分布式学习
1、分布式理论基础
1.1、CAP理论
- 数据一致性(consistency):如果系统对一个写操作返回成功,那么之后的读请求都必须读到这个新数据;如果返回失败,那么所有读操作都不能读到这个数据,对调用者而言数据具有强一致性
- 服务可用性(availability):所有读写请求在一定时间内得到响应,可终止,不会一直等待
- 分区容错性(partition-tolerance):在网络分区的情况下,被分隔的节点仍能正常对外服务。
对于单体服务,完全可以保证CAP,C可以通过事务保障。服务可用性用TP999那些去衡量,P在单体中不存在,不存在节点间的网络通信。
那也就是说,P是分布式应用必须存在的,如果不选择P,那么就是单体服务。
从而证明,分布式框架中CAP,必须要存在P,也就是CP,或者AP。
就以数据库为例。
如果选择了CP,那么就要保证数据一致性,每一个节点之间必须必须要同步,但因为存在网络,想要实现强一致性就必须要等待网络同步数据,此时就无法满足服务可用性。
如果选择了AP,那么就必须要保证服务可以一直对外提供。但由于网络同步数据问题,就会造成用户在节点1写入新数据,在节点2读到老数据。所以无法满足数据强一致性。
1.2、BASE理论
CAP理论的一种妥协,由于cap只能二取其一,base理论降低了发生分区容错时对可用性和一致性的要求。
- 基本可用:允许可用性降低(可能响应延长、可能服务降级)
- 软状态:指允许系统中的数据存在中间状态,并认为该中间状态不好影响系统整体可用性
- 最终一致性:节点数据同步可以存在时延,但在一定的期限后必须达成数据的一致,状态变成最终状态。
1.3、Quorum机制、WARO
waro:一种简单的副本控制协议,写操作时、只有当所有的副本都更新成功之后,这次写操作才算成功,否则视为失败。优先保证读、任何节点读到的数据都是最新节点,牺牲了更新服务的可用性、只要有一个副本宕机了,写服务就不会成功。但只要有一个节点存活、仍能提供读服务。
