【动手学深度学习】学习笔记
 【动手学深度学习】李沐——所有章节的学习记录,包括代码的解释及个人见解。
【动手学深度学习】李沐——所有章节的学习记录,包括代码的解释及个人见解。
线性神经网络
图像分类数据集
import torch
import torchvision
from matplotlib import pyplot as plt
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l
# 在数字标签索引以及文本名称之间转换
def get_fashion_mnist_labels(labels): #@save
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankel boot']
return [text_labels[int(i)] for i in labels] # 将索引与标签一一对应
# 可视化样本
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5): #@save
figsize = (num_cols * scale, num_rows * scale)
_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten() # 展开,方便索引
for i, (ax, img) in enumerate(zip(axes, imgs)):
if torch.is_tensor(img):
ax.imshow(img.numpy())
else:
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False) # 隐藏坐标轴
ax.axes.get_yaxis().set_visible(False)
if titles:
ax.set_title(titles[i])
return axes
"""
d2l.use_svg_display() # 使用svg显示图片,清晰度更高
# 读取数据集
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(root="dataset/FashionMNIST",
train=True, transform=trans,
download=True)
mnist_test = torchvision.datasets.FashionMNIST(root="dataset/FashionMNIST",
train=False, transform=trans,
download=True)
X, y = next(iter(data.DataLoader(mnist_train, batch_size=18)))
show_images(X.reshape(18, 28, 28), 2, 9, titles=get_fashion_mnist_labels(y))
plt.show()
"""
def get_dataloader_workers(): #@save
return 4 # 使用4个进程来读取数据
# 定义函数用于获取和读取该数据集,返回训练集和验证集的迭代器
def load_data_fashion_mnist(batch_size, resize = None): #@save
trans = [transforms.ToTensor()]
if resize: # 如果需要更改尺寸
trans.insert(0,transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(root="dataset/FashionMNIST",
train=True, transform=trans,
download=False)
mnist_test = torchvision.datasets.FashionMNIST(root="dataset/FashionMNIST",
train=False, transform=trans,
download=False)
return (data.DataLoader(mnist_train,batch_size,shuffle=True,
num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test, batch_size, shuffle=True,
num_workers=get_dataloader_workers()))
softmax回归的从零开始实现
import torch
from IPython import display
from d2l import torch as d2l
from matplotlib import pyplot as plt
btach_size = 256
# 调用之间的函数获取两个迭代器
train_iter,test_iter = d2l.load_data_fashion_mnist(batch_size=btach_size)
num_inputs = 784 # 将每个28和28的图片展开成就是784,输入大小
num_outputs = 10 # 输入要预测十个类别
# 使用正态分布来初始化权重,第三个参数是为了待会要计算梯度
W = torch.normal(0,0.01, size=(num_inputs,num_outputs),requires_grad=True)
b = torch.zeros(num_outputs,requires_grad=True)
def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(1,keepdim = True) # 求和仍然保持维度不变
return X_exp / partition
# 定义模型
def net(X):
return softmax(torch.matmul(X.reshape((-1,W.shape[0])),W)+b)
# 定义损失函数
def cross_entropy(y_hat,y):
return -torch.log(y_hat[range(len(y_hat)),y])
# 计算分类精度
def accuracy(y_hat,y): #@save
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis = 1) # 取出预测概率最大的下标
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
# 定义一个用来计算变量累加的类
class Accumulator: #@save
def __init__(self,n):
self.data = [0.0] * n
def add(self,*args): # 不限制输入数目
self.data = [ a + float(b) for a,b in zip(self.data,args)]
def reset(self):
self.data = [0.0] * len(self.data) # 重置为0
def __getitem__(self, idx):
return self.data[idx]
# 评估在模型上的精度
def evaluate_accuracy(net,data_iter): #@save
if isinstance(net,torch.nn.Module): # 如果是当前已有的模块
net.eval() # 转为评估模式,常在计算测试集精度时使用,该模式下不可以计算梯度
metric = Accumulator(2)
with torch.no_grad(): # 不计算精度
for X,y in data_iter:
metric.add(accuracy(net(X),y),y.numel()) # 第二个参数是统计tensor的个数
return metric[0] / metric[1]
# 训练
def train_epoch_ch3(net,train_iter,loss,updater): #@save
# 将模型设置为训练模式
if isinstance(net,torch.nn.Module):
net.train()
# 训练损失总和,训练精确度总和,样本数
metric = Accumulator(3)
for X,y in train_iter:
y_hat = net(X) # 计算网络的输出
l = loss(y_hat,y)
if isinstance(updater,torch.optim.Optimizer):
# 使用内置的优化器和损失函数
updater.zero_grad()
l.mean().backward()
updater.step()
else:
# 使用定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()),accuracy(y_hat,y),y.numel())
return metric[0]/metric[2],metric[1]/metric[2] # 返回训练损失和训练准确度
class Animator: #@save
def __init__(self,xlabel=None, ylabel = None, legend=None, xlim = None,ylim=None,xscale='linear',
yscale='linear',fmts=('-','m--','g-','r:'),nrows=1,ncols=1, figsize=(3.5,2.5)):
# 增量地绘制多条线
if legend is None:
legend=[]
d2l.use_svg_display()
self.fig,self.axes = d2l.plt.subplots(nrows,ncols,figsize=figsize) # 创建绘图窗口
if nrows * ncols == 1:
self.axes = [self.axes,]
# 使用lambda函数捕获参数
self.config_axes = lambda : d2l.set_axes(self.axes[0],xlabel,ylabel,xlim,ylim,xscale,yscale,legend)
self.X,self.Y,self.fmts = None,None,fmts
def add(self,x,y):
# 向图表中添加多个数据点
if not hasattr(y,"__len__"): # 判断实例对象y是否包含某个属性或方法
y = [y]
n = len(y)
if not hasattr(x,"__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i,(a,b) in enumerate(zip(x,y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x,y,fmt in zip(self.X,self.Y,self.fmts):
self.axes[0].plot(x,y,fmt)
self.config_axes()
display.display(self.fig)
display.clear_output(wait=True)
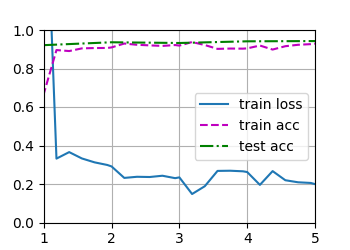
# 实现一个训练函数,它会在训练数据集上训练模型,并每轮会在测试集上计算误差
def train_ch3(net,train_iter, test_iter, loss, num_epochs, updater): #@sace
animator = Animator(xlabel='epoch',xlim=[1,num_epochs],ylim = [0.3,0.9],
legend=['train loss','train acc','test acc'])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net,train_iter,loss,updater) # 每一轮的已写过,返回误差和精度
test_acc = evaluate_accuracy(net, test_iter) # 计算在测试集上的精度
animator.add(epoch+1, train_metrics+(test_acc,))
train_loss, train_acc = train_metrics # 遍历了单次数据集当前的误差和精度
assert train_loss < 0.5, train_loss # 如果不小于0.5就发生异常
assert train_acc <=1 and train_acc > 0.7, train_acc
assert test_acc <=1 and test_acc > 0.7, test_acc
lr = 0.1
def updater(batch_size):
return d2l.sgd([W,b],lr,batch_size)
num_epochs = 10
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater) # 训练模型
plt.show() # 在pycharm中最终使用这一句才会显示出图像
# 预测测试集
def predict_ch3(net,test_iter, n=6): #@save
for X,y in test_iter:
break # 这里只为了展示因此只取出第一份
trues = d2l.get_fashion_mnist_labels(y)
preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))
titles = [true + '\n' + pred for true,pred in zip(trues,preds)] # 训练取出真实和预测标签
d2l.show_images(X[0:n].reshape((n,28,28)),1,n,titles = titles[0:n])
plt.show()
predict_ch3(net,test_iter)
softmax回归的简洁实现
import torch
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 初始化模型参数
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
def init_weight(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01) # 给tensor初始化,一般是给网络中参数weight初始化,初始化参数值符合正态分布
net.apply(init_weight) # 将初始化权重的操作应用于该父模块和各个子模块
loss = nn.CrossEntropyLoss(reduction='none') # 不对输出执行均值或者求和的操作
optimer = torch.optim.SGD(net.parameters(),lr = 0.01)
num_epoch = 10
d2l.train_ch3(net,train_iter,test_iter, loss, num_epoch, optimer)
多层感知机
多层感知机的从零开始实现
import torch
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
# 初始化模型参数
num_inputs, num_outputs, num_hiddens = 784, 10, 256
W1 = nn.Parameter(torch.randn(num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
W2 = nn.Parameter(torch.randn(num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]
def relu(X):
a = torch.zeros_like(X)
return torch.max(X, a)
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X @ W1 + b1) # @代表矩阵乘法的简写
return H @ W2 + b2
loss = nn.CrossEntropyLoss(reduction='none')
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr)
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)
plt.show()
d2l.predict_ch3(net,test_iter)
plt.show()
多层感知机的简洁实现
import torch
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(nn.Flatten(), nn.Linear(784, 256), nn.ReLU(), nn.Linear(256, 10))
def init_weights(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
batch_size, lr, num_epochs = 256, 0.01, 10
loss = nn.CrossEntropyLoss(reduction='none')
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
optimer = torch.optim.SGD(net.parameters(), lr=lr)
d2l.train_ch3(net, train_iter,test_iter, loss, num_epochs, optimer)
plt.show()
权重衰减
简洁实现
net = nn.Sequential(nn.Linear(num_inputs, 1))
for param in net.parameters():
param.data.normal_()
optimer = torch.optim.SGD([ {"params":net[0].weight,'weight_decay':wd},
{"params":net[0].bias}],lr=lr)
上面设置“weight_decay”为wd就是设置其使用权重衰减。
Dropout
一个好的模型需要对输入数据的扰动鲁棒,也就是不能够受噪声的影响。那么如果使用带有噪声的数据来学习的话,如果能够使得其不学习到噪声的那部分内容,那么也相当于是正则化。因此丢弃法(Dropout)就是在层之间加入噪音。
那么从定义方向出发,它就是无偏差的加入噪音,即对原本输入\(\pmb{x}\)加入噪音得到\(\pmb{x}^{\prime}\),希望其均值不变,即:
那么丢弃法具体的做法是对每个元素执行如下扰动:
那么这样可以保证期望不变:
那么这个丢弃概率就是控制模型复杂度的超参数
具体是通常将丢弃法作用在多层感知机的隐藏层的输出上,即:
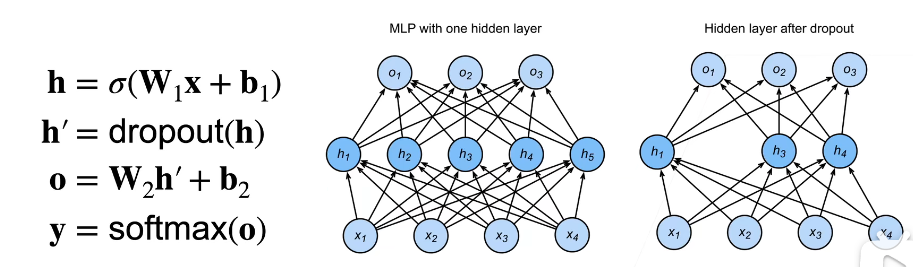
这是在训练过程中使用,它将会影响模型参数的更新,而在测试的时候并不会进行dorpout操作,这样能够保证确定性的输出。从实验上来说,它和正则化能够达到类似的效果。
那么Dropout放在隐藏层的输出,会将那些被置为0的神经元的权重在本次不进行更新,那么就可以认为是每一次Dropout都是从所有的隐藏层神经元中挑选出一部分来进行更新。
具体的实现直接调用nn.Dropout()层即可。
数值稳定性
在计算梯度时:

因为向量对向量的求导是矩阵,因此这么多次矩阵的运算可能会遇见梯度爆炸或者梯度消失的问题。
假设矩阵中的梯度大部分都是比1大一点的数,那么经过这么多次梯度计算就可能出现梯度过大而爆炸;那么梯度如果稍微小于1也就会经过这么多次迭代之后接近于0。

