第4章 4.5 读取csv文件
1. 读取csv文件:
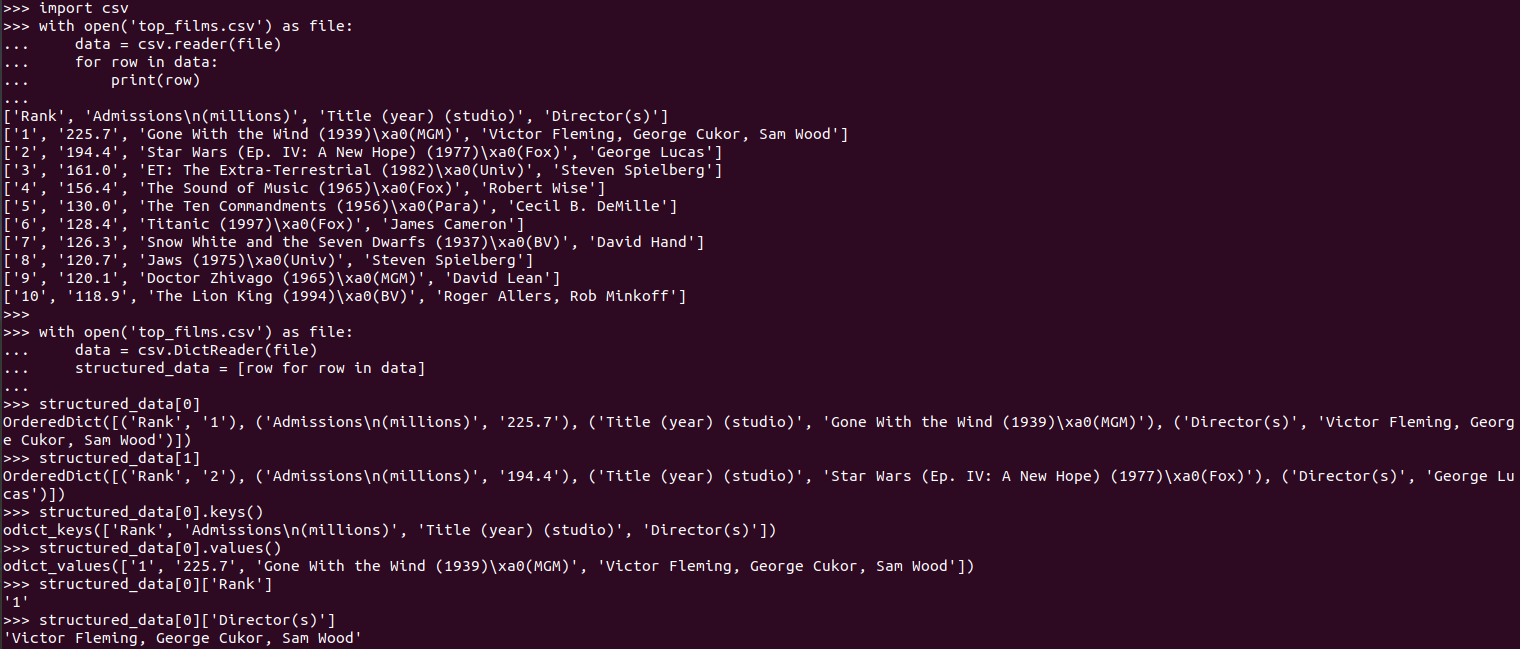
>>> import csv
>>> with open('top_films.csv') as file:
... data = csv.reader(file)
... for row in data:
... print(row)
...
['Rank', 'Admissions\n(millions)', 'Title (year) (studio)', 'Director(s)']
['1', '225.7', 'Gone With the Wind (1939)\xa0(MGM)', 'Victor Fleming, George Cukor, Sam Wood']
['2', '194.4', 'Star Wars (Ep. IV: A New Hope) (1977)\xa0(Fox)', 'George Lucas']
['3', '161.0', 'ET: The Extra-Terrestrial (1982)\xa0(Univ)', 'Steven Spielberg']
['4', '156.4', 'The Sound of Music (1965)\xa0(Fox)', 'Robert Wise']
['5', '130.0', 'The Ten Commandments (1956)\xa0(Para)', 'Cecil B. DeMille']
['6', '128.4', 'Titanic (1997)\xa0(Fox)', 'James Cameron']
['7', '126.3', 'Snow White and the Seven Dwarfs (1937)\xa0(BV)', 'David Hand']
['8', '120.7', 'Jaws (1975)\xa0(Univ)', 'Steven Spielberg']
['9', '120.1', 'Doctor Zhivago (1965)\xa0(MGM)', 'David Lean']
['10', '118.9', 'The Lion King (1994)\xa0(BV)', 'Roger Allers, Rob Minkoff']
>>>
>>> with open('top_films.csv') as file:
... data = csv.DictReader(file)
... structured_data = [row for row in data]
...
