

08 学生课程分数的Spark SQL分析
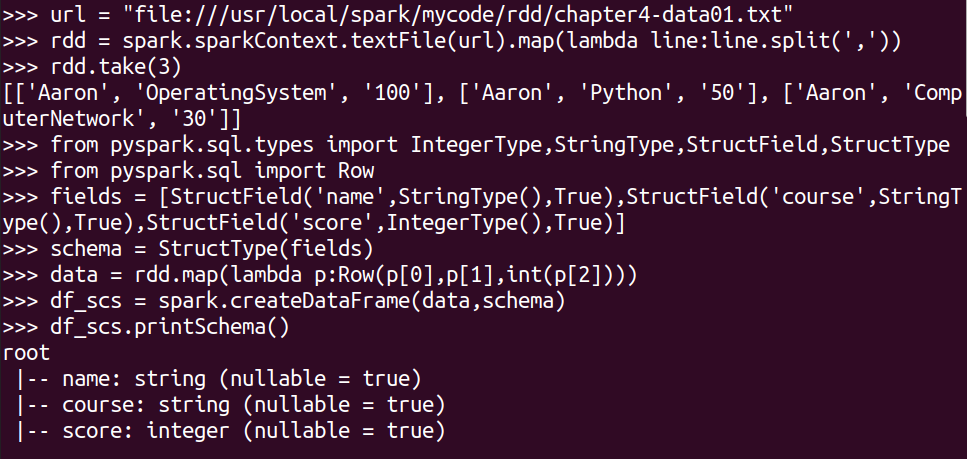
读学生课程分数文件chapter4-data01.txt,创建DataFrame。
url = "file:///usr/local/spark/mycode/rdd/chapter4-data01.txt"
rdd = spark.sparkContext.textFile(url).map(lambda line:line.split(','))
rdd.take(3)
from pyspark.sql.types import IntegerType,StringType,StructField,StructType
from pyspark.sql import Row
#生成“表头”
fields = [StructField('name',StringType(),True),StructField('course',StringType(),True),StructField('score',IntegerType(),True)]
schema = StructType(fields)
