论文翻译:跨语言语音转换和富有表现力的语音转换
- 跨语言语音转换(XVC),其中源语音和参考语音使用不同的语言(例如英文——>中文)。
- 表现语音转换(EVC),是转换的音频更富有说话人身份和情感风格特点。
• 提出了一种新的说话人特征提取方法,其中应用了说话人一致性损失到联合说话人编码器。实验结果表明,包含说话人一致性损失可以提高说话人相似性和情感相似性。
• 使用Whisper实现XVC:我们使用跨语言语音识别模型Whisper的中间特征,这有助于生成没有外国口音的高质量语音,从而实现XVC。
• 使用PPG作为输入实现EVC:为了模拟参考语音中的情感和说话人信息,我们使用PPG作为输入来实现EVC,从而实现准确的情感和说话人特征转换。
语音转换系统在常见的语音转换任务中在自然度和相似性方面取得了显著进展。然而,在跨语言语音转换和表现语音转换等更复杂任务中,它们的性能仍不完美。在本研究中,我们提出了一种新颖的方法,将联合训练的说话人编码器和从跨语言语音识别模型Whisper中提取的内容特征结合起来,实现高质量的跨语言语音转换。
此外,我们引入了一个说话人一致性损失到联合编码器中,从而改善转换后语音与参考语音之间的相似性。为了进一步探索联合说话人编码器的能力,我们使用音素后验图作为内容特征,使模型能够有效地重现参考语音的说话人特征和情感方面。
关键词:跨语言语音转换、表现语音转换、联合说话人编码器、说话人一致性损失
引言:
目前,解耦和重构语音中的信息是实现高质量语音转换模型的最流行方法。
具体而言,在训练过程中,从语音中提取内容和说话人信息,然后用于语音重构。在推理过程中,通过使用源语音中的内容信息和参考语音中的说话人信息,生成新的语音来实现语音转换(简单来说就是非平行)。
基于音素后验概率(PPG)的语音转换方法,如PPG-VC[9],是基于这一原理的经典语音转换方法。然而,过去受限于自动语音识别(ASR)性能和语音合成模型能力不足,合成输出的语音质量有限[10]。随着非自回归(NAR)文本到语音(TTS)模型的出现,例如VITS[11]、FastSpeech2[12]、DiffSinger[13],以及大规模预训练的自监督学习(SSL)模型的可用性,例如Hubert[14]和WavLM[15],高质量的语音转换模型已经成为可能。FreeVC[16]、ACE-VC[17]和广泛采用的开源歌声转换(SVC)模型SO-VITS-SVC2的基本原理是利用SSL模型从原始语音中提取内容特征。然后,使用说话人ID或说话人分类模型从语音中提取说话人特定信息。最后,这两组信息都被用于通过TTS模型重构语音。语音转换结果的质量在很大程度上取决于语音重构模型的合成能力,特别是在准确和明确的内容信息可用时。(说人话:就是用音素作为特征,训练一个声码器做语音的生成,这样的好处是可以保留大量的说话人原本的情绪变换特点)
