第一次个人编程作业
https://github.com/Enuang/Sensitive-words-recognition
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | 20 | 15 |
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | 240 | 270 |
| · Design Spec | · 生成设计文档 | 30 | 30 |
| · Design Review | · 设计复审 | 20 | 15 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 8 |
| · Design | · · 具体设计 | 80 | 90 |
| · Coding | · 具体编码 | 1000 | 1200 |
| · Code Review | · 代码复审 | 90 | 80 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | 60 | 40 |
| · Size Measurement | · 计算工作量 | 10 | 7 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 60 | 45 |
| 合计 | 1750 | 1860 |
二、计算模块接口
1. 计算模块接口的设计与实现过程:
1.1 敏感词库初始化:
将敏感词拆分:
邪教-> [['邪', 'x', 'xie', '牙阝'], ['教', 'j', 'jiao', '孝攵']]
递归,对于拆分后的敏感词排列组合出除原敏感词外的各类变形的敏感词(将原汉字转化为拼音、首字母、偏旁部首):
['xj', 'xjiao', 'x孝攵', 'xiej', 'xiejiao', 'xie孝攵', '牙阝j', '牙阝jiao', '牙阝孝攵']
将变形的敏感词与原敏感词映射构成字典:
{'xj': '邪教', 'xjiao': '邪教', 'x孝攵': '邪教', 'xiej': '邪教', 'xiejiao': '邪教', 'xie孝攵': '邪教', '牙阝j': '邪教', '牙阝jiao': '邪教', '牙阝孝攵': '邪教'}同时将所有字拆分后的偏旁部首移入列表chaizi中
1.2 DFA算法
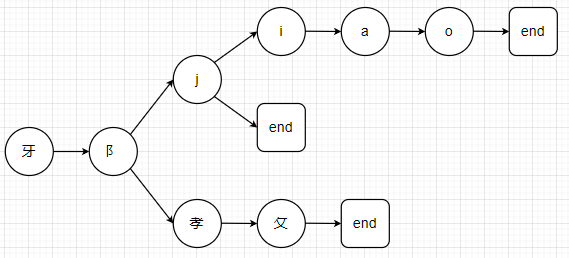
对于敏感词字典的key值用dict数据结构构建树
dict = { '牙':{ '阝':{ '孝':{ '攵':{ 'end':True }, 'end':False }, 'end':False }, 'end':False } }
1.3 类设计