#生成“表中的记录”
data = rdd.map(lambda p:Row(p[0],p[1],int(p[2])))
#把“表头”和“表中的记录”拼接在一起
df_scs = spark.createDataFrame(data,schema)
df_scs.printSchema()
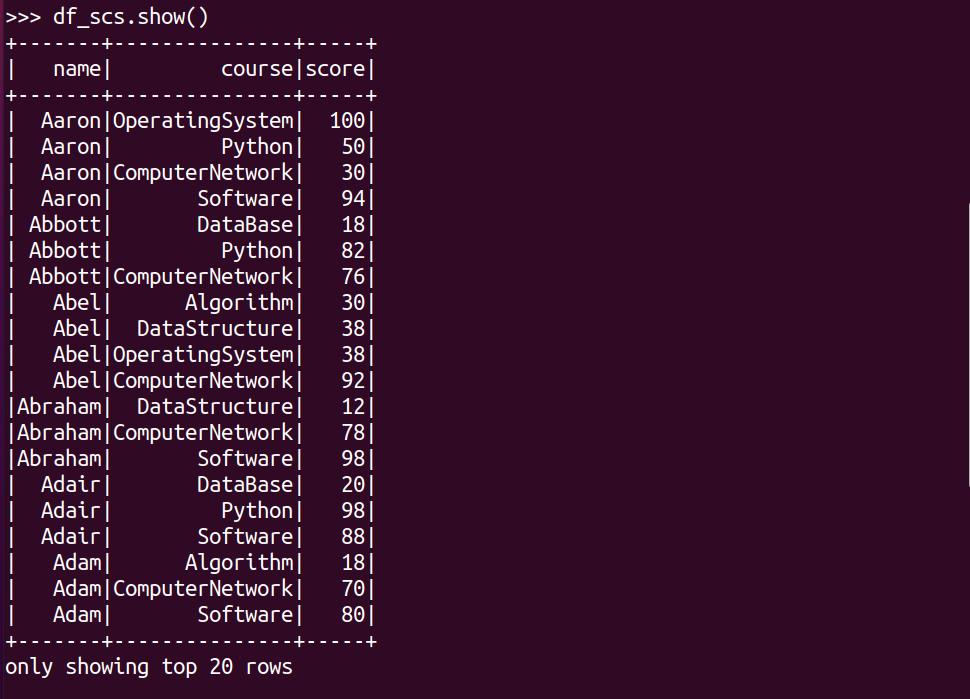
df_scs.show()
一、用DataFrame的操作或SQL语句完成以下数据分析要求,并和用RDD操作的实现进行对比:
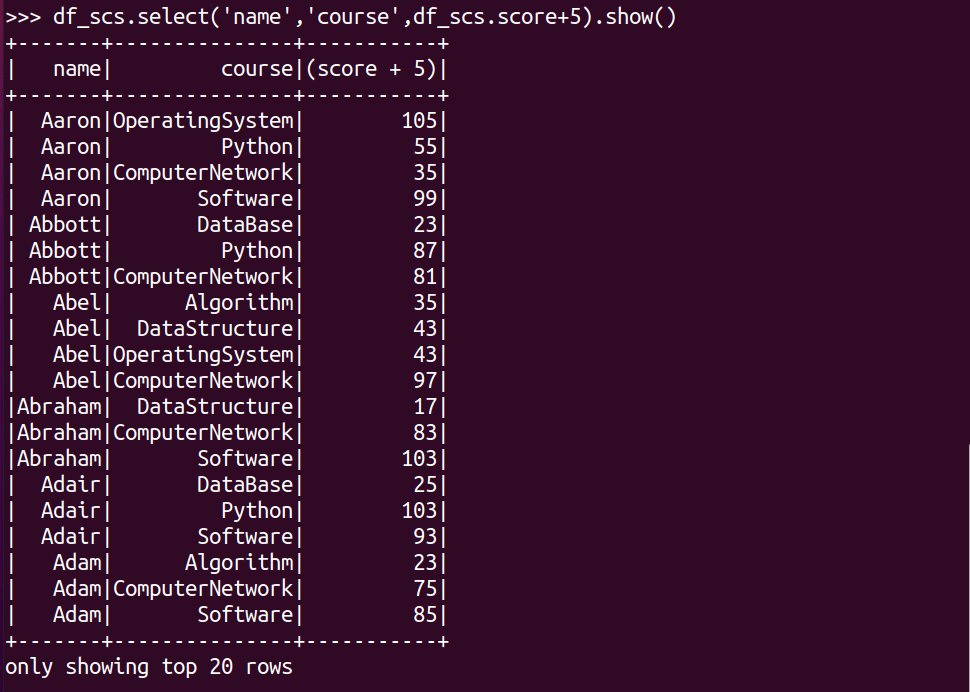
每个分数+5分。
df_scs.select('name','course',df_scs.score+5).show()
总共有多少学生?
df_scs.select('name').distinct().count()

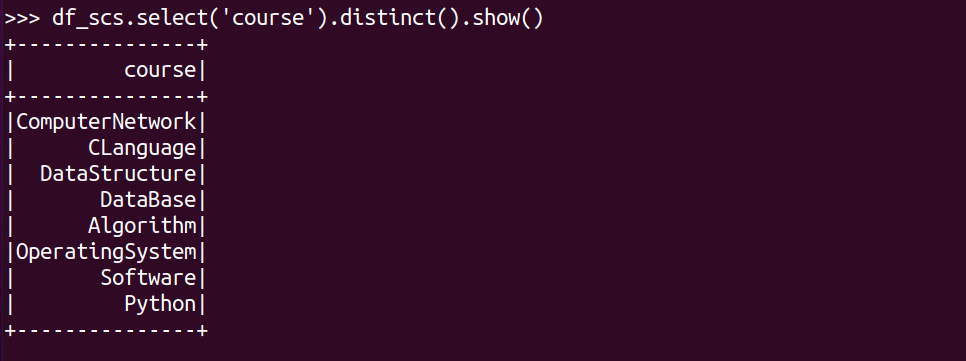
总共开设了哪些课程?
df_scs.select('course').distinct().show()
每个学生选修了多少门课?
