Panoptic Scene Graph学习笔记
我拜读PSG的了两篇blog和论文原文, 下面是笔记; 因为我看完blog后有去看了一波论文, 所以可能有重复的部分
起因
在ml的发展中, 让计算机了解世界是十分重要的一环, 我们人类用感官丈量这个世界, 在对我们看到, 听到, 触碰到的信息进行处理, 形成一个概念, 比如, 看到一个人骑车的图像, 我们脑子里就会有这个念头: 这个人在骑车.

我们搜集这些"念头"是有原因的, 我们要依靠它们作为我们一切行为的基准, 从某种意义上来说, 我们并没有依靠这个图片的各个像素的信息做出决定, 而是通过由此产生的念头做出的决定.那么, 计算机是否也该有这样的机制呢? 或者说, 当他看到人和车这两个物体以某种结构出现时, 他可以知道这是人在骑一辆车. 我觉得这就是场景图(Scene Graph)出现的原因了, 图片场景图生成任务(Image scene graph generation)目标是让计算机自动生成一种语义化的图结构(称为 scene graph,场景图),作为图像的表示。
Scene Graph Generation( 场景图生成任务 )
特征
场景图独特的定义使其具有了语义, 一个场景图有三个核心部分组成:
- 节点(Nodes):表示场景中的物体实例(如“人”、“狗”、“椅子”)
- 边(Edges):表示物体之间的关系(如“人牵着狗”、“狗坐在椅子旁”)
- 属性(Attributes):描述物体的特征(如“狗是棕色的”)
这样的定义使得场景图拥有了这些特点:
- 结构化表示: 通过显式的节点和边表示物体与关系,结构与人类语言描述一致,会更接近人类的认知逻辑
- 无论输入是图像、文本、视频还是语音,Scene Graph均可抽象为物体-关系-属性的三元组结构, 不同类型的信息都可以转换为相似的形式, 赋予了SG多模态融合的潜力
- 和知识图谱的相似性, 使其便于复用知识图谱的推理技术; 同时其包含的推理性质使其可以参与到推理任务中(跨模态检索, 联合推理, 生成任务)
场景图生成
Scene graph 刚开始提出时,被应用到图片检索任务,利用 scene graph 去图片库搜索内容相近的图片。当时使用到的 scene graph 是基于目标检测数据集人工标注的,耗时耗力。
随着 Visual Genome 大型数据集的公开,其对超过十万的图片进行了 scene graph 的人工标注,此后的主要研究任务就变成了如何自动地生成场景图, 也就是Scene Graph Generation.
根据给定条件多少,场景图生成任务可以由简单到复杂细分为以下几种:
形式化地,记关系集合为R,目标集为O, 目标位置为B (一般是 Bounding box),图像为 I,则图片场景图为G={ B, O, R}。
- 关系分类(Predicate classification): 已知图中目标位置及类别,对关系进行归类,记为 P(R | O, B, I)
- 场景图分类(Scene graph classification): 已知图中目标位置,对关系及目标关系(谁和谁有什么关系)进行归类,记为 P(R, O | B, I)。
- 场景图生成(Scene graph generation): 只给定图片,要求生成 scene graph,记为 P( G={R, O, B} | I)。
前一个任务可认为是后一个任务简化版。在评测模型能力时,一般需要考察模型在此三个任务的表现,以评价模型中关系分类模块、目标分类模块及目标定位模块的作用。
输入图片, 生成场景图(这个应该是 P(R, O | B, I)吧):
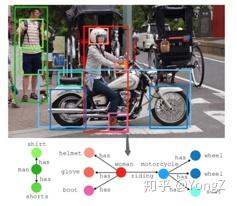
Visual Genome数据集
Visual Genome 于2016年提出,是这个领域最常用的数据集,包含对超过 10W 张图片的目标、属性、关系、自然语言描述、视觉问答等的标注。
形式上,场景图SG是一个有向图数据结构。用元组的形式定义, 这也是为什么我们要用Edges这个称呼, 因为它本来就是边
正如我上文所说的, 一个数据集的数据可以被分为以下几个部分:
- Nodes:用 bounding box 标注位置,并且有对应的类别名称。Visual Genome 包含约 17,000 种目标。
