
词频统计
作业要求参照[https://edu.cnblogs.com/campus/nenu/2020Fall/homework/11206]
代码Git地址:https://etherealh.coding.net/public/wf_homework/hanzhichao/git/files/master/wf_homework
词频统计代码如下:
此函数功能读取文件并把文件中特殊字符替换成空字符,把文件中字母转换成小写,再以空字符为间隔分开。
def found_file(file_path):
file_name = open(file_path, "r", encoding="utf-8")
file_txt = file_name.read()
spce = re.compile(u'!@$#%&*,.,.?;:')
file_txt = re.sub(spce,'',file_txt)
file_txt = file_txt.lower()
return file_txt.split()
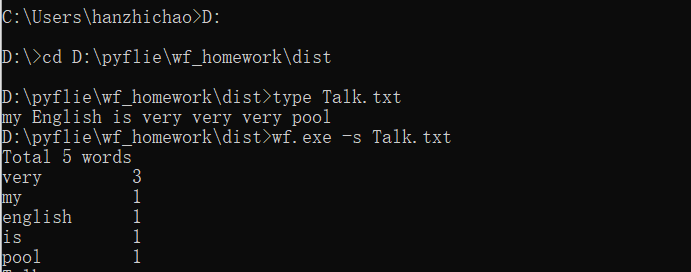
功能1 小文件输入。 为表明程序能跑,结果真实而不是迫害老五,请他亲自键
盘在控制台下输入命令。
运行结果如下:
这两个函数分别用于将单词存放在字典里,输出单词的个数,并且统计前十个单词的频次,第二个函数查找文件是否在路径之内并返回它的路径。
def put_num(word_list,f = True):
d = {}
for list in word_list:
d[list] = d.get(list,0)+1
d_list = sorted(d.items(), key=lambda x: x[1], reverse=True)
print("Total",len(d_list),"words")
for i in range(min(len(d_list),10)):
print("{0:<9}{1:>5}".format(d_list[i][0], d_list[i][1]))
if (f == False):