df_scs.groupBy('name').count().show()
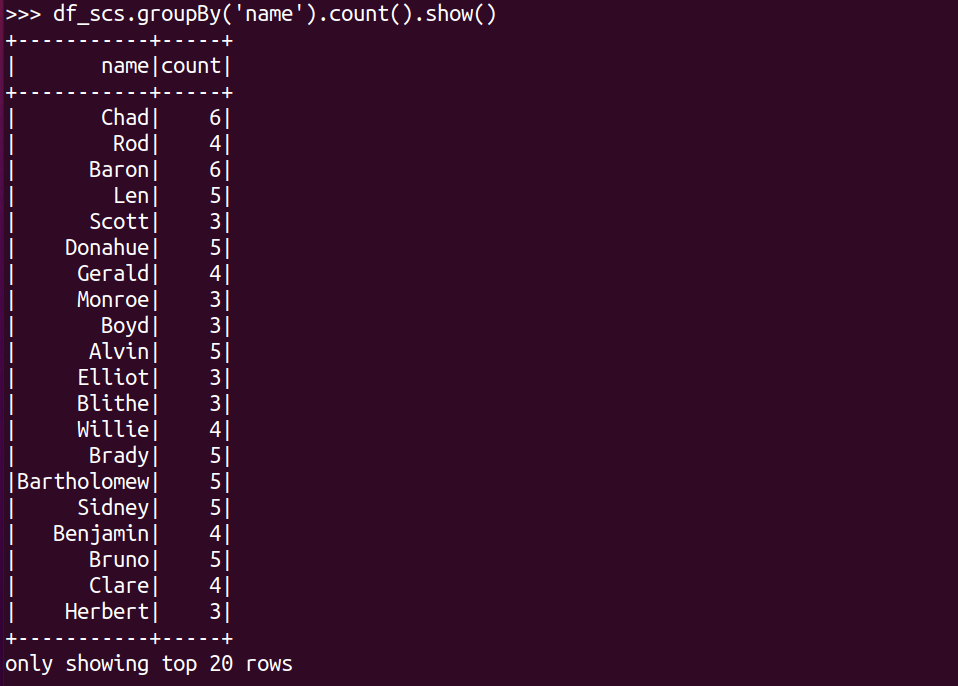
每门课程有多少个学生选?.
df_scs.groupBy('course').count().show()
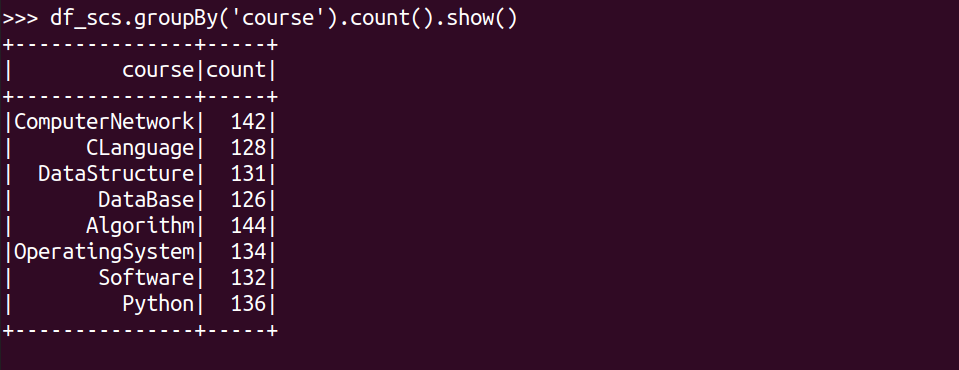
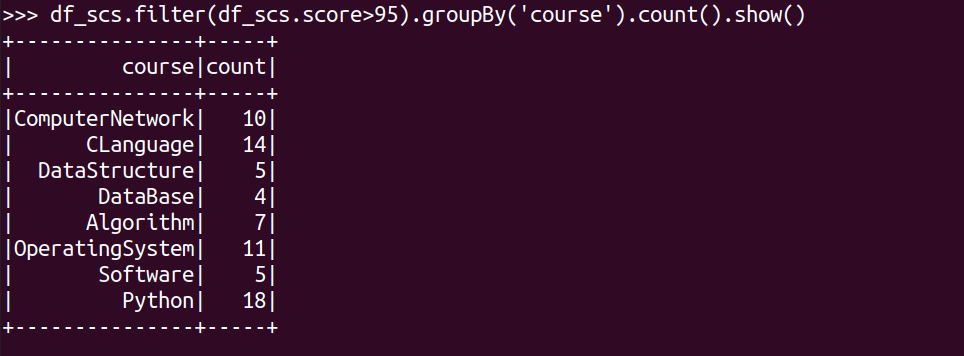
每门课程大于95分的学生人数?
