洛谷与 Codeforces 的难度评级
为了比较 CF 与洛谷的题目难度评级,我写了一个爬虫,爬取了 CF 题目在源站和洛谷中的难度,并进行比较。
这里先给出两者的换算:
| 洛谷 | 入门 | 普及- | 普及/提高- | 普及+/提高 | 提高+/省选- | 省选/NOI- | NOI/NOI+/CTSC |
|---|---|---|---|---|---|---|---|
| CF | 800 | 900-1100 | 1200-1500 | 1600-1900 | 2000-2300 | 2400-2900 | 3000-3500 |
本文中的爬虫代码修改自阮行止的博文《洛谷提交记录爬虫》,已获得作者授权。
获取洛谷的难度评级
我选择按页爬取洛谷的 CF 题库。查看源代码后发现貌似并没有我们想要的题目难度数据。其实它藏在那段 js 后面。
利用 beautifulsoup,我们可以得到 js 里面的数据。
想要深入探究的读者可以参考上面给出的文章链接。这里直接给出源代码,不再赘述。
import requests as rq
from urllib.parse import unquote
from bs4 import BeautifulSoup
from re import findall
import json
import threading
count = 164
lim = 30
l = {}
def getPage(page):
url = f'https://www.luogu.com.cn/problem/list?type=CF&page={page}'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
r = rq.get(url, headers=headers, timeout = 5)
soup = BeautifulSoup(r.text, 'html.parser')
res = soup.script.get_text()
res = unquote(res.split('\"')[1])
data = json.loads(res)
data = data['currentData']['problems']['result']
for i in data:
l[i['pid'][2:]] = i['difficulty']
print(page)
def work(x):
for i in range(x, x+lim):
if i > count:
return
getPage(i)
if __name__ == '__main__':
pool = [threading.Thread(target=work, args=[x]) for x in range(1, count + lim, lim)]
for x in pool:
x.start()
for x in pool:
x.join()
json.dump(l, open('luogu.json', 'w'))
获取 CF 的难度评级
从 Codeforces API 中我们发现有一个 包含所有题目的网页(JSON 格式,大小较大)。因此只需把它保存下来(代码中命名为 codeforces_raw.json),在本地进行处理即可:
import json
raw = json.load(open('codeforces_raw.json', encoding='utf-8'))
l = {}
for i in raw['result']['problems']:
try:
l[str(i['contestId']) + i['index']] = i['rating']
except KeyError:
print(i)
json.dump(l, open('codeforces.json', 'w'))
汇总
我们再写一个程序,输出具有特定 CF 和洛谷评级的题目个数:
import json
l = json.load(open('luogu.json'))
c = json.load(open('codeforces.json'))
t = {(i, j): [] for i in range(800, 3500+100, 100) for j in range(0, 8)}
for p in l:
if p not in c:
continue
r = c[p]
d = l[p]
t[r, d].append(p)
print(end='\t')
for j in range(0, 8):
print(j, end='\t')
print()
for i in range(800, 3500+100, 100):
print(i, end='\t')
for j in range(0, 8):
print(len(t[i, j]), end='\t')
print()
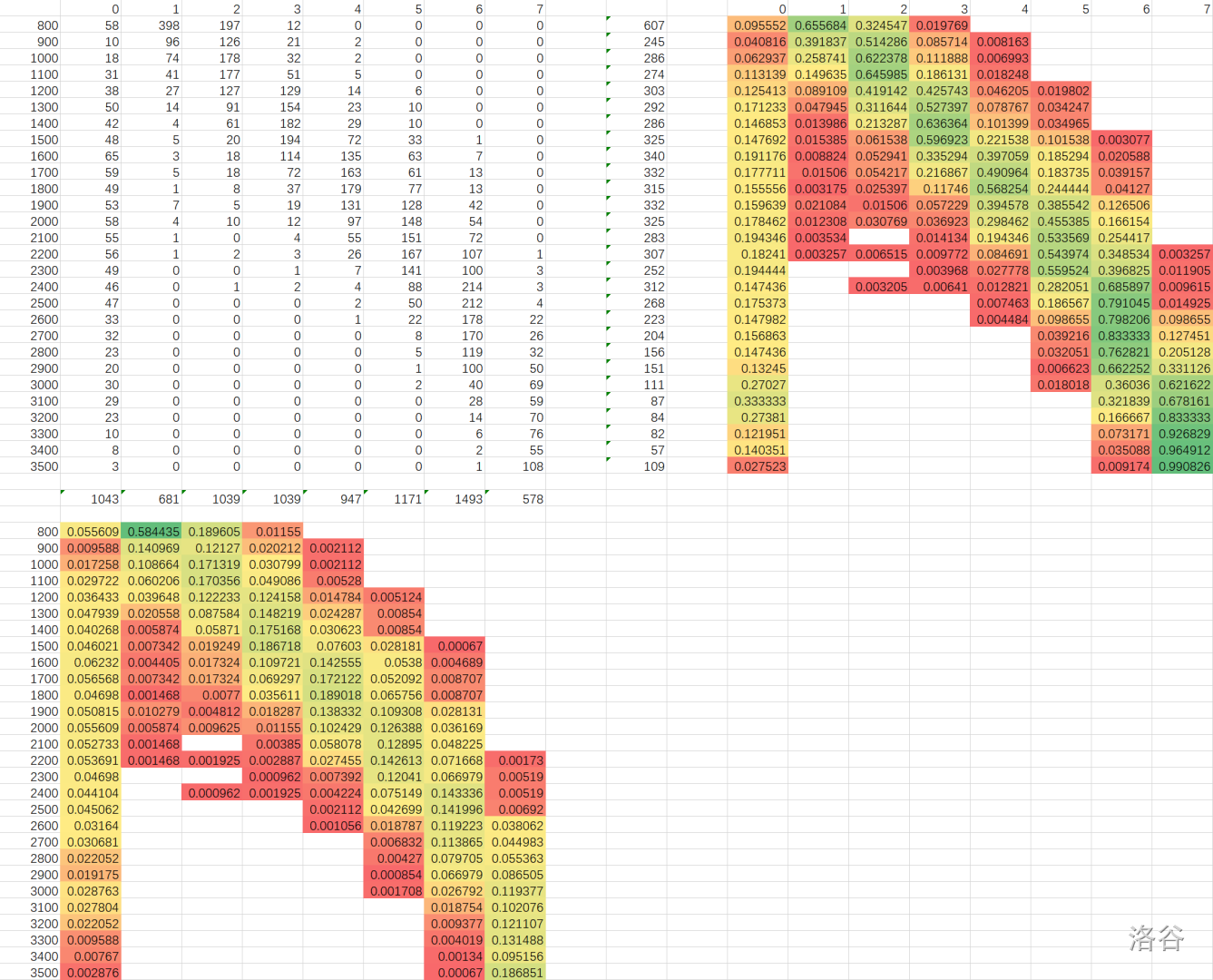
输出如下:
0 1 2 3 4 5 6 7
800 58 398 197 12 0 0 0 0
900 10 96 126 21 2 0 0 0
1000 18 74 178 32 2 0 0 0
1100 31 41 177 51 5 0 0 0
1200 38 27 127 129 14 6 0 0
1300 50 14 91 154 23 10 0 0
1400 42 4 61 182 29 10 0 0
1500 48 5 20 194 72 33 1 0
1600 65 3 18 114 135 63 7 0
1700 59 5 18 72 163 61 13 0
1800 49 1 8 37 179 77 13 0
1900 53 7 5 19 131 128 42 0
2000 58 4 10 12 97 148 54 0
2100 55 1 0 4 55 151 72 0
2200 56 1 2 3 26 167 107 1
2300 49 0 0 1 7 141 100 3
2400 46 0 1 2 4 88 214 3
2500 47 0 0 0 2 50 212 4
2600 33 0 0 0 1 22 178 22
2700 32 0 0 0 0 8 170 26
2800 23 0 0 0 0 5 119 32
2900 20 0 0 0 0 1 100 50
3000 30 0 0 0 0 2 40 69
3100 29 0 0 0 0 0 28 59
3200 23 0 0 0 0 0 14 70
3300 10 0 0 0 0 0 6 76
3400 8 0 0 0 0 0 2 55
3500 3 0 0 0 0 0 1 108
其中左边为 CF 评级,上方为洛谷评级,从左到右为:暂无评定,入门,普及-,普及/提高-,普及+/提高,提高+/省选-,省选/NOI-,NOI/NOI+/CTSC。
接下来把表格复制到 Excel 中进行处理。下面是结果:左上角是原始数据;右上角是已知 CF 评级,洛谷评级的出现频率;左下角为已知洛谷评级,CF 评级的出现频率。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号