Redis
简介:
Redis是一个开源(BSD许可),内存存储的数据结构服务器,可用作数据库,高速缓存和消息队列代理。它支持字符串、哈希表、列表、集合、有序集合,位图,hyperloglogs等数据类型。内置复制、Lua脚本、LRU收回、事务以及不同级别磁盘持久化功能,同时通过Redis Sentinel提供高可用,通过Redis Cluster提供自动分区。Redis目前是市面上90%以上的公司都在使用的一个高性能分布式中间件。学好Redis是成为架构师的必修课。
入坑:建议查看教程:Redis中文网
入坑:Redis核心概念:
1.一句话总结redis------Redis就是一个进程外的分布式缓存
入坑:Redis应用场景:
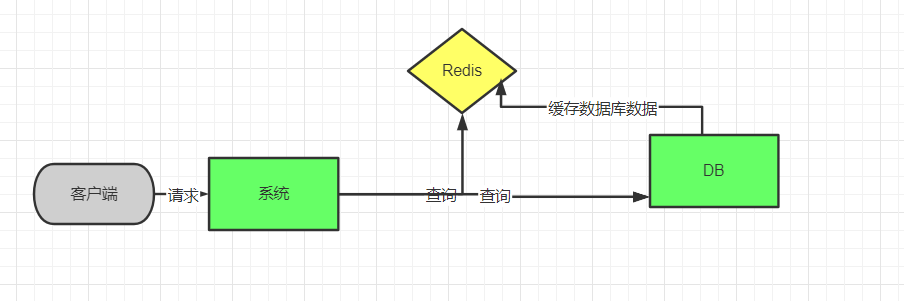
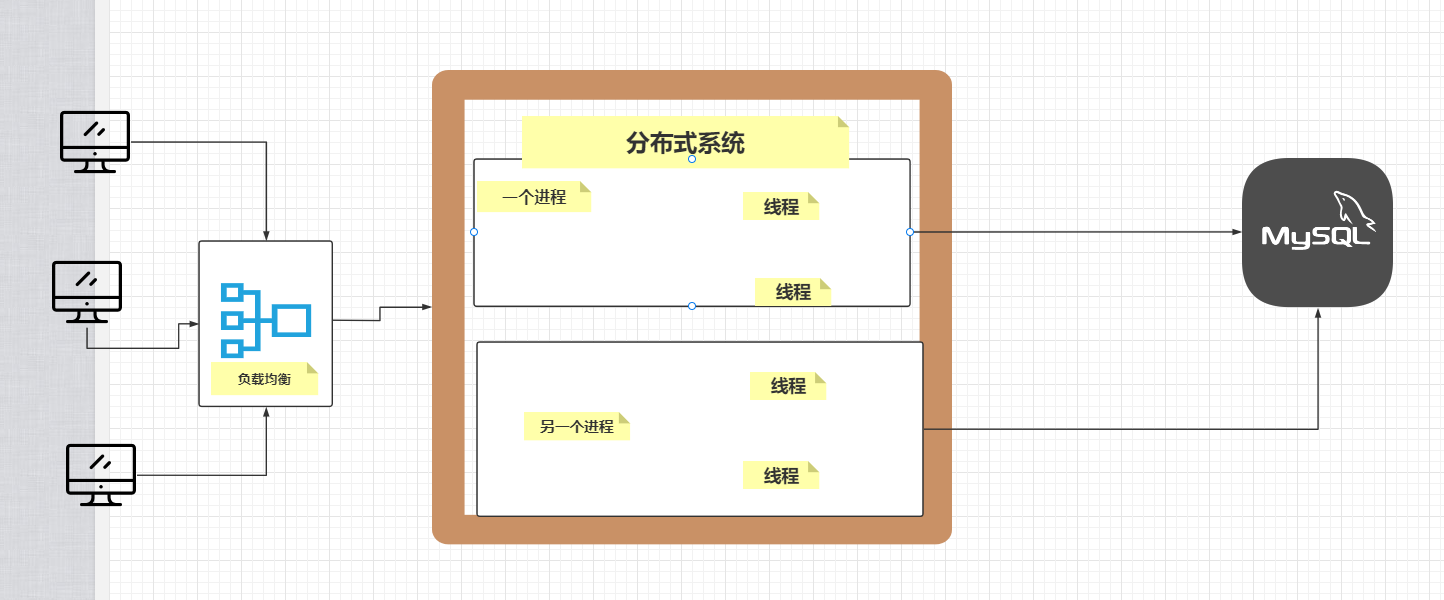
1.首先 在集群项目中使用 ,例如电商集群系统;如下图所示
2.如果是单体系统 如下图所示
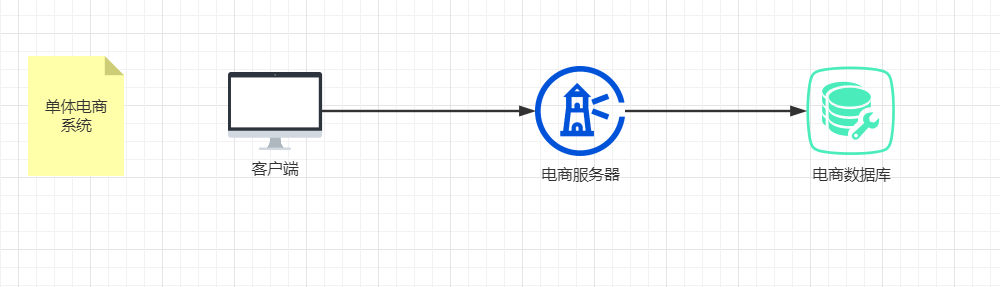
2.1:查询商品业务流程:客户端请求---》应用服务器----》数据库查询 ——》返回服务器——》客户端
