
分布式 基本理论 BASE
比起CAP的生硬来, 我更加喜欢BASE。BASE 显得更加好理解。尽管BASE 这个名字本身有迎合语言习惯的恶臭味,为什么不是缩写为 BaSsEc 呢?
其实大部分系统是可以 同时 CAP 的, 因为TM 网络问题也不是 大概率! 当然对于大型分布式系统可能就不一样的了!
基本介绍
介绍1
BASE理论 BASE是指基本可用(Basically Available)、软状态( Soft State)、最终一致性( Eventual Consistency)。 基本可用(Basically Available) 基本可用是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。 电商大促时,为了应对访问量激增,部分用户可能会被引导到降级页面,服务层也可能只提供降级服务。这就是损失部分可用性的体现。 软状态( Soft State) 软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据至少会有三个副本,允许不同节点间副本同步的延时就是软状态的体现。mysql replication的异步复制也是一种体现。 最终一致性( Eventual Consistency) 最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。 链接:https://www.jianshu.com/p/f432665d523f
介绍2
1. 什么是 Base 理论 BASE:全称:Basically Available(基本可用),Soft state(软状态),和 Eventually consistent(最终一致性)三个短语的缩写,来自 ebay 的架构师提出。 Base 理论是对 CAP 中一致性和可用性权衡的结果,其来源于对大型互联网分布式实践的总结,是基于 CAP 定理逐步演化而来的。其核心思想是: 既是无法做到强一致性(Strong consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。 2. Basically Available(基本可用) 什么是基本可用呢?假设系统,出现了不可预知的故障,但还是能用,相比较正常的系统而言: 响应时间上的损失:正常情况下的搜索引擎 0.5 秒即返回给用户结果,而基本可用的搜索引擎可以在 1 秒作用返回结果。 功能上的损失:在一个电商网站上,正常情况下,用户可以顺利完成每一笔订单,但是到了大促期间,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面。 3. Soft state(软状态) 什么是软状态呢?相对于原子性而言,要求多个节点的数据副本都是一致的,这是一种 “硬状态”。 软状态指的是:允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本存在数据延时。 4. Eventually consistent(最终一致性) 这个比较好理解了哈。 上面说软状态,然后不可能一直是软状态,必须有个时间期限。在期限过后,应当保证所有副本保持数据一致性。从而达到数据的最终一致性。这个时间期限取决于网络延时,系统负载,数据复制方案设计等等因素。 稍微官方一点的说法就是: 系统能够保证在没有其他新的更新操作的情况下,数据最终一定能够达到一致的状态,因此所有客户端对系统的数据访问最终都能够获取到最新的值。 而在实际工程实践中,最终一致性分为 5 种: 1. 因果一致性(Causal consistency) 指的是:如果节点 A 在更新完某个数据后通知了节点 B,那么节点 B 之后对该数据的访问和修改都是基于 A 更新后的值。于此同时,和节点 A 无因果关系的节点 C 的数据访问则没有这样的限制。 2. 读己之所写(Read your writes) 这种就很简单了,节点 A 更新一个数据后,它自身总是能访问到自身更新过的最新值,而不会看到旧值。其实也算一种因果一致性。 3. 会话一致性(Session consistency) 会话一致性将对系统数据的访问过程框定在了一个会话当中:系统能保证在同一个有效的会话中实现 “读己之所写” 的一致性,也就是说,执行更新操作之后,客户端能够在同一个会话中始终读取到该数据项的最新值。 4. 单调读一致性(Monotonic read consistency) 单调读一致性是指如果一个节点从系统中读取出一个数据项的某个值后,那么系统对于该节点后续的任何数据访问都不应该返回更旧的值。 5. 单调写一致性(Monotonic write consistency) 指一个系统要能够保证来自同一个节点的写操作被顺序的执行。 然而,在实际的实践中,这 5 种系统往往会结合使用,以构建一个具有最终一致性的分布式系统。实际上,不只是分布式系统使用最终一致性,关系型数据库在某个功能上,也是使用最终一致性的,比如备份,数据库的复制过程是需要时间的,这个复制过程中,业务读取到的值就是旧的。当然,最终还是达成了数据一致性。这也算是一个最终一致性的经典案例。 5. 总结 总的来说,BASE 理论面向的是大型高可用可扩展的分布式系统,和传统事务的 ACID 是相反的,它完全不同于 ACID 的强一致性模型,而是通过牺牲强一致性来获得可用性,并允许数据在一段时间是不一致的。 作者:莫那鲁道 出处: 博客园:http://www.cnblogs.com/stateis0/ 个人博客: thinkinjava.cn
上面的说明,非常的棒! 但是我也看到了,即使 BASE 理论, 同样是不方便做 量化的,完全不同于 数学、 物理或者化学的 哪些公式和理论。( 至少是没有看到 相关的 量化的 实际方案) 比如PH 理论, 我们至少是有个PH值 来进行测量的。 BASE 有吗? 可以给BA 打分吗? 可以给S 或者 E 打分吗? 估计还是操作上的 不方便, 这种打分的意义也是不大的, 这个系统的打分,对于其他不同的系统,是没有参考意义的。 因为 BASE 的程度, 基本上,完全是 依据具体业务 而定的。
探讨
尽管不能量化,但我们仍需要的尽量的探索。我们还需要探讨一下的是;
什么情况是满足BA 的?