print("----")
return None
def d_file(file_path):
if (os.path.isdir(file_path) == True):
return os.listdir(file_path)
elif os.path.isfile(file_path) == True:
return [file_path]
return None
重定向代码:
def function_four(file_txt):
spce = re.compile(u'!@$#%&*,.,.?;:')
file_txt = re.sub(spce, '', file_txt)
file_txt = file_txt.lower()
file_txt =file_txt.split()
put_num(file_txt)
return None
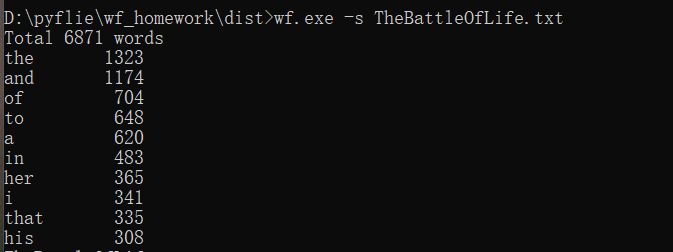
功能2 支持命令行输入英文作品的文件名,请老五亲自录入。
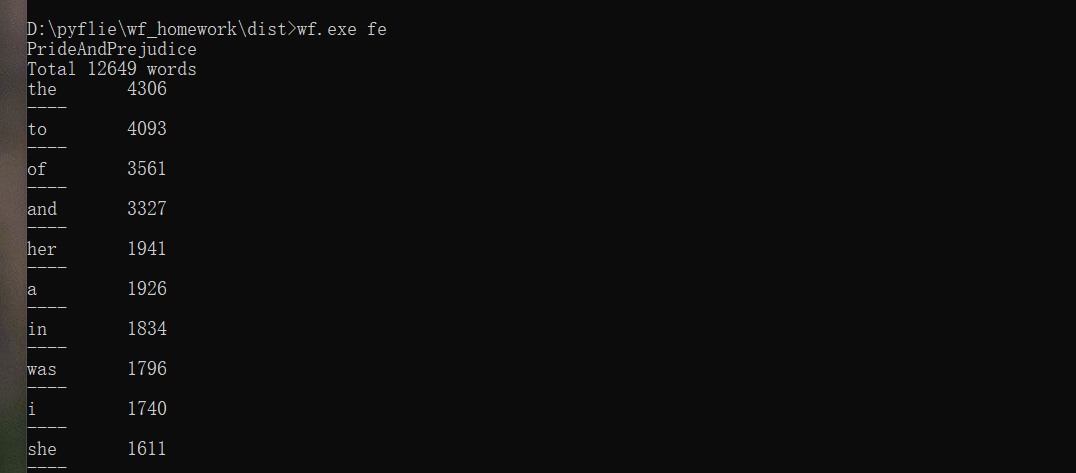
功能3 支持命令行输入存储有英文作品文件的目录名,批量统计。
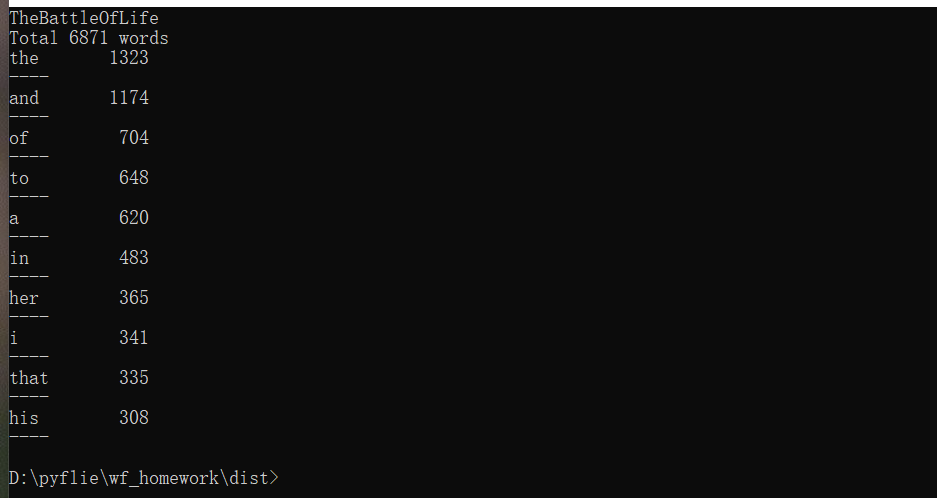
接上一张图片:
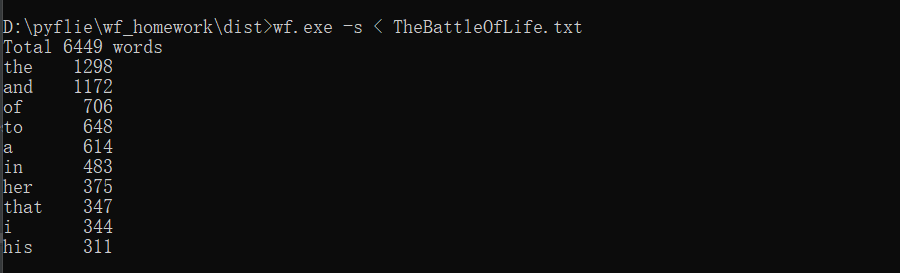
功能4 从控制台读入英文单篇作品,这不是为了打脸老五,而是为了向你女朋
友炫酷,表明你能提供更适合嵌入脚本中的作品(或者如她所说,不过是更灵活
的接口)。如果读不懂需求,请教师兄师姐,或者 bing: linux 重定向,尽管
这个功能在windows下也有,搜索关键词中加入linux有利于迅速找到。
功能四效果如下:
PSP:
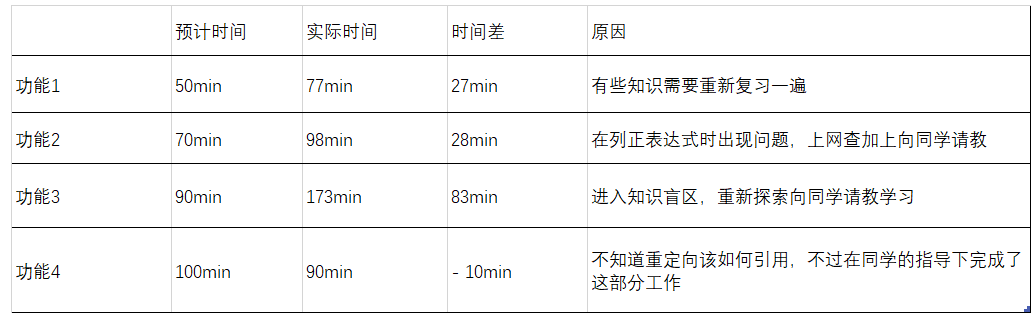
本次作业虽然遇到很多困难,但经过虚心向同学请教,再加上上网查阅资料,完成了这次任务。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号