论文翻译:Speeding Learning of Personalized Audio Equalization
#论文翻译:
# Speeding Learning of Personalized Audio Equalization #
## Abstract ##
音频均衡器(eq)可能是音频制作中最常用的工具。SocialEQ项目是一个基于网络的个性化音频均衡系统,它使用了标准方法的替代界面范式。在这里,用户指定一个想要的效果(例如使声音温暖),并告诉工具(例如均衡器)什么设置使声音体现这个术语。SocialEQ通常需要25个评级来适当地个性化均衡设置。在本文中,我们提出了三种方法来提高个性化项目(音频设置)的生成速度,用户可以在评分数量少得多的例子后提供个性化的EQ曲线。这些方法可以适用于任何需要协同过滤的情况,为用户创建的最终产品是独一无二的,彼此之间具有可比性,但之前的用户不像当前用户对同一组示例进行评级。方法在1635个用户会话的数据集上进行测试。
## INTRODUCTION ##
Sabin et.al[1]开发了另一种界面范式,其中用户指定一个期望的效果(如使声音温暖),并告诉工具(如均衡器)应该应用哪些设置使声音体现该术语。术语(warm)和设置(各频段的增益/削减)的组合是一个用户概念(例如Bob s warm)。
SocialEQ[2]项目是一个基于网络基础的个性化音频均衡系统,使用[1]中的方法。自从它在网上发布以来,已经有超过3000个用户概念被传授给了这个系统。
数据集中的每个用户概念是通过让用户从用于训练系统的50个音频示例中随机选择25个音频示例来学习。尽管评级方法是构建个性化音频对象的好方法,但它需要从每个用户那里获得太多评级(例如25个)才能获得准确的结果。
为了减少用户需要回答的问题数量,在[3]中应用了迁移学习。我们的想法是使用先验知识来预测用户对未评级音频例子的评级。换句话说,在当前用户对少量示例进行评分后,该系统通过使用之前的用户数据来预测用户对其他未评级示例的偏好。[3]中的方法要求所有用户对完全相同的一组示例进行评级,这样就可以直接测量用户评级列表之间的距离。SocialEQ要求用户从50个样本中随机选择25个样本进行评分,所以大多数用户只在他们的评分样本中有一部分是重叠的。因此,必须修改该方法,以便当用户没有对相同的示例进行评级时,用户概念之间的相似性可以衡量。
在本文中,我们提出了三种方法来提高生成个性化条目(音频设置)的速度。
第一种改进了[1]中的学习算法。接下来的两种方法利用以前的用户数据加速个性化,克服了[3]中的限制。一种是允许用户概念之间的比较,而不直接参考用户评分。另一种是一种新的插补方法,它填补了缺失的评分,从而可以根据用户对条目的评分来比较用户概念。所有三种方法都可以适用于协作过滤的任何情况,令人满意的是,为用户创建的最终产品是独一无二的,彼此之间可以比较,但以前的用户不会像当前用户那样对同一组示例进行评分。
###RELATED WORK ###
在本文中,我们加快学习的一种方法与推荐系统中基于记忆的协同过滤有关。它通过分析其他用户[4]的已知喜好,预测用户未知的喜好。基于记忆的协同过滤的一个重要问题是如何处理稀疏的用户-物品矩阵来精确计算用户之间的相似度。Yongli等人[5]提出了一种选择信息量最大的缺失数据进行插补的方法,用于基于内存(基于邻居)的协同过滤。Hao等人[6]提出了一种缺失数据预测算法,该算法利用了用户和物品的信息。该研究认为,如果一件物品非常受欢迎,新用户很可能会给该物品一个好的评级,因此它同时使用用户相关性和物品相关性来预测遗漏的评级。然而,该论证可能不适用于我们的案例,因为项目(即音频例子)在本文中我们生成的音频意在调查用户对音频效果的偏好,但是同一个用户可以会对同一个音频实列进行不同的概念评价,列如(这音乐很细腻,这音乐是暗黑风)
