Spark源码 RDD部分
Spark源码 RDD部分各类算子以及接口
- Spark源码 RDD部分各类算子以及接口
- Spark-RDD
- BaseRDD
- persist与cache
- checkpoint
- localCheckpoint
- setCheckpointDir || getCheckpointFile || isCheckpointed || doCheckpoint || markCheckpoint
- 持久化和Checkpoint的区别
- preferredLocations
- iterator
- getnarrowAncestors
- computeOrReadCheckpoint || getOrCompute
- withScope
- repartition || coalesce
- sample || takeSample
- sortBy || intersection || subtract
- glom
- cartesian
- groupBy
- pipe
- map || mapPartitions || mapPartitionsWithIndexInternal || mapPartitionsInternal || mapPartitionsWithIndex
- zip || zipPartitions || zipWithIndex || zipWithUniqueId
- foreach
- collect
- toLocalIterator
- reduce || reduceByKey || treeReduce
- fold || aggregate || treeAggregate
- count || countApprox || countByKey || countByValue || countByValueApprox || countApproxDistinct || countApproxDistinctByKey
- take || top || takeOrdered || first
- saveAsTextFile || saveAsObjectFile || saveAsSequenceFile
- keyBy
- lookup
- collect || collectPartitions
- cleanShuffleDependencies
- barrier
- withResources || getResourceProfile
- toDebugString || debugString || firstDebugString || shuffleDebugString
- debugChildren
- outputDeterministicLevel || getOutputDeterministicLevel
- BaseRDD
- Spark-RDD
Spark Version:3.1.1
需要事先说明的是,本文仅为个人阅读源码过程中的积累,其中案例有的来自官方有的来自网络,并非全部由我自己编写,这篇博客也主要用于自己翻阅为主
Spark-RDD
filepath:spark-3.1.1\core\src\main\scala\org\apache\spark\rdd
filelists:
AsyncRDDActions.scala
BinaryFileRDD.scala
BlockRDD.scala
CartesianRDD.scala
CheckpointRDD.scala
coalesce-public.scala
CoalescedRDD.scala
CoGroupedRDD.scala
DoubleRDDFunctions.scala
EmptyRDD.scala
HadoopRDD.scala
InputFileBlockHolder.scala
JdbcRDD.scala
LocalCheckpointRDD.scala
LocalRDDCheckpointData.scala
MapPartitionsRDD.scala
NewHadoopRDD.scala
OrderedRDDFunctions.scala
package-info.java
package.scala
PairRDDFunctions.scala
ParallelCollectionRDD.scala
PartitionerAwareUnionRDD.scala
PartitionPruningRDD.scala
PartitionwiseSampledRDD.scala
PipedRDD.scala
RDD.scala
RDDBarrier.scala
RDDCheckpointData.scala
RDDOperationScope.scala
ReliableCheckpointRDD.scala
ReliableRDDCheckpointData.scala
SequenceFileRDDFunctions.scala
ShuffledRDD.scala
SubtractedRDD.scala
UnionRDD.scala
util(dir)
WholeTextFileRDD.scala
ZippedPartitionsRDD.scala
ZippedWithIndexRDD.scala
由RDD.scala实现RDD基类,其他类型的RDD大多由这个文件extend而来
BaseRDD
A Resilient Distributed Dataset (RDD), the basic abstraction in Spark. Represents an immutable,partitioned collection of elements that can be operated on in parallel. This class contains the basic operations available on all RDDs, such as map, filter, and persist. In addition,[[org.apache.spark.rdd.PairRDDFunctions]] contains operations available only on RDDs of key-value pairs, such as groupByKey and join;
[[org.apache.spark.rdd.DoubleRDDFunctions]] contains operations available only on RDDs of Doubles; and [[org.apache.spark.rdd.SequenceFileRDDFunctions]] contains operations available on RDDs that can be saved as SequenceFiles. All operations are automatically available on any RDD of the right type (e.g. RDD[(Int, Int)]) through implicit.
Internally, each RDD is characterized by five main properties:
- A list of partitions
- A function for computing each split
- A list of dependencies on other RDDs
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for
an HDFS file)
All of the scheduling and execution in Spark is done based on these methods, allowing each RDD to implement its own way of computing itself. Indeed, users can implement custom RDDs (e.g. for reading data from a new storage system) by overriding these functions.
Rdd是Spark中的基本抽象,代表了一个不可变的、可并行操作的元素的分区集合。RDD类包含了所有Rdd上可用的基本操作比如map\filter\persist。
Rdd内部主要有五个属性:分区列表、对每个split的计算功能、对于其他Rdd的依赖列表以及k-v Rdd的partitioner(比如用来表示Rdd是hash分区的)、计算每个split的首选位置的列表(比如HDFSfile的block块)
spark中所有的调度和执行都是基于Rdd的这些方法完成的,并且允许其他类型的Rdd在拓展的基础实现自己的计算方式。
总的来说除了实现RDD本身的计算功能外,Spark还提供了一系列针对分区的计算操作以补充分布式抽象数据集的分区操作功能
persist与cache
/**
* Mark this RDD for persisting using the specified level.