Quorum机制:10个副本,一次成功更新了三个,那么至少需要读取八个副本的数据,可以保障读到了最新的数据。无法保证强一致性,也就是无法实现任何时刻任何用户或节点都可以读到最近一次成功提交的副本数据。需要配合一个获取最新成功提交的版本号的metadata服务,这样可以确认最新已经成功提交的版本号,然后从已经读到的数据中就可以确认最新写入的数据。
1.4、paxos算法
1.5、一致性模型
cap数据是强一致性模型,base理论是最终一致性。
因果一致性:要求有因果关系的操作顺序得到保证,
2、分布式事务
分布式事务的解决方案
- 基于XA协议的:两阶段提交和三阶段提交,需要数据库层面支持
- 基于事务补偿机制的:TCC,基于业务层面实现(try,commit,cancel)
- 本地消息表:基于本地数据库+mq,维护本地状态()
- 基于事务消息:mq
2.1、XA协议
两阶段协议和三阶段协议都是在数据库层面实现的。
两阶段:
- 发送prepare消息(基本完成sql语句操作),但未提交事务
- 阶段一所有prepar操作成功/失败,则通知所有库提交事务/回滚事务
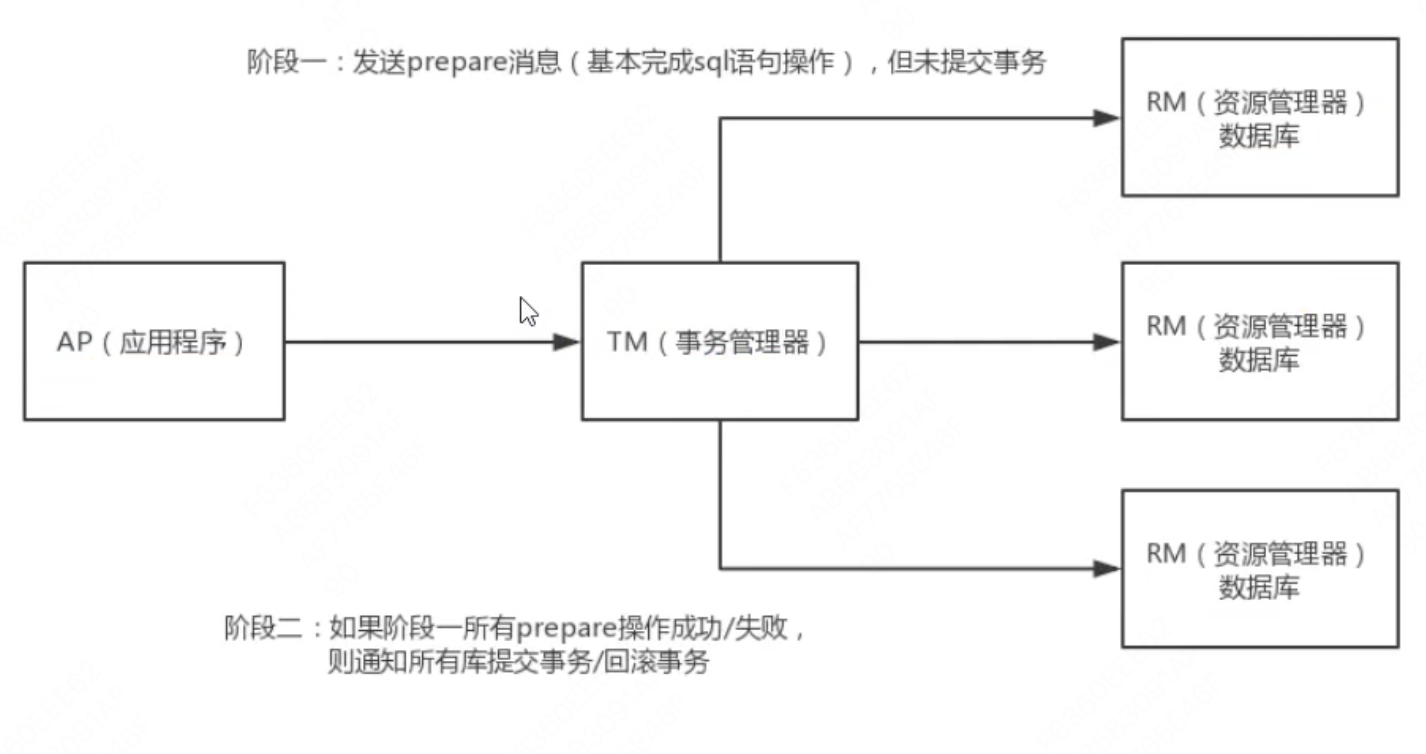
但两阶段存在局限性:
- 单点故障:一旦事务管理器出现故障,整个系统不可用
- 数据不一致:在阶段二,如果事务管理器只发送了部分commit,此时网络发送异常,那么只有部分参与者受到commit消息,也就是说只有部分参与者提交事务,使得系统数据不一致。
- 响应时间较长:参与者和协调者资源都被锁住,提交或者回滚之后才能释放
- 不确定性:当协事务管理器发送commit之后,并且此时只有一个参与者收到了commit,那么当该参与者与实物管理器同时宕机之后,重新选举的事务管理器无法确定该条信息是否提交成功。
三阶段提交:
主要是针对两阶段的优化,解决了2PC单点故障的问题,但是性能问题和不一致问题仍然没有根本解决。
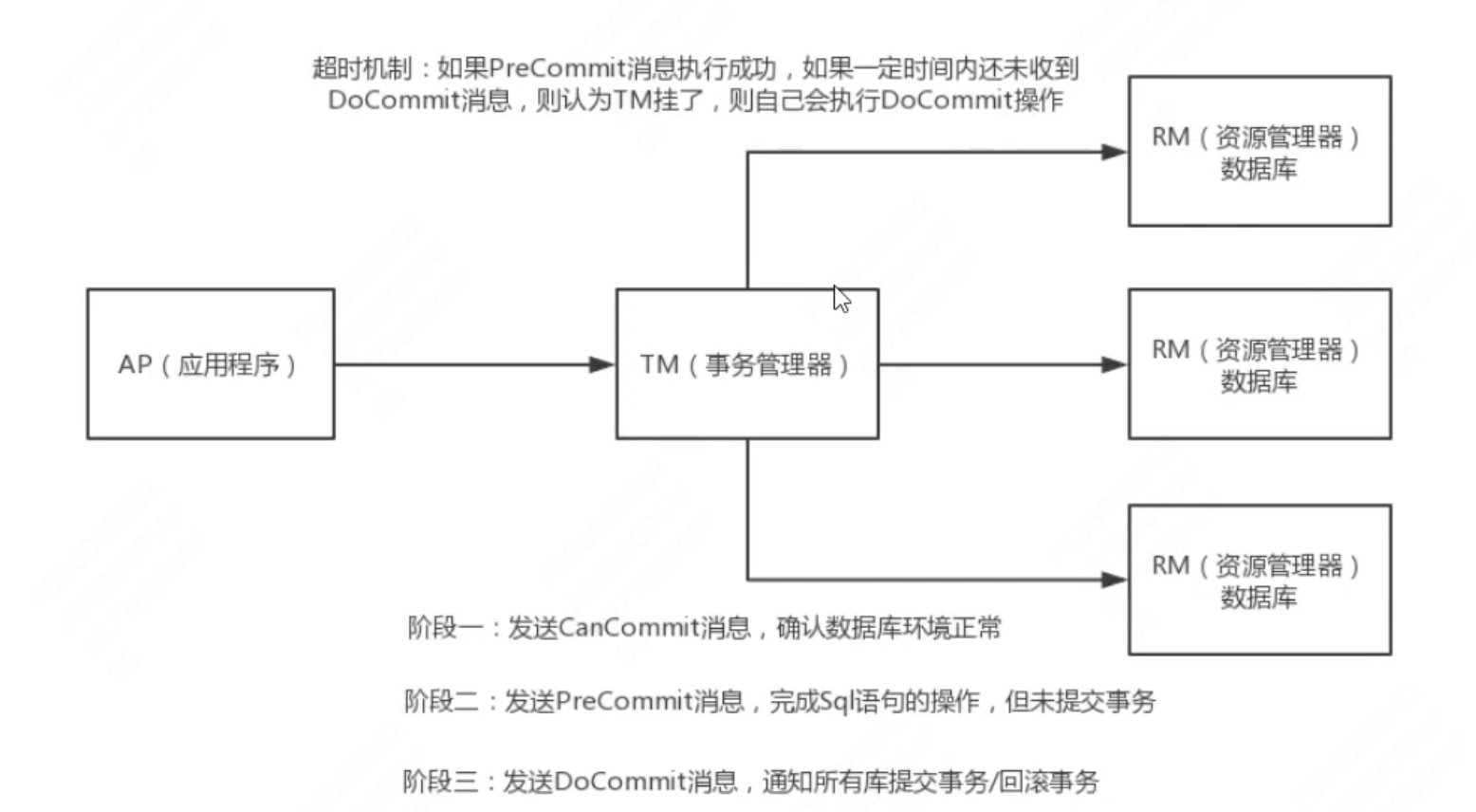
引入超时机制解决参与者阻塞的问题,超时后本地提交,2PC只有协调者有超时机制。
