

数据处理笔记---决策树
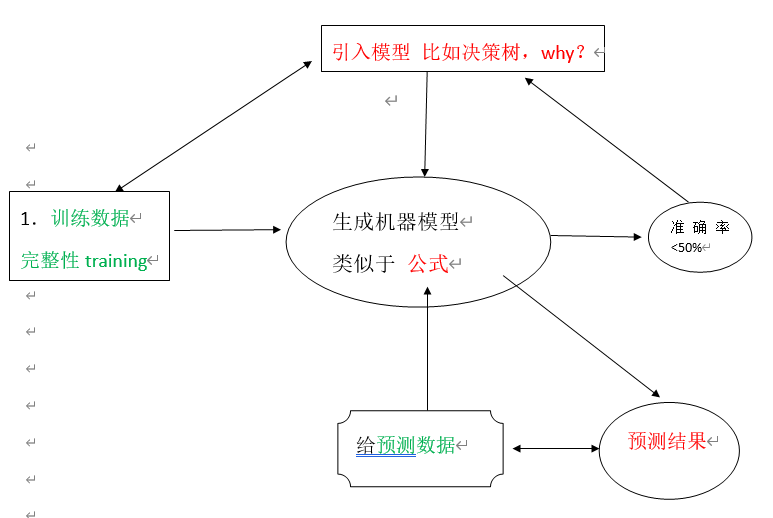
决策树是机器学习有监督算法中分类算法的一种,有关机器学习中分类和预测算法的评估主要体现在:
- 准确率:预测的准确与否是本算法的核心问题,其在征信系统,商品购买预测等都有应用。
- 速度:一个好的算法不仅要求具备准确性,其运行速度也是衡量重要标准之一。Log2(n)
- 强壮:具备容错等功能和扩展性等。
- 可规模性:能够应对现实生活中的实际案例
- 可解释性:运行结果能够说明其含义。
每个内部结点表示在一个属性上的测试,每个分支代表一个属性输出,而每个树叶结点代表类或类分布。树的最顶层是根结点。比如
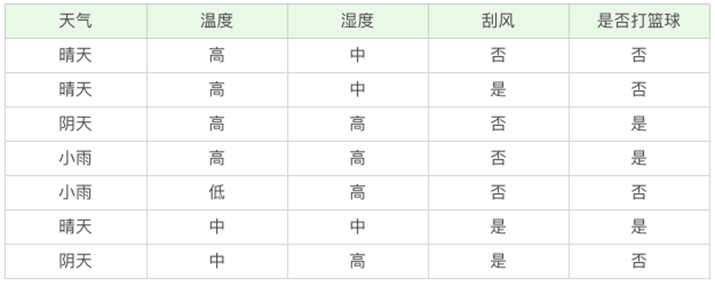

如上案例判断是否去打球?根节点显示7天中2天适合打球,其中5天不适合打球。这里面没有全部一致的情况,说明还需要细分:
1 晴天:晴天中有2天适合打球,3天不适合打球,还需细分①湿度小于等于70时候有2天都适合打球,停止划分;②湿度大于70有3天都不适合打球,停止划分。
2 阴天:共4天都适合打球,停止划分。
3 雨天:3天适合打球,2天不适合打球,继续划分。①没有风的有3天且都适合打球,停止划分;②有风的2天且都不适合打球,停止划分。
注意:有的时候不易太细的划分,特征过多过细的话反而会影响预测的准确率。把大多数归为一类,极少数的可以归到大多数之中。
案例:如上决策树,如果某天是:晴天,湿度90 判定是否适合打球,可以由图知是不适合打球的。
官方文档: http://scikit-learn.org/stable/modules/tree.html
2 构造决策树的基本算法:
判定顾客对商品购买能力
2.1 算法结果图:

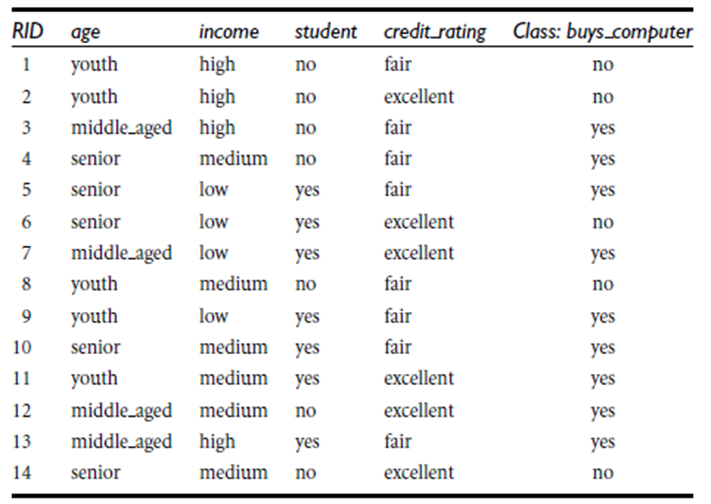
根据决策树分析如下客户数据,判定新客户购买力。其中(构建决策)
客户年龄age:青年、中年、老年
客户收入income:低、中、高
客户身份student:是学生,不是学生
客户信用credit_rating:信用一般,信用好
是否购买电脑buy_computer:购买、不购买
2.2 在介绍决策树算法之前,先了解信息熵的概念。熵的(entropy)概念:信息和抽象,如何度量?