2.2:首先一个前提:数据文件在数据库系统中存在与服务器磁盘中,而应用服务器中数据常常存储在应用服务器内存中,这就意味着 服务器的并发处理请求能力比数据库处理请求能力要高;大概是 应用 服务器处理500个 ,数据库可以处理200个,在客户端满载时,数据库压力过大 可能导致宕机等后果
2.3:任何情况下提升系统性能的第一步就是 使用缓存:如下图,此时可能完全适应500的并发请求,等到并发的需求大于500时 系统内部缓存似乎也土崩瓦解不堪重任,数据库 应用服务器都有可能宕机

2.4:如何解决?如果一台不行 那就再来一台 这就是集群系统产生的原因之一(高并发,高性能 高可用) 如图
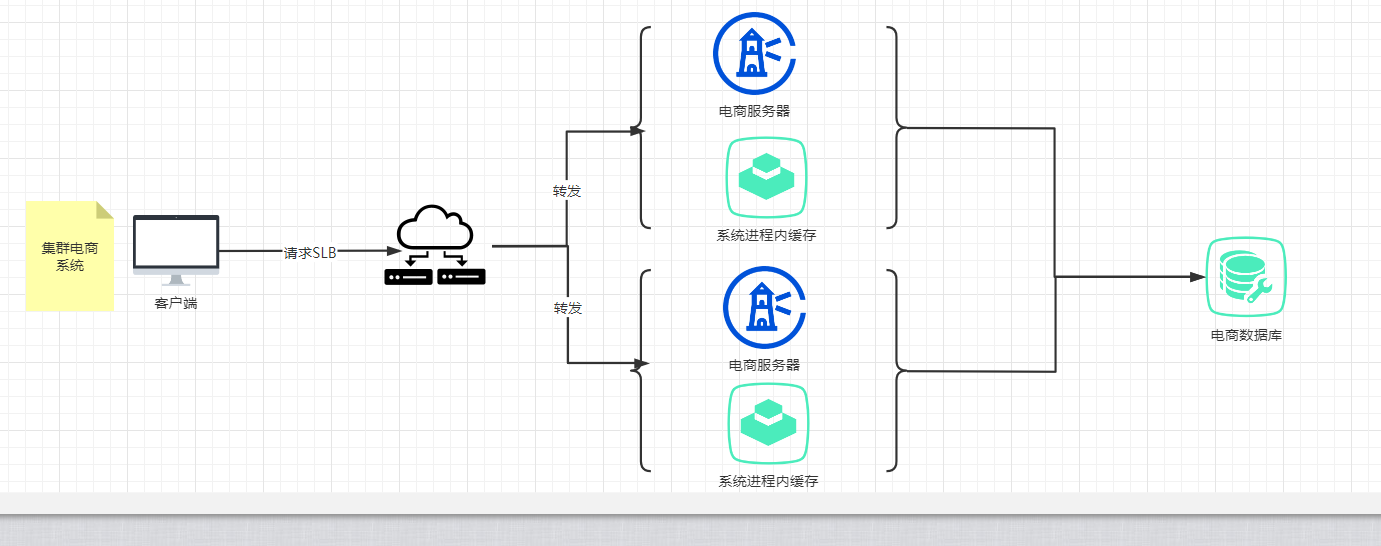
如上图所示 电商服务器已经集群,但是我们将请求进行了nginx转发,第一次请求时,访问01服务器 数据库回源,缓存本地,第二次同样的请求 访问02服务器 加载服务器缓存 缓存为0 数据回源,加载到内存缓存中,这样缓存命中率只有50%,并且每台服务器保存一份 服务器内存严重浪费,加上数据库回源请求,数据库压力上升,导致查询性能下降。这就是使用集群系统的缺点,当然 我们可以在nginx处做一点配置(使用)Iphase ;
