LMdeploy 执行效率高于VLLM探究
VLLM功能多,开发者多,代码比较容易懂也比较容易修改, 能适配不同的平台
LMdeploy执行效率高,开发者少,文档几乎没有,只支持NVidia
公司实际上线,肯定要博采众长,既要有LMdeploy的执行效率,也要参考VLLM的各种功能实现。
LMdelpoy的执行效率是要高于VLLM的,尤其是对于int4量化的模型,效率能差开30%左右。
下面是网上找到的两个测试图。
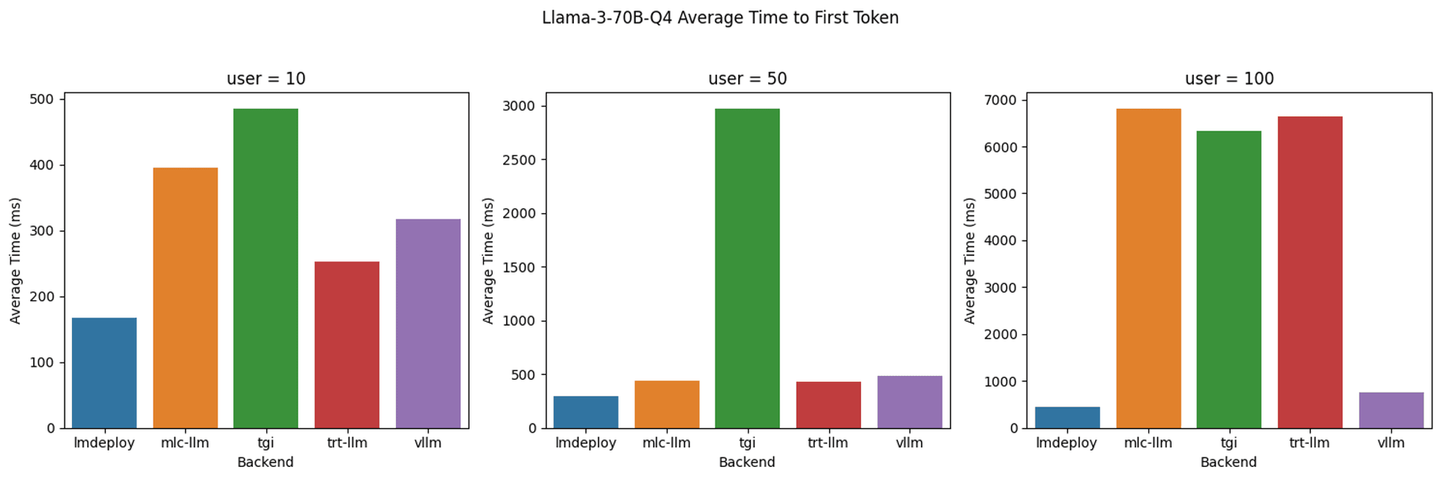
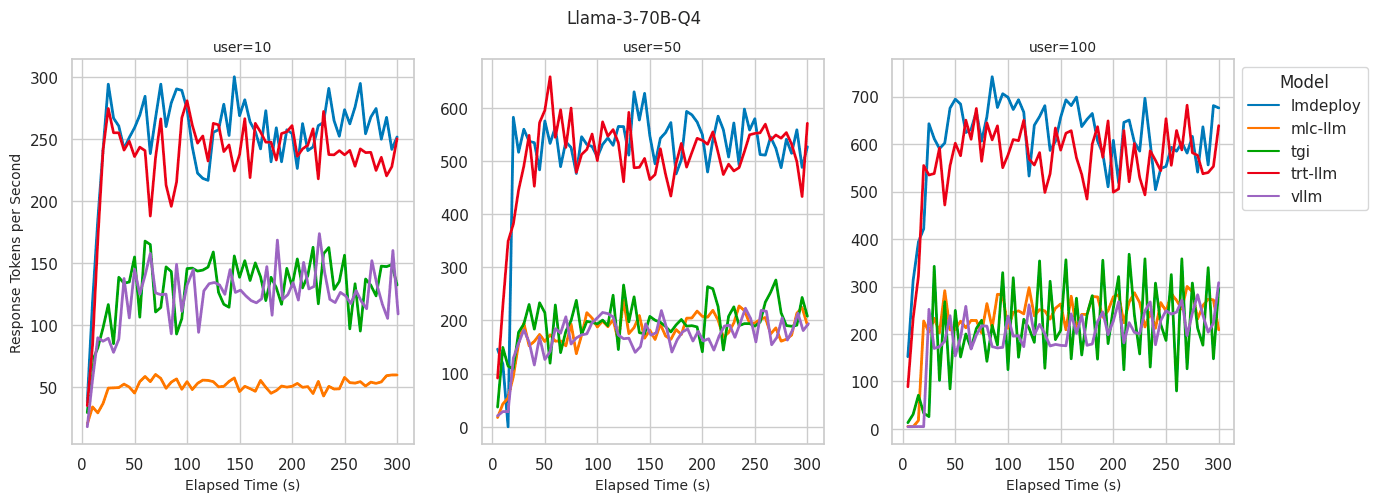
自己测试没有上图差距那么夸张,差距25%左右,可能是网上的测试VLLM的版本比较老。

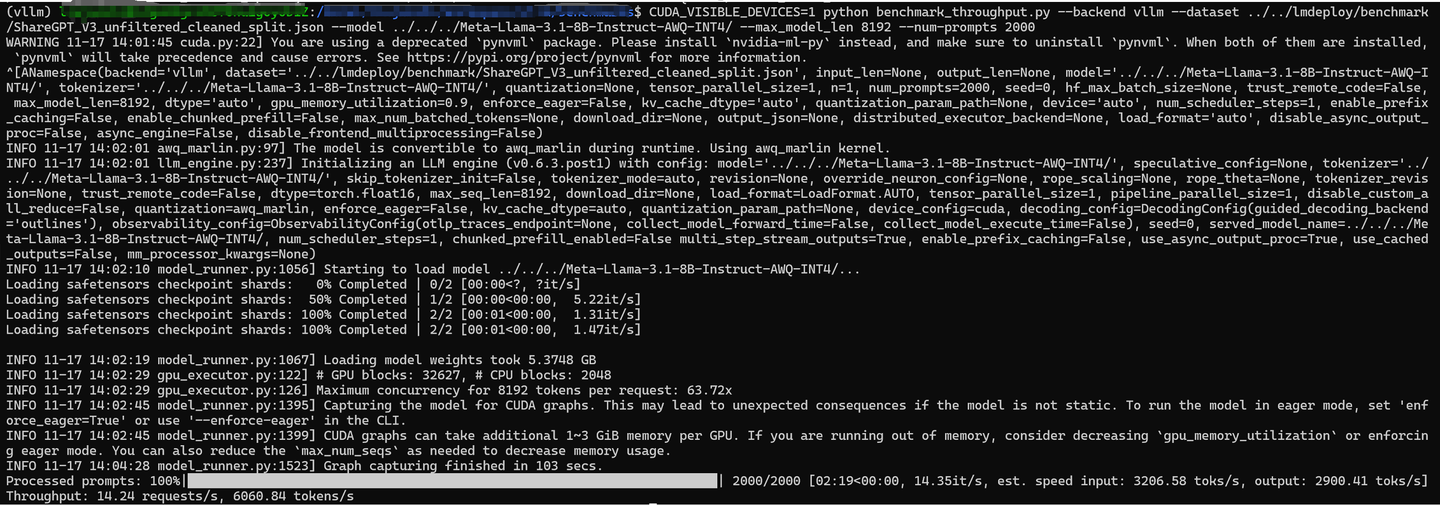
通过查阅资料,代码定位了解到,lmdeploy的后端turbomind执行效率高于vllm的后端,其中最核心的是关于int4量化的实现方式差别。
VLLM对AWQ的模型没有原生支持[强制使用awq模式性能非常差],需要转换成AWQ_marlin,然后调用对应的cuda kernel计算,核心的kernel是gptq_marlin_gemm
turbomind,原生集成了AWQ的kernel,都放在GemmPool里面, 调用的时候gemm->Run,这里拿出了turbomind的linear模块,测试turbomind对于awq int4量化的性能。
下面放2段测试代码,时间关系,不是很严谨, turbomind对于awq int4的执行耗时35s,对比vllm的int4 gemm
执行耗时48s,代码贴在下面了。可以看出两者实现效率确实存在差距。后面文章会通过分析两者底层实现的差距,找到原因。内容会涉及cutlass之类的底层内容。
test_for_turbomind
import torch
import torch.nn as nn
import turbomind as tm
torch.manual_seed(0)
def i32x8_to_i4x8(w):
"""merge 8 integers (range from 0 to 15) into one 32-bit integer."""
assert w.shape[-1] % 8 == 0
shape = (w.shape[0], w.numel() // (w.shape[0] * 8), 8)
shape = shape[:-1] + (1, )
result = torch.zeros(shape, dtype=w.dtype, device=w.device)
mask = torch.tensor([15], dtype=w.dtype, device=w.device)
for i in range(8):
shift = 4 * (7 - i)
result[..., 0] |= (w[..., i] & mask) << shift
result = result.view(w.shape[0], -1)
return result
def makeup_weights(in_features: int, out_features: int, group_size: int = 128):
# make up qweight
assert out_features % 8 == 0
qweight = torch.randint(0,
16, (in_features, out_features // 8, 8),
dtype=torch.int32,
device='cuda')
print(f'-- makeup qweight: shape {qweight.shape}')
print(qweight.view(in_features, -1))
qweight = i32x8_to_i4x8(qweight)
print(