1948年,香农提出了 ”信息熵(entropy)“的概念,一条信息的信息量大小和它的不确定性有直接的关系,要搞清楚一件非常非常不确定的事情,或者是我们一无所知的事情,需要了解大量信息==>信息量的度量就等于不确定性的多少。
例子:猜世界杯冠军,假如一无所知,猜多少次?每个队夺冠的几率不是相等的,比特(bit)来衡量信息的多少。
采用如下方式求信息熵:
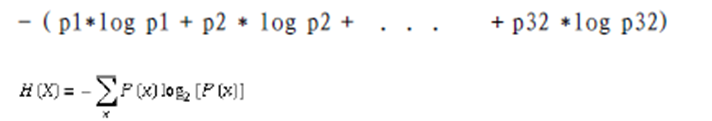
1 当每个球队夺冠概率相等时候,32支参加世界杯夺冠球队的信息熵是5,计算是2^5=32,也就是你5次可以猜对那支球队夺冠。
2 当球队夺冠概率不相等,比如巴西、德国、荷兰是强队概率较大,信息熵就小于5,也就是你用不到5次就可以猜出哪个球队夺冠。
注:变量的不确定性越大,熵也就越大
2.3 决策树归纳算法(ID3)
1970-1980, J.Ross. Quinlan首先提出ID3算法,第一步是选择属性判断结点,我们采用信息熵的比较。第二步是信息获取量(Information Gain):Gain(A) = Info(D) - Infor_A(D)通过A来作为节点分类获取了多少信息
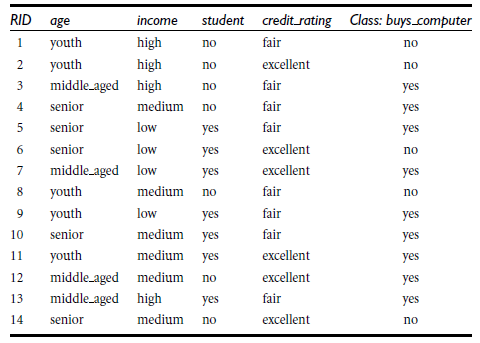
Info(student)=-[7/14*(6/7*log(6/7)+1/7*log(1/7)+7/14*(3/7*log(3/7)+4/7*log4/7 ]=
5/14[2/5log2(2/5)+3/5log(3/5)] +4/14[4/4log(4/4)+0/4log(0/4)] + 5/14[3/5log(3/5)+2/5*log(2/5)]
详解:
信息获取量/信息增益(Information Gain):
Gain(A) = Info(D) - Infor_A(D),例如age的信息增益,
Gain(age) = Info(buys_computer) - Infor_age(buys_computer)。
Info(buys_computer)是这14个记录中,购买的概率9/14,不购买的5/14,带入到信息总熵公式。
Infor_age(buys_computer)是age属性中,青年5/14购买概率是2/5,不购买3/5;中年4/14购买概率是1,不购买概率是0,老年5/14购买概率3/5,不购买概率是2/5.分别代入特征信息熵公式
Info(buys_computer)与Infor_age(buys_computer)做差,即是age的信息增益,具体如下:
Info(student)=-{7/14(买电脑6/7log(6/7)+不买电脑1/7*log(1/7))+7/14(买电脑3/7log(3/7)+不买电脑4/7*log(4/7))}
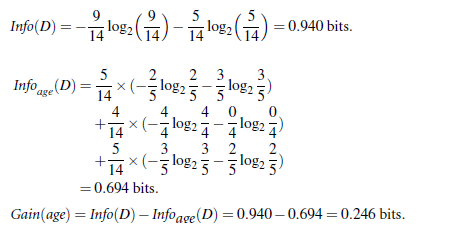
Info(student)=7/14*{6/7*log(6/7)+1/7*log1/7}+7/14{3/7*log3/7+4/7*log4/7}=0.79
Gain(student0=0.94-.79=0.15
类似,Gain(income) = 0.029,
Gain(student) = 0.151
Gain(credit_rating)=0.048
Gain(age)=0.246
所以,选择信息增益最大的作为根节点即age作为第一个根节点
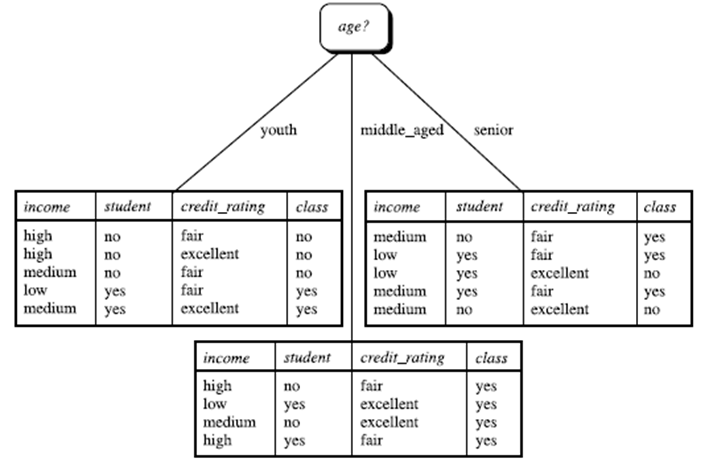
重复计算即可得到
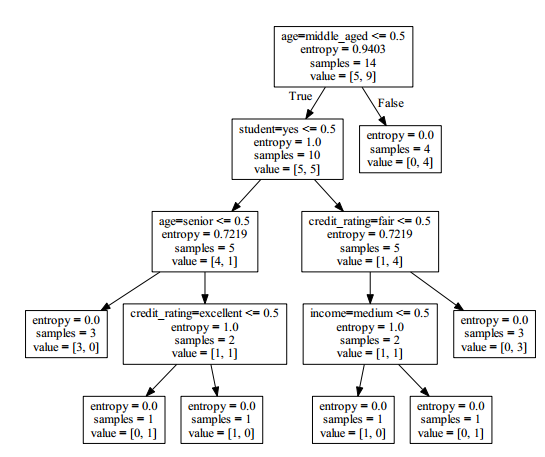
2.4 决策树算法:
决策树算法的形式化描述如下:
- 树以代表训练样本的单个结点开始(步骤1)。
- 如果样本都在同一个类,则该结点成为树叶,并用该类标号(步骤2 和3)。