*
* @param newLevel the target storage level
* @param allowOverride whether to override any existing level with the new one
*/
private def persist(newLevel: StorageLevel, allowOverride: Boolean): this.type = {
// TODO: Handle changes of StorageLevel
if (storageLevel != StorageLevel.NONE && newLevel != storageLevel && !allowOverride) {
throw new UnsupportedOperationException(
"Cannot change storage level of an RDD after it was already assigned a level")
}
// If this is the first time this RDD is marked for persisting, register it
// with the SparkContext for cleanups and accounting. Do this only once.
if (storageLevel == StorageLevel.NONE) {
sc.cleaner.foreach(_.registerRDDForCleanup(this))
sc.persistRDD(this)
}
storageLevel = newLevel
this
}
/**
* Set this RDD's storage level to persist its values across operations after the first time
* it is computed. This can only be used to assign a new storage level if the RDD does not
* have a storage level set yet. Local checkpointing is an exception.
*/
def persist(newLevel: StorageLevel): this.type = {
if (isLocallyCheckpointed) {
// This means the user previously called localCheckpoint(), which should have already
// marked this RDD for persisting. Here we should override the old storage level with
// one that is explicitly requested by the user (after adapting it to use disk).
persist(LocalRDDCheckpointData.transformStorageLevel(newLevel), allowOverride = true)
} else {
persist(newLevel, allowOverride = false)
}
}
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
/**
* Persist this RDD with the default storage level (`MEMORY_ONLY`).
*/
def cache(): this.type = persist()
cache()方法内层其实就调用了persist(),他是persist方法无参情况下的实现,因此相当于调用了persist(StorageLevel.MEMORY_ONLY)
checkpoint
rdd的checkpoint机制(检查点,相当于快照),可以将你认为很重要的rdd存放到一个公共的高可用的存储系统中去,如hdfs,下次数据丢失时,就可以从前面ck的rdd直接进行数据恢复,而不需要根据lineage去从头一个一个的去恢复,这样极大地提高了效率。
checkpoint方法不能使用本地路径,因为分区机制,只有部分数据会上传到本地磁盘
用法:
sc.setCheckpointDir("hdfs://master:9000/rdd-checkpoint")
#设置存放路径
rdd.checkpoint()
rdd.collect()
localCheckpoint
localCheckpoint的作用是标记此RDD使用Spark现有的缓存层进行本地化的checkpointing操作,这对于那些单纯的想要切断RDD的长lineage,又不想使用普通checkpoint将数据保存到高可靠文件系统的开销的场景,尤其是那些需要周期性的truncate长lineage的情形, 譬如迭代计算,譬如处理增量RDD(不停地union新数据)。
localCheckpoint将数据写入executor的本地存储中去,考虑到其没有将数据写入可靠存储,其性能是有所提升的,但损失了容错性。一旦executor执行失败,已被checkpoint过的数据便无法访问,会引发异常。
对于启用资源动态分配的情况下,executor是会随着任务进行动态分配与释放的,这便有对应的active状态与dead状态,对于dead之后executor的存储是无法访问了的,又重新分配的executor计算资源时也不一定能读到了,除非设置spark.dynamicAllocation.cachedExecutorIdleTimeout为一个较高的值,至少保证能缓存到下一次访问
若在调用localCheckpoint之前已经checkpoint()且已有action触发过doCheckpoint,即已经写入可靠存储且斩断依赖了,则日志提示警告什么也不做
若仅进行过checkpoint调用,但尚未有action被触发过,则以此为准重新生成localRDDCheckpointData,忽略之前的ReliableRDDCheckpointData
localCheckpoint是设计出来斩断lineage的,而checkpoint是用来提供容错的。调用r.localCheckpoint()时,除了进行checkpoint操作,r之前的lineage会被斩断,仿佛它是新load出来的数据一样
setCheckpointDir || getCheckpointFile || isCheckpointed || doCheckpoint || markCheckpoint
setCheckpointDir:用于设置checkpoint文件的路径。
getCheckpointFile:获取checkpoint文件的路径。如果没有做过checkpoint,则为空。
isCheckpointed:判断是否做过checkpoint。