BA 就是主要功能可用,不管网络问题也好节点挂掉也好, 我们需要保证关键的主要的业务 照常运行, 否则客户 或者老板就骂人了! 什么是关键、主要 业务? 跟业务主管去讨论吧!
什么情况是满足S 的?
(这里说满足, 不知道是否恰当, 因为S 是比BA 还要虚的)
“允许系统中的数据存在中间状态” ,到底是几个状态?随便什么状态,随便几个状态,只要满足Ba 就可以了。 所以说, BA 是必须满足的, 否则 一切都没有了意义!!
什么情况是满足E 的?
E, 最终一致性, 其实相对强一致性C 而言的。 我们知道完美C 是非常难的,那么可以尽量的满足部分的C,但是,部分C 肯定是不够的,甚至是 可能有问题的! 因为, 没有人喜欢部分C,我们都喜欢完美C, 它简单容易理解, 客户体验好。 而E 是对完美C的一个迂回, 牺牲了部分的客户体验( 其实也就是 需要让客户等待一些时间, 等待之后 就是他们想要的 “正确的数据”), 如果不考虑时间因素, 其实E 和C 是一样的。 当然, 具体多少 “等待时间” (其实就是 所谓的 “不一致窗口”), 又是依情况而定的。
以客户端为中心分类
总的来说,BA是我们的必须要达成的目标, S 是手段,E 是一种状态。
最终一致性 又分了很多种,(这帮专家真是够闲的了。。):
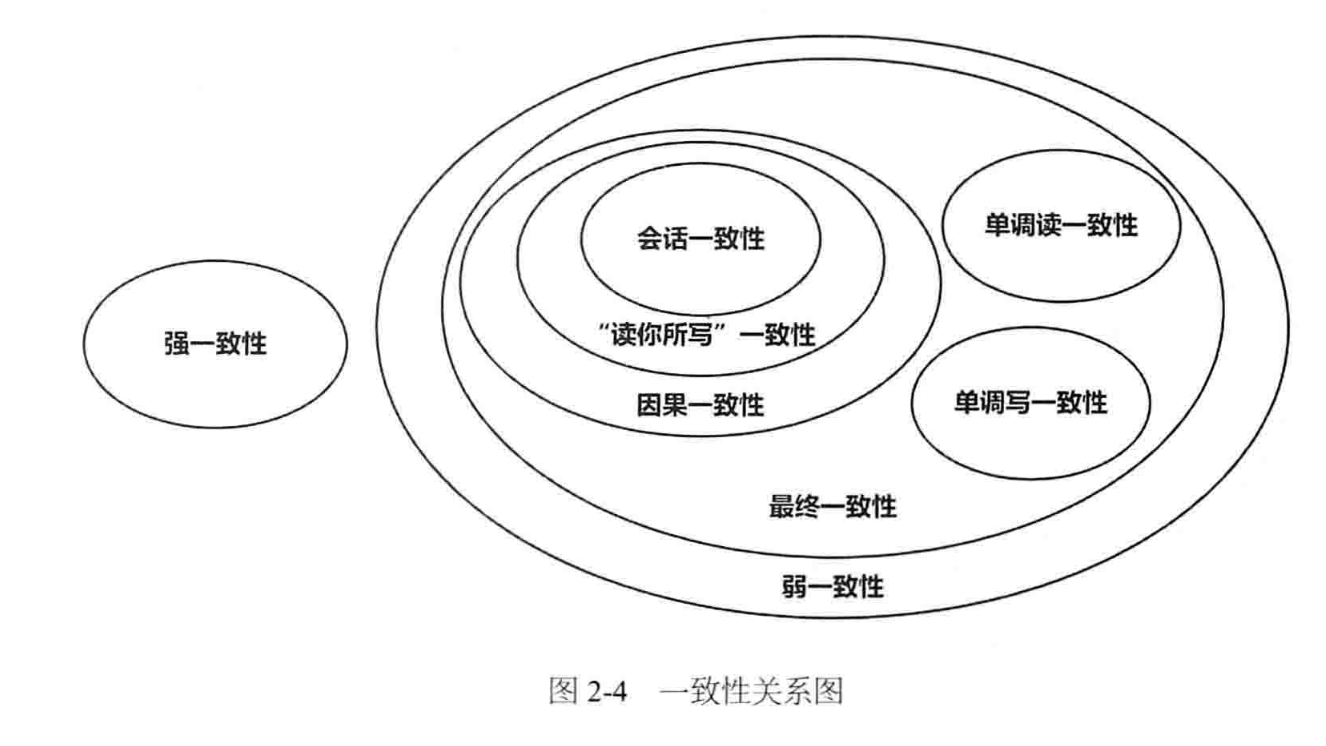
分类是为了更好的 讨论, 不至于你说东他说西, 所以这种分类 其实是很有好处的。
不过感觉 莫那鲁道 没有说清楚 E的这个分类。 我这里需要再补充几点。
这里的一致性 (这里的一致性, 都是强一致性) ,是针对于 具体的某个客户端而言的, 是 以客户端为中心的, 不考虑服务端的 各种情况, 只管客户端 看到的内容的 一致性。 比如,客户在某个浏览器做了各种操作,比如随便的读和写。
然后呢, 分类如下:
因果一致性:
什么是因果一致性。我们假设一个key-value数据存储,有两个基本操作: put(key,val) 和 get(key)=val. 这个类似于在单机的共享内存系统中的读操作和写操作(可参考:Go语言Goroutine与Channel内存模型)。
我们约定遵循下面三个规则表示潜在一致性,用符号表达 ->:
- 在同一执行线程:. 如果a 和 b 是一个执行线程中的两个操作,如果操作a发生在操作b之前,那么a ->b;
- 不同线程Gets From. 如果 a是一个put放入操作,且b是一个获得操作,能返回被a放入的写操作结果值,那么a->b;
- 传递性Transitivity. 对于操作a, b, 和 c, if a -> b 且 b -> c, 那么 a -> c.