只写了一个DFA类,六个函数写在了这个类里
1.__init__函数:初始化并构建dfa字典树、添加无意义词库
2.add_word函数:构建敏感词字典树
3.get_word函数:获取原文该行中的源词(即经历了各种变形的敏感词)和相匹配的原敏感词列表,调用check_word函数和find_right函数
4.check_word函数:递归获取原文该行中的源词,调用check_pinyin函数
5.check_pinyin函数:check_word函数的子函数,在树中查找汉字的拼音
6.find_right函数:递归获取相匹配的原敏感词
2. 计算模块接口部分的性能改进:
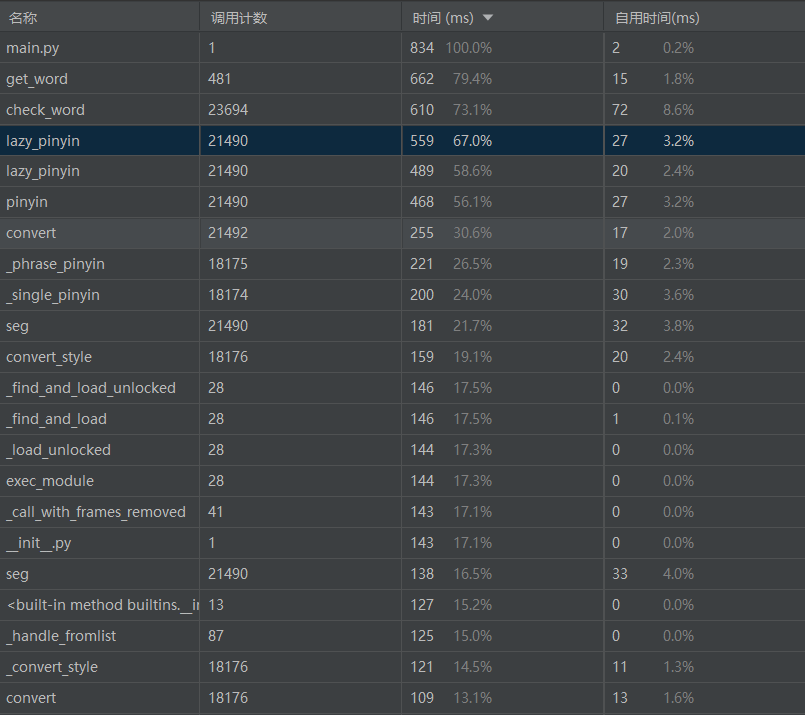
2.1 各函数按总时间降序排列
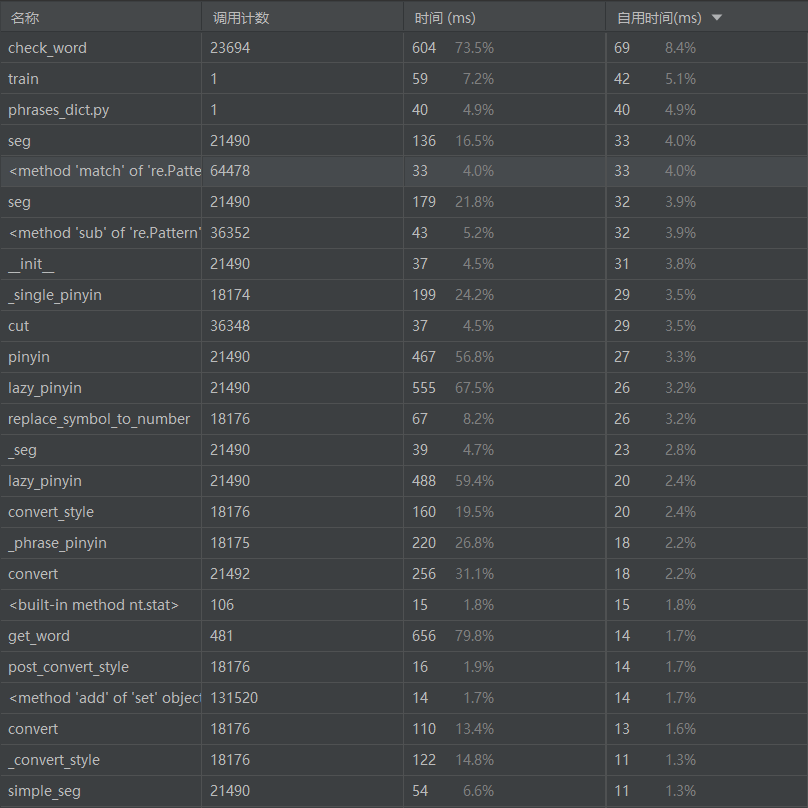
2.2 各函数按自用时间降序排列
2.3 调用关系图
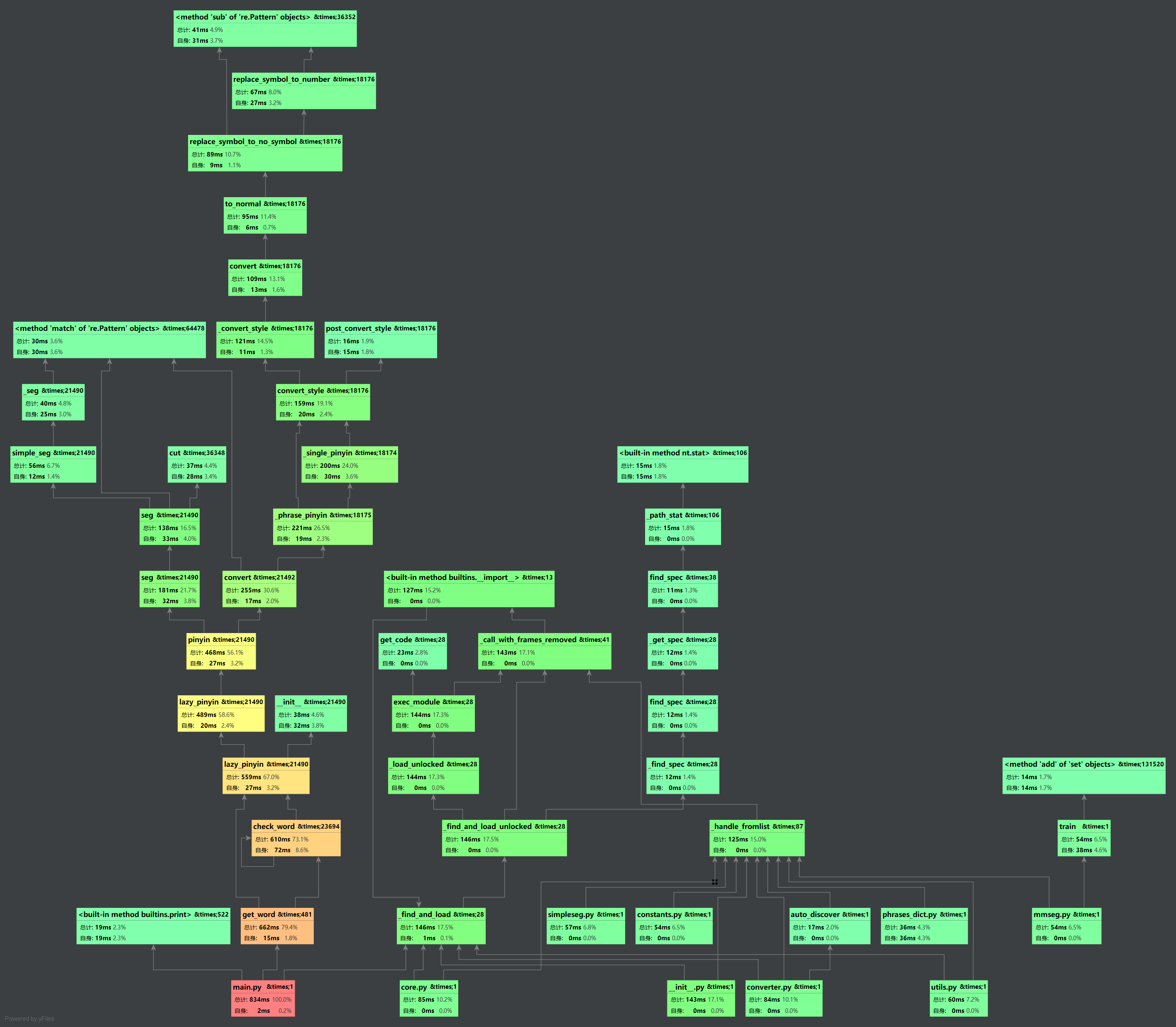
从性能测试和调用关系图中可以看到耗时最大的是get_word函数,代码如下:
def get_word(self, txt):
# 获取匹配到的词语
matched_word = list()
right_word = list()
for i in range(len(txt)):
node = self.root
lengthList = self.check_word(txt, i, i, node, [])
if lengthList:
lengthList.sort()
length = lengthList[-1]
if length > 0:
flag = False # 判断无意义字符是否为数字
word = txt[i:i + int(length)]
matched_word.append(word) # 获取匹配到的词
for j in word:
if j in self.ignore_word:
word = word.replace(j, '')
if '0' <= j <= '9':
flag = True
if 'A' <= j <= 'Z':
# 去除无意义字符,大写转小写
word = word.replace(j, j.lower())
str1 = str()
for j in word:
if j in init.chaizi:
str1 += j
else:
str1 += pypinyin.lazy_pinyin(j)[0]
ans_word = self.find_right(str1, 0, '', '')
right_word.append(self.swd[ans_word])
if flag and init.is_chinese(self.swd[ans_word]): # 中文加数字不算敏感词,剔除
