
【文字检测算法】传统方法+RCNN+SPPNet+Fast Rcnn+Faster R-CNN+YOLO+SSD+EAST+RefineNet+DSSD+DCN
文字检测与其他目标检测的区别
一、长宽比差异很大,而且普遍较小;
二、文字是以字符为基本单元按照一定空间排列而成的序列,而不是一个单独的目标;
三、文字存在多种粒度和多语言。
传统方法系列
一、流程
1.基于滑动窗口:用不同大小的窗口在原图上滑动,并用分类模型判断每一个窗口是否包含文字,最后对检测结果使用非极大值抑制等进行后处理。
2.基于连通分量:首先根据低级特征(比如,光强,颜色,梯度等)把图像的像素聚集成不同的连通分量,再用分类模型对这些连通分量进行判断,过滤其中的噪声区域。包括基于笔画宽度变换(SWT)、最大稳定极值区域(MSER)、极值区域(ER)等方法。
二、SWT
1.思想:首先求图像的笔画宽度变换即每个像素都分配了一个笔画宽度,然后利用灵活的几何推理,把有着相似比划宽度的位置都被聚合成词。
2.流程:笔画宽度转换、像素聚成连通域、连通域滤除、字符连成文本行、文本行分割成词。
3.链接:https://www.cnblogs.com/dawnminghuang/p/3807678.html
三、MSER
1.思想:对图像进行二值化,二值化阈值取[0, 255],这样二值化图像就经历一个从全黑到全白的过程(就像水位不断上升的俯瞰图)。在这个过程中,有些连通区域面积随阈值上升的变化很小,这种区域就叫MSER。
2.链接:https://blog.csdn.net/pirlck/article/details/52846550
四、ER
五、Selective Search
1.思想
采用分层聚类的思想,整体思想是为了避免无法得到不同层次的目标的问题,采用小区域不断一步步往上聚类得到不同层次目标区域的结果。首先把图像按分割的方法分成一个个小区域,然后按照特性(颜色、纹理、尺寸、交叠)计算相似性并把相似度高且大小合适的聚起来,最后就得到了不同层次的目标。