df_scs.filter(df_scs.score>95).groupBy('course').count().show()
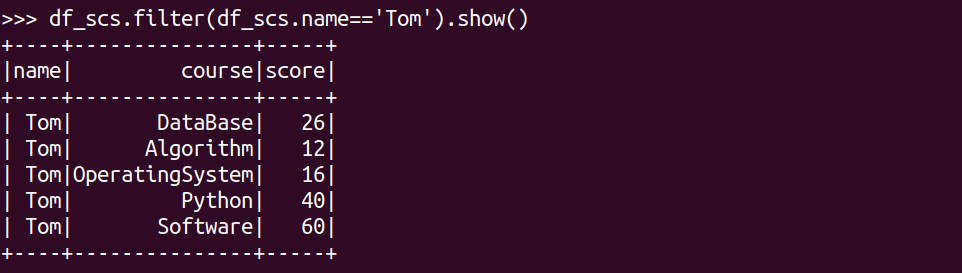
Tom选修了几门课?每门课多少分?
df_scs.filter(df_scs.name=='Tom').show()
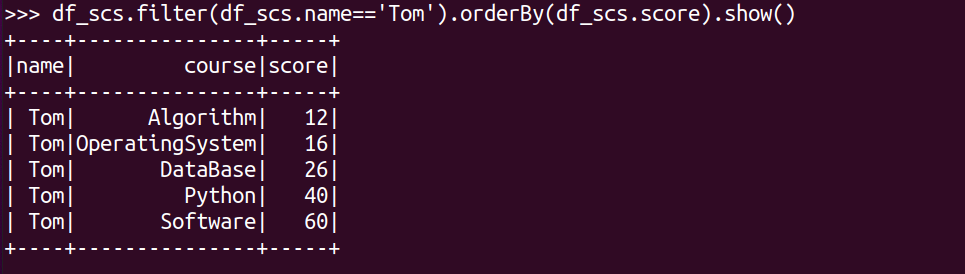
Tom的成绩按分数大小排序。
df_scs.filter(df_scs.name=='Tom').orderBy(df_scs.score).show()
Tom的平均分。
df_scs.filter(df_scs.name=='Tom').agg({"score":"mean"}).show()

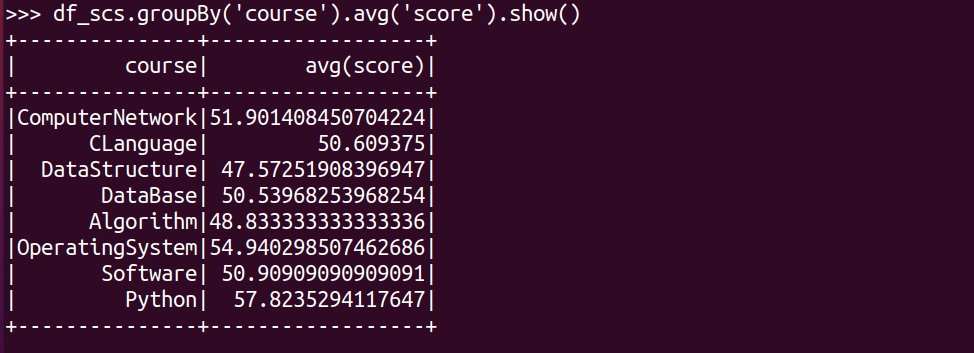
求每门课的平均分,最高分,最低分。
#求每门课的平均分
df_scs.groupBy('course').avg('score').show()
#求每门课的最高分
df_scs.groupBy('course').max('score').show()

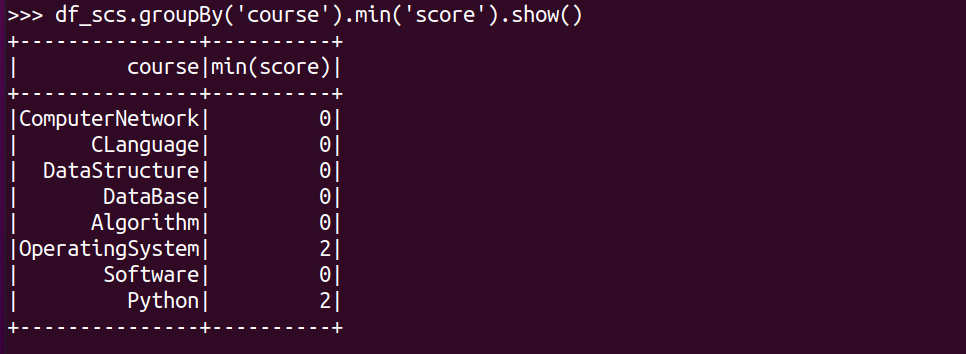
#求每门课的最低分