- Edges:可以动作 (jumping over),空间关系(on),从属关系(belong-to, has),动词(wear)等。Visual Genome 包含一共 13K 种关系。
- Attributes(在图中附着在是节点上):可以实验颜色(yellow),状态(standing)等。Visual Genome 包含约 155000 种属性。
对于目标、关系、属性对应的字词,使用了 WordNet 进行规范化,目的是为了归并同义词。不过常用的只是 Visual Genome 的一个子集( VG150),选取了150 种常见目标,50 种常见关系
对 Visual Genome 数据集的一些分析发现:目标和关系总是以成对或成团的子结构反复出现。比如person 总是和 possessive 和 semantic 类型的关系一起出现(比如人和家具, 人和人工制品等)。因此,知道主语宾语目标类型很容易推断关系类型,如图中蓝线表示,知道首尾节点类别后,对于关系预测的 top-5 精度能够达到 95% 以上。
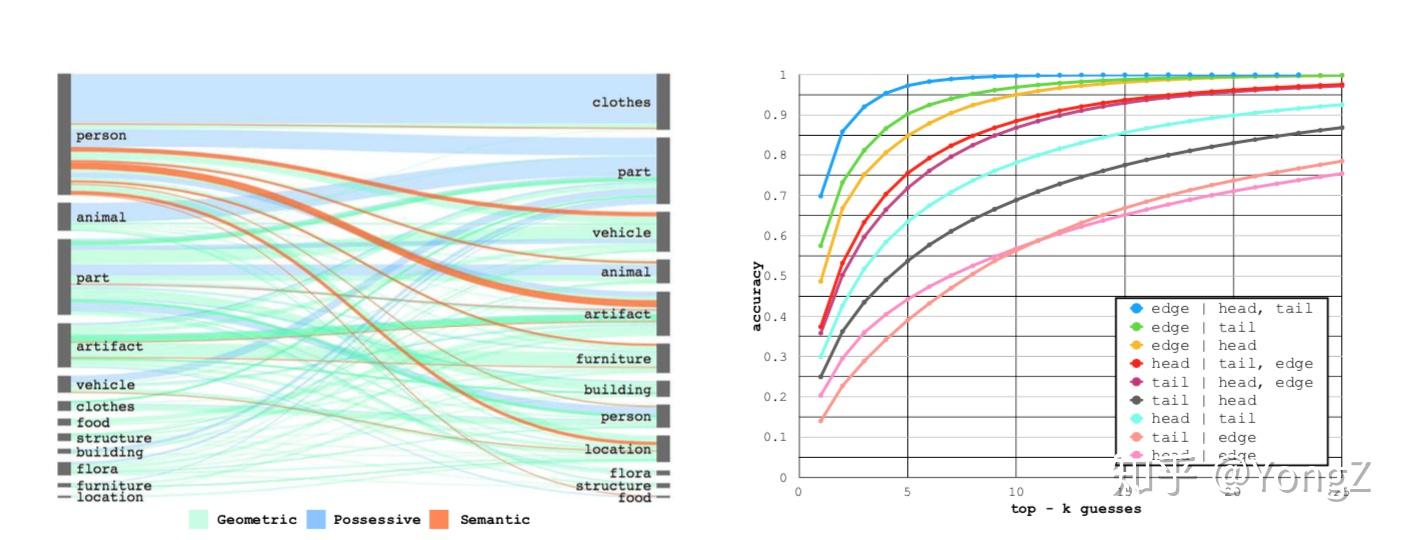
另外,结合我们的生活常识,目标、关系的类别预测和整个图片上下文(context,比如其他的目标和关系)是密切相关的。比如知道了“马在吃草”,会提升检测到目标“人”和关系“骑”的概率(maybe人在骑马)。这个认知启发研究者们要考虑利用全局信息协助局部的目标和关系预测,常见的手法是 RNN,GCN 等模型。
方法
目前的大多数场景图生成模型,根据任务的分解大致分为如下两种:
- P(O,B,R | I) = P(O,B | I) * P(R| I,O,B),即先目标检测,再进行关系预测(有一个专门研究该子任务的领域,称为研究视觉关系识别,visual relationship detection)。最简单的方法是下文中基于统计频率的 baseline 方法,另外做视觉关系检测任务的大多数工作都可以应用到这里
- P(O,B,R | I) = P(B | I) * P(R,O| I,O,B),即先定位目标(只知道位置, 还不清楚是个啥),然后将一张图片中所有的目标和关系看做一个未标记的图结构,再分别对节点和边进行类别预测。这种做法考虑到了一张图片中的各元素互为上下文,为彼此分类提供辅助信息。接下来的 IMP、GRCNN 及 Neural Motif 中基于 RNN 的方法属于这一类。
基于统计频率的方法 (Frequency baseline )
从第二节中对 Visual Genome 的统计分析看出,知道主语宾语的标签,两者的关系的类型很容易猜测(见 Figure 2 有图)。这表明只要做好目标检测,然后根据统计的频率猜测关系,即为本方法的基本思路。
显然这种方法忽略了很多可用信息,比如上下文、位置、视觉信息等。忽略这些信息的后果是,不能对同一类别的多个实例进行区分。比如图片中A在踢球,B 在守门,C 是个无关人员,利用这种盲猜的方法做预测,A,B,C 和球的关系将会是相同的结果。然而实验表明,该方法提供了很强的 baseline 效果,即使是当前效果最好的方法也仅仅是微弱的优势。
IMP (Iterative message passing )
以往的方法独立地预测每对目标之间的关系,这种局部的预测忽略了图片的上下文。如果在预测时考虑这种上下文,可以减少关系预测的模糊性。因此,研究者设计的神经网络模型中在边和节点进行信息传递。利用 RNN 进行多次迭代传递之后,可以认为在进行目标归类(node)和关系归类(edge)时融合了全局信息。
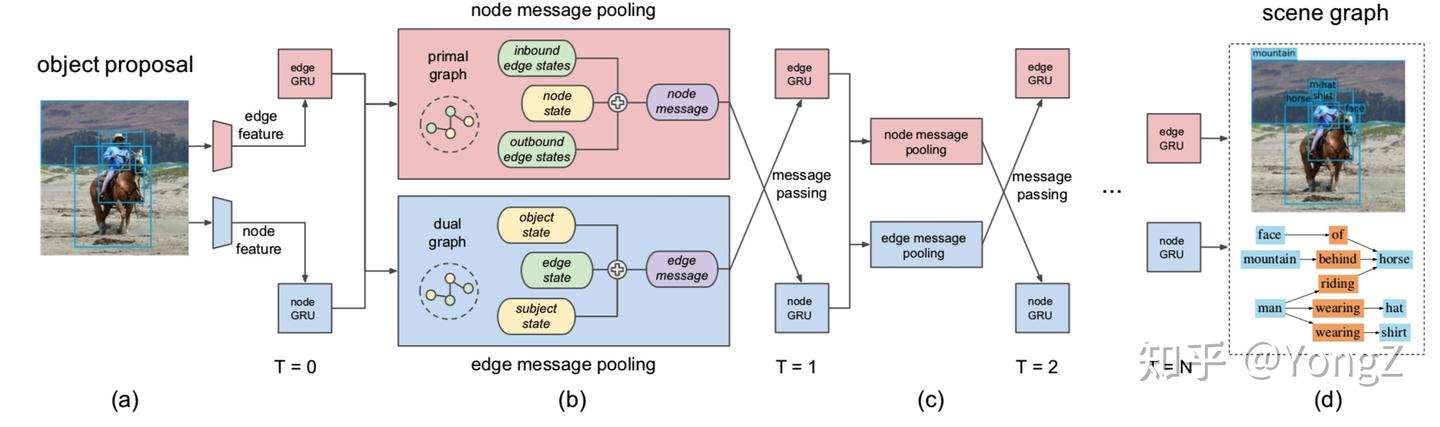
Neural Motif
采用 RNN 来融合全局和局部信息,从而得到边和节点包含全局信息的特征,再做目标和关系的归类
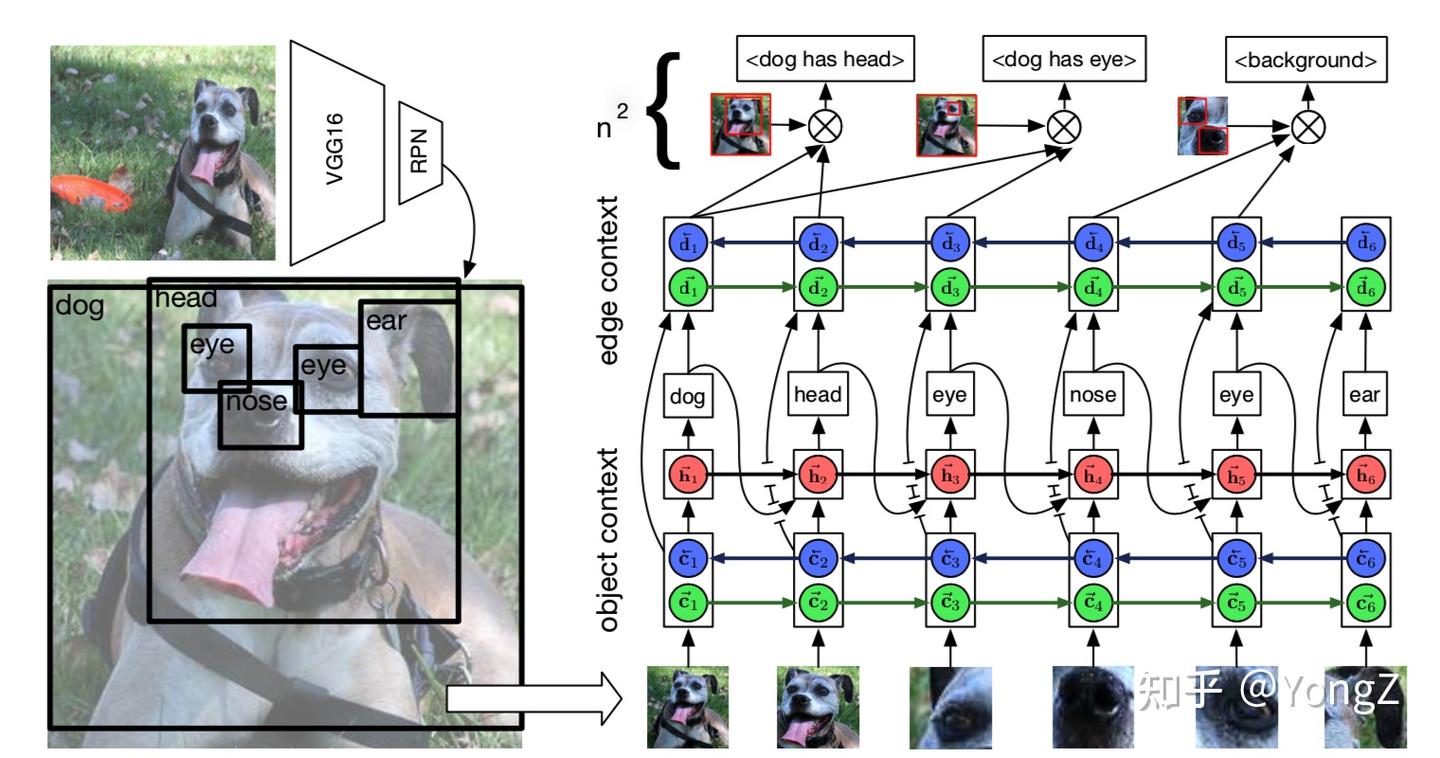
然而,使用 RNN融合全局信息存在一些缺点。由于 RNN 的输入是顺序的,proposals 以什么顺序输入影响信息的融合。即使文章中发现根据 x 坐标对proposal 排序后输入效果相对最好,但和随机顺序差别不大。RNN 毕竟只能接受的一维顺序输入,而目标关系的图结构是高阶的,RNN 模拟不了。
