ollama部署与open-webui
1.ollama简介
Ollama 是一款开源工具,允许用户在本地便捷地运行多种大型开源模型,如 DeepSeek、ChatGLM、Llama 等。通过 Docker Compose,我们可以快速部署 Ollama 服务,并结合其他工具(如 Dify 或 Open-WebUI)构建强大的 AI 应用。
2.版本获取
2.1 官网
https://ollama.com/2.2 github
https://github.com/ollama/ollama2.3 镜像获取
https://hub.docker.com/r/ollama/ollama/tags2.4 支持的模型
https://ollama.com/search3.docker-compose部署
version: '3.9'
services:
ollama1:
image: 172.16.4.17:8090/bigmodel/ollama:0.9.6
container_name: ollama-1
restart: always
deploy:
resources:
reservations:
devices:
- driver: nvidia
device_ids: ['0']
capabilities: [gpu]
volumes:
- ./data:/root/.ollama
- ./scripts:/scripts
environment:
# GPU 配置(双保险)
- CUDA_VISIBLE_DEVICES=0
# 网络配置
- OLLAMA_HOST=0.0.0.0:11434
- OLLAMA_ORIGINS=*
# 模型管理
- OLLAMA_MAX_LOADED_MODELS=3
# 并发控制
- OLLAMA_MAX_QUEUE=6
# 性能优化
- OLLAMA_MMAP=1
- OLLAMA_KEEP_ALIVE=30m
# GPU专用优化
- OLLAMA_GPU_LAYERS=35
- OLLAMA_MAX_VRAM=4096 # 显存限制4GB(单位MB)
ports:
- "31434:11434"
security_opt:
- seccomp:unconfined
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:11434"]
interval: 30s
timeout: 5s
retries: 3
start_period: 20s- docker-compose部署参数说明
version: '3.9'
services:
ollama1:
# 镜像配置
image: 172.16.4.17:8090/bigmodel/ollama:0.9.6 # 私有仓库中的Ollama镜像
container_name: ollama-1 # 容器名称标识
restart: always # 容器退出时自动重启
# GPU资源配置(核心配置)
deploy:
resources:
reservations:
devices:
- driver: nvidia # 使用NVIDIA显卡驱动
device_ids: ['0'] # 指定使用GPU 0(单卡)
# 替代方案(使用所有GPU):
# count: all # 使用所有可用GPU
capabilities: [gpu] # 启用GPU计算能力
# 数据卷配置
volumes:
- ./data:/root/.ollama # 模型持久化存储(必需)
- ./scripts:/scripts # 自定义脚本目录(可选)