以前的语音转换模型,如PPG-VC和Freevc,通常使用预训练的说话人编码器在说话人分类任务上进行训练,以获取说话人嵌入,然后用于引导语音合成。值得注意的是,训练说话人编码器的主要目标不是语音合成,而是说话人识别。因此,这种方法可能会忽略参考语音中存在的宝贵信息,比如情感。此外,训练说话人分类模型需要大量的数据集。Freevc-s[16]、Quickvc[18]和NVC-Net[19]使用联合训练的说话人编码器,以确保说话人编码器的输出仅包含与说话人相关的信息。这是通过实现瓶颈结构并仔细排除内容特征中的说话人信息来实现的。然而,缺乏一个更详细的损失函数,专门设计用于捕捉与说话人相关的特征。
说话人一致性损失的概念已经在几项研究中使用,包括YourTTS[20]和CyclePPG-XVC[21],旨在改善模型生成的语音与真实语音之间的说话人相似性。这是通过比较同时处理生成语音和真实语音的说话人编码器的输出来实现的。然而,这些研究使用了专门针对说话人分类任务进行训练的预训练说话人编码器。这种方法有一定的局限性,如上述讨论的情感信息的忽略。此外,这些研究中使用的说话人一致性损失仅更新语音合成模块,对说话人编码器本身没有影响。因此,在应用说话人一致性损失方面仍有改进的空间,特别是在XVC和EVC任务中。
方法
2.1.动机
在最近的VC研究中,最先进的VC系统表现出令人印象深刻的性能,特别是在单语种(通常是英语)且没有情感改变的场景中。生成的语音样本显示出与人类声音的显著自然度和相似度。我们认为现在是将VC研究的重点从传统VC转向更复杂应用的时候了。因此,我们选择了XVC和EVC任务来展示我们设计的说话人信息编码方法的灵活性,它可以处理更多超出传统VC范围的任务。
所提出的ConsistencyVC灵感来自于FreeVC-s[16]、LoraSVC3、VALL-e[23]和YourTTS[20]。该模型基于FreeVC-s的基础架构,因为它具有端到端的结构,可以实现高质量的VC。FreeVC-s的联合说话人编码器的瓶颈结构确保只编码说话人特征,而不包括内容信息。此外,非自回归设计改进了推断速度。然而,与FreeVC-s不同,我们从LoraSVC中汲取灵感,并选择在XVC任务中表现更好的内容特征,消除了需要进行数据增强的需求,从而节省了大量存储空间。VALL-e是一种零样本语音合成模型,它在训练过程中使用目标语音的3秒片段作为参考语音输入。该模型可以模仿说话人的特征,甚至从任何3秒参考语音片段中合成高质量的语音,包括情感特征。这种分段概念启发了我们的假设,即语音的子段应该包含与整个语音相似的说话人和情感特征。基于这一假设,并受到YourTTS的启发,我们将说话人一致性损失应用于联合说话人编码器VC模型的训练中。这种应用改善了说话人相似性和情感相似性。
2.2. 模型架构
如图1所示,ConsistencyVC模型的主要结构遵循VITS语音合成模型。但是,文本编码器和持续时间预测器被替换为类似于VITS中的后验编码器的内容编码器。内容编码器使用WaveNet残差块。内容编码器不使用文本作为输入,而是采用来自预训练ASR模型的内容特征作为输入。说话人信息则通过Mel频谱图使用联合训练的说话人编码器进行编码。在实验部分,XVC和EVC任务使用不同的数据集和不同类型的内容特征来训练VC模型。然而,VC模型的结构保持不变。接下来,将详细解释内容特征的选择以及说话人编码器的结构。