FOCUS:此外,这篇文章首次使用关系的统计频率作为偏移,加到模型的类别输出上。在模型中还引入了目标类别的语义信息(i.e. word embedding),有利于语义相近的目标产生类似的输出。常用的例子是由于“马”和“象”意义相近,“人骑马”的训练数据有利于检测“人骑象”,即使“人骑象”在训练数据中可能没有出现过。 此技巧告诉我们语义信息也是一个重要的信息源。
Graph RCNN
该方法提出关系 Proposal 模块,先检测关系是否存在,再判断是什么关系。
FOCUS:关系 Proposal 网络类似于目标检测的 object proposal,先筛选出存在关系的目标对,再去识别是什么关系。好处在于不用对每组目标都预测是什么关系。思路是ok的,对数据集进一步的统计可以看出来,由于已知主语宾语的关系分布 bias 问题非常严重,识别有没有关系显得比识别是什么关系更重要(在已知两者存在关系的条件下)。识别是否存在关系,可能需要用到目标的位置、类别、视觉信息等。该文章看起来只用到了目标检测阶段得到的类别信息,是可以改进的。
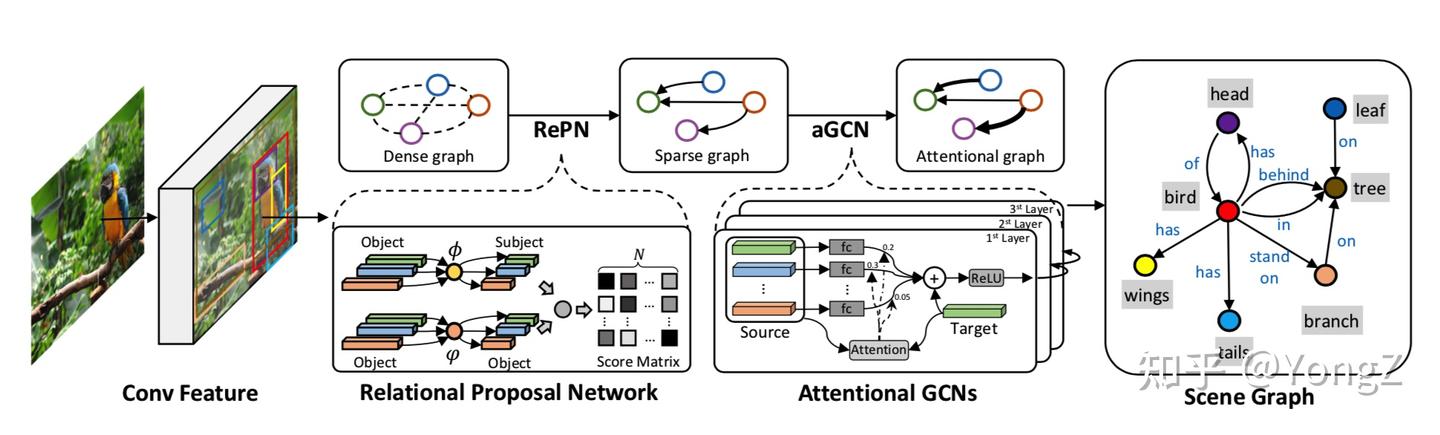
方法评价指标
最常用的评价指标是 recall @ top k, 即主谓宾关系三元组 <subject, predicate, object> , 选取前 k 个最可信预测结果的召回率。三元组的confidence score一般采用 score(subject) * score(object) * score(predicate) 。如果在排序时,一对目标只选取最可信的那组关系来排序,则称之为 constrained scene graph generation;
如果一对目标所有的关系三元组都参与排序,即一组目标可能预测多个关系,则称之为 unconstrained scene graph generation。这两种方式分别对应两种 recall 指标。
另外,可以对每一种谓语关系计算召回率,所有 predicate类别的平均召回率也是一个常用指标。还有一种召回率称之为 zero-shot recall,指的是对那些训练数据中从未出现过的关系三元组的召回率,以此反映出方法的泛化能力。
sg的一些问题 ( 设计可能过于简单了? )
- 高维关系如何在图中表示
- 只能做到对象级的节点构建,不能做到实例级,比如知道图中的节点是一个人,而不知道是谁
- 场景图中很少加入属性
- FOCUS:关系类别不互斥。比如 on, sitting on。这使得同一对目标可能存在多个关系标注。视觉关系分类建模成“多选一”的分类问题是否合理,也需要深思
- 关系的条件分布 bias 问题严重。比如已知主语宾语是 person 和 head,基本就可以猜测关系是 person has head 或是无关系。这也导致用复杂模型来预测并不比盲猜好多少的现象。
PSG
SGG工作方法主要是用bbox( bounding box )识别object然后预测它们之间的relation。基于bounding box的labels在当下数据集中往往包含了很多冗余的类别,例如hair,并且会忽略背景信息对理解场景的巨大作用。
因此, 有人提出了一个全新的任务: panoptic scene graph generation(全景场景图理解)。该任务基于全景的分割( segmentation )而不是固定的bbox。该数据集包含了49k个来自COCO和Visual Genome标注的重叠图像。同时提出了四个两阶段的baselines和两个一阶段的算法。
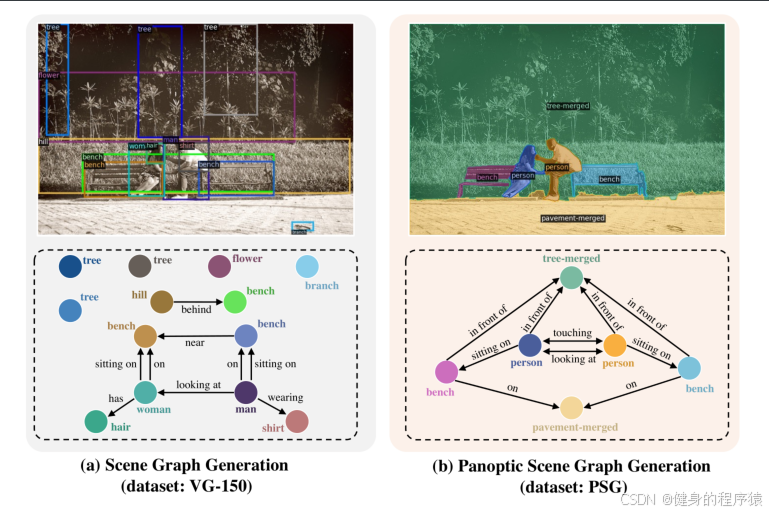
bbox提供物体标签的方式主要有以下几点问题:
- 只提供了粗糙的object定位并含有大量的噪声和别的类别的物体的像素点。
- bbox不能覆盖整张图片上的场景。
- 目前的场景图数据中包含了大量的物体类和信息类似woman-has-hair这些信息是微不足道的。同时一些物体会被在图片中重复标注,这些额外的标注对于生成场景图来讲并没有很大的贡献,而且可能会混淆模型。
其实, 在实际生活中, 我们也是基于场景来理解视觉信息的, 我们不会以物体为单位来理解一个场景, 我们理解一个场景后总结出的概念都是基于场景本身的.