# 环境变量配置(关键参数)
environment:
# GPU选择
- CUDA_VISIBLE_DEVICES=0 # 指定容器可见的GPU(与device_ids对应)
# 多GPU示例:CUDA_VISIBLE_DEVICES=0,1
# 网络服务配置
- OLLAMA_HOST=0.0.0.0:11434 # 监听所有接口的11434端口
- OLLAMA_ORIGINS=* # 允许所有跨域请求(CORS)
# 资源管理
- OLLAMA_MAX_LOADED_MODELS=3 # 内存中最大模型缓存数(防OOM)
- OLLAMA_MAX_QUEUE=6 # 最大请求队列长度(并发控制)
# 性能优化
- OLLAMA_MMAP=1 # 启用内存映射加速加载
- OLLAMA_KEEP_ALIVE=30m # 模型空闲保留时间(30分钟)
# GPU专项优化
- OLLAMA_GPU_LAYERS=35 # GPU计算层数(调优核心)
- OLLAMA_MAX_VRAM=4096 # 显存限制4096MB(4GB)
# 端口映射
ports:
- "31434:11434" # 主机31434 → 容器11434(避免端口冲突)
# 安全配置
security_opt:
- seccomp:unconfined # 禁用seccomp安全限制(解决线程创建问题)
# 健康检查
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:11434"] # HTTP健康检查
interval: 30s # 检查间隔
timeout: 5s # 超时时间
retries: 3 # 失败重试次数
start_period: 20s # 容器启动后等待时间4.下载模型
4.1 模型选择
- 根据服务器的硬件情况选择自己的模型,如deepseek,由于我的GPU是NVIDIA 2060,显存6G,所以需要选择下列模型,才能使用

4.2 下载模型命令
# 最佳性能平衡(适合编程任务)
ollama pull deepseek-coder:1.3b
# 最佳中文能力(适合对话/创作)
ollama pull deepseek-rlhf:7b-q4_0 --num-gpu-layers 184.3 下载deepseek-coder:1.3b模型
root@ded76a4b1f7c:/# ollama pull deepseek-coder:1.3b
pulling manifest
pulling d040cc185215: 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████▏ 776 MB
pulling a3a0e9449cb6: 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████▏ 13 KB
pulling 8893e08fa9f9: 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████▏ 59 B
pulling 8972a96b8ff1: 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████▏ 297 B
pulling d55c9eb1669a: 100% ▕██████████████████████████████████████████████████████████████████████████████████████████████████████▏ 483 B