2.2.1. 内容特征
Whisper是一种ASR模型,在跨语言语音识别任务中取得了显著的成果。它的模型架构基于编码器-解码器transformer。我们选择transformer编码器块的输出,称为Whisper编码器的输出(WEO),作为内容特征。与以前XVC研究中的内容特征相比,WEO提供了更准确和全面的信息,包括源语音的口音(这里小编持怀疑态度,对说话人语音使用IN会消除不同人语音分布的均值和方差分布的影响,只保留内容信息,难道Whisper没用IN?,而且在这篇文文章中是希望消除掉源说话人的口音信息,有点矛盾了),这对于实现无外语口音的XVC至关重要。因此,我们选择WEO作为XVC任务的内容特征。
对于EVC任务,我们选择使用从在音素识别任务上训练的wav2vec模型中获得的PPG(Phoneme Posteriorgram)。这个选择基于以下事实:同一段话中的不同情感具有不同的韵律。PPG提供了清晰的内容信息,且包含的韵律信息较少,因此重建语音的韵律完全依赖于说话者编码器的输出,这使得PPG更适合用于EVC任务。
相反,对于XVC任务,WEO比PPG更合适。这是因为在不同的语言中,相同的发音可能有不同的韵律或口音。在XVC任务中,重建语音的韵律应该依赖于来自本地说话者的源语音。
说话者编码器使用Mel-spectrogram作为输入来生成编码的说话者嵌入。说话者编码器与模型的其余部分一起训练。它由一个包含3层LSTM模块和一个全连接层的块组成,类似于FreeVC-s模型。我们将从语音中得到的Mel-spectrogram输入到说话者编码器的LSTM层中。 LSTM的最终隐藏状态被传递给全连接层,使得可变长度的Mel-spectrogram输入转换为固定大小的嵌入,实现了瓶颈结构。内容编码器的输出被假设为与说话者无关。为了合成语音,模型使用来自说话者编码器的输入来替换缺失的说话者信息。
在训练策略上,ConsistencyVC模型遵循VITS的训练策略,在训练过程中加入了VAE和对抗训练。对于生成器部分,损失可以表示为:
Lvae = Lrecon + Lkl + Ladv(G) + Lfm(G) + LSCL
其中,Lrecon是重建损失,Lkl是KL散度损失,Ladv(G)是对抗损失,Lfm(G)是特征匹配损失。这些损失类似于VITS,所以这里不再详述具体细节。而是着重解释说话者一致性损失LSCL。
在VITS的实现中,研究人员采用了窗口化生成器训练技术[24],该技术在训练过程中仅生成原始波形的一部分,以减少计算需求。他们随机提取潜在表示z的片段,并将其馈送到基于HiFi-GAN的解码器,相应的音频片段则从真实的原始波形中提取作为训练目标。这导致模型在训练过程中生成的输出语音长度只是输入语音长度的一小部分。