df_scs.groupBy('course').min('score').show()
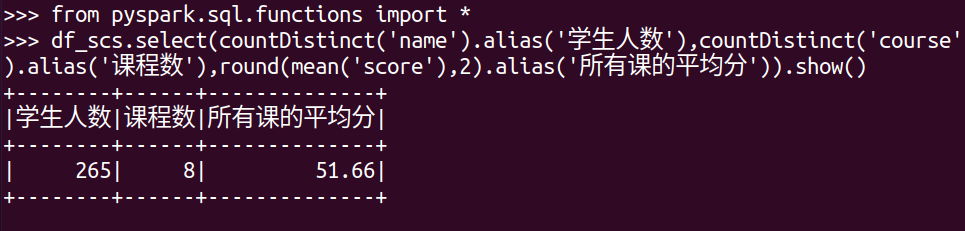
求每门课的选修人数及平均分,精确到2位小数。
from pyspark.sql.functions import *
df_scs.select(countDistinct('name').alias('学生人数'),countDistinct('course').alias('课程数'),round(mean('score'),2).alias('所有课的平均分')).show()
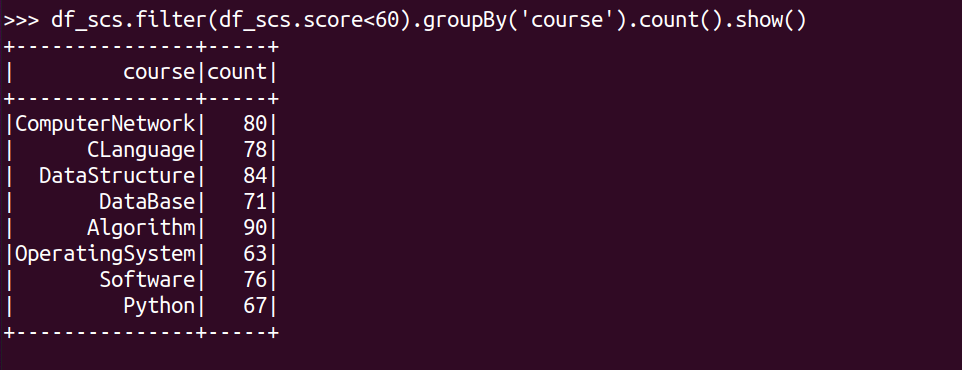
每门课的不及格人数,通过率
df_scs.filter(df_scs.score<60).groupBy('course').count().show()
二、用SQL语句完成以上数据分析要求
必须先把DataFrame注册为临时表
df_scs.createOrReplaceTempView("scs")
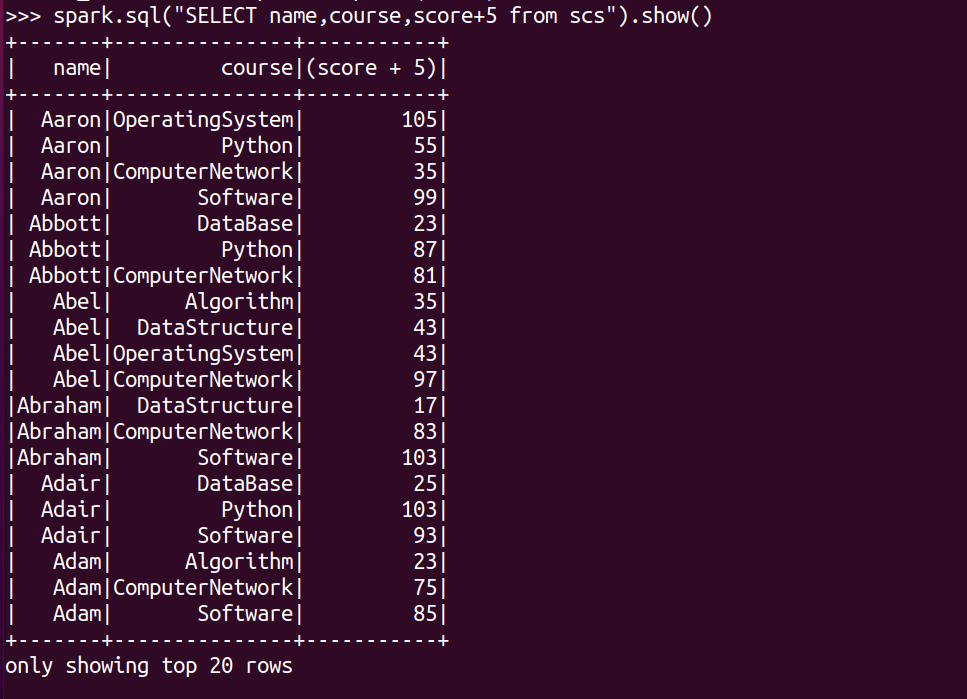
每个分数+5分。
spark.sql("SELECT name,course,score+5 from scs").show()
总共有多少学生?
