使用tensorflow的lstm网络进行时间序列预测
https://blog.csdn.net/flying_sfeng/article/details/78852816
版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/Flying_sfeng/article/details/78852816
这篇文章将讲解如何使用lstm进行时间序列方面的预测,重点讲lstm的应用,原理部分可参考以下两篇文章:
Understanding LSTM Networks LSTM学习笔记
编程环境:python3.5,tensorflow 1.0
本文所用的数据集来自于kesci平台,由云脑机器学习实战训练营提供:真实业界数据的时间序列预测挑战
数据集采用来自业界多组相关时间序列(约40组)与外部特征时间序列(约5组)。本文只使用其中一组数据进行建模。
加载常用的库:
-
#加载数据分析常用库
-
import pandas as pd
-
import numpy as np
-
import tensorflow as tf
-
from sklearn.metrics import mean_absolute_error,mean_squared_error
-
from sklearn.preprocessing import MinMaxScaler
-
import matplotlib.pyplot as plt
-
% matplotlib inline
-
import warnings
-
warnings.filterwarnings('ignore')
数据显示:
-
path = '../input/industry/industry_timeseries/timeseries_train_data/11.csv'
-
data11 = pd.read_csv(path,names=['年','月','日','当日最高气温','当日最低气温','当日平均气温','当日平均湿度','输出'])
-
data11.head()
| 年 | 月 | 日 | 当日最高气温 | 当日最低气温 | 当日平均气温 | 当日平均湿度 | 输出 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 2015 | 2 | 1 | 1.9 | -0.4 | 0.7875 | 75.000 | 814.155800 |
| 1 | 2015 | 2 | 2 | 6.2 | -3.9 | 1.7625 | 77.250 | 704.251112 |
| 2 | 2015 | 2 | 3 | 7.8 | 2.0 | 4.2375 | 72.750 | 756.958978 |
| 3 | 2015 | 2 | 4 | 8.5 | -1.2 | 3.0375 | 65.875 | 640.645401 |
| 4 | 2015 | 2 | 5 | 7.9 | -3.6 | 1.8625 | 55.375 | 631.725130 |
加载数据:
-
##load data(本文以第一个表为例,其他表类似,不再赘述)
-
f=open('../input/industry/industry_timeseries/timeseries_train_data/11.csv')
-
df=pd.read_csv(f) #读入数据
-
data=df.iloc[:,3:8].values #取第3-7列
定义常量并初始化权重:
-
#定义常量
-
rnn_unit=10 #hidden layer units
-
input_size=4
-
output_size=1
-
lr=0.0006 #学习率
-
tf.reset_default_graph()
-
#输入层、输出层权重、偏置
-
weights={
-
'in':tf.Variable(tf.random_normal([input_size,rnn_unit])),
-
'out':tf.Variable(tf.random_normal([rnn_unit,1]))
-
}
-
biases={
-
'in':tf.Variable(tf.constant(0.1,shape=[rnn_unit,])),
-
'out':tf.Variable(tf.constant(0.1,shape=[1,]))
-
}
分割数据集,将数据分为训练集和验证集(最后90天做验证,其他做训练):
-
def get_data(batch_size=60,time_step=20,train_begin=0,train_end=487):
-
batch_index=[]
-
-
scaler_for_x=MinMaxScaler(feature_range=(0,1)) #按列做minmax缩放
-
scaler_for_y=MinMaxScaler(feature_range=(0,1))
-
scaled_x_data=scaler_for_x.fit_transform(data[:,:-1])
-
scaled_y_data=scaler_for_y.fit_transform(data[:,-1])