doCheckpoint:通过保存这个RDD来执行checkpoint。它在使用这个RDD的作业完成后被调用(因此RDD已经被物化并可能存储在内存中)。在父rdd上递归调用doCheckpoint()。
markCheckpoint:将这个RDD的依赖关系从原来的父RDD更改为一个新的RDD 从checkpoint文件创建,忘记它原来的依赖项和分区。
持久化和Checkpoint的区别
1.位置
Persist 和 Cache 只能保存在本地的磁盘和内存中(或者堆外内存--实验中)
Checkpoint 可以保存数据到 HDFS 这类可靠的存储上
2.生命周期
Cache和Persist的RDD会在程序结束后会被清除或者手动调用unpersist方法
Checkpoint的RDD在程序结束后依然存在,不会被删除
3.Lineage(血统、依赖链)
Persist和Cache,不会丢掉RDD间的依赖链/依赖关系,因为这种缓存是不可靠的,如果出现了一些错误(例如 Executor 宕机),需要通过回溯依赖链重新计算出来
Checkpoint会斩断依赖链,因为Checkpoint会把结果保存在HDFS这类存储中,更加的安全可靠,一般不需要回溯依赖链
preferredLocations
final def preferredLocations(split: Partition): Seq[String] = {
checkpointRDD.map(_.getPreferredLocations(split)).getOrElse {
getPreferredLocations(split)
}
}
用于获取rdd分区数据的最优位置
iterator
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
getOrCompute(split, context)
} else {
computeOrReadCheckpoint(split, context)
}
}
从缓存中读取可适用的rdd数据或者计算它
getnarrowAncestors
private[spark] def getNarrowAncestors: Seq[RDD[_]] = {
val ancestors = new mutable.HashSet[RDD[_]]
def visit(rdd: RDD[_]): Unit = {
val narrowDependencies = rdd.dependencies.filter(_.isInstanceOf[NarrowDependency[_]])
val narrowParents = narrowDependencies.map(_.rdd)
val narrowParentsNotVisited = narrowParents.filterNot(ancestors.contains)
narrowParentsNotVisited.foreach { parent =>
ancestors.add(parent)
visit(parent)
}
}
visit(this)
// In case there is a cycle, do not include the root itself
ancestors.filterNot(_ == this).toSeq
}
用于获取给定rdd的先祖,仅能通过窄依赖来进行遍历,使用DFS计算,需要防止rdd circle以免死循环
computeOrReadCheckpoint || getOrCompute
前者从CheckPoint中读取rdd,后者在iterator中用于查询cached rdd
withScope
用于将一个代码块中产生的所有rdd归于一个范围(也就是总和成一个rdd)
repartition || coalesce
返回一个具有制定分区个数的新Rdd,可以用于增加或者减少RDD中的并行级别。内部调用了coalesce方法。
coalesce方法返回一个被缩减为' numPartitions '分区的新RDD。这导致了一个狭窄的依赖关系,例如,如果从1000个分区到100个分区,将不会出现shuffle,而是100个新分区中的每个分区将占用当前分区的10个。如果请求的分区数量更大,则将保持当前的分区数量不变。然而,如果您正在进行剧烈的合并,例如numPartitions = 1,这可能会导致计算发生在比您希望的更少的节点上(例,numPartitions = 1的情况下是一个节点)。为了避免这种情况,您可以传递shuffle = true。这将增加一个shuffile步骤,但意味着当前的上游分区将并行执行(无论当前分区是什么)。@note使用shuffle = true,你可以合并到更大数量的分区。如果您有少量分区(比如100个),并且可能有一些分区异常大,那么这很有用。调用coalesce(1000, shuffile = true)将产生1000个分区,使用散列分区器分发数据。传入的可选分区合并器必须是可序列化的。
sample || takeSample
返回一个RDD的抽样子集,参数如下
withReplacement: Boolean, //元素可以多次抽样(在抽样时替换)
fraction: Double, //期望样本的大小作为RDD大小的一部分,当withReplacement=false时:选择每个元素的概率;分数一定是[0,1] ;当withReplacement=true时:选择每个元素的期望次数; 分数必须大于等于0。
seed: Long = Utils.random.nextLong//随机数生成器的种子
sampleByKey,只有pairRDD能调用
takeSample返回一个Array[T],且该方法只能在预期结果数组很小的情况下使用,因为所有数据会被加载入driver内存中,设计目的可能是为了在driver端的控制台打印rdd的数据,所以参数1直接指定数目而不是指定获取样本的方式
sortBy || intersection || subtract
sortBy根据给定函数排序RDD
intersection返回两个RDD的交集并且去重,还可以指定返回RDD的分区数
subtract类似于intersection,但返回在RDD中出现,并且不在otherRDD中出现的元素,不去重。参数含义同intersection
glom
glom的作用是将同一个分区里的元素合并到一个array里
glom属于Transformation算子:这种变换并不触发提交作业,完成作业中间过程处理。
cartesian
返回两个RDD的笛卡儿积
groupBy
有三种实现,第一种只传入函数,第二种传入函数以及分区数,第三种传入函数以及Partitioner
该操作的代价可能很大,因为涉及到宽依赖
pipe
对于每个分区,都执行一个perl或者shell脚本,返回输出的RDD
Spark有一个pipe的编程接口,用的是Unix的标准输入和输出,类似于 Unix的 | 管道,例如: ls | grep ^d
案例需求如下:
- 2万个文件,每个10G,放在HDFS上了,总量200TB的数据需要分析。
- 分析程序本身已经写好了,程序接受一个参数:文件路径
- 如何用spark完成集群整个分析任务?
