第一ppt网站爬虫与acw_sc__v2加密解密
基于scrapy框架,爬取第一ppt网站上的ppt文件。涉及到acw_sc__v2的加密解密,以及爬虫项目执行时遇到的问题处理记录。
1.说在开始
最近折腾了一下爬虫相关的东西,了解了爬虫的发展历史与技术栈,整合到一起方便后期复习查看。
爬虫属于灰色地带,有恶意的有善意的。所以写爬虫相关的东西,还是要遵守基本道德,只取自己所需资源,只取免费资源,不要触碰别人的利益,砸别人饭碗。
一些恶意的爬虫项目,把什么多线程多进程爬虫,协程爬虫,分布式爬取这些手段几乎全部用上,爬取时间间隔也不加限制,恨不得一秒钟对一个网站访问几十万次,这就给别人的网站带来巨大的负担,一些服务器比较低级的小网站,可能瞬间就崩溃了。并且基于scrapy框架,上述的手段实现也比较简单,目前的爬虫难的不是这些,对于各种验证码的处理,也有很多现成的处理措施,比较有意思的还是js逆向,各种加密手段的解密,攻克这些才是比较有成就感的。
在我看来,善意爬虫就像是对于数据的批量处理,只不过这些数据是在网上,不像是在本地处理那样快速方便。一些网站上的图片,文件本来就是供免费下载的,一些爬虫的需求可能仅仅是一个网页页面上的一行文字,所以如果是需要大批量的下载或者文字复制粘贴,人力也可以做到,只不过是浪费时间,而爬虫就是在节省这个时间。所以,只要限制自己的爬取速度,在不伤害别人网站的前提下,提取一些免费资源,爬虫也不是那么的邪恶。
2. Scrapy
实现爬虫的方式有比较多,其中觉得比较有意思的就是scrapy框架。之前学过Java和Springboot相关的东西,知道了框架绝对是个好东西,可以极大的方便开发。此外,对于selenium也比较感兴趣,但是用selenium做爬虫实在是速度慢,而且这玩意儿最初始设计出来就不是为了爬虫,对这玩意儿感兴趣,是因为感觉它和python自带的键盘鼠标控制等脚本化的包结合在一起,可以更加方便的写一个自动化的脚本,或者写一些小工具,还是比较有意思的。
基于上述,后续的爬虫相关,主要还是基于scrapy框架以及xpath的解析方式。
首先必须了解scrapy的框架结构和基本运行逻辑,以下图片便很好的进行了说明:
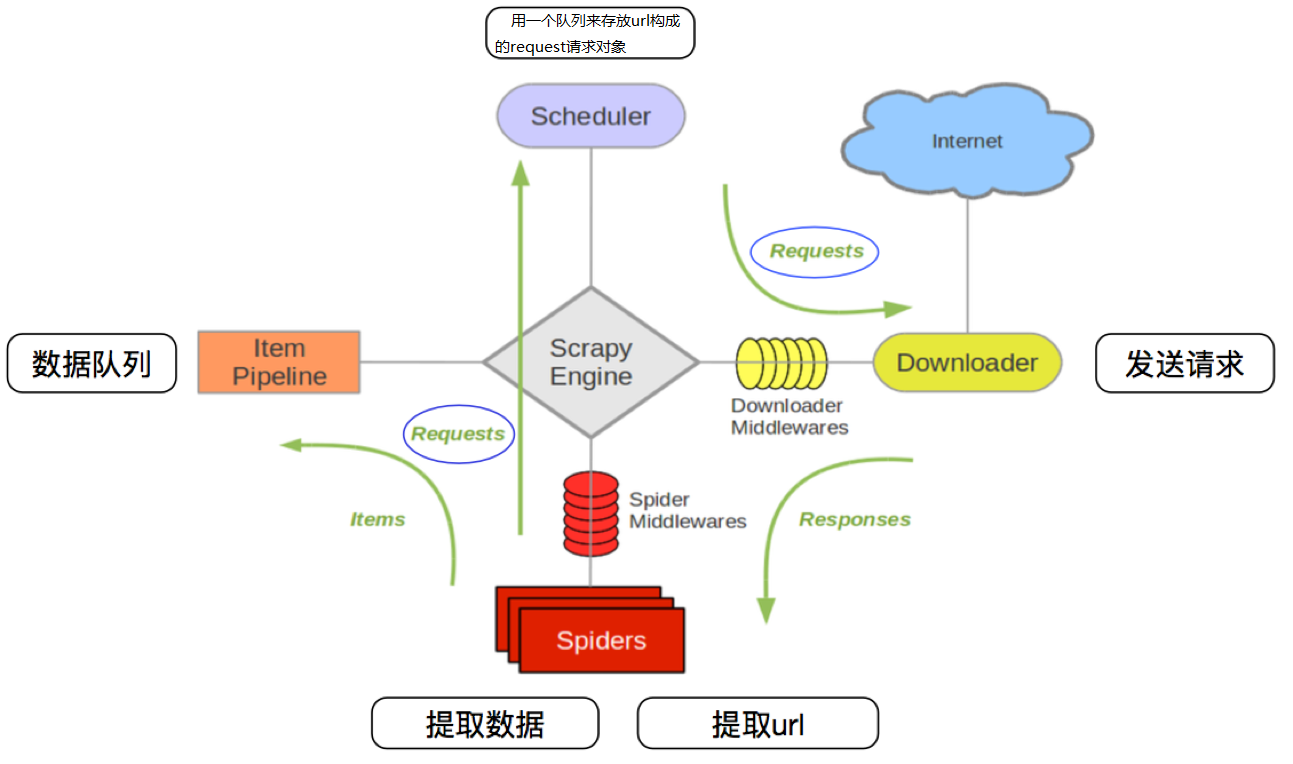
上述图片的每个模块的详细,网上有很多教程,理论方面不做过多描述。内部源码感觉也不像Java,python,springboot那样需要深挖,爬虫说到底也就是个工具,没有必要深挖内部逻辑,了解基本框架和运行逻辑,会使用即可。
-
scrapy基本命令(创建完之后,模板中的具体语句说明,见后续项目实战注释)
# 新建一个项目 scrapy startproject 项目名 # 定位到项目文件夹下,并生成一个爬虫模板文件,名字和项目文件名尽量一致 cd 项目名 scrapy genspider 模板名 起始域名 -
配置文件说明和修改
# 这三个无需修改,表示项目名包名等等 BOT_NAME = "ppt" SPIDER_MODULES = ["ppt.spiders"] NEWSPIDER_MODULE = "ppt.spiders" #写用户代理,最基本的避免反爬 USER_AGENT = "" #ROBOTSTX协议,默认TRUE,但是国内几乎就没有允许爬的网站,设置成false ROBOTSTXT_OBEY = False #默认最大并发量,下载器基于多线程,可以理解为开了多少个线程(可以开小点,避免反爬拉黑) CONCURRENT_REQUESTS = 32 #和上面想法,降低抓取频率,太快容易被拉黑 DOWNLOAD_DELAY = 3 #cookie允许,默认就是false COOKIES_ENABLED = False #header设置,上述的user-agent也可以写在这里,避免反爬.Cookie也可以放进去 DEFAULT_REQUEST_HEADERS = { "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8", "Accept-Language": "en", } #开启管道,多个管道可以设置优先级,300是默认,数字越小优先级越高 ITEM_PIPELINES = { "PPT.pipelines.PptPipeline": 300, } #日志设置(debug<info<warring<error<critical) #等级 LOG_LEVEL='INFO'(只会显示这个等级及其以上等级的日志) #把日志保存,用于后续分析 LOG_FILE='名字.log' #乱码处理,设置数据导出的编码('gb18030',默认是utf-8,一般导出为csv或者json时,会设置这个) FEED_EXPORT_ENCODING= #自定义中间件的优先级 SPIDER_MIDDLEWARES = { "PPT.middlewares.PptSpiderMiddleware": 543, } -
总项目文件夹下,新建一个run.py,用于启动项目。位置如下:
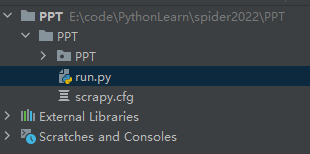
# 加上split,不然scrapy crawl ppt就被当成了一个参数,而不是三个 'scrapy crawl ppt'.split()
具体各模块的详细说明,和代码详解,见后续项目的注释。
3. 第一PPT网站文件爬取
3.1 项目要求
爬取PPT下载 - 第一PPT (1ppt.com)中所有类别中的第一页中,所有的ppt模板文件。
这是一个多页的爬虫项目
-
第一页:跳转到下载页面
- xpath:
/html/body/div[4]/div[@class="col_nav clearfix"]/ul/li - 提取栏目分类名称:
./a/text() - 得到栏目分类链接:
./a/@href需要和https://www.1ppt.com/拼接形成具体分类的页面链接
- xpath:
-
第二页:进入某一个分类页
- xpath:
//ul[@class="tplist"]/li - PPT名称:
./h2/a/text() - 进入PPT详情页链接:
./h2/a/@href需要和https://www.1ppt.com/拼接形成具体分类的页面链接
- xpath:
-
第三页:一个分类存在多页面
- 获取每一个页面的url地址
- 第一页的地址就是当前分类页面的地址,更新完meta再次放入调度器,不可以过滤
-
第四页:进入了某一个PPT详情页
- xpath:
//ul[@class="downurllist"]/li/a/@href需要和https://www.1ppt.com/拼接形成具体分类的页面链接 - 进入下载页链接
- xpath:
-
第五页:进入下载页面
- 第一ppt对下载页面进行了加密处理,需要进行加密方法提取,以及写相应的解密程序
- 修改请求内容,重新访问下载页
-
第六页:重新进入下载页
- xpath:
//ul[@class='downloadlist']/li[@class='c1']/a - 提取具体的ppt下载链接,交给项目管道文件处理
- xpath:
3.2 相关代码