2.链接
https://blog.csdn.net/qq_28132591/article/details/73549560%20和 https://blog.csdn.net/guoyunfei20/article/details/78723646
六、EdgeBox
1.思想:
利用边缘信息(Edge),确定box内的轮廓个数和与box边缘重叠的edge个数(知道一个box内完全包含的轮廓个数,那么目标有很大可能性,就在这个box中),基于此对box进行评分,进一步根据得分的高低顺序确定proposal信息。
2.链接:
https://blog.csdn.net/wsj998689aa/article/details/39476551
七、传统特征
1.字符:
轮廓形状直方图、边缘方向直方图、长宽比、密度。
2.链:
候选区域的个数、平均角度、平均分数、大小变化、距离变化、密度变化、宽度变化、结构相似性。
深度学习方法系列
一、R-CNN
1.思想:
首先提取一系列的候选区域,然后对这些候选区域用CNN提取固定长度的特征,然后用SVM对特征进行分类,最后对候选区域进行微调。
2.步骤:
(1)使用Selective Search对输入图像提取大约2000个候选区域(proposal);
(2)对每个候选区域的图像进行拉伸形变,使之成为固定大小的图像(如227*227),并将该图像输入到CNN(Alexnet)中提取(4096维的)特征;(先在ImageNet上进行预训练再微调,IOU阈值为0.5,分类为21个channel(是不是目标,是哪类目标))
(3)使用线性的SVM对提取的特征进行分类(对每一类训练一个分类器);
(4)对proposal进行微调(在附录里面)。
(5)测试时,用NMS做后处理。(对IOU大于一定阈值(如0.5)的proposal对,去掉面积小的proposal)
3.缺点:
(1)输入需要固定尺寸;