- 否则,算法使用称为信息增益的基于熵的度量作为启发信息,选择能够最好地将样本分类的属性(步骤6)。该属性成为该结点的“测试”或“判定”属性(步骤7)。在算法的该版本中,
- 所有的属性都是分类的,即离散值。连续属性必须离散化。
- 对测试属性的每个已知的值,创建一个分枝,并据此划分样本(步骤8-10)。
- 算法使用同样的过程,递归地形成每个划分上的样本判定树。一旦一个属性出现在一个结点上,就不必该结点的任何后代上考虑它(步骤13)。
- 递归划分步骤仅当下列条件之一成立停止:
- (a) 给定结点的所有样本属于同一类(步骤2 和3)。
- (b) 没有剩余属性可以用来进一步划分样本(步骤4)。在此情况下,使用多数表决(步骤5)。
- 这涉及将给定的结点转换成树叶,并用样本中的多数所在的类标记它。替换地,可以存放结
- 点样本的类分布。
- (c) 分枝
- test_attribute = a i 没有样本(步骤11)。在这种情况下,以 samples 中的多数类
- 创建一个树叶(步骤12)
在决策树ID3基础上,又进行了算法改进,衍生出 其他算法如:C4.5: (Quinlan) 和Classification and Regression Trees (CART): (L. Breiman, J. Friedman, R. Olshen, C. Stone)。这些算法共同点:都是贪心算法,自上而下(Top-down approach)
再看是否给与信贷的决策基本数据
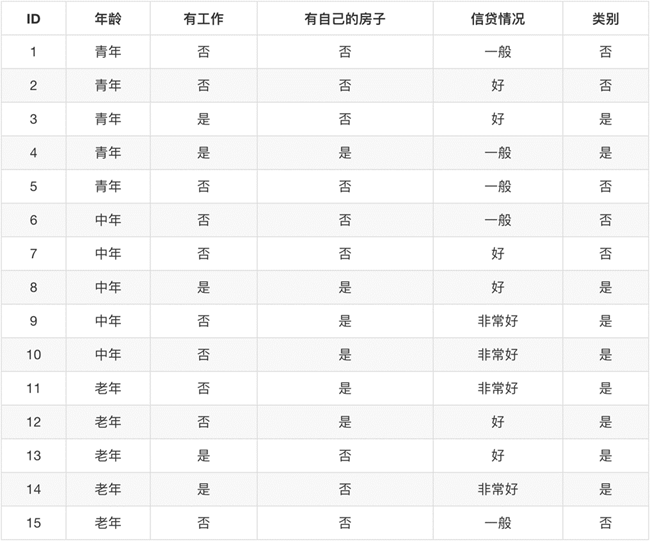
区别:属性选择度量方法不同: C4.5 (gain ratio,增益比), CART(gini index,基尼指数), ID3 (Information Gain,信息增益)
2.5 如何处理连续性变量的属性?
有些数据是连续性的,其不像如上实验数据可以离散化表示。诸如根据天气情况预测打球案例中,其湿度是一个连续值,我们的做法是将湿度70作为一个分界点,这里就是连续变量离散化的体现。
2.6 补充知识
树剪枝叶 (避免overfitting过度拟合):为了避免拟合问题,我们可以对归于繁琐的树进行剪枝(就是降低树的高度),可以分为先剪枝和后剪枝。
决策树的优点:直观,便于理解, 小规模数据集有效
决策树的缺点:处理连续变量不好、类别较多时,错误增加的比较快、可规模性一般
2.7 信息熵算法程序
1 import numpy as np 2 import pandas as pd 3 import pyhdfs as py 4 cn=py.HdfsClient(hosts='master:50070') 5 #cn.delete('/买电脑.txt') 6 #cn.copy_from_local('买电脑.txt','/买电脑.txt') 7 f=cn.open('/买电脑.txt') 8 #print(f.read()) 9 10 #ds=pd.read_csv('外出.txt') 11 data=pd.read_csv(f) 12 del data['RID'] 13 # data = pd.DataFrame( 14 # {'学历': ['专科', '专科', '专科', '专科', '专科', '本科', '本科', '本科', '本科', '本科', 15 # '研究生', '研究生', '研究生', '研究生', '研究生'], 16 # '婚否': ['否', '否', '是', '是', '否', '否', '否', '是', '否', '否', '否', '否', '是', '是', '否'], 17 # '是否有车': ['否', '否', '否', '是', '否', '否', '否', '是', '是', '是', '是', '是', '否', '否', 18 # '否'], 19 # '收入水平': ['中', '高', '高', '中', '中', '中', '高', '高', '很高', '很高', '很高', '高', '高', 20 # '很高', '中'], 21 # '类别': ['否', '否', '是', '是', '否', '否', '否', '是', '是', '是', '是', '是', '是', '是', '否']}) 22 # 定义计算信息熵的函数:计算Infor(D) 23 print(data) 24 print(data.to_dict('list')) 25 # def get_entropy(data_df,columns = None): 26 # if (columns is None) and (data_df.shape[1] > 1) : 27 # raise "the dim of data_df more than 1, the columns must be not empty!" 28 # # 信息值 29 # pe_value_array = data_df[columns].unique() 30 # ent = 0.0 31 # for x_value in pe_value_array: 32 # p = float(data_df[data_df[columns] == x_value].shape[0]) / data_df.shape[0] 33 # logp = np.log2(p) 34 # ent -= p * logp 35 36 # return ent 37 38 def infor(data): 39 a = pd.value_counts(data) / len(data) 40 return sum(np.log2(a) * a * (-1)) 41 #测试结果 42 #print('购买总信息熵:',get_entropy(data["buy"],columns=5)) 43 print('购买总信息熵:',infor(data["buy"])) 44 print('年龄信息熵:',infor(data["age"])) 45 print('收入信息熵:',infor(data["income"])) 46 print('学生身份信息熵:',infor(data["student"])) 47 print('信用度信息熵:',infor(data["credit_rating"]))
3 基于python代码的决策树算法实现
3.1 机器学习的库:
scikit-learn覆盖分类(classification), 回归(regression), 聚类(clustering), 降维(dimensionality reduction),模型选择(model selection), 预处理(preprocessing)等领域。
3.2 scikit-learn的使用:Anaconda集成了如下包,不需要安装即可使用
安装scikit-learn: pip, easy_install, windows installer,安装必要package:numpy, SciPy和matplotlib, 可使用Anaconda (包含numpy, scipy等科学计算常用package)
商品购买例子:
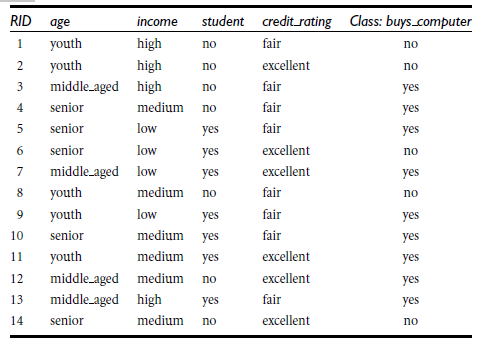
特征向量数值化
1.赋值方式 2.布尔值方式()
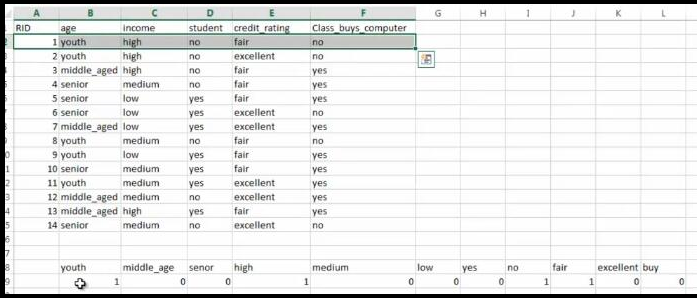
转化为csv文件如下:

3.3 运行效果如下:

其中,datafile存放模型训练数据集和测试数据集,TarFile是算法生成文本形式的dot文件和转化后的pdf图像文件,两个py文件,一个是训练算法一个是测试训练结果。右侧预测值【0 1 1】代表三条测试数据,其中后两条具备购买能力。具体算法和细节下节详解。