scrapy的模块有好几个,在文档里对每个模块分别说明非常麻烦。具体说明在代码中进行了详细注释。
3.3 相关问题处理记录
-
acw_sc__v2解密,js逆向。详情在代码注释中有详细解释。
参考链接:cookie 参数 acw_sc__v2 加密分析
以及提供几个好用的工具链接:
-
调度器的请求过滤设置
坑了我很久,由于使用的scrapy框架,所有的请求是要传给调度器的,调度器如果默认设置,会将重复的链接删除掉,避免多次请求。
这个去重功能是为了避免请求相同的链接,导致爬取的数据出现重复,干扰也浪费空间。但是这个案例特殊在更新cookie之后,需要重新加载下载页面,也就是要重新进行请求。这个请求和重新加载前的页面唯一的区别就是cookie更新为解密之后,生成的cookie,但是url链接并没有发生变化,而调度器的去重仅仅基于sha1的加密算法生成指纹做判断的,而不是看两个请求整体是不是一样,这就导致更新后的请求进入调度器之后,被过滤掉了,所以这一级页面的请求,需要将dont_filter设置成TRUE。
本项目的多页提取也存在这个问题,在翻页时,第一页的链接不会变化,直接用的父链接。在翻页提取的时候,需要一个循环,但是第一个链接不能变化,并且需要重新请求一次,因为meta的数据需要更新。但是调度器中已经存在了一个相同url的链接,此时再调入一个,会被过滤,此时也需要设置不允许过滤。
不知道scrapy中能不能直接修改调度器的代码,或者存在什么方法,使得过滤的时候,只要新的数据,过滤掉旧的数据
-
日志只会在控制台中展示,一旦设置了LOG_FILE,日志就会存入文件,而不在控制台展示
写一个Log类,新加一个handler,这样日志既可以在控制台输出,也可以在文件中输出
import logging class Log(): log = logging.getLogger() log.setLevel("INFO") # 创建控制台Handler并设置日志级别为DEBUG console_handler = logging.StreamHandler() console_handler.setLevel("INFO") # 创建Formatter并将其添加到Handler中 formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') console_handler.setFormatter(formatter) # 将Handler添加到logger中 log.addHandler(console_handler) def __init__(self): self.log = Log -
open和spider的参数问题
pipeline中在存入mysql的时候,这两个函数必不可少,确保数据链接和关闭只进行一次。这两个函数得入参必须要存在一个参数,虽然这个参数后续没有用上,但是也不能删掉。这属于低级错误。
4. 写在最后
本项目是我的第一个爬虫实践,真正有意思的还是数据解密的环节,这种攻防才是最有意思的。写爬虫还是得有基本的道德底线,毕竟属于灰色地带,相关的爬虫脚本功能目的,最好还是替代人工进行网页上免费资源的获取,属于自动化工具,而不是恶意攻击和收费资源的爬取,不然真就是“爬虫写的好,监狱进的早”了,共勉。
之前从事代码相关的工作,使用的是java。由于后续从事人工智能,需要使用python,代码这东西还是敲几遍才会有提升,光看教程用处不大,此次爬虫脚本也算是我第一次用python自己写了一个项目。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号