PSG通过segmentation来定位对象,一个成功的Recall要求subject和object都和真实值的IOU大于0.5,并且在S-V-O三元组中的每个位置上都有正确的分类。
PSG的阶段
Two-Stage PSG Baselines
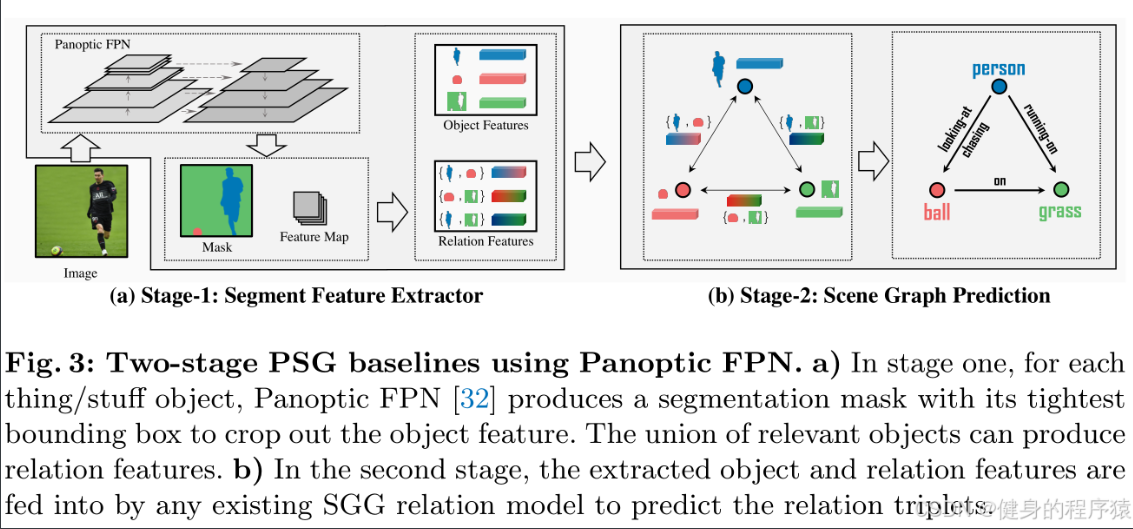
第一阶段Segment Feature Extractor
- 输入:原始图像
- 关键步骤:
- Panoptic FPN处理:
- 生成分割掩码(Mask)和特征图(Feature Map),区分可数对象(如人、球)和不可数背景(如草地)。
- 为每个对象提取边界框(Bounding Box),并裁剪对应的对象特征(Object Features)。
- 关系特征生成:
- 通过合并相关对象的区域(如“人”和“球”的联合区域)生成关系特征(Relation Features),用于后续关系预测。
- Panoptic FPN处理:
- 输出: 对象特征和关系特征
第二阶段:Scene Graph Prediction
- 输入:第一阶段提取的对象特征和关系特征。
- 预测任务:
- 将特征输入现有SGG模型(如MotifNet、VCTree等),输出关系三元组:
〈人 - 拿着 - 球〉〈球 - 在 - 草地上〉
- 将特征输入现有SGG模型(如MotifNet、VCTree等),输出关系三元组:
One-Stage PSG Baseline - PSGTR
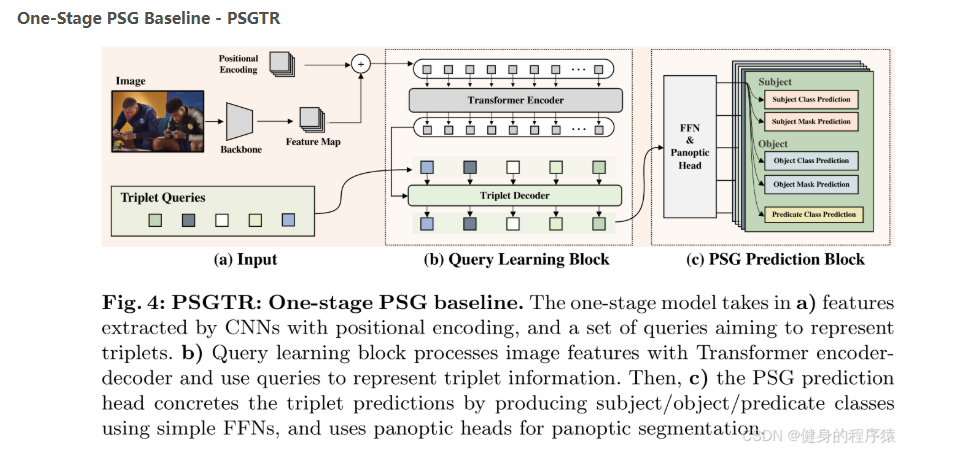
目标:从输入图像直接生成全景场景图(Panoptic Scene Graph, PSG),无需两阶段分割和关系预测的分离流程。
核心公式:Pr(G|I) = Pr(M, O, R|I)
其中:
- G:场景图(Scene Graph)
- I:输入图像
- M:分割掩码(Mask)
- O:对象类别(Object)
- R:关系(Relation)
(a) 输入(Input)
- 图像特征提取:
- CNN主干网络(如ResNet)提取图像特征图(Feature Map)。
- 加入位置编码(Positional Encoding)保留空间信息。
- 三元组查询(Triplet Queries)初始化:
- 一组可训练的查询向量(Triplet Queries)作为三元组候选的初始表示。
(b) 查询学习块(Query Learning Block)
- Transformer编码器-解码器:
- 编码器:增强图像特征的全局上下文(如“人”和“球”的关联)。
- 解码器:通过查询与特征交互,学习三元组语义(如“踢”需结合人和球的特征)。
- 输出:更新后的查询向量,携带三元组信息。
(c) PSG预测块(PSG Prediction Block)
-
三元组分类:
-
简单前馈网络(FFN)预测主体/对象类别(如“人”“球”)和谓词(如“踢”)。
-
预测后的匹配: 匈牙利匹配(Hungarian Matching):
-
将预测的三元组与真实三元组进行最优匹配,最小化匹配代价:
Cₜₘ(Tᵢ, Gₒ₍ᵢ₎) = ∑ Cₛₑ₉(Tₖ, Gₖ) + Cₒ(Tₖ, Gₖ) + Cᵣ(Tₖ, Gₖ)
- k ∈ {S, O, R}:分别计算Subject、Object、Relation的匹配代价。
- Cₛₑ₉:分割掩码的Dice损失或F1损失。
- Cₒ/Cᵣ:对象/关系分类的交叉熵损失。
-
总损失 = 分类损失(交叉熵) + 分割损失(F1/Dice Loss) + 定位损失(L1)
-
-
-
全景分割:
- 并行全景头(Panoptic Head)生成对象分割掩码(如人的像素区域)。
PSGFormer
PSGFormer是一种基于Transformer的单阶段场景图生成方法,通过双查询机制(物体查询+关系查询)直接预测三元组(Subject-Predicate-Object)。整体流程分为四个模块:
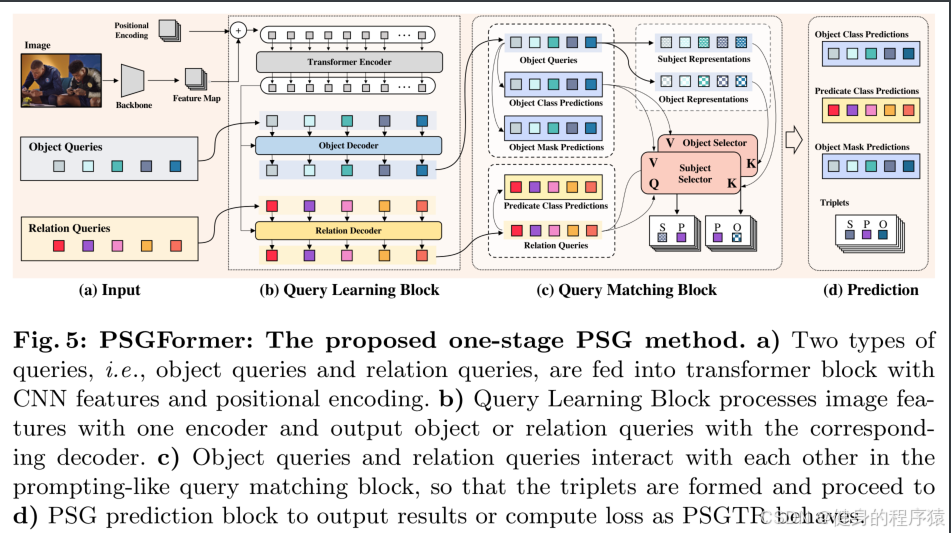
(a) 输入模块
前两个阶段, 和之前相比就是查询变成了object和relation的分开查询
- 图像特征提取:
- CNN主干(如ResNet)生成多尺度特征图(Feature Map)
- 加入位置编码(Positional Encoding)保留空间信息
- 双查询初始化:
- 物体查询(Object Queries):可学习向量,用于定位和分类物体(如人、球)
- 关系查询(Relation Queries):可学习向量,用于预测谓词(如踢、拿)
(b) 查询学习模块: 一个编码器的输出将被分别输入两个解码器中
- Transformer编码器:
- 对图像特征进行全局上下文建模(如捕捉"人-球"的空间关联)
- 双解码器设计:
- 物体解码器:输出物体特征(Object Representatives)
- 关系解码器:输出关系特征(Relation Activities)
- 通过交叉注意力机制实现特征交互
(c) 查询匹配模块
-
物体查询处理路径(左半部分)
- 输入:Object Queries(可学习向量,携带物体位置和语义信息)
- 处理流程:
- 物体特征解码:
- 通过Transformer解码器生成两种表示:
Subject Representations(主体表示,如"人")Object Representations(客体表示,如"球")
- 通过Transformer解码器生成两种表示:
- 分类与分割预测:
Object Class Predictions:线性层预测物体类别(如Person/Ball)Object Mask Predictions:分割头生成像素级掩码
- 物体特征解码:
-
关系查询处理路径(右半部分)
-
输入:Relation Queries(可学习向量,编码潜在关系语义)
-
关键操作:
-
物体选择器(Object Selector):
-
从所有物体表示中筛选与当前关系相关的候选:
Scandidate =TopK( Attention(relation_query,subject_repr) )
-
-
三元组注意力交互:
-
关系查询作为
Query,主体/客体表示作为Key/Value:Predicate_Logits=CrossAttention(relation_query, [subject_repr;object_repr])
-
-
-
-
动态匹配过程(核心交互)
-
匹配逻辑:
-
通过共享的
Object Selector确保关系与物体语义对齐:
- 例:关系查询"踢"会优先匹配
subject_repr="人"和object_repr="球"
- 例:关系查询"踢"会优先匹配
-
使用匈牙利算法解决一对多匹配(如一个人可能同时"踢球"和"拿球")
-
-
数学表示:
![]()
-
PSGFormer,它具有显式关系建模和类似提示的匹配机制。首先我们提出两个Query,一个叫Relation query,一个是object Query, 和PSGTR一样,object和relation query with CNN features 和 position encoding会被喂入transformer encoder,但decode的时候它俩会分别有一个自己的decoder。
Object & Relation Query Matching Block:每一个object query都会有一个FFN产生的object prediction和一个全景head产生的mask prediction。然后每一个relation query会产生一个关系预测。因为object query 和relation query是独立的,因此需要将二者连接来产生三元组。因此我们提出了一个类似提示的查询匹配块。
为了引导促成( prompting )一个relation,我们希望有一个sub obj 对,因此我们提出了两个选择器——subject selector和object selector。对于一个给出的Relation,subject和object selector应该会返回一个最合适的的候选来形成一个完整的三元组。
我们使用一个在object queries和relation query上标准的余弦相似度模型。同时,因此object query需要两个FFN来获取到subject representation和object representation。
作者的思考
- 或许对于图片的像素可以当做点云中的一个点来进行处理?
- RGB图片投射为3D点云,cross-model增强得到结果?
- 构造3D bounding box数据集?
- context imformation真的那么重要嘛,或者说是不是整张图的所有背景都非常重要,或许背景中只有一部分是很重要的,但另一部分的存在只会影响到物体的预测(非常理的特殊组合)。例如一般车会在路上,但如果有一张图里车在房顶上,那这时背景信息的存在会不会反而影响到了对车的物体的识别。
读论文 Panoptic Scene Graph Generation
综述
作者开篇表示自己的观点: 使用边界框来检测对象,然后预测它们的成对关系的范式会导致一些问题,阻碍该领域的进展
- 过多的考虑冗余类, 比如头发, 凳子等一些没有用的物体会被多次标记
- 忽略了对理解上下文至关重要的背景信息
于是本文引入了全景场景图生成(PSG),这是一个新的问题任务,它要求模型基于全景分割而不是刚性的边界框来生成更全面的场景图表示
本文还提供了一个高质量的PSG数据集,其中包含49 k来自COCO和Visual Genome的良好标记的重叠图像
为了进行基准测试,本文有两个模型:
四个两阶段基准模型,它们是对SGG中的经典方法进行修改的,以及两个单阶段基准模型,分别称为PSGTR和PSGFormer,它们是基于高效的基于Transformer的检测器:
即, 详细信息PSGTR使用一组查询来直接学习三元组,而PSGFormer则以来自两个Transformer解码器的查询的形式分别对对象和关系进行建模,然后是类似于提示的关系对象匹配机制
作者的idea: 不用边界框, 用全景分割:
- 理想情况下,对象的基础应该是清晰和精确的,场景图不仅应该关注图像中的显著区域和关系,而且应该足够全面,以便于理解场景。我们认为,与边界框相比,全景分割标签将是构建场景图的更好选择。为此,我们引入了一个新问题,即全景场景图生成(PSG),目标是基于全景分割而不是刚性边界框生成场景图表示。
为了进行基准测试:
- 论文通过将四种经典的SGG方法集成到经典的全景分割框架中来构建四个两阶段模型
- 论文还将DETR(一种高效的基于Transformer的检测器)转换为一个称为PSGTR的单阶段PSG模型,该模型已被证明对PSG任务有效。
- 论文进一步提供了另一个称为PSGFormer的一阶段基准模型,它扩展了PSGTR,并进行了两项改进:
- 1)在两个Transformer解码器中以查询的形式分别对对象和关系进行建模
- 2)类似于编译的交互机制。
相关工作
从SGG到PSG
场景图生成现有的场景图生成(SGG)方法主要由两阶段流水线组成,包括对象检测和成对谓词估计。给定边界框,早期的工作使用条件随机场预测谓词,或者将谓词预测转换为分类问题。受知识图嵌入的启发,VTransE 和UVTransE 被提出用于显式谓词建模。后续工作已经研究了各种变体,例如,RNN和基于图的建模,基于能量的模型,外部知识[,以及最近的语言监督。最近的研究已经将注意力转移到与SGG数据集相关的问题上,例如谓词的长尾分布
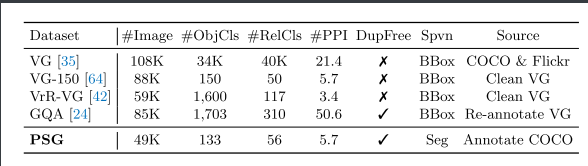
表1:经典SGG数据集和PSG数据集之间的比较。#PPI计数每个图像的同品种器械。DupFree检查是否清除了重复的对象基础。Spvn指示对象是否通过边界框或分割固定。
论文提出了SSG数据集的一些漏洞: 过度的视觉无关谓词,以及边界框的不准确定位。