首先创建一个RDD,罗列输入的任务
// 此处文件的List可以从另一个HDFS上的文件读取过来
val data = List("hdfs://xxx/xxx/xxx/1.txt","hdfs://xxx/xxx/xxx/2.txt",...)
val dataRDD = sc.makeRDD(data) //sc 是你的 SparkContext
然后创建一个shell脚本用于启动分析任务
#!/bin/sh
echo "Running launch.sh shell script..."
while read LINE; do
echo "启动分析任务, 待分析文件路径为: ${LINE}"
bash hdfs://xxx/xxx/xx/analysis_program.sh ${LINE}
done
最后RDD对接到启动脚本
val scriptPath = "hdfs://xxx/xxx/launch.sh"
val pipeRDD = dataRDD.pipe(scriptPath)
pipeRDD.collect()
总结
dataRDD里面包含了我们要分析的文件列表,这个列表会被分发到spark集群,- 然后spark的工作节点会分别启动一个
launch.sh脚本,接受文件列表作为输入参数, - 在
launch.sh脚本的循环体用这些文件列表启动具体的分析任务
这样之后的好处是:
- 既有程序
analysis_program.sh不需要任何修改,做到了重用,这是最大的好处 - 使用集群来做分析,速度比以前更快了(线性提升)
- 提高了机器的利用率(以前可能是一台机器分析)
map || mapPartitions || mapPartitionsWithIndexInternal || mapPartitionsInternal || mapPartitionsWithIndex
map和mapPartitions两个函数最终处理得到的结果是一样的
mapPartitions比较适合需要分批处理数据的情况,比如将数据插入某个表,每批数据只需要开启一次数据库连接,大大减少了连接开支
后面几种mapPartitions都是Spark's internal mapPartitions method,为了达到特殊情况下的性能最优,通常不会使用
mapPartitionsWithIndex在mapPartitions的基础上跟踪索引原始分区
zip || zipPartitions || zipWithIndex || zipWithUniqueId
zip函数用于将两个RDD组合成Key/Value形式的RDD,这里默认两个RDD的partition数量以及元素数量都相同,否则会抛出异常
zipPartitions函数将多个RDD按照partition组合成为新的RDD,该函数需要组合的RDD具有相同的分区数,但对于每个分区内的元素数量没有要求
该函数有好几种实现,可分为三类:
1.参数是一个RDD
def zipPartitions[B, V](rdd2: RDD[B])(f: (Iterator[T], Iterator[B]) => Iterator[V])(implicit arg0: ClassTag[B], arg1: ClassTag[V]): RDD[V]
def zipPartitions[B, V](rdd2: RDD[B], preservesPartitioning: Boolean)(f: (Iterator[T], Iterator[B]) => Iterator[V])(implicit arg0: ClassTag[B], arg1: ClassTag[V]): RDD[V]
这两个区别就是参数preservesPartitioning,是否保留父RDD的partitioner分区信息
2.参数是两个RDD
def zipPartitions[B, C, V](rdd2: RDD[B], rdd3: RDD[C])(f: (Iterator[T], Iterator[B], Iterator[C]) => Iterator[V])(implicit arg0: ClassTag[B], arg1: ClassTag[C], arg2: ClassTag[V]): RDD[V]
def zipPartitions[B, C, V](rdd2: RDD[B], rdd3: RDD[C], preservesPartitioning: Boolean)(f: (Iterator[T], Iterator[B], Iterator[C]) => Iterator[V])(implicit arg0: ClassTag[B], arg1: ClassTag[C], arg2: ClassTag[V]): RDD[V]
用法同上面,只不过该函数参数为两个RDD,映射方法f输入参数为两个RDD的迭代器。
3.也就是比上面有多了一个输入RDD
zipWithIndex
val z = sc.parallelize(Array("A", "B", "C", "D"))
val r = z.zipWithIndex
res110: Array[(String, Long)] = Array((A,0), (B,1), (C,2), (D,3))
zipWithUniqueId
val z = sc.parallelize(Array("A", "B", "C", "D"))
val r = z.zipWithUniqueId
r.collect
res25: Array[(String, Long)] = Array((A,0), (B,2), (C,1), (D,3))
foreach
Applies a function f to all elements of this RDD.