这些规则在同一个线程内的操作之间以及在与数据存储交互的不同线程的操作之间创建了潜在的因果关系,这个模型,并不允许线程直接通讯,而是通过数据存储进行通讯。
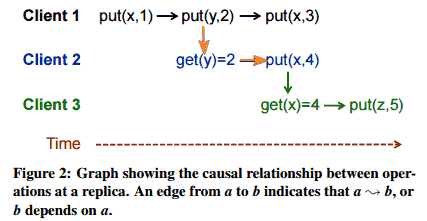
在一致性的要求上,又比顺序一致性降低了:它仅要求有因果关系的操作顺序得到保证,
非因果关系的操作顺序则无所谓。
因果相关的要求是这样的:
本地顺序:本进程中,事件执行的顺序即为本地因果顺序。
异地顺序:如果读操作返回的是写操作的值,那么该写操作在顺序上一定在读操作之前。
闭包传递:和时钟向量里面定义的一样,如果a->b,b->c,那么肯定也有a->c
说了这么多,可能我们还是比较懵逼。 其实可以这么理解,假设客户端两个操作,o2 依赖于 o1,这是怎么一种操作呢? 就是说, o1 不发生,o2就不可能发生, 这就是所谓的“因果” (终于跟佛教扯上了一些关系了啊!), 比如,发帖子的操作,完成之后,才可能有 对这个帖子的 评论操作。 这个看起来是 废话, 但是,分布式系统中, 确实有可能出现违背 因果关系的 情况。 因果关系是 符合我们的 直观理解的, 看起来是自然而然的, 违背了的话, 就会觉得TM 简直乱套了,不可思议!
读你所写一致性:
它是因果一致性的 非常直观的特例, 就是说写操作完成之后, 我才有可能把 写的内容 读出来(这简直就是废话啊! 但是分布式系统可能出现违背, 所以,也要把它列出来)。它要求 我自己写的内容, 我自己是一定 立即 能够读出来的! 但是呢, 其他客户端写的内容, 就不给与保证了! 这样的情况是有一点合理性的,某些场景客户容易理解也可以接受。 客户 或 那个场景就 不是要求非常的实时,不是非常高。我们可以做一定的设计, 然后满足这样子的需求, 比如 用户阅读某个帖子, 然后很多评论, 同时很多人还在继续评论, 然后用户自己也发表了评论,那么这个时候,虽然有很多新的评论, 但用户只需要读到自己的写的评论就好了, 其他的看不到也不要紧, 用户怎么知道瞬间 新的评论又出现了呢? 这个是无法感知的, 知道了新评论 当然用户体验更好, 但是不知道也不要紧啊! 但是呢, 如果 他自己刚刚写的评论, 如果都看不到, 那就会觉得不可思议啊, 坑爹啊! 读你所写一致性 如果不能满足,那TM 简直不可思议, 肯定是 不可取的。
会话一致性:
读你所写一致性的特例,相当于在同一个会话内保证读你所写一致性,但是不同的会话不保证。 就是说, 客户做了各种读写操作,然后退出了 登录后, 然后重新登录, 然后就可能 不能读到之前会话写的数据了! 也就是不保证数据一致性了!! 这种情况有点 费解, 它做了更多的条件限制,其体验, 当然是比 读你所写一致性 更差!