特别是最近的一项研究表明,训练SGG模型同时生成场景图和预测语义分割掩码可以带来改进,这激发了我们的研究。在我们的工作中,我们研究了全景分割为基础的场景图生成在一个更系统的方式,制定一个新的问题,并建立一个新的基准。
我们还注意到,一个密切相关的主题人机交互(HOI)与SGG有着相似的目标,即,以从图像中检测显著关系。然而,HOI任务将模型限制为仅检测与人相关的关系,而忽略了对象之间的有价值信息,这些信息通常对全面的场景理解至关重要。
可迁移点: 许多HOI方法适用于SGG任务,其中一些启发了我们的PSG基准模型。
SSG数据集的发展:
早期的SGG作品构建了几个较小的数据集,而大规模的Visual Genome(VG)在2017年发布后迅速成为标准的SGG数据集,促使后续工作在更现实的环境中进行研究。
然而,社区提出了VG的几个关键缺陷,因此,一些VG变体逐渐被引入来解决一些问题。人们注意到VG包含了33877个不实用的对象类和40480个不实用的谓词类,这使得VG-150 [64]只保留了最常见的150个对象类和50个谓词类,以实现更现实的设置。
后来,VrR-VG 认为VG-150中的许多谓词可以通过统计先验很容易地估计出来,因此决定重新过滤原始VG类别,只保留视觉相关的谓词类。然而,通过仔细检查VrR-VG,我们发现许多谓词是冗余的(例如,besides,besides。beyond,down)。类似的缺点出现在另一个具有场景图注释的大规模数据集中,称为GQA 。总之,尽管关系在SGG任务中起着关键作用,但遗憾的是,在所有现有的SGG数据集中,关系的系统定义都被忽视了。
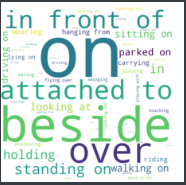
在PSG数据集中,考虑了单词之间的全面覆盖范围和非重叠的覆盖范围, 然后定义了一个具有56个类的谓词字典,可以更好地提出场景图问题; 可以看到, 经常使用的谓词: on, in front of, beside, attached to等
除了谓词定义的问题外,当前SGG数据集还存在另一个关键缺陷——它们均采用基于边界框的物体标注方法,这不可避免地引发了一系列问题:
- 标注粗糙:边界框无法达到像素级精度;
- 覆盖不全:边界框无法标注背景信息(如路面、天空);
- 冗余信息:现有数据集常标注次要物体(如“头部”),生成无意义关系(如“人-有-头发”);
- 重复标注:同一物体可能被多个边界框重复标注。
这些问题共同导致当前SGG数据集质量低下,阻碍了领域发展。为此,本文提出的PSG数据集通过全景分割技术对图像进行标注,结合COCO数据集中合理的物体类别粒度,以解决上述所有缺陷。表1对比了PSG数据集与经典SGG数据集的统计信息。
全景分割全景分割任务统一了语义分割和实例分割以实现全面的场景理解,第一种方法是语义分割模型和实例分割模型的简单组合,以分别产生填充掩码和事物掩码。后续工作,如Panoptic FPN 和UPSNet ,旨在通过多任务学习将两个任务统一在单个模型中,以提高计算效率和分割性能。最近的办法(例如,MaskFormer ,Panoptic Segformer 和K-Net )已经转向基于transformer的更高效的架构,如DETR,通过将检测任务转换为集合预测问题来简化检测管道。
PSG问题
我们首先简要回顾一下经典场景图生成(SGG)任务的目标,该任务旨在对分布进行建模:
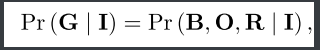
其中I是输入图像,G是期望的场景图,其包括边界框B = {b1,...,bn}和标签O = {o 1,...,on},以及它们的关系集合R = {r1,...,rl}。更具体地说,bi 表示框的坐标,oi 是某个物体, 属于所有对象类的集合; ri是某种关系, 属于所有关系类的集合
PSG并不通过边界框坐标定位每个对象,而是通过更细粒度的全景分割来确定每个对象的位置。为了简洁起见,将对象和背景都称为对象。
-
利用全景分割,图像被分割成一组掩模M = {m1,...,mn},其中mi ∈ {0,1}H×W.
全景分割(Panoptic Segmentation)的数学表示形式,其核心是将一张图像分割成若干二值掩码(binary masks),每个掩码对应图像中的一个独立物体或区域(待学习)
H×W:图像的高度(Height)和宽度(Width),即掩码的尺寸与原始图像一致。
-
其中, 每一个分割出来的musk都关联了一个带有标号的object, 同时还预测了对象之间的一组relation。musk之间并不能重叠
-
由此可得,PSG任务模拟了以下分布(可以看到, 主要区别在M):
![]()
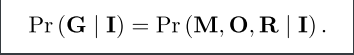
数据集构建
文章用三个步骤来构建数据集:
COCO: 大规模图像识别数据集,专注于物体检测、分割和描述生成
VG: 场景图(Scene Graph)数据集,专注于物体关系建模。
构建PSG数据集,需同时满足:
- 像素级分割(来自COCO)→ 解决边界框的粗糙性问题。
- 丰富的关系标注(来自VG)→ 提供场景图所需的谓词。
第一步:粗略的COCO和VG融合:
- 图像匹配:
- 选取COCO和VG的共有48749张图像作为基础。
- 对象类别对齐:
- 人工映射表:将VG的物体类别(如“animal”)与COCO的80类(如“dog”)匹配,确保语义一致。
- 空间重叠验证:
- 计算VG边界框与COCO分割掩码的IoU(交并比),保留IoU > 0.5的匹配对。
- 过滤掉VG中边界框覆盖多个COCO物体的情况(如“人”的框包含“头发”和“衣服”)。
- 谓词迁移:
- 对匹配成功的物体对(如COCO中的“人”和“自行车”),从VG中提取对应的关系谓词(如“riding”)。
- 生成初步三元组:
<主体掩码, 谓词, 客体掩码>。
- 标签系统不匹配:VG的类别更粗粒度(如“vehicle”对应COCO的“car”“bus”等),需人工干预。
- 定位偏差:VG的边界框可能仅部分覆盖COCO分割区域(如框住“自行车轮子”但分割是整个自行车)。
