
pytorch情感分类的初步学习
本文主要参考pytorch入门+实战系列五:pytorch情感分类 - 知乎. 若有兴趣, 大家可以去看原文😃
一.任务概述
情感分类是自然语言处理(NLP)中的经典任务,目标是对文本(如评论、推文)的情感倾向进行分类(如二分类:正面/负面)
数据用得是IMDB影评数据集,首先,就是这个数据集的准备,使用torchtext工具包来完成,并且帮助我们来创建一个词典。然后就用pytorch实现三个模型, 在进行训练.
二.包导入和随机种子
import torch
import torch.nn as nn
import torch.nn.functional as F
from torchtext import data
import torch.optim as optim
import time
SEED = 1234
# 固定随机种子和确定性算法,使得每次运行代码时,模型的初始化、数据加载顺序、dropout 等随机操作的结果完全一致,便于调试和结果对比
torch.manual_seed(SEED) # 通过 torch.manual_seed(SEED) 设置 PyTorch 的随机种子,确保 CPU 上的随机操作可复现。
torch.cuda.manual_seed(SEED) # torch.cuda.manual_seed(SEED) 设置 GPU 上的随机种子,保证 CUDA 操作的随机性一致
torch.backends.cudnn.deterministic = True # torch.backends.cudnn.deterministic = True 强制 cuDNN 使用确定性算法,避免因不同运行导致的随机性差异
三.导入数据集
# 运用torchtext
TEXT = data.Field(tokenize='spacy')
LABEL = data.LabelField(dtype=torch.float)
print(vars(train_data.examples[0]))
Field是torchtext的一个类,用于文本预处理;tokenize='spacy':指定使用 spaCy 分词器对文本进行分词(例如:"I love NLP"→["I", "love", "NLP"])。data.LabelField是 PyTorch 的torchtext库中的一个类, 可以对标签进行标准化处理,并将其转换为模型训练所需的张量格式dtype=torch.float:指定标签的数据类型为浮点数(此次任务是二分类任务,就用 0/1 标签就行), 如果是多分类任务,可能会用torch.long
四.数据集处理: 划分数据集
train_data, valid_data = train_data.split(random_state=random.seed(SEED))
print(f'Number of training examples: {len(train_data)}')
print(f'Number of validation examples: {len(valid_data)}')
print(f'Number of testing examples: {len(test_data)}')
## 结果:
Number of training examples: 17500
Number of validation examples: 7500
Number of testing examples: 25000
- train_data.split():将原始的 train_data 按默认比例(通常是 70% 训练集 / 30% 验证集)划分为新的训练集 train_data 和验证集 valid_data
- random_state=random.seed(SEED):固定随机种子(SEED=1234),确保每次划分结果一致(可复现性)
- 防止过拟合(Overfitting):
- 优化超参数(Hyperparameter Tuning):
如学习率、网络层数、Dropout 率等,需通过验证集调整,而非直接用测试集(避免“数据泄露”)。
五.创建词典
- 将文本和标签转换为数值形式,供模型处理。
- 利用预训练词向量 提升模型语义理解能力。
- 控制词表大小,平衡计算效率与覆盖率。
# 基于训练集 train_data 构建文本的词表,将每个单词映射到一个唯一的整数索引,同时支持加载预训练词向量
TEXT.build_vocab(train_data, max_size=25000, vectors="glove.6B.100d", unk_init=torch.Tensor.normal_)
LABEL.build_vocab(train_data)
print(f"Unique tokens in TEXT vocabulary: {len(TEXT.vocab)}") # 25002
print(f"Unique tokens in LABEL vocabulary: {len(LABEL.vocab)}") # 2
-
max_size=25000: 限制词表的最大大小为 25,000。即只保留数据集中出现频率最高的 25,000 个单词
其余视为低频词(替换为
<unk>) -
vectors="glove.6B.100d": 加载预训练的 GloVe 词向量(维度为 100),词向量会与词表自动对齐:
- 例如,单词 "cat" 在词表中的索引会对应 GloVe 中 "cat" 的 100 维向量。