(2)proposal的特征需要存储,占用大量存储空间;
(3)每个proposal单独提取特征,大量重叠,浪费计算资源。
4.参考:
https://blog.csdn.net/lhanchao/article/details/72287377;
https://www.cnblogs.com/gongxijun/p/7071509.html?utm_source=debugrun&utm_medium=referral
二、SPPNet
1.思想:
改进R-CNN,使得原图只需输入一次,并且不需要固定大小。思路是,首先提取Proposal,然后将整张图输入到神经网络中得到feature map,将proposal位置对应到feature map上,剪切下来再进行图像金字塔池化得到固定长度的特征,最后再用分类器进行分类。
2.步骤:
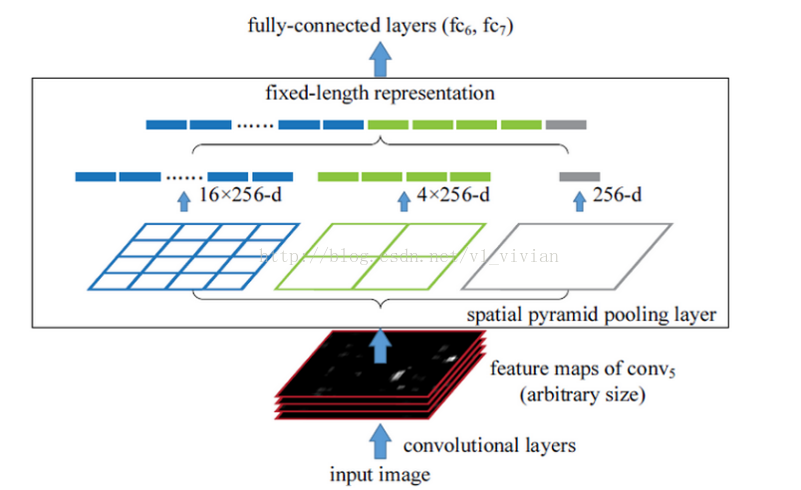
(1)使用Selective Search对输入图像提取大约2000个候选区域(proposal);
(2)将整张图像输入到神经网络(如ZF-5)中得到feature map,并对候选区域对应的feature map采用空间金字塔(4级,1*1,2*2,3*3,6*6共50块)池化得到固定大小(256个channel*50=12800维)的特征;(只有1*1时是全局平均池化)
(3)用多个二分类SVM进行分类;
(4)bounding box回归。
(5)测试时,NMS做后处理。
3.缺点:
(1)仍然基于RCNN框架,非端到端;
(2)提取proposal依然耗时;
(3)金字塔池化两端无法同时训练。
4.参考:
https://blog.csdn.net/v1_vivian/article/details/73275259
三、Fast R-CNN
1.思想:
将SPP的空间金字塔池化思想引入到R-CNN,用softmax代替SVM分类器,同时将bounding box 回归纳入到整体框架中。