2.2、TCC模型
TCC(补偿事务):Try、Confirm、Cancel
针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作。
Try:对业务检查和资源预留,Confirm做业务确认操作,Cancl实现一个与Try相反的操作既回滚操作。
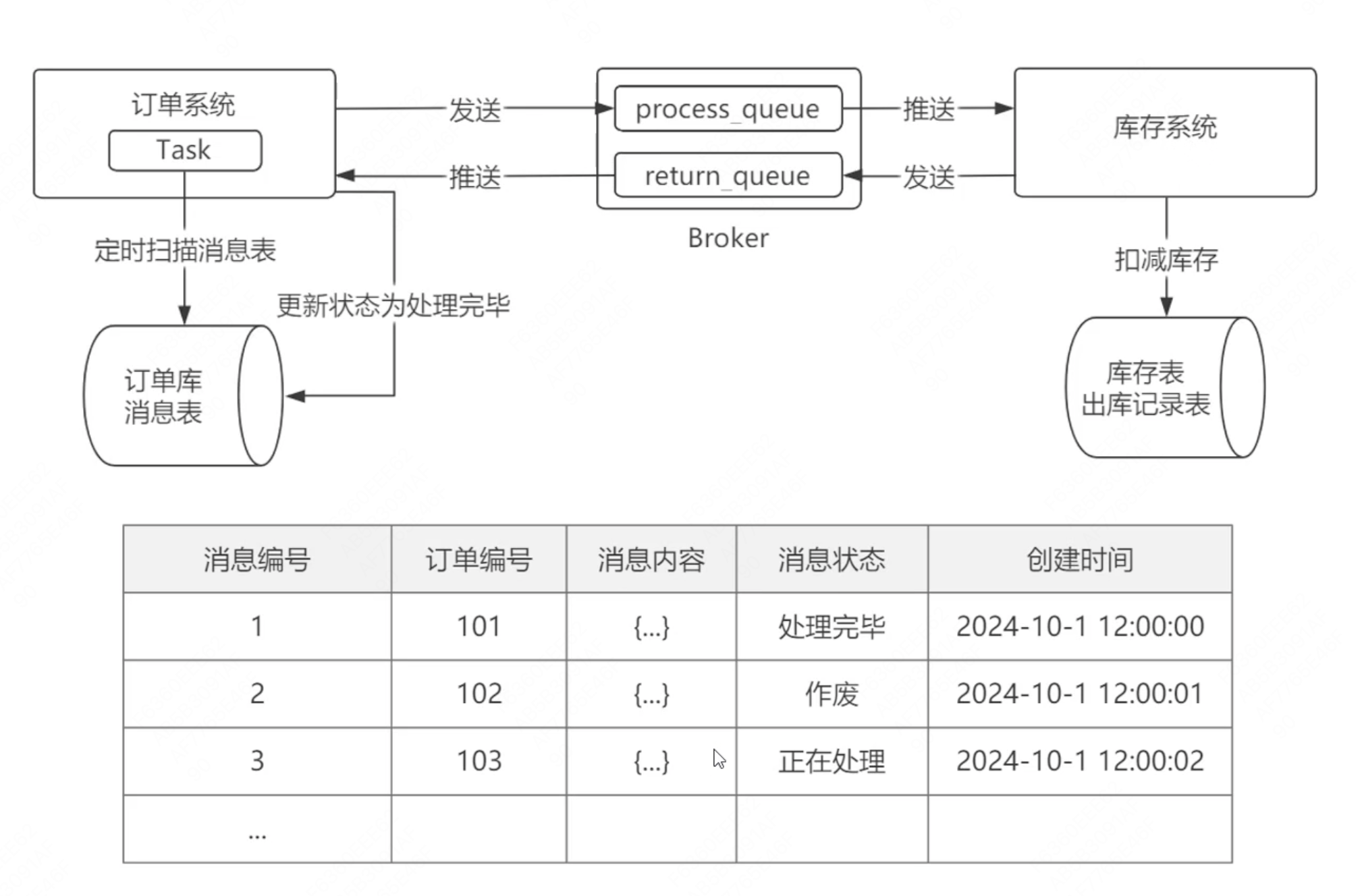
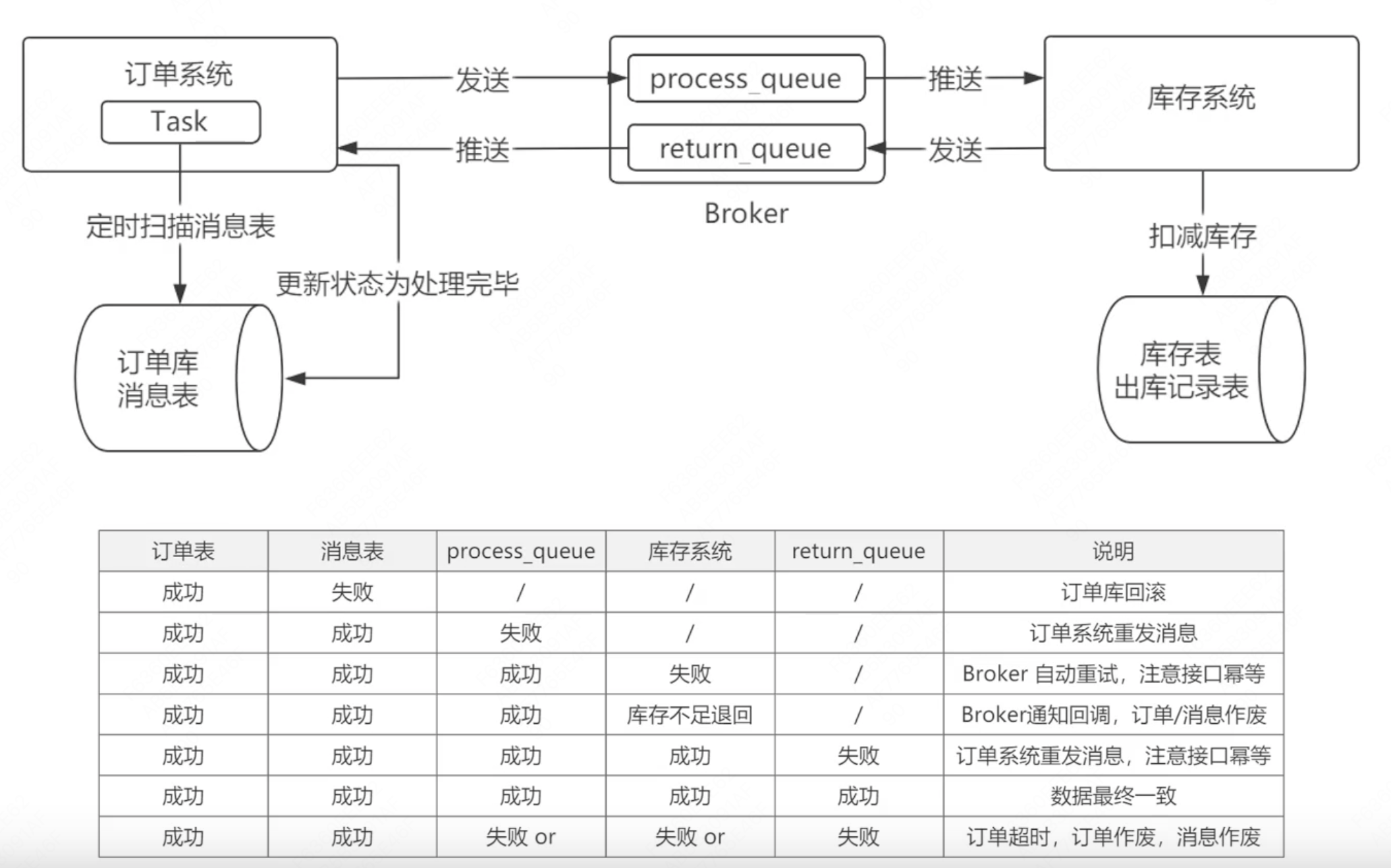
2.2、本地消息表模式
在业务的基础上增加了定时任务,消息表,broker。
系统a在执行完业务操作中,向消息表里插入数据,由定时任务定时扫描消息表,如果扫描到有需要进行的任务,就发送消息给broker,broker发消息给系统b。系统b在执行完业务后,会给broker发送返回消息,最后告知系统a。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号