- 若词表中某单词不在 GloVe 中,则按下文的
unk_init初始化。
-
unk_init=torch.Tensor.normal_ : 对未登录词(
<unk>)或未在 GloVe 中出现的单词,用正态分布随机初始化其词向量。 -
LABEL.build_vocab(train_data): 构建标签的词表(适用于分类任务,如情感分析的
pos/neg):- 标签会被映射为整数(如
pos→1,neg→0),存储在LABEL.vocab.stoi中。
- 标签会被映射为整数(如
-
使用TEXT.vocab和LABEL.vocab即可访问词表:
itos:索引 → 单词(列表),用于将模型输出转换为可读文本。stoi:单词 → 索引(字典),用于将文本转换为模型输入。
六.创建迭代器
使用 torchtext 的 BucketIterator 来创建数据迭代器(DataLoader),并对一个训练批次(batch)的样本进行可视化。
BATCH_SIZE = 64 # 先确定好一个批次的样本数
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # 自动检测是否可用 GPU(cuda),否则使用 CPU
# 创建迭代器
train_iterator, valid_iterator, test_iterator = data.BucketIterator.splits(
(train_data, valid_data, test_data),
batch_size=BATCH_SIZE,
device=device)
# 通过这行代码可以看到各样本的第 2 个词, 详情就不细说了
[TEXT.vocab.itos[i] for i in next(iter(train_iterator)).text[1, :]]
data.BucketIterator.splits: 将数据集(train_data,valid_data,test_data)转换为可迭代的批次数据,支持高效训练和评估- 输出: 赋值给了三个迭代器, 分别对应训练数据/验证数据/测试数据的迭代器
- 输入:
- 三类数据: (train_data, valid_data, test_data)
batch_size:每个批次的样本数device:指定数据加载到 GPU 或 CPUBucketIterator的额外特性:自动将长度相似的样本分到同一批次,减少填充符(<pad>)的使用,提升计算效率。
七.Word Averaging模型
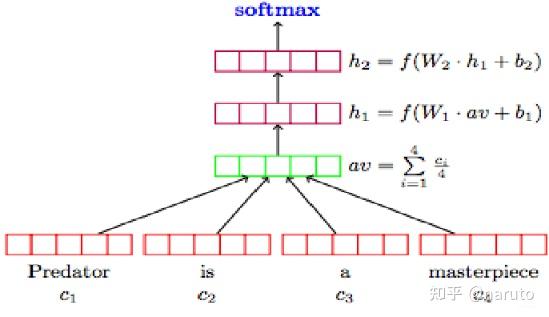
我们从简单开始, word averaging模型正如其名, 核心思想是 将句子中所有词的词向量取平均,然后通过分类器预测标签; 仅包含embedding, average pooling, Fully Connected Layer:
输入句子: "I love NLP"
↓
分词: ["I", "love", "NLP"], 这之中, 还经历了glove.6B.100d词表的处理
↓
词向量: [v₁, v₂, v₃] (每个v是100维向量)
↓
平均池化: (v₁ + v₂ + v₃) / 3 → 句子向量 (100维)
↓
全连接层: 100维 → 2维(二分类)
↓
输出: 概率 (如 "正面": 0.8, "负面": 0.2)
思考一下, 我们需要几个层?
- 一个embedding层, 将词转化为词向量
- nn.embedding 应该获取到词表的总数, 词向量的维度, 已经填充符的信息
- 一个平均池化层, 得到句子专属的向量
- 偏计算的维度
- 一个全连接层, 用于生成输出
- 应该获取句子向量原本的维度, 和我们需要映射到的维度
class WordAVGModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, output_dim, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx)
# padding_idx=pad_idx: 指定填充符 <pad> 的索引(通常为 1),其对应的词向量会被强制设为全 0(避免影响池化结果)
self.fc = nn.Linear(embedding_dim, output_dim)
def forward(self, text):
# 输入 text 默认填好了 [sent_len, batch_size](torchtext 的默认格式), 输出[sent len, batch size, emb dim]
embedded = self.embedding(text)
# 维度调整, 便于后续计算
embedded = embedded.permute(1, 0, 2) #[batch size, sent len, emb dim]
# 这个就相当于在seq_len维度上做了一个平均
pooled = F.avg_pool2d(embedded, (embedded.shape[1], 1)).squeeze(1) #[batch size, embedding_dim]
return self.fc(pooled)
假设输入
embedded的形状为[sent_len, batch_size, emb_dim]:
参数含义:
permute(1, 0, 2)表示将原始张量的维度按以下顺序重新排列:
- 第1维(索引 0)→ 原始的第 1 维(
batch_size)- 第2维(索引 1)→ 原始的第 0 维(