spark.sql("SELECT COUNT( DISTINCT name) from scs").show()

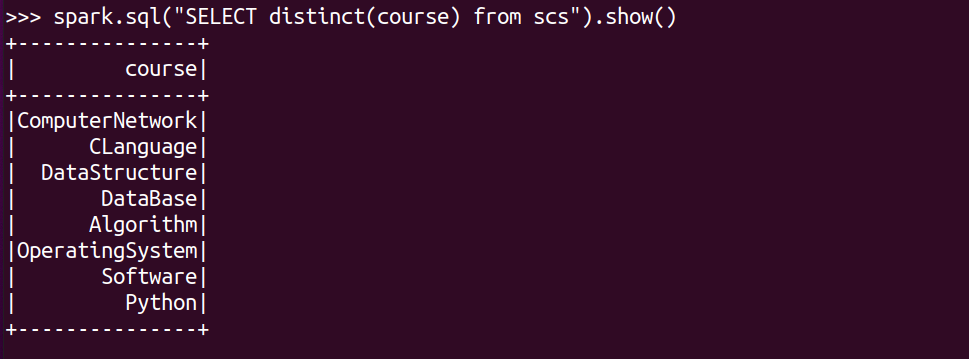
总共开设了哪些课程?
spark.sql("SELECT distinct(course) from scs").show()
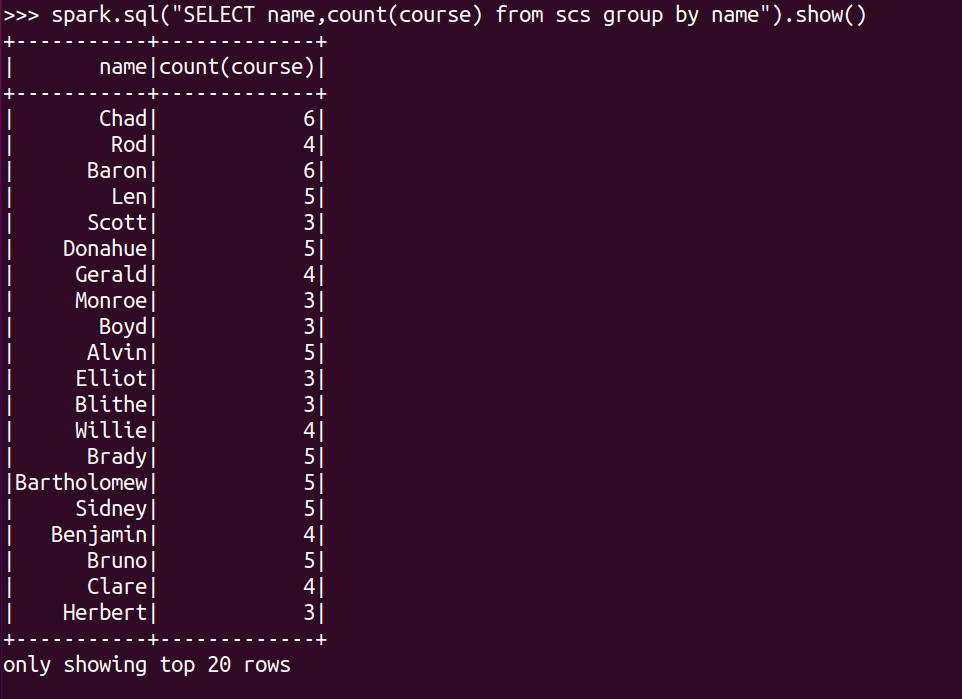
每个学生选修了多少门课?