matched_word.pop()
right_word.pop()
return matched_word, right_word
由于get_word函数调用了check_word函数和find_right函数,而这两个函数还需要调用多次的pypinyin库,这一部分时间无法减少。递归过程中已经缩短了检测时间:对于检测的每一个汉字若在chaizi列表中则进行一次部首查找和一次拼音查找,否则只进行拼音查找。对于英文,只进行拼音查找(英文转化拼音为本身)。
就目前我的能力而言,暂时想不到性能的优化方案,如果有同学想到了能再次缩短耗时的方法,欢迎一起讨论。
3. 计算模块部分单元测试展示:
3.1 验证初始化字典函数new_swd()
构造测试数据的思路:
测试初始化字典,验证排列组合后各种变形敏感词能否与原敏感词对应
def test_swd(self):
word=['秋天']
ans = dict({'qt': '秋天', 'qtian': '秋天', 'qiut': '秋天', 'qiutian': '秋天', '禾火t': '秋天', '禾火tian': '秋天'})
result = init.new_swd(word)
self.assertEqual(result,ans)
3.2 验证搜索结果函数get_word()
构造测试数据的思路:
测试代码核心部分,即验证中文敏感词各种变形(敏感词中插入若干字符、拼音替代、首字母替代、拆分偏旁等情况)后能否查找正确。
def test_get_word(self):
word=['全球总决赛','规模']
org=['我们决定在冰岛雷克雅未克举办2021全!球总^jue赛。\n',
'这场今年最大gu!i&模,最顶级的电子竞技全$王_求z决赛将于10月5日正式开幕\n',
'并于11月6日举行顶级 规%m_ 的冠亚军决赛。']
ans=['Line1: <全球总决赛> 全!球总^jue赛', 'Line2: <规模> gu!i&模', 'Line2: <全球总决赛> 全$王_求z决赛', 'Line3: <规模> 规%m']
sw=init.new_swd(word)
dfa=main.DFA(sensitive_word=sw)
result = list()
for i in org:
match, right = dfa.get_word(i)
if match and right:
num = org.index(i)
for j in match:
ind = match.index(j)
result.append('Line' + str(num + 1) + ': ' + '<' + right[ind] + '> ' + match[ind])
