
原文链接: https://arxiv.org/pdf/2103.01468
开源 : https://github.com/griffbr/ODMD
论文切入点:给定一系列包围框和观察的相机移动距离,通过神经网络训练学习,来估计相机的深度。
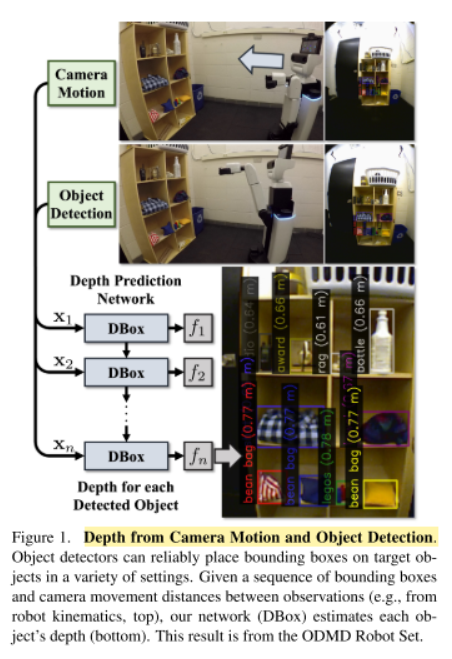
论文贡献
(1)提出未经标定的运动和基于检测的深度估计推导分析模型和相应的解决方案;
(2)开发递归神经网络(RNN),根据运动和边界框(DBox)预测深度;
(3)贡献了Object Depth via Motion and Detection数据集。
论文核心
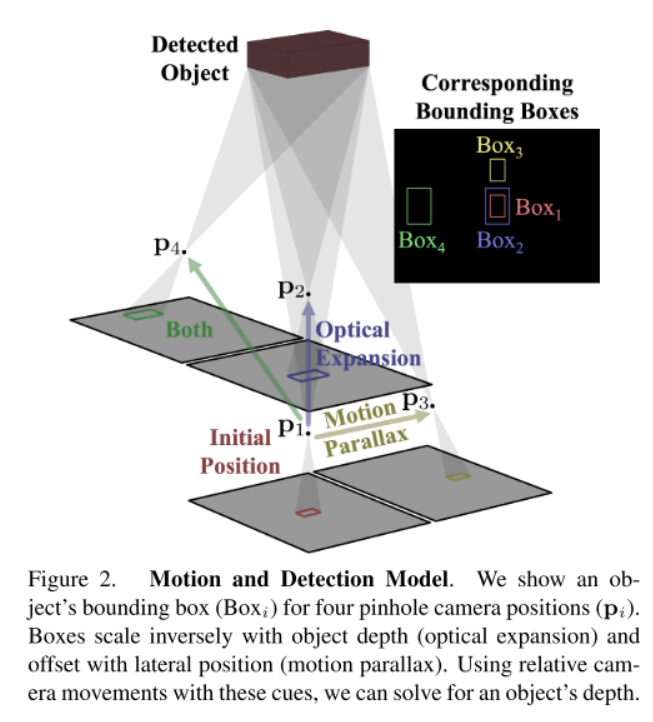
Depth from Motion and Detection Model
模型输入
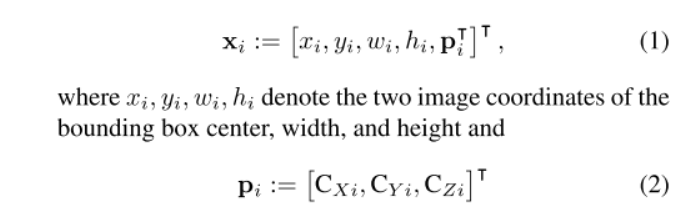
xi, yi, wi,hi分别表示为第i次观测的图像边框中心坐标、宽度和高度,Pi为相机的相应位置。
相机模型
可以参考相机模型的知识:https://zhuanlan.zhihu.com/p/52322904


fx, fy, cx, cy为相机的焦距和主点,X, Y为深度为Zi的3D相机帧中的图像坐标。Zi是摄像机与被探测物体可见周长之间沿光轴的距离(或深度)。
图像坐标中的目标宽度wi 与 世界坐标下的目标真实宽度W的关系:
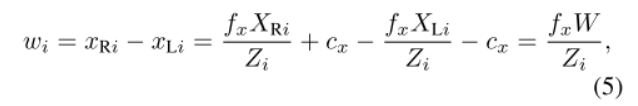
其中,xRi、xLi分别为左右方框图像坐标和3D坐标XRi、XLi(世界坐标系)。
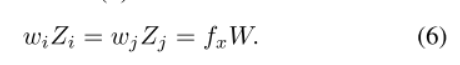
考虑相机位置Pi之后,静态对象的观察深度Zi的变化仅由相机位置CZi的变化引起