Jeong等[7]定义了用户信用,并将每一组用户评级转换为用户信用。这使得即使在评分数据不完整的情况下,也可以衡量用户之间的相似性。我们在我们的一种方法中采用了类似的方法来加速对均衡曲线的学习。**请注意,我们处理的情况不同于一般的推荐系统**((例如电影或音乐推荐))我们不只是从评分项目中推荐一个现有的选项,而是创造一个新的个性化项目(EQ设置),体现用户的音乐喜好。
###METHODS ###
在本节中,我们解释了如何使用[1]中的原始方法,基于SocialEQ数据中的用户评分构建个性化的EQ曲线。然后,我们描述了对这种学习方法的改进和两种使用先验用户数据来加快学习的方法,一种依赖于缺失用户数据的归算,一种不依赖。
#### - A.The SocialEQ data set ####
SocialEQ数据集有3369个会话。单个会话包含来自单个用户的25个已知示例评级。在每次会话中,用户选择一个概念词(如细腻的)并以-1到1的等级来评价这些例子。 用户评分为1意味着音频示例与用户想要的声音完美匹配(如非常细腻的)用户评分为-1意味着示例具有相反的意义,如(非常不细腻的)。
一个音频的例子(给与用户做听觉体验的)是一个声音文件,它被修改为均衡设置,指定在40个频率的每个振幅的增强或削减。这一设置表示为具有40个数据点的曲线(EQ曲线)表示从20 Hz到19682 Hz的对数间隔频率(图2)。
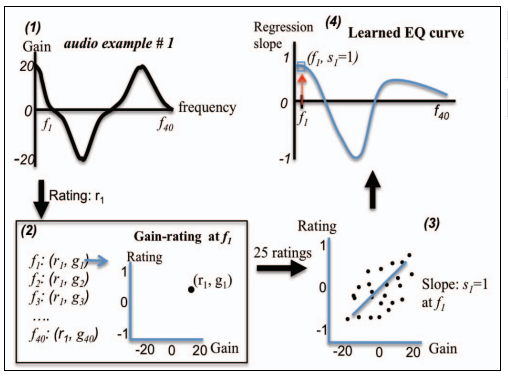
图2。概述基线学习方法的过程
当用户给一个音频例子评分为r1时,我们得到了在这40个频率点下的这40个增益的评级。例如,如果用户评分,25个音频示例,每个频带产生25个(评分,增益)数据点。在一个会话中,所有示例都将EQ曲线应用于相同的音频文件。每一阶段的所有EQ曲线都是从50条EQ曲线中绘制的。
我们使用[2]中使用的纳入标准来过滤会话,这样用来过滤一些垃圾数据。我们使用[2]中使用的纳入标准来过滤会话,这样只有那些付出努力并一直对示例进行评分的人的会话被用于我们的研究。我们还删除了任何参与者对调查问题回答“否”的数据,最后,每个参与者评价的40个例子中有15个是重复的例子。这让我们可以测试用户响应的一致性。我们使用皮尔森相关性来衡量每个参与者对第一次展示的例子和第二次展示的例子的评价之间的一致性。如果一个参与者的一致性低于所有参与者的平均值一个以上的标准差,那么该参与者就被排除在外。在过滤掉低质量的数据之后,我们有1635个之前的会议。本文中的所有结果都使用这组1635个会话。
#### - The Baseline Learning Method ####
一个用户想要的到的完美EQ曲线是逼近用户所描述的词的(例如一条完美调制的细腻型EQ曲线)在这项工作中,我们假设[1]的基线学习方法在一个会话中给出来自SocialEQ数据的25个评分示例时,能够完美地学习用户概念。
输入是一组包含25条指定的40频率点波段EQ的曲线。对于每个频带,我们从25个评级中计算用户的回归斜率。各频带的回归斜率表示用户喜欢的频率点的上的相对增益。这就产生了一条40点的EQ曲线,我们称之为用户概念。有关EQ构建过程的更详细说明,请参阅[1]。