self.assertEqual(result, ans)
3.3 单元测试覆盖率
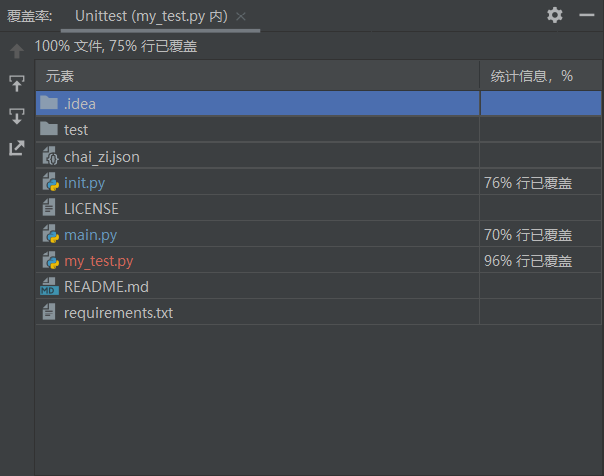
3.4 结果统计及可视化输出
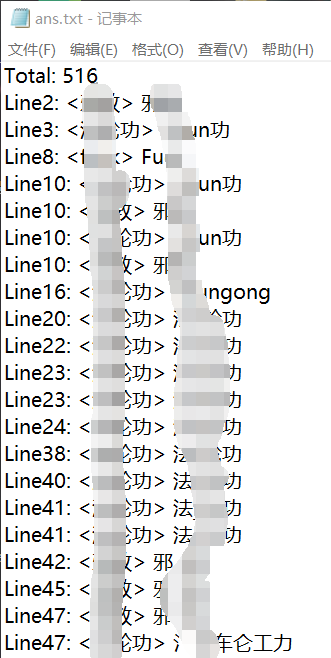
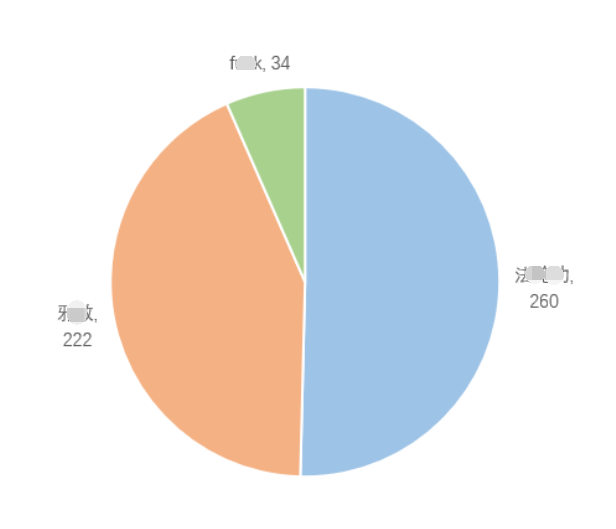
4. 计算模块部分异常处理说明:
IO异常:程序运行时需要读入words和org文件,将结果写入ans文件,同时在本人的代码中还需要读取一个json文件文件。而在读写文件时常会发生错误,示例为文件未成功读取时的异常处理。
def test_IOError(self):
try:
f=open('requirement.txt','r',encoding='utf-8')
except IOError:
print('IOError:未找到文件或读取文件失败')
else:
print("文件读取成功")
f.close()
Import异常:python中常常需要导入第三方模块,来方便代码实现,示例为导入失败时的异常处理。
def test_ImportError(self):
try:
from numpy import a
except ImportError:
print("ImportError:导入未成功")
else:
print("导入成功")
三、心得
这次编程作业我原来的想法是一个一个阶段的实现,开始着手写的时候花了6个小时先把简单的敏感词识别做出来,即不考虑偏旁部首变化。第二天晚上重新找了几个敏感词去测的时候发现出了大大小小情况不同的bug,bug改了一晚上。第三天打算加入偏旁部首变形操作的时候,发现搜索函数需要重新写,心态直接炸裂,熬夜写到凌晨四点,把demo写出来了,第四天继续改bug改了一晚上。每天code完第二天还是要考虑算法的具体实现。所以:前期设计真的很重要很重要,不要只经过简单的思考过后就去写代码!!!(code一小时debug一整天的过程真是太折磨人了)。
在写性能改进的时候发现自己好像自动在code的过程中改进了,原来的想法是进行两轮搜索分别是拼音跟偏旁部首,后来写着写着发现好像只有偏旁部首需要搜索两轮,拼音和英文只需要搜索一轮。从原来只有简单的敏感词检测到后来加入检测偏旁部首变形操作后,代码可以说是完全两回事了,只有树的结构没有改。
总之,经过这一次软工个人编程实践,能感觉到自己代码能力在长进。看到自己的输出的结果比测试组给的还要多几个且正确的情况下,还是感到无比的欣慰,感觉几天的努力没有白费。
ps:代码上传GitHub实在是太折磨人了,一直连接超时,改天找找怎么Scientific Internet。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号