2.5:如何提升查询性能;
他的原因:缓存命中率低 ————》解决 提升命中率, 内存缓存分布在每个系统 我们只需要将 缓存独立在一起这样就可以解决命中率问题;--------------------》使用Redis
总结:使用redis主要应用在集群系统中,如果使用的是单体系统,就不建议使用Redis,强烈建议使用本地缓存,因为:本地缓存存在本地,性能远远比redis高,使用redis还需要网络IO,即使他的性能很高。
linux 安装Redis
省略
入坑:Redis通信原理:
1.redis 建立连接过程 :
理解1:
1.1 建立redis连接 (多路复用机制,可以理解为订阅发布机制)
1.2:通过socket四层通信进行连接 客户端 发起连接----》发送到链路层 ---》OS---》获取请求----》向Redis发起请求
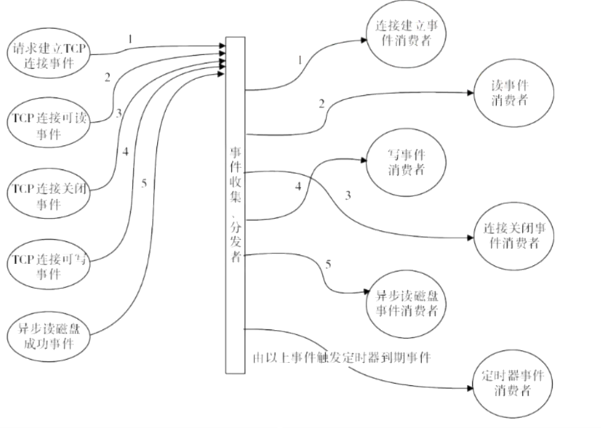
1.4 Redis的异步通信: 为了提升性能 OS会一次性的将请求 推送到 事件处理器 redis会订阅该处理器进行多线程处理 这种模型被称为 epoll模型
理解二“