spark.sql("SELECT name,count(course) from scs group by name").show()
每门课程有多少个学生选?
spark.sql("SELECT count(name),course from scs group by course").show()

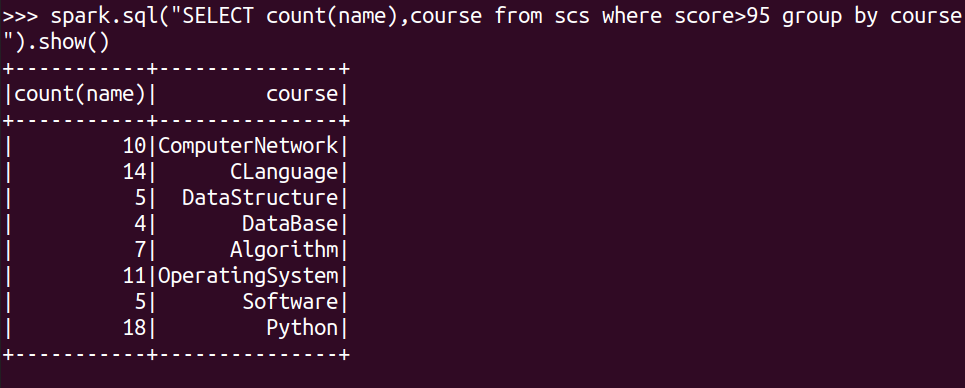
每门课程大于95分的学生人数?
spark.sql("SELECT count(name),course from scs where score>95 group by course").show()
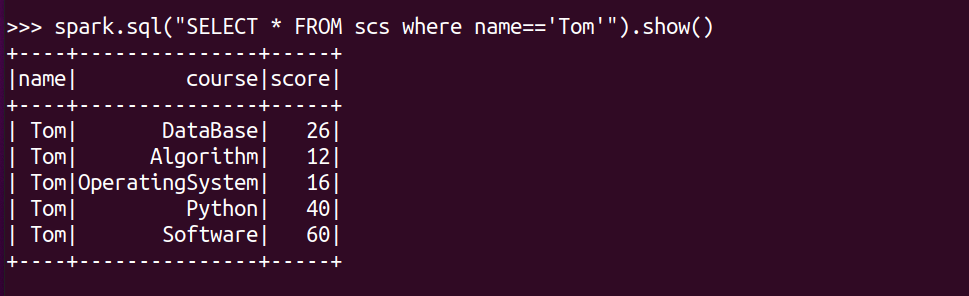
Tom选修了几门课?每门课多少分?
spark.sql("SELECT * FROM scs where name=='Tom'").show()
Tom的成绩按分数大小排序。
spark.sql("SELECT course,score from scs where name='Tom' order by score desc").show()

Tom的平均分。
spark.sql("SELECT avg(score) from scs where name='Tom'").show()

求每门课的平均分,最高分,最低分。
spark.sql("SELECT course,avg(score),max(score),min(score) from scs group by course").show()

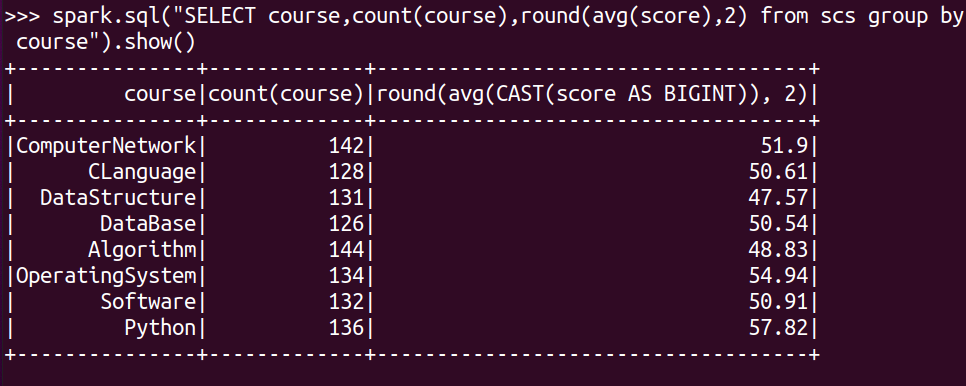
求每门课的选修人数及平均分,精确到2位小数。
spark.sql("SELECT course,count(course),round(avg(score),2) from scs group by course").show()
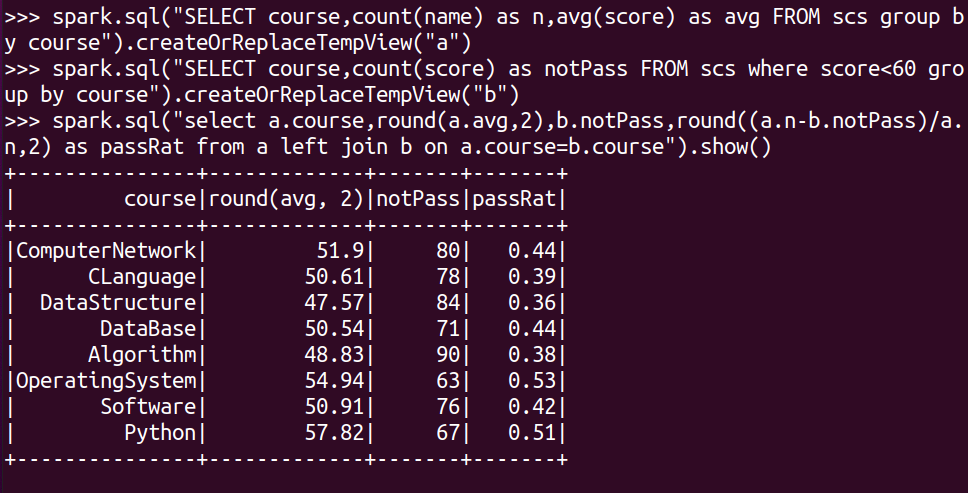
每门课的不及格人数,通过率
spark.sql("SELECT course,count(name) as n,avg(score) as avg FROM scs group by course").createOrReplaceTempView("a")
spark.sql("SELECT course,count(score) as notPass FROM scs where score<60 group by course").createOrReplaceTempView("b")
