StructuredStreaming基础操作和窗口操作
一、流式DataFrames/Datasets的结构类型推断与划分
◆ 默认情况下,基于文件源的结构化流要求必须指定schema,这种限制确保即
使在失败的情况下也会使用一致的模式来进行流查询。
◆ 对于特殊用例,可以通过设置spark.sql.streaming.schemaInference = true。
此时将会开启Spark自动类型推断功能。
◆ 注意:默认Spark sql中自动类型推断为启动状态。
◆ 当读取数据的目录中出现/key=value/ 的子目录时,Spark将自动递归这些子目
录,产生分区发现。
◆ 如果用户提供的 schema 中出现了这些列, Spark将会根据正在读取的文件路
径进行填充。
◆ 构成分区结构的目录必须在查询开始时是存在的,并且必须保持static 。
➢ 例如,当 /data/year=2015/ 存在时,可以添加 /data/year=2016/,但是更改
分区列将无效的(即通过创建目录 /data/date=2016-04-17/ )。
◆ 注意:如果希望得到的数据可以按照/key=value/这种目录生成时,可以在输出
数据时借助于partitionBy(“columnName”)
二、流式DataFrames/Datasets的操作
◆ 基础操作-Selection, Projection, Aggregation
◆ 基于Event Time的窗口操作
◆ 连接操作
◆ 流式去重操作
◆ 任意状态运算
◆ 不支持操作
2.1 基础操作-Selection, Projection, Aggregation
◆ DataFrames/Datasets上的大多数常用操作都支持流式运算。(后面在讨论不
支持的操作)
◆ 例如:
➢ case class DeviceData(device: String, deviceType: String, signal: Double, time: DateTime) ➢ val df: DataFrame = …
➢ val ds: Dataset[DeviceData] = df.as[DeviceData]
➢ df.select("device").where("signal > 10") ➢ ds.filter(_.signal > 10).map(_.device) ➢ df.groupBy("deviceType").count() ➢ import org.apache.spark.sql.expressions.scalalang.typed
➢ ds.groupByKey(_.deviceType).agg(typed.avg(_.signal))
◆ 可以注册一个流式DataFrames/DataSets作为临时视图,使用SQL命令做查
询操作。
➢ df.createOrReplaceTempView(“ updates”) ➢ spark.sql(“ select count(*) from updates”) ➢ df.isStreaming
2.2基于Event Time的窗口操作
◆ 基于结构化流的滑动事件时间窗口的聚合操作比较简单,与分组聚合非常相似。
在分组聚合中,按照用户指定的列进行分组聚合。在基于窗口的聚合中,按照
每个窗口进行聚合操作
◆ 案例模型:实时处理流单词统计的窗口操作示意图
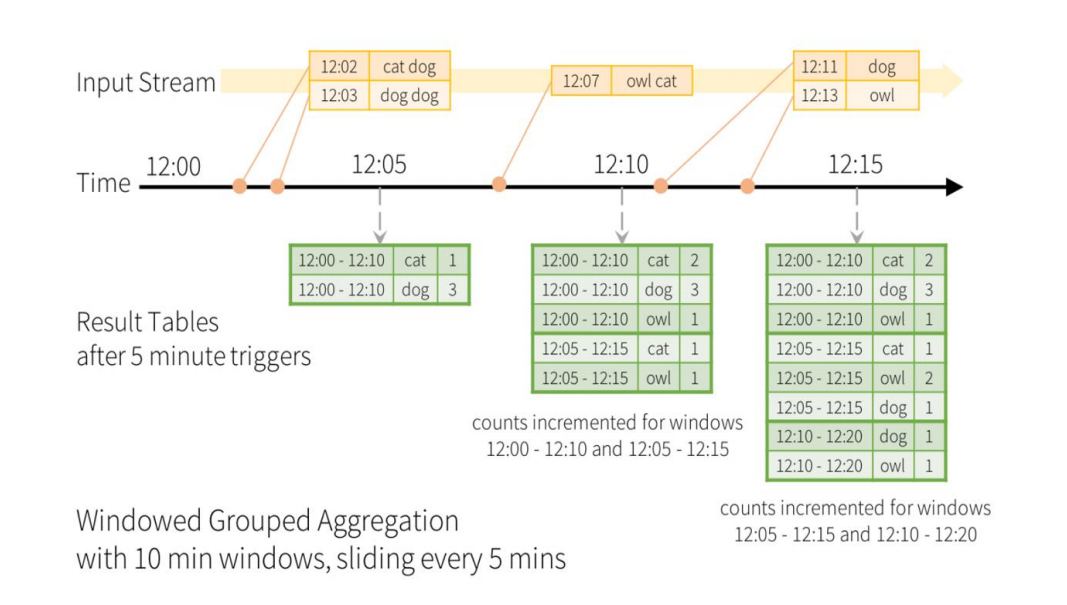
◆ 窗口操作类似于分组操作
◆ 例子:可以使用groupBy()和window()操作来表示窗口聚合。 ➢ import spark.implicits._ ➢ val words: DataFrame = ... // schema { timestamp: Timestamp, word: String }
➢ val windowedCounts = words.groupBy( window($"timestamp"
, "10 minutes"
, "5 minutes"), $"word" ).count()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号