请看下图
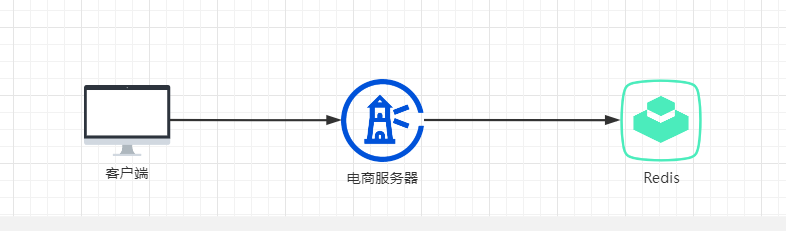
1.5:电商系统和redis连接 靠socket 四层连接 如图
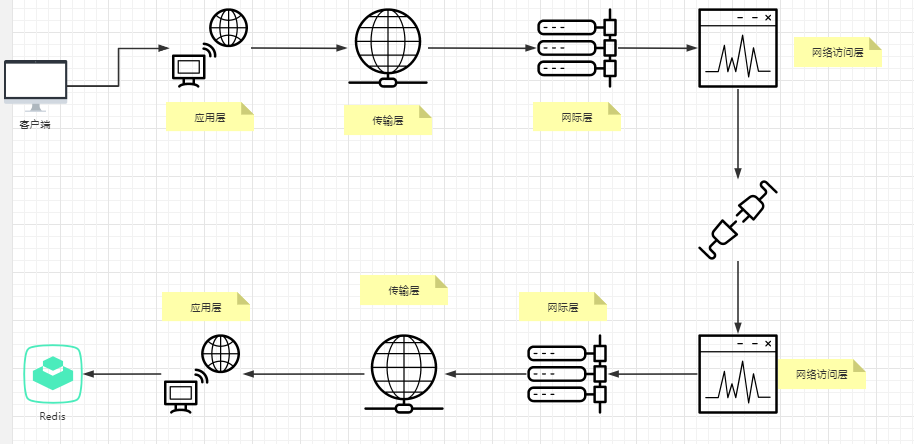
1.6:当网络访问层收到请求 通过Os将请求一层一层向上发向Redis OS 请求 redis 如果是同步请求 每一次请求都会消耗一个线程来建立 连接,如何让一个线程来解决100个请求?看图
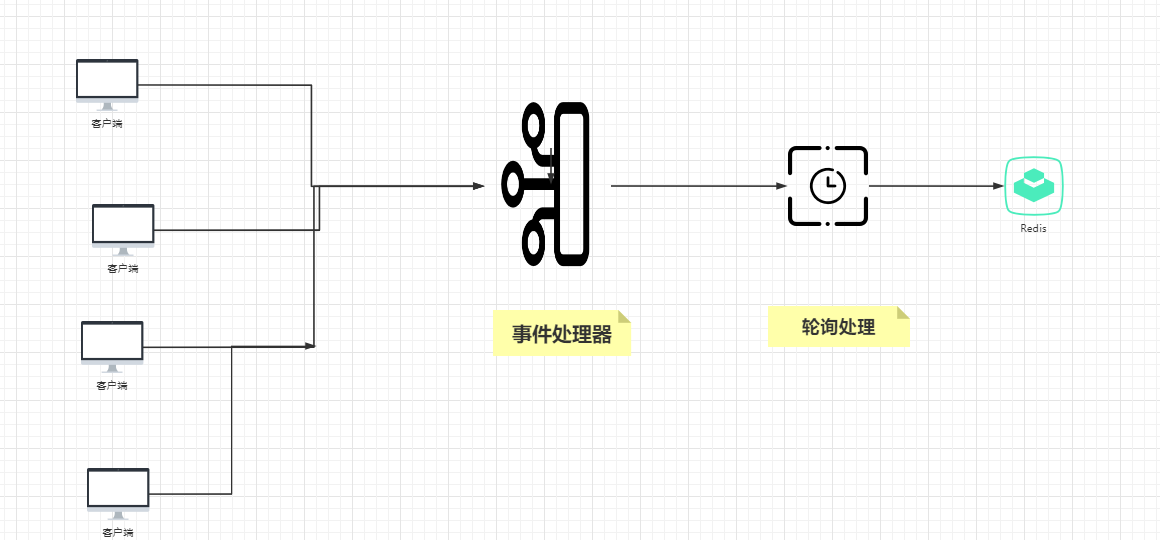
1.7:当很多个客户端发起对redis的请求时 ,将所有请求放入到 消息处理器,redis只需要对消息处理器轮询处理
1.8:上图解释: 左边部分为OS接受各种来自client的请求,右边为redis从消息收集器轮询处理消息
总结:1.epoll模型就是 Os+ 队列 的多路复用机制: 多路:多个客户端 ; 复用:一个redis线程和所有客户点交互的过程;
2.连接查询 缓存的三件事 :1.建立连接 2.存储数据到本地缓存 3.持久化数据到本地文件(开启新线程)
3.reids使用单线程:reids完全基于内存操作,性能足够,若使用多线程 形成线程锁导致性能下降