那么梯度爆炸就会带来如下的问题:
- 值超过了数值类型可以表示的范围
- 对学习率更加敏感
- 当学习率比较大,乘上较大的梯度就更新程度比较大,难以稳定
- 当学习率太小,那么可能导致在除开梯度爆炸的那些权重外的正常权重无法正常更新
而对于梯度消失,例如采用sigmoid函数:
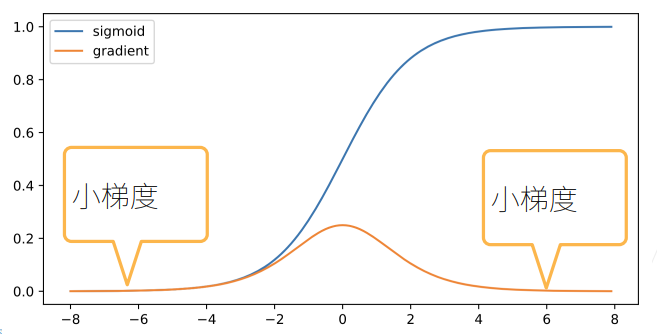
这么小的梯度在多个叠加之后就可能会出现梯度消失的问题。它的主要问题是:
- 也是超过表示范围,直接就使大部分梯度值为0,无法更新
- 训练因为梯度值为0,无法正常更新
- 对于底部层尤为严重,因为梯度是从输出层反向传播计算得到的,越到底部层,叠加的层数越多,梯度越可能消失,那就使得只有顶部层能够正常训练更新
那么如何使训练更加稳定的首要目标,就是让梯度值在合理的范围内,例如在某些算法中它们将梯度的乘法转换成加法,或者是对梯度进行归一化、裁剪等。但还有一种重要的方法就是合理的进行权重初始化,以及选择适合的激活函数。
具体来说,结论就是在对权重进行初始化的时候,让权重是从一个均值为0,方差为\(\gamma_t=\frac{2}{n_{t-1}+n_t}\)中采样得到的。其中\(n_{t-1}、n_{t}\)代表该权重所连接的两个层的神经元的数目。因此需要根据层的形状来选择权重所服从分布的方差。
而激活函数经过推导,可以认为tanh(x)和ReLU(x)这两个激活函数能够具有较好的特性,而sigmoid(x)需要调整为\(4\times sigmoid(x)-2\)才能够达到与前两个相同的效果。
环境和分布偏移
1、分布偏移的类型
主要有以下几种偏移类型:
- 协变量偏移:指的是数据的分布\(p(x)\)发生了变化,例如在训练的时候用到的训练数据集分布\(p_1(x)\)和测试的时候用到的测试集分布\(p_2(x)\)不同,那么这就很难使得模型在测试数据集上表现好。不过这种变化还有一个架设计就是虽然输入的分布可能随时间发生变化,但是标签函数(即条件分布\(P(y\mid x)\))不会改变。例如在训练的时候我们用真实的猫和狗来让机器学会分类,但是在测试的时候我们用的是卡通的猫和狗,这就是训练和测试两部分的数据集不相同,但是它们的标签函数是相同的,可以正确地对猫和狗进行标注。
- 标签偏移:指的是和协变量偏移相反的问题,因为这里假设标签边缘概率\(P(y)\)可以改变,但是类别条件分布\(P(x\mid y)\)在不同的领域之间保持不变。这里可以举一个例子就是预测患者的疾病,症状就是x,而所患的疾病就是标签y,那么疾病的相对流行率,或者说各种疾病之间的比例可能发生变化(即\(P(y)\))可能发生变化,而对于某种特定疾病所对应的症状(\(P(x\mid y))\)不会发生变化。
- 概念偏移:指的是标签的定义出现了变化。举个例子就是我们对于美貌的定义,可能会随着时间的变化而发生变化,那么这个“美貌”的标签的概念就发生了变化。
2、分布偏移纠正
首先需要了解什么是经验风险与实际风险:在训练时我们通常是最小化损失函数(不考虑正则化项),即:
这一项在训练数据集上的损失称为经验风险。那么经验风险就是为了来近似真实风险的,也就是数据的真实分布下的损失。然而在实际中我们无法获得真实数据的分布。因此一般认为最小化经验风险可以近似于最小化真实风险。
协变量偏移纠正
对于目前已有的数据集(x,y),我们要评估\(P(y\mid x)\),但是当前的数据\(x_i\)是来源于某些源分布\(q(x)\)(可以认为是训练数据集的分布),而不是来源于目标分布\(p(x)\)(可以认为是真实数据的分布,或者认为是测试数据的分布)。但存在协变量偏移的假设即\(p(y\mid x)=q(y\mid x)\)。因此:
因此当前我们需要计算数据来自于目标分布和来自于源分布之间的比例,来重新衡量每个样本的权重,即:
那么将该权重代入到每个数据样本中,就可以使用加权经验风险最小化来训练模型:
因此接下来的问题就是估计\(\beta\)。具体的方法为:从两个分布中抽取样本来进行分布估计。即对于目标分布\(p(x)\)我们就可以通过访问测试数据集来获取;而对于源分布\(q(x)\)则直接通过训练数据集获取。这里需要考虑到访问测试数据集是否会导致数据泄露的问题,其实是不会的,因为我们只访问了特征\(x \sim p(x)\),并没有访问其标签y。在这种方法下,有一种非常有效的办法来计算\(\beta\):对数几率回归。
我们假设从两个分布中抽取相同数据的样本,对于p抽取的样本数据标签为z=1,对于q抽取的样本数据标签为z=-1。因此该混合数据集的概率为:
因此如果我们使用对数几率回归的方法,即\(P(z=1\mid x)=\frac{1}{1+exp(-h(x))}\)(h是一个参数化函数,设定的),那么就有:
因此只要训练得到\(h(x)\)即可。
但上述算法依赖一个重要的假设:需要目标分布(测试集分布)中的每个数据样本在训练时出现的概率非零,否则将会出现\(p(x_i)>0,q(x_i)=0\)的情况。
标签偏移纠正
同样,这里假设标签的分布随时间变化\(q(y)\neq p(y)\),但类别条件分布保持不变\(q(x\mid y)=p(x\mid y)\)。那么:
因此重要性权重将对应于标签似然比率:
因为,为了顾及目标标签的分布,我们首先采用性能相当好的现成的分类器(通常基于训练数据训练得到),并使用验证集计算混淆矩阵。那么混淆矩阵是一个\(k\times k\)的矩阵(k为分类类别数目)。每个单元格的值\(c_{ij}\)是验证集中真实标签为j,而模型预测为i的样本数量所占的比例。
但是现在我们无法计算目标数据上的混淆矩阵,因为我们不知道真实分布。那么我们所能做的就是**将现有的模型在测试时的预测取平均数,得到平均模型输出\(\mu (\hat{y})\in R^k\),其中第i个元素为我们的模型预测测试集中第i个类别的总预测分数。
那么具体来说,如果我们的分类器一开始就相当准确,并且目标数据只包含我们以前见过的类别(训练集和测试集的拥有的类别是相同的),那么如果标签偏移假设成立,就可以通过一个简单的线性系统来估计测试集的标签分布:
因此若C可逆,则可得:
概念偏移纠正
这个很难用什么确切的方法来纠正。不过这种变化通常是很罕见的,或者是特别缓慢的。我们能够做的一般是训练时要适应网络的变化,使用新的数据来更新网络。
实战kaggle比赛:预测房价
import numpy as np
import pandas as pd
import torch
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
import hashlib
import os
import tarfile
import zipfile
import requests
DATA_HUB = dict()
DATA_URL = 'http://d2l-data.s3-accelerate.amazonaws.com/'
def download(name, cache_dir=os.path.join("dataset", "data_kaggle")): # @save
assert name in DATA_HUB, f"{name} 不存在于 {DATA_HUB}"
url, shal_hash = DATA_HUB[name]
os.makedirs(cache_dir, exist_ok=True) # 按照第一个参数创建目录,第二参数代表如果目录已存在就不发出异常
fname = os.path.join(cache_dir, url.split('/')[-1])
if os.path.exists(fname): # 如果已存在这个数据集
shal = hashlib.sha1()
with open(fname, 'rb') as f:
while True:
data = f.read(1048576) # 这里进行数据集的读取,一次能够读取的最大行数为1048576
if not data: # 如果读取到某一次不成功
break
shal.update(data)
if shal.hexdigest() == shal_hash:
return fname # 命中缓存
print(f'正在从{url}下载{fname}...')
r = requests.get(url, stream=True, verify=True)
# 向链接发送请求,第二个参数是不立即下载,当数据迭代器访问的时候再去下载那部分,不然全部载入会爆内存,第三个参数为不验证证书
with open(fname, 'wb') as f:
f.write(r.content)
return fname
# 下载并解压一个zip或tar文件
def download_extract(name, folder=None): # @save
fname = download(name)
base_dir = os.path.dirname(fname) # 获取文件的路径,fname是一个相对路径,那么就返回从当前文件到目标文件的路径
data_dir, ext = os.path.splitext(fname) # 将这个路径最后的文件名分割,返回路径+文件名,和一个文件的扩展名
if ext == '.zip': # 如果为zip文件
fp = zipfile.ZipFile(fname, 'r')
elif ext in ('.tar', '.gz'):
fp = tarfile.open(fname, 'r')
else:
assert False, "只有zip/tar文件才可以被解压缩"
fp.extractall(base_dir) # 解压压缩包内的所有文件到base_dir
return os.path.join(base_dir, folder) if folder else data_dir
def download_all(): # @save
for name in DATA_HUB:
download(name)
# 下载并缓存房屋数据集
DATA_HUB['kaggle_house_train'] = ( # @save
DATA_URL + 'kaggle_house_pred_train.csv',
'585e9cc93e70b39160e7921475f9bcd7d31219ce'
)
DATA_HUB['kaggle_house_test'] = ( # @save
DATA_URL + 'kaggle_house_pred_test.csv',
'fa19780a7b011d9b009e8bff8e99922a8ee2eb90'
)
train_data = pd.read_csv(download('kaggle_house_train'))
test_data = pd.read_csv(download('kaggle_house_test'))
# print(train_data.shape)
# print(test_data.shape)
# print(train_data.iloc[0:4,[0,1,2,3,-3,-2,-1]])
# 将序号列去掉,训练数据也不包含最后一列的价格列,然后将训练数据集和测试数据集纵向连接在一起
all_features = pd.concat((train_data.iloc[:, 1:-1], test_data.iloc[:, 1:]))
# 将数值型的数据统一减去均值和方差
numeric_features = all_features.dtypes[all_features.dtypes != 'object'].index # 在panda中object类型代表字符串
all_features[numeric_features] = all_features[numeric_features].apply(
lambda x: (x - x.mean()) / (x.std()) # 应用匿名函数
)
# 在标准化数据后,所有均值消失,因此我们可以设置缺失值为0
all_features[numeric_features] = all_features[numeric_features].fillna(0)
# 对离散值进行处理
all_features = pd.get_dummies(all_features, dummy_na=True) # 第二个参数代表是否对nan类型进行编码
# print(all_features.shape)
n_train = train_data.shape[0] # 训练数据集的个数
train_features = torch.tensor(all_features[:n_train].values, dtype=torch.float32) # 取出训练数据
test_features = torch.tensor(all_features[n_train:].values, dtype=torch.float32) # 取出测试数据
train_labels = torch.tensor(train_data.SalePrice.values.reshape(-1, 1), dtype=torch.float32) # 取出训练数据的价格列
loss = nn.MSELoss()
in_features = train_features.shape[1] # 特征的个数
# 网络架构
def get_net():
net = nn.Sequential(nn.Linear(in_features, 1))
return net
# 取对数约束输出的数量级
def log_rmes(net, features, labels):
clipped_preds = torch.clamp(net(features), 1, float('inf'))
# 第一个为要约束的参数,第二个为最小值,第三个为最大值,小于最小值就为1
rmse = torch.sqrt(loss(torch.log(clipped_preds), torch.log(labels)))
return rmse.item()
# 训练的函数
def train(net, train_features, train_labels, test_features, test_labels, num_epochs, learning_rate,
weight_decay, batch_size):
train_ls, test_ls = [], []
train_iter = d2l.load_array((train_features, train_labels), batch_size) # 获取数据迭代器
optimizer = torch.optim.Adam(net.parameters(), lr=learning_rate, weight_decay=weight_decay)
# 这是另外一个优化器,它对lr的数值不太敏感,第三个参数代表是否使用正则化
for epoch in range(num_epochs):
for X, y in train_iter:
optimizer.zero_grad() # 梯度先清零
l = loss(net(X), y) # 计算损失
l.backward() # 反向传播计算梯度
optimizer.step() # 更新参数
train_ls.append(log_rmes(net, train_features, train_labels))
if test_labels is not None:
test_ls.append(log_rmes(net, test_features, test_labels))
return train_ls, test_ls
# K折交叉验证
def get_k_fold_data(k, i, X, y):
assert k > 1
fold_size = X.shape[0] // k
X_train, y_train = None, None
for j in range(k):
idx = slice(j * fold_size, (j + 1) * fold_size) # 创建一个切片对象
X_part, y_part = X[idx, :], y[idx] # 将切片对象应用于索引
if j == i: # 取出第i份作为验证集
X_valid, y_valid = X_part, y_part
elif X_train is None: # 如果当前训练集没有数据就初始化
X_train, y_train = X_part, y_part
else:
X_train = torch.cat([X_train, X_part], 0) # 如果是训练集那么就进行合并
y_train = torch.cat([y_train, y_part], 0)
return X_train, y_train, X_valid, y_valid
# k次的k折交叉验证
def k_fold(k, X_train, y_train, num_epochs, learning_rate, weight_decay, batch_size):
train_l_sum, valid_l_sum = 0, 0
for i in range(k):
data = get_k_fold_data(k, i, X_train, y_train)
net = get_net()
train_ls, valid_ls = train(net, *data, num_epochs, learning_rate, weight_decay, batch_size)
train_l_sum += train_ls[-1]
valid_l_sum += valid_ls[-1]
if i == 0:
d2l.plot(list(range(1, num_epochs + 1)), [train_ls, valid_ls], xlabel="epoch",
ylabel='ylabel', xlim=[1, num_epochs], legend=["train", 'valid'], yscale='log')
print(f"折{i + 1},训练log rmse{float(train_ls[-1]):f},"
f"验证log rmse{float(valid_ls[-1]):f}")
return train_l_sum / k, valid_l_sum / k
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
train_l,valid_l = k_fold(k,train_features, train_labels, num_epochs, lr, weight_decay, batch_size)
print(f"{k}折验证:平均训练log rmse:{float(train_l):f}",
f"平均验证log rmse:{float(valid_l):f}")
plt.show()
下面为我自己调试的结果:
def get_net():
net = nn.Sequential(nn.Linear(in_features, 256),
nn.ReLU(),
nn.Linear(256,1))
return net
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 5, 0, 64
5折验证:平均训练log rmse:0.045112 平均验证log rmse:0.157140
我总感觉256直接到1不太好,因此调整了模型的结构:
def get_net():
net = nn.Sequential(nn.Linear(in_features, 128),
nn.ReLU(),
nn.Linear(128,1))
return net
k, num_epochs, lr, weight_decay, batch_size = 5, 100, 0.03, 1, 64
5折验证:平均训练log rmse:0.109637 平均验证log rmse:0.136201
更复杂的模型总感觉没办法再降低误差了。
深度学习计算
层与块
自定义Sequential模块:
class MySequential(nn.Module):
def __init__(self, *args):
super().__init__()
for idx, module in enumerate(args):
self._modules[str(idx)] = module
# _modules是一个用来存放模块的地方,它的好处是方便访问,类似于一个字典
def forward(self,X):
for block in self._modules.values():
X = block(X)
return X
如果想要某些参数不更新,那么可以设置requires_grad=False,即
self.rand_weight = torch.rand((20,20),requires_grad=False)
小结:
一个块可以由许多层组成,一个块也可以由许多块组成
块内可以包含我们自定义的代码
块负责大量的内部处理,包括参数初始化和反向传播
层与块的顺序连接由Sequential块处理
参数管理
参数访问有很多种方式,如下:
net = nn.Sequential(nn.Linear(4,8),nn.ReLU(), nn.Linear(8,1))
net[2].state_dict() # 访问索引为2的模型(第二个Linear)的状态字典,其中就包含权重和偏置的参数
net[2].bias
net[2].bias.data # 取出值
参数初始化:
def init_normal(m):
if type(m) == nn.Linear:
nn.init.normal_(m.weight, mean=0, std=0.01) # 调用正态分布初始化,当然也有很多其他分布方法
nn.init.zeros_(m.bias) # 初始化为0
net.apply(m) # 为nn内部的linear全部初始化参数
参数绑定:
shared = nn.Linear(8,8)
net = nn.Sequential(nn.Linear(4,8),nn.ReLU(), shared, nn.ReLU(), shard, nn.ReLU())
这样两个shared层之间的参数就一直保持相同,共享参数。需要是同一个实例化对象才会共享参数的。
自定义层
自定义层和自定义网络很类似:
class MyLinear(nn.Module): # 要集成这个负类
def __init__(self, in_units, units):
super().__init__() # 同样初始化
self.weight = nn.Parameter(torch.randn(in_units, units)) # 定义参数时要用这个函数
self.bias = nn.Parameter(torch.randn(units,))
def forward(self,X):
linear = torch.matmul(X, self.weight.data)+self.bias.data
return F.relu(linear)
那么就跟其他层一样可以正常使用了。
读写文件
对于数据的存储可采用如下方式:
torch.save(x,"文件名")
y = torch.load("文件名")
也可以多个x,y进行存储。
而对于模型的存储:
class MLP(nn.Module):
---------这里省略了定义
net = MLP()
torch.save(net.state_dict(), "文件名") # 将参数存储起来
clone = MLP() # 必须先实例化一个对象才可以来接收存储的参数
clone.load_state_dict(torch.load("文件名"))
GPU
import torch
from torch import nn
print(torch.cuda.device_count()) # 查询可用的GPU数量
def try_gpu(i=0): # @save
if torch.cuda.device_count() >= i + 1:
return torch.device(f'cuda:{i}') # 返回目标的那个gpu
return torch.device('cpu') # 如果不满足则返回cpu
def try_all_gpus(): # @save
devices = [torch.device(f'cuda:{i}') for i in range(torch.cuda.device_count())]
return devices if devices else [torch.device('cpu')]
print(try_gpu())
print(try_gpu(10))
print(try_all_gpus())
1
cuda:0
cpu
[device(type='cuda', index=0)]
那么接下来就是将模型、输入、loss这三部分挪到GPU上,那么就可以在GPU上进行计算。
X = torch.ones(2, 3, device=try_gpu())
# 如果有多个gpu,也需要在同一个gpu上运算:Z = X.cuda(1)
net = nn.Sequential(nn.Linear(3,1))
net = net.to(device=try_gpu())
print(net[0].weight.data.device)
需要注意的是,一般来说数据的处理是先在cpu上做,处理完成后再移动到GPU上和网络进行计算。
卷积神经网络
从全连接层到卷积
小结:
- 图像的平移不变性使得我们以相同的方式处理局部图像,而不在乎它所在的位置
- 局部性意味着计算相应的隐藏表示只需要一小部分的局部图像像素
- 在图像处理中,卷积层通常比全连接层需要更少的参数,但依旧获得高效用的性能
- 卷积神经网络CNN是一类特殊的神经网络,它可以包含多个卷积层
- 多个输入和输出通道使模型造每个空间位置可以获得图像的多方面特征
图像卷积
import torch
from torch import nn
from d2l import torch as d2l
def corr2d(X, K): # @save
h, w = K.shape # 卷积核的大小
Y = torch.zeros((X.shape[0] - h + 1, X.shape[1] - w + 1))
for i in range(Y.shape[0]):
for j in range(Y.shape[1]):
Y[i, j] = (X[i:i + h, j:j + w] * K).sum()
return Y
class Conv2D(nn.Module):
def __init__(self, kernel_size):
super().__init__()
self.weight = nn.Parameter(torch.rand(kernel_size))
self.bias = nn.Parameter(torch.zeros(1))
def forward(self, x):
return corr2d(x, self.weight) + self.bias
X = torch.ones((6,8))
X[:,2:6] = 0
K = torch.tensor([[1.0,-1.0]])
Y = corr2d(X,K)
print(Y)
填充和步幅度
当当输入图像的形状为\(n_h \times n_w\),卷积形状为\(k_h \times k_w\)时,那么输出形状为\((n_h-k_h+1)\times (n_w -k_w+1)\)。
那么若填充\(p_h\)行和\(p_w\)列(分别进行上下左右平均分类),那么最终输出的形状为:
若调整垂直步幅为\(s_h\),水平步幅为\(s_w\)时,输出形状为:
import torch
from torch import nn
def comp_conv2d(conv2d,x):
x = x.reshape((1,1) + X.shape) # 将维度弄成4个,前两个为填充和步幅
y = conv2d(x)
return y.reshape(y.shape[2:])
conv2d = nn.Conv2d(1,1,kernel_size=(3,5),padding=(0,1),stride=(3,4))
X = torch.rand(size=(8,8))
print(comp_conv2d(conv2d,X).shape)
小结:
- 填充可以增加输出的高度和宽度,这常用来使得输出与输入具有相同的高和宽
- 步幅可以减小输出的高和宽,例如输出的高和宽仅为输入的高和宽的\(\frac{1}{n}\)
- 填充和步幅可用于有效地调整数据的维度
多输入多输出通道
对于多输入通道来说,一般都有相同通道数的卷积核来跟其进行匹配,然后计算的过程就是对每个通道输入的二维张量和对应通道的卷积核的二维张量进行运算,每个通道得到一个计算结果,然后就将各个计算结果相加作为输出的单通道的那个位置的数值,如下图:
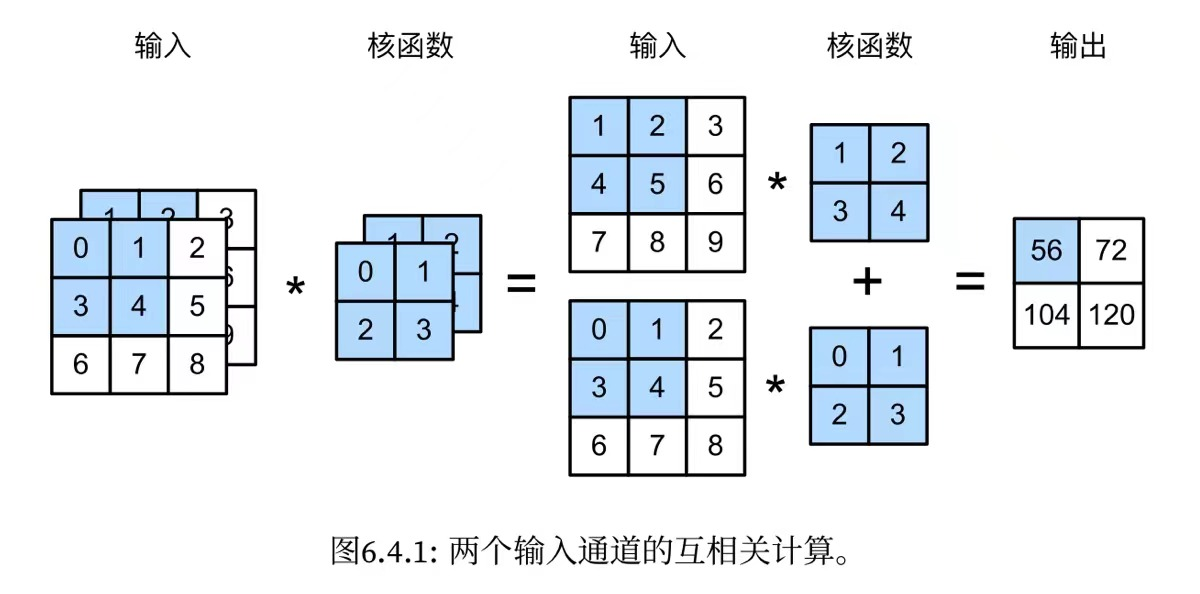
对于多输出通道来说,可以将每个通道看作是对不同特征的响应,假设\(c_i、c_o\)分别为输入和输出通道的数目,那么为了得到这多个通道的输出,我们需要为每个输出通道创建一个形状为\(c_i\times k_h \times k_w\)大小的卷积核张量,因此总的卷积核的形状为\(c_o\times c_i \times k_h \times k_w\)。
而还有一种特殊的卷积层,为\(1\times 1\)卷积层。因为高宽只有1,因此它无法造高度和宽度的维度上,识别相邻元素间相互作用的能力,它唯一的计算发生在通道上。如下图:
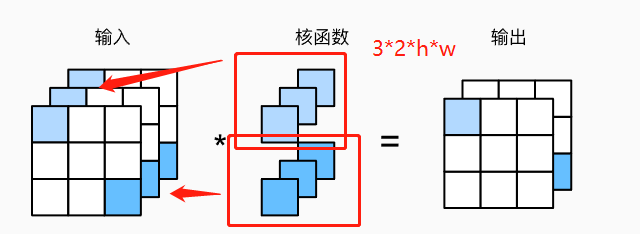
这种卷积层会导致输入和输出具有相同的高度和宽度,但是通道数发生了变化,输出中的每个元素都是从输入图像中同一位置的元素的线性组合,这就说明可以将这个卷积层起的作用看成是一个全连接层,输入的每个通道就是一个输入结点,然后卷积核的每一个通道就是对应的权重。
因此\(1\times 1\)卷积层通常用于调整网络层的通 道数量和控制模型的复杂度
池化层(汇聚层)
池化层可以用来处理卷积对于像素位置尤其敏感的问题,例如下面:
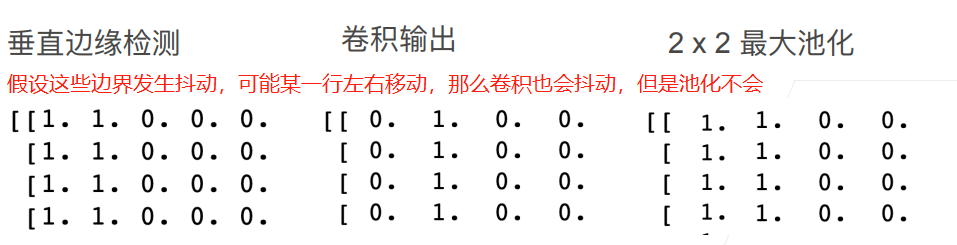
那么池化有最大池化以及平均池化
具体实现为:
pool2d = nn.MaxPool2d((2,3),padding=(1,1),stride=(2,3))
如果应对多通道的场景,会保持输入和输出通道相等。
小结:
- 对于给定输入元素,最大池化层会输出该窗口内的最大值,平均池化层会输出该窗口内的平均值
- 池化层的主要优点之一是减轻卷积层对位置的过度敏感
- 可以指定池化层的填充和步幅
- 使用最大池化层以及大于1的步幅,可以减小空间的维度
- 池化层的输出通道数和输入通道数相同
卷积神经网络(LeNet)
import torch
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
class Reshape(torch.nn.Module):
def forward(self, x):
return x.view(-1, 1, 28, 28)
net = nn.Sequential(
Reshape(),
nn.Conv2d(1, 6, kernel_size=5, padding=2),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5),
nn.Sigmoid(),
nn.AvgPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 5 * 5, 120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.Sigmoid(),
nn.Linear(84, 10)
)
# 载入数据集
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size=batch_size)
# 修改评估函数,使用GPU来计算
def evaluate_accuracy_gpu(net, data_iter, device=None): # @save
if isinstance(net, torch.nn.Module):
net.eval() # 转为评估模式
if not device: # 如果不是为None
device = next(iter(net.parameters())).device
metric = d2l.Accumulator(2)
for X,y in data_iter:
if isinstance(X, list):
X = [x.to(device) for x in X]
else:
X = X.to(device)
y = y.to(device)
metric.add(d2l.accuracy(net(X),y), y.numel())
return metric[0] / metric[1]
# 对训练函数做改动,使其能够在GPU上跑
def train_ch6(net, train_iter, test_iter, num_eopchs, lr, device): #@ save
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print("training on:",device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1,num_eopchs],
legend=["train loss",'train acc', 'test,acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_eopchs):
metric = d2l.Accumulator(3)
net.train() # 开启训练模式
for i,(X,y) in enumerate(train_iter):
timer.start() # 开始计时
optimizer.zero_grad() # 清空梯度
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat,y), X.shape[0])
timer.stop() # 停止计时
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i+1) % (num_batches // 5) == 0 or i==num_batches-1:
animator.add(epoch + (i+ 1) / num_batches,
(train_l, train_acc ,None))
test_acc = evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch+1, (None, None, test_acc))
print(f'loss{ train_l:.3f},train acc{train_acc:.3f},'
f'test acc{test_acc:.3f}')
print(f'{metric[2] * num_eopchs / timer.sum():1f} examples / sec'
f'on{str(device)}')
lr, num_epoch = 0.5,20
train_ch6(net, train_iter, test_iter, num_epoch, lr ,d2l.try_gpu())
plt.show()
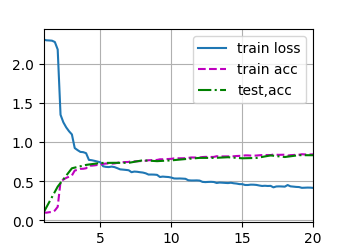
loss0.417,train acc0.847,test acc0.836
36144.960085 examples / seconcuda:0
小结:
- 卷积神经网络是一类使用卷积层的网络
- 在卷积神经网络中,组合使用卷积层、非线性激活函数和池化层
- 为了构造高性能的CNN,我们通常对卷积层进行排序,逐渐降低其表示的空间分辨率,同时增加通道数
- 在传统的卷积神经网络中,卷积块编码得到的表征在输出之前需要由一个或多个全连接层进行处理
- LeNet是最早发布的卷积神经网络之一
深度卷积神经网络(AlexNet)
import torch
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
net = nn.Sequential(
nn.Conv2d(1, 96, kernel_size=11, stride=4, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(96, 256, kernel_size=5, padding=2),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(256, 384, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(384, 384, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Flatten(),
nn.Linear(6400, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 10)
)
batch_size = 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
# 读取数据然后将其高和宽都拉成224
lr, num_epochs = 0.01, 10
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
plt.show()
跑了好久:
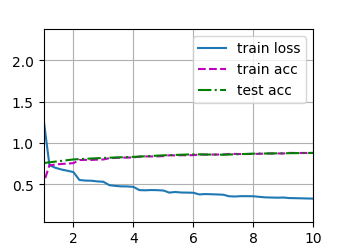
loss 0.328, train acc 0.881, test acc 0.881
666.9 examples/sec on cuda:0
使用块的网络(VGG)
VGG就是沿用了AlexNet的思想,将多个卷积层和一个池化层组成一个块,然后可以指定每个块内卷积层的数目,以及块的数目,经过多个块对图像信息的提取后再经过全连接层。
VGG块中包含以下内容:
- 多个带填充以保持分辨率不变的卷积层
- 每个卷积层后都带有非线性激活函数
- 最后一个池化层
具体代码如下:
import torch
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
def vgg_block(num_convs, in_channels, out_channels):
# 该函数用来创建单个的VGG块
layers = []
for _ in range(num_convs):
layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1))
layers.append(nn.ReLU())
in_channels = out_channels
layers.append(nn.MaxPool2d(kernel_size=2, stride=2))
return nn.Sequential(*layers)
def vgg(conv_arch):
conv_blks = []
in_channels = 1
# 构建卷积层
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
return nn.Sequential(
*conv_blks,
nn.Flatten(),
nn.Linear(out_channels * 7 * 7, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(),
nn.Dropout(p=0.5),
nn.Linear(4096, 10)
)
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
# 第一个为块内卷积层个数,第二个为输出通道数
ratio = 4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
# 除以ratio减少通道数目
net = vgg(small_conv_arch)
lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net,train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
plt.show()
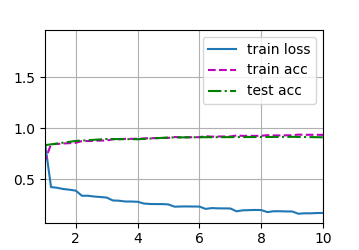
loss 0.170, train acc 0.936, test acc 0.912
378.0 examples/sec on cuda:0
小结:
- VGG-11使用可复用的卷积块来构造网络,不同的VGG模型可通过每个块中卷积层数量和输出通道数量的差异来定义
- 块的使用导致网络定义得非常简洁,使用块可以有效地设计复杂的网络
- 在研究中发现深层且窄的卷积(多层\(3\times 3\))比浅层且宽(例如少层\(5\times 5\))的效果更好
网络中的网络(NiN)
之前的网络都有一个共同的特点在于最后都会通过全连接层来对特征的表示进行处理,这就导致参数数量很大。那么NiN就是希望能够很其他的模块来替换掉全连接层,那么就用到了\(1 \times 1\)的卷积层,因此1个NiN块就是一个正常的卷积层和两个\(1 \times 1\)的卷积层,那么经过多个NiN块后,将通道数拓展到希望输出的类别数,然后用一个具有输出类别数目的通道数的全局平均池化层来进行处理,也就是对每个通道进行全部平均得到单个标量,那么有\(out\_channels\)个通道就有相应个数值,再经过softmax就可以作为输出了。
import torch
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
def nin_block(in_channels, out_channels, kernel_size, strides, padding):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size, strides, padding),
# 在第一个卷积层就将其转换为对应的通道数和大小
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1),
nn.ReLU(),
nn.Conv2d(out_channels, out_channels, kernel_size=1),
nn.ReLU() # 两个1*1的卷积层都不改变大小和通道
)
net = nn.Sequential(
nin_block(1, 96, kernel_size=11, strides=4, padding=0),
nn.MaxPool2d(3, stride=2), # 使得高宽减半
nin_block(96, 256, kernel_size=5, strides=1, padding=2),
nn.MaxPool2d(3,stride=2),
nin_block(256, 384, kernel_size=3, strides=1, padding=1),
nn.MaxPool2d(3,stride=2),
nn.Dropout(p=0.5),
# 标签类别数为10,因此最后一个输出通道数设为10
nin_block(384, 10, kernel_size=3, strides=1, padding=1),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten() # 将四维度的转成两个维度(批量大小,输出通道数)
)
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
plt.show()
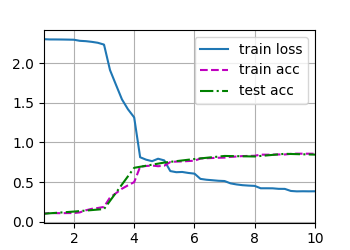
loss 0.383, train acc 0.857, test acc 0.847
513.3 examples/sec on cuda:0
小结:
- NiN使用由一个卷积层和多个\(1\times 1\)卷积层组成的块,该块可以在卷积神经网络中使用,以允许更多的像素非线性
- NiN去除了容易造成过拟合的全连接层,将它们替换成全局平均池化层,该池化层通道数量为所需的输出数目
- 移除全连接层可以减少过拟合,同时显著减少参数量
含并行连接的网络(GoogLeNet)
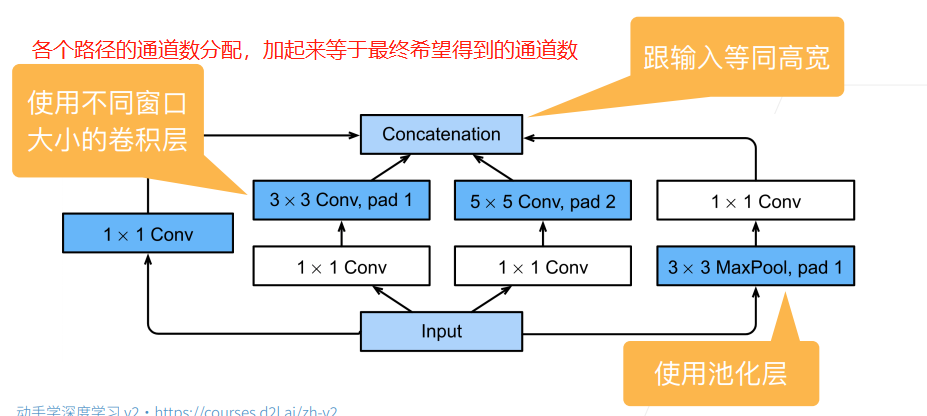
