:结合上面的网址,服务端应用软件规定:客户端要下载的数据都在/var/www/htm1文件夹内找,也代表它就是软件管理的根目录。
根据假设,一旦客户端把路径提交过来,就等于去服务器:/var/www/htm1/u/ForceEdge-77
注:后面期中架构的时候,会发现报错,看看文件路径,看看有没有文件,有,还是看不了,看看有没有读权限就行了。url地址可以定位到全球唯一的一个资源。
三,网络通信流程与数据包发送
在一个网站输入网址,回城,瞬间拿到内容,现在分析背后的过程和细节。
第一步,dhcp本机获取ip地址信息,也可以是自己/etc/hosts固定配置的,一旦输入网站,基于udp协议把域名发给了dns服务,拿到了ip地址浏览器会拿着域名,调着计算机发一个udp协议的请求,发给dns,然后得到了想要访问网站的ip地址,默认端口80,目前在应用层,而应用层是基于传输层工作的,传输层使用tcp协议把对方资源下载下来,所以下一步是先去发tcp协议,先把双向通路建立起来,把三次握手做好。准备工作做好了,准备发包。
第二步,发包,应用层把数据组织好,数据组织成例如:就是要下载https://i.cnblogs.com/posts/edit 这个网站的/posts/edit这个文件,然后往下面一层层封装,基于http协议进行封装,封装完交给传输层,封装tcp头,源端口是用户机器浏览器的端口,目标端口是默认80,交给网络层打ip头,源ip自己ip,目标ip是用户访问网站的ip,是一个外网ip地址,再往后发,包以太网头,源mak是自己,然后交给二层设备交换机,发现目标mak是网关(这里省略了arp协议,因为需要用ip找到网关的mak地址),直接把数据包交给网关,网关拿到后做snat源地址转换,然后把包发给对方,对方进行相同的方式一步步反解出来。
流程要记住。(集群架构用)
要补充一点:
关于数据包的发送。
准备工作已经做好,开始发包,4960 先封http协议,tcp协议的头20,变4980,传输层做完,打ip头20个字节,到ip这一层变成5000个字节,到了以太网协议规定网卡一次性可以传多少个字节,也就是mtu,最大传1500个字节,现在5000个字节,所以需要分段发,假设要分成4段,到了交互机这一层,第一段数据要加mak地址,第二段也要加mak,每一段前面都要加以太网协议的头,每个以太网协议的头,14个字节,需要分4次,一次1500最大,说明每一次1500字节里,都有15个以太网字节在里面,数据包会每次往后方14个字节。
对方收包,一段段收的,如果一段丢了一个,就丢包,包就废了。
如何判断这个包我应该丢掉?crc校验,一种校验的数学方法。
crc校验:
讲到这里,先储备一个知识点
中断的概念:linux的软件中断和硬件中断
收包的时候,硬件相当于把包拿过来,硬件相当于送快递的,操作系统相当于收快递的人,如果操作系统一直停下工作,时不时去看快递来了没有,操作系统大量时间都浪费掉,这样效率很低,所以采用,操作系统忙的时候,硬件送快递,直接给操作系统打个电话告诉操作系统数据来了,操作系统停顿了一下(这里就是硬件中断,非常短暂),操作系统知道后,不会立刻去拿快递,而是做完目前的工作再去拿包,这就叫异步,如果快递员是网卡,那么网卡通知完操作系统,就可以去干别的事,操作系统也不需要时不时去看看快递包来了没,所以异步提升效率。而操作系统把事情忙完,去取快递包,这个由软件主动中断的是软件中断。
网卡是如何收包和发包。
网卡有一个缓冲区。

调用套接字,就是调用操作系统。
4段最开始在内存里。排队往缓冲区里进,网卡这时候不会直接发包,而是加上一个crc校验值,到时候才是真正的把数据发出去,对面网卡一收到包,先不进进网卡的缓冲区,网卡的驱动程序会进行校验crc值,如果没问题,就会去掉这个crc值,先进缓冲区,接下来给操作系统,这时候网卡产生了一个硬件中断,敲了操作系统的脑袋一下,告诉操作系统有一个包到了,操作系统过一会才去拿,产生了一个软件中断,拿到内存,后续系统内核解包。这里面有个漏洞,数据包先校验,然后丢到缓冲区,网卡的缓冲区,不是内存,很小,如果取的不及时,就会占满,后面的包进不来,就会导致网卡丢包。第一把网卡缓冲区调大。
网卡的工作方式:ethtool 以太网协议的工具。ethtool eth0 可以查看多少兆的网卡,是什么工作方式。
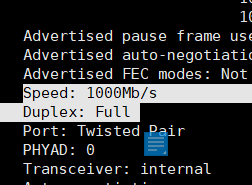
全双工(默认):往外发,也能收
半双工:如同对讲机。
如果是万兆网卡,需要搭配万兆交换机
实际操作:
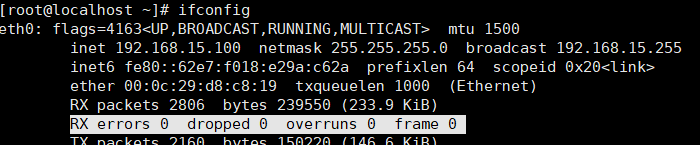
ifconfig命令查看,收包的错误数,多少包丢了,多少包溢出了,校验出错丢了多少包。
ethtool -S eth0 | grep crc :0 查看crc错误值是多少,如果也是很大的话,通常就是因为服务器外部的网络环境有问题导致的。
如果是dropped让网络工程师来弄。
如果是overruns数字很大,需要调大缓存区。
ethtool -g eth0 查看缓存区多大
ethtool -G eth0 2048 调大缓存区
五,子网划分:
172.16.10.11 这个ip地址应该包含这俩个信息,网络地址和主机地址,单纯看不出来
子网页码的功能就来了。
通过python里的bin()把172.16.10.11/24 转成二进制数
10101100.00010000.00001010.00001011 ip地址
111111111.11111111.11111111.00000000 子网页码为24时,24个1,说明上面ip地址对应的也是前24位,是网络地址,后8位就为主机名。
按位与运算得到网络地址 10101100.00010000.00001010.00000000-》172.16.10.0
172.16.10.11就是主机名,代表网络当中11编号的机器。在一个局域网里,每一个机器都应该有一个独立的编号,0不能用,172.16.10.255是本网段的网络地址,如果是255.255.255.255,这是一个全网广播的网络地址,172.16.10.1,通常是用来当本网段网关的网络地址,剩下的就是2到254,一共253个主机位可以用,如果不够用,就改子网页码,发现子网页码可以控制网络位不一样,影响包含主机个数。
A类局域网 1——8是网络位,后面24位都是主机位 国家需要组网的时候用,1~126开头的都是A类
B类局域网 1——16是网络位,后面16位都是主机位 128~191开头都是B类
c类局域网 1——24是网络位,后面8位都是主机位 小型组织用,因为主机位最多就253个 192~223开头都是c类
网络地址越多,可以分出来的网段越多,但同时每个网段里包含的主机位都在减少。
常见特殊ip地址:
.0代表是一个b类的网络地址
.255代表是一个本网段的ip地址
255.255.255.255代表是一个全网广播
.1代表是一个网段网关的ip地址
一般在公司都是用10,172,192来配置ip地址,做集群来说,172和192比较常见。
- 10.0.0.0~10.255.255.255,表示一个A类地址
- 172.16.0.0~172.31.255.255,表示16个B类地址
- 192.168.0.0~192.168.255.255,表示256个C类地址

 浙公网安备 33010602011771号
浙公网安备 33010602011771号