SFT、DPO、RLHF对比
1. 概念与目标
-
SFT(有监督微调):
-
定义:SFT是一种基于标注数据的微调方法,通过最小化模型输出与标注数据之间的差异来优化模型。
-
目标:使模型在特定任务上表现更好,通常用于有明确标注数据的场景。
-
-
DPO(直接偏好优化):
-
定义:DPO是一种基于人类偏好数据的优化方法,通过对比偏好回答和非偏好回答来调整模型。
-
目标:使模型的输出更符合人类偏好,避免了强化学习的复杂性。
-
2. 训练流程
-
SFT:
-
流程:直接使用标注数据进行监督学习,通过交叉熵损失函数优化模型参数。
-
复杂度:训练过程简单,计算成本主要取决于数据规模和模型大小。
-
-
DPO:
-
流程:在SFT的基础上,引入偏好数据和参考模型,通过优化偏好回答的概率来调整模型。
-
复杂度:虽然避免了强化学习的复杂性,但依赖于偏好数据的质量,且需要设计对比学习的损失函数。
-
3. 数据需求
-
SFT:
-
数据类型:需要高质量的标注数据,通常为输入-输出对。
-
数据量:对数据量要求较高,且数据需要覆盖任务的所有场景。
-
-
DPO:
-
数据类型:需要偏好数据,即对同一输入的多个回答进行偏好标注。
-
数据量:偏好数据的规模和质量直接影响模型性能。
-
4. 优势与劣势
-
SFT:
-
优势:简单直接,易于实现和理解,适用范围广。
-
劣势:对未见过的输入可能表现不佳,泛化能力有限。
-
-
DPO:
-
优势:训练过程简单,避免了强化学习的复杂性,模型输出更符合人类偏好。
-
劣势:依赖偏好数据的质量,可能在复杂任务上不如强化学习方法有效。
-
5. 适用场景
-
SFT:
-
适用于有大量标注数据的任务,如文本分类、机器翻译等。
-
-
DPO:
-
适用于需要对齐人类偏好的任务,如对话生成、内容推荐等。
-
总结
以下是读完上述文章后的个人理解,关于Loss、模型向后看的能力以及负反馈
不确定自己的理解是否准确,(o-_-o)
Loss
首先从Loss来看:
SFT的 Loss:
𝐿𝑆𝐹𝑇=−1𝑛∑𝑖=1𝑛𝑙𝑜𝑔𝑃(𝑦𝑖|𝑥<𝑖)
典型的基于概率的损失函数,计算的是模型输出与Label之间的交叉熵损失。
RLHF的 Loss:
𝐿𝑅𝐿𝐻𝐹=−𝐸𝑥∼πθ[𝑅(𝑥)]
其中R是一个预训练好的Reward Model(输入是一个句子, 输出是一个评分),这里为了简化,去掉了KL散度和pretrain模型的部分。
这里可以简单展开一下梯度的公式:
∇θ𝐿𝑅𝐿𝐻𝐹=−𝐸𝑥∼πθ[𝑅(𝑥)∇θ𝑙𝑜𝑔πθ(𝑥)]
SFT的Loss是基于token级别的平均损失,而RLHF的Loss则是根据奖励模型评分加权后的损失。
尽管在 RLHF 中,奖励模型 R(x) 对整个序列的评分是相同的,但在实际的 RLHF 训练过程中,引入了 Critic 模型。Advantage 函数对生成序列中的每个 token 进行加权,这意味着每个 token 获得的奖励是不同的,从而起到了加权的作用。
假设在句子“这个房间很大,面积大约是 20 平方米”中:
- 大约这个房间很大,面积𝑃(“大约”∣“这个房间很大,面积”)的优势函数值 A(s, a) 为 0.6;
- 这个房间很大,面积大约是𝑃(“20”∣“这个房间很大,面积大约是”) 的优势函数值 A(s, a) 为 0.8。
那么,在梯度更新时, 这个房间很大,面积大约是𝑃(“20”∣“这个房间很大,面积大约是”) 的概率增幅将大于 大约这个房间很大,面积𝑃(“大约”∣“这个房间很大,面积”)
向后看的能力
SFT不具备向后看的能力, 𝑃(𝑦𝑖|𝑥<𝑖) 可以看出SFT只能看到当Token前面的句子, 而RLHF由于critic model和reward model都是能看到当前位置后面的句子的,所以RLHF能看到整个句子
这里有一点DPO具备不具备呢? 原文章里写的有,但是我感觉不具备,可以从DPO的Loss函数中看出来:
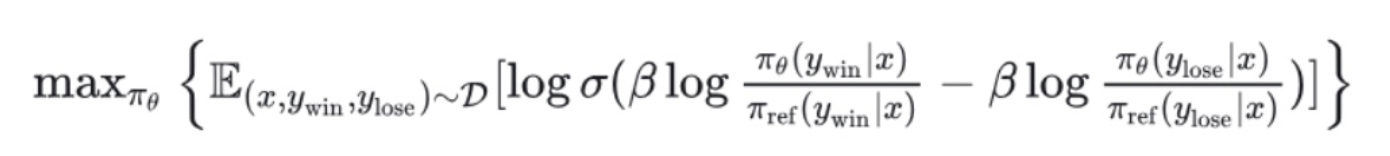
也没有Reward model对整个序列打分,还是只能看到之前的token。
负反馈问题
SFT给的都是正例,没有负反馈。而RLHF会通过给序列一个低分,来给模型一些负反馈,减少生成某个token的概率。那么DPO有没有负反馈呢?DPO会增大正例序列生成的概率,减少负例序列生成的概率(可以看到下面DPO的目标函数) :
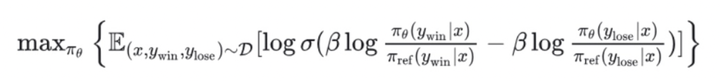
Again 不确定自己的理解是否正确,(o-_-o)
参考
posted on 2025-03-01 00:42 ExplorerMan 阅读(1883) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号