collect
Return an array that contains all of the elements in this RDD
也可以传入一个filter,输出符合的值
toLocalIterator
返回一个包含RDD中所有元素的迭代器。
迭代器将消耗与该RDD中最大分区相同的内存
reduce || reduceByKey || treeReduce
reduce将RDD中元素前两个传给输入函数,产生一个新的return值,新产生的return值与RDD中下一个元素(第三个元素)组成两个元素,再被传给输入函数,直到最后只有一个值为止
reduceByKey就是对元素为KV对的RDD中Key相同的元素的Value进行binary_function的reduce操作,因此,Key相同的多个元素的值被reduce为一个值,然后与原RDD中的Key组成一个新的KV对
可以实现同样功能的还有GroupByKey函数,但是,groupbykey函数并不能提前进行reduce,也就是说reduceByKey会在数据迁移也就是分区合并前预先做一次合并
reduceByKey和treeReduce之间有一个根本区别,reduceByKey它只对key-value pair RDDs可用,而treeReduce可以对任何RDD使用,相当于是reduce操作的泛化。 reduceByKey用于实现treeReduce,但它们在任何其他意义上都不相关。
reduceByKey对每个键执行reduce,结果生成RDD; 它不是"action"操作,而是返回ShuffleRDD,是"transformation"。 这等效于groupByKey后面跟着一个map,它执行key-wise reduction(为什么使用groupByKey是低效的)。
另一方面,treeAggregate是reduce函数的泛化,灵感来自AllReduce。 这在Spark中是一个"action",将结果返回到master节点。在执行本地的reduce操作之后,普通的reduce在master上执行剩余的计算,这样的计算量可能是非常繁重的(特别是在机器学习中,reduce函数结果是大的向量或矩阵时)。 相反,treeReduce使用reduceByKey并行的执行reduction(这是通过在运行时创建key-value pair RDD,其中键由树的深度确定)
fold || aggregate || treeAggregate
def fold(zeroValue: T)(op: (T, T) => T): T
rdd.fold(value)(func)
fold与reduce函数功能类似,区别在于fold多了一个初始值参数
因此rdd.fold(0)((x,y)=>x+y)等价于rdd.reduce((x,y)=>x+y)
而reduce和fold的共同点在于这两个函数的返回值必须和rdd数据类型相同
aggregate函数就超越了这个限制
def aggregate[U: ClassTag](zeroValue: U)(seqOp: (U, T) => U, combOp: (U, U) => U)
比如返回一个(Int,Int),这样就可以让aggregate函数同时实现rdd元素的累加和以及元素计数(x, y) => (x._1 + y, x._2 + 1),需要注意的是这段代码仅表示seqOp,seqOp方法是对单独一个分区内的数据进行累加和计数,而后面的comOp是将seqOp后的结果再进行聚合
官方实例
>>> seqOp = (lambda x, y: (x[0] + y, x[1] + 1))
>>> combOp = (lambda x, y: (x[0] + y[0], x[1] + y[1]))
>>> sc.parallelize([1, 2, 3, 4]).aggregate((0, 0), seqOp, combOp)
(10, 4)
>>> sc.parallelize([]).aggregate((0, 0), seqOp, combOp)
(0, 0)
treeAggregate:
def treeAggregate[U: ClassTag](zeroValue: U)(
seqOp: (U, T) => U,
combOp: (U, U) => U,
depth: Int = 2)
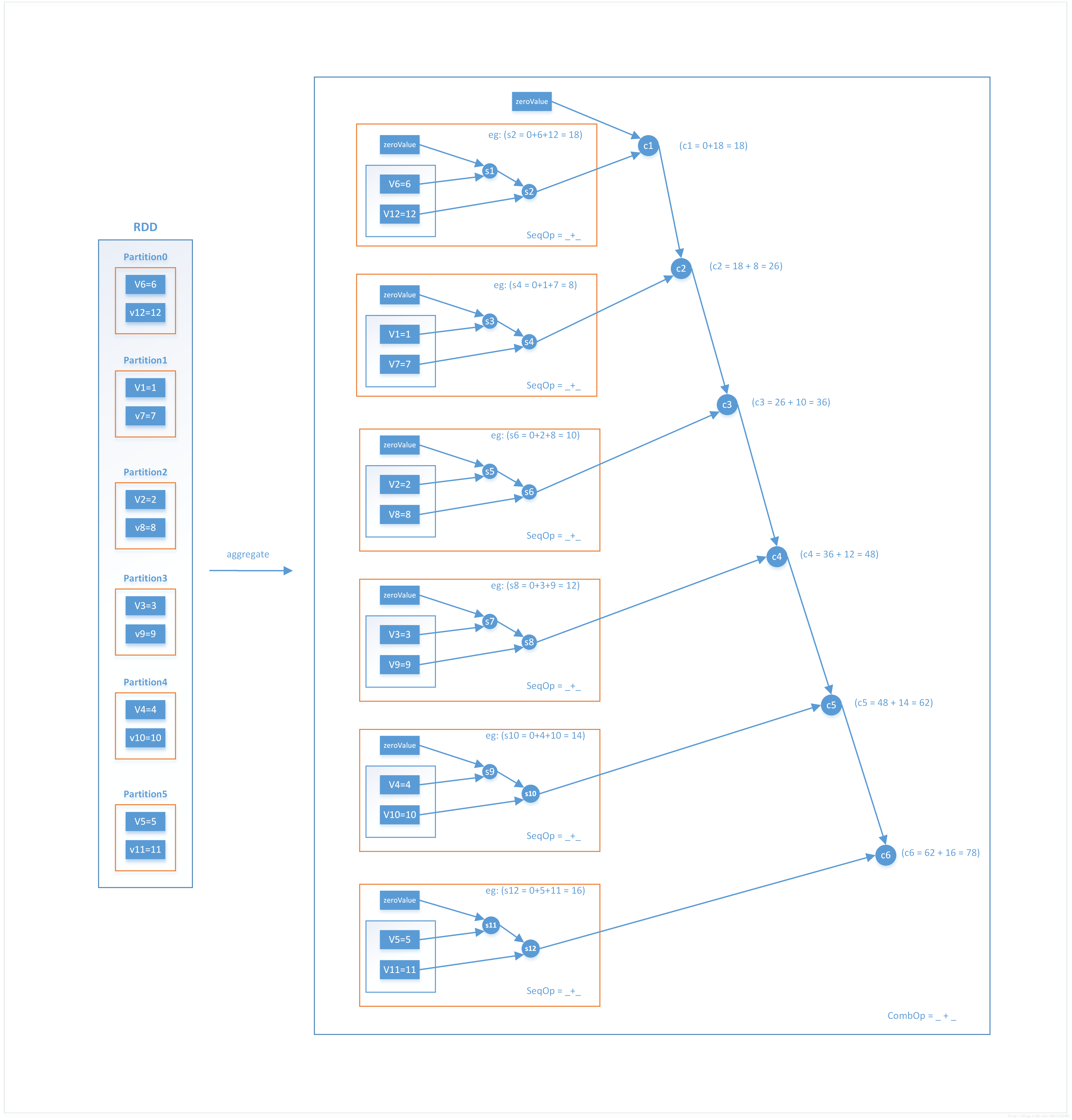
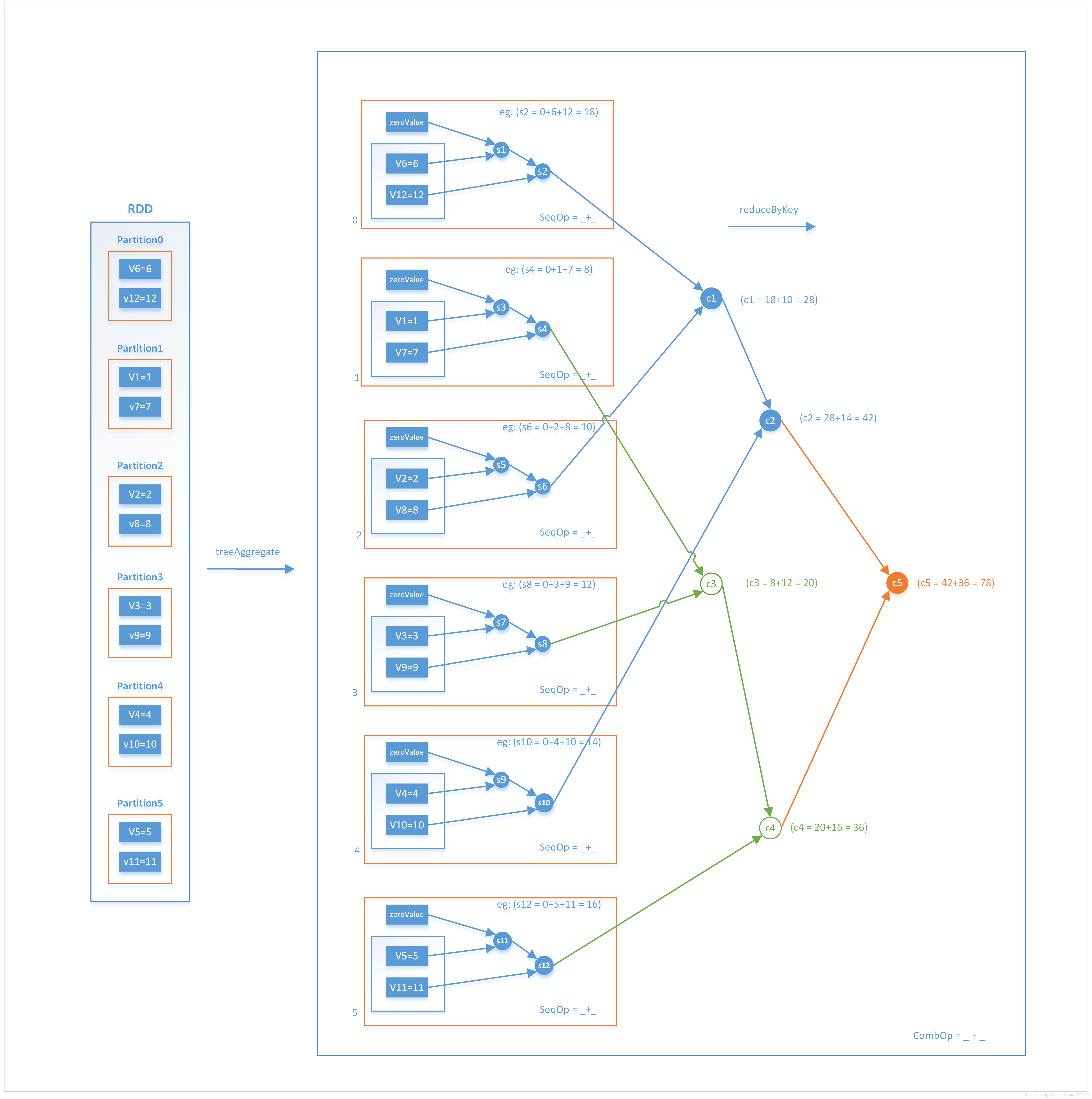