#DictReader()函数是将默认第一行为标题,作为字典的键,联合其它行对应的列组成字典。data是一个数据对象,需要循环之后转成列表
>>> structured_data[0]
OrderedDict([('Rank', '1'), ('Admissions\n(millions)', '225.7'), ('Title (year) (studio)', 'Gone With the Wind (1939)\xa0(MGM)'), ('Director(s)', 'Victor Fleming, George Cukor, Sam Wood')])
>>> structured_data[1]
OrderedDict([('Rank', '2'), ('Admissions\n(millions)', '194.4'), ('Title (year) (studio)', 'Star Wars (Ep. IV: A New Hope) (1977)\xa0(Fox)'), ('Director(s)', 'George Lucas')])
>>> structured_data[0].keys()
odict_keys(['Rank', 'Admissions\n(millions)', 'Title (year) (studio)', 'Director(s)'])
>>> structured_data[0].values()
odict_values(['1', '225.7', 'Gone With the Wind (1939)\xa0(MGM)', 'Victor Fleming, George Cukor, Sam Wood'])
>>> structured_data[0]['Rank']
'1'
>>> structured_data[0]['Director(s)']
'Victor Fleming, George Cukor, Sam Wood'
>>>
>>>
>>>
>>>
>>>
>>> with open('top_films.csv') as file:
... data = csv.DictReader(file)
...
>>> print(data)
<csv.DictReader object at 0x7fc69aefd610>
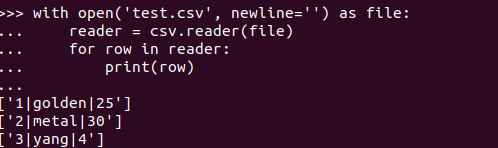
2. csv文件可以用逗号、分号、竖线或制表符等分隔,当使用竖线时,使用csv.reader()的默认方法读取文件,得不到真正想要的分隔,可以使用Sniffer类分析文件以什么分隔,如下:
(.venv) (base) metal@metal-Lenovo-Product:~/project/PAutomationCookbook/ch04$ cat test.csv
1|golden|25
2|metal|30
3|yang|4

>>> with open('test.csv', newline='') as file:
... reader = csv.reader(file)
... for row in reader:
... print(row)
...
['1|golden|25']
['2|metal|30']
['3|yang|4']
>>> with open('test.csv', newline='') as file:
... dialect = csv.Sniffer().sniff(file.read())
...
>>> with open('test.csv', newline='') as file:
... reader = csv.reader(file, dialect)
... for row in reader:
... print(row)
...
['1', 'golden', '25']
['2', 'metal', '30']
['3', 'yang', '4']

考虑到csv文件中同时包含逗号和其它分隔符号,csv.Sniffer()方法也能正确嗅探到真正的分隔符号,如下:
(.venv) (base) metal@metal-Lenovo-Product:~/project/PAutomationCookbook/ch04$ cat test.csv
1|golden,2|25
2|metal|30
3|yang|4
(.venv) (base) metal@metal-Lenovo-Product:~/project/PAutomationCookbook/ch04$ python
Python 3.7.6 (default, Jan 8 2020, 19:59:22)
[GCC 7.3.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import csv
>>> with open('test.csv', newline='') as file:
... dialect = csv.Sniffer().sniff(file.read())
...
>>> with open('test.csv', newline='') as file:
... reader = csv.reader(file, dialect)
... for row in reader:
... print(row)
...
['1', 'golden,2', '25']
['2', 'metal', '30']
['3', 'yang', '4']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号