在FreeVC-S中,对于VC任务,输入的内容信息也被分段,限制了内容特征的最大大小。我们假设与输入内容特征相对应的语音段和模型输出的语音段应该包含相同的情感和说话者特征。基于这个假设,我们可以为共同训练的说话者编码器设计说话者一致性损失。
形式上,设ϕ(·)是说话者编码器的函数,它输出参考语音的说话者嵌入。说话者一致性损失定义为生成的语音段与真实语音段之间的说话者嵌入的L1距离:
其中,t和h分别表示真实语音段和生成的语音段。与YourTTS和其他研究类似,我们并不是在训练的开始阶段引入说话者一致性损失,而是在模型学习了基本的语音合成能力后再引入这一损失。
据我们所知,我们是第一个将一致性损失引入到共同训练的说话者编码器中的研究。
实验(这篇文章实验做的真多)
3.1. 跨语种语音转换
3.1.1. 数据集
在跨语种语音转换实验中,我们使用了几个数据集,包括Aishell-3、LibriTTS-100、JVS、ESD、VCTK、Aishell-1和JECS。其中,LibriTTS-100、ESD、Aishell3和JVC包含了英语、中文和日语的语音样本;这些数据集被用于训练跨语种语音转换模型。而VCTK、Aishell-1和JECS数据集则用于提供未在训练集中出现的英语、中文和日语说话者的样本。这些未知说话者的样本被用于评估模型对于模仿不在训练集中的说话者的能力。
3.1.2. 实验设置
在我们的实验中,我们使用了16,000 Hz的采样率。每位说话者的语句被随机分为训练集和测试集,比例为9:1。我们的模型基于FreeVC-S,但有一些参数的设计略有不同。最显著的区别在于,对于跨语种语音转换任务,我们选择了WEO作为内容信息,其跳跃大小为320。至于模型的其他输入,我们使用短时傅里叶变换(STFT)计算了线性频谱图和80频带的Mel频谱图,其中FFT大小、窗口大小和跳跃大小分别设为1024、1024和320。HiFi-GAN解码器中的四个残差块的上采样比例被分解为320 = 10 × 8 × 2 × 2,这意味着四个块的上采样比例分别为[10,8,2,2]。为了避免“ConvTranspose1d”上采样层引起的潜在棋盘效应[31],我们使用了[20,16,4,4]的卷积核尺寸。我们使用AdamW优化器,并且设置了与FreeVC-S相同的权重衰减和学习率。
在我们的实验中,我们比较了两个版本的ConsistencyVC:ConsistencyXVC和ConsistencyXVC-w/o loss。这两个模型都是在一块NVIDIA 3090 GPU上进行训练,使用fp16训练技术,训练步数最多为300k步。在前100k步中,批大小为108,训练时使用的语句长度范围从24,000到96,000个采样点,对应于1.5到6秒的语音。输入到基于HiFi-GAN的解码器的潜变量z被分为28个片段,导致语音长度为28 × 320 = 8,960个采样点。然而,在ConsistencyXVC中,从100k步开始,我们引入了额外的训练阶段,使用说话人一致性损失继续训练200k步。在这个阶段,潜变量z被分为75个片段,导致语音长度为75 × 320 = 24,000个采样点。由于潜变量z的大小较大,批大小减小为42。另一方面,ConsistencyXVC-w/o loss则继续使用相同的参数在300k步内进行训练,而没有引入说话人一致性损失。(看来这个算法比较难训练)