第二步:构建简洁的谓词词典(56词):
目标:解决VG谓词语义重叠冗余的问题(如“on/over/above”)。
筛选策略:
- 参考多数据集:
- 分析初始PSG噪声数据、VG-150、VrR-VG、GQA中的高频谓词。
- 去重与合并:
- 语义独立化:保留最典型谓词(如仅用“on”合并“over”“above”)。
- 剔除模糊谓词:删除“has”“near”等无明确视觉意义的谓词。
- 覆盖性验证:
- 确保56类谓词能描述数据集中95%以上的关系(如“parked on”替代泛化的“on”)。
Step 3: 严格人工标注流程
目标:清洗噪声并补充VG未覆盖的关系(如背景关系)。
标注规则:
- 噪声清洗:
- 删除自动生成的不合理三元组
- 关系扩展(主要是因为多了背景这个对象):
- 物体-背景:如“车-停在-路面”(COCO有“路面”分割,VG无此类关系)。
- 背景-背景:如“天空-在-山脉上方”。
- 谓词精确化:
- 强制使用最具体谓词(如用“parked on”而非泛化的“on”描述车与路面的关系)。
- 审核和测试集标注:由论文作者亲自标注,确保最高可靠性。
PSG的评估与指标
对PSG任务的评价: 参照经典场景图生成(SGG)任务的设定,PSG任务包含两个子任务:
- 谓词分类(PredCls):给定真实物体标签和位置, 生成场景图,用于隔离分割性能干扰,仅评估关系预测能力 (没那么重要)
- 适用性:仅适用于两阶段PSG模型(见第4.1节),因一阶段模型无法直接利用给定的分割结果。
- 场景图生成(SGDet):从零生成完整场景图,是PSG任务的核心评估目标(重要)
注:经典SGG任务中的场景图分类(SGCls)子任务在PSG中不适用。
- 原因:SGG可通过Faster R-CNN等检测器直接替换预测框为真实框,但全景分割模型无法直接使用真实分割掩码进行分类(需端到端训练),因此SGCls对PSG无效。
PSG的评估:
-
R@K与mR@K:
-
R@K(召回率@K):模型预测的前K个三元组中,正确匹配真实三元组的比例
-
mR@K(平均召回率@K):按谓词类别计算的召回率的平均值,解决长尾分布问题
mR@K缓解了谓词类别不平衡问题(如“骑”比“停放”更常见)
-
匹配条件:
-
主体和客体的分割掩码IoU > 0.5
- 引入掩码IoU阈值(0.5)替代边界框IoU,强化像素级精度要求。
-
三元组(主体-谓词-客体)类别全部正确。
-
-
-
全景分割指标(如PQ):
- 可用于模型诊断(如分割质量分析),但不作为PSG核心指标。
可以发现, PSG的评估更严格(依赖分割质量),而SGG仅需框级匹配
PSG的基本模型
这篇论文中, PSG的基本模型参照了SSG的模型设计
双阶段模型
大多数现有的场景图生成(SGG)方法采用两阶段流程:
- 使用现成的目标检测器(如Faster R-CNN)检测物体;
- 在检测到的物体之间进行成对关系预测。
- 第一阶段:使用预训练的全景分割模型(Panoptic FPN)提取物体的初始特征、分割掩码和类别预测;
- 第二阶段:将提取的物体特征和关系特征输入经典的SGG关系预测模块(如IMP、MOTIFS、VCTree、GPSNet),生成最终的场景图预测。
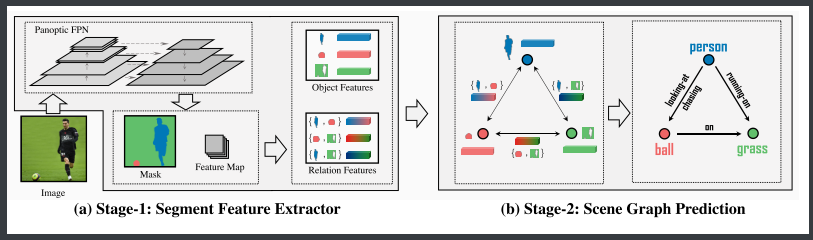
- (a) :Panoptic FPN 为每个物体生成分割掩码,并计算其最小外接矩形框,用于获取物体特征( Object Features )。相关物体的联合区域可生成关系特征(Relation Features)
- (b) :提取的物体特征和关系特征输入现有的SGG关系模型,预测关系三元组(如“人-看-球”)。
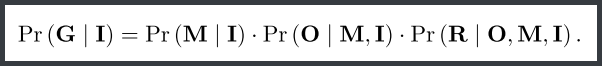
这个公式形象地表明了Musk=>Object=>Relation的预测步骤
单阶段模型PSGTR
PSGTR无需依赖物体检测前置步骤,直接联合建模场景图生成和像素级分割任务
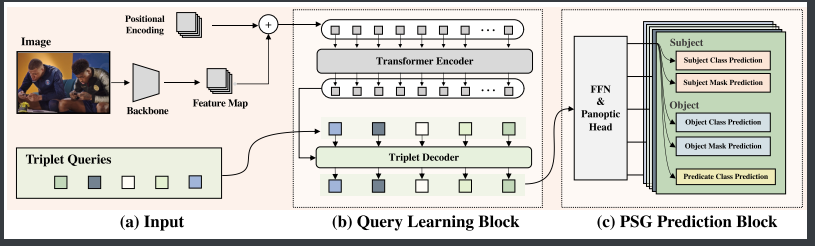
步骤1:图像特征提取
- 输入:原始图像(如480×640分辨率)。
- CNN骨干网络(Backbone) - 比如ResNet-50:
- 提取多尺度特征图(如C5层输出特征图尺寸为15×20×2048)得到feature map
- 位置编码(Positional Encoding):
- 为特征图添加空间位置信息,增强Transformer对物体位置的感知。
输出:带有位置信息的图像特征张量(尺寸:H×W×C)
步骤2:三元组查询初始化(对应图4-a)
- 可学习的三元组查询(Triplet Queries):
- 初始化一组N个(如100个)随机向量(维度256),每个查询对应一个潜在的三元组(主体-谓词-客体)。
- 查询作用:
- 通过训练,每个查询将学习捕捉特定类型的三元组模式(如“人-骑-自行车”)。
输出:三元组查询矩阵(尺寸:N×256)。
步骤3:Transformer编码器-解码器处理
- 编码器(Encoder):
- 图像特征放入多头自注意力中
- 解码器(Decoder):
- 查询+编码器输出一起进行注意力的处理
输出:更新后的三元组特征(尺寸:N×256),包含物体和关系的上下文信息。
步骤4:三元组预测
- 类别预测(FFN Heads):
- 主体/客体分类头:3层MLP,预测出subject class & object class
- 谓词分类头:3层MLP,预测出predicate(谓语) class
- 分割预测(Panoptic Heads):
- 两个独立的全景分割头:
- 分别生成主体和客体的二值掩码: subject musk & object musk
- 两个独立的全景分割头:
输出:
- 类别预测:N×(133物体类 + 56谓词类)
- 分割掩码:N×2×H×W(每个三元组对应主体和客体的掩码)。
步骤5:三元组匈牙利匹配
-
匹配成本计算:
- 分割匹配成本(Cseg):
- 计算预测掩码与真实掩码的DICE系数差异。