spark.sql("select a.course,round(a.avg,2),b.notPass,round((a.n-b.notPass)/a.n,2) as passRat from a left join b on a.course=b.course").show()
三、对比分别用RDD操作实现、用DataFrame操作实现和用SQL语句实现的异同。(比较两个以上问题)
总共有多少学生?
RDD操作实现:
lines=sc.textFile("file:///usr/local/spark/mycode/rdd/chapter4-data01.txt")
lines.map(lambda line:line.split(',')[0]).distinct().count()

DataFrame操作实现:
df_scs.select('name').distinct().count()

SQL语句实现:
spark.sql("SELECT COUNT( DISTINCT name) from scs").show()
Tom的平均分?
RDD操作实现:
from numpy import mean
tomList=lines.map(lambda line:line.split(',')).map(lambda line:(line[0],line[2])).lookup('Tom')
mean([int(x) for x in tomList])

DataFrame操作实现:
df_scs.filter(df_scs.name=='Tom').agg({"score":"mean"}).show()

SQL语句实现:
spark.sql("SELECT avg(score) from scs where name='Tom'").show()
Tom选修了几门课?每门课多少分?
RDD操作实现:
Tom=lines.filter(lambda line:'Tom' in line).map(lambda line:line.split(','))
Tom.collect()

DataFrame操作实现:
df_scs.filter(df_scs.name=='Tom').show()
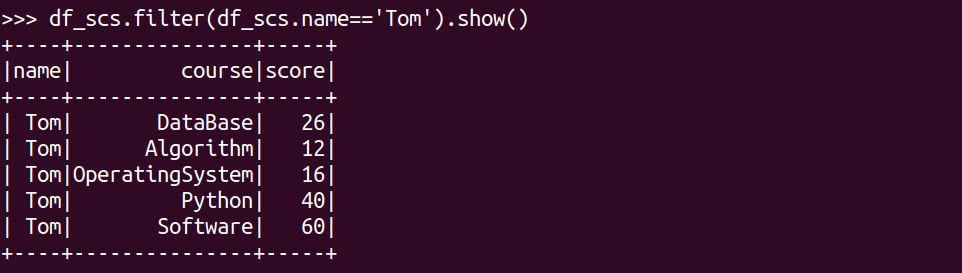
SQL语句实现:
spark.sql("SELECT * FROM scs where name=='Tom'").show()
四、结果可视化。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号