3.4 具体算法和细节
python中导入决策树相关包文件,然后通过对csv格式转化为sklearn工具包中可以识别的数据格式,再调用决策树算法,最后将模型训练的结果以图形形式展示
包
的导入:
1 from sklearn.feature_extraction import DictVectorizer 2 import csv 3 from sklearn import tree 4 from sklearn import preprocessing 5 from sklearn.externals.six import StringIO
'读取csv文件,将其特征值存储在列表featureList中,将预测的目标值存储在labelList中'
1 featureList = [] 2 labelList = [] 3 4 #读取商品信息 5 allElectronicsData=open(csvfileurl) 6 reader = csv.reader(allElectronicsData) #逐行读取信息 7 headers=str(allElectronicsData.readline()).split(',') #读取信息头文件 8 print(headers)
运行结果:

存储特征数列和目标数列
1 for row in reader: 2 labelList.append(row[len(row)-1]) #读取最后一列的目标数据 3 rowDict = {} #存放特征值的字典 4 for i in range(1, len(row)-1): 5 rowDict[headers[i]] = row[i] 6 # print("rowDict:",rowDict) 7 featureList.append(rowDict) 8 print(featureList) 9 print(labelList)
运行结果:
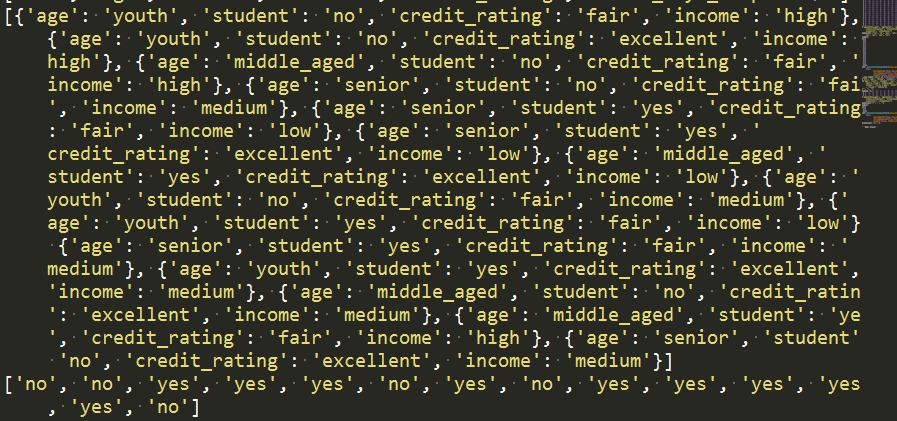
将特征值数值化
1 vec = DictVectorizer() #整形数字转化 2 dummyX = vec.fit_transform(featureList) .toarray() #特征值转化是整形数据 3 4 print("dummyX: " + str(dummyX)) 5 print(vec.get_feature_names()) 6 7 print("labelList: " + str(labelList)) 8 9 # vectorize class labels 10 lb = preprocessing.LabelBinarizer() 11 dummyY = lb.fit_transform(labelList) 12 print("dummyY: \n" + str(dummyY))
运行结果:

如上算法就是将商品信息转化为机器学习决策树库文件可以识别的形式,即如下形式:
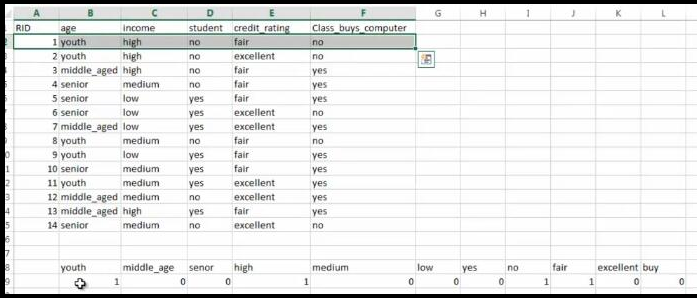
使用决策树进行分类预测处理
1 # clf = tree.DecisionTreeClassifier() 2 #自定义采用信息熵的方式确定根节点 3 clf = tree.DecisionTreeClassifier(criterion='entropy') 4 clf = clf.fit(dummyX, dummyY) 5 print("clf: " + str(clf)) 6 7 # Visualize model 8 with open("../Tarfile/allElectronicInformationGainOri.dot", 'w') as f: 9 f = tree.export_graphviz(clf, feature_names=vec.get_feature_names(), out_file=f)