verifying sha256 digest
writing manifest
success 4.4 模型命令汇总
- 模型管理命令

- 交互命令
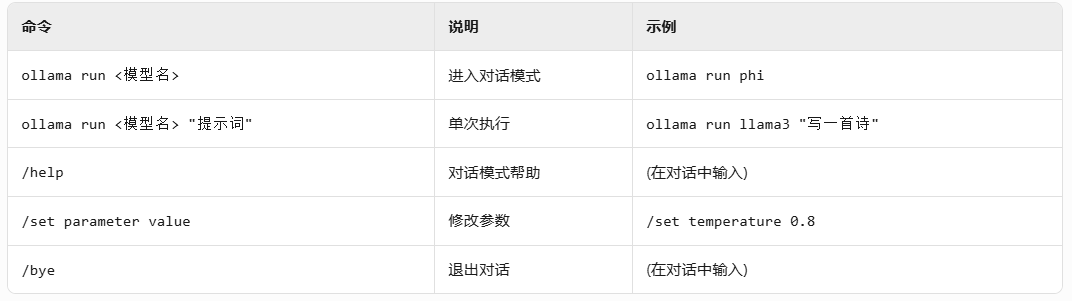
- API服务命令

- 示例:
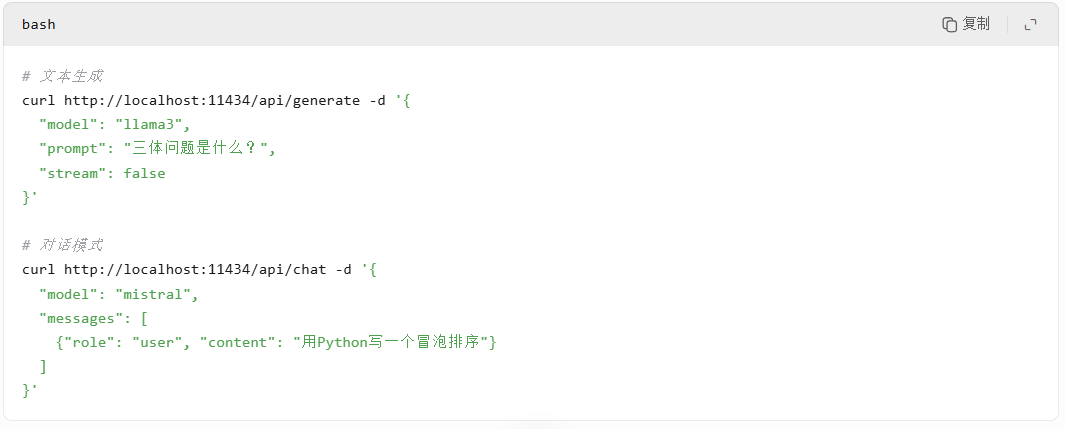
- 系统维护命令
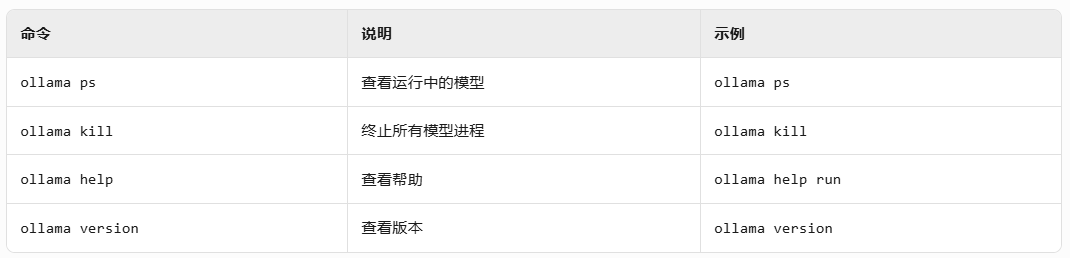
- 常见问题处理
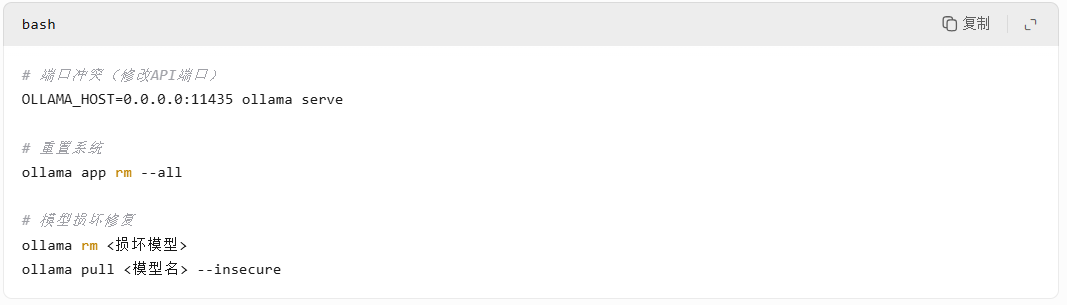
5.模型调用测试
# 深度测试模型能力
ollama run deepseek-coder:1.3b "用Python实现快速排序,添加中文注释"
ollama run deepseek-rlhf:7b-q4_0 "写一篇关于人工智能伦理的短文(300字)"
# 显存监控(另开终端)
watch -n 1 nvidia-smi6.创建模型别名
6.1 创建模型别名
# 1. 下载原始模型
ollama pull deepseek-coder:1.3b
# 2. 创建别名my-deepseek:1.3b
ollama cp deepseek-coder:1.3b my-deepseek:1.3b
# 3. 使用自定义名称
ollama run my-deepseek:1.3b6.2 删除别名的影响
1.删除别名,不影响原始模型的加载和调用
2.删除原始模型名称,不影响别名模型的加载和调用
3.只有当所有引用都被删除后,权重文件才会在运行 ollama prune 时被删除
4.关键理解要点
- 权重文件是共享的,原始模型和别名都指向同一个物理权重文件
- 元数据是独立的,每个"名称"都有自己的配置文件
- 删除操作很克制,ollama rm 只删除元数据,不删除被引用的权重文件
- 引用计数机制,Ollama 内部跟踪权重文件的引用计数:

6.3 安全删除模型
# 删除原始模型(不影响别名)
ollama rm deepseek-coder:1.3b
# 删除别名
ollama rm my-coder
# 清理未引用文件(释放磁盘)
ollama prune
7.open-webui安装
7.1 docker-compose部署open-webui
version: '3.8'
services:
webui:
image: ghcr.io/open-webui/open-webui:main # 纯WebUI镜像
container_name: ollama-webui
ports:
- "3000:8080" # 访问端口:http://IP:3000
volumes:
- ./webui-data:/app/backend/data # 持久化聊天记录/配置
environment:
- OLLAMA_BASE_URL=http://127.0.0.1:31434 # 关键!连接本地Ollama
restart: unless-stopped
security_opt:
- seccomp:unconfineddocker-compose up -d7.2 访问地址:http://IP:3000
- 可以选择自己安装的模型
posted on 2025-10-11 15:27 ExplorerMan 阅读(1380) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号