我们还选择了BNE-PPG-VC作为基准线。BNE-PPG-VC使用F0、PPG和说话人嵌入作为输入,通过seq2seq模型进行语音重建。由于该模型可以访问源语音的F0信息,它也可以在进行跨语言语音转换(XVC)时避免外语口音。我们在与ConsistencyXVC相同的三语数据集上对BNE-PPG-VC进行了训练。
在主观评估实验中,我们采用了平均意见分数(Mean Opinion Score,MOS)作为主观指标来计算转换后语音的自然度和相似度得分。我们邀请了来自Amazon Mechanical Turk的47名英语母语者来评估这些语音。所有的源语音都是英语,但参考语音可以是英语、中文或日语。每个参与者需要评估数据集中6个原始语音的自然度,以及60个转换后语音的自然度。此外,他们还需要评估32个转换后语音与目标说话人语音的相似度。一些音频样本可以在演示页面上找到。
表1中自然度的实验结果显示,参考语音不是英语并不影响英语语音的自然度。这表明模型在XVC任务中取得了成功。与此同时,说话人相似性实验显示,引入说话人一致性损失改善了生成语音的说话人与出现在模型训练集中的说话人之间的相似性。然而,对于在训练集中未见过的说话人,说话人一致性损失并没有改善说话人相似性。
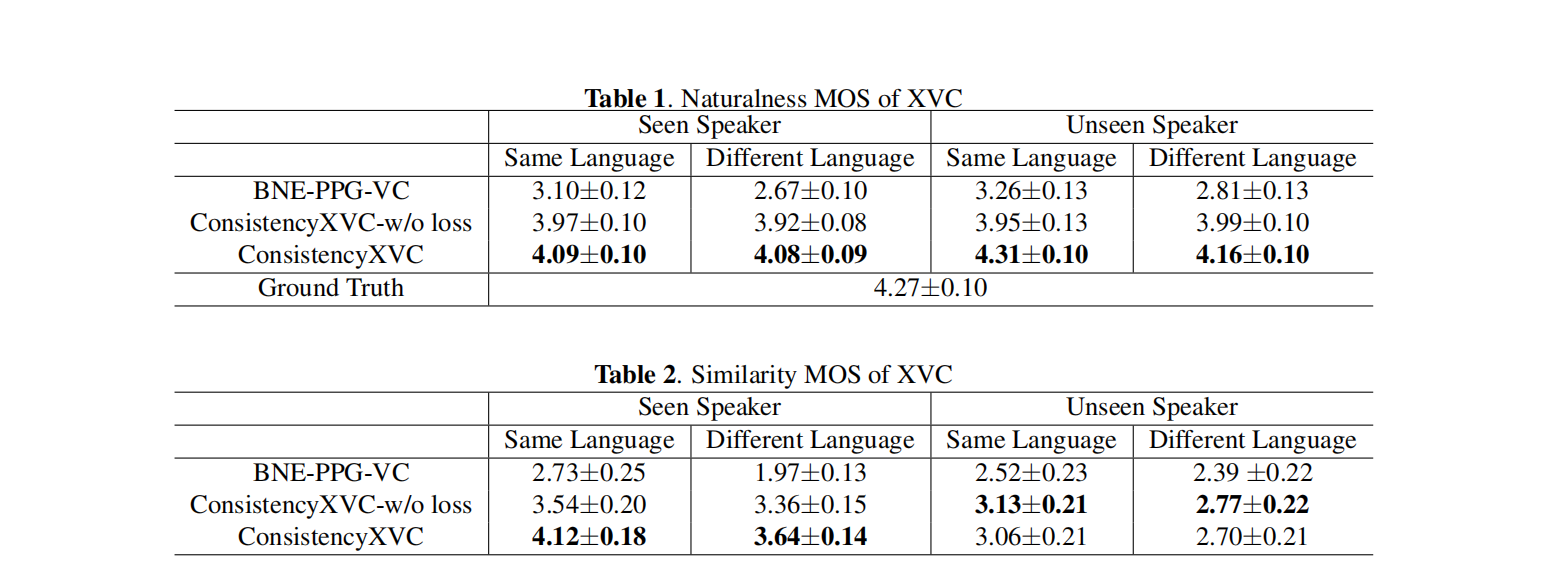
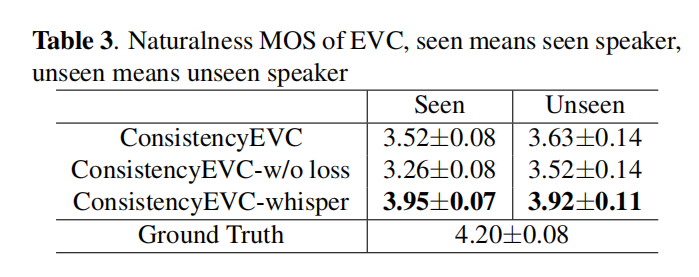
讲实话,基线和文章提出的指标差距有点大,一度直逼标签语音的质量,难道是商务评价?
EVC任务:
在EVC任务中,我们使用了英语数据集进行实验。我们从ESD数据集[2]和VCTK数据集[28]中选择了英语数据用于训练模型。此外,我们还从Emov-db数据集[32]中选择了样本作为参考语音,以考虑模型在模拟训练集中没有出现的说话人的情感语音方面的能力。
在EVC任务中,我们比较了ConsistencyVC模型的不同变体,包括是否使用说话人一致性损失以及使用不同类型的内容特征,包括PPG和WEO。
所比较的模型变体如下:
-
ConsistencyEVC:该模型使用PPG作为内容特征输入。在前100k步中,它以批大小为108的形式进行训练,不使用说话人一致性损失。然后,在接下来的200k步中,通过减小批大小至42,继续训练并加入说话人一致性损失。
-
ConsistencyEVC-w/o loss:该模型也使用PPG作为内容特征输入。在整个训练过程中,共进行300k步,批大小为108,且不使用说话人一致性损失。
-
ConsistencyEVC-whisper:该模型使用WEO作为内容特征输入。类似于ConsistencyEVC,在前100k步中,以批大小为108的形式进行训练,不使用说话人一致性损失。然后,在接下来的200k步中,通过减小批大小至42,继续训练并加入说话人一致性损失。