4.redis使用多线程:开启多个线程做不同的事情,而不是开启多个线程干一件事;
入坑:Redis数据结构原理:
1. 数据为一条商品数据:通过stringset()将数据存到redis内存中, redis 不支持对象,所以需要jsonconvert(object)
2.数据为集合的商品数据:通过SetAdd()/SetMembers 存取集合数据;
2.1.Q:Redis如何将数据存到set?
A:通过数组存储数据;通过Hash标识数组元素 ,
Q: 如果修改某条数据的某个属性的值怎么办? 使用HashSet存储
3.(HashSet)字典 通过 HashSet/HashGet 存取数据,key/Value格式
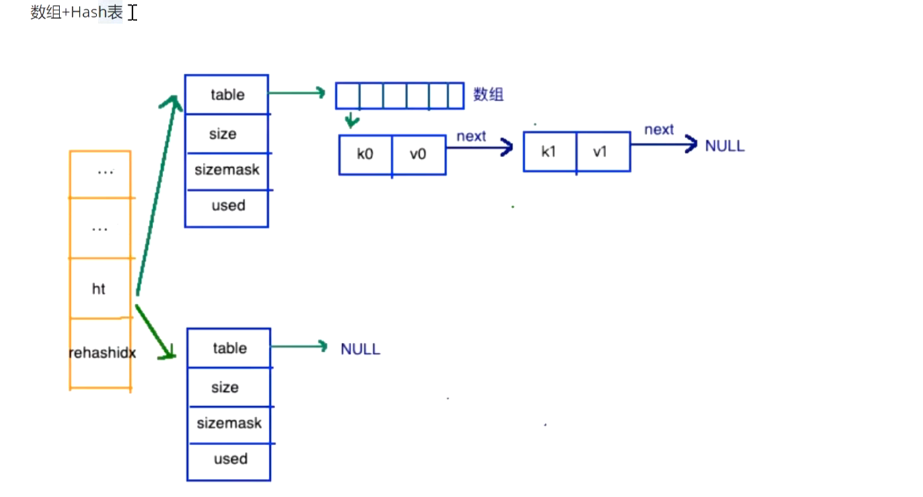
如何吧数据存入hash?看上图:HashSet(key,value) key被管理 值存到数组
4.第一个是 数组的key 第二个是 数组的索引key 第三个是值 完全基于内存操作 缺陷是内存不足;
5.如果要保证 销量表中的 销量 和总量的值 +1 -1 则需要使用事务 保证数据一致性