sent_len)- 第3维(索引 2)→ 原始的第 2 维(
emb_dim,保持不变)操作结果:
原始形状[10, 64, 100]→ 新形状[64, 10, 100]大多数框架(如 PyTorch、TensorFlow)的卷积/池化层默认假设输入形状为
[batch_size, channels, height, width]。将
batch_size放在第0维是标准做法,便于批量处理在此函数中,
avg_pool2d默认在张量的 最后两个维度 上操作(即(H, W)),因此需要将sent_len维度放在倒数第二维
- F.avg_pool2d的功能:对输入张量的最后两个维度(H, W)进行平均池化。
input:输入张量(必须是 4D,形状为[batch, channel, H, W])。kernel_size:池化窗口大小(kH, kW)。
# 定义一些模型初始化需要的参数, 相当于针对此次训练对象对上面定义的模型结构填空
INPUT_DIM = len(TEXT.vocab) # 指定词表的大小, INPUT_DIM = 25002 (25,000 个单词 + 2 个特殊标记(<unk> 和 <pad>))
# nn.Embedding 层需要知道词表大小,以初始化一个形状为 [INPUT_DIM, EMBEDDING_DIM] 的词嵌入矩阵。
EMBEDDING_DIM = 100 # 定义每个单词的词向量的维度
OUTPUT_DIM = 1 # 指定模型的输出维度, 这是一个二分类任务, 所以输出 1 维(0/1 或概率)就行
PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token] # 指定填充符 <pad> 在词表中的索引,用于屏蔽无效位置
# 调用模型初始化函数
model = WordAVGModel(INPUT_DIM, EMBEDDING_DIM, OUTPUT_DIM, PAD_IDX)
八.训练
之前不是说过要使用预训练的词向量数据吗, 我们来先导入一下
- 这就是常说的迁移和微调的思想
# 通过 TEXT.build_vocab(train_data, vectors="glove.6B.100d") 加载的预训练词向量矩阵,形状为 [vocab_size, embedding_dim]
pretrained_embeddings = TEXT.vocab.vectors
# 将预训练词向量复制到模型的嵌入层权重(model.embedding.weight.data),覆盖随机初始化的值
model.embedding.weight.data.copy_(pretrained_embeddings)
# 这样网络训练的时候向量只需微调就行了
# 当然对于两个特殊字符,还是初始化为0
UNK_IDX = TEXT.vocab.stoi[TEXT.unk_token] # 获取 <unk> 的索引
model.embedding.weight.data[UNK_IDX] = torch.zeros(EMBEDDING_DIM) # 初始化为全 0
model.embedding.weight.data[PAD_IDX] = torch.zeros(EMBEDDING_DIM) # 初始化为全 0
然后就可以开始正式训练过程:
# 这是一个具有通用性的训练函数, 传入模型、迭代器、优化器、损失函数
def train(model, iterator, optimizer, criterion):
epoch_loss = 0 # 累计损失
epoch_acc = 0 # 累计准确率
model.train() # 设置为训练模式
for batch in iterator:
optimizer.zero_grad() # 清除上一批次的梯度,避免累积
predictions = model(batch.text).squeeze(1) # 正向传播 (模型输出 [batch_size, 1] → 压缩为 [batch_size])
loss = criterion(predictions, batch.label) # 计算损失
acc = binary_accuracy(predictions, batch.label) # 计算准确率
loss.backward() # 反向传播, 梯度计算
optimizer.step() # 更新参数
epoch_loss += loss.item() # 累加损失(.item()提取标量值)
epoch_acc += acc.item() # 累加准确率
return epoch_loss / len(iterator), epoch_acc / len(iterator) # 返回平均损失和准确率
# 评估函数 evaluate
def evaluate(model, iterator, criterion):
epoch_loss = 0
epoch_acc = 0
model.eval() # 评估模式
with torch.no_grad(): # 禁用梯度计算, 只评估, 不训练
for batch in iterator:
# 仅保留前向传播和统计量累计步骤,省略 zero_grad()、backward() 和 step()
predictions = model(batch.text).squeeze(1)
loss = criterion(predictions, batch.label)
acc = binary_accuracy(predictions, bath.label)