综合上面式子,相机深度Zi的解算为:
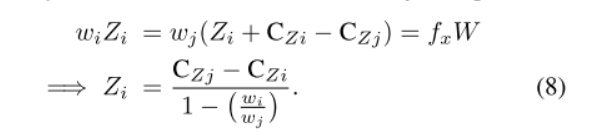
通过移动相机,得到n次观测,将上式处理为矩阵形式:
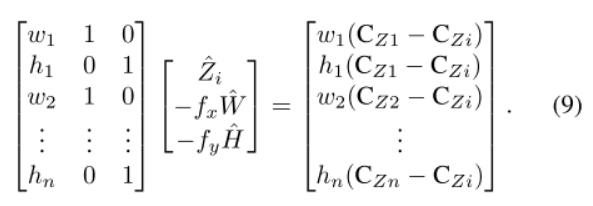
来自相机移动和检测网络的深度
网络输入
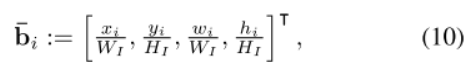
其中,WI和HI是方框图像的宽度和高度。
归一化相机位置Pi
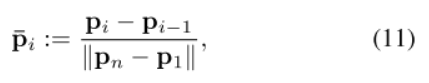
||Pn-P1|| 为欧几里得相机的整体移动范围,Pi - Pi-1表示摄像机增量移动。
综合(10)与(11),归一化的输入为:
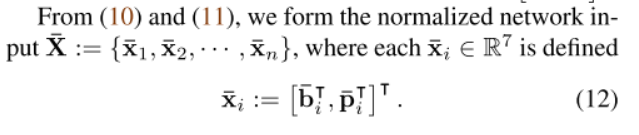
损失函数设计
真实相机深度与预测深度的偏差作为损失函数
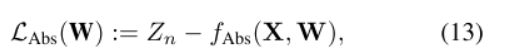
转化为无量纲损失,得:
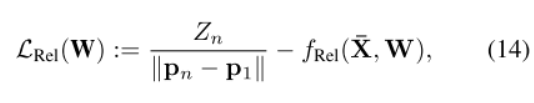
通过使用归一化和无量纲的输入损失公式(14),DBox可以在图像分辨率和摄像机移动范围大不相同的领域中预测物体深度。
神经网络架构
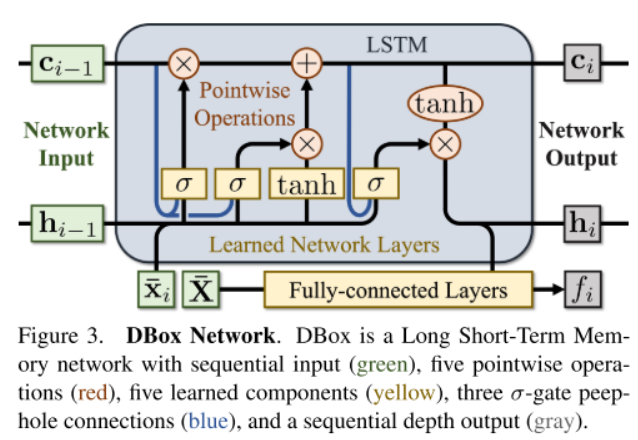
每一次观察i作为时序信息,通过LSTM来训练学习和预测。 用初始条件c0, h0 = 0,每个中间输入(ci−1,hi−1,xi~)和输出(ci, hi, fi)是唯一的。
数据集制作

生活中常用的数据组成,相机位置移动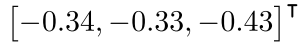 到
到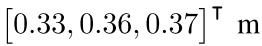 之间,相机深度Zn控制到0.11m——1.64m。
之间,相机深度Zn控制到0.11m——1.64m。
其他参数配置:

结果展示
评价标准

Zn为真实标签距离,Zn^为模型预测的相机距离。
物体深度通过运动和检测结果

其中,![]() 为对于Robot Set和整体的最好结果,
为对于Robot Set和整体的最好结果, ![]() 为对于动相机运动和目标检测集的最好结果,
为对于动相机运动和目标检测集的最好结果,![]() 为在正常下的最好结果,
为在正常下的最好结果,![]() 为只使用z轴摄像机运动的结果,
为只使用z轴摄像机运动的结果,
![]() 代表训练迭代为DBoxp的十分之一的结果,
代表训练迭代为DBoxp的十分之一的结果,![]() 训练一百倍迭代,如果需要,可以更快地训练最先进的DBoxp取得更好的结果。
训练一百倍迭代,如果需要,可以更快地训练最先进的DBoxp取得更好的结果。
对象深度通过运动和分割结果
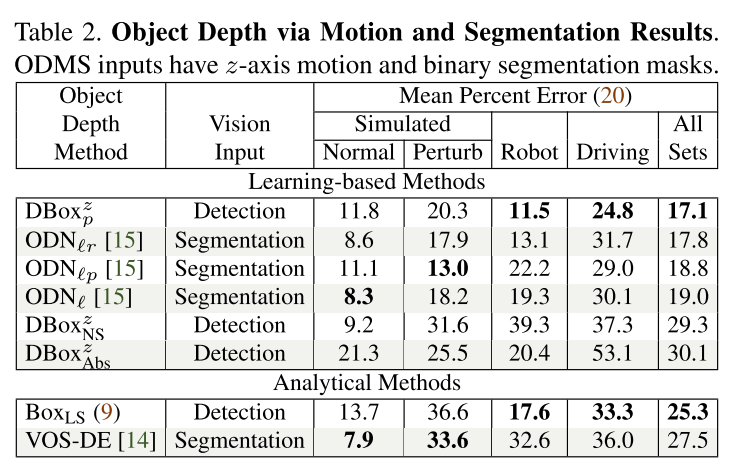
可视化结果

总结
创新点:众所周知,2D图像下,已经损失了目标的深度信息,这个文章提出一种通过相机移动并且使用LSTM神经网络来预测目标距离相机的距离。向大众提供了一份 ODMD数据集,
利用ODMD数据集训练第一个从运动和检测中估计目标深度的网络,开发了bounding box、相机运动和相对深度预测的广义表示,此可以改善广泛不同领域的通用适用性。
使用单一的ODMD训练的网络进行目标检测或分割,我们在现有的驾驶和机器人基准上实现了最先进的结果,并准确地估计了目标深度。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号