-
-
label_train = scaled_y_data[train_begin:train_end]
-
label_test = scaled_y_data[train_end:]
-
normalized_train_data = scaled_x_data[train_begin:train_end]
-
normalized_test_data = scaled_x_data[train_end:]
-
-
train_x,train_y=[],[] #训练集x和y初定义
-
for i in range(len(normalized_train_data)-time_step):
-
if i % batch_size==0:
-
batch_index.append(i)
-
x=normalized_train_data[i:i+time_step,:4]
-
y=label_train[i:i+time_step,np.newaxis]
-
train_x.append(x.tolist())
-
train_y.append(y.tolist())
-
batch_index.append((len(normalized_train_data)-time_step))
-
-
size=(len(normalized_test_data)+time_step-1)//time_step #有size个sample
-
test_x,test_y=[],[]
-
for i in range(size-1):
-
x=normalized_test_data[i*time_step:(i+1)*time_step,:4]
-
y=label_test[i*time_step:(i+1)*time_step]
-
test_x.append(x.tolist())
-
test_y.extend(y)
-
test_x.append((normalized_test_data[(i+1)*time_step:,:4]).tolist())
-
test_y.extend((label_test[(i+1)*time_step:]).tolist())
-
-
return batch_index,train_x,train_y,test_x,test_y,scaler_for_y
定义LSTM的网络结构:
-
#——————————————————定义神经网络变量——————————————————
-
def lstm(X):
-
batch_size=tf.shape(X)[0]
-
time_step=tf.shape(X)[1]
-
w_in=weights['in']
-
b_in=biases['in']
-
input=tf.reshape(X,[-1,input_size]) #需要将tensor转成2维进行计算,计算后的结果作为隐藏层的输入
-
input_rnn=tf.matmul(input,w_in)+b_in
-
input_rnn=tf.reshape(input_rnn,[-1,time_step,rnn_unit]) #将tensor转成3维,作为lstm cell的输入
-
cell=tf.contrib.rnn.BasicLSTMCell(rnn_unit)
-
#cell=tf.contrib.rnn.core_rnn_cell.BasicLSTMCell(rnn_unit)
-
init_state=cell.zero_state(batch_size,dtype=tf.float32)
-
output_rnn,final_states=tf.nn.dynamic_rnn(cell, input_rnn,initial_state=init_state, dtype=tf.float32) #output_rnn是记录lstm每个输出节点的结果,final_states是最后一个cell的结果
-
output=tf.reshape(output_rnn,[-1,rnn_unit]) #作为输出层的输入
-
w_out=weights['out']
-
b_out=biases['out']
-
pred=tf.matmul(output,w_out)+b_out
-
return pred,final_states
模型训练与预测:
-
#——————————————————训练模型——————————————————
-
def train_lstm(batch_size=80,time_step=15,train_begin=0,train_end=487):
-
X=tf.placeholder(tf.float32, shape=[None,time_step,input_size])
-
Y=tf.placeholder(tf.float32, shape=[None,time_step,output_size])
-
batch_index,train_x,train_y,test_x,test_y,scaler_for_y = get_data(batch_size,time_step,train_begin,train_end)