- 分类匹配成本(Ccls):
- 计算预测类别与真实类别的交叉熵损失。
- 分割匹配成本(Cseg):
-
最优匹配搜索:
-
使用匈牙利算法找到预测三元组与真实三元组的最小成本匹配
![]()
-
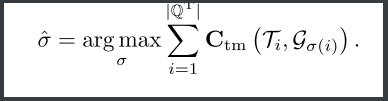
输出:匹配后的三元组索引
步骤6:损失计算与优化
- 总损失:
- 分割损失(Lseg):DICE/F1损失,优化掩码精度。
- 分类损失(Lcls):交叉熵损失,优化类别预测。
- 反向传播:
- 联合更新CNN骨干、Transformer和预测头的参数。
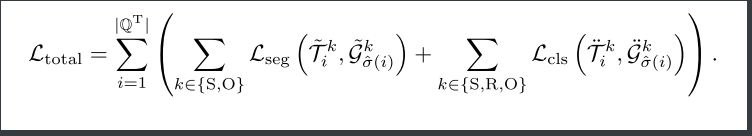
PSGFormer
PSGFormer是基于PSGTR改进的单阶段全景场景图生成模型; 使用了分离对象查询+关系查询
阶段1:输入预处理与特征提取(这部分差不多)
步骤1.1 图像输入标准化
- 输入:原始RGB图像(如480×640×3)
- 预处理:短边缩放到480px,长边不超过1333px,保持纵横比
步骤1.2 骨干网络特征提取
- 使用ResNet-50/FPN作为骨干网络
- 输出多尺度特征图:
- 高分辨率浅层特征(用于小物体分割)
- 低分辨率深层特征(用于语义理解)
步骤1.3 位置编码注入
- 对特征图添加正弦位置编码(Positional Encoding)
- 输出:带有空间信息的特征张量 F∈RH×W×C
阶段2:双类型查询初始化
步骤2.1 对象查询生成
- 初始化100个可学习向量 QO=
- 每个查询维度:256(对应Transformer隐藏层大小)
步骤2.2 关系查询生成
- 并行初始化100个关系查询 QR=
- 设计目标:
- 对象查询专注物体实例(如"人")
- 关系查询专注交互区域(如"骑"的动作区域)
阶段3:Transformer编码器-解码器处理
步骤3.1 特征全局编码
- 编码器输入:F + 位置编码
- 通过6层多头自注意力(MHSA)建模全局上下文
- 输出:增强后的特征 F′
步骤3.2 双分支解码
- 对象解码器(Object Decoder):
- 输入:对象查询 QO + F′
- 通过交叉注意力聚焦物体区域
- 输出:物体特征
- 关系解码器(Relation Decoder):
- 输入:关系查询 QR + F′
- 通过交叉注意力聚焦交互区域(如人与自行车的接触部分)
- 输出:关系特征
阶段4:三元组动态匹配
-
输入准备:输入transformer输出的特征数据
- 对象特征 {O1′,...,O100′}:来自对象解码器,每个Oj '∈R256包含物体类别和位置信息。
- 关系特征 {R1′,...,R100′}:来自关系解码器,每个Ri ′∈R256编码谓词语义(如"骑"的动作特征)。
-
步骤1:角色敏感特征提取
- 对象特征目前还是针对所有物体的特征, 没有针对主宾进行特殊对待, 也就是没有"角色敏感", 所以我们需要再提取一波特征, 使其"角色敏感"一点
- 主体选择器FFN fs:
- 输入:对象特征Oj ′
- 输出:主体角色特征 O-js=f s(Oj ′)
- 作用:强调对象作为主体的属性(如"人"作为"骑"的主动方)
- 客体选择器FFN fo:
- 输出:客体角色特征 O-jo=fo(Oj ′)
- 作用:强调对象作为客体的属性(如"自行车"作为被骑的被动方)
-
步骤2:关系-对象相似度计算: 在分角色的计算出主宾对象的特征后, 我们就可以为动作匹配主宾了
这就是我们之前说的: 填空式-----我先准备好relation, 然后主宾的部分就是我们要填入的空, 这时候直接根据相似度匹配最可能的主宾就行了
对每个关系查询Ri ′:
- 主体匹配:
- 计算Ri ′与所有O-js (主题选择器输出的特征) 的余弦相似度:
![]()
- 选择相似度最高的对象作为主体:
![]()
- 计算Ri ′与所有O-js (主题选择器输出的特征) 的余弦相似度:
- 客体匹配:
- 同理选择Oi,但使用OjO特征计算相似度
- 主体匹配:
-
步骤3:三元组组装 (不多说)
- 组合匹配结果:(Si,Ri ′,Oi)
- 示例:若Ri′="骑",Si="人",Oi="自行车" → 生成三元组"人-骑-自行车"
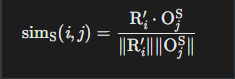
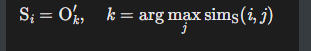
阶段5:预测与损失计算
步骤5.1 三元组预测
- 类别预测:
- 主体/客体:3层MLP分类头 → 133类物体
- 谓词:3层MLP分类头 → 56类关系
- 分割预测:
- 两个全景头生成主体/客体的二值掩码
步骤5.2 损失函数
-
三元组匹配损失
(匈牙利算法):
- 分割损失:DICE系数(掩码IoU)
- 分类损失:交叉熵(主体/谓词/客体)
-
辅助损失:
- 全景分割DETR的物体去重损失
实验结果
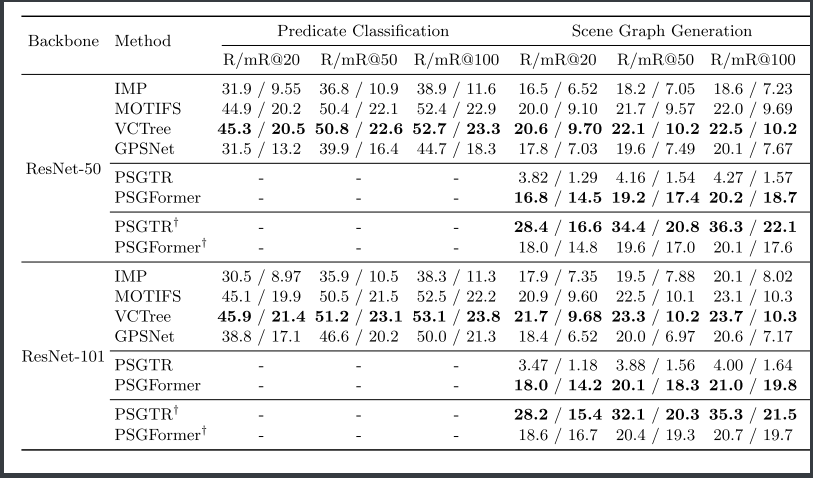
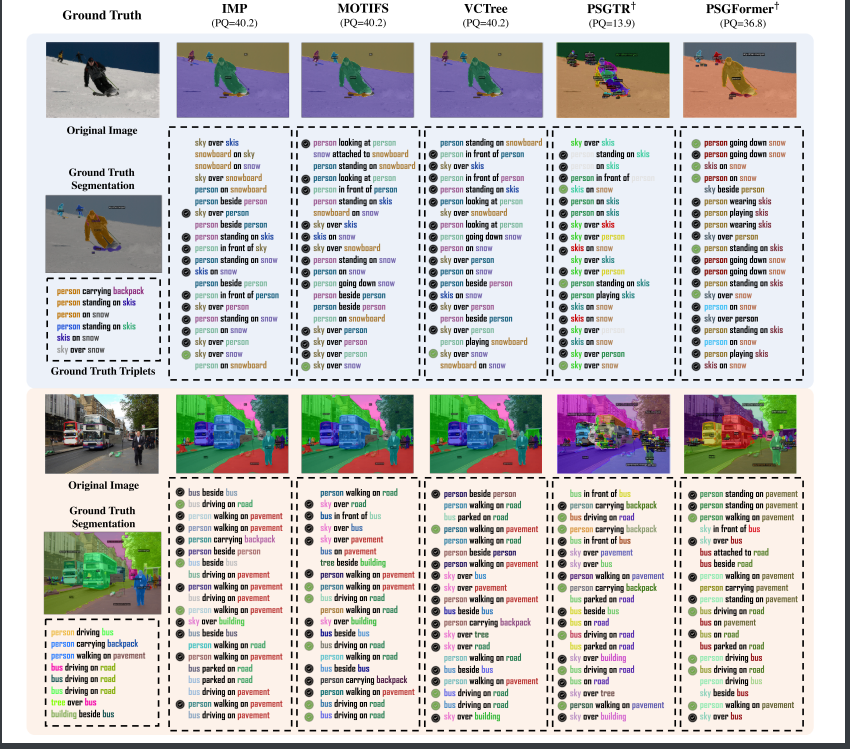
-
二阶段内部比较: 分割性能对最终结果有不小的影响
-
长时训练后, PSGTR体现出较强的准确率, 而在短时训练时, 可可以看到PSGTR很弱; PSGFormer在R上也有落后, 但是它可以保证较高的mR, 也就是对一些稍微偏门的词预测也不错;
- R@K:正确预测三元组数量/三元组总数
- mR@K对每个谓词类别单独计算R@K,再对所有谓词取平均。
R高但是mR低: 数据集中某些谓词(如“有”)占比过高,模型倾向于预测这些“安全”关系。
-
在ResNet变强后, 二阶段PSG和单阶段的PSGTR效果都有变好, 但是PSGFormer并未变好
posted on 2025-05-26 21:00 Fg0_MURAMASA 阅读(232) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号