前面提到的各种网络,其中的问题在于各个卷积层的参数可能都是不一样的,而DNN的解释性如此之差,我们很难解释清楚哪一个超参数的卷积层才是我们需要的,才是最好的。因此在GoogLeNet网络中,其引入了Inception块,这种块引入了并行计算的思想,将常见的多种不同超参数的卷积层都放入,希望能够通过多种提取特征的方式来得到最理想的特征提取效果,如下图:
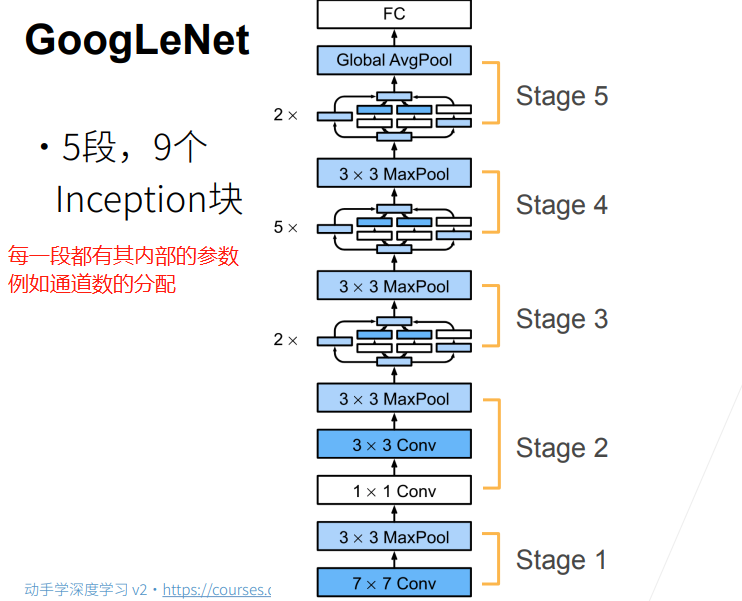
其具体的结构为:
import torch
from matplotlib import pyplot as plt
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Inception(nn.Module):
def __init__(self, in_channels, c1,c2,c3, c4, **kwargs):
super(Inception, self).__init__(**kwargs)
# 线路1,单1*1卷积层
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
# 线路2,1*1卷积层后接3*3卷积层
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0],c2[1], kernel_size=3, padding=1)
# 线路3,1*1卷积层后接上5*5卷积层
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
# 线路4,3*3最大池化层后接上1*1卷积层
self.p4_1 = nn.MaxPool2d(kernel_size=3, stride=1,padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self,x):
p1 = F.relu(self.p1_1(x))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(x))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(x))))
p4 = F.relu(self.p4_2(self.p4_1(x)))
# 再在通道维度上叠加在一起
return torch.cat((p1,p2,p3,p4),dim=1)
b1 = nn.Sequential(
nn.Conv2d(1,64, kernel_size=7, stride=2, padding=3),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
b2 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=1),
nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
b3 = nn.Sequential(
Inception(192,64,(96,128),(16,32),32),
Inception(256,128,(128,192),(32,96),64),
nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
)
b4 = nn.Sequential(
Inception(480, 192, (96,208),(16,48), 64),
Inception(512, 160, (112,224),(24,64), 64),
Inception(512,128,(128,256),(24,64),64),
Inception(512,112, (144,288),(32,64), 64),
Inception(528, 256, (160,320),(32,128),128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
b5 = nn.Sequential(
Inception(832,256, (160,320),(32,128),128),
Inception(832, 384, (192,384), (48,128),128),
nn.AdaptiveAvgPool2d((1, 1)), nn.Flatten()
)
net = nn.Sequential(
b1,b2,b3,b4,b5,nn.Linear(1024,10)
)
lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
plt.show()
"""
x = torch.rand(size=(1,1,96,96))
for layer in net:
x = layer(x)
print(layer.__class__.__name__, 'output shape \t', x.shape)
"""
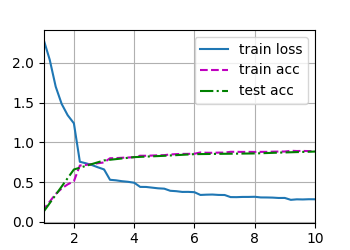
loss 0.284, train acc 0.891, test acc 0.884
731.9 examples/sec on cuda:0
小结:
- Inception块相当于一个有4条路径的子网络,它通过不同窗口形状的卷积层和最大池化层来并行抽取信息,并使用\(1\times 1\)卷积层减少每像素级别上的通道维数从而降低模型复杂度
- GoogLeNet将多个设计精细的Inception块与其他层(卷积层、全连接层)串联起来,其中Inception块的通道数分配之比是在ImageNet数据集上通过大量的实验得到的
- GoogLeNet和它的后继者们一度是ImageNet上最有效的模型之一:它以较低的计算复杂度提供了类似的测试精度
批量归一化
在训练过程中,一般正常情况下,后面的层的梯度会比较大,而前面层的梯度会因为经过多层的传播一直相乘而变得比较小,而此时学习率如果固定的话,那么前面的层就会更新得比较慢,后面层会更新得比较快,那么当后面层更新即将完成时,会因为前面的层发生了变动,那么后面层就需要重新更新。
那么批量规范化的思想是:在每一个卷积层或线型层后应用,将其输出规范到某一个分布之中(不同的层所归到的分布是不一样的,是各自学习的),那么限制到一个想要的分布后便可以使得收敛更快。
假设当前批量B得到的样本为\(\pmb{x}=(x_1,x_2,...,x_n)\),那么:
可以认为\(\gamma、\beta\)分别为要规范到的分布的方差和均值,是两个待学习的参数。
研究指出,其作用可能就是通过在每个小批量中加入噪音来控制模型的复杂度,因为批量是随机取得的,因此批量的均值和方差也就不同,相当于对该次批量加入了随机偏移\(\hat{\mu}_B\)和随机缩放\(\hat{\sigma}_B\)。需要注意的是它不需要与Dropout一起使用。
它可以作用的全连接层和卷积层的输出上,激活函数之前,也可以作用到全连接层和卷积层的输入上:
- 对于全连接层来说,其作用在特征维
- 对于卷积层,作用在通道维
而当我们在训练中采用和批量归一化,我们就需要记下来每个用到批量归一化的地方,其整个样本数据集的均值和方差是多少,这样才能够在进行预测的时候也对预测样本进行规范。
import torch
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
if not torch.is_grad_enabled(): # 说明当前在预测
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps) # 防止方差为0
# 这两个参数就是整个数据集的均值和方差
else:
assert len(X.shape) in (2,4) # 维度数目为2,是全连接层,为4是卷积层
if len(X.shape) == 2:
mean = X.mean(dim = 0)
var = ((X - mean) ** 2 ).mean(dim = 0)
else:
mean = X.mean(dim=(0,2,3),keepdim=True)
# 每一个通道是一个不同的特征,其提取了图像不同的特征,因此对通道维计算均值方差
var = ((X - mean) ** 2).mean(dim=(0,2,3), keepdim = True)
# 当前在训练模式
X_hat = (X - mean) / torch.sqrt(var + eps)
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta
return Y, moving_mean.data, moving_var.data
class BatchNorm(nn.Module):
def __init__(self,num_features, num_dims):
super().__init__()
if num_dims == 2:
shape = (1, num_features)
else:
shape = (1, num_features, 1, 1)
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.ones(shape)
def forward(self, X):
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
Y,self.moving_mean, self.moving_var = batch_norm(X,self.gamma, self.beta, self.moving_mean,
self.moving_var, eps=1e-5, momentum=0.9)
return Y
net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5),
BatchNorm(6, num_dims=4),
nn.Sigmoid(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16,kernel_size=5),
BatchNorm(16, num_dims=4),
nn.Sigmoid(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 4 * 4, 120),
BatchNorm(120, num_dims=2),
nn.Sigmoid(),
nn.Linear(120, 84),
BatchNorm(84, num_dims=2),
nn.Sigmoid(),
nn.Linear(84, 10))
lr, num_epochs, batch_size = 1.0, 10 ,256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch6(net,train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
plt.show()
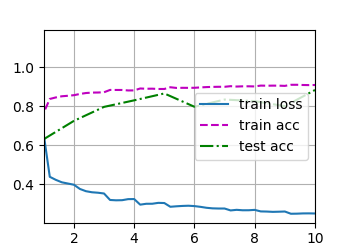
loss 0.251, train acc 0.908, test acc 0.883
17375.8 examples/sec on cuda:0
而nn中也有简单的实现方法:
net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5),
nn.BatchNorm2d(6),
nn.Sigmoid(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16,kernel_size=5),
nn.BatchNorm2d(16),
nn.Sigmoid(),
nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(),
nn.Linear(16 * 4 * 4, 120),
nn.BatchNorm2d(120),
nn.Sigmoid(),
nn.Linear(120, 84),
nn.BatchNorm2d(84),
nn.Sigmoid(),
nn.Linear(84, 10))
小结:
- 在模型训练的过程中,批量归一化利用小批量的均值和标准差,不断调整神经网络的中间输出,使整个神经网络各层的中间输出更加稳定
- 批量归一化在全连接层和卷积层的使用略有不同,需要注意作用的维度
- 批量归一化和Dropout一样,在训练模式和预测模式下计算不同
- 批量归一化有许多有益的副作用,主要是正则化
残差网络(ResNet)
我们需要讨论一个问题是:是否加入更多的层就能够使得精度进一步提高?
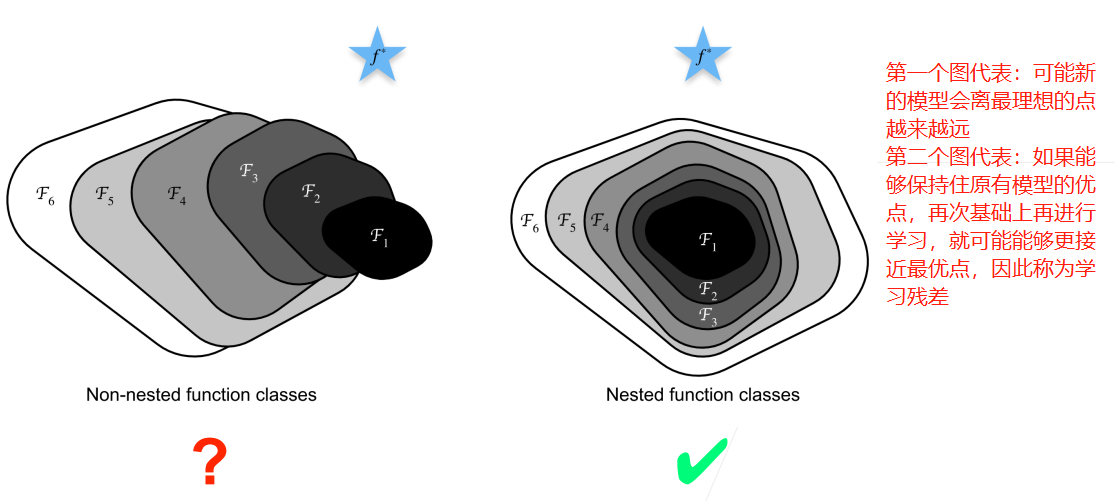
因此ResNet就是这种思想,最具体的表现是:
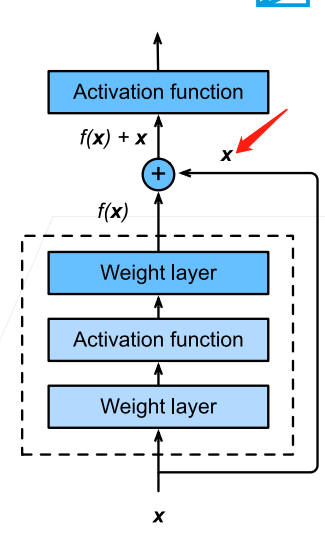
那么将该块的输入连接到输出,就需要输入和输出的维度是相同的,可以直接相加,因此如果块内部对维度进行了改变,那么就需要对输入也进行维度的变化才能够相加:
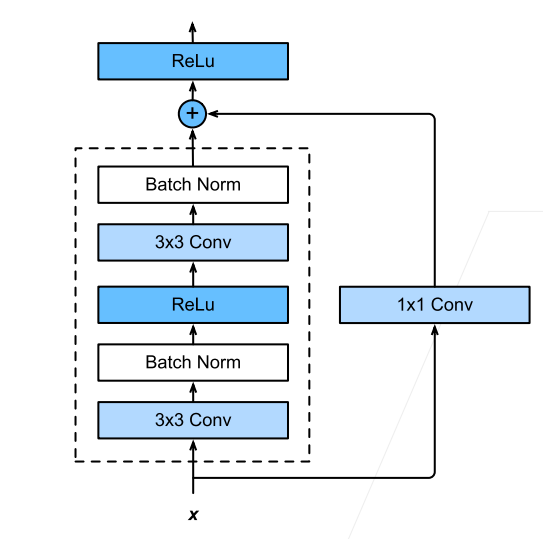
那么一般来说,是先对输入进行多个高宽减半的ResNet块,后面再接多个高宽不变的ResNet块,可以使得后面提取特征的时候减少计算量:
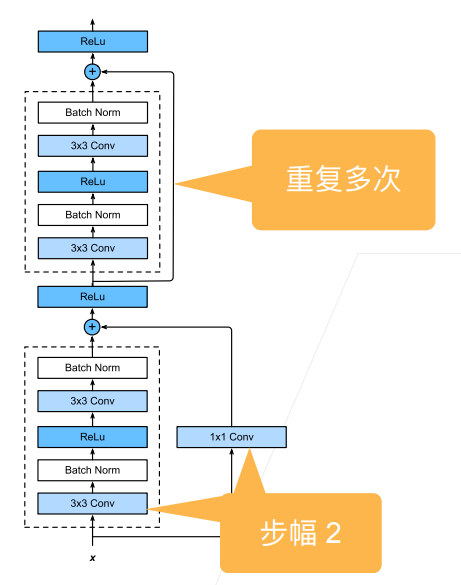
那么整体的架构就是:
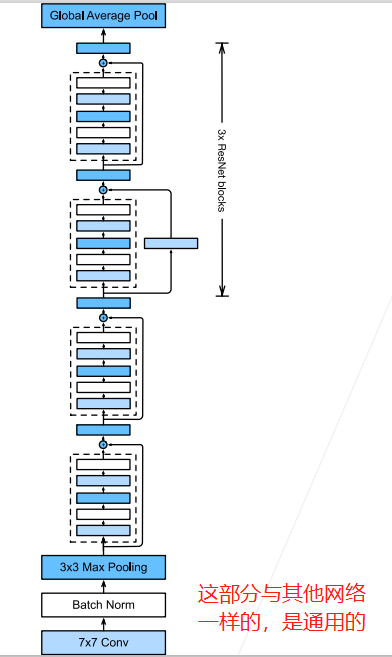
因此,代码为:
import torch
from matplotlib import pyplot as plt
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Residual(nn.Module): #@save
def __init__(self, input_channels, num_channels,
use_1x1conv=False, strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels,
kernel_size=3, padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels,
kernel_size=3, padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
# 第一个模块基本上在卷积神经网络中都是一样的
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
def resnet_block(input_channels, num_channels, num_residuals,first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(Residual(input_channels, num_channels,use_1x1conv=True, strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*resnet_block(64,64,2,first_block=True))
b3 = nn.Sequential(*resnet_block(64,128,2))
b4 = nn.Sequential(*resnet_block(128,256,2))
b5 = nn.Sequential(*resnet_block(256,512,2))
# *号代表把resnet_block返回的列表展开,可以理解为把元素都拿出来,不是单个列表了
net = nn.Sequential(
b1,b2,b3,b4,b5,
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(),
nn.Linear(512,10)
)
"""
X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__,'output shape:\t', X.shape)
"""
lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
plt.show()
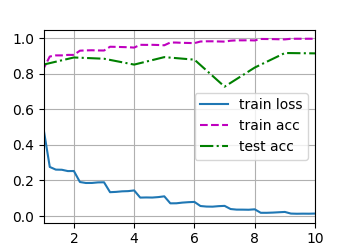
loss 0.014, train acc 0.996, test acc 0.914
883.9 examples/sec on cuda:0
李沐老师后面又补充了一节关于ResNet的梯度计算的内容,具体如下:
图像分类竞赛
本次我先是采用了李沐老师上课讲过的ResNet11去跑,结果达到了0.8多一点,具体的代码请见下:
# 首先导入包
import torch
import torch.nn as nn
import pandas as pd
import numpy as np
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import os
from d2l import torch as d2l
import matplotlib.pyplot as plt
from LeavesDataset import LeavesDataset # 数据加载器
先是要对标签类的数据进行处理,将其从字符串转换为对应的类别数字,同时在这两者之间建立关系方便后续:
label_dataorgin = pd.read_csv("dataset/classify-leaves/train.csv") # 读取csv文件
leaves_labels = sorted(list(set(label_dataorgin['label']))) # 取出标签列然后set去重再列表排序
num_class = len(leaves_labels) # 总共的类别数目
class_to_num = dict(zip(leaves_labels, range(num_class))) # 建立字典,类别名称对应数字
num_to_class = {i:j for j,i in class_to_num.items()} # 数字对应类别名称
接下来就是写我们数据加载器,因为我发现一个问题就是如果把数据加载器和整体的代码写在同样的文件中会报错,会在之后调用d2l的训练函数时说找不到这个数据加载器的定义,那么我们需要在另外的文件写数据加载器的定义然后引用,我在另外的LeavesDataset.py文件中为其定义:
class LeavesDataset(Dataset):
def __init__(self, csv_path, file_path, mode = 'train', valid_ratio = 0.2,
resize_height = 256, resize_width=256):
self.resize_height = resize_height # 拉伸的高度
self.resize_width = resize_width # 宽度
self.file_path = file_path # 文件路径
self.mode = mode # 模式
self.data_csv = pd.read_csv(csv_path, header=None) # 读取csv文件去除表头
self.dataLength = len(self.data_csv.index) - 1 # 数据长度
self.trainLength = int(self.dataLength * (1 - valid_ratio)) # 训练集的长度
if mode == 'train':
# 训练模式
self.train_images = np.asarray(self.data_csv.iloc[1:self.trainLength, 0]) # 第0列为图像的名称
self.train_labels = np.asarray(self.data_csv.iloc[1:self.trainLength, 1]) # 第1列为图像的标签
self.image_arr = self.train_images
self.label_arr = self.image_arr
elif mode == 'valid':
self.valid_images = np.asarray(self.data_csv.iloc[self.trainLength:, 0])
self.valid_labels = np.asarray(self.data_csv.iloc[self.trainLength:, 1])
self.image_arr = self.valid_images
self.label_arr = self.valid_labels
elif mode == 'test':
self.test_images = np.asarray(self.data_csv.iloc[1:,0]) # 测试集没有标签列
self.image_arr = self.test_images
self.realLen_now = len(self.image_arr)
print("{}模式下已完成数据载入,得到{}个数据".format(mode, self.realLen_now))
def __getitem__(self, index):
image_name = self.image_arr[index] # 得到文件名
img = Image.open(os.path.join(self.file_path, image_name)) # 拼接后得到当前访问图片的完整路径
transform = transforms.Compose([
transforms.Resize((224,224)), # 更改为224*224
transforms.ToTensor()
])
img = transform(img)
if self.mode == 'test':
return img
else:
label = self.label_arr[index]
number_label = class_to_num[label]
return img, number_label
def __len__(self):
return self.realLen_now
那么接下来就是加载各个数据集了:
train_path = "dataset/classify-leaves/train.csv" # 根据你的实际情况修改
test_path = "dataset/classify-leaves/test.csv"
img_path = "dataset/classify-leaves/"
train_dataset = LeavesDataset(train_path, img_path, mode = 'train')
valid_dataset = LeavesDataset(train_path, img_path, mode = 'valid')
test_dataset = LeavesDataset(test_path, img_path, mode = 'test')
batch_size = 64 # 这里如果显存不够可以调小
train_loader = DataLoader(dataset=train_dataset,batch_size=batch_size, shuffle=False,num_workers=5) # 不随机打乱,进程数为5
valid_loader = DataLoader(dataset=valid_dataset,batch_size=batch_size, shuffle=False,num_workers=5)
test_loader = DataLoader(dataset=test_dataset,batch_size=batch_size, shuffle=False,num_workers=5)
得到数据后接下来就是定义模型了,我先是采用了ResNet11:
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
def resnet_block(input_channels, num_channels, num_residuals,first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(d2l.Residual(input_channels, num_channels,use_1x1conv=True, strides=2))
else:
blk.append(d2l.Residual(num_channels, num_channels))
return blk
b2 = nn.Sequential(*resnet_block(64,64,2,first_block=True))
b3 = nn.Sequential(*resnet_block(64,128,2))
b4 = nn.Sequential(*resnet_block(128,256,2))
b5 = nn.Sequential(*resnet_block(256,512,2))
net = nn.Sequential(
b1,b2,b3,b4,b5,
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(),
nn.Linear(512,176)
)
然后因为我希望如果模型能够达到要求的精度我就将其保存下来,因此修改了训练函数:
def train_ch6_save(net, train_iter, test_iter, num_epochs, lr, device, best_acc): #@save
"""Train a model with a GPU (defined in Chapter 6).
Defined in :numref:`sec_lenet`"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# Sum of training loss, sum of training accuracy, no. of examples
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
if test_acc > best_acc:
print("模型精度较高,值得保存!")
torch.save(net.state_dict(), "Now_Best_Module.pth")
else:
print("模型精度不够,不值得保存")
lr, num_epochs,best_acc = 0.05, 25, 0.8 # epoch太小训练不完全
train_ch6_save(net, train_loader, valid_loader, num_epochs, lr, device=d2l.try_gpu(), best_acc=best_acc)
plt.show()
得到结果为:
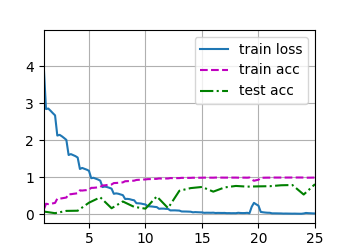
那么我接下来希望加大ResNet的深度来提高模型复杂度,用了网上的ResNet50模型发现太大了,读完模型之后再读数据,就算把batch_size设置小也显存爆了,因此只能修改模型小一点:
b2 = nn.Sequential(*resnet_block(64,64,2,first_block=True))
b3 = nn.Sequential(*resnet_block(64,256,2))
b4 = nn.Sequential(*resnet_block(256,512,2))
b5 = nn.Sequential(*resnet_block(512,2048,3))
net = nn.Sequential(
b1,b2,b3,b4,b5,
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(),
nn.Linear(2048,176)
)
跑了五个小时结果过拟合了...
loss 0.014, train acc 0.996, test acc 0.764
31.6 examples/sec on cuda:0
最终调试了好几个模型花费了一整天的时间,还是没有最开始的ResNet11的效果好,最终决定就用这个了。
因此完整的代码为:
# 首先导入包
import torch
import torch.nn as nn
import pandas as pd
import numpy as np
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import os
from d2l import torch as d2l
import matplotlib.pyplot as plt
from tqdm import tqdm
from LeavesDataset import LeavesDataset
def resnet_block(input_channels, num_channels, num_residuals, first_block=False): # 这是ResNet定义用到的函数
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(d2l.Residual(input_channels, num_channels, use_1x1conv=True, strides=2))
else:
blk.append(d2l.Residual(num_channels, num_channels))
return blk
def train_ch6_save(net, train_iter, test_iter, num_epochs, lr, device, best_acc): # @save
"""Train a model with a GPU (defined in Chapter 6).
这是因为我需要训练完保存因此将老师的训练函数进行了修改,就放在这里了
Defined in :numref:`sec_lenet`"""
def init_weights(m):
if type(m) == nn.Linear or type(m) == nn.Conv2d:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
print('training on', device)
net.to(device)
optimizer = torch.optim.SGD(net.parameters(), lr=lr)
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=['train loss', 'train acc', 'test acc'])
timer, num_batches = d2l.Timer(), len(train_iter)
for epoch in range(num_epochs):
# Sum of training loss, sum of training accuracy, no. of examples
metric = d2l.Accumulator(3)
net.train()
for i, (X, y) in enumerate(train_iter):
timer.start()
optimizer.zero_grad()
X, y = X.to(device), y.to(device)
y_hat = net(X)
l = loss(y_hat, y)
l.backward()
optimizer.step()
with torch.no_grad():
metric.add(l * X.shape[0], d2l.accuracy(y_hat, y), X.shape[0])
timer.stop()
train_l = metric[0] / metric[2]
train_acc = metric[1] / metric[2]
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(train_l, train_acc, None))
test_acc = d2l.evaluate_accuracy_gpu(net, test_iter)
animator.add(epoch + 1, (None, None, test_acc))
print(f'loss {train_l:.3f}, train acc {train_acc:.3f}, '
f'test acc {test_acc:.3f}')
print(f'{metric[2] * num_epochs / timer.sum():.1f} examples/sec '
f'on {str(device)}')
if test_acc > best_acc:
print("模型精度较高,值得保存!")
torch.save(net.state_dict(), "Now_Best_Module.pth") # 对模型进行保存
else:
print("模型精度不够,不值得保存")
if __name__ == "__main__": # 一定要将运行的代码放在这里!否则会报错,我目前还不知道原因
label_dataorgin = pd.read_csv("dataset/classify-leaves/train.csv") # 读取训练的csv文件
leaves_labels = sorted(list(set(label_dataorgin['label']))) # 取出标签列然后去重再排序
num_class = len(leaves_labels) # 类别的个数
class_to_num = dict(zip(leaves_labels, range(num_class))) # 转换为字典
num_to_class = {i: j for j, i in class_to_num.items()}
train_path = "dataset/classify-leaves/train.csv"
test_path = "dataset/classify-leaves/test.csv"
img_path = "dataset/classify-leaves/"
submission_path = "dataset/classify-leaves/submission.csv" # 最终要提交的文件的路径
train_dataset = LeavesDataset(train_path, img_path, mode='train')
valid_dataset = LeavesDataset(train_path, img_path, mode='valid')
test_dataset = LeavesDataset(test_path, img_path, mode='test')
#print("数据载入完成")
batch_size = 64
train_loader = DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=False, num_workers=5)
valid_loader = DataLoader(dataset=valid_dataset, batch_size=batch_size, shuffle=False, num_workers=5)
test_loader = DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False, num_workers=5)
#print("数据已变换为loader")
# 定义模型
# 第一个模块基本上在卷积神经网络中都是一样的
b1 = nn.Sequential(nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
net = nn.Sequential(
b1, b2, b3, b4, b5,
nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(),
nn.Linear(512, 176)
)
lr, num_epochs, best_acc = 0.02, 15, 0.85
device = d2l.try_gpu()
train_ch6_save(net, train_loader, valid_loader, num_epochs, lr, device=device, best_acc=best_acc)
plt.show()
# 开始做预测
net.load_state_dict(torch.load("Now_Best_Module.pth")) # 载入模型
# print("模型载入完成")
net.to(device)
net.eval() # 开启预测模式
predictions = [] # 用来存放结果类别对应的数字
for i, data in enumerate(test_loader):
imgs = data.to(device)
with torch.no_grad():
logits = net(imgs) # 计算结果是一个176长的向量
predictions.extend(logits.argmax(dim=-1).cpu().numpy().tolist())
# 取出最大的作为结果,并且放回cpu中,再转换成列表方便插入到predictions中
preds = []
for i in predictions:
preds.append(num_to_class[i]) # 转换为字符串
test_csv = pd.read_csv(test_path)
test_csv['label'] = pd.Series(preds) # 将结果作为一个新的列添加
submission = pd.concat([test_csv['image'], test_csv['label']], axis=1) # 拼接
submission.to_csv(submission_path, index=False) # 写入文件
提交的分数为:
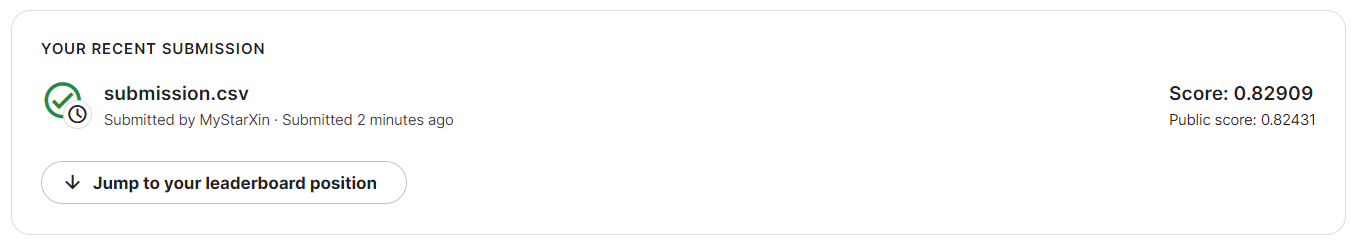
自己还是非常开心的!第一次完完整整地完成了一个项目,真正地学到了很多东西!只有自己动手从零开始才真正明白自己哪部分欠缺,因此才能够有进步!
请继续努力吧!
稠密连接网络(DenseNet)
与ResNet相比,DenseNet具有更加稠密连接的特点。
之前的ResNet通常是每个层,会与它前面的某一层相连接,按照元素相加的方式结合,如下图:
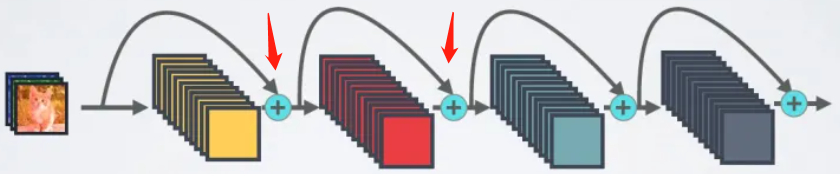
而DenseNet不同,它是每个层都会与前面所有层相连接,而且连接的方式是在通道维度上拼接在一起,这样对于一个\(L\)层的网络,DenseNet共包含有\(\frac{L(L+1)}{2}\)个连接,因此是一种密集连接型。
如果要数字化来表示这种关系,假设传统的网络在第\(l\)层的输出为:
那么ResNet的输出为:
而DenseNet的输出为:
稠密网络主要由两部分构成:稠密块和过渡层。前者定义如何连接输入和输出,后者则控制通道数量,使其不会太复杂。
具体代码如下:
import torch
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
def conv_block(input_channels, num_channels): # 改良版的卷积
return nn.Sequential(
nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=3, padding=1)
)
class DenseBlock(nn.Module):
# 一个稠密块由多个卷积块组成,每个卷积块使用相同数量的输出通道
def __init__(self, num_convs, input_channels, num_channels):
super(DenseBlock,self).__init__()
layer = []
for i in range(num_convs):
layer.append(conv_block( num_channels * i + input_channels, num_channels))
# 因此每次都会加上前面输入的通道数目
self.net = nn.Sequential(*layer)
def forward(self,X):
for blk in self.net:
Y = blk(X)
X = torch.cat((X,Y), dim = 1) # 进行通道维度的连接
return X
def transition_block(input_channels, num_channels):
# 这一层使用1*1的卷积层来减小通道数,使用步幅为2的平均池化层来减半高宽,防止模型太复杂
return nn.Sequential(
nn.BatchNorm2d(input_channels), nn.ReLU(),
nn.Conv2d(input_channels, num_channels, kernel_size=1),
nn.AvgPool2d(kernel_size=2, stride=2)
)
if __name__ == "__main__":
"""
blk = DenseBlock(2,3,10)
X = torch.rand(4,3,8,8)
Y = blk(X)
print(Y.shape)
blk2 = transition_block(23,10)
print(blk2(Y).shape)
"""
b1 = nn.Sequential(
nn.Conv2d(1,64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
num_channels, growth_rate = 64,32 # 第二个参数是指每一个卷积层输出为多少通道
num_convs_in_dense_blocks = [4,4,4,4] # 这个是每一个稠密块中有多少个卷积层
# 每个稠密块4个卷积层,每个卷积层输出为32,因此每个稠密块增加通道数为4*32=128
blks = []
for i, num_convs in enumerate(num_convs_in_dense_blocks):
blks.append(DenseBlock(num_convs, num_channels, growth_rate))
num_channels += num_convs * growth_rate # 每个稠密块运行完都要修改输出通道数
if i != len(num_convs_in_dense_blocks) - 1:
# 在稠密块之间添加转换层,使其通道数量减半
blks.append(transition_block(num_channels, num_channels//2))
num_channels = num_channels // 2
net = nn.Sequential(
b1,
*blks,
nn.BatchNorm2d(num_channels),
nn.ReLU(),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten(),
nn.Linear(num_channels,10)
)
lr, num_epochs, batch_size = 0.1, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
plt.show()
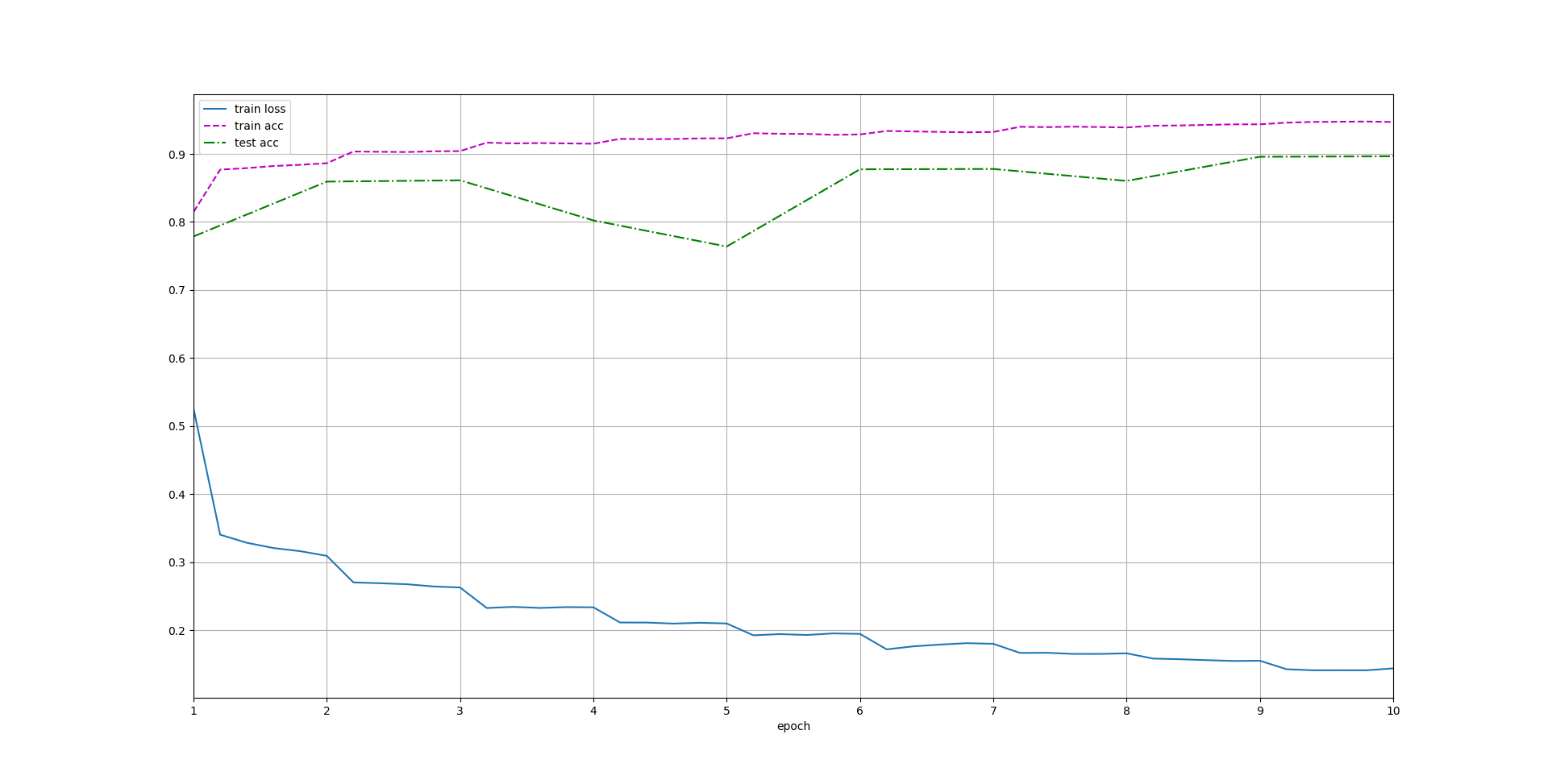
loss 0.144, train acc 0.947, test acc 0.896
1030.5 examples/sec on cuda:0
小结:
- 在跨层连接上,不同于ResNet中将输入与输出按元素相加,DenseNet在通道维上连接输入和输出
- DenseNet的主要构建模块是稠密块与过渡层
- 在构建DenseNet时,我们需要通过添加过渡层来控制网络的维数,从而再次减少通道的数量
计算机视觉
图像增广
图像增广实际上就是对数据进行增强,使得数据集具有更多的多样性,常见的增强方法有:
- 切割:从图片中切割一块,然后变形到固定形状
- 颜色:改变色调、饱和度、明亮度等等
具体代码如下:
import torch
import torchvision
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
d2l.set_figsize()
img = d2l.Image.open("cat.jpg")
d2l.plt.imshow(img)
plt.show()