-
pred,_=lstm(X)
-
#损失函数
-
loss=tf.reduce_mean(tf.square(tf.reshape(pred,[-1])-tf.reshape(Y, [-1])))
-
train_op=tf.train.AdamOptimizer(lr).minimize(loss)
-
with tf.Session() as sess:
-
sess.run(tf.global_variables_initializer())
-
#重复训练5000次
-
iter_time = 5000
-
for i in range(iter_time):
-
for step in range(len(batch_index)-1):
-
_,loss_=sess.run([train_op,loss],feed_dict={X:train_x[batch_index[step]:batch_index[step+1]],Y:train_y[batch_index[step]:batch_index[step+1]]})
-
if i % 100 == 0:
-
print('iter:',i,'loss:',loss_)
-
####predict####
-
test_predict=[]
-
for step in range(len(test_x)):
-
prob=sess.run(pred,feed_dict={X:[test_x[step]]})
-
predict=prob.reshape((-1))
-
test_predict.extend(predict)
-
-
test_predict = scaler_for_y.inverse_transform(test_predict)
-
test_y = scaler_for_y.inverse_transform(test_y)
-
rmse=np.sqrt(mean_squared_error(test_predict,test_y))
-
mae = mean_absolute_error(y_pred=test_predict,y_true=test_y)
-
print ('mae:',mae,' rmse:',rmse)
-
return test_predict
调用train_lstm()函数,完成模型训练与预测的过程,并统计验证误差(mae和rmse):
test_predict = train_lstm(batch_size=80,time_step=15,train_begin=0,train_end=487)迭代5000次后的结果:
-
iter: 3900 loss: 0.000505382
-
iter: 4000 loss: 0.000502154
-
iter: 4100 loss: 0.000503413
-
iter: 4200 loss: 0.00140424
-
iter: 4300 loss: 0.000500015
-
iter: 4400 loss: 0.00050004
-
iter: 4500 loss: 0.000498159
-
iter: 4600 loss: 0.000500861
-
iter: 4700 loss: 0.000519379
-
iter: 4800 loss: 0.000499999
-
iter: 4900 loss: 0.000501265
-
mae: 121.183626208 rmse: 162.049017904
画图分析:
-
plt.figure(figsize=(24,8))
-
plt.plot(data[:, -1])
-
plt.plot([None for _ in range(487)] + [x for x in test_predict])
-
plt.show()
结果如下:
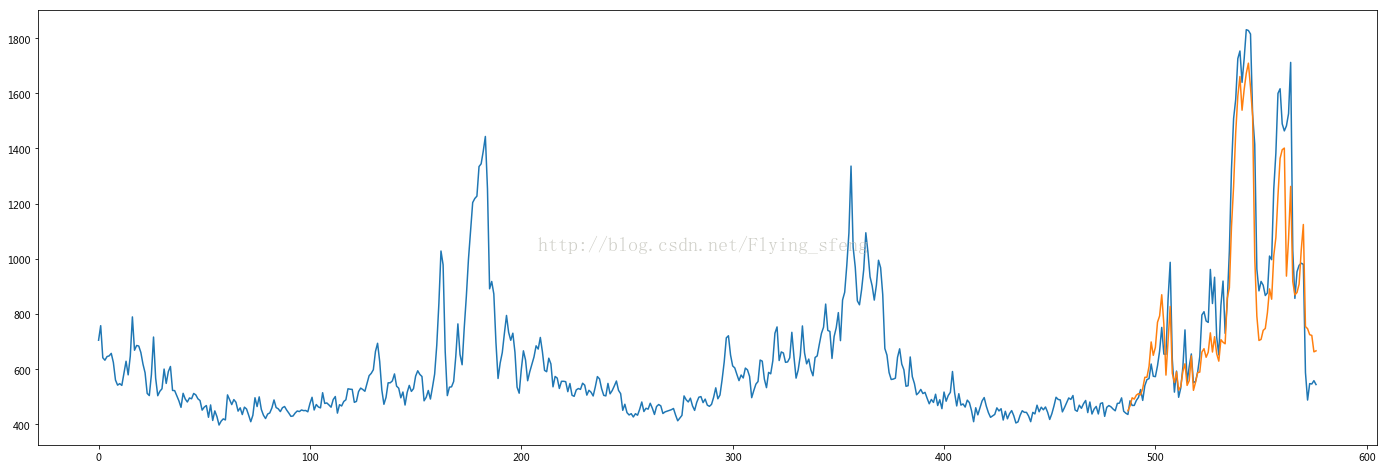
可以看到,lstm模型基本能预测出序列的趋势。
为了简化流程,本文在特征工程及参数调优方面并没有下功夫,适合初学者探索lstm模型在时间序列问题上的应用。
ps:数据的归一化很重要,必须保证把训练集跟验证集规范在同一个空间内,否则得到的效果会很差。(我以前做天池的降雨量预测问题时一开始用的就是lstm,就是这一步没做好,导致最后得到的结果基本很相近,最后这个模型被我放弃了。我在做这个数据集的时候一开始也遇到这个问题,后来在归一化时把样本都设置在同个空间范畴,就解决问题了)。
数据集提供了大概45组数据,所以我们可以使用multi-task learning探索各组数据之间的关联性,这部分我还没具体了解,就不贻笑大方了。
本文建模的框架来自于:Tensorflow实例:利用LSTM预测股票每日最高价(二)
--------------------- 本文来自 Flying_sfeng 的CSDN 博客 ,全文地址请点击:https://blog.csdn.net/flying_sfeng/article/details/78852816?utm_source=copy

 浙公网安备 33010602011771号
浙公网安备 33010602011771号