6.如果一次性存储多个商品数据以hashset存储 使用CreateBatch()
对Redis set进行排序存储 需要在存对象时使用 sortsetAdd()
总结:
场景1:单个商品的存储
场景2:多个商品的存储
场景3:商品字段的更新
场景4:商品多个字段添加一致性
场景5:多个商品数据批量添加
场景7:商品数据如何排序
场景8:商品数据如何分页
入坑:redis分布式锁:锁住一个进程
1: 什么是锁:锁就是为了保证数据安全的一种机制;
在我们的系统中常常有线程锁:在一个进程中有多个线程,当一个共享资源同时只允许一个线程访问时就产生了线程锁;
重点来了:什么又是进程锁?不言而喻 当然是锁住一个进程了
以上两个进程同时访问:加上线程锁发现了超卖现象;以为线程锁跨进程 ;如何解决?问题原因是两个线程同时访问了数据库 那我们只需要让一个进程的一 个线程访问; --------------------分布式锁就能实现这样的需求;
总结一下:分布式锁的使用场景 主要是在分布式的集群环境中,主要使用再对数据库的update操作;select insert delete不涉及相关问题;
2:如何封装分布式锁
入坑:redis哨兵集群:使用Redis主要是在集群系统中使用,除了对业务的分析,我们还要保证redis再系统中的高可用;