定义函数方便应用各种变幻效果:
# 该函数可以将各种变幻直接用aug参数传入
def apply(img, aug, num_row=2, num_cols=4, scale=1.5):
Y = [aug(img) for _ in range(num_row * num_cols)]
d2l.show_images(Y, num_row, num_cols, scale=scale)
翻转:
左右翻转:
apply(img, torchvision.transforms.RandomHorizontalFlip()) # 随机左右翻转
plt.show()

上下翻转:
apply(img, torchvision.transforms.RandomVerticalFlip()) # 随机上下翻转
plt.show()

裁剪:
shape_aug = torchvision.transforms.RandomResizedCrop(
(200,200), scale=(0.1,1), ratio=(0.5,2)
) # 随机裁剪面积为10%到100%,裁剪后缩放到200,宽高比从0.5到2之间取值
apply(img,shape_aug)
plt.show()

改变亮度:
apply(img, torchvision.transforms.ColorJitter(
brightness=0.5, contrast=0, saturation=0, hue=0
)) # 随机改变亮度为原始的50% 到150%之间
plt.show()

改变色调:
apply(img, torchvision.transforms.ColorJitter(
brightness=0, contrast=0, saturation=0, hue=0.5))
plt.show()

随机改变亮度、对比度、饱和度、色调:
color_aug = torchvision.transforms.ColorJitter(
brightness=0.5, contrast=0.5, saturation=0.5, hue=0.5)
apply(img, color_aug)
plt.show()

结合多种图像增广办法:
augs = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(), color_aug, shape_aug])
apply(img, augs)
plt.show()

利用图像增广来训练模型:
batch_size, devices, net = 256, d2l.try_gpu(), d2l.resnet18(10,3)
def load_cifar10(is_train, augs, batch_size):
dataset = torchvision.datasets.CIFAR10(root="dataset", train=is_train,
transform=augs, download=True)
dataloader = DataLoader(dataset, batch_size=batch_size,
shuffle=is_train, num_workers=d2l.get_dataloader_workers())
return dataloader
def train_with_data_aug(train_augs, test_augs, net, lr=0.001):
train_iter = load_cifar10(True, train_augs, batch_size=batch_size)
test_iter = load_cifar10(False, test_augs, batch_size=batch_size)
loss = nn.CrossEntropyLoss(reduction='none')
trainer = torch.optim.Adam(net.parameters(),lr=lr)
d2l.train_ch6(net, train_iter, test_iter, 10, lr, devices)
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomHorizontalFlip(), # 随机左右翻转
torchvision.transforms.ToTensor()])
test_augs = torchvision.transforms.Compose([ # 测试集不做增广,只转为tensor
torchvision.transforms.ToTensor()])
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.xavier_uniform_(m.weight)
net.apply(init_weights)
train_with_data_aug(train_augs, test_augs, net)
plt.show()
因为我的电脑只有一个GPU,因此就直接用原来的训练函数了。
不知道为什么跑出来的结果就很烂...
loss 0.181, train acc 0.943, test acc 0.655
650.8 examples/sec on cuda:0
小结:
- 图像增广基于现有的训练数据生成随机图像,来提高模型的泛化能力
- 为了在预测过程中得到确切的结果,我们通常只对训练样本进行图像增广,而对于测试样本不使用带有随机操作的图像增广
- 深度学习框架提供了许多不同的图像增广办法,这些方法可以被同时应用
微调
一个神经网络一般可以分成两个部分,分别是特征抽取和线性分类器部分,前者将原始像素变成容易线型分割的特征,后者用来进行分类。