2.步骤:
(1)对输入的图片利用Selective Search得到约2000个感兴趣区域,即ROI;
(2)将整张图输入到网络中得到feature map,并在feature map上求得每个ROI对应的区域;
(3)用ROI Pooling层得到固定长度的向量,然后经过一个全连接层得到ROI的特征向量;
(4)分别经过一个全连接层得到预测结果,一个用来分类是哪个目标,一个用来bbox回归。
(5)测试时,非极大值抑制得到最终结果。
3.细节:
ROI pooling:
是SppNet的图像金字塔池化的一种特例,只有一层。
4.Loss:
分类softmax loss+回归smooth L1 loss
5.缺点:
(1)仍然是双阶段的;
6.参考:
https://blog.csdn.net/wonder233/article/details/53671018
四、Faster R-CNN
1.思想:
用RPN(区域生成网络)取代以往算法的区域生成阶段,然后交替训练,使得RPN和Fast RCNN共享参数。
2.步骤:
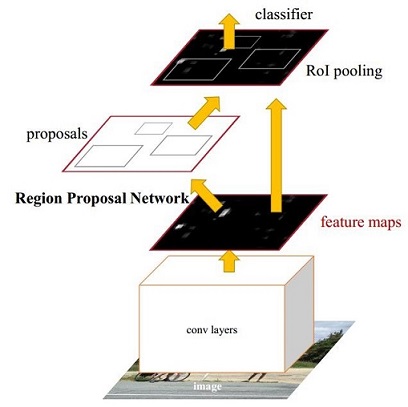
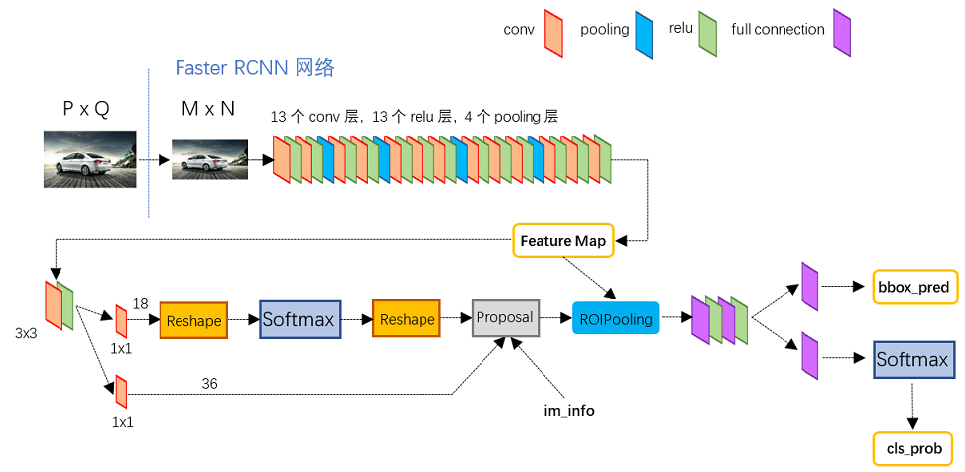
(1)用基础网络(VGG16)获得feature map;
(2)将feature map输入到RPN网络中,提取proposal,并将proposal映射到原feature上;
(3)将proposal的feature map用ROI pooling池化到固定长度;
(4)进行类别的分类和位置的回归。
3.细节:
RPN网络:


在feature map的每个cell上赋予9=3(3种size)*3(3种比例,1:1,1:2,2:1)个anchor,每个anchor需要检测该cell是不是目标(9*2=18维),以及目标的更精确的位置(9*4=36维),整个feature map得到W/4*H/4*(18+36=54)大小的feature map,接着就可以按分数取正负样本,再从原feature map上裁出来然后ROI pooling,就得到待分类和回归的proposal。