1:保证redis的高可用是业务实现的基础;
Redis的集群演变:
1.1redis集群第一代演变:主从集群:数据写入master master分发到slaver
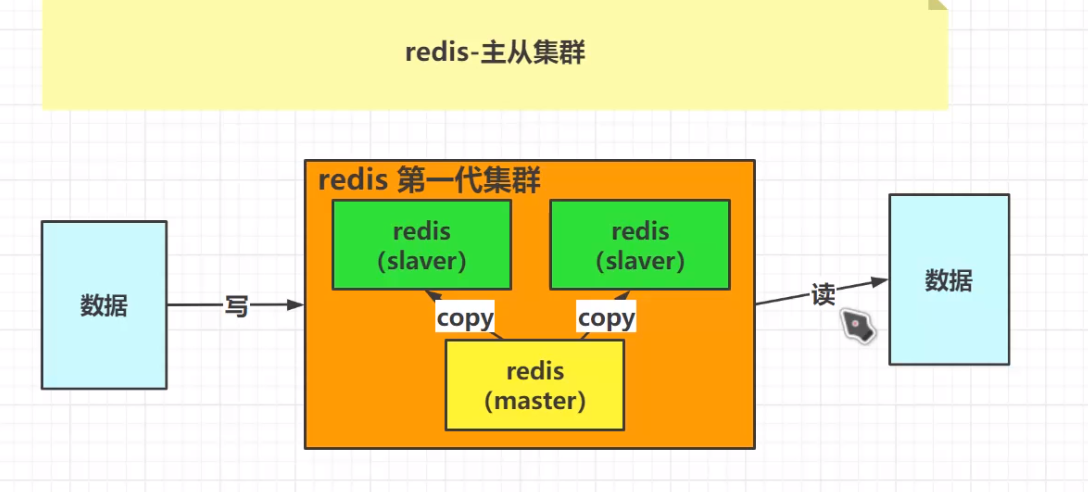
主从集群的缺陷:master宕机 整个集群不可用
1.2redis集群第二代演变:哨兵集群:数据写入master master分发到slaver sentine监视master 当master宕机,从多个slaver选举一个master
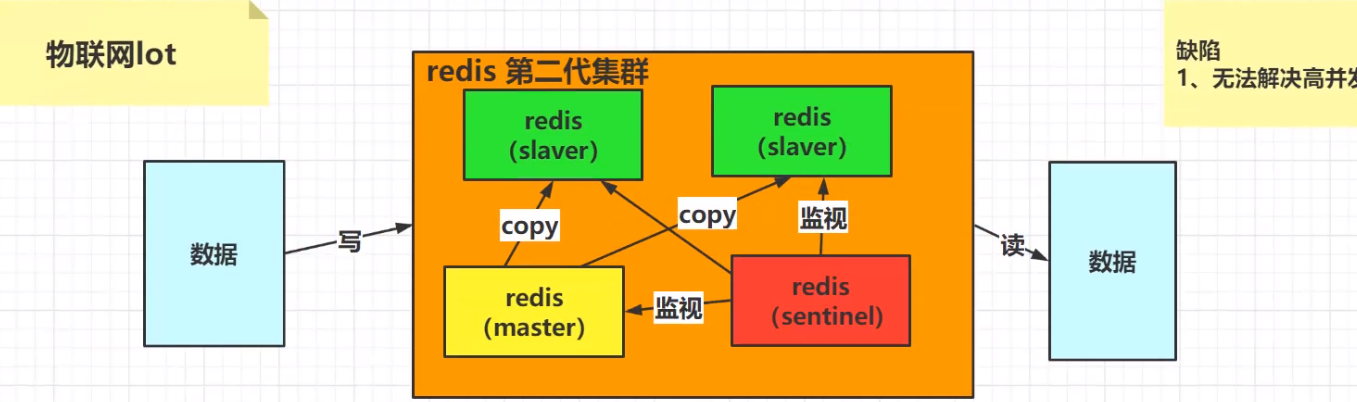
哨兵集群的缺陷:无法解决高并发写/海量数据存储的问题;每个redis实例部署的环境的数据存储磁盘都是有限的; 这就需要扩容;
高并发写:IOT项目中;场景:要统计一个城市每户用自来水的实时情况;
1.3redis集群第三代演变:多master集群模式
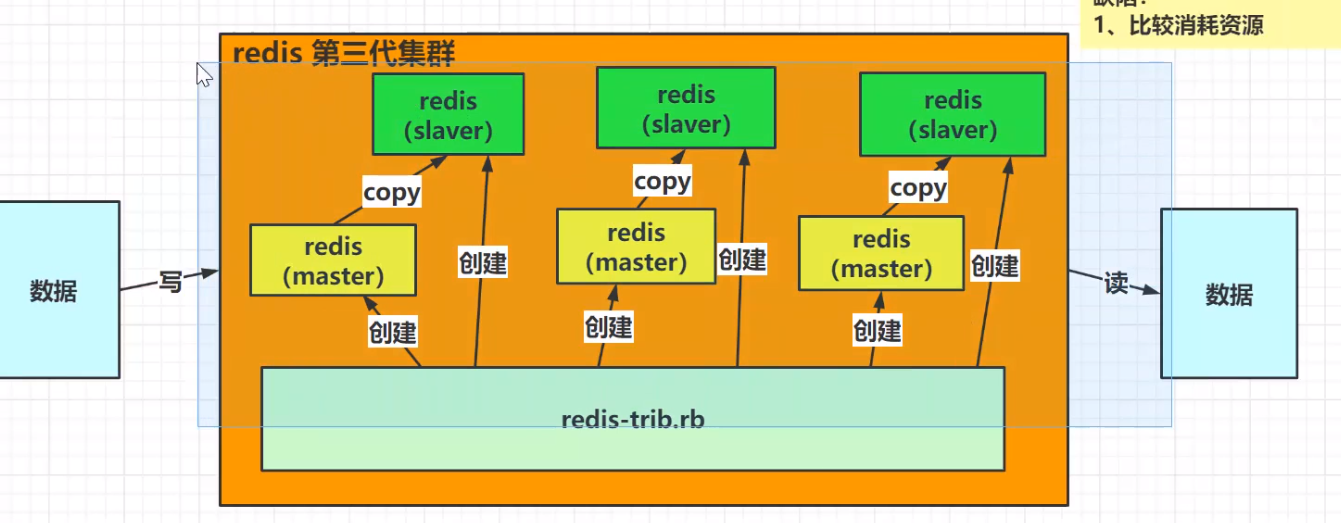
缺陷:比较消耗资源

 浙公网安备 33010602011771号
浙公网安备 33010602011771号