Linux中的数组
awk中的数组本来就是"关联数组",之所以先用以数字作为下标的数组举例,是为了让读者能够更好的过度,不过,以数字作为数组下标的数组在某些场景中有一定的优势,但是它本质上也是关联数组,awk默认会把"数字"下标转换为"字符串",所以,本质上它还是一个使用字符串作为下标的关联数组
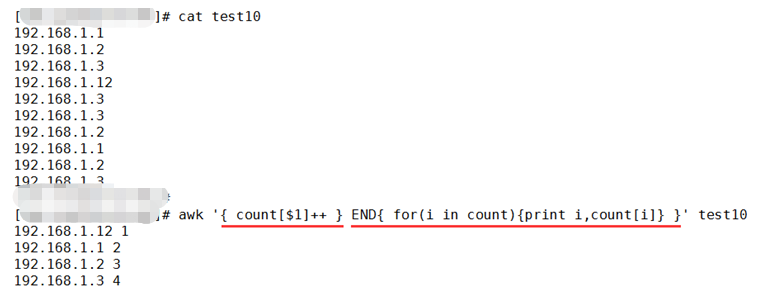
上图中,我们使用了一个空模式,一个END模式。
空模式中,我们随便创建了一个数组,并且将IP地址作为引用元素的下标,进行了引用,所以,当执行到第一行时,我们引用的是count["192.168.1.1"]
很明显,这个元素并不存在,所以,当第一行被空模式中的动作处理完毕后,count["192.168.1.1"]的值已经被赋值为1了。
由于END模式中的动作会最后执行,所以我们先不考虑END模式。
这时,空模式中的动作继续处理下一行,而下一行的IP地址为192.168.1.2
所以,count["192.168.1.2"]第一次参与运算的过程与上述过程同理。
其他IP地址第一次参与运算的过程与上述过程同理。
直到再次遇到相同的IP地址时,使用同样一个IP地址作为下标的元素将会再次被自加,每次遇到相同的IP地址,对应元素的值都会加1。
直到处理完所有行,开始执行END模式中的动作。
而END模式中,我们打印出了count数组中的所有元素的下标,以及元素对应的值。
此刻,count数组中的下标即为IP地址,元素的值即为对应IP地址出现的次数。
最终,我们统计出了每个IP地址出现的次数。
其实,我们就是利用了之前所演示的一个知识点:
我们对一个不存在的元素进行自加运算后,这个元素的值就变成了自加运算的次数
count是数组名。由于直接引用一个数组中不存在的元素时,AWK会自动创建一个元素。
所以当遇到第一个ip时,由于该元素不存在,所以会创建下标为该ip的元素,且元素值在自加后为1,当再次遇到该元素时,由于相同下标的该元素已经存在且值为1,故会在1的基础上自加,即文章中所说的“对一个不存在的值进行自加运算后,这个元素的值就变成了自加的次数“

 浙公网安备 33010602011771号
浙公网安备 33010602011771号