bbox回归
将anchor映射回原图进行回归,回归之后去掉超出边界的Bbox,再用非极大值抑制,最后选择前TopN的anchor进行输出。
ROI pooling
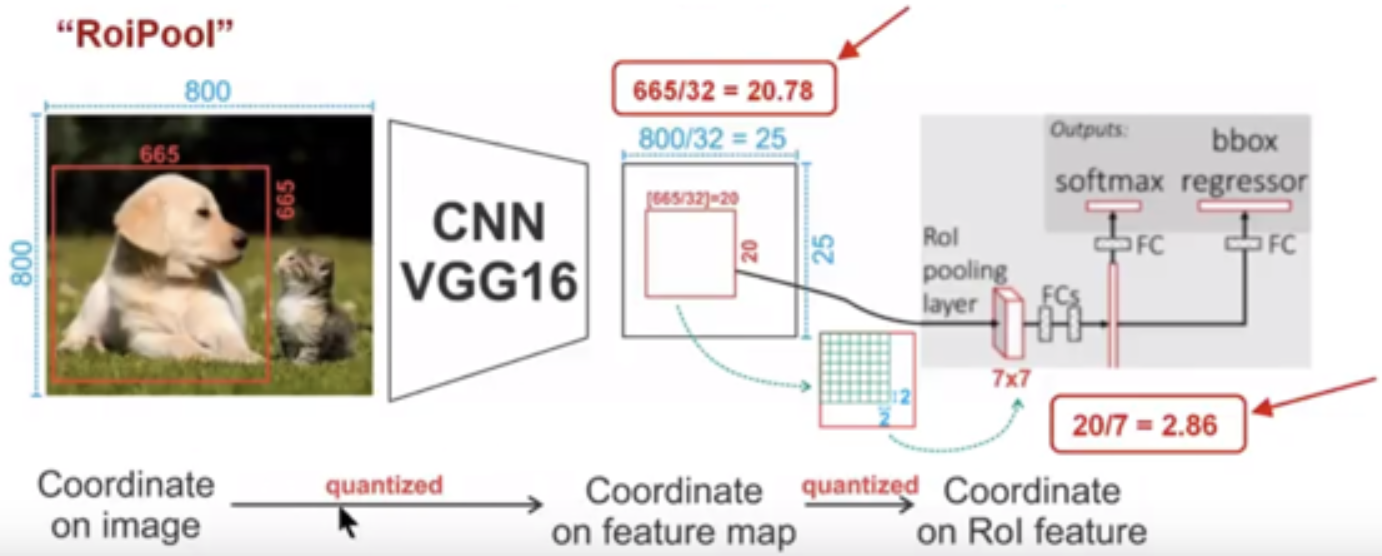
https://www.cnblogs.com/wangyong/p/8523814.html
4.Loss:
RPN损失:分类损失(softmax)+λ回归损失(L1 smooth)
Fast RCNN损失:见上
5.参考:
http://www.360doc.com/content/17/0809/10/10408243_677742029.shtml
五、YOLO
1.思想:
将原图经过基础网络(类似于GoogleNet)得到特征,然后接两个全连接层,直接进行回归,不是对特征图上的每个cell进行回归(x/y/w/h/confidence),而是对原图打7*7的格子,对每一个格子进行回归,判定是不是目标以及目标的具体位置。
2.步骤
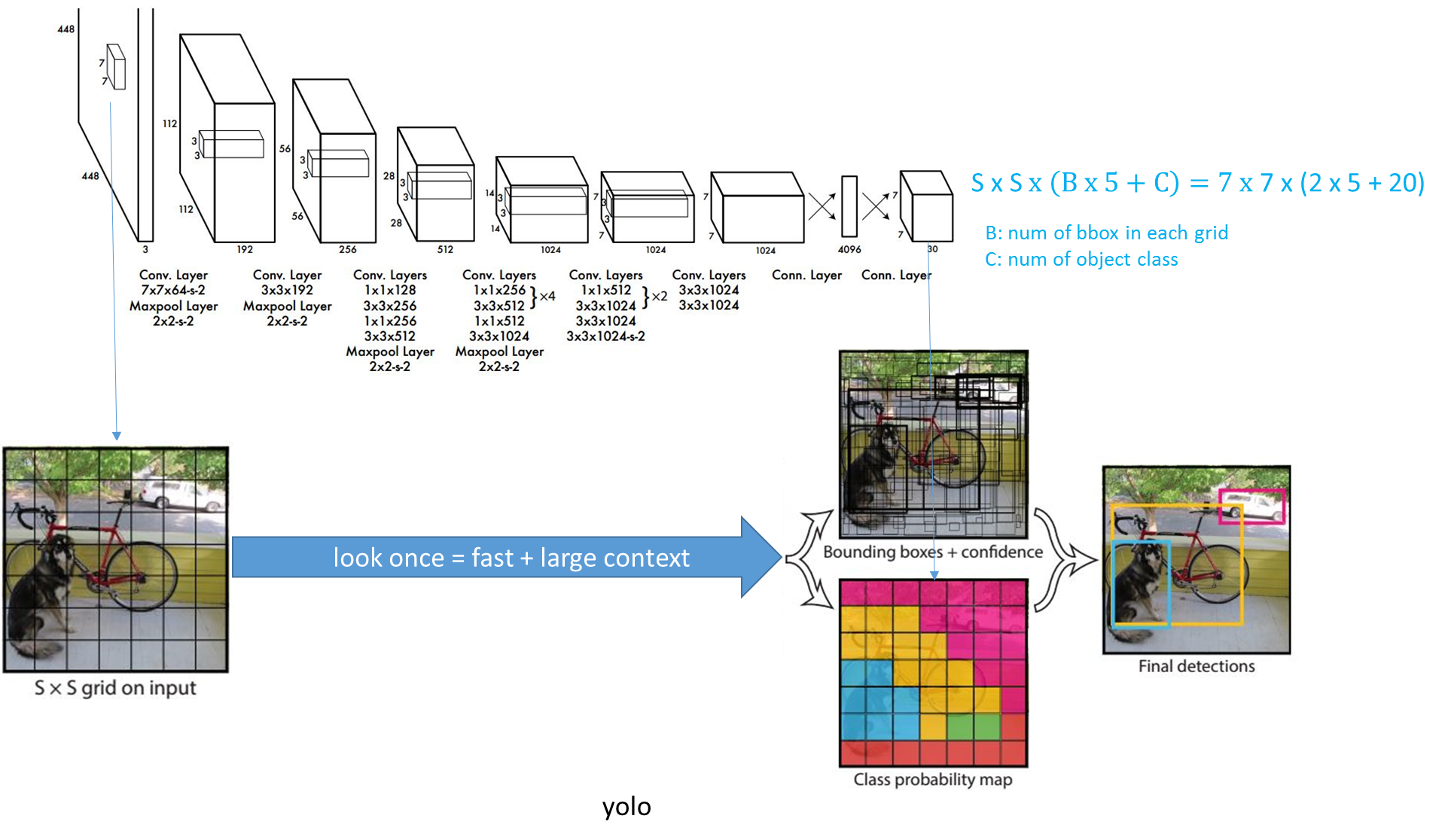
3.细节
训练是分步的,先用ImageNet2012训练基础网络部分,然后在特定库上训练合起来的整体。
坐标和分类非目标的权重分别为λcoord=5,λnoobj=0.5
4.Loss
正样本:置信度,分类分数,位置,负样本:置信度
对宽高都进行开根是为了使用大小差别比较大的边界框差别减小。
值都是绝对值,而非相对值。

5.缺点
一个格子中只能检测两个物体,且两个物体只能属于同一类别;Loss设计为绝对值;位置信息回归相对不够准确;单层预测。
6.参考