运行结果
3 随机森林在sklearn中的实现
3.1随机森林简介
决策树算法易于理解和解释。但通常,一棵树不足以产生有效的结果。这就引入随机森林的概念。
3.2 集成算法概述
集成学习(ensemble learning)是时下非常流行的机器学习算法,它本身不是一个单独的机器学习算法,而是通过在数据上构建多个模型,集成所有模型的建模结果。基本上所有的机器学习领域都可以看到集成学习的身影,在现实中集成学习也有相当大的作用,它可以用来做市场营销模拟的建模,统计客户来源,保留和流失,也可用来预测疾病的风险和病患者的易感性。在现在的各种算法竞赛中,随机森林,梯度提升树(GBDT),Xgboost等集成算法的身影也随处可见,可见其效果之好,应用之广。
集成算法的目标
集成算法会考虑多个评估器的建模结果,汇总之后得到一个综合的结果,以此来获取比单个模型更好的回归或分类表现。 |
多个模型集成成为的模型叫做集成评估器(ensemble estimator),组成集成评估器的每个模型都叫做基评估器(base estimator)。通常来说,有三类集成算法:装袋法(Bagging),提升法(Boosting)和stacking。
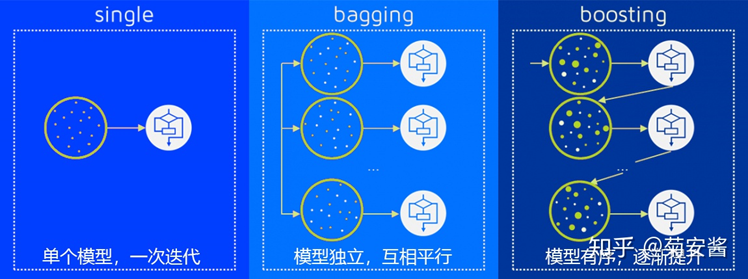
装袋法的核心思想是构建多个相互独立的评估器,然后对其预测进行平均或多数表决原则来决定集成评估器的结果。装袋法的代表模型就是随机森林。
提升法中,基评估器是相关的,是按顺序一一构建的。其核心思想是结合弱评估器的力量一次次对难以评估的样本进行预测,从而构成一个强评估器。提升法的代表模型有Adaboost和梯度提升树。
1.2 sklearn中的集成算法
sklearn中的集成算法模块ensemble

集成算法中,有一半以上都是树的集成模型,可以想见决策树在集成中必定是有很好的效果。在这堂课中,我们会以随机森林为例,慢慢为大家揭开集成算法的神秘面纱。
复习:sklearn中的决策树
在开始随机森林之前,我们先复习一下决策树。决策树是一种原理简单,应用广泛的模型,它可以同时被用于分类和回归问题。决策树的主要功能是从一张有特征和标签的表格中,通过对特定特征进行提问,为我们总结出一系列决策规则,并用树状图来呈现这些决策规则。

决策树的核心问题有两个,一个是如何找出正确的特征来进行提问,即如何分枝,二是树生长到什么时候应该停下。
对于第一个问题,我们定义了用来衡量分枝质量的指标不纯度,分类树的不纯度用基尼系数或信息熵来衡量,回归树的不纯度用MSE均方误差来衡量。每次分枝时,决策树对所有的特征进行不纯度计算,选取不纯度最低的特征进行分枝,分枝后,又再对被分枝的不同取值下,计算每个特征的不纯度,继续选取不纯度最低的特征进行分枝。

每分枝一层,树整体的不纯度会越来越小,决策树追求的是最小不纯度。因此,决策树会一致分枝,直到没有更多的特征可用,或整体的不纯度指标已经最优,决策树就会停止生长。
决策树非常容易过拟合,这是说,它很容易在训练集上表现优秀,却在测试集上表现很糟糕。为了防止决策树的过拟合,我们要对决策树进行剪枝,sklearn中提供了大量的剪枝参数,我们一会儿会带大家复习一下。
sklearn的基本建模流程
我们先来了解一下sklearn建模的基本流程。

在这个流程下,随机森林对应的代码和决策树基本一致