单调读一致性:
它是指如果一个节点从系统中读取出一个数据项的某个值后,那么系统对于该节点后续的任何数据访问都不应该返回更旧的值。 潜在的台词是 客户端1从节点1写入的值, 客户端2从节点2 也应该能够“尽量”读出来 。保证读操作的序列化。 http://dict.youdao.com/w/eng/%E5%8D%95%E8%B0%83%E8%AF%BB%E4%B8%80%E8%87%B4%E6%80%A7/ 的解释是: 单调读一致性(Monotonic read consistency):如果进程已经看到过数据对象的某个值,那么任何后续访问都不会返回在那个值之前的值。 还是有些费解。 其实可以这么理解,系统给客户端 提供的数据 是比较新的,是不会返回“更旧的” 数据, 也就是说, 虽然 我系统返回给客户端的 可能不是最新的, 但是已经是 比较新的了。 像kafka 就有这种情况, 同一个partition 的不同分片 尽量提供新的数据, 但是 不保证是 最新的( 当然, 如果客户端访问的是 更旧的分片,那么也有可能返回 更旧的数据, 系统应该避免这种情况)。 这个其实客户也 还比较容易接受。
单调写一致性:
指一个系统要能够保证来自同一个节点的写操作被顺序的执行。它保证写操作的序列化。不知道莫道的这个解释是否有误, 我感觉是比较费解。我认为的下面的解释比较好:
一个进程对数据项X执行的写操作必须在该进程对数据项X执行的任何后续写操作之前完成。单调写一致性同以数据为中心的FIFO一致性类似,本质是同一进程上执行的写操作必须在任何地方以正确的顺序执行。单调写一执行保证在一个副本上执行数据更新时,在此之前(其它副本上执行的)的所有数据更新都将首先执行。
https://www.jianshu.com/p/dcead11b3da9
其实就算是, 客户端 随意的读写, 可能 先是写(w1操作) 分布式系统的A 节点, 然后写(w2操作) B 节点。 这个两个写是有顺序的, 那么我们期望,系统的记录也是 有序的, 即 必须先 在整个系统内部 完成 w1, 然后才能完成w2。 完成w1 意味着, 分布式系统中所有的节点 的当前数据备份 都是 w1的数值。 同理w2 也是这样。 这样的要求, 看起来平平常常, 但是 对于一个分布式系统而言, 可能也是一个巨大的挑战呢! 为了保证这种 单调写, 我们需要复杂的算法, PAXOS 就是这样的算法, 能够严格满足 单调写 等 特性。当然, 实际情况, 我们可能不需要“严格的” 实现 PAXOS, 也不是因为难以实现, 而是考虑性能 等综合因素。
在我之前的想法中, 单调写 其实 考虑了 网络的延迟和乱序啊。 其实那 是分布式系统外部的事情, 跟分布式系统无关, 也无法控制。系统都是有边界的,那些 只能在传输或者 网络层面控制。在此不做讨论了。
单调写, 其实是针对那些可以 多个节点同时写的 分布式系统, 这个看起来更像是 ZK 做的事情, ZK 的各个节点是可以 允许 你随便写的。 像有些系统, 它读写分离了,只有一个写的节点(即master), 那么单调写是 自动满足的吧!
小结
如上大图 所示,前面的各种一致性 是有一定的 包含关系的。最终一致性是 弱一致性的子集,最终一致性包含各种情况,其中因果 包含了 读你所写, 读你所写 包含了 会话一致性。
在具体的分布式系统 或我们自己的 实现中,我们可以做一些取舍来实现其中某些一致性。 如果保证每次同一个客户端的的读写操作都 落到 分布式系统的同一个 节点, 那么就容易实现 “读你所写”, 单调一致性也是这样的。 也就是说 : 如果每次都是同一台服务器,那么就比较容易保证“读己之所写”一致性和单调一致性。(单调一致性 会复杂一些, 如果依次发生ABC写操作,分别发生于Node 1、2、3, 那么 从node1 读取可能读取到 ABC, 也可能是 ACB 或者其他情况,ACB肯定不是 单调一致性, 也不是我们所需要的)
参考:
https://www.cnblogs.com/biterror/p/6909624.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号