https://www.cnblogs.com/EstherLjy/p/6774864.html%20和 https://www.cnblogs.com/fariver/p/7446921.html
六、SSD
1.思想:
采用直接在特征图上回归和分类的方式来直接得到一张图上的目标。
2.步骤:
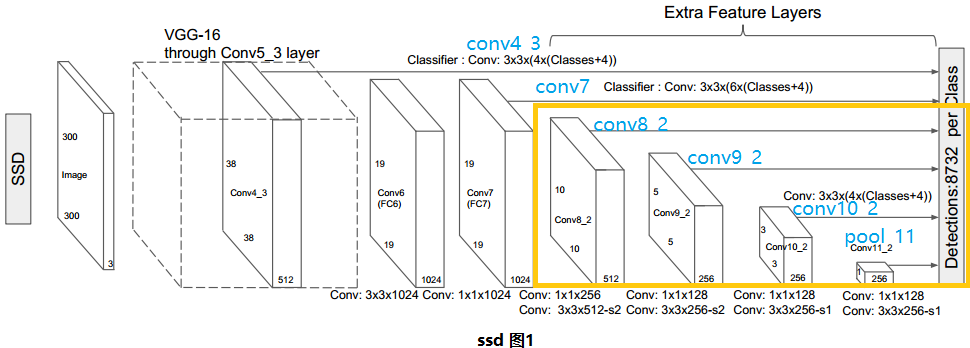
3.细节:
Default Box:比例——{1, 2, 3,1/2,1/3},尺度——20%~90%
难负样本挖掘:控制正负样本比例为1:3,即选择Loss较高的正样本和负样本。
数据增广:原图/随机采样/翻转
4.Loss:

5.参考:
https://www.cnblogs.com/fariver/p/7347197.html 和 https://blog.csdn.net/u013989576/article/details/73439202%20和 http://m.sohu.com/a/168738025_717210
七、EAST
1.结构:


2.Loss:(λg=1)
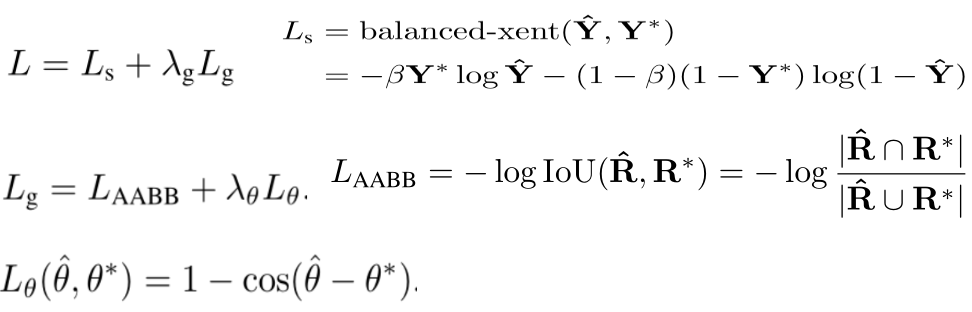
3.缺点:
检测长文本效果不够好,因为感受野不够大,而且分数采用sigmod函数【0-1】,以512为基准,这样样本都落在很小的地方,就很不均衡。
4.参考:
https://www.cnblogs.com/EstherLjy/p/9278314.html
八、RefineNet
1.结构图:
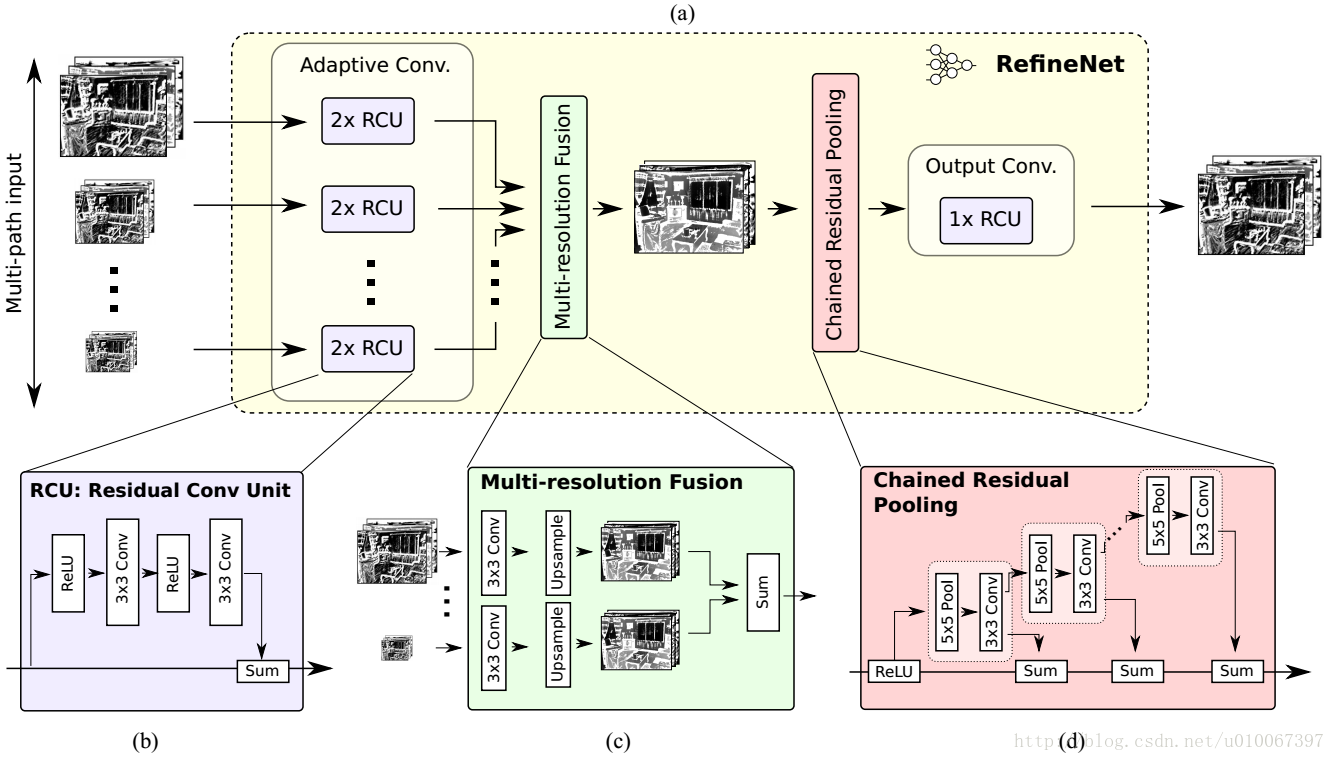
主要组成部分为RCU(残差卷积单元)、多分辨率融合、链式残差池化、RCU输出。
2.特点:
使用残差级联的方式组织网络,这样误差可以短路传播;用链式残差池化来从图中捕获背景信息;
能够有效的将下采样中缺失的信息融合进来,从而产生高分辨率的预测图像。
使用残差连接和identity mapping 的思想,能够实现端到端的训练。
3.问题:
为什么可以捕获背景信息?