那么如果我们拥有一个在庞大数据集上已经训练好的模型,那么可以认为特征提取部分学习到了比较通用的提取方法,对我们想要应用的新数据集可能是有用的,而线性部分因为标签已经发生了变化因此无法重复利用,因此一般是将已经训练好的模型的特征提取部分直接copy到新模型中,然后随机初始化最后的线性分类层,这样就叫做微调,
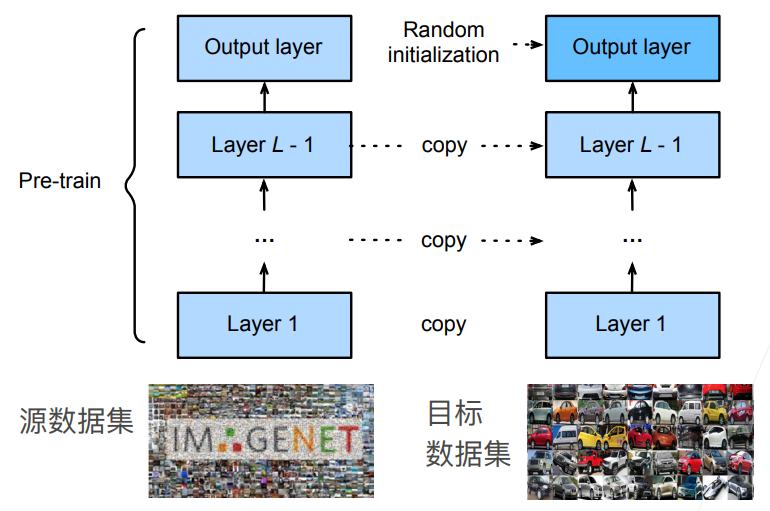
而在训练的时候通常会采用更强的正则化,即在那些重用的特征提取层的参数一般使用很小的学习率进行修改,并且学习迭代次数也比较少,而最后的线性分类层是使用较大的学习率来修改,甚至可以固定底部的某些特征提取层不变(因为底部的才是更加通用的)来减少模型复杂度。
具体代码如下:
import os
import torch
import torchvision
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
#@save
from torch.utils.data import DataLoader
#d2l.DATA_HUB['hotdog'] = (d2l.DATA_URL + 'hotdog.zip','fba480ffa8aa7e0febbb511d181409f899b9baa5')
#data_dir = d2l.download_extract('hotdog')
data_dir = "dataset/hotdog/hotdog" # 因为我一直下载不了,就手动下载解压到这个目录下了
train_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'train'))
test_imgs = torchvision.datasets.ImageFolder(os.path.join(data_dir, 'test'))
# 使用RGB通道的均值和标准差,以标准化每个通道
normalize = torchvision.transforms.Normalize(
[0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
# 这个是imageNet中数据的均值方差,因为模型在这上面训练的时候进行了标准化,因此我们也需要标准化
train_augs = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(224),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
normalize])
test_augs = torchvision.transforms.Compose([
torchvision.transforms.Resize(256),
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
normalize])
finetune_net = torchvision.models.resnet18(pretrained=True) # 获取预先训练的模型
finetune_net.fc = nn.Linear(finetune_net.fc.in_features, 2) # 调整线性分类层
nn.init.xavier_uniform_(finetune_net.fc.weight) # 随机初始化线性分类层的权重
# 如果param_group=True,输出层中的模型参数将使用十倍的学习率
def train_fine_tuning(net, learning_rate, batch_size=128, num_epochs=5,
param_group=True):
train_iter = DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train'), transform=train_augs),
batch_size=batch_size, shuffle=True)
test_iter = DataLoader(torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'test'), transform=test_augs),
batch_size=batch_size)
devices = d2l.try_all_gpus()
loss = nn.CrossEntropyLoss(reduction="none")
if param_group:
params_1x = [param for name, param in net.named_parameters()
if name not in ["fc.weight", "fc.bias"]]
trainer = torch.optim.SGD([{'params': params_1x},
{'params': net.fc.parameters(),
'lr': learning_rate * 10}],
lr=learning_rate, weight_decay=0.001)
else:
trainer = torch.optim.SGD(net.parameters(), lr=learning_rate,
weight_decay=0.001)
d2l.train_ch13(net, train_iter, test_iter, loss, trainer, num_epochs,
devices)
train_fine_tuning(finetune_net, 5e-5)
plt.show()
结果为:
loss 0.200, train acc 0.929, test acc 0.943
188.7 examples/sec on [device(type='cuda', index=0)]
可以看到效果是很好的。
小结:
- 迁移学习将从源数据集中学到的知识“迁移”到目标数据集,微调是迁移学习的常见技巧。
- 除输出层外,目标模型从源模型中复制所有模型设计及其参数,并根据目标数据集对这些参数进行微调。但是,目标模型的输出层需要从头开始训练。
- 通常,微调参数使用较小的学习率,而从头开始训练输出层可以使用更大的学习率。
实战Kaggle比赛:图像分类(CIFAR-10)
import collections
import math
import os
import shutil
import pandas as pd
import torch
import torchvision
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
from torch.utils.data import DataLoader
d2l.DATA_HUB['cifar10_tiny'] = (d2l.DATA_URL + 'kaggle_cifar10_tiny.zip',
'2068874e4b9a9f0fb07ebe0ad2b29754449ccacd')
# 如果你使用完整的Kaggle竞赛的数据集,设置demo为False
demo = True
if demo:
data_dir = d2l.download_extract('cifar10_tiny')
else:
data_dir = 'dataset/cifar-10/'
# @save
def read_csv_labels(fname):
with open(fname, 'r') as f:
lines = f.readlines()[1:] # 跳过文件头一行
tokens = [l.rstrip().split(',') for l in lines]
return dict(((name, label) for name, label in tokens))
#@save
def copyfile(filename, target_dir):
# 将文件复制到目标路径,一个类别占有一个文件夹
os.makedirs(target_dir, exist_ok=True)
shutil.copy(filename, target_dir)
#@save
def reorg_train_valid( data_dir, labels, valid_ratio):
# 该函数将验证集从原始的训练集中拆分出来
n = collections.Counter(labels.values()).most_common()[-1][1] # 取出训练数据集中样本最少的类别中的样本数
n_valid_per_label = max(1, math.floor(n * valid_ratio)) # 至少不能小于1
label_count = {}
for train_file in os.listdir(os.path.join(data_dir, 'train')): # 该文件夹下的类别名称的文件名列表
label = labels[train_file.split(".")[0]]
fname = os.path.join(data_dir, "train", train_file)
copyfile(fname, os.path.join(data_dir, "train_valid_test","train_valid", label))
if label not in label_count or label_count[label] < n_valid_per_label:
copyfile(fname, os.path.join(data_dir, "train_valid_test", "valid", label))
label_count[label] = label_count.get(label,0) + 1
else:
copyfile(fname, os.path.join(data_dir, "train_valid_test", "train", label))
return n_valid_per_label
#@save
def reorg_test(data_dir):
# 在预测期间整理测试集方便读取
for test_file in os.listdir(os.path.join(data_dir, 'test')):
copyfile(os.path.join(data_dir, 'test', test_file),
os.path.join(data_dir, 'train_valid_test','test','unknown'))
def reorg_cifar10_data(data_dir, valid_ratio):
labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv'))
reorg_train_valid( data_dir, labels, valid_ratio)
reorg_test(data_dir)
def get_net():
num_classes = 10
net = d2l.resnet18(num_classes,3)
return net
def train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period, lr_decay):
# 这里主要不同是后面两个参数,就是学习率每经过几个epoch后就乘以lr_decay来缩小
trainer = torch.optim.SGD(net.parameters(), lr=lr, momentum=0.9, weight_decay=wd)
scheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_period,lr_decay)
# 这个就可以访问trainer中的lr并修改了
num_batches, timer = len(train_iter), d2l.Timer()
legend = ['train loss', 'train acc']
if valid_iter is not None:
legend.append('valid acc')
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],legend=legend)
net = nn.DataParallel(net, device_ids=devices).to(devices[0])
for epoch in range(num_epochs):
net.train()
metric = d2l.Accumulator(3)
for i, (features, labels) in enumerate(train_iter):
timer.start()
l, acc = d2l.train_batch_ch13(net, features, labels,
loss, trainer, devices)
metric.add(l, acc, labels.shape[0])
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[2], metric[1] / metric[2],
None))
if valid_iter is not None:
valid_acc = d2l.evaluate_accuracy_gpu(net, valid_iter)
animator.add(epoch + 1, (None, None, valid_acc))
scheduler.step() # 更新学习率
print("第{}个epoch已更新完成!".format(epoch+1))
measures = (f'train loss {metric[0] / metric[2]:.3f}, '
f'train acc {metric[1] / metric[2]:.3f}')
if valid_iter is not None:
measures += f', valid acc {valid_acc:.3f}'
print(measures + f'\n{metric[2] * num_epochs / timer.sum():.1f}'
f' examples/sec on {str(devices)}')
if __name__ == '__main__':
labels = read_csv_labels(os.path.join(data_dir, 'trainLabels.csv'))
print("训练样本数目为:\t", len(labels))
print("类别数目为:\t", len(set(labels.values())))
batch_size = 32 if demo else 128
valid_ratio = 0.1
reorg_cifar10_data(data_dir, valid_ratio)
# 下面做图像的增广
transform_train = torchvision.transforms.Compose(
[torchvision.transforms.Resize(40), # 因为原尺寸32,加大到40后再随机裁剪32的大小
torchvision.transforms.RandomResizedCrop(32, scale=(0.64,1.0), ratio=(1.0,1.0)),
# 裁剪后生成一个面积为原来0.64到1倍大小的正方形(ratio保持不变就是原来的比例)
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.4914, 0.4822,0.4465],[0.2023,0.1994,0.2010])
# 这是imageNet数据集三个通道的均值和方差
])
transform_test = torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010])
])
train_ds, train_valid_ds = [torchvision.datasets.ImageFolder(
os.path.join(data_dir, "train_valid_test",folder),
transform=transform_train) for folder in ['train','train_valid']]
valid_ds, test_ds = [torchvision.datasets.ImageFolder(
os.path.join(data_dir, "train_valid_test",folder),
transform=transform_test) for folder in ['valid','test']]
train_iter, train_valid_iter = [DataLoader(dataset, batch_size, shuffle=True, drop_last=True)
for dataset in (train_ds, train_valid_ds)] # shuffle随机打乱
valid_iter = DataLoader(valid_ds, batch_size, shuffle=False, drop_last=True)
test_iter = DataLoader(test_ds, batch_size, shuffle=False, drop_last=False)
loss = nn.CrossEntropyLoss(reduction='none')
devices, num_epochs, lr,wd = d2l.try_all_gpus(), 20, 5e-4, 5e-4
lr_period, lr_decay, net = 4, 0.9, get_net()
train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period, lr_decay)
plt.show()
# 训练完,前面是根据验证集不断调整参数,调整好了现在要将验证集加入然后重新按照刚才的参数训练来预测
net, preds = get_net(), []
train(net, train_valid_iter, None, num_epochs, lr, wd, devices, lr_period, lr_decay)
plt.show()
for X,_ in test_iter:
y_hat = net(X.to(devices[0]))
preds.extend(y_hat.argmax(dim=1).type(torch.int32).cpu().numpy())
sorted_ids = list(range(1,len(test_ds) + 1))
sorted_ids.sort(key=lambda x:str(x))
df = pd.DataFrame({'id':sorted_ids,"label":preds})
df['label'] = df['label'].apply(lambda x : train_valid_ds.classes[x])
df.to_csv("submission_cifar10.csv",index=False)
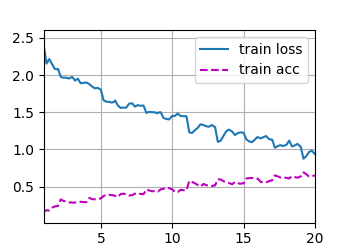
训练结果为:
train loss 1.088, train acc 0.609, valid acc 0.391
482.5 examples/sec on [device(type='cuda', index=0)]
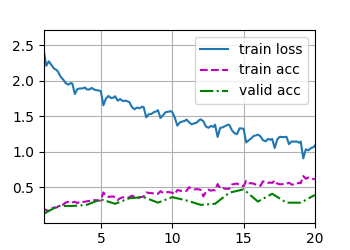
train loss 0.936, train acc 0.653
521.7 examples/sec on [device(type='cuda', index=0)]
实战Kaggle比赛:狗的品种识别
import os
import torch
import torchvision
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
# @save
from torch.utils.data import DataLoader
d2l.DATA_HUB['dog_tiny'] = (d2l.DATA_URL + 'kaggle_dog_tiny.zip',
'0cb91d09b814ecdc07b50f31f8dcad3e81d6a86d')
# 如果你使用Kaggle比赛的完整数据集,请将下面的变量更改为False
demo = True
if demo:
data_dir = d2l.download_extract('dog_tiny')
else:
data_dir = os.path.join('dataset', 'dog-breed-identification')
# 这里同样是整理数据集,将数据集按照标签分类到对应的文件夹中
def reorg_dog_data(data_dir, valid_ratio):
labels = d2l.read_csv_labels(os.path.join(data_dir, 'labels.csv'))
d2l.reorg_train_valid(data_dir, labels, valid_ratio) # 这个函数在上个实战中已经实现过
d2l.reorg_test(data_dir) # 测试集也是一样
# 加载预训练好的模型
def get_net(devices):
finetune_net = nn.Sequential() # 一开始是空的
finetune_net.features = torchvision.models.resnet34(pretrained=True) # 新增一个名为特征的Sequential
# 其内容就是resnet34的整个模型
# 定义一个新的输出网络,共有120个输出类别,因为原始的resnet34输出为1000,因此需要从1000开始
finetune_net.output_new = nn.Sequential(nn.Linear(1000, 256), nn.ReLU(), nn.Linear(256, 120))
# 将模型参数分配给用于计算的CPU或GPU
finetune_net = finetune_net.to(devices[0])
# 特征提取部分不更新,因为数据集是imageNet的子集
for param in finetune_net.features.parameters():
param.requires_grad = False
return finetune_net
# 用来计算损失
def evaluate_loss(data_iter, net, devices):
l_sum, n = 0.0, 0
for features, labels in data_iter:
features, labels = features.to(devices[0]), labels.to(devices[0])
outputs = net(features)
l = loss(outputs, labels)
l_sum += l.sum()
n += labels.numel()
return (l_sum / n).to('cpu')
# 定义训练函数
def train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period,
lr_decay):
# 只训练小型自定义输出网络
net = nn.DataParallel(net, device_ids=devices).to(devices[0]) # 多GPU
trainer = torch.optim.SGD((param for param in net.parameters() # 这里是必须requires_grad为True才训练
if param.requires_grad), lr=lr, # 也就只有我们刚才新增的MLP
momentum=0.9, weight_decay=wd)
scheduler = torch.optim.lr_scheduler.StepLR(trainer, lr_period, lr_decay)
num_batches, timer = len(train_iter), d2l.Timer()
legend = ['train loss']
if valid_iter is not None:
legend.append('valid loss')
animator = d2l.Animator(xlabel='epoch', xlim=[1, num_epochs],
legend=legend)
for epoch in range(num_epochs):
metric = d2l.Accumulator(2)
for i, (features, labels) in enumerate(train_iter):
timer.start()
features, labels = features.to(devices[0]), labels.to(devices[0])
trainer.zero_grad()
output = net(features)
l = loss(output, labels).sum()
l.backward()
trainer.step()
metric.add(l, labels.shape[0])
timer.stop()
if (i + 1) % (num_batches // 5) == 0 or i == num_batches - 1:
animator.add(epoch + (i + 1) / num_batches,
(metric[0] / metric[1], None))
measures = f'train loss {metric[0] / metric[1]:.3f}'
if valid_iter is not None:
valid_loss = evaluate_loss(valid_iter, net, devices)
animator.add(epoch + 1, (None, valid_loss.detach().cpu()))
scheduler.step()
if valid_iter is not None:
measures += f', valid loss {valid_loss:.3f}'
print(measures + f'\n{metric[1] * num_epochs / timer.sum():.1f}'
f' examples/sec on {str(devices)}')
if __name__ == '__main__':
batch_size = 32 if demo else 128
valid_ratio = 0.1
reorg_dog_data(data_dir, valid_ratio)
# 进行图像增广处理
transform_train = torchvision.transforms.Compose([
torchvision.transforms.RandomResizedCrop(224, scale=(0.08, 1.0), ratio=(3.0 / 4.0, 4.0 / 3.0)),
# 随机裁剪图像,面积为原来的0.08到1之间,并且高宽比控制在3/4到4/3之间,然后缩放到224的大小
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4),
# 随机改变亮度、对比度和饱和度
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
transform_test = torchvision.transforms.Compose([
torchvision.transforms.Resize(256), # 先缩放的256
# 从图像中心裁切224x224大小的图片
torchvision.transforms.CenterCrop(224),
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
# 读取数据集
train_ds, train_valid_ds = [torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder),
transform=transform_train) for folder in ['train', 'train_valid']]
valid_ds, test_ds = [torchvision.datasets.ImageFolder(
os.path.join(data_dir, 'train_valid_test', folder),
transform=transform_test) for folder in ['valid', 'test']]
# 创建数据迭代器
train_iter, train_valid_iter = [DataLoader(dataset, batch_size, shuffle=True, drop_last=True)
for dataset in (train_ds, train_valid_ds)]
valid_iter = DataLoader(valid_ds, batch_size, shuffle=False, drop_last=True)
test_iter = DataLoader(test_ds, batch_size, shuffle=False, drop_last=False)
# 损失函数
loss = nn.CrossEntropyLoss(reduction='none')
# 设置参数
devices, num_epochs, lr, wd = d2l.try_all_gpus(), 50, 1e-2, 1e-4
lr_period, lr_decay, net = 10, 0.1, get_net(devices)
train(net, train_iter, valid_iter, num_epochs, lr, wd, devices, lr_period, lr_decay)
plt.show()
# 预测模型
net = get_net(devices)
train(net, train_valid_iter, None, num_epochs, lr, wd, devices, lr_period,
lr_decay)
preds = []
for data, label in test_iter:
output = torch.nn.functional.softmax(net(data.to(devices[0])), dim=0)
# 这里并不是将最高概率的取出,而是经过softmax将所有概率都放入
preds.extend(output.cpu().detach().numpy())
ids = sorted(os.listdir(os.path.join(data_dir, 'train_valid_test', 'test', 'unknown')))
with open('submission.csv_dog_all', 'w') as f:
f.write('id,' + ','.join(train_valid_ds.classes) + '\n')
for i, output in zip(ids, preds):
f.write(i.split('.')[0] + ',' + ','.join([str(num) for num in output]) + '\n')
目标检测
目标检测是对图片或者视频中出现的目标物体进行圈出,具体的边缘框的表达方式有多种,最典型是以下两种:
- (左上x,左上y,右下x,右下y)
- (左上x,左上y,宽,高)
import torch
from d2l import torch as d2l
from matplotlib import pyplot as plt
d2l.set_figsize()
img = d2l.plt.imread("catdog.jpg")
d2l.plt.imshow(img)
#plt.show()
# @save
def box_corner_to_center(boxes):
# 该函数将框的表示从两个角转换为(中间,宽度,高度)的表示方法
x1, y1, x2, y2 = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
cx = (x1 + x2) / 2 # 中心
cy = (y1 + y2) / 2
w = x2 - x1 # 宽度
h = y2 - y1 # 高度
boxes = torch.stack((cx, cy, w, h), axis=-1) # 沿着一个新的维度对张量进行拼接,需要张量都是相同的形状
return boxes
#@save
def box_center_to_corner(boxes):
"""从(中间,宽度,高度)转换到(左上,右下)"""
cx, cy, w, h = boxes[:, 0], boxes[:, 1], boxes[:, 2], boxes[:, 3]
x1 = cx - 0.5 * w
y1 = cy - 0.5 * h
x2 = cx + 0.5 * w
y2 = cy + 0.5 * h
boxes = torch.stack((x1, y1, x2, y2), axis=-1)
return boxes
dog_bbox, cat_bbox = [60.0, 45.0, 378.0, 516.0], [400.0, 112.0, 655.0, 493.0]
boxes = torch.tensor((dog_bbox, cat_bbox))
print(box_center_to_corner(box_corner_to_center(boxes)) == boxes)
#@save
def bbox_to_rect(bbox, color):
# 将边界框(左上x,左上y,右下x,右下y)格式转换成matplotlib格式:
# ((左上x,左上y),宽,高)
return d2l.plt.Rectangle(xy=(bbox[0], bbox[1]), width=bbox[2]-bbox[0], height=bbox[3]-bbox[1],
fill=False, edgecolor=color, linewidth=2)
fig = d2l.plt.imshow(img)
fig.axes.add_patch(bbox_to_rect(dog_bbox,'blue'))
fig.axes.add_patch(bbox_to_rect(cat_bbox,'red'))
plt.show()
小结:
- 目标检测不仅可以识别图像中所有感兴趣的物体,还能够识别它们的位置,该位置通常由矩形边界框表示
- 常用表示方法为(中间,宽度,高度)和(左上,右下)
目标检测数据集
import os
import pandas as pd
import torch
import torchvision
from d2l import torch as d2l
#@save
from matplotlib import pyplot as plt
from torch.utils.data import DataLoader
d2l.DATA_HUB['banana-detection'] = (
d2l.DATA_URL + 'banana-detection.zip',
'5de26c8fce5ccdea9f91267273464dc968d20d72')
#@save
def read_data_bananas(is_train=True):
# 读取香蕉检测数据集中的图像和标签
data_dir = d2l.download_extract('banana-detection')
csv_fname = os.path.join(data_dir, 'bananas_train' if is_train else 'bananas_val','label.csv')
csv_data = pd.read_csv(csv_fname)
print(csv_data[1:5])
csv_data = csv_data.set_index('img_name') # 将这一列作为索引标签号
print(csv_data[1:5])
images, targets = [],[]
for img_name ,target in csv_data.iterrows():
images.append(torchvision.io.read_image(os.path.join(data_dir,'bananas_train' if is_train else
'bananas_val','images',f'{img_name}')))
# 这里的target包含(类别,左上角x,左上角y,右下角x,右下角y),
# 其中所有图像都具有相同的香蕉类(索引为0)
targets.append(list(target))
return images, torch.tensor(targets).unsqueeze(1) / 256
#@save
class BananasDataset(torch.utils.data.Dataset):
"""一个用于加载香蕉检测数据集的自定义数据集"""
def __init__(self, is_train):
self.features, self.labels = read_data_bananas(is_train)
print('read ' + str(len(self.features)) + (f' training examples' if
is_train else f' validation examples'))
def __getitem__(self, idx):
return self.features[idx].float(), self.labels[idx]
def __len__(self):
return len(self.features)
#@save
def load_data_bananas(batch_size):
"""加载香蕉检测数据集"""
train_iter = DataLoader(BananasDataset(is_train=True),
batch_size, shuffle=True)
val_iter = DataLoader(BananasDataset(is_train=False),
batch_size)
return train_iter, val_iter
batch_size, edge_size = 32, 256
train_iter, _ = load_data_bananas(batch_size)
batch = next(iter(train_iter))
# 是一个列表,两个元素都是一个tensor,然后第一个tensor记录图片的信息(批次,通道数目,高,宽)
# 第二个是记录对应图片中那些矩形框的位置,(批次,矩形框数目,记录位置的维度),第三个是一个长度为5的数组
# 该数组的第一个元素如果为-1,就代表这个矩形框是非法的,因为我们必须保持矩形框数目相同,而有的图片中矩形框数据不一样
# 因此以-1来填充保持大小一样,后面四个元素就记录这个矩形框的位置了
print("batch[0].size:\t",batch[0].shape)
print("batch[1].size:\t",batch[1].shape)
imgs = (batch[0][0:10].permute(0,2,3,1)) / 255 # 将维度转换为(批次,高,宽,通道数目)
axes = d2l.show_images(imgs, 2,5,scale = 2)
for ax, label in zip(axes, batch[1][0:10]):
d2l.show_bboxes(ax, [label[0][1:5] * edge_size], colors=['w'])
plt.show()

其中我对部分地方进行了输出,方便理解读入的数据的形式:
img_name label xmin ymin xmax ymax
1 1.png 0 68 175 118 223
2 2.png 0 163 173 218 239
3 3.png 0 48 157 84 201
4 4.png 0 32 34 90 86
label xmin ymin xmax ymax
img_name
1.png 0 68 175 118 223
2.png 0 163 173 218 239
3.png 0 48 157 84 201
4.png 0 32 34 90 86
锚框
目标检测算法通常会在输入图像中采样大量的区域,然后判断这些区域中是否包含我们感兴趣的目标,并调整目标边界从而更准确地预测目标的真实边框界。
具体的流程为:
- 提出多个被称为锚框的区域(边缘框)
- 预测每个锚框里面是否含有关注的物体
- 如果是,预测从这个锚框到真实边缘框的偏移
那么上述过程就存在许多可以进行细究的点。
首先是如何生成多个锚框。
假设输入图像的高度为h,宽度为w。我们以图像的每个像素为中心生成不同形状的锚框:缩放比为\(s\in (0,1]\),宽高比为\(r>0\),那么锚框的宽度和高度分别是\(ws\sqrt{r}、hs/\sqrt{r}\)表达。
那么如果考虑每个像素点都随机应用所有\(s_1,...,s_n\)和\(r_1,...,r_m\)的组合,这样复杂度为\(whnm\)太高了。因为只考虑:
因此复杂度为\(wh(n+m-1)\)。
接下来是计算锚框与真实边缘框的差距。
使用IoU交并比来计算两个框之间的相似度:
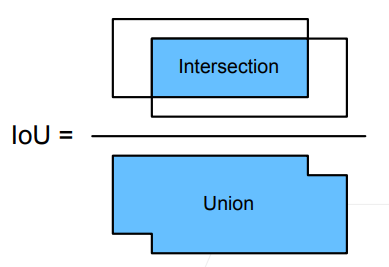
接下来是在训练数据中标注出锚框。
因为在训练集中,目标检测任务和图片分类任务不同,可以认为每个锚框是一个训练样本。而为了训练这个模型,我们需要知道每个锚框的类别和偏移量标签,前者是这个锚框是框住了哪一个对象,后者是该锚框相对于该对象的真实边缘框的偏移量。
那么我们生成了很多的锚框,可能这会导致每个都去计算的话计算量太大。那么将真实边界框进行分配,减少计算量的算法为:
- 给定图像,假设真实边框为\(B_1,...,B_{n_b}\),生成的锚框为\(A_1,...,A_{n_a}\),其中\(n_b\leq n_a\)。定义一个矩阵为\(\pmb{X}\in R^{n_a\times n_b}\),其中第i行第j列的元素为锚框\(A_i\)和真实边框\(B_j\)之间的IoU。
- 不断在矩阵中寻找最大值,找到后就将其对应的列和行删除,得到缩小的矩阵。直到所有的列均删除,也就是每个真实边缘框都有对应的最大IoU的锚框匹配。最后剩下\(n_a-n_b\)个锚框。
- 对于剩下的锚框,对于\(A_i\),找到它和所有真实边缘框的IoU中最大的那个值,如果值大于阈值,就可以将该真实边缘框分配给\(A_i\)。完成
标记类别和偏移量。
假设锚框A和其分配到的真实边缘框B,中心坐标分别为\((x_a,y_a)、(x_b,y_b)\),宽度分别为\(w_a、w_b\),高度分别为\(h_a、h_b\),那么将A的偏移量标记为:
其中\(\mu和\sigma\)取常用值。
使用非极大值抑制(NMS)输出
经过上述处理,我们剩下的锚框中仍然可能是一个真实边缘框对应多个锚框,那么可能这些锚框是很相似的。NMS的处理就是将这些对应同一个真实边缘框的多个锚框,它们分别对自己框内的物体做预测,得到预测为真实边缘框内物体的置信度,然后选择最大的置信度对应的锚框\(A_i\),然后将其他与\(A_i\)的IoU值大于阈值的锚框删除掉。重复上述过程指导所有锚框要么被选中,要么被去掉。
区域卷积神经网络(R-CNN)系列
首先是最原始的R-CNN。
简而言之,R-CNN首先从输入图像中选取若干提议区域(锚框就是一种,可理解为选取锚框),并标注它们的类别和边界框(如与真实框的偏移量),然后用卷积神经网络对每个提议区域进行前向传播以抽取其特征,然后用每个提议区域的特征来预测类别和边界框。
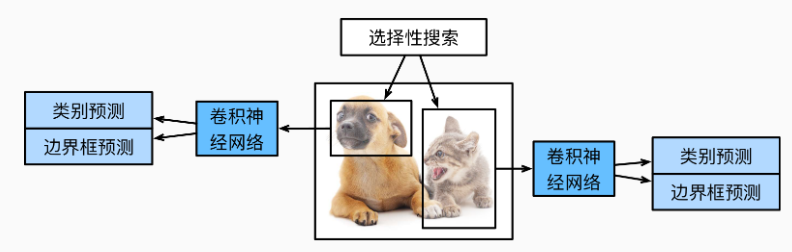
具体的步骤为:
- 对输入图像使用选择性搜索来选取多个高质量的提议区域(锚框)。这些锚框通常是在多个尺度下选取的,具有不同的大小和形状。每个提议区域都将被标注类别和真实边界框。
- 选择一个预训练的卷积神经网络,并将其在输出层之前截断。将每个提议区域变形为网络需要的输入尺寸,并通过前向传播输出抽取的提议区域特征。
- 将每个提议区域的特征连同其标注的类别作为一个样本。训练多个支持向量机对目标分类,其中每个支持向量机用来判断样本是否属于某一个类别。
- 将每个提议区域的特征连同其标注的边界框作为一个样本,训练线性回归模型来预测真实边界框。
R-CNN模型通过预训练的卷积神经网络有效地抽取了图像特征,但是速度很慢,原因在于对每个提议区域都进行了卷积的前向传播。
Fast R-CNN
R-CNN的主要性能瓶颈在于,对每个提议区域,卷积神经网络的前向传播是独立的,而没有共享计算。 由于这些区域通常有重叠,独立的特征抽取会导致重复的计算。 Fast R-CNN对R-CNN的主要改进之一,是仅在整张图象上执行卷积神经网络的前向传播。

具体步骤为:
- 对整张图像进行卷积神经网络的特征提取,并且该网络也会参与训练。设CNN的输出为\(1\times c \times h_1 \times w_1\)
- 假设选择性搜索生成了\(n\)个提议区域,那么这些区域就按照在原始图像中位置的比例,去CNN输出的特征图像中相同位置的比例,标出形状各异的兴趣区域。
- 然后这些形状各异的兴趣区域需要经过兴趣区域池化层RoI,它可以对每个区域的输出形状直接指定。其将卷积神经网络的输出和提议区域作为输入,输出连结后的各个提议区域抽取的特征,形状为\(n \times c \times h_2 \times w_2\)
- 通过全连接层将输出形状变换为\(n\times d\),d取决于模型设计
- 预测这n个提议区域中每个区域的类别和边界框。在预测时将全连接层的输出分类转换为形状为\(n\times q\)(q为类别数目)的输出和形状为\(n \times 4\)的输出(真实标记框需要用4个数字表达)的输出
RoI的特点在于可以自己指定输出的形状。例如指定输出为\(h_2、w_2\),对于任何形状为\(h \times w\)的兴趣区域窗口,该窗口会被划分为\(h_2 \times w_2\)个子窗口网络,其中每个子窗口大小约为\((h/h_2)\times (w/w_2)\)。
Faster R-CNN
为了较精确地检测目标结果,Fast R-CNN模型通常需要在选择性搜索中生成大量的提议区域。而Faster R-CNN提出用区域提议网络(神经网络)来代替选择性搜索,从而减少提议区域的生成数量。
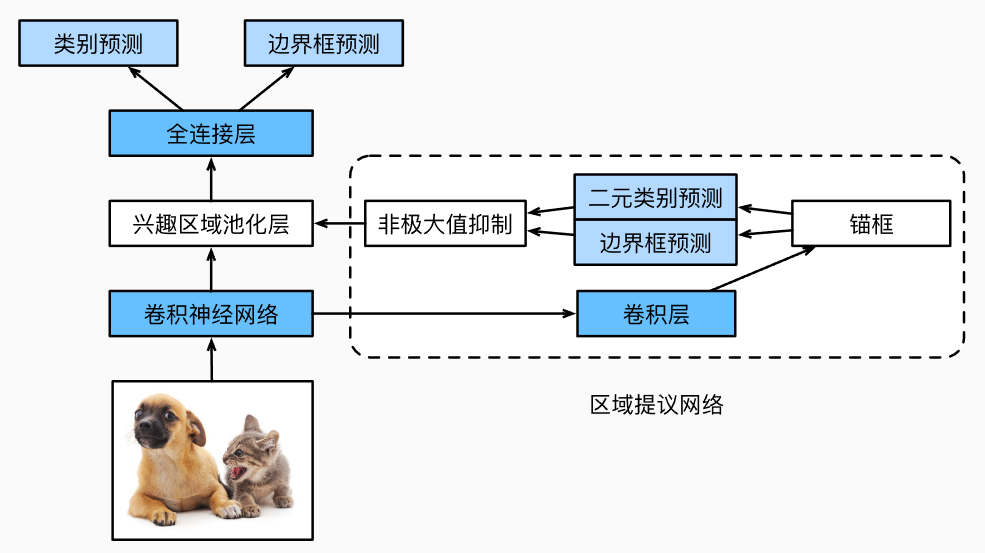
除了区域提议网络外,其他都与Fast R-CNN相同,因此这里只介绍区域提议网络流程:
- 使用padding=1的\(3\times 3\) 的卷积层将卷积神经网络的输出进行处理,设输出通道为c。因此卷积神经网络为图像抽取的特征图中的每个单元均得到一个长度为c的新特征(因为该卷积层不会改变高宽,因此相当于每个特征图中的像素点都得到一个长度为c的新特征)
- 以特征图的每个像素为中心,生成多个不同大小和高宽比的锚框并标注
- 使用锚框中心像素的长度为c的特征,分别去预测该锚框的二元类别(是目标还是背景)和边界框
- 使用非极大值抑制,从预测类别为目标的预测边界框中移除相似的结果。最终输出的预测边界框即是兴趣区域汇聚层所需的提议区域。
值得注意的是,区域提议网络也是跟模型一起训练的。
Mask R-CNN
如果在训练集中还标注了每个目标在图像上的像素级位置,那么Mask R-CNN能够有效地利用这些详尽的标注信息进一步提升目标检测的精度。
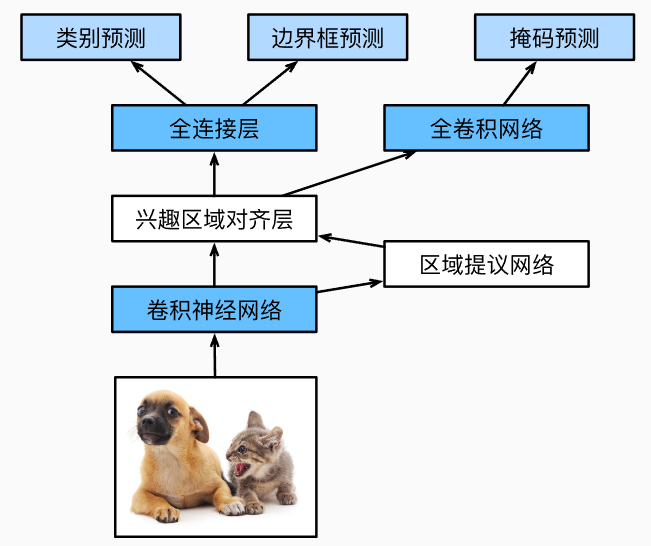
它首先是将RoI层转换为兴趣区域对齐层,因为之间划分的时候像素会取整,这样会导致偏移,这在以像素为单元的Mask R-CNN中行不通,因此相当于它将不能够平分的像素,进行细化,例如\(3\times 3\)要输出\(2\times 2\),那么最中间的像素点就需要继续划分成4个小像素点,可以采用各种方法去分配取值。另外一个部分是掩码预测将在后续补充。
小结:
- R-CNN对图像选取若干提议区域,使用卷积神经网络对每个提议区域执行前向传播以抽取其特征,然后再用这些特征来预测提议区域的类别和边界框。
- Fast R-CNN对R-CNN的一个主要改进:只对整个图像做卷积神经网络的前向传播。它还引入了兴趣区域汇聚层,从而为具有不同形状的兴趣区域抽取相同形状的特征。
- Faster R-CNN将Fast R-CNN中使用的选择性搜索替换为参与训练的区域提议网络,这样后者可以在减少提议区域数量的情况下仍保证目标检测的精度。
- Mask R-CNN在Faster R-CNN的基础上引入了一个全卷积网络,从而借助目标的像素级位置进一步提升目标检测的精度。
单发多框检测(SSD)
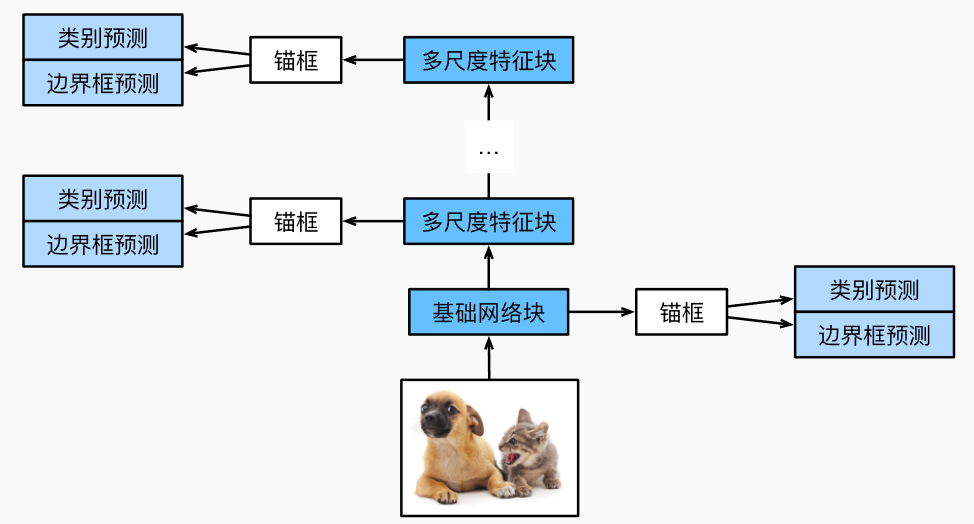
如上图所示,SSD主要由基础网络块,以及几个多尺度特征块构成。
基础网络块的主要作用是从输入图像中提取特征,并且通常让其输出的高和宽比较大,这样它的输出用于去生成锚框时,就可以用来标注一些原图中尺寸比较小的物体。然后多尺度特征块将上一层提供的特征图的高和宽减小(如减半)这样相同的锚框大小,就具有更大的感受野,因此后面的锚框将多用于检测原图中较大的物体。
这里稍微补充一下YOLO(you only look ones你只看一次)的思想,因为SSD中锚框大量重叠,因此浪费了很多计算。那么YOLO将图片均匀分成\(S\times S\)个锚框,每个锚框就需要预测图片中已知的B个边缘框,这样可以减小锚框数量。