1 from sklearn.tree import RandomForestClassifier #导入需要的模块 2 3 rfc = RandomForestClassifier() #实例化 4 rfc = rfc.fit(X_train,y_train) #用训练集数据训练模型 5 result = rfc.score(X_test,y_test) #导入测试集,从接口中调用需要的信息 6 2 RandomForestClassifier 7 class sklearn.ensemble.RandomForestClassifier(n_estimators=’10’,criterion=’gini’, 8 max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, 9 max_features=’auto’, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, 10 bootstrap=True, oob_score=False, n_jobs=None, random_state=None, verbose=0, warm_start=False, 11 class_weight=None)
随机森林是非常具有代表性的Bagging集成算法,它的所有基评估器都是决策树,分类树组成的森林就叫做随机森林分类器,回归树所集成的森林就叫做随机森林回归器。这一节主要讲解RandomForestClassifier,随机森林分类器。
2.1 重要参数
2.1.1 控制基评估器的参数

这些参数在随机森林中的含义,和我们在上决策树时说明的内容一模一样,单个决策树的准确率越高,随机森林的准确率也会越高,因为装袋法是依赖于平均值或者少数服从多数原则来决定集成的结果的。
2.1.2 n_estimators
这是森林中树木的数量,即基基评估器的数量。这个参数对随机森林模型的精确性影响是单调的,n_estimators越大,模型的效果往往越好。但是相应的,任何模型都有决策边界,n_estimators达到一定的程度之后,随机森林的精确性往往不在上升或开始波动,并且,n_estimators越大,需要的计算量和内存也越大,训练的时间也会越来越长。对于这个参数,我们是渴望在训练难度和模型效果之间取得平衡。
n_estimators的默认值在现有版本的sklearn中是10,但是在即将更新的0.22版本中,这个默认值会被修正为100。这个修正显示出了使用者的调参倾向:要更大的n_estimators。
来建立一片森林吧
树模型的优点是简单易懂,可视化之后的树人人都能够看懂,可惜随机森林是无法被可视化的。所以为了更加直观地让大家体会随机森林的效果,我们来进行一个随机森林和单个决策树效益的对比。我们依然使用红酒数据集。
导入我们需要的包
1 %matplotlib inline 2 from sklearn.tree import DecisionTreeClassifier 3 from sklearn.ensemble import RandomForestClassifier 4 from sklearn.datasets import load_wine
导入需要的数据集并用sklearn建模
1 wine = load_wine() 2 3 wine.data 4 wine.target
1 from sklearn.model_selection import train_test_split 2 3 Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3) 4 5 clf = DecisionTreeClassifier(random_state=0) 6 rfc = RandomForestClassifier(random_state=0) 7 clf = clf.fit(Xtrain,Ytrain) 8 rfc = rfc.fit(Xtrain,Ytrain) 9 score_c = clf.score(Xtest,Ytest) 10 score_r = rfc.score(Xtest,Ytest) 11 12 print("Single Tree:{}".format(score_c) 13 ,"Random Forest:{}".format(score_r) 14 )