链式残差池化,然后再卷积相加,不同的池化相当于大小不同的窗口,整合不同尺度的特征,结合上下文,从而捕获背景。
4.参考:
https://blog.csdn.net/qq_36165459/article/details/78345269
九、DSSD
1.思想:
改进SSD,卷积后进行去卷积,然后加起来再做预测。
2.结构图:

十、DCN(可变形卷积网络)
1.思想:
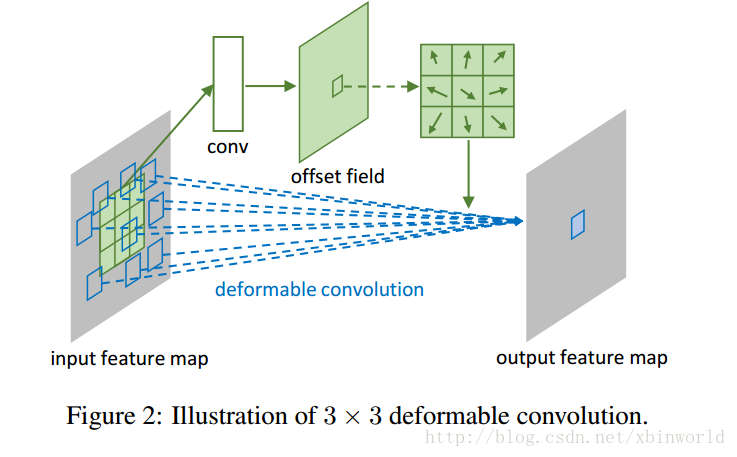
以往方块卷积核窗口,可能不是最好的,考虑不用方块卷积,而是一个不固定的窗口,让他自己去学习应该用什么样的窗口才更好。采用的方法是,学习卷积核权重的同时,对每一个要输出结果的像素点,采用的偏移点不再是周围一圈的位置,而是学习出其偏移的量(x,y两个坐标)。如3*3的卷积核,对于输出点p,需要学习9个偏移量。
2.详细:
标准卷积和变形卷积直观比较:
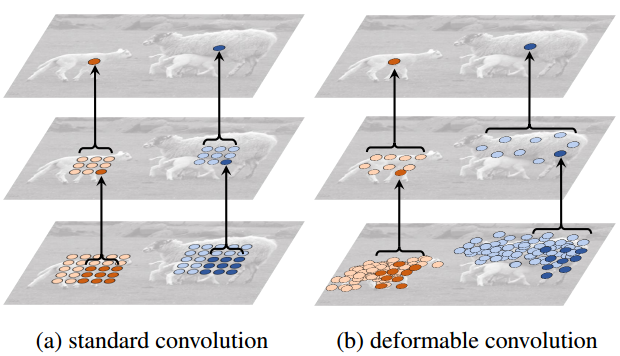
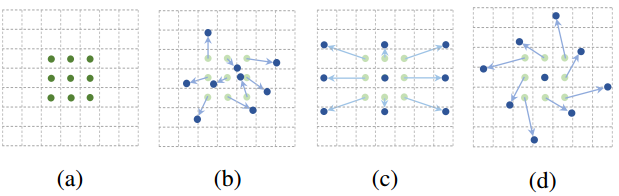
变形卷积可以达到对原始卷积移动、尺度缩放、旋转的效果:
可变形卷积过程:
传统卷积输出:
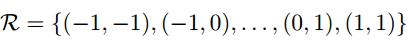
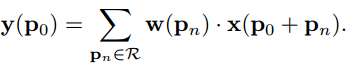
可变形卷积输出:
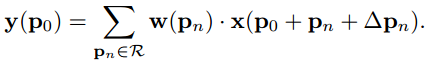
Δpn只是影响x输入层像素的抽样,并不影响窗口像素权重w。
原始池化:
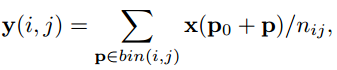
可变形池化:
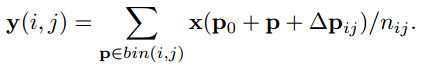
3.可视化效果:


4.参考:
https://blog.csdn.net/xbinworld/article/details/69367281%20和 https://blog.csdn.net/AMDS123/article/details/72082318?ref=myrecommend
5.DCN+FPN:
FPN:上采样后的特征图和低层的做融合,且多层预测;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号