小结:
- 单发多框检测是一种多尺度目标检测模型。基于基础网络块和各个多尺度特征块,单发多框检测生成不同数量和不同大小的锚框,并通过预测这些锚框的类别和偏移量检测不同大小的目标。
- 在训练单发多框检测模型时,损失函数是根据锚框的类别和偏移量的预测及标注值计算得出的。
循环神经网络
序列模型
在现实生活中很多数据都是有时序结构的,那么对于时序结构的研究也是必要的。
一般对于时序结构而言,在第t个时间点的观察值\(x_t\)是与前面t-1个时刻的观察值有关的,但反过来在现实中不一定可行,即:
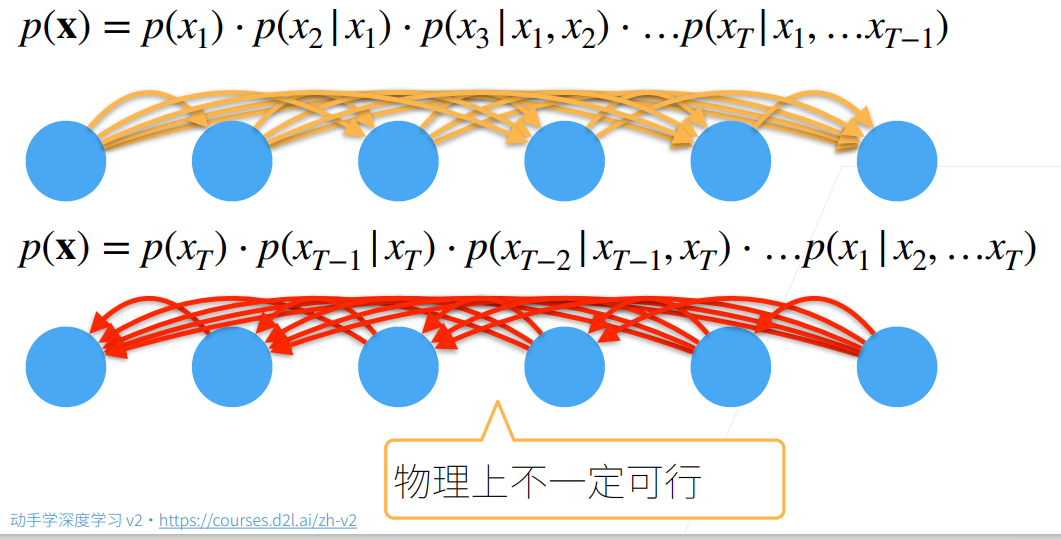
那么我们对条件概率进行建模,即:

那么如果能够学习到模型f,及概率计算方法p,就可以进行预测了。
那么针对这个问题,有两种比较常见的研究方法:
马尔科夫假设:
因为前面我们的叙述是当前时刻的观察值跟前面所有时刻的观察值相关,那么马尔科夫假设就是假定当前数据只和过去\(\tau\)个数据点相关,这样函数f的输入就从不定长转换为了定长,因此就方便很多:
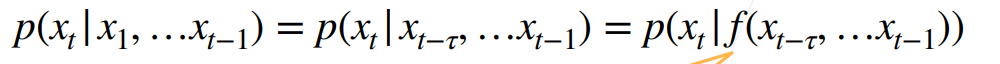
那么就可以用一个简单的MLP来实现。
潜变量模型:
即引入潜变量\(h_t\)来表示过去信息\(h_t=f(x_1,...,x_{t-1})\),那么\(x_t=p(x_t \mid h_t)\):
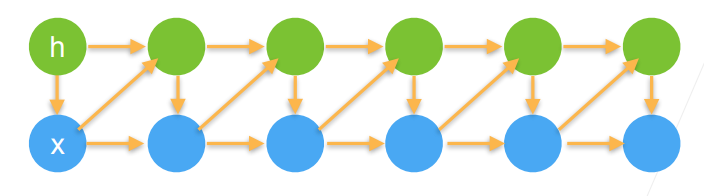
具体老师通过了一个小例子来为我们展示了训练以及预测:
import torch
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
T = 1000 # 总共产生1000个点
time = torch.arange(1, T + 1, dtype=torch.float32)
x = torch.sin(0.01 * time) + torch.normal(0, 0.2, (T,)) # 加上噪音
# d2l.plot(time, [x], 'time', 'x', xlim=[1, 1000], figsize=(6, 3))
tau = 4
features = torch.zeros((T - tau, tau)) # 因为前tau个之间没有tau个可以作为输入
for i in range(tau):
features[:, i] = x[i: T - tau + i] # 例如第0列就是每个数据的前面第4个
labels = x[tau:].reshape((-1, 1)) # 从第4个往后都是前面tau个造成的输出了
batch_size, n_train = 16, 600
# 用前600个样本来训练,然后后面400个完成预测任务
train_iter = d2l.load_array((features[:n_train], labels[:n_train]),
batch_size, is_train=True)
# 初始化网络权重的函数
def init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
# 一个简单的多层感知机
def get_net():
net = nn.Sequential(nn.Linear(4, 10),
nn.ReLU(),
nn.Linear(10, 1))
net.apply(init_weights)
return net
loss = nn.MSELoss(reduction='none')
def train(net, train_iter, loss, epochs, lr):
trainer = torch.optim.Adam(net.parameters(), lr)
for epoch in range(epochs):
for X, y in train_iter:
trainer.zero_grad()
l = loss(net(X), y)
l.sum().backward()
trainer.step()
print(f'epoch {epoch + 1}, '
f'loss: {d2l.evaluate_loss(net, train_iter, loss):f}')
net = get_net()
train(net, train_iter, loss, 5, 0.01)
onestep_preds = net(features)
# 单步预测,就是每次都给定4个真实值来让你预测下一个
# 注意这里采用detach是将本来含有梯度的变量,复制一个不含有梯度,不过都是指向同一个数值
# 不含有梯度是因为画图不需要计算梯度,防止在画图中发生计算过程而改变梯度
d2l.plot([time, time[tau:]],
[x.detach().numpy(), onestep_preds.detach().numpy()], 'time',
'x', legend=['data', '1-step preds'], xlim=[1, 1000],figsize=(6, 3))
plt.show()
# 多步预测,只知道600个,然后可以结合真实数据预测到604个,那么后面都是靠预测值来预测
multistep_preds = torch.zeros(T)
multistep_preds[: n_train + tau] = x[: n_train + tau]
for i in range(n_train + tau, T):
multistep_preds[i] = net(multistep_preds[i - tau:i].reshape((1, -1)))
d2l.plot([time, time[tau:], time[n_train + tau:]],
[x.detach().numpy(), onestep_preds.detach().numpy(),
multistep_preds[n_train + tau:].detach().numpy()], 'time',
'x', legend=['data', '1-step preds', 'multistep preds'],
xlim=[1, 1000], figsize=(6, 3))
plt.show()
max_steps = 64
features = torch.zeros((T - tau - max_steps + 1, tau + max_steps))
# 列i(i<tau)是来自x的观测,其时间步从(i)到(i+T-tau-max_steps+1)
for i in range(tau):
features[:, i] = x[i: i + T - tau - max_steps + 1]
# 列i(i>=tau)是来自(i-tau+1)步的预测,其时间步从(i)到(i+T-tau-max_steps+1)
for i in range(tau, tau + max_steps):
features[:, i] = net(features[:, i - tau:i]).reshape(-1)
steps = (1, 4, 16, 64)
d2l.plot([time[tau + i - 1: T - max_steps + i] for i in steps],
[features[:, (tau + i - 1)].detach().numpy() for i in steps], 'time', 'x',
legend=[f'{i}-step preds' for i in steps], xlim=[5, 1000],
figsize=(6, 3))
plt.show()
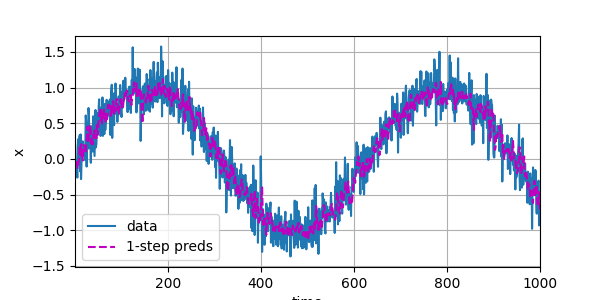
可以看到单步预测的结果还是很精确的。
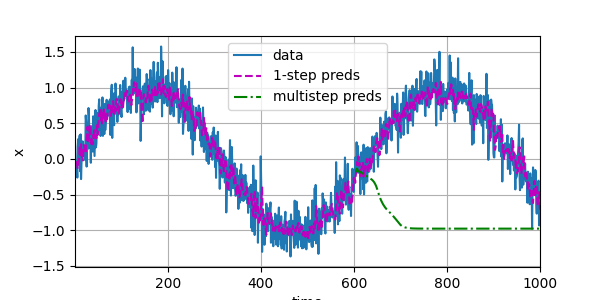
但是在多步预测时,我们如果只给前面600个数据点,然后让其预测后面400个,就结果差的很离谱
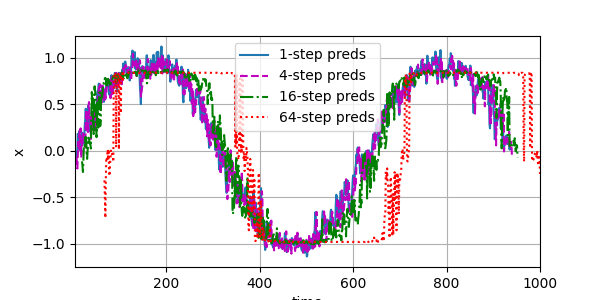
可以看到,多步预测为1,4,16的结果都还算可以,但是增加到64时就出现了明显的差异。
小结:
- 时序模型中,当前数据跟之前观察到的数据相关
- 自回归模型使用自身过去数据来预测未来
- 马尔科夫模型假设当前只跟最近少数数据相关,从而简化模型
- 潜变量模型使用潜变量来概括历史信息
文本预处理
该章节主要是介绍了对于一个简单文本文件的处理,生成可以用来使用的数据集
import collections
import re
from d2l import torch as d2l
# @save
d2l.DATA_HUB['time_machine'] = (d2l.DATA_URL + 'timemachine.txt',
'090b5e7e70c295757f55df93cb0a180b9691891a')
# 下载数据集
def read_time_machine():
with open(d2l.download('time_machine'), 'r') as f:
lines = f.readlines()
return [re.sub('[^A-Za-z]+', ' ', line).strip().lower() for line in lines]
# 就是将除了A-Z和a-z,还有空格,其他的符号都去掉,再去掉回车,再转成小写
lines = read_time_machine()
print(f'# 文本总行数: {len(lines)}')
print(lines[0])
print(lines[10])
def tokenize(lines, token='word'): # @save
if token == 'word':
return [line.split() for line in lines]
elif token == 'char':
return [list(line) for line in lines]
else:
print('错误:未知词元类型:' + token)
tokens = tokenize(lines)
for i in range(11):
print(tokens[i])
def count_corpus(tokens): # @save
"""统计词元的频率"""
# 这里的tokens是1D列表或2D列表
if len(tokens) == 0 or isinstance(tokens[0], list):
# 所有单词都展开成一个列表
tokens = [token for line in tokens for token in line]
return collections.Counter(tokens)
class Vocab:
def __init__(self, tokens=None, min_freq=0, reserved_tokens=None):
if tokens is None:
tokens = []
if reserved_tokens is None:
reserved_tokens = []
# 按照出现的频率来进行排序
counter = count_corpus(tokens)
self._token_freqs = sorted(counter.items(), key=lambda x: x[1],
reverse=True)
# 按照出现频率从大到小排序
# 未知词元索引在0,包括出现频率太少,还有句子起始和结尾的标志
self.idx_to_token = ['<unk>'] + reserved_tokens
self.token_to_idx = {token: idx for idx, token in enumerate(self.idx_to_token)}
for token, freq in self._token_freqs:
if freq < min_freq:
break
if token not in self.token_to_idx:
self.idx_to_token.append(token)
self.token_to_idx[token] = len(self.idx_to_token) - 1
# 不断添加进去词汇并建立和位置之间的索引关系
def __len__(self):
return len(self.idx_to_token)
@property
def unk(self): # 未知词元的索引为0,装饰器,可以直接self.unk,不用加括号
return 0
def __getitem__(self, tokens):
if not isinstance(tokens, (list, tuple)): # 如果是单个
return self.token_to_idx.get(tokens, self.unk)
return [self.__getitem__(token) for token in tokens] # 如果是多个
def to_tokens(self, indices):
if not isinstance(indices, (list, tuple)):
return self.idx_to_token[indices] # 从索引到单词
return [self.idx_to_token[index] for index in indices]
@property
def token_freqs(self):
return self._token_freqs
vocab = Vocab(tokens)
print(list(vocab.token_to_idx.items())[:10])
def load_corpus_time_machine(max_tokens=-1): # @save
"""返回时光机器数据集的词元索引列表和词表"""
lines = read_time_machine()
tokens = tokenize(lines, 'char')
vocab = Vocab(tokens)
# 因为时光机器数据集中的每个文本行不一定是一个句子或一个段落,
# 所以将所有文本行展平到一个列表中
corpus = [vocab[token] for line in tokens for token in line]
if max_tokens > 0:
corpus = corpus[:max_tokens]
return corpus, vocab
corpus, vocab = load_corpus_time_machine()
len(corpus), len(vocab)
语言模型和数据集
语言模型是指,给定文本序列\(x_1,...,x_T\),其目标是估计联合概率\(p(x_1,...,x_T)\),也就是该文本序列出现的概率。
那么假设序列长度为2,那我们可以使用计数的方法,简单计算为:
那么继续拓展序列长度也可以采用类似的计数方法。
但是如果序列长度太长,如果文本量不够大的情况下可能会出现\(n(x_1,...,x_T)\leq 1\)的情况,那么就可以用马尔科夫假设来缓解这个问题:
- 一元语法:\(p(x_1,x_2,x_3,x_4)=p(x_1)p(x_2)p(x_3)p(x_4)\)
- 二元语法:\(p(x_1,x_2,x_3,x_4)=p(x_1)p(x_2\mid x_1)p(x_3\mid x_2)p(x_4\mid x_3)\)
- 三元语法:\(p(x_1,x_2,x_3,x_4)=p(x_1)p(x_2\mid x_1)p(x_3\mid x_1,x_2)p(x_4\mid x_2,x_3)\)
代码为:
import random
import torch
from d2l import torch as d2l
from matplotlib import pyplot as plt
tokens = d2l.tokenize(d2l.read_time_machine())
# 因为每个文本行不一定是一个句子或一个段落,因此我们把所有文本行拼接到一起
corpus = [token for line in tokens for token in line]
vocab = d2l.Vocab(corpus) # 计算频率得到的词汇列表
freqs = [freq for token, freq in vocab.token_freqs] # 将频率变化画出来
d2l.plot(freqs, xlabel='token: x', ylabel='frequency: n(x)', xscale='log', yscale='log')
plt.show() # 以上这是单个单词的情况
# 我们来看看连续的两个单词和三个单词的情况,即二元语法和三元语法
bigram_tokens = [pair for pair in zip(corpus[:-1], corpus[1:])]
bigram_vocab = d2l.Vocab(bigram_tokens)
trigram_tokens = [triple for triple in zip(corpus[:-2], corpus[1:-1], corpus[2:])]
trigram_vocab = d2l.Vocab(trigram_tokens)
bigram_freqs = [freq for token, freq in bigram_vocab.token_freqs]
trigram_freqs = [freq for token, freq in trigram_vocab.token_freqs]
d2l.plot([freqs, bigram_freqs, trigram_freqs], xlabel='token: x',
ylabel='frequency: n(x)', xscale='log', yscale='log',
legend=['unigram', 'bigram', 'trigram'])
plt.show() # 画出来对比
# 下面我们对一个很长的文本序列,随机在上面采样得到我们指定长度的子序列,方便我们输入到模型中
def seq_data_iter_random(corpus, batch_size, num_steps): # @save
"""使用随机抽样生成一个小批量子序列"""
# 从随机偏移量开始对序列进行分区,随机范围包括num_steps-1
corpus = corpus[random.randint(0, num_steps - 1):]
# 因为长度为num_steps是肯定的,那我们如果每次都从0开始,那么例如2-7这种就得不到
# 因此每次都随机的初始点开始就可以保证我们能够采样得到不同的数据
# 减去1,是因为我们需要考虑标签
num_subseqs = (len(corpus) - 1) // num_steps
# 长度为num_steps的子序列的起始索引
initial_indices = list(range(0, num_subseqs * num_steps, num_steps))
# 在随机抽样的迭代过程中,
# 来自两个相邻的、随机的、小批量中的子序列不一定在原始序列上相邻
random.shuffle(initial_indices)
def data(pos):
# 返回从pos位置开始的长度为num_steps的序列
return corpus[pos: pos + num_steps]
num_batches = num_subseqs // batch_size
for i in range(0, batch_size * num_batches, batch_size):
# 在这里,initial_indices包含子序列的随机起始索引
initial_indices_per_batch = initial_indices[i: i + batch_size]
X = [data(j) for j in initial_indices_per_batch]
Y = [data(j + 1) for j in initial_indices_per_batch]
# 这里解释一下,一开始我认为应该输入序列x之后我们要输出x之后的下一个单词,因此认为y应该为长度为1
# 但是实际上在训练时我们并不是5个丢进去,然后生成1个出来
# 我们是丢进去第一个,然后生成第二个,然后结合1,2的真实标签,去预测第三个,以此类推
# 直到后面结合5个去预测第6个
yield torch.tensor(X), torch.tensor(Y)
# 这个函数是让相邻两个小批量中的子序列在原始序列上是相邻的
def seq_data_iter_sequential(corpus, batch_size, num_steps): # @save
"""使用顺序分区生成一个小批量子序列"""
# 从随机偏移量开始划分序列
offset = random.randint(0, num_steps)
num_tokens = ((len(corpus) - offset - 1) // batch_size) * batch_size
Xs = torch.tensor(corpus[offset: offset + num_tokens])
Ys = torch.tensor(corpus[offset + 1: offset + 1 + num_tokens])
Xs, Ys = Xs.reshape(batch_size, -1), Ys.reshape(batch_size, -1)
num_batches = Xs.shape[1] // num_steps
for i in range(0, num_steps * num_batches, num_steps):
X = Xs[:, i: i + num_steps]
Y = Ys[:, i: i + num_steps]
yield X, Y
class SeqDataLoader: # @save
"""加载序列数据的迭代器"""
def __init__(self, batch_size, num_steps, use_random_iter, max_tokens):
if use_random_iter:
self.data_iter_fn = d2l.seq_data_iter_random
else:
self.data_iter_fn = d2l.seq_data_iter_sequential
self.corpus, self.vocab = d2l.load_corpus_time_machine(max_tokens)
self.batch_size, self.num_steps = batch_size, num_steps
def __iter__(self):
return self.data_iter_fn(self.corpus, self.batch_size, self.num_steps)
# 封装,同时返回数据迭代器和词汇表
def load_data_time_machine(batch_size, num_steps, #@save
use_random_iter=False, max_tokens=10000):
"""返回时光机器数据集的迭代器和词表"""
data_iter = SeqDataLoader(
batch_size, num_steps, use_random_iter, max_tokens)
return data_iter, data_iter.vocab
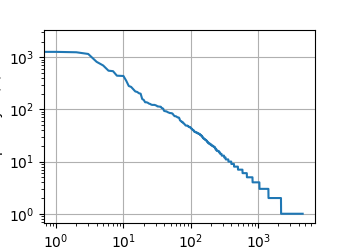
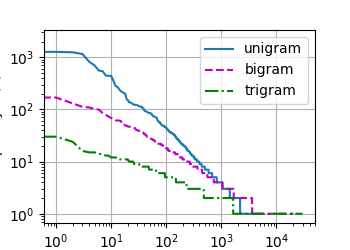
循环神经网络
其模型可以用下图来表示:
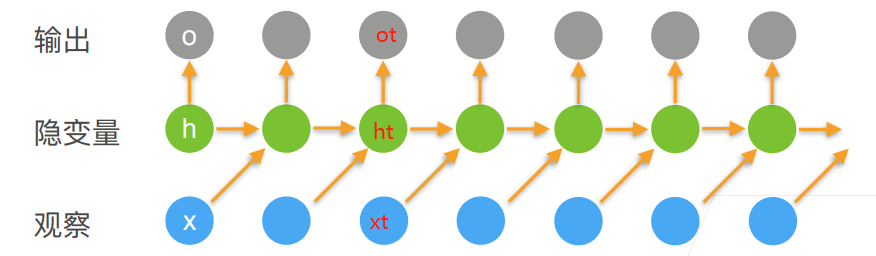
即中间的隐变量,是用来捕获并保留数序列直到其当前时间步的历史信息,其内部原理为:
- 更新隐藏状态:\(\pmb{h}_t=\phi(\pmb{W}_{hh}\pmb{h}_{t-1}+\pmb{W}_{hx}\pmb{x}_{t-1}+\pmb{b}_h)\)
- 输出:\(\pmb{o}_t=(\pmb{W}_{ho}\pmb{h}_t+\pmb{b}_o)\)
例如在\(t_1\)时刻输入\(x_1=\)"你",那么我们希望它能够能够计算得到\(h_1\)并得到输出\(o_1\)="好",然后接下来输入为\(x_2\)="好",我们希望\(o_2\)="世"等等。
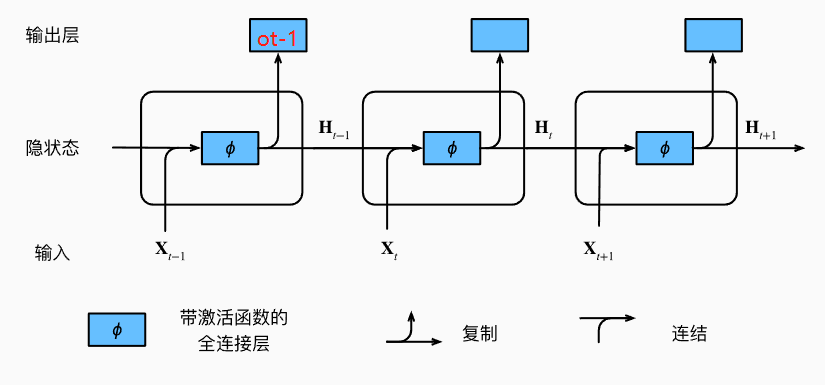
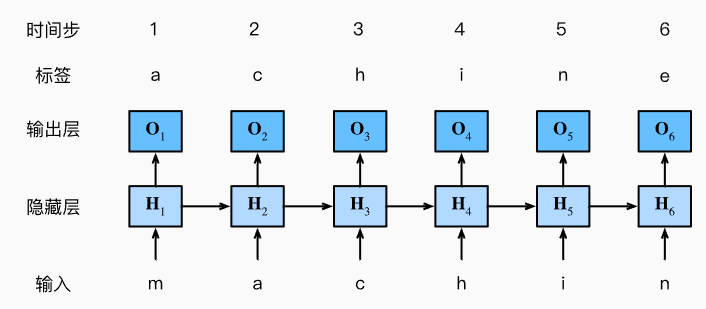
而衡量一个句子的质量,使用的是困惑度,其内部使用平均交叉熵来实现:
注意这里指的是根据现有已知的\(x_{1},...,x_{t-1}\)的情况(都是真实标签),我们能够预测出正确结果\(x_t\)的概率,那么如果每次都能够正确预测,就是p=1,那么log=0。而常见的是用\(\exp(\pi)\)来表达,因此1代表完美,无穷大为最差情况。
下一个知识点是梯度裁剪。
为了防止在迭代过程中计算T个时间步上的梯度时由于不断叠加而产生的数值不稳定的情况,而引入梯度裁剪:将所有层的梯度拼成一个向量g,那么如果该向量的L2范数超过了设定值\(\theta\)就将其进行修正,修正为\(\theta\)值,即:
RNN有非常多的应用场景:
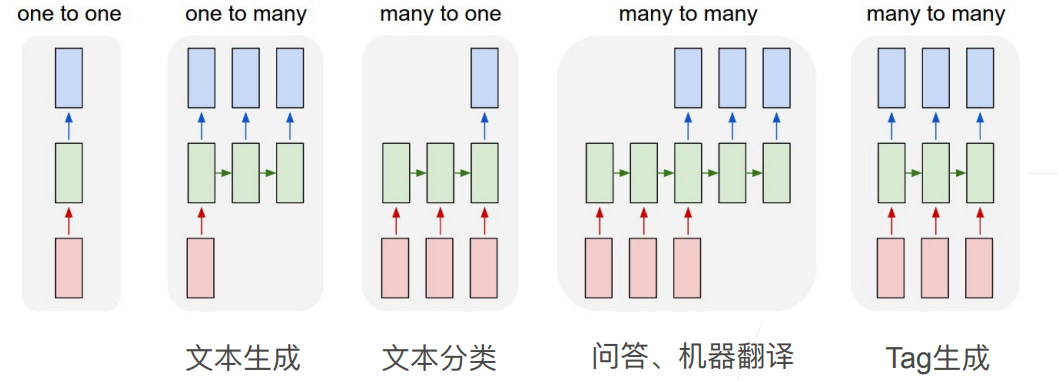
小结:
- RNN的输出取决于当前输入和前一时刻的隐变量
- 应用到语言模型中时,RNN根据当前词预测下一次时刻词
- 通常使用困惑度来衡量语言模型的好坏
RNN的从零开始实现
完成代码如下,需要注意的地方和讲解的地方都在注释中了。
import math
import torch
from matplotlib import pyplot as plt
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# 接下来引入独热编码的使用
# print(F.one_hot(torch.tensor([0, 2]), len(vocab)))
# 第一个参数0和2,代表我有两个编码,第一个编码在0的位置取1,第二个在2的位置取1,而长度就是第二个参数
# 而我们每次采样得到都是批量大小*时间步数,将每个取值(标量)转换为独热编码就是三维
# 批量大小*时间步数*独热编码,那为了方便,我们将维度转换为时间步数*批量大小再去变成独热编码
# 这样每个时刻的数值就连在一起了方便使用,如下:
X = torch.arange(10).reshape((2, 5)) # 批量为2,时间步长为5
# print(F.one_hot(X.T, 28).shape) # 输出为5,2,28
# 初始化模型参数
def get_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
# 因为输入是一个字符,就是1个独特编码,输出是预测的下一个字符也是独热编码,因此长度都是独特编码的长度
def normal(shape):
return torch.randn(size=shape, device=device) * 0.01
# 隐藏层参数
W_xh = normal((num_inputs, num_hiddens))
W_hh = normal((num_hiddens, num_hiddens))
b_h = torch.zeros(num_hiddens, device=device)
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True) # 我们后面要计算梯度
return params
# 下面是对RNN模型的定义
# 定义初始隐藏层的状态
def init_rnn_state(batch_size, num_hiddens, device):
# 这里用元组的原因是为了和后面LSTM统一
return (torch.zeros((batch_size, num_hiddens), device=device), )
def rnn(inputs, state, params):
# inputs的形状:(时间步数量,批量大小,词表大小)
W_xh, W_hh, b_h, W_hq, b_q = params
H, = state # 注意state是元组,第二个参数我们暂时不要,所有不用接受,但是要有逗号,否则H是元组
outputs = []
# X的形状:(批量大小,词表大小),这就是我们前面转置的原因,方便对同一时间步的输入做预测
for X in inputs:
H = torch.tanh(torch.mm(X, W_xh) + torch.mm(H, W_hh) + b_h) # 更新H
Y = torch.mm(H, W_hq) + b_q # 对Y做出预测
outputs.append(Y) # 这里outputs是数组,长度为时间步数量,每个元素都是批量大小*词表大小
# 那个下面对output进行堆叠,就是将时间步维度去掉,行数为(时间步*批量大小),列为词表大小
return torch.cat(outputs, dim=0), (H,)
# 用类来封装这些函数
class RNNModelScratch: #@save
"""从零开始实现的循环神经网络模型"""
def __init__(self, vocab_size, num_hiddens, device,get_params, init_state, forward_fn):
self.vocab_size, self.num_hiddens = vocab_size, num_hiddens
self.params = get_params(vocab_size, num_hiddens, device)
# 下面这两个其实是函数,第一个就是刚才初始化隐状态的函数,第二个就是rnn函数进行前向计算
self.init_state, self.forward_fn = init_state, forward_fn
def __call__(self, X, state):
X = F.one_hot(X.T, self.vocab_size).type(torch.float32)
return self.forward_fn(X, state, self.params) # 进行前向计算后返回
def begin_state(self, batch_size, device):
return self.init_state(batch_size, self.num_hiddens, device)
# 检查输出是否具有正确的形状
num_hiddens = 512
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,
init_rnn_state, rnn)
state = net.begin_state(X.shape[0], d2l.try_gpu())
Y, new_state = net(X.to(d2l.try_gpu()), state)
print(Y.shape, "\n",len(new_state),"\n", new_state[0].shape)
# 定义预测函数
def predict_ch8(prefix, num_preds, net, vocab, device): #@save
"""在prefix后面生成新字符"""
# prefix是用户提供的一个包含多个字符的字符串
state = net.begin_state(batch_size=1, device=device)
outputs = [vocab[prefix[0]]] # 将其第一个字符转换为数字放入其中
get_input = lambda: torch.tensor([outputs[-1]], device=device).reshape((1, 1))
# 上是一个匿名函数,可以在每次outputs更新后都调用outputs的最后一个元素
for y in prefix[1:]: # 预热期,此时不做预测,我们用这些字符不断来更新state
_, state = net(get_input(), state)
outputs.append(vocab[y]) # 将下一个待作为输入的转换为数字进入
for _ in range(num_preds): # 预测num_preds步
y, state = net(get_input(), state) # 预测并更新state
outputs.append(int(y.argmax(dim=1).reshape(1))) # 这就是将预测的放入,并作为下一次的输入
return ''.join([vocab.idx_to_token[i] for i in outputs]) # 拼接成字符
print(predict_ch8('time traveller ', 10, net, vocab, d2l.try_gpu())) # 看看效果
# 梯度裁剪
def grad_clipping(net, theta): #@save
"""裁剪梯度"""
if isinstance(net, nn.Module):
params = [p for p in net.parameters() if p.requires_grad]
# 取出那些需要更新的梯度
else:
params = net.params
norm = torch.sqrt(sum(torch.sum((p.grad ** 2)) for p in params))
if norm > theta:
for param in params:
param.grad[:] *= theta / norm # 对梯度进行修剪
# 训练模型
#@save
def train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter):
"""训练网络一个迭代周期(定义见第8章)"""
state, timer = None, d2l.Timer()
metric = d2l.Accumulator(2) # 训练损失之和,词元数量
for X, Y in train_iter:
if state is None or use_random_iter:
# 如果用的是打乱的,那么后一个小批量和前一个小批量的样本之间并不是连接在一起的
# 那么它们的隐变量不存在关系,所以必须初始化
# 在第一次迭代或使用随机抽样时初始化state
state = net.begin_state(batch_size=X.shape[0], device=device)
else: # 否则的话,我们就可以沿用上次计算完的隐变量,只不过detach是断掉链式求导,我们现在隐变量是数值了,跟之前的没有关系了
if isinstance(net, nn.Module) and not isinstance(state, tuple):
# state对于nn.GRU是个张量,这部分可以认为我们将state变换为常数
# 那么梯度更新时就不会再和前面批次的梯度进行相乘,这里就直接断掉梯度的链式法则了
state.detach_()
else:
# state对于nn.LSTM或对于我们从零开始实现的模型是个张量,这部分在后面有用
for s in state:
s.detach_()
y = Y.T.reshape(-1)
X, y = X.to(device), y.to(device)
y_hat, state = net(X, state)
l = loss(y_hat, y.long()).mean()
if isinstance(updater, torch.optim.Optimizer):
updater.zero_grad() # 清空梯度
l.backward()
grad_clipping(net, 1)
updater.step() # 更新参数
else:
l.backward()
grad_clipping(net, 1)
# 因为已经调用了mean函数
updater(batch_size=1)
metric.add(l * y.numel(), y.numel())
return math.exp(metric[0] / metric[1]), metric[1] / timer.stop()
#@save
def train_ch8(net, train_iter, vocab, lr, num_epochs, device,use_random_iter=False):
"""训练模型(定义见第8章)"""
loss = nn.CrossEntropyLoss()
animator = d2l.Animator(xlabel='epoch', ylabel='perplexity',
legend=['train'], xlim=[10, num_epochs])
# 初始化
if isinstance(net, nn.Module):
updater = torch.optim.SGD(net.parameters(), lr)
else:
updater = lambda batch_size: d2l.sgd(net.params, lr, batch_size)
predict = lambda prefix: predict_ch8(prefix, 50, net, vocab, device) # 预测函数
# 训练和预测
for epoch in range(num_epochs):
ppl, speed = train_epoch_ch8(net, train_iter, loss, updater, device, use_random_iter)
if (epoch + 1) % 10 == 0:
print(predict('time traveller'))
animator.add(epoch + 1, [ppl])
print(f'困惑度 {ppl:.1f}, {speed:.1f} 词元/秒 {str(device)}')
print(predict('time traveller'))
print(predict('traveller'))
# 顺序采样
num_epochs, lr = 500, 1
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu())
plt.show()
# 随机采用
net = RNNModelScratch(len(vocab), num_hiddens, d2l.try_gpu(), get_params,init_rnn_state, rnn)
train_ch8(net, train_iter, vocab, lr, num_epochs, d2l.try_gpu(),use_random_iter=True)
plt.show()
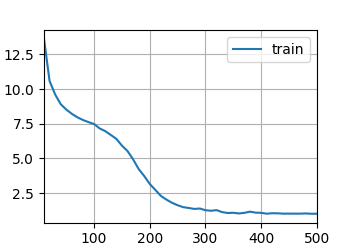
困惑度 1.0, 50189.8 词元/秒 cuda:0
time traveller for so it will be convenient to speak of himwas e
traveller with a slight accession ofcheerfulness really thi
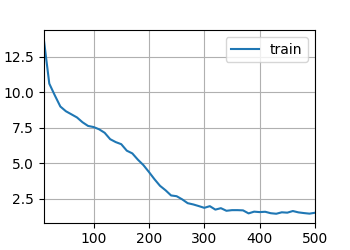
困惑度 1.5, 47149.4 词元/秒 cuda:0
time traveller proceeded anyreal body must have extension in fou
traveller held in his hand was a glitteringmetallic furmime
小结:
- 我们可以训练一个基于循环神经网络的字符级语言模型,根据用户提供的文本的前缀 生成后续文本
- 一个简单的循环神经网络语言模型包括输入编码、循环神经网络模型和输出生成
- 循环神经网络模型在训练以前需要初始化状态,不过随机抽样和顺序划分使用初始化方法不同
- 当使用顺序划分时,我们需要分离梯度以减少计算量(detach)
- 在进行任何预测之前,模型通过预热期进行自我更新(获得比初始值更好的隐状态,训练只是修改参数,并没有改状态)
- 梯度裁剪可以防止梯度爆炸,但不能应对梯度消失
RNN的简洁实现
import torch
from matplotlib import pyplot as plt
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# 定义模型
num_hiddens = 256
rnn_layer = nn.RNN(len(vocab), num_hiddens) # 直接调用模型
# 初始化隐状态
state = torch.zeros((1, batch_size, num_hiddens))
X = torch.rand(size=(num_steps, batch_size, len(vocab)))
Y, state_new = rnn_layer(X, state)
# 这里要注意的是rnn_layer的输出Y并不是我们想要的预测变量!而是隐状态!里面只进行了隐状态的计算而已
# 完成的RNN模型
#@save
class RNNModel(nn.Module):
"""循环神经网络模型"""
def __init__(self, rnn_layer, vocab_size, **kwargs):
super(RNNModel, self).__init__(**kwargs)
self.rnn = rnn_layer # 计算隐状态
self.vocab_size = vocab_size
self.num_hiddens = self.rnn.hidden_size
# 如果RNN是双向的(之后将介绍),num_directions应该是2,否则应该是1
if not self.rnn.bidirectional:
self.num_directions = 1
self.linear = nn.Linear(self.num_hiddens, self.vocab_size) # 输出层计算Y
else:
self.num_directions = 2
self.linear = nn.Linear(self.num_hiddens * 2, self.vocab_size)
def forward(self, inputs, state):
X = F.one_hot(inputs.T.long(), self.vocab_size)
X = X.to(torch.float32)
Y, state = self.rnn(X, state)
# 全连接层首先将Y的形状改为(时间步数*批量大小,隐藏单元数)
# 它的输出形状是(时间步数*批量大小,词表大小)。
output = self.linear(Y.reshape((-1, Y.shape[-1])))
return output, state
def begin_state(self, device, batch_size=1):
if not isinstance(self.rnn, nn.LSTM):
# nn.GRU以张量作为隐状态
return torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens),device=device)
else:
# nn.LSTM以元组作为隐状态
return (torch.zeros((
self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device),
torch.zeros((self.num_directions * self.rnn.num_layers,
batch_size, self.num_hiddens), device=device))
# 训练与预测
device = d2l.try_gpu()
net = RNNModel(rnn_layer, vocab_size=len(vocab))
net = net.to(device)
num_epochs, lr = 500, 1
d2l.train_ch8(net, train_iter, vocab, lr, num_epochs, device)
plt.show()
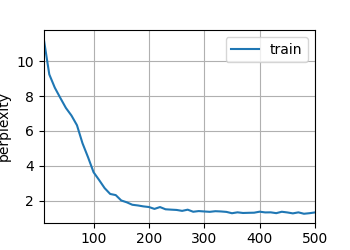
perplexity 1.3, 390784.5 tokens/sec on cuda:0
time travellerit s against reatou dimensions of space generally
traveller pus he iryed it apredinnen it a mamul redoun abs
小结:
- 深度学习框架的高级API提供了RNN层的实现
- 高级API的RNN层返回一个输出和一个更新后的隐状态,我们还需要另外一个线型层来计算整个模型的输出
- 相比从零开始实现的RNN,使用高级API实现可以加速训练
通过时间反向传播
在RNN中,前向传播的计算相对简单,但是其通过时间反向传播实际上要求我们将RNN每次对一个时间步进行展开,以获得模型变量和参数之间的依赖关系,然后基于链式法则去应用放反向传播计算和存储梯度,这就导致当时间长度T较大时,可能依赖关系会相当长。
假设RNN可表示为:
那么在计算梯度时:
上述计算中最麻烦的是第三个,因为\(h_t\)不仅依赖于\(w_h\),还依赖于\(h_{t-1}\),而\(h_{t-1}\)也依赖于\(w_h\),这样就会不停计算下去,即:
那么如果采用上述完成的链式计算,当t很大时这个链就会变得很长,难以计算。具体有以下几种办法。
完全计算
显然最简单的思想当然是直接计算,但是这样非常缓慢,并且很可能会发生梯度爆炸,因为初始条件的额微小变化就可能因为连乘而带给结果巨大的影响,就类似于蝴蝶效应,这是不可取的。
截断时间步
可以在\(\tau\)步后截断上述的求和运算,即将链式法则终止于\(\frac{\partial h_{t-\tau}}{\partial w_h}\),这样通常被称为截断的通过时间反向传播。这么做会导致模型主要侧重于短期影响,而不是长期影响,它会将估计值偏向更简单和更稳定的模型。
随机截断
引入一个随机变量来代替\(\frac{\partial h_t}{\partial w_h}\),即定义\(P(\xi_t=0)=1-\pi_t,P(\xi_t=\pi_t^{-1})=\pi_t\),那么\(E[\xi_t]=1\),令:
那么可以推导出\(E[z_t]=\frac{\partial h_t}{\partial w_h}\),这就导致了不同长度的截断,
门控循环单元GRU
这个机制是引入了重置门和更新门来更好地控制时序信息的传递,具体如下:
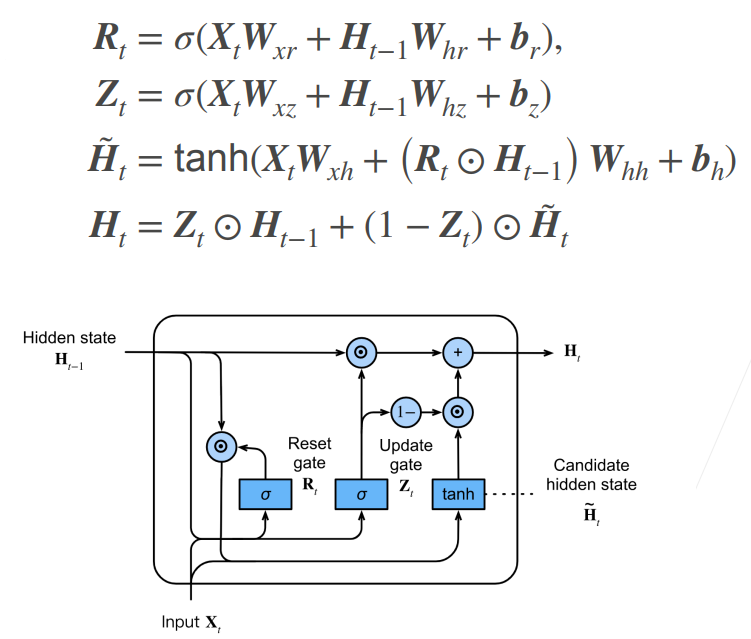
可以看到其中\(R_t、Z_t\)分别称为重置门和更新门,那么当\(Z_t=1\)时,\(H_t=H_{t-1}\),相当于信息完全不更新直接传递过去;而当\(Z_t=0,R_t=0\)时,相当于此时不关注\(H_{t-1}\)的信息,截断时序的传递,那就相当于初始化了。
注意这里\(R_t和H_{t-1}\)之间的计算是按照元素相乘。
import torch
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# 初始化模型参数,这部分和RNN不同
def get_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size # 输入输出都是这个长度的向量
def normal(shape):
return torch.randn(size=shape, device=device) * 0.01
def three(): # 用这个函数可以减少重复写
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xz, W_hz, b_z = three() # 更新门参数
W_xr, W_hr, b_r = three() # 重置门参数
W_xh, W_hh, b_h = three() # 候选隐状态参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
# 初始化隐状态
def init_gru_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),)
# 定义模型
def gru(inputs, state, params):
W_xz, W_hz, b_z, W_xr, W_hr, b_r, W_xh, W_hh, b_h, W_hq, b_q = params # 获取参数
H, = state # 隐状态
outputs = []
for X in inputs:
Z = torch.sigmoid((X @ W_xz) + (H @ W_hz) + b_z) # 计算更新门,@是矩阵乘法
R = torch.sigmoid((X @ W_xr) + (H @ W_hr) + b_r)
H_tilda = torch.tanh((X @ W_xh) + ((R * H) @ W_hh) + b_h) # 注意这里R*H是按元素
H = Z * H + (1 - Z) * H_tilda # 这里也是按元素
Y = H @ W_hq + b_q # 输出
outputs.append(Y)
return torch.cat(outputs, dim=0), (H,) # 同样是叠在一起
vocab_size, num_hiddens, device = len(vocab), 256, d2l.try_gpu()
num_epochs, lr = 500, 1
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_params,
init_gru_state, gru)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
plt.show()