epoch_loss += loss.item()
epoch_acc += acc.item()
return epoch_loss / len(iterator), epoch_acc / len(iterator)
可以看到, 在上述函数中, 模型是可以更换的, 迭代器是提前定义好的, 优化器和损失函数时自己指定的, 所以这是一个通用性很强的训练函数, 之后也可以使用。
同时, binary_accuracy需要我们自己编写, 此外还可以写一个辅助函数:
def binary_accuracy(preds, y):
# 使用sigmoid函数将原始输出(logits)映射为0-1之间的概率值, 再四舍五入得到预测类别0或1
rounded_preds = torch.round(torch.sigmoid(preds))
# 计算正确预测数
correct = (rounded_preds == y).float()
# acc = 正确预测数除以总样本数
acc = correct.sum() / len(correct)
return acc
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
接下来开始正式训练:
# 初始化组件
optimizer = optim.Adam(model.parameters()) # 使用Adam优化器
criterion = nn.BCEWithLogitsLoss() # 二分类损失函数(结合了 Sigmoid 激活和二元交叉熵损失)
model = model.to(device) # 将模型移至GPU(如果可用)
criterion = criterion.to(device) # 损失函数也移至GPU
# 训练参数
N_EPOCHS = 10 # 训练轮数
best_valid_loss = float('inf') # 要求记录验证集上的最低损失,用于保存最佳模型
# 训练循环
for epoch in range(N_EPOCHS):
start_time = time.time() # 记录epoch开始时间
# 训练并评估
train_loss, train_acc = train(model, train_iterator, optimizer, criterion)
valid_loss, valid_acc = evaluate(model, valid_iterator, criterion)
# 计算耗时
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
# 保存最佳模型
if valid_loss < best_valid_loss:
best_valid_loss = valid_loss
torch.save(model.state_dict(), 'wordavg-model.pt')
# 打印日志
print(f'迭代轮次: {epoch+1:02} | 迭代一轮时间: {epoch_mins}m {epoch_secs}s')
print(f'\t训练损失: {train_loss:.3f} | 训练准确率: {train_acc*100:.2f}%')
print(f'\t 验证损失: {valid_loss:.3f} | 验证准确率: {valid_acc*100:.2f}%')
九.RNN模型
我们也可以换一些相对先进的模型, 比如说RNN:
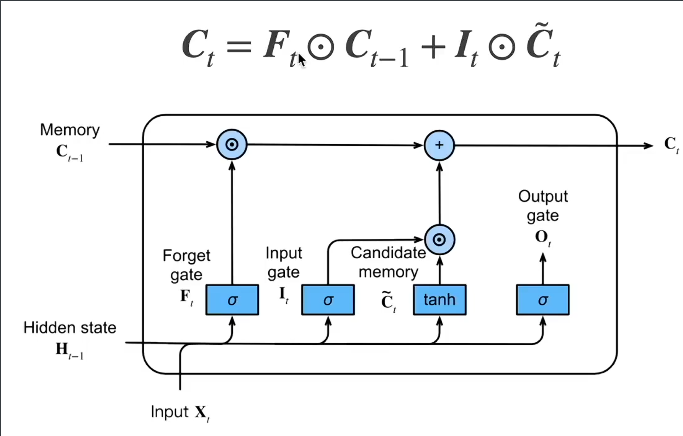
LSTM(长短期记忆网络)
核心思想:LSTM 是 RNN 的改进版,通过引入门控机制(遗忘门、输入门、输出门)和细胞状态(cell state),解决 RNN 的长期依赖问题
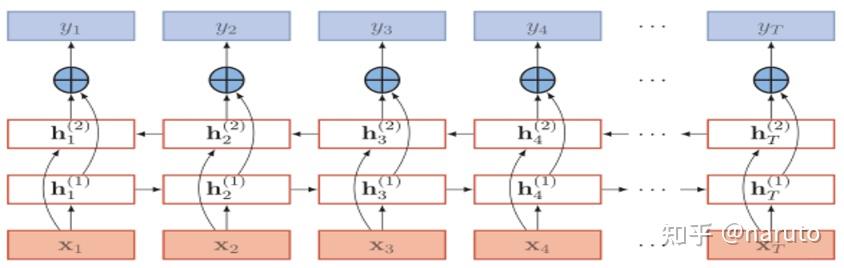
如果仔细查看一个记忆单元的话:

细胞状态(Ct):
- 贯穿整个时间步的“记忆通道”,保留长期信息。
- 通过门控机制选择性更新或遗忘信息。
三个门控
(均通过 Sigmoid 函数输出 0~1 的权重):
- 遗忘门(Forget Gate):决定丢弃哪些历史信息。
- 输入门(Input Gate):决定新增哪些信息到细胞状态。
- 输出门(Output Gate):决定当前隐藏状态的输出。
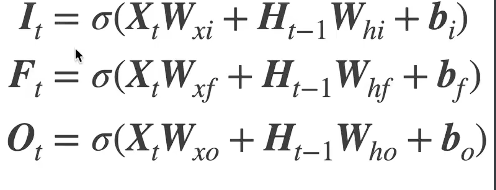
状态更新公式:
候选细胞状态Ct~:
Ct~ 是当前时间步通过输入数据 xt 和前一时刻隐藏状态 ht−1 生成的临时记忆,表示模型可能新增到细胞状态中的新信息
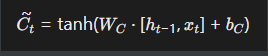
细胞状态Ct:
Ct是 LSTM 的核心记忆单元,承载了从初始时刻到当前时刻的长期信息,通过门控机制选择性更新
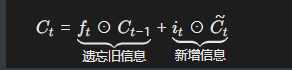
> 1. **信息流**: > - *C**t*~ 是当前输入和隐藏状态生成的**原始信息** > - *Ct* 是经过门控(遗忘门 + 输入门)筛选后的**最终记忆**,结合了历史信息(*Ct*−1)和当前候选信息(*C**t*~) > 2. **类比理解**: > - *C*~*t* 像“草稿”,*Ct* 像“正式文档” > - 输入门 *it* 是“编辑”,决定草稿中哪些内容写入正式文档;遗忘门 *ft* 是“删减”,决定旧文档中哪些内容需要删除
上面小小复习了一下LSTM的内容, 现在看看代码:
class RNN(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers, bidirectional, dropout, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx) # embedding层
self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=n_layers, bidirectional=bidirectional, dropout=dropout) # rnn层
self.fc = nn.Linear(hidden_dim*2, output_dim) # 全连接层
self.dropout = nn.Dropout(dropout) # dropout
def forward(self, text):
# 输入的text 是一个批量的句子,每个句子是单词索引序列 (输入[sent_len, batch_size])
embedded = self.dropout(self.embedding(text)) # 输出[sent len, batch size, emb dim]
output, (hidden, cell) = self.rnn(embedded) # 输入[sent len, batch size, emb dim]
# 输出 output: [sent_len, batch_size, hid_dim * 2]
# 输出 hidden: [2, batch_size, hid_dim]
# 输出 cell = [num layers * num directions, batch size, hid dim]
# 如果是双向 LSTM(bidirectional=True),hidden 包含前向和反向的最终隐藏状态
#输入hidden[-2,:,:], hidden[-1,:,:]; 输出[batch_size, hid_dim * 2]
hidden = self.dropout(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim=1))
#输入[batch_size, hid_dim * 2] 输出[batch_size, output_dim]
return self.fc(hidden.squeeze(0))
self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=n_layers, bidirectional=bidirectional, dropout=dropout) # rnn层
- 设置输入词向量的维度embedding_dim
- 设置隐藏层的维度hidden_dim
num_layers=n_layers:堆叠多层 LSTMbidirectional=bidirectional:设置是否使用双向 LSTM(BiLSTM)dropout=dropout:在 LSTM 层之间应用 Dropout(防止过拟合)
forward思路:
我们的输入一批句子,大小是[seq_len, batch_size]
-
第一步依然是经过一个embedding层得到每个单词的embedding向量,此时, 维度是[seq_len, batch_size, embed_dim]
-
第二步经过一个双向的LSTM,并且是2层堆叠起来的,这时候的网络输出会是一个[seq_len, batch_size, hidden_size**num_directions]*
-
LSTM的隐藏状态h和c是[num_layers*num_directions,batch_size, hidden_size], 所以这时候我们需要拿到最后一层最后一个时间步LSTM的隐藏层状态,把它两进行一个拼接,然后再通过全连接层得到结果。
-
双向LSTM的正向和反向隐藏状态捕获了序列的不同信息:
- 正向:从过去到当前时间步的信息。
- 反向:从未来到当前时间步的信息。
拼接可以结合这两个方向的信息,提供更全面的上下文表示
一个便于理解的小例子:
seq_len = 10(序列长度)。batch_size = 32。embed_dim = 100。hidden_size = 256。num_layers = 2。num_directions = 2(双向)。
- Embedding层:
- 输入:
[10, 32](假设是单词索引)。- 输出:
[10, 32, 100]。
- 双向LSTM:
- 第一层:
- 正向LSTM:输入
[10, 32, 100],输出[10, 32, 256]。- 反向LSTM:输入
[10, 32, 100],输出[10, 32, 256]。- 合并:
[10, 32, 512](因为双向,256 * 2)。- 第二层:
- 正向LSTM:输入
[10, 32, 512],输出[10, 32, 256]。- 反向LSTM:输入
[10, 32, 512],输出[10, 32, 256]。- 合并:
[10, 32, 512]。- 最终输出:
[10, 32, 512]。- 隐藏状态
h和c:
- 第一层正向:
h[0],c[0],[32, 256]。- 第一层反向:
h[1],c[1],[32, 256]。- 第二层正向:
h[2],c[2],[32, 256]。- 第二层反向:
h[3],c[3],[32, 256]。- 所以
h和c的形状是[4, 32, 256]。