treeAggregate是aggregate的一种特殊形式,aggregate在执行完SeqOp后会将计算结果拿到driver端使用CombOp遍历一次SeqOp计算的结果,最终得到聚合结果。而treeAggregate不会一次就Comb得到最终结果,SeqOp得到的结果也许很大,直接拉到driver可能会OutOfMemory,因此它会先把分区的结果做局部聚合(reduceByKey),如果分区数过多时会做分区合并,之后再把结果拿到driver端做reduce,在每个分区内都会做两次或者多次comOp
def seqOp(s1:Int, s2:Int):Int = {
println("seq: "+s1+":"+s2)
s1 + s2
}
def combOp(c1: Int, c2: Int): Int = {
println("comb: "+c1+":"+c2)
c1 + c2
}
val rdd = sc.parallelize(1 to 12).repartition(6)
val res1 = rdd.aggregate(0)(seqOp, combOp)
val res2 = rdd.treeAggregate(0)(seqOp, combOp)
count || countApprox || countByKey || countByValue || countByValueApprox || countApproxDistinct || countApproxDistinctByKey
count返回一个RDD内存储的元素的个数
countApprox(
timeout: Long,
confidence: Double = 0.95)
countApprox是count的近似版本,在给定的时间限制范围内返回一个可能不完整的结果,也就是说超时的情况下不是所有的count任务都会完成,还会输入一个置信度作为参数,如果countApprox被以0.9的置信度多次调用,就会期望90%的结果包含真实的计数
countByKey作用于键值对类型的元素,计算的是每个键对应出现的value的次数
countByValue统计一个RDD中每一个元素出现的次数,返回一个MAP
countApproxDistinct计算单一值大概的出现的次数,注意是大概的,并且可以用参数p,sp控制对正常集或者稀疏集统计的精度,或者用参数relativeSD控制计算的精度
val a = sc.parallelize(1 to 10000, 20)
val b = a++a++a++a++a
b.countApproxDistinct(0.1)
res14: Long = 8224
b.countApproxDistinct(0.05)
res15: Long = 9750
b.countApproxDistinct(0.01)
res16: Long = 9947
b.countApproxDistinct(0.001)
res0: Long = 10000
其余两个API大致可以从上面几个推断出用法
take || top || takeOrdered || first
take函数用于获取RDD中从0到num-1下标的元素(不排序)
scala> var rdd1 = sc.makeRDD(Seq(10, 4, 2, 12, 3))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[40] at makeRDD at :21
scala> rdd1.take(1)
res0: Array[Int] = Array(10)
scala> rdd1.take(2)
res1: Array[Int] = Array(10, 4)
top函数中用户从RDD中按照默认降序或者指定的排序规则返回前N个元素。该函数带隐式函数Ordering[T],既可以指定排序规则
scala> var rdd1 = sc.makeRDD(Seq(10, 4, 2, 12, 3))
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[40] at makeRDD at :21
scala> rdd1.top(1)
res2: Array[Int] = Array(12)
scala> rdd1.top(2)
res3: Array[Int] = Array(12, 10)
//指定排序规则
scala> implicit val myOrd = implicitly[Ordering[Int]].reverse
myOrd: scala.math.Ordering[Int] = scala.math.Ordering$$anon$4@767499ef
scala> rdd1.top(1)
res4: Array[Int] = Array(2)
scala> rdd1.top(2)