#### - Speed Learning with Reestimation ####
如果只从几个被评级的例子(例如5个例子(**具体来说我理解为用户测试的轮次**),而不是25个)中学习,用基线方法建立的用户概念的估计可能是不可靠的。
然而,从较少的评级中获得的估计可以作为输入,用于预测用户尚未评级的例子的评级。然后,我们可以结合实际评分和估计评分来重新评估用户概念。方法如下:我们使用基线法得到由n个用户评分(如5个评分)生成的EQ曲线。接下来,我们预测其余未评级示例的评级(其余20个未评级的例子)通过计算皮尔逊相关性来估计用户概念EQ曲线和每个未评级音频示例的EQ曲线之间的关系。我们使用这个相关系数作为估计的评级。然后,我们通过使用估计值(例如20个估计值)和实际值(例如5)构建一条新曲线来重新估计用户概念EQ曲线,再用基线方法来生成回归曲线。我们称这种方法为重估。
#### - **Transfer learning and active learning** ####
迁移学习[8]是一种有效的学习方法,通过使用先前学习任务中的先前知识来加速概念学习。我们可以通过使用先前的用户数据(用户概念)来进一步改进我们对输出EQ曲线的估计,以增加从当前用户的评级中获得的信息。
这个想法是,如果两个用户概念彼此接近,无论是从用户给例子的评分,还是从评分的部分集合(即使只有几次评分)得到的EQ曲线来看是接近的,在25次评分后得出的用户概念EQ曲线也应该是相似的。当用户评价n个实例时,我们在n维评价空间或40维EQ空间中衡量当前用户概念与先前用户概念之间的相似性。一旦我们有了当前的用户概念和所有之前的用户概念之间的相似性,我们可以使用先验数据的k近邻线性组合(K-nearest neighbor linear)来估计当前用户对当前未评级示例的评分。在这项研究中,作为一种相似性度量,使用Pearson相关性,因为它解释了用户之间的缩放差异(即用户a对所有内容的评分范围为1到- 1,用户B的评价范围在0.01到-0.01之间)。我们选择了64个最接近的先前用户概念,因为一项初步研究表明,这个数字是产生良好估计的最佳数字。
主动学习是指学习者自己选择学习的例子,而不是被动地接受老师选择的例子。我们采用[9]中使用的主动学习方法,也就是根据之前所有用户对这些例子的打分的差异向用户展示这些例子。这使我们能够快速区分之前的用户概念,并在之前的用户概念(用户喜好)中定位当前用户的概念(喜好)。选择这种方法是为了简单、有效和与我们之前建立的工作相一致。与其他方法的比较超出了本文的范围。我们现在描述两种应用k近邻估计的方法
#### - Using Prior Data with Missing Values without need for imputation of missing values ####
在我们的例子中,任何两个用户学习到的均衡曲线都可以直接进行比较,尽管它们是由不同的评级对象生成的。因此,不需要对缺失的评级进行估计,这样就可以对所有之前的用户进行比较,我们从当前用户的评分集创建一个EQ曲线(即使他们只评价了几个例子)并将这条曲线与之前每个用户的情商曲线进行比较。注意,之前的用户EQ曲线是使用基线方法从会话中的所有25个示例中学习的。这让我们可以应用以前用户的数据,即使他们评价完全不同的EQ设置示例。从当前用户的评分中,我们使用基线方法从n个评分中构建了一条情商曲线,并衡量这条(公认很糟糕的)EQ曲线与从以前用户学习到的每条EQ曲线的相似性。。注意,之前的用户EQ曲线是使用基线方法从会话中的所有25个示例中学习的。这是用皮尔逊相关性完成的。然后,我们从64条最接近之前用户的EQ曲线中为当前用户创建一个复合EQ曲线。每个先验用户的用户概念EQ曲线的权重与其与当前用户的曲线的相似性成正比。