除了数据集和内容特征之外,所有其他训练参数与XVC任务中使用的参数保持一致。
在主观实验中,我们采用了类似于Du等人的方法[33],使用Mean Opinion Score(MOS)来计算语音的自然度,并使用ABX偏好测试来比较不同方法在风格相似性方面的结果。我们邀请了来自亚马逊 Mechanical Turk 的45位参与者参与实验。每个参与者对数据集中的六个原始语音和60个转换后的语音进行了自然度评估,并进行了36组偏好测试。在每个测试中,参与者被要求选择哪个语音更类似于参考语音,包括说话人和情感方面。
与XVC任务类似,使用说话人一致性损失提高了模型模仿已见说话人参考语音的能力。此外,实验结果显示,WEO作为内容特征在自然度(MOS)方面表现优于PPG。WEO包含更多适合重建的信息,从而产生更自然的合成语音。
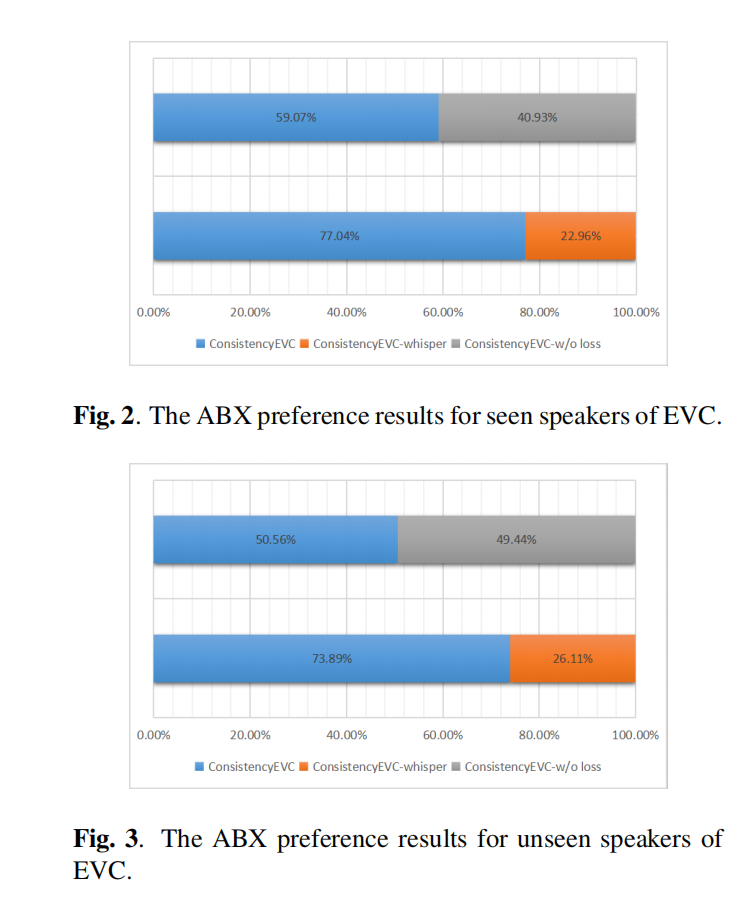
然而,在ABX偏好测试中,ConsistencyEVC-whisper的表现比ConsistencyEVC差。这是因为WEO除了内容之外还包含其他信息,例如语调,这对于XVC任务有助于消除外国说话者在不同语言中的口音。然而,对于EVC任务,我们希望保留源语音的内容特征,并让参考语音决定转换语音的语调。因此,WEO对于XVC任务较为适用,而对于EVC任务则较为不适合。
结论、限制和未来工作
在本研究中,我们在FreeVC-s的基础上使用了跨语言语音识别模型Whisper和基于wav2vec的音素识别模型来实现跨语言语音转换和情感语音转换。为了改进对参考语音的模仿能力,我们引入了共同训练的说话人一致性损失。实验结果表明,这种损失有助于改进说话人和情感特征。然而,我们的研究仍然存在一些限制:
-
对未知说话人的模仿能力下降:在测试集中,当参考语音属于未在训练集中出现的说话人时,模型的说话人相似度下降。通过使用更多多样的说话人数据来训练模型,可能会提高其模仿未知说话人的能力。例如,使用LibriTTS-R数据集[34]进行训练,该数据集包含来自2,456位说话人的585小时语音数据,可以提高零样本和更高质量的语音转换效果。
-
XVC和EVC任务的内容特征不一致:选择内容特征是灵活的。如果重点是保持语音质量和相似的音调,可以选择Whisper。然而,如果重点是表达情感,使用PPG作为内容特征可以确保VC模型生成与参考语音相同风格的语音。可能这两个任务并不是互相排斥的,因为XVC需要保留语调,而这在EVC任务中需要进行修改。未来的研究中,值得探索如何解耦语音中的情感和说话人信息的方法。
总的来说,本研究提出了一个有前景的方法来实现跨语言和情感语音转换,但仍有许多潜在的改进和应用可以探索。未来的研究可以继续在此基础上深入探索,推动语音转换技术的进一步发展。
CycleGAN-VC:https://arxiv.org/pdf/1711.11293v2.pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号