


KTransformers(发音为 Quick Transformers)旨在通过先进的内核优化和放置/并行策略来增强您对 🤗 [Transformers](https://github.com/huggingface/transformers) 的体验。
KTransformers 是一个以 Python 为中心的灵活框架,其核心是可扩展性。通过用一行代码实现并注入优化模块,用户可以获得与 Transformers 兼容的接口、符合 OpenAI 和 Ollama 的 RESTful API,甚至是一个简化的类似 ChatGPT 的 Web 界面。
我们对 KTransformers 的愿景是成为一个用于实验创新 LLM 推理优化的灵活平台。如果您需要任何其他功能,请联系项目方
官方docker部署流程:https://github.com/kvcache-ai/ktransformers/blob/main/doc/en/Docker.md
但里面给的是0.2.1的镜像,部署过程中可能有一些卡壳
以下是使用latest镜像部署安装的流程
准备工作
1、机器资源
根据模型文件的大小,来配置不同的资源。如果资源较小,可以选择小模型,比如deepseek-r1,可以在魔塔社区找
我用的是deepseek-r1-gguf,DeepSeek-R1-Q4_K_M,模型文件大小总共约200多G,
启动后内存占用230G,GPU使用12G左右
2、模型文件
这里需要注意的是,模型文件下载时,不光要下载gguf文件,也要下载相关的配置文件
gguf中可能没有,也可以到deepseek-r1模型中下载,下全了

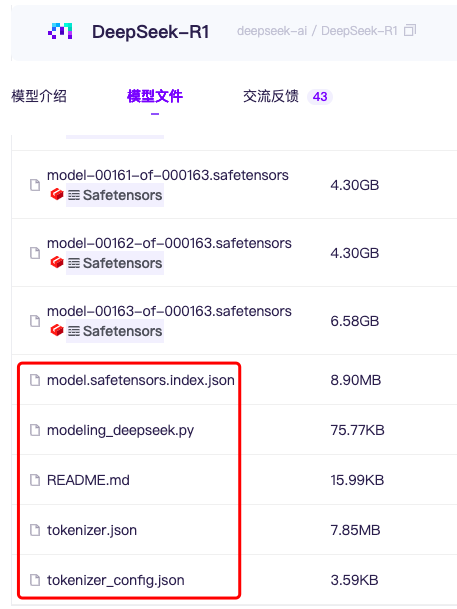
官方建议的模型(https://kvcache-ai.github.io/ktransformers/en/install.html)

2、本地先装好docker
3、选择镜像
到镜像仓库中找镜像的版本,https://docker.mybacc.com/(连不上的话可以找国内的源)。选择适合自己机器的镜像,建议下载最新的版本,因为有其他版本的问题可能都已经修复了
docker pull approachingai/ktransformers:latest-AVX512
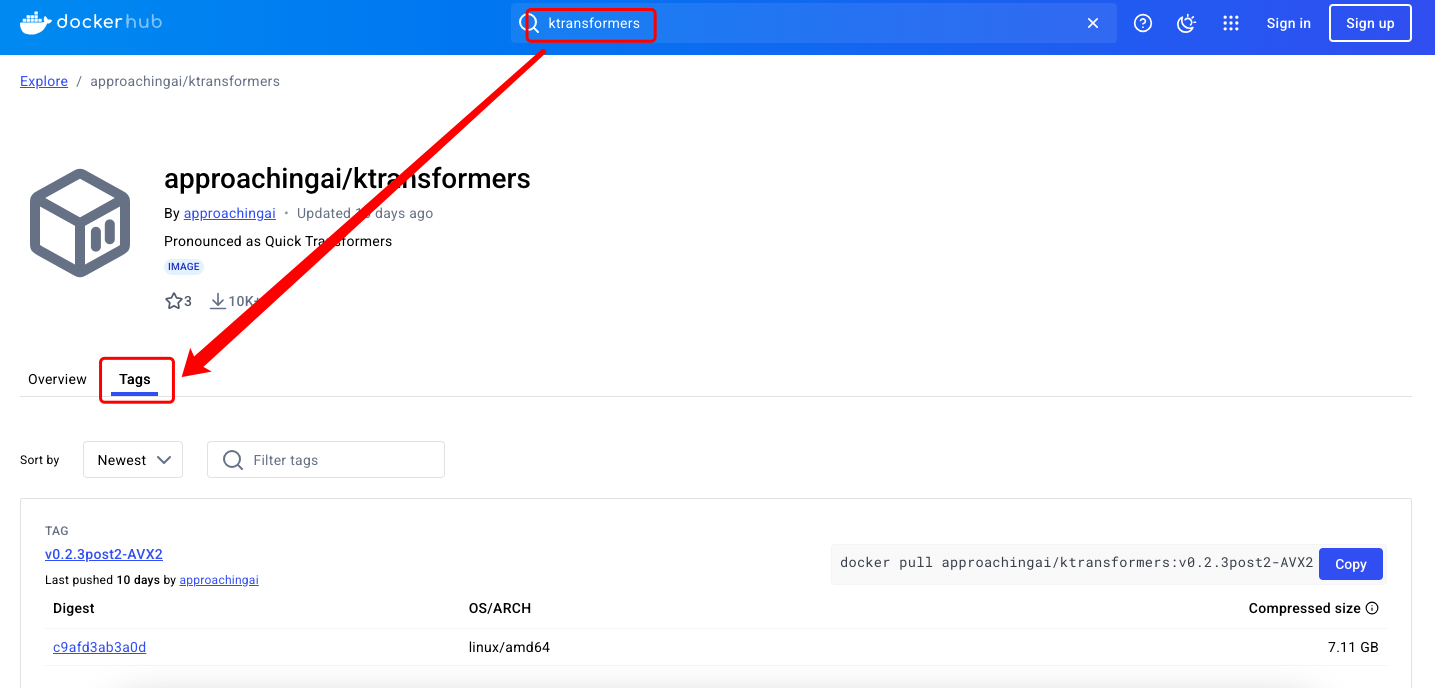
后缀AVX512、AVX2意思是cpu架构相关的信息,在机器中查看cpu(lscpu)找对应的字眼,能找到哪个就下哪个
剩下就简单了,一路执行命令即可
4、启动容器并进入容器
docker run --gpus all -v /path/to/models:/models --name ktransformers -itd approachingai/ktransformers:latest-AVX512
docker exec -it ktransformers /bin/bash
根据需要在run时设置宿主机与容器的映射端口,方便后续用api或者web方式调用
5、容器内进行chat
python -m ktransformers.local_chat --gguf_path /models/path/to/gguf_path --model_path /models/path/to/model_path --cpu_infer 33
启动时需要花费一定时间,耐心等待,启动之后,会进入chat窗口,输入你的内容即可开始
6、通过API方式启动
ktransformers --model_path /models/path/to/model_path --gguf_path /models/path/to/gguf_path --port 10002
启动后,当前窗口会停留在监听状态,通过其他窗口即可进行api调用
7、通过web方式启动,可访问页面
ktransformers --model_path /models/path/to/model_path --gguf_path /models/path/to/gguf_path --port 10002 --web True
启动后,当前窗口会停留在监听状态
网页端访问地址:http://localhost:10002/web/index.html#/chat
需要改website中的配置,默认写死了

ps: 如果有问题,可以在github仓库的issues中查找,基本都有讨论,看的过程中也可以了解很多知识

 浙公网安备 33010602011771号
浙公网安备 33010602011771号