perplexity 1.1, 16015.2 tokens/sec on cuda:0
time traveller for so it will be convenient to speak of himwas e
traveller for so it will be convenient to speak of himwas e
那么GRU的简洁实现也很简单:
num_inputs = vocab_size
gru_layer = nn.GRU(num_inputs, num_hiddens)
model = d2l.RNNModel(gru_layer, len(vocab)) # 封装成model的同时会加上线型层
model = model.to(device)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
plt.show()
perplexity 1.0, 256679.5 tokens/sec on cuda:0
time traveller for so it will be convenient to speak of himwas e
travelleryou can show black is white by argument said filby
可以看到我们调用高级API比从零实现快很多。
小结:
- 门控循环神经网络可以更好地捕获时间步距离很长的序列上的依赖关系
- 重置门有助于捕获系列中的短期依赖关系
- 更新门有助于捕获序列中的长期依赖关系
- 重置门打开时,门控循环单元包含基本循环神经网络;更新门被打开时,门控循环单元可以跳过子序列
长短期记忆网络(LSTM)
这一部分老师讲得比较简单,更关注于实现方面,那么关于LSTM的比较全面的介绍内容可以观看李宏毅老师的课程中相关章节,或者阅读我这篇博客[点此跳转]([机器学习]李宏毅——Recurrent Neural Network(循环神经网络)_FavoriteStar的博客-CSDN博客)。
LSTM的结构具体如下:
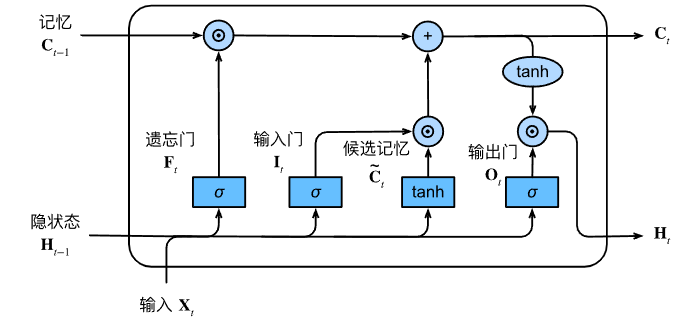
它最主要的特点就是引入了三个门控以及另外一个状态\(C_t\)来更好地存储和控制信息,三个门控分别为:
- 输入门:决定是否忽略输入数据
- 忘记门:将数值朝零减少
- 输出门:决定是否使用隐状态
具体讲解可以看我上述提到的那篇博客。
import torch
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# 初始化模型参数
def get_lstm_params(vocab_size, num_hiddens, device):
num_inputs = num_outputs = vocab_size
def normal(shape):
return torch.randn(size=shape, device=device)*0.01
def three():
return (normal((num_inputs, num_hiddens)),
normal((num_hiddens, num_hiddens)),
torch.zeros(num_hiddens, device=device))
W_xi, W_hi, b_i = three() # 输入门参数
W_xf, W_hf, b_f = three() # 遗忘门参数
W_xo, W_ho, b_o = three() # 输出门参数
W_xc, W_hc, b_c = three() # 候选记忆元参数
# 输出层参数
W_hq = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
# 附加梯度
params = [W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc,
b_c, W_hq, b_q]
for param in params:
param.requires_grad_(True)
return params
# 初始化隐状态,这部分就是两个了
def init_lstm_state(batch_size, num_hiddens, device):
return (torch.zeros((batch_size, num_hiddens), device=device),
torch.zeros((batch_size, num_hiddens), device=device))
# 定义模型
def lstm(inputs, state, params):
[W_xi, W_hi, b_i, W_xf, W_hf, b_f, W_xo, W_ho, b_o, W_xc, W_hc, b_c,
W_hq, b_q] = params # 获取参数
(H, C) = state # 获取隐状态
outputs = []
for X in inputs:
I = torch.sigmoid((X @ W_xi) + (H @ W_hi) + b_i)
F = torch.sigmoid((X @ W_xf) + (H @ W_hf) + b_f)
O = torch.sigmoid((X @ W_xo) + (H @ W_ho) + b_o)
C_tilda = torch.tanh((X @ W_xc) + (H @ W_hc) + b_c)
C = F * C + I * C_tilda
H = O * torch.tanh(C)
Y = (H @ W_hq) + b_q # 计算输出
outputs.append(Y)
return torch.cat(outputs, dim=0), (H, C)
vocab_size, num_hiddens, device = len(vocab), 512, d2l.try_gpu()
num_epochs, lr = 500, 1
model = d2l.RNNModelScratch(len(vocab), num_hiddens, device, get_lstm_params,
init_lstm_state, lstm)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
plt.show()
perplexity 1.1, 13369.1 tokens/sec on cuda:0
time traveller well the wild the urais diff me time srivelly are
travelleryou can show black is white by argument said filby
下面是简洁实现:
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens)
model = d2l.RNNModel(lstm_layer, len(vocab)) # 同样会补上输出的线型层实现
model = model.to(device)
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
plt.show()
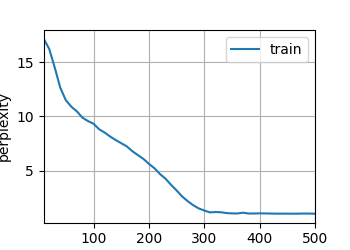
perplexity 1.0, 147043.6 tokens/sec on cuda:0
time travelleryou can show black is white by argument said filby
travelleryou can show black is white by argument said filby
调用高级API的速度是从零实现是十倍往上。
小结:
- LSTM有三种类型的门:输入门、遗忘门和输出门
- LSTM隐藏层输出包括隐状态和记忆元,只有隐状态会传递到输出层,而记忆元完全属于内部信息
- LSTM可以缓解梯度消失和梯度爆炸的问题,因此多次使用到tanh将输出映射到[-1,1]之间,具体可以看我那篇博客最后。
深度循环神经网络
为了能够获得更多的非线性以及更强的表示能力,我们可以在深度上拓展循环神经网络:
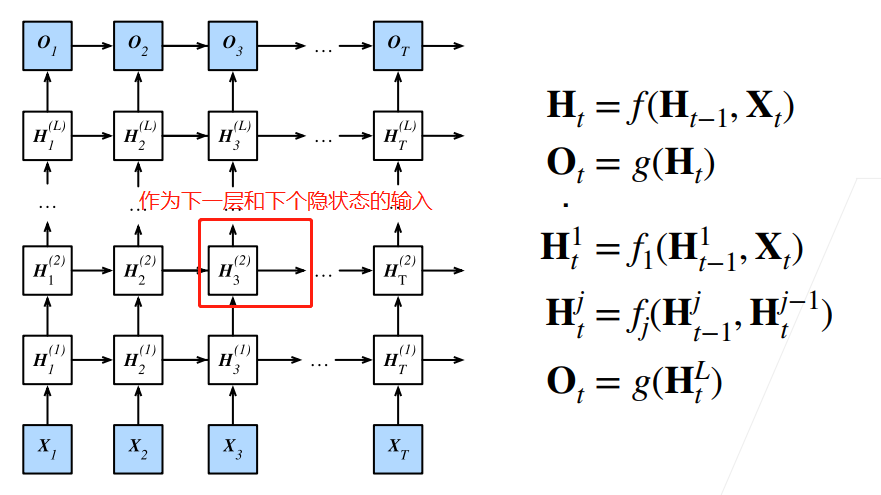
这部分还是很简单很好理解的,对于GRU和LSTM同样可以采用。
import torch
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
batch_size, num_steps = 32, 35
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2 # 指定隐藏层的层数
num_inputs = vocab_size
device = d2l.try_gpu()
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers) # 第三个参数指定隐藏层数目
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
num_epochs, lr = 500, 2
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
plt.show()
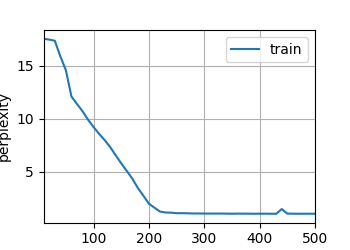
perplexity 1.0, 128068.2 tokens/sec on cuda:0
time travelleryou can show black is white by argument said filby
travelleryou can show black is white by argument said filby
小结:
- 在深度循环神经网络中,隐状态的信息被传递到当前层的下一时间步和下一层的当前时间步
- 有许多不同风格的深度循环神经网络,如LSTM、GRU、RNN等,这些模型都可以用深度学习框架的高级API实现
- 总体而言,深度循环神经网络需要大量的调参(如学习率和修剪) 来确保合适的收敛,模型的初始化也需要谨慎。
双向循环神经网络
之前的模型都是观察历史的数据来预测未来的数据,但是如果是在一些填空之类的任务中,未来的信息对这个空也是至关重要的:

因此双向循环神经网络就是可以观察未来的信息,它拥有一个前向RNN隐层和一个反向RNN隐层,然后输出层的输入是这两个层隐状态的合并,如下:
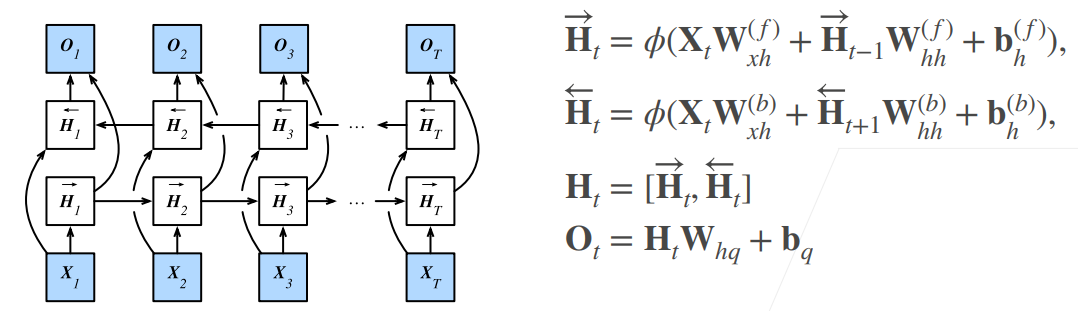
虽然这在训练的时候是没问题的,但是这种模型不能用于做预测任务,因此它无法得知未来的信息,这会造成很糟糕的结果。它最主要的用处是用来对序列进行特征抽取,因为它能够观察到未来的信息,因此特征抽取会更加全面。
import torch
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
# 加载数据
batch_size, num_steps, device = 32, 35, d2l.try_gpu()
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# 通过设置“bidirective=True”来定义双向LSTM模型
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers, bidirectional=True)
model = d2l.RNNModel(lstm_layer, len(vocab)) # 里面已经设置了当为双向时线性层会不同
model = model.to(device)
# 训练模型
num_epochs, lr = 500, 1
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
plt.show()
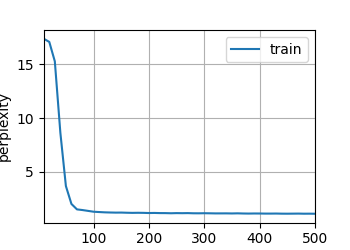
perplexity 1.1, 76187.7 tokens/sec on cuda:0
time travellerererererererererererererererererererererererererer
travellerererererererererererererererererererererererererer
可以看到预测的效果是极差的。
小结:
- 在双向循环神经网络中,每个时间步的隐状态由当前时间步的前后数据同时决定。
- 双向循环神经网络与概率图模型中的“前向-后向”算法具有相似性。
- 双向循环神经网络主要用于序列编码和给定双向上下文的观测估计。
- 由于梯度链更长,因此双向循环神经网络的训练代价非常高。
机器翻译与数据集
import os
import torch
from d2l import torch as d2l
#@save
from matplotlib import pyplot as plt
d2l.DATA_HUB['fra-eng'] = (d2l.DATA_URL + 'fra-eng.zip',
'94646ad1522d915e7b0f9296181140edcf86a4f5')
#@save
def read_data_nmt():
"""载入“英语-法语”数据集"""
data_dir = d2l.download_extract('fra-eng')
with open(os.path.join(data_dir, 'fra.txt'), 'r',encoding='utf-8') as f:
return f.read()
raw_text = read_data_nmt()
print(raw_text[:75])
#@save
def preprocess_nmt(text):
"""预处理“英语-法语”数据集"""
def no_space(char, prev_char):
return char in set(',.!?') and prev_char != ' '
# 使用空格替换不间断空格
# 使用小写字母替换大写字母
text = text.replace('\u202f', ' ').replace('\xa0', ' ').lower() # 将utf-8中半角全角空格都换成空格
# 在单词和标点符号之间插入空格
out = [' ' + char if i > 0 and no_space(char, text[i - 1]) else char
for i, char in enumerate(text)]
return ''.join(out)
text = preprocess_nmt(raw_text)
print(text[:80])
#@save
def tokenize_nmt(text, num_examples=None):
"""词元化“英语-法语”数据数据集"""
source, target = [], []
for i, line in enumerate(text.split('\n')):
if num_examples and i > num_examples:
break
parts = line.split('\t') # 按照制表符将英文和法文分开
if len(parts) == 2: # 说明前面是英文,后面是法文
source.append(parts[0].split(' ')) # 按照我们前面插入的空格来划分
target.append(parts[1].split(' '))
return source, target
source, target = tokenize_nmt(text)
print(source[:6], target[:6])
def show_list_len_pair_hist(legend, xlabel, ylabel, xlist, ylist):
"""绘制列表长度对的直方图"""
d2l.set_figsize()
_, _, patches = d2l.plt.hist(
[[len(l) for l in xlist], [len(l) for l in ylist]])
d2l.plt.xlabel(xlabel)
d2l.plt.ylabel(ylabel)
for patch in patches[1].patches:
patch.set_hatch('/')
d2l.plt.legend(legend)
show_list_len_pair_hist(['source', 'target'], '# tokens per sequence',
'count', source, target)
plt.show()
src_vocab = d2l.Vocab(source, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])
# 转换成词表,然后加入一些特殊的词,分别是填充、开始、结尾
print(len(src_vocab))
#@save
def truncate_pad(line, num_steps, padding_token): # 这是为了保证我们的输入都是等长的
"""截断或填充文本序列"""
if len(line) > num_steps: # 如果这个句子的长度大于设定长度,我们就截断
return line[:num_steps] # 截断
return line + [padding_token] * (num_steps - len(line)) # 如果小于就进行填充
print(truncate_pad(src_vocab[source[0]], 10, src_vocab['<pad>']))
#@save
def build_array_nmt(lines, vocab, num_steps):
"""将机器翻译的文本序列转换成小批量"""
lines = [vocab[l] for l in lines] # 将文本转换为向量
lines = [l + [vocab['<eos>']] for l in lines] # 每一个都要加上结尾符
array = torch.tensor([truncate_pad(l, num_steps, vocab['<pad>']) for l in lines])
# 进行填充或截断
valid_len = (array != vocab['<pad>']).type(torch.int32).sum(1)
# 这是把每个句子除填充外的有效长度都标注出来,之后计算会用到
return array, valid_len
#@save
def load_data_nmt(batch_size, num_steps, num_examples=600):
"""返回翻译数据集的迭代器和词表"""
text = preprocess_nmt(read_data_nmt()) # 预处理
source, target = tokenize_nmt(text, num_examples) # 生成英文和法文两部分
# 转成词典
src_vocab = d2l.Vocab(source, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])
tgt_vocab = d2l.Vocab(target, min_freq=2,reserved_tokens=['<pad>', '<bos>', '<eos>'])
src_array, src_valid_len = build_array_nmt(source, src_vocab, num_steps)
tgt_array, tgt_valid_len = build_array_nmt(target, tgt_vocab, num_steps)
data_arrays = (src_array, src_valid_len, tgt_array, tgt_valid_len)
data_iter = d2l.load_array(data_arrays, batch_size) # 一次迭代含有4个变量
return data_iter, src_vocab, tgt_vocab
train_iter, src_vocab, tgt_vocab = load_data_nmt(batch_size=2, num_steps=8)
for X, X_valid_len, Y, Y_valid_len in train_iter:
print('X:', X.type(torch.int32))
print('X的有效长度:', X_valid_len)
print('Y:', Y.type(torch.int32))
print('Y的有效长度:', Y_valid_len)
break
Go. Va !
Hi. Salut !
Run! Cours !
Run! Courez !
Who? Qui ?
Wow! Ça alors !
go . va !
hi . salut !
run ! cours !
run ! courez !
who ? qui ?
wow ! ça alors !
[['go', '.'], ['hi', '.'], ['run', '!'], ['run', '!'], ['who', '?'], ['wow', '!']] [['va', '!'], ['salut', '!'], ['cours', '!'], ['courez', '!'], ['qui', '?'], ['ça', 'alors', '!']]
10012
[47, 4, 1, 1, 1, 1, 1, 1, 1, 1]
X: tensor([[ 7, 0, 4, 3, 1, 1, 1, 1],
[118, 55, 4, 3, 1, 1, 1, 1]], dtype=torch.int32)
X的有效长度: tensor([4, 4])
Y: tensor([[6, 7, 0, 4, 3, 1, 1, 1],
[0, 4, 3, 1, 1, 1, 1, 1]], dtype=torch.int32)
Y的有效长度: tensor([5, 3])
小结:
- 机器翻译指的是将文本序列从一种语言自动翻译成另一种语言。
- 使用单词级词元化时的词表大小,将明显大于使用字符级词元化时的词表大小。为了缓解这一问题,我们可以将低频词元视为相同的未知词元。
- 通过截断和填充文本序列,可以保证所有的文本序列都具有相同的长度,以便以小批量的方式加载。
编码器-解码器架构
这是一个很重要的模型。因为机器翻译是序列转换模型中的一个核心问题,其输入和输出都是长度可变的序列。那么为了处理这种类型的结构,我们便使用到了编码器-解码器架构。
首先是编码器,它接受一个长度可变的序列作为输入,然后将其转换为具有固定形状的编码状态;然后是解码器,它将固定形状的编码状态映射到长度可变的序列,如下:
对于AE自编码器的介绍可以看我这篇博客,讲得比较仔细,有助于理解这种结构。
from torch import nn
#@save
class Encoder(nn.Module):
"""编码器-解码器架构的基本编码器接口"""
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, X, *args):
raise NotImplementedError
#@save
class Decoder(nn.Module):
"""编码器-解码器架构的基本解码器接口"""
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, enc_outputs, *args): # 这部分就是编码后的状态
raise NotImplementedError
def forward(self, X, state):
raise NotImplementedError
#@save
class EncoderDecoder(nn.Module):
"""编码器-解码器架构的基类"""
def __init__(self, encoder, decoder, **kwargs):
super(EncoderDecoder, self).__init__(**kwargs)
self.encoder = encoder
self.decoder = decoder
def forward(self, enc_X, dec_X, *args):
enc_outputs = self.encoder(enc_X, *args) # 计算编码后的值
dec_state = self.decoder.init_state(enc_outputs, *args)
return self.decoder(dec_X, dec_state) # 解码
小结:
- 编码器-解码器架构可以将长度可变的序列作为输入和输出,因此适用于机器翻译等序列转换问题。
- 编码器将长度可变的序列作为输入,并将其转换为具有固定形状的编码状态。
- 解码器将具有固定形状的编码状态映射为长度可变的序列。
序列到序列学习(Seq2Seq)
这种任务就是给定一个序列,我们希望将其变换为另一个序列,最典型的应用就是机器翻译,它给定一个源语言的句子并将其翻译为目标语言。那么这就要求给定句子的长度是可变的,而且翻译后的句子可以有不同的长度。
那么这个任务最开始用的是编码器-解码器架构来做的:
且编码器和解码器用的都是RNN的模型。
编码器中RNN使用长度可变的序列作为输入,将其转换为固定形状的隐状态,此时输入序列的信息都被编码到隐状态中;然后将该编码器的最后一个隐状态作为解码器的初始隐状态,解码器的RNN根据该初始隐状态和自己的输入,开始进行预测。
那么这种架构在训练和预测的时候有所不同,在训练时解码器的输入一直都是正确的预测结果,而在预测的时候解码器的输入就是本身预测的上一个结果,不一定正确。
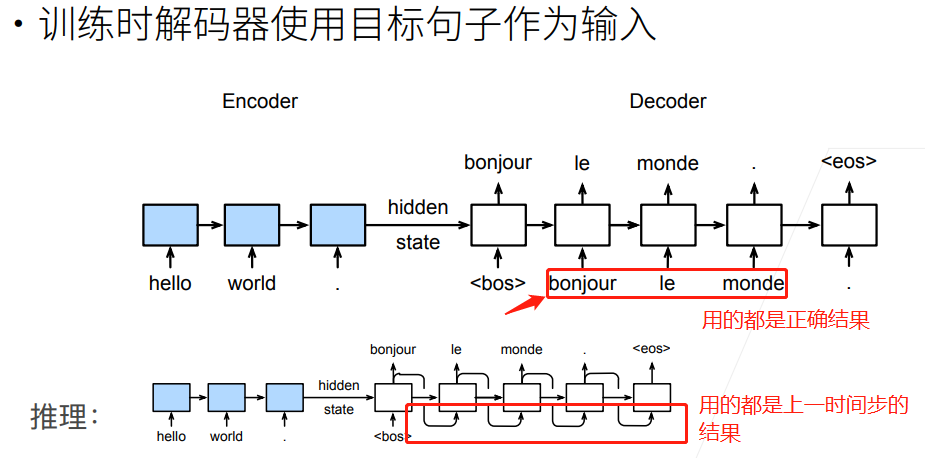
而因为现在我们不仅仅是预测字母,我们是预测整个句子,因此需要一个新的衡量指标来量化预测句子的好坏。常用的是BLEU,其具体如下:
设\(p_n\)是预测中所有n-gram的精度,例如真实序列ABCDEF和预测序列ABBCD,那么\(p_1\)就是预测序列中单个单元(A,B,B,C,D)在真实序列中是否出现,可以看到总共有4个出现了(B只出现1次)因此\(p_1=\frac{4}{5}\),同理\(p_2=\frac{3}{4}\),\(p_3=\frac{1}{3}\),\(p_4=0\)。
而BLEU的定义如下:
其中指数项是为了惩罚过短的预测,因此如果我只预测单个单元,那么只要其出现了我所有的\(p_n\)(也就是\(p_1\))就是1了,但这是不行的。第二项因为p都是小于1的,因此较长的匹配其指数(\(\frac{1}{2^n}\))会较小,因此可以认为其具有更大的权重。
import collections
import math
import torch
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
# @save
class Seq2SeqEncoder(d2l.Encoder):
"""用于序列到序列学习的循环神经网络编码器"""
def __init__(self, vocab_size, embed_size, num_hiddens,
num_layers, dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
# 嵌入层
self.embedding = nn.Embedding(vocab_size, embed_size)
# 词嵌入,将文字自动转换成词向量
self.rnn = nn.GRU(embed_size, num_hiddens, num_layers, dropout=dropout)
# 因为已经转换为词向量,因此输入为词向量的长度
def forward(self, X, *args):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X) # 先转换为词向量
# 在循环神经网络模型中,第一个轴对应于时间步
X = X.permute(1, 0, 2) # 转换为时间步*批量大小*长度
# 如果未提及状态,则默认为0
output, state = self.rnn(X)
# output的形状:(num_steps,batch_size,num_hiddens),
# 因为有多层,它可以认为是最后一层的所有时间步的隐状态输出
# state的形状:(num_layers,batch_size,num_hiddens)
# 它是所有层的最后一个时间步的隐状态输出
return output, state
class Seq2SeqDecoder(d2l.Decoder):
"""用于序列到序列学习的循环神经网络解码器"""
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size + num_hiddens, num_hiddens, num_layers,
dropout=dropout)
# 因为下面做了拼接处理,因此这里输入的维度为embed_size+num_hiddens
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, *args):
return enc_outputs[1] # 里面有output,state,【1】就是把state拿出来
def forward(self, X, state):
# 输出'X'的形状:(batch_size,num_steps,embed_size)
X = self.embedding(X).permute(1, 0, 2)
# 广播context,使其具有与X相同的num_steps state[-1]是前面最后一层的最后一个隐状态
context = state[-1].repeat(X.shape[0], 1, 1)
# context的维度为num_steps,1,num_hiddens
X_and_context = torch.cat((X, context), 2)
# 将它们拼在一起,即输入embed_size+num_hiddens
# 这里可以认为是:我觉得单纯的隐状态的传递不够,我再将最后一层的最后一个隐状态
# 和我的第一个输入拼在一起,我觉得它浓缩了很多信息,也一起来作为输入
output, state = self.rnn(X_and_context, state)
output = self.dense(output).permute(1, 0, 2)
# output的形状:(batch_size,num_steps,vocab_size)
# state的形状:(num_layers,batch_size,num_hiddens)
return output, state
# @save
def sequence_mask(X, valid_len, value=0): # 该函数生成mask并进行遮挡
"""在序列中屏蔽不相关的项"""
maxlen = X.size(1) # 取出X中的第一维度的数量
mask = torch.arange((maxlen), dtype=torch.float32,
device=X.device)[None, :] < valid_len[:, None]
# arange生成一个一维的tensor,[None,:]是将其变成二维的,1*maxlen的tensor
# 而valid_len是长度为max_len的向量,[:,None]就变成了max_len*1的tensor
# 然后小于就会触发广播机制,例如max_len=4,那么arange生成的[[1,2,3,4]]就会广播
# 变成4行,每一行都是[1,2,3,4],那么将每一列和valid_len这个列比较
# 因为valid_len中的元素就是多少个有效的,那么假设2,就是前两个为true,后两个为false
# 这样就可以将其提取出来了
X[~mask] = value
return X
# @save
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
"""带遮蔽的softmax交叉熵损失函数"""
# pred的形状:(batch_size,num_steps,vocab_size)
# label的形状:(batch_size,num_steps)
# valid_len的形状:(batch_size,)
def forward(self, pred, label, valid_len):
weights = torch.ones_like(label)
weights = sequence_mask(weights, valid_len)
self.reduction = 'none' # 不对求出来的损失求和、平均等操作
unweighted_loss = super(MaskedSoftmaxCELoss, self).forward(
pred.permute(0, 2, 1), label) # 这里维度转换为torch本身的要求
weighted_loss = (unweighted_loss * weights).mean(dim=1) # 按元素相乘
return weighted_loss
# @save
def train_seq2seq(net, data_iter, lr, num_epochs, tgt_vocab, device):
"""训练序列到序列模型"""
def xavier_init_weights(m):
if type(m) == nn.Linear:
nn.init.xavier_uniform_(m.weight)
if type(m) == nn.GRU:
for param in m._flat_weights_names:
if "weight" in param:
nn.init.xavier_uniform_(m._parameters[param])
net.apply(xavier_init_weights)
net.to(device)
optimizer = torch.optim.Adam(net.parameters(), lr=lr)
loss = MaskedSoftmaxCELoss()
net.train() # 开启训练模式
animator = d2l.Animator(xlabel='epoch', ylabel='loss', xlim=[10, num_epochs])
for epoch in range(num_epochs):
timer = d2l.Timer()
metric = d2l.Accumulator(2) # 训练损失总和,词元数量
for batch in data_iter:
optimizer.zero_grad() # 清空梯度
X, X_valid_len, Y, Y_valid_len = [x.to(device) for x in batch]
# 英文、英文有效长度、法文、法文有效长度
bos = torch.tensor([tgt_vocab['<bos>']] * Y.shape[0], device=device).reshape(-1, 1) # 转换为相同纬度
# Y是法文,在训练时是作为解码器的输入的,然后我们需要一个开始标注
# 因此我们将Y的最后一个单词去掉,再在第一个前面加上一个开始标志bos
# 这样我们强制让它学习bos去预测第一个词,而最后一个词它不会用来做预测,因此在预测时它去掉没关系
# 那之后在真正预测的时候,我们就只需要给解码器第一个为bos,后面它自己生成的拿来做输入就可以
dec_input = torch.cat([bos, Y[:, :-1]], 1) # 强制教学
Y_hat, _ = net(X, dec_input, X_valid_len) # 这个模型的第一个参数的编码器输入,第二个是解码器输入
# 第三个是编码器输入的有效长度
l = loss(Y_hat, Y, Y_valid_len) # 这里就是用原来的Y去和预测的做损失
l.sum().backward() # 损失函数的标量进行“反向传播”
d2l.grad_clipping(net, 1) # 梯度裁剪
num_tokens = Y_valid_len.sum()
optimizer.step()
with torch.no_grad():
metric.add(l.sum(), num_tokens)
if (epoch + 1) % 10 == 0:
animator.add(epoch + 1, (metric[0] / metric[1],))
print(f'loss {metric[0] / metric[1]:.3f}, {metric[1] / timer.stop():.1f} '
f'tokens/sec on {str(device)}')
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10 # 10是句子最长为10,超过裁剪,不足就补充
lr, num_epochs, device = 0.005, 300, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = Seq2SeqEncoder(len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqDecoder(len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
plt.show()
# @save
def predict_seq2seq(net, src_sentence, src_vocab, tgt_vocab, num_steps, device,
save_attention_weights=False):
"""序列到序列模型的预测"""
# 在预测时将net设置为评估模式
net.eval()
# 将输入的句子变成小写再按空格分隔再加上结尾符,并且都经过src_vocab这个类转换成向量了
src_tokens = src_vocab[src_sentence.lower().split(' ')] + [src_vocab['<eos>']]
# 该句子的有效长度
enc_valid_len = torch.tensor([len(src_tokens)], device=device)
# 对该句子检查长度进行填充或者裁剪
src_tokens = d2l.truncate_pad(src_tokens, num_steps, src_vocab['<pad>'])
# 添加批量轴,将src_tokens添加上批量这个维度,因此变成批量*时间步*vocabsize
enc_X = torch.unsqueeze(torch.tensor(src_tokens, dtype=torch.long, device=device),
dim=0)
# 计算encoder的输出
enc_outputs = net.encoder(enc_X, enc_valid_len)
# 计算decoder应该接受的初始状态
dec_state = net.decoder.init_state(enc_outputs, enc_valid_len)
# 添加批量轴,因为现在是预测因此decoer的输入只有一个<bos>,那么为它添加一个批量轴
dec_X = torch.unsqueeze(torch.tensor(
[tgt_vocab['<bos>']], dtype=torch.long, device=device), dim=0) # 增加一个维度
output_seq, attention_weight_seq = [], []
for _ in range(num_steps):
Y, dec_state = net.decoder(dec_X, dec_state) # 输出和隐状态
# 我们使用具有预测最高可能性的词元,作为解码器在下一时间步的输入
dec_X = Y.argmax(dim=2) # 更新输入
pred = dec_X.squeeze(dim=0).type(torch.int32).item() # 去除批量这个维度
# 保存注意力权重(稍后讨论)
if save_attention_weights:
attention_weight_seq.append(net.decoder.attention_weights)
# 一旦序列结束词元被预测,输出序列的生成就完成了
if pred == tgt_vocab['<eos>']:
break
output_seq.append(pred)
return ' '.join(tgt_vocab.to_tokens(output_seq)), attention_weight_seq
def bleu(pred_seq, label_seq, k): #@save
"""计算BLEU"""
pred_tokens, label_tokens = pred_seq.split(' '), label_seq.split(' ')
len_pred, len_label = len(pred_tokens), len(label_tokens)
score = math.exp(min(0, 1 - len_label / len_pred))
for n in range(1, k + 1):
num_matches, label_subs = 0, collections.defaultdict(int)
for i in range(len_label - n + 1):
# 这个循环是将真实序列中的各种长度的连续词汇都变成词典计数
label_subs[' '.join(label_tokens[i: i + n])] += 1
for i in range(len_pred - n + 1):
if label_subs[' '.join(pred_tokens[i: i + n])] > 0:
num_matches += 1 # 这里判断出来预测序列中有对应的n-gram
label_subs[' '.join(pred_tokens[i: i + n])] -= 1 # 要减一
score *= math.pow(num_matches / (len_pred - n + 1), math.pow(0.5, n))
return score
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, attention_weight_seq = predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device)
print(f'{eng} => {translation}, bleu {bleu(translation, fra, k=2):.3f}')
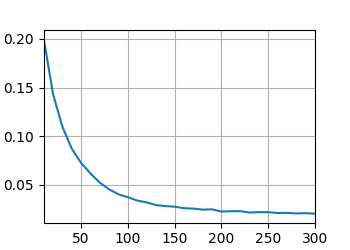
loss 0.019, 12068.0 tokens/sec on cuda:0
go . => va !, bleu 1.000
i lost . => j'ai perdu ., bleu 1.000
he's calm . => il est riche ., bleu 0.658
i'm home . => je suis chez moi chez moi chez moi juste ., bleu 0.537
小结:
- 根据“编码器-解码器”架构的设计, 我们可以使用两个循环神经网络来设计一个序列到序列学习的模型。
- 在实现编码器和解码器时,我们可以使用多层循环神经网络。
- 我们可以使用遮蔽来过滤不相关的计算,例如在计算损失时。
- 在“编码器-解码器”训练中,强制教学方法将原始输出序列(而非预测结果)输入解码器。
- BLEU是一种常用的评估方法,它通过测量预测序列和标签序列之间的n元语法的匹配度来评估预测。
束搜索
在前面的预测之中,我们采用的策略是贪心策略,也就是每一次预测的时候都是选择当前概率最大的来作为结果。那么贪心策略的最终结果通常不是最优的,然后穷举搜索计算复杂度太大了,因此有另一种方法为束搜索来进行改进。
束搜索有一种关键的参数为束宽\(k\)。在时间步1,也就是根据<bos>做第一次预测时,我们不止是选取概率最大的那个来进行输出,而是选择具有最高概率的\(k\)个词元,例如下图中我们在第一个时间步选择到了A和C。那么在之后的时间步中,就会基于上一个时间步所选择的\(k\)个候选序列,来从\(k\vert Y\vert\)个可能中挑选出具有最高条件概率的\(k\)个候选输出序列:
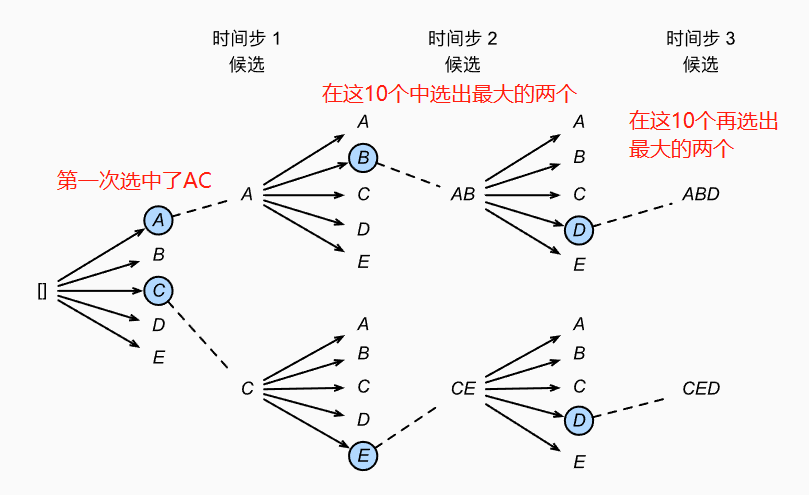
并且,我们不止是考虑最终得到的长序列,而是考虑在选择过程中选择到的各个序列,即A,C,AB,CE,ABD,CED这两个序列。对它们的评估我们采用以下公式进行计算:
其中L为序列的长度,\(\alpha\)常取0.75,这部分是为了中和长短序列的差距,因为短序列乘的概率少总是会大一点,因此用这部分来进行中和,相当于给选择短序列加入了一定的惩罚。
束搜索的时间复杂度为\(O(k\vert Y\vert T)\)
小结:
- 序列搜索策略包括贪心搜索、穷举搜索和束搜索。
- 贪心搜索所选取序列的计算量最小,但精度相对较低。
- 穷举搜索所选取序列的精度最高,但计算量最大。
- 束搜索通过灵活选择束宽,在正确率和计算代价之间进行权衡。
注意力机制
注意力机制与注意力分数
第一节课注意力机制的时候我听完老师的讲解一直没能理解,什么是注意力机制,但我听了第二节的注意力分数后才感觉到豁然开朗,因此我就按照自己的方式来进行记录。
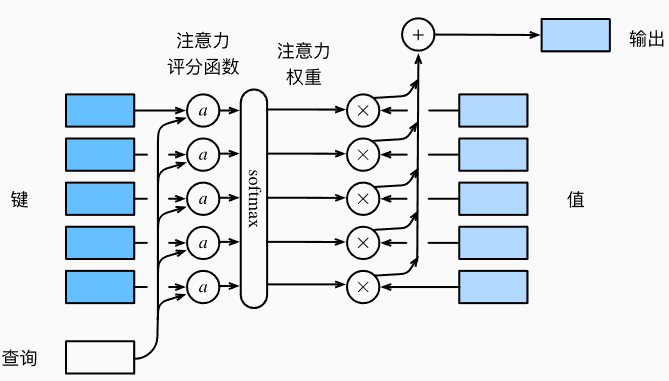
注意力机制完全可以用上图很好地表示,其中需要注意的几个点为:
- 键:可以认为是已有的样本\(x_i\)
- 值:可以认为是每个样本对应的函数值\(y_i=f(x_i)\)
- 查询:可以认为是我们新得到的输入\(\hat{x}\)
而我们的目的是希望能够通过键和值来计算未知的\(f(\hat{x})\)
那么注意力机制的方法就是通过注意力评分函数来计算\(\hat{x}\)与每一个已知样本\(x_i\)之间的得分,再转换成权重,再对每一个\(y_i\)进行加权和即可。
那么对于最简单的情形,当然是权重都一致,因此相当于取平均:
而这样的效果通常是较差的,因此通常是根据各种方式来计算评分与权重:
即用函数a计算评分,再经过softmax转换为权重\(\alpha\)。
对于标量来说,比较直观的思想当然是计算两个标量之间的距离,即:
而拓展到向量的情况,假设查询为\(\pmb{q}\in R^q\),具有m个键值对\((\pmb{k}_1,\pmb{v}_1),...,(\pmb{k}_m,\pmb{v}_m)\),其中\(\pmb{k}_i\in R^k,\pmb{v}_i\in R^v\),注意力汇聚则可写成:
因此现在就需要对查询与键之间的评分进行衡量,此处介绍两种方法。
1、Additive Attention
其需要进行参数的学习,可学习的参数为:\(\pmb{W}_k\in R^{h\times k},\pmb{W}_q\in R^{h\times q},\pmb{v}\in R^h\)
等价于将查询和键进行拼接,成为长度为\((q+k)\)的向量,再经过一个隐藏大小为\(h\)、输出大小为1的单隐藏层MLP。那么这种方法就不要求查询和键的长度是一样的,是很适用的方法。
2、Scaled Dot-Product Attention
这部分不需要进行参数的学习,但它要求查询和键向量长度是相同的,设长度为d,那么:
这里将两个向量做内积,然后除以\(\sqrt{d}\),这是因为长度较长的向量内积会比较大,那么这部分可以消除长度的影响。
上述算法的批量化版本为:
import math
import torch
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
# 先定义遮挡的softmax操作,因为我们有时候并不是要利用所有的键值对
def masked_softmax(X, vaild_lens):
if vaild_lens is None:
return nn.functional.softmax(X, dim=-1)
# 如果不进行遮挡,那么就直接进行softmax就好
else:
shape = X.shape # X的维度是(批量数,批量内样本数目,样本长度)
if vaild_lens.dim() == 1: # 说明是一个向量,不是矩阵
vaild_lens = torch.repeat_interleave(vaild_lens, shape[1])
# 例如vaild_lens[1,2],内部元素的意义是对于两个批量
# 第一个批量内所有样本只需要看第一个键值对,第二个批量内所有样本只看前两个键值对
# 而在批量内样本数目的维度进行复制,例如样本数目为3,那么就会变成
# [1,1,1,2,2,2],这样就是针对每一个样本的有效长度了
else:
vaild_lens = vaild_lens.reshape(-1)
# 因为已经是矩阵了,就已经是我们针对每一个样本的有效长度了
# 例如上面的[1,1,1,2,2,2]只不过维度是[[1,1,1],[2,2,2]]
# 那么我们将其展开成一维的[1,1,1,2,2,2]就可以了
X = d2l.sequence_mask(X.reshape(-1, shape[-1]), vaild_lens, value=-1e6)
# 将X展开,然后那些无效的就设成负数使其指数接近于0
return nn.functional.softmax(X.reshape(shape), dim=-1)
# 加性注意力实现
# @save
class AdditiveAttention(nn.Module):
def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):
super(AdditiveAttention, self).__init__(**kwargs)
self.W_k = nn.Linear(key_size, num_hiddens, bias=False)
self.W_q = nn.Linear(query_size, num_hiddens, bias=False)
self.w_v = nn.Linear(num_hiddens, 1, bias=False)
self.dropout = nn.Dropout(dropout)
def forward(self, queries, keys, values, valid_lens):
queries, keys = self.W_q(queries), self.W_k(keys)
# 两者先经过线性模型的处理
# 此时queries形状为(批量数目,单个批量的查询个数,num_hidden)
# keys形状为(批量数目,单个批量的键个数,num_hidden)
# 这样是不能直接相加的,我们的目的是每一个q都跟每个k加一次
# 因此拓展维度
# 在维度扩展后,
# queries的形状:(batch_size,查询的个数,1,num_hidden)
# key的形状:(batch_size,1,“键-值”对的个数,num_hiddens)
# 使用广播方式进行求和,我们想要让每个查询,都和每个key加一次,
# 因此出来时(batch_size,查询个数,键个数,num_hidden)
features = queries.unsqueeze(2) + keys.unsqueeze(1)
features = torch.tanh(features)
scores = self.w_v(features).squeeze(-1) # 最后一个维度是1,因为是标量
# 去掉最后一个维度就变成(batch_size,查询个数,键个数)
self.attention_weights = masked_softmax(scores, valid_lens)
# 获取权重,其中将无效的转换为0了
return torch.bmm(self.dropout(self.attention_weights), values)
# 进行dropout丢弃掉其中一部分权重,但dropout是保证加起来为1的,然后再最进行遮挡的相乘bmm
# 实现缩放点积注意力
class DotProductAttention(nn.Module):
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
def forward(self, queries, keys, values, valid_lens=None):
# queries的形状:(batch_size,查询的个数,d)
# keys的形状:(batch_size,“键-值”对的个数,d)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
# valid_lens的形状:(batch_size,)或者(batch_size,查询的个数)
d = queries.shape[-1]
scores = torch.bmm(queries, keys.transpose(1,2))/math.sqrt(d)
# 将k最后面的两个维度进行交换,也就相当于转置了,然后用batch方式的相乘
self.attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(self.attention_weights), values)
if __name__ == "__main__":
queries, keys = torch.normal(0, 1, (2, 1, 20)), torch.ones((2, 10, 2))
# values的小批量,两个值矩阵是相同的
values = torch.arange(40, dtype=torch.float32).reshape(1, 10, 4).repeat(
2, 1, 1)
valid_lens = torch.tensor([2, 6])
attention = AdditiveAttention(key_size=2, query_size=20, num_hiddens=8,
dropout=0.1)
attention.eval()
print(attention(queries, keys, values, valid_lens))
d2l.show_heatmaps(attention.attention_weights.reshape((1, 1, 2, 10)),
xlabel='Keys', ylabel='Queries')
plt.show()
queries = torch.normal(0, 1, (2, 1, 2))
attention = DotProductAttention(dropout=0.5)
attention.eval()
print(attention(queries, keys, values, valid_lens))
d2l.show_heatmaps(attention.attention_weights.reshape((1, 1, 2, 10)),
xlabel='Keys', ylabel='Queries')
plt.show()
tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]],
[[10.0000, 11.0000, 12.0000, 13.0000]]], grad_fn=<BmmBackward0>)
tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]],
[[10.0000, 11.0000, 12.0000, 13.0000]]])
小结:
- 注意力分数是查询和键的相似度,注意力权重是分数的softmax结果
- 两种常见的分数计算为:
- 将查询和键合并起来进入一个单输出单隐藏层的MLP
- 直接将查询和键做内积
自注意力机制用于Seq2Seq
例如前面英文翻译成法文的句子,在Decoder中,我们是将Encoder的最后时间步的最后隐藏层的输出的隐状态,来和输入拼接,再输入到Decoder中。但这就存在问题就是例如hello world进行翻译,第一个翻译出来的法语应该是和hello这个单词对应的隐状态输出息息相关的,然后后面的法语应该是和world对应的息息相关的,如下图:
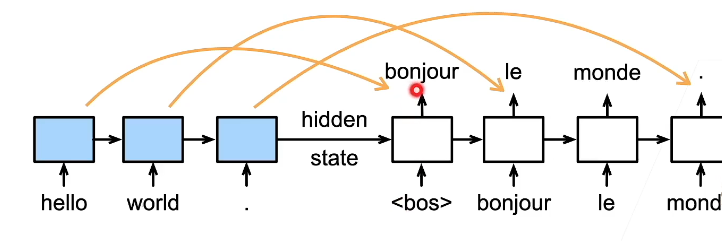
但是我们的机制并不能够注意到这一点,而是直接将浓缩到最后的隐状态拿来使用。
那么我们引入注意力机制来实现这个目的,具体的做法就是:
- 将原先我们用于和输入进行拼接的隐状态作为查询\(q\),将Encoder的最后一层的所有时间步的隐状态输出作为键值\(k、v\)(注意两者是一模一样的)
- 然后用\(q、k、v\)输入到注意力机制当中,也就是说将本来的q,去Encoder中变换成和它比较接近的,有接近意义的v。
- 然后再将新得到的隐状态和输入拼接进行输入
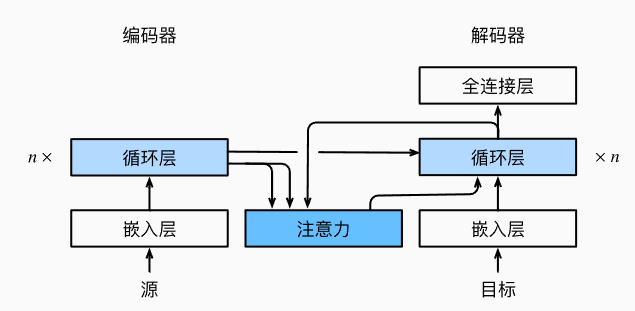
import torch
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
# 定义带有注意力机制解码器的基本接口,这部分我也不太理解其意义所在
#@save
class AttentionDecoder(d2l.Decoder):
"""带有注意力机制解码器的基本接口"""
def __init__(self, **kwargs):
super(AttentionDecoder, self).__init__(**kwargs)
@property
def attention_weights(self):
raise NotImplementedError
# 实现带有注意力机制的循环神经网络解码器,因为编码器和之前是一模一样的
class Seq2SeqAttentionDecoder(AttentionDecoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqAttentionDecoder,self).__init__(**kwargs)
self.attention = d2l.AdditiveAttention(num_hiddens,num_hiddens, num_hiddens,
dropout)
# 这里注意力机制的q,k,v,三者都是同样的形状,q就可以认为是当前解码器时间步的输入
# 而k和v就固定为编码器所有时间步的最后一层隐藏层的输出,k和v是一样的东西,q,v,k三者是相同空间
# 因为我是根据q去查询,编码器输出空间的隐状态,根据相似程度,输出最终也需要是q这种形状的
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.GRU(embed_size+num_hiddens, num_hiddens, num_layers, dropout=dropout)
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
outputs, hidden_state = enc_outputs
# outputs是所有时间步的最后一层的隐状态输出
# hidden_state是最后一个时间步的所有层的隐状态输出
return (outputs.permute(1,0,2), hidden_state, enc_valid_lens)
def forward(self, X, state):
enc_outputs, hidden_state, enc_valid_lens = state
# 第一个形状为(批量数,时间步, num_hiddens)
# 第二个形状为(隐层数,批量数,num_hiddens)
X = self.embedding(X).permute(1,0,2)
outputs, self._attention_weights = [],[]
for x in X:
query = torch.unsqueeze(hidden_state[-1], dim=1)
# 第一次就是取出最后一层的最后一个时间步的隐状态,然后加入一个维度(batch_size,1,num_hiddens)
# 第二次就是更新得到的隐状态去查询了
context = self.attention(query, enc_outputs, enc_outputs, enc_valid_lens)
# 这步就是用这个隐状态去编码器的所有隐状态输出中查询,然后转换计算分数、权重等
# value还是隐状态,因为我们希望得到的还是一个隐状态的输出
x = torch.cat((context, torch.unsqueeze(x,dim=1)), dim=-1)
# 将得到的新的隐状态和输入拼接在一起
out, hidden_state = self.rnn(x.permute(1,0,2), hidden_state)
# 这一步就计算输出并更新隐状态
outputs.append(out)
self._attention_weights.append(self.attention.attention_weights)
# 此时outputs形状为batch_size, num_steps, num_hiddens
outputs = self.dense(torch.cat(outputs, dim=0))
# 此时outputs形状为num_steps, batch_size, vocab_size
return outputs.permute(1,0,2),[enc_outputs, hidden_state, enc_valid_lens]
@property
def attention_weights(self):
return self._attention_weights
if __name__ == "__main__":
encoder = d2l.Seq2SeqEncoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
encoder.eval()
decoder = Seq2SeqAttentionDecoder(vocab_size=10, embed_size=8, num_hiddens=16,
num_layers=2)
decoder.eval()
X = torch.zeros((4, 7), dtype=torch.long) # (batch_size,num_steps)
state = decoder.init_state(encoder(X), None)
output, state = decoder(X, state)
print("output.shape=\t",output.shape)
print("len(state)=\t",len(state))
print("state[0].shape=\t",state[0].shape)
print("len(state[1]), state[1][0].shape = \t",len(state[1]), state[1][0].shape)
embed_size, num_hiddens, num_layers, dropout = 32, 32, 2, 0.1
batch_size, num_steps = 64, 10
lr, num_epochs, device = 0.005, 250, d2l.try_gpu()
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = d2l.Seq2SeqEncoder(
len(src_vocab), embed_size, num_hiddens, num_layers, dropout)
decoder = Seq2SeqAttentionDecoder(
len(tgt_vocab), embed_size, num_hiddens, num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
plt.show()
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, dec_attention_weight_seq = d2l.predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device, True)
print(f'{eng} => {translation}, ',
f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
attention_weights = torch.cat([step[0][0][0] for step in dec_attention_weight_seq], 0).reshape((
1, 1, -1, num_steps))
# 加上一个包含序列结束词元
d2l.show_heatmaps(
attention_weights[:, :, :, :len(engs[-1].split()) + 1].cpu(),
xlabel='Key positions', ylabel='Query positions')
plt.show()
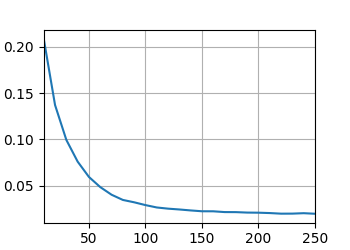
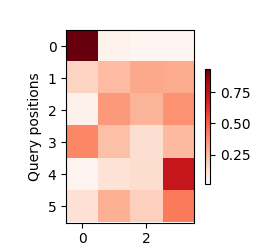
output.shape= torch.Size([4, 7, 10])
len(state)= 3
state[0].shape= torch.Size([4, 7, 16])
len(state[1]), state[1][0].shape = 2 torch.Size([4, 16])
loss 0.020, 4975.5 tokens/sec on cuda:0
go . => va !, bleu 1.000
i lost . => j'ai perdu ., bleu 1.000
he's calm . => il est suis ., bleu 0.658
i'm home . => je suis chez moi ., bleu 1.000
可见效果有所提升。
小结:
- 在预测词元时,如果不是所有输入词元都是相关的,那么具有Bahdanau注意力的循环神经网络编码器-解码器会有选择地统计输入序列的不同部分。这是通过将上下文变量视为加性注意力池化的输出来实现的。
- 在循环神经网络编码器-解码器中,Bahdanau注意力将上一时间步的解码器隐状态视为查询,在所有时间步的编码器隐状态同时视为键和值。
自注意力与位置编码
首先关注什么是自注意力机制
自注意力机制指的是:给定一个序列\(x_1,...,x_n(x_i\in R^d)\),那么自注意力池化层将\(x_i\)当成key、value、query来对序列抽取特征得到\(y_1,...,y_n\),即:
也就是它不需要像前述的Encoder和Decoder结构,只需要输入序列即可。
那么比较一下能够提取序列信息的几种结果:CNN、RNN、自注意力
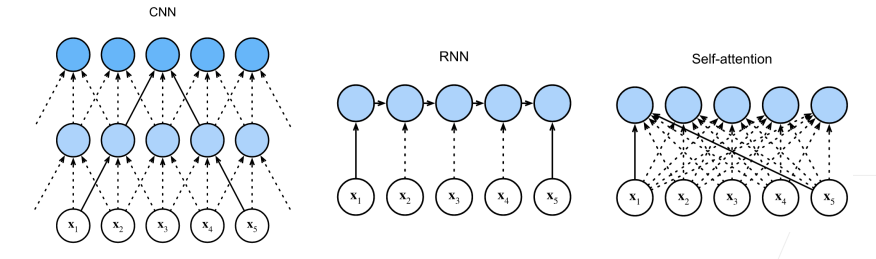
| CNN | RNN | 自注意力 | |
|---|---|---|---|
| 计算复杂度 | O(knd^2) | O(nd^2) | O(n^2d) |
| 并行度 | O(n) | O(1) | O(n) |
| 最长路径 | O(n/k) | O(n) | O(1) |
可以看到因为自注意力机制是每个输入\(x_i\)都要和全部序列进行计算,因此它的时间复杂度是\(n^2\)级别的,因此是相当高的,但是因为它的计算没有像RNN一样的先后顺序,因此其并行度同样也比较高。而最长路径指的是序列的第一个样本要经过多少次计算才能够将信息与最后一个样本结果,那么因为自注意力一开始就全部进行了计算,因此其最长路径为1。
而有一个非常重要的特征,就是自注意力其实并没有记录位置信息,因为假设把输入序列中的几个样本调换位置,那么它们所产生的输出也只是调换了位置而已,内容并不会发生变化,因此需要将位置的信息加入到其中。
而为了保持自注意力机制的长序列读取能力、并行能力,决定用位置编码将位置信息注入到输入中,即假设长度为n的序列\(\pmb{X}\in R^{n\times d}\),位置编码矩阵为\(\pmb{P}\in R^{n\times d}\),将\(\pmb{X+P}\)作为自注意力机制的输入。因此我们只需要选择如何计算位置编码矩阵即可,通常其计算为:
使用这种编码存在的好处为位于\(i+\delta\)处的位置编码可以线性投影到位置\(i\)处的位置编码,它们之间存在关系可以相关表示为:
即假设两个样本想个\(\delta\),那么不管它们在序列中的什么位置,只要保持住相隔的大小,那么它们之间的相互信息可以认为是不变的。
多头注意力
在实际中,我们希望当给定相同的查询、键和值的集合时,模型可以基于同样的注意力机制学习到不同的行为或特征,再将这些不同的行为特征当成知识组合起来,捕获序列中各种范围的依赖关系(例如同时捕获到长距离依赖和短距离依赖)。那么要实现这个效果,就需要注意力机制组合使用查询、键和值的不同子空间表示来进行学习。
那么具体的实现方法是用独立学习得到的h组不同的线性投影来对查询、键和值进行变化(用全连接层映射到较低的维度),再将h组变换后的查询、键和值并行地送入到注意力汇聚之中,最后将这h个注意局汇聚得到的输出进行拼接,再经过另外一个可学习的线性投影进行变换,产生最终输出,这种结构称为多头注意力。如下图:
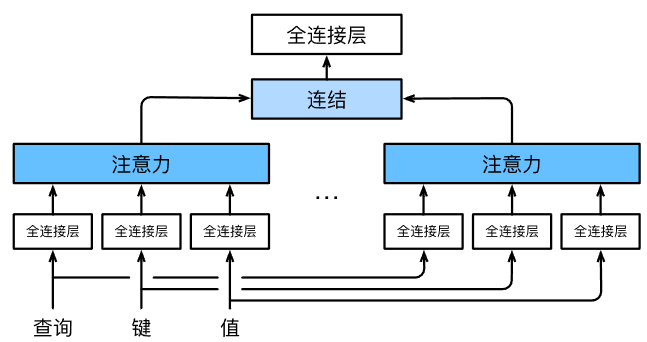
那么其数学语言为:
给定\(q\in R^{d_q}、k\in R^{d_k}、v\in R^{d_v}\),每个注意力头\(h_i(i=1,...,h)\)计算方法为:
\[h_i=f(W_i^{(q)}q,W^{(k)}_ik,W^{(v)}_iv)\in R^{p_v} \]再经过另外一个线性变换\(W_o\in R^{p_o\times h p_v}\)得到最终的输出:
\[W_o\left[ \begin{matrix} h_1\\ ...\\ h_h \end{matrix} \right] \in R^{p_o} \]
import math
import torch
from torch import nn
from d2l import torch as d2l
#@save
def transpose_qkv(X, num_heads):
"""为了多注意力头的并行计算而变换形状"""
# 输入X的形状:(batch_size,查询或者“键-值”对的个数,num_hiddens)
# 输出X的形状:(batch_size,查询或者“键-值”对的个数,num_heads,
# num_hiddens/num_heads)
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
# 输出X的形状:(batch_size,num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
X = X.permute(0, 2, 1, 3)
# 最终输出的形状:(batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
# 这是为了方便在多个头中进行并行计算而设置的
return X.reshape(-1, X.shape[2], X.shape[3])
#@save
def transpose_output(X, num_heads):
"""逆转transpose_qkv函数的操作"""
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
X = X.permute(0, 2, 1, 3)
# 我们最后要把多个头的堆叠在一起的,跟单个一样的形式的
return X.reshape(X.shape[0], X.shape[1], -1)
#@save
class MultiHeadAttention(nn.Module):
"""多头注意力"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = d2l.DotProductAttention(dropout)
# 这里为什么没有分成num_heads份,是因为我并行计算的
# 可以认为原来100个nun_hiddens,5个num_heads
# 那么我输入就通过线性变换,每个头的输入都变成特征为20
# 处理完之后每个也是特征为20,那么再5个在特征维度叠加起来
# 然后直接输入进行变换即可
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
# queries,keys,values的形状:
# (batch_size,查询或者“键-值”对的个数,num_hiddens)
# valid_lens 的形状:
# (batch_size,)或(batch_size,查询的个数)
# 经过变换后,输出的queries,keys,values 的形状:
# (batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
if valid_lens is not None:
# 在轴0,将第一项(标量或者矢量)复制num_heads次,
# 然后如此复制第二项,然后诸如此类。
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0)
# output的形状:(batch_size*num_heads,查询的个数,
# num_hiddens/num_heads)
output = self.attention(queries, keys, values, valid_lens)
# output_concat的形状:(batch_size,查询的个数,num_hiddens)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat)
# 位置编码的实现
#@save
class PositionalEncoding(nn.Module):
"""位置编码"""
def __init__(self, num_hiddens, dropout, max_len=1000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(dropout)
# 创建一个足够长的P
self.P = torch.zeros((1, max_len, num_hiddens))
X = torch.arange(max_len, dtype=torch.float32).reshape(
-1, 1) / torch.pow(10000, torch.arange(
0, num_hiddens, 2, dtype=torch.float32) / num_hiddens)
# 就是三角函数里面那个数值
self.P[:, :, 0::2] = torch.sin(X) # 从1到最后,间隔为1
self.P[:, :, 1::2] = torch.cos(X) # 从0到最后,间隔为2
def forward(self, X):
X = X + self.P[:, :X.shape[1], :].to(X.device)
# 这部分是P固定长度,X不固定,每次在P中截取X的长度即可
return self.dropout(X)
Transformer
这一节学习的是重要的Transformer架构,因为我觉得李沐老师讲得可能不够通俗易懂,因此我将结合李宏毅老师的课程来进行讲解。
总体的结构图如下:
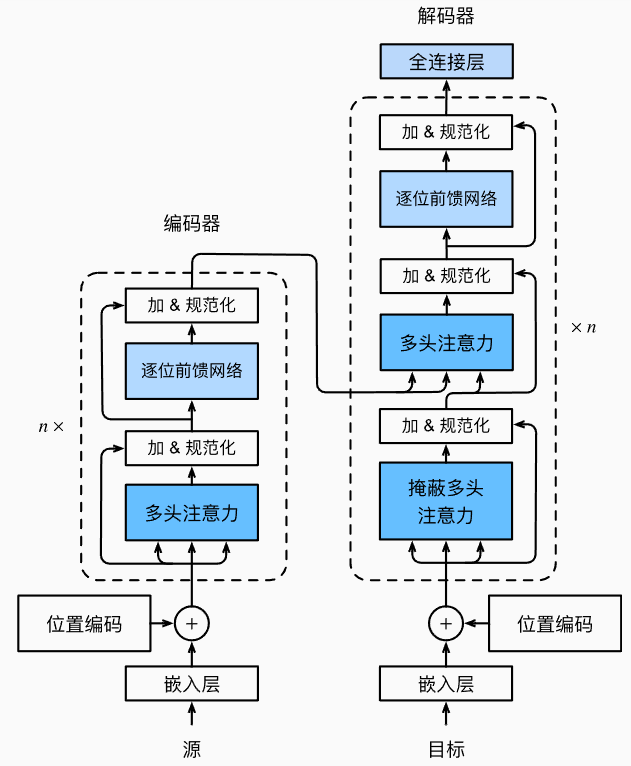
Transformer类似于seq2seq模型,也是一个Encoder和一个Decoder,将输入的向量给Encoder进行处理,处理后的结果交给Decoder,由Decoder来决定应该输出一个什么样的向量。
那么接下来我们对其中的模块一一讲解。
多头注意力
这部分我在上一节讲过,请观看上一节的内容。
掩码多头注意力
这部分是因为在进行预测时,我们只能够知道当前时刻以及之前时刻的各种信息,我们并不能够知道未来时刻的输入信息,这个Encoder中是不一样的,因此在做attention时,在这里我们需要根据当前的时刻,为后面时刻的内容加上掩码,防止我们提前用到了未来的信息,具体可以看下面这两张图的区别:
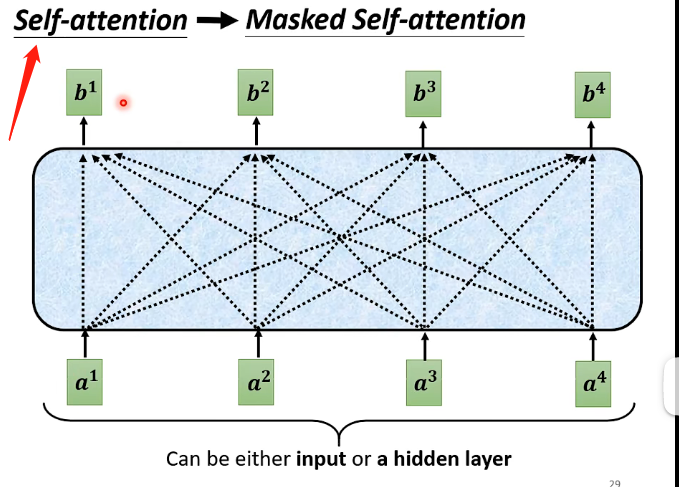
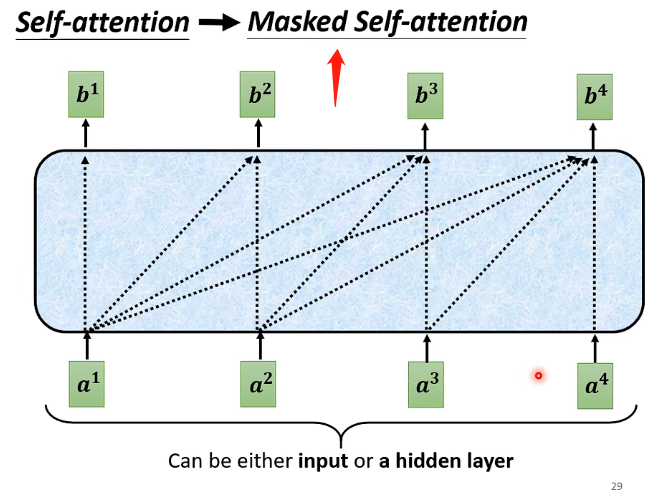
我觉得李宏毅老师的这两张图片形容非常恰当,很容易理解。
加&规范化
首先加就是利用了残差连接网络的思想,即每个样本输入到attention后得到的向量需要加上输入,才能够构成输出。
那么规范化值得深究,常见的规范化例如批量归一化和层归一化,下面来探讨它们在此处应用的区别:
- 批量归一化:就可以认为我对当前这个批量(句子),它里面含有len个样本(len个词语),每个词语的维度为d,那么我是对每一个维度进行归一化,这是我们常见的做法,对每个维度都归一化到均值为0方差为1。但这里存在的问题是每个句子长度会变(len会变),那么不同长度的句子它们自己进行归一化,可能会使得效果不好。
- 层归一化:它这里跟我们之前普遍的认识不同,它是对单个样本进行归一化,即对单个样本的d个维度计算均值方差然后归一化,虽然我们认为这不同维度之间可能存在不同的数量级关系等等问题,但是在这种场合下,这种方法确实能够克服len不同所带来的差异,并且效果较好。
因此此处的规范化采用的是层归一化。
基于位置的前馈网络
这部分实际上就是一个全连接层。经过前面的规范化后得到的输入形状为\((batch\_size, num\_len, dimention)\),那么要放入全连接层通常要求维度是2维,在以前我们的处理是将转换为\((batch\_size,num\_len*dimention)\),但是在这里的问题是因为\(num\_len\)会变,如果这样处理就意味着全连接层的输入维度会发生变化,这是不行的,因此这里的做法是转换为\((batch\_size*num\_len,dimention)\),保证输入维度不发生变化, 是个数发生变化,再经过一个全连接层+ReLU+全连接层后再换回来\((batch\_size, num\_len, dimention^{\prime})\)。
信息传递——Decoder中的多头注意力
可以看到在Decoder中的多头注意力其输入箭头两个来自于Encoder的输出,一个来自于自己的输出。那么其具体做法为将Encoder的输出(最后一层)\(y_1,...,y_n\)作为这个attention的键和值,而查询就来自于Decoder的目标序列经过掩码多头注意力的输出(经过规范化),同时这也意味着Encoder和Decoder中输出维度是一致的。
老师这里指出它们的块的个数是一致的,可能是认为是将每一个块的编码器的输出作为解码器对应块的该attention的键和值,那么在李宏毅老师的讲解中它强调虽然这部分有争议,但是大部分还是只用编码器最后一块的输出,来作为解码器每一块的键和值。
预测注意要点
在预测时,我们是将词一个一个的输入,也就是当输入到第\(t\)个样本时,由于时序的特征,我们在进行attention时,是将前\(t-1\)个样本作为键和值,而第\(t\)个样本作为键和值还有查询,然后得到第\(t\)个样本对应的输出的。
import math
import pandas as pd
import torch
from matplotlib import pyplot as plt
from torch import nn
from d2l import torch as d2l
# 基于位置的前馈网络的实现
class PositionWiseFFN(nn.Module):
def __init__(self, ffn_num_input, ffn_num_hiddens, ffn_num_outputs,**kwargs):
super(PositionWiseFFN, self).__init__(**kwargs)
self.dense1 = nn.Linear(ffn_num_input, ffn_num_hiddens)
# 输入是三个维度,但是pytorch默认将前两个合并,就达到我们的目的了
self.relu = nn.ReLU()
self.dense2 = nn.Linear(ffn_num_hiddens, ffn_num_outputs)
def forward(self,X):
return self.dense2(self.relu(self.dense1(X)))
# 残差连接与层规范化
class AddNorm(nn.Module):
def __init__(self, normalized_shape, dropout, **kwargs):
super(AddNorm, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
self.ln = nn.LayerNorm(normalized_shape)
def forward(self, X, Y):
return self.ln(self.dropout(Y)+X)
# 实现编码器的块
class EncoderBlock(nn.Module):
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, use_bias=False, **kwargs):
super(EncoderBlock, self).__init__(**kwargs)
self.attention = d2l.MultiHeadAttention(key_size, query_size,
value_size, num_hiddens, num_heads,
dropout, use_bias)
self.addnorm1 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens)
self.addnorm2 = AddNorm(norm_shape, dropout)
def forward(self, X, valid_len):
Y = self.addnorm1(X, self.attention(X,X,X,valid_len))
return self.addnorm2(Y,self.ffn(Y))
# 实现编码器
class TransformerEncoder(d2l.Encoder):
def __init__(self, vocab_size, key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input, ffn_num_hiddens,
num_heads, num_layers, dropout, use_bias=False, **kwargs):
super(TransformerEncoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
# 词嵌入第一个参数为我们有多少个需要表示的词,第二个为我们要用多少个维度来表示一个单词
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module("block"+str(i),
EncoderBlock(key_size, query_size, value_size,
num_hiddens,norm_shape,ffn_num_input,
ffn_num_hiddens,num_heads,dropout,
use_bias))
def forward(self, X, valid_len, *args):
# 因为位置编码值在-1和1之间,而embedding通常会将d维度变成范数为1,那么就可能d大的时候元素大小很小
# 因此嵌入值乘以嵌入维度的平方根进行缩放,使得差不多跟位置编码大小
# 然后再与位置编码相加。
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self.attention_weights = [None] * len(self.blks)
for i, blk in enumerate(self.blks):
X = blk(X, valid_len) # 计算该块的输出并作为下一层的输入
self.attention_weights[i] = blk.attention.attention.attention_weights
return X
# 实现解码器块
class DecoderBlock(nn.Module):
def __init__(self, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,
dropout, i, **kwargs):
super(DecoderBlock, self).__init__(**kwargs)
self.i = i
self.attention1 = d2l.MultiHeadAttention(key_size, query_size, value_size,
num_hiddens, num_heads, dropout)
self.addnorm1 = AddNorm(norm_shape,dropout)
self.attention2 = d2l.MultiHeadAttention(key_size, query_size, value_size,
num_hiddens, num_heads, dropout)
self.addnorm2 = AddNorm(norm_shape, dropout)
self.ffn = PositionWiseFFN(ffn_num_input, ffn_num_hiddens, num_hiddens)
self.addnorm3 = AddNorm(norm_shape, dropout)
def forward(self, X, state):
# 前两个分别为编码器的输出和有效长度
enc_outputs, enc_valid_lens = state[0],state[1]
# 训练阶段,输出序列的所有词元都在同一时间处理,
# 因此state[2][self.i]初始化为None。
# 预测阶段,输出序列是通过词元一个接着一个解码的,
# 因此state[2][self.i]包含着直到当前时间步第i个块解码的输出表示
if state[2][self.i] is None:
key_values = X
else:
key_values = torch.cat((state[2][self.i], X), axis=1)
# 在预测时存储着当前时间步包括之前的x,来作为key和value
state[2][self.i] = key_values # 更新
if self.training:
batch_size, num_steps, _ = X.shape
# dec_valid_lens的开头:(batch_size,num_steps),用来做掩码attention
# 其中每一行是[1,2,...,num_steps]
dec_valid_lens = torch.arange(1, num_steps+1, device=X.device).repeat(batch_size,1)
else:
dec_valid_lens = None # 在预测的时候不关心这个,因为是一个一个进来的
X2 = self.attention1(X, key_values, key_values, dec_valid_lens)
Y = self.addnorm1(X,X2)
Y2 = self.attention2(Y, enc_outputs, enc_outputs, enc_valid_lens)
Z = self.addnorm2(Y,Y2)
return self.addnorm3(Z,self.ffn(Z)), state
# 完成的transformer解码器
class TransformerDecoder(d2l.AttentionDecoder):
def __init__(self,vocab_size, key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers,
dropout, **kwargs):
super(TransformerDecoder, self).__init__(**kwargs)
self.num_hiddens = num_hiddens
self.num_layers = num_layers
self.embedding = nn.Embedding(vocab_size, num_hiddens)
self.pos_encoding = d2l.PositionalEncoding(num_hiddens, dropout)
self.blks = nn.Sequential()
for i in range(num_layers):
self.blks.add_module("block"+str(i), DecoderBlock(key_size, query_size, value_size,
num_hiddens, norm_shape, ffn_num_input,
ffn_num_hiddens, num_heads, dropout, i))
self.dense = nn.Linear(num_hiddens, vocab_size)
def init_state(self, enc_outputs, enc_valid_lens, *args):
return [enc_outputs, enc_valid_lens, [None]*self.num_layers]
def forward(self, X, state):
X = self.pos_encoding(self.embedding(X) * math.sqrt(self.num_hiddens))
self._attention_weights = [[None] * len(self.blks) for _ in range(2)]
for i, blk in enumerate(self.blks):
X, state = blk(X, state)
self._attention_weights[0][
i] = blk.attention1.attention.attention_weights
# “编码器-解码器”自注意力权重
self._attention_weights[1][
i] = blk.attention2.attention.attention_weights
return self.dense(X), state
@property
def attention_weights(self):
return self._attention_weights
if __name__ == "__main__":
num_hiddens, num_layers, dropout, batch_size, num_steps = 32, 2, 0.1, 64, 10
lr, num_epochs, device = 0.005, 200, d2l.try_gpu()
ffn_num_input, ffn_num_hiddens, num_heads = 32, 64, 4
key_size, query_size, value_size = 32, 32, 32
norm_shape = [32]
train_iter, src_vocab, tgt_vocab = d2l.load_data_nmt(batch_size, num_steps)
encoder = TransformerEncoder(len(src_vocab), key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads,num_layers, dropout)
decoder = TransformerDecoder(len(tgt_vocab), key_size, query_size, value_size, num_hiddens,
norm_shape, ffn_num_input, ffn_num_hiddens, num_heads, num_layers, dropout)
net = d2l.EncoderDecoder(encoder, decoder)
d2l.train_seq2seq(net, train_iter, lr, num_epochs, tgt_vocab, device)
plt.show()
engs = ['go .', "i lost .", 'he\'s calm .', 'i\'m home .']
fras = ['va !', 'j\'ai perdu .', 'il est calme .', 'je suis chez moi .']
for eng, fra in zip(engs, fras):
translation, dec_attention_weight_seq = d2l.predict_seq2seq(
net, eng, src_vocab, tgt_vocab, num_steps, device, True)
print(f'{eng} => {translation}, ',
f'bleu {d2l.bleu(translation, fra, k=2):.3f}')
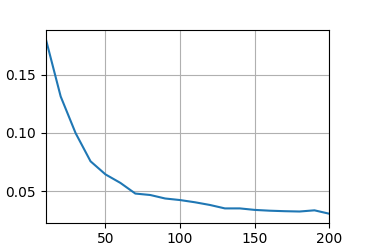
loss 0.031, 4096.8 tokens/sec on cuda:0
go . => va !, bleu 1.000
i lost . => je perdu ., bleu 0.687
he's calm . => il est calme ., bleu 1.000
i'm home . => je suis chez moi ., bleu 1.000
很多次预测的BELU都达到了1.0。
小结:
- transformer是编码器-解码器架构的一个实践,尽管在实际情况中编码器或解码器可以单独使用。
- 在transformer中,多头自注意力用于表示输入序列和输出序列,不过解码器必须通过掩蔽机制来保留自回归属性。
- transformer中的残差连接和层规范化是训练非常深度模型的重要工具。
- transformer模型中基于位置的前馈网络使用同一个多层感知机,作用是对所有序列位置的表示进行转换。
自然语言处理:预训练
要理解文本,我们应该先学习它如何进行表示。利用来自大型语料库的现有文本序列,我们可以通过自监督学习来预训练文本表示,例如通过使用周围文本的其他部分来预测文本的隐藏部分,这样模型可以在海量数据中学习信息, 而不需要昂贵的标签标注。
词嵌入(Word2vec)
将单词映射到实向量的技术称为词嵌入。
在之前我们用过one-hot编码来进行表示,但虽然one-hot编码很容易构建,但它们并不是一个很好的选择,因为独特向量不能够准确表达不同词之间的相似度,例如计算相似度的“余弦相似度”,对于两个向量,它们之间的相似度就是它们角度的余弦:
但是独热编码任意两个不同的词向量之间计算余弦相似度都为0,因此它不能够编码词之间的相关性。
由于上述问题,因此诞生了word2vec工具,它将每个词映射到一个固定长度的向量,这些向量可以更好地表示不同次之间的相似性和类比关系。其包含两个模型,即跳元模型和连续词袋,都属于自监督模型。下面将进行简要介绍。
跳元模型(Skip-Gram)
该模型假设一个词可以用来在文本序列中生成其周围的单词,例如文本序列"the man loves his son",假设中心词选择"love",其上下窗口设置为2,那么跳元模型考虑生成其上下文词的条件概率为:
而若再假设上下文词都是给定中心词的情况下独立生成的,可写成:
在跳元模型中,每个词都有两个d维向量来表示,对于词典中索引为i的任何词,分别用$v_i\in R^d、u_i\in R^d \(来表示其用作中心词和上下文词时的两个向量。那么假设给定中心词\)w_c\(,生成其上下文词\)w_o$,条件概率计算为:
其中V是所有词典的意思。那么前面我们也提到上下文窗口的意义,因此给定长度为T的文本序列,假设上下文词是在给定任何中心词的情况下独立生成的,那么对于上下文窗口m,跳元模型的似然函数就是在给定任何中心词的情况下生成所有上下文词的概率:
在训练时也是通过最大化似然函数来学习模型参数。
连续词袋(CBOW)
它与跳元模型最主要的区别在于其假设中心词是基于其在文本序列中的周围上下文词所生成的,即:
而由于对单个词的生成存在多个上下文词,因此需要取平均。对于字典中索引为i的任意词,用$v_i\in R^d、u_i\in R^d $来表示其用作上下文和中心词时的两个向量(与跳元模型相反),那么:
同样,给定长度为T的文本序列,其似然函数为:
小结:
- 词向量是用于表示单词意义的向量,也可以看作是词的特征向量。将词映射到实向量的技术称为词嵌入。
- word2vec工具包含跳元模型和连续词袋模型。
- 跳元模型假设一个单词可用于在文本序列中,生成其周围的单词;而连续词袋模型假设基于上下文词来生成中心单词。
近似训练
在上一节的讨论中,我们可以发现两种模型的似然函数都含有对完整词典的求和项,这在实际中计算的开销太大,因此需要进行优化。为了降低上述计算的复杂度,下面介绍两种近似训练方法:负采样和分层softmax(以跳元模型为例子)
负采样
负采样首先修改了原目标函数。给定中心词\(w_c\)的上下文窗口,任意上下文词\(w_o\)属于该窗口的被认为是如下事件的概率:
同样似然函数为:
但是这样第一个连乘符号只考虑了位于窗口内的上下文词,可以认为我们在训练时没有考虑负样本,只考虑了正样本,因此我们需要增加负样本来进行学习。
用S来表示上下文词\(w_o\)来自于中心词\(w_c\)的上下文窗口的事件。然后从预定义分布\(P(w)\)中采样K个不是来自于这个上下文窗口的噪声词\(w_k(k=1,2,...,K)\)。用\(N_k\)表示\(w_k\)不是来自于该上下文窗口的事件。因此重写为:
训练以上的似然函数最大化即可。
层序softmax
这一部分比较抽象,简单理解应该就是将计算复杂度降为词表大小的对数级别。
小结:
- 负采样通过考虑相互独立的事件来构造损失函数,这些事件同时涉及正例和负例。训练的计算量与每一步的噪声词数成线性关系。
- 分层softmax使用二叉树中从根节点到叶节点的路径构造损失函数。训练的计算成本取决于词表大小的对数。
本笔记可能存在未记录的章节,我也是舍弃一部分内容的学习,后续有时间会补上的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号