画出随机森林和决策树在十组交叉验证下的效果对比
1 #交叉验证:是数据集划分为n分,依次取每一份做测试集,每n-1份做训练集,多次训练模型以观测模型稳定性的方法 2 3 rfc_l = [] 4 clf_l = [] 5 6 for i in range(10): 7 rfc = RandomForestClassifier(n_estimators=25) 8 rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean() 9 rfc_l.append(rfc_s) 10 clf = DecisionTreeClassifier() 11 clf_s = cross_val_score(clf,wine.data,wine.target,cv=10).mean() 12 clf_l.append(clf_s) 13 14 plt.plot(range(1,11),rfc_l,label = "Random Forest") 15 plt.plot(range(1,11),clf_l,label = "Decision Tree") 16 plt.legend() 17 plt.show()
可以注意到,单个决策树的波动轨迹和随机森林一致?再次验证了我们之前提到的,单个决策树的准确率越高,随机森林的准确率也会越高
n_estimators的学习曲线
1 superpa = [] 2 for i in range(200): 3 rfc = RandomForestClassifier(n_estimators=i+1,n_jobs=-1) 4 rfc_s = cross_val_score(rfc,wine.data,wine.target,cv=10).mean() 5 superpa.append(rfc_s) 6 print(max(superpa),superpa.index(max(superpa))) 7 plt.figure(figsize=[20,5]) 8 plt.plot(range(1,201),superpa) 9 plt.show()
2.2 重要属性和接口
随机森林中有三个非常重要的属性:.estimators_,.oob_score_以及.feature_importances_。
.estimators_是用来查看随机森林中所有树的列表的。
oob_score_指的是袋外得分。随机森林为了确保林中的每棵树都不尽相同,所以采用了对训练集进行有放回抽样的方式来不断组成信的训练集,在这个过程中,会有一些数据从来没有被随机挑选到,他们就被叫做“袋外数据”。这些袋外数据,没有被模型用来进行训练,sklearn可以帮助我们用他们来测试模型,测试的结果就由这个属性oob_score_来导出,本质还是模型的精确度。
而.feature_importances_和决策树中的.feature_importances_用法和含义都一致,是返回特征的重要性。
随机森林的接口与决策树完全一致,因此依然有四个常用接口:apply, fit, predict和score。除此之外,还需要注意随机森林的predict_proba接口,这个接口返回每个测试样本对应的被分到每一类标签的概率,标签有几个分类就返回几个概率。如果是二分类问题,则predict_proba返回的数值大于0.5的,被分为1,小于0.5的,被分为0。传统的随机森林是利用袋装法中的规则,平均或少数服从多数来决定集成的结果,而sklearn中的随机森林是平均每个样本对应的predict_proba返回的概率,得到一个平均概率,从而决定测试样本的分类。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号