- 获取最后一层的隐藏状态:
- 最后一层的正向:
h[2],[32, 256]。- 最后一层的反向:
h[3],[32, 256]。- 拼接:
[32, 512]。
- 全连接层:
- 输入:
[32, 512]。- 输出:取决于任务(例如分类任务可能是
[32, num_classes])。
十.CNN模型
我学习的这篇帖子发现CNN训练起来也有不错的效果, 这里我就不详细介绍, 只是展示一下
class CNN(nn.Module):
def __init__(self, vocab_size, embedding_size, num_filters, filter_size, out_size, dropout, pad_idx):
super(CNN, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_size, padding_idx=pad_idx)
self.conv = nn.Conv2d(in_channels=1, out_channels=num_filters, kernel_size=(filter_size, embedding_size))
self.linear = nn.Linear(num_filters, out_size)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
text = text.permute(1, 0) #[batch_size, seq_len]
embedded = self.embedding(text) #[batch_size, seq_len, emb_dim]
embedded = embedded.unsqueeze(1)#[batch_size, 1, seq_len, emb_dim]
conved = F.relu(self.conv(embedded)) #[batch_size, num_filters, seq_len-filter_size+1]
conved = conved.squeeze(3)
pooled = F.max_pool1d(conved, conved.shape[2])#把第二个维度压扁,[batch_size, numf, 1]
pooled = pooled.squeeze(2) #[batch_size, num_filters]
pooled = self.dropout(pooled) #[batch_size, num_filters]
return self.linear(pooled)
class CNN_Model(nn.Module):
def __init__(self, vocab_size, embedding_dim, n_filters, filter_sizes, output_dim, dropout, pad_idx):
super(CNN_Model, self).__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx=pad_idx)
self.convs = nn.ModueList([
nn.Conv2d(in_channels=1, out_channels=n_filters, kernel_size=(fs, embedding_dim))
for fs in filter_sizes
])
self.fc = nn.Linear(len(filter_sizes) * n_filters, output_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, text):
text = text.permute(1, 0) #[batch_size, seq_len]
embedded = self.embedding(text)#[batch_size, seq_len, embed_dim]
embedded = embedded.unsqueeze(1) #[batch_size, 1, seq_len, embed_dim]
conved = [F.relu(conv(embedded)).squeeze(3) for conv in self.convs]
#conv_n:[batch_size, num_filters, seq_len-filter[n]+1]
pooled = [F.max_pool1d(conv, conv.shape[2]).squeeze(2) for conv in conved]
#pooled_n:[batch_size, n_filters]
cat = self.dropout(torch.cat(pooled, dim=1)) #[batch_size, n_filters*len(filter_size)]
return self.fc(cat)
十一.实践
学习了这些代码, 我想自己实践一下, 我这里目前是两种实践方案: 首先我想上kaggle找一些相关的题目试一试排名;然后我在上github找一些相关的项目尝试复现一下, 以后也会在这个文档中逐步更新。
END.来源
本文档是对情感分析的初步学习, 学习了pytorch入门+实战系列五:pytorch情感分类 - 知乎.
posted on 2025-05-20 13:15 Fg0_MURAMASA 阅读(62) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号