res5: Array[Int] = Array(2, 3)
top与takeOrdered返回顺序相反,takeOrderd也可以指定排序规则
def top(num: Int)(implicit ord: Ordering[T]): Array[T] = withScope {
takeOrdered(num)(ord.reverse)
}
saveAsTextFile || saveAsObjectFile || saveAsSequenceFile
saveAsTextFile(
rdd1.saveAsTextFile("hdfs://cdh5/tmp/1234/",classOf[com.hadoop.compression.lzo.LzopCodec])
hadoop fs -ls /tmp/1234
-rw-r--r-- 2 hadoop supergroup 0 2015-07-10 09:20 /tmp/1234/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 71 2015-07-10 09:20 /tmp/1234/part-00000.lzo
saveAsSequenceFile方法用于将RDD中的元素序列化成对象,存储到文件中
saveAsObjectFile用于将RDD中的元素序列化成对象,存储到文件中
HDFS默认采用SequenceFile格式存储
keyBy
keyBy用于为RDD中各个元素按指定的函数生成key,返回k-v形式的RDD
scala> val a = sc.parallelize(List("dog", "salmon", "salmon", "rat", "elephant"), 3)
a: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[123] at parallelize at <console>:21
scala> val b = a.keyBy(_.length)
b: org.apache.spark.rdd.RDD[(Int, String)] = MapPartitionsRDD[124] at keyBy at <console>:23
scala> b.collect
res80: Array[(Int, String)] = Array((3,dog), (6,salmon), (6,salmon), (3,rat), (8,elephant))
lookup
从key-value型的RDD中,筛选出指定的key集合。返回的是Scala的sequence。
val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "panther", "eagle"), 2)
val b = a.map(x => (x.length, x))
b.lookup(5)
res0: Seq[String] = WrappedArray(tiger, eagle)
collect || collectPartitions
collect方法可以用于将RDD类型的数据转化为Array类型并参与后续运算
而collect方法是从各个节点将数据拉到driver端,所以需要重新分区,每次collect都会导致一次Shuffle,而每一次Shuffle都会调度一次stage,带来很多个碎片task,会导致程序运行时间大大增加,比较耗时,更可能导致driver端内存溢出,因此分布式环境下尽量避免或用其他方式替代
collectPartitions方法同样属于一种Action操作,会将数据拉到driver端,唯一的区别是这个方法产生的数据类型不同于collect方法,collect是将所有RDD汇到一个数组中,而collectPartitions方法是把各个分区内的所有元素存储到一个数组中,然后拉到driver端的时候再产生一个数组,因此collect产生一个一维数组,collectPartitions方法产生一个二维数组
cleanShuffleDependencies
spark在3.1.0加入的一个实验性方法,用于删除一个RDD的Shuffle以及它的非持久化的先祖。在没有运行shuffle服务的时候清除shuffle文件以减少规模,在调用这个函数之后使用RDD首先需要进行checkpoint以及materialize
其主要运作方式表现为将driver GC调优为更加激进,从而触发常规上下文清理器以及设置一个适当的TTL来自动清除shuffle文件
barrier
spark在2.4.0引入方法,用于将当前stage标记为barrier阶段,spark必须在这个阶段同时启动所有task,任务失败时,spark不会仅仅重新启动失败的任务而是中止任务,重新启动这个stage以及stage下的所有task