### - THE EXPERIMENT ###
这项工作的目的是减少评估用户想要的音频概念所需的评级示例的数量。为此,我们首先通过比较其他常见的插填方法来评估III-F节中描述的插填技术。然后我们测量第三节中描述的每种方法的学习速度。
#### - Data imputation evaluation ####
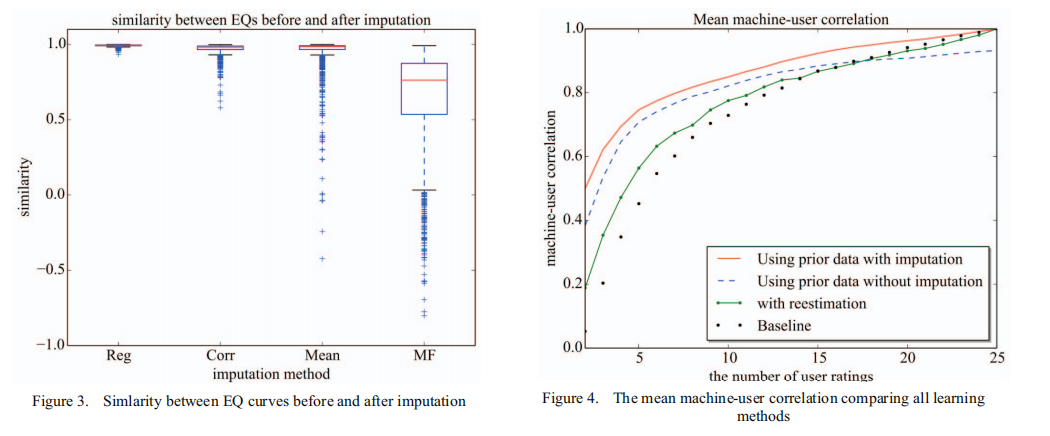
我们比较了第III-F节中的插填方法。(标记为Reg,用于回归)到三种广泛使用的技术来估算缺失值。这些是:1)用户的leanred EQ曲线和未评级音频例子之间的Pearson相关系数;(Corr) 2)所有先前用户对某些例子的评分平均值(mean);和3)矩阵分解(MF)[10]。图3显示了来自SocialEQ数据集中1635个用户概念的25个实际评分和25个实际评分+ 25个估算评分生成的EQ曲线之间的两两Pearson相关关系。相似性1.0表示从包括估算评分在内的数据中学习到的EQ曲线与仅从25个实际评分中学习到的原始EQ曲线是相同的。两种方法的Reg和Corr平均相似度值分别为0.992和0.969。更重要的是,从图中可以看出,我们的方法具有更稳定和准确的性能。即使在最坏的情况下,相关性也在0.95以上,而其他三种方法的相关性方差较大。这意味着我们的imputation方法比现有的方法更不可能通过创建错误的数据估计来扭曲结果。因此,让我们在迁移学习中使用先验数据是最好的方法。
#### - Learning methods evaluation ####
第三节中描述的方法是为了让系统学习比基线系统要求的评分更少的用户概念。我们测量每种加速学习方法的能力如下:首先,我们从SocialEQ数据中选择1635个之前的课程之一。每个会话有25个评分示例。然后,我们选择n个由该会话中的用户评分的音频示例。然后,我们使用第三节中的每一种方法生成一条EQ曲线来表示用户概念。为了衡量每条EQ估计曲线的正确性,将估计的EQ曲线与用户在该会话的全套评分示例生成的实际EQ进行比较。比较采用Pearson相关,相关系数称为机器-用户相关。我们对所有1635个之前的会话进行模拟,并通过取平均值总结出1635个机器用户相关值。图4显示了平均机器相关性作为额定示例数n的函数,比较了所有学习方法。这三种方法都优于基线方法。利用我们的imputation技术和测量相似性的imputation先验数据在评级空间是测试的最佳解决方案。例如,当我们使用该方法时,仅使用7个评分就可以实现与25个评分示例学习到的最终EQ曲线0.8的相关性。但基准方法需要13个等级才能达到相同的相关性水平。
### - CONCLUSIONS ###
我们提出了三种方法来减少创建个性化音频EQ曲线所需的评级数量,并使用SocialEQ数据集测试了这些方法。每种方法都比基线学习方法有所改善。当先验数据不可用时,我们在第三- c节中的重估计方法可以改善学习。如果之前的数据是可用的,而缺失数据的imputation是不可行的,第III-E节描述了一种方法,改进学习甚至更多。如果缺失评分可以可靠地估计,那么我们在第三- f节中的方法进一步改善了学习。此外,对于我们的数据集,Section III-F中的插填方法是新颖的,在估计缺失值方面明显优于现有的技术,如矩阵分解。这项工作可以适用于系统根据用户对样本物品的评分生成个性化物品的任何情况。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号