barrier mode是一种实验性方法,用于引入新的调度模型——屏障调度,只用于处理有限的场景,比如深度学习
withResources || getResourceProfile
spark在3.1.0引入的实验性方法,用于指定计算这个RDD时采用的resourceProfile,用于一些环境下实现stage级别的动态分配,以解决spark调优粒度过大的问题
其背景以及业务场景介绍
熟悉 Spark 的同学都知道,Spark 作业启动的时候我们需要指定 Exectuor 的个数以及内存、CPU 等信息。但是在 Spark 作业运行的时候,里面可能包含很多个 Stages,这些不同的 Stage 需要的资源可能不一样,由于目前 Spark 的设计,我们无法对每个 Stage 进行细粒度的资源设置。而且即使是一个资深的工程师也很难准确的预估一个比较合适的配置,使得作业启动时设置的参数适合 Spark 每个 Stage。
我们来考虑这个这样的场景:我们有个 Spark 作业,它总共有两个 Stages。第一个 Stage 主要对我们输入的数据进行基本的 ETL 操作。这个阶段一般会启动大量的 Task,但是每个 Task 仅仅需要少量的内存以及少数的核(比如1个core)。第一个 Stage 处理完之后,我们将 ETL 处理的结果作为 ML 算法的输入,这个 Stage 只需要少数的 Task,但是每个 Task 需要大量的内存、GPUs 以及 CPU。
像上面这种业务场景大家应该经常遇到过,我们需要对不同 Stage 设置不同的资源。但是目前的 Spark 不支持这种细粒度的资源配置,导致我们不得不在作业启动的时候设置大量的资源,从而导致资源可能浪费,特别是在机器学习的场景下。
不过值得高兴的是,来自英伟达的首席系统软件工程师 Thomas Graves 给社区提了个 ISSUE,也就是 SPIP: Support Stage level resource configuration and scheduling,旨在让 Spark 支持 Stage 级别的资源配置和调度。大家从名字还可以看出,这是个 SPIP(Spark Project Improvement Proposals 的简称),SPIP 主要是标记重大的面向用户或跨领域的更改,而不是小的增量改进。所以可以看出,这个功能对 Spark 的修改很大,会对用户产生比较大的影响。
withResources 方法主要用于设置当前 RDD 的 resourceProfile,并返回当前 RDD 实例。ResourceProfile 里面指定的资源包括 cpu、内存和额外的资源(GPU/FPGA/等)。我们还可以利用它实现其他功能,比如限制每个 stage 的 task 数量,为 shuffle 指定一些参数。不过为了设计实现的简单,目前只考虑支持 Spark 目前支持的资源,针对 Task 可以设置 cpu 和额外的资源(GPU/FPGA/等);针对 Executor 可以设置 cpu、内存和额外的资源(GPU/FPGA/等) 。执行器资源包括cpu、内存和额外资源(GPU、FPGA等)。通过给现有 RDD 类添加上面的方法,这使得所有继承自 RDD 的演变 RDD 都支持设置资源,当然包括了输入文件生成的 RDD。
用户在编程的时候,可以通过 withResources 方法来设置 ResourceProfile 的,当然肯定不可以设置无限的资源。可以通过 ResourceProfile.require 同时设置 Executor 和 task 需要的资源。
toDebugString || debugString || firstDebugString || shuffleDebugString
可以用于输出RDD的血缘关系列表,用来分析RDD变化流程
debugChildren
对RDD血缘关系上的最后一个RDD应用一个不同的rule,如果RDD的dependencies长度为0\1_时分别应用不同的方法,主要用于调试
outputDeterministicLevel || getOutputDeterministicLevel
RDD输出的确定性级别
getOutputDeterministicLevel:开发者API,缺省情况下,一个可靠的检查点RDD,或者没有父RDD(根RDD)的RDD是DETERMINATE。对于具有父级的rdd,我们将根据依赖关系为每个父级生成一个确定性级别候选。当前RDD的确定性级别是确定性最小的候选确定性级别。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号