第一次作业:深度学习基础
第一部分 视频学习心得及问题总结
视频学习心得
-
人工智能。就是像一部机器人一样进行感知、认知、决策、执行的人工程序或系统。人工智能包含三个层面,即计算智能(计算机快速计算和记忆存储能力-1997年深蓝算法战胜国际象棋大师卡斯帕罗夫)、感知智能(类似于人的视觉、听觉、触觉等感知能力)、认知智能(概念、意识、观念)。实现人工智能有早期的知识工程/专家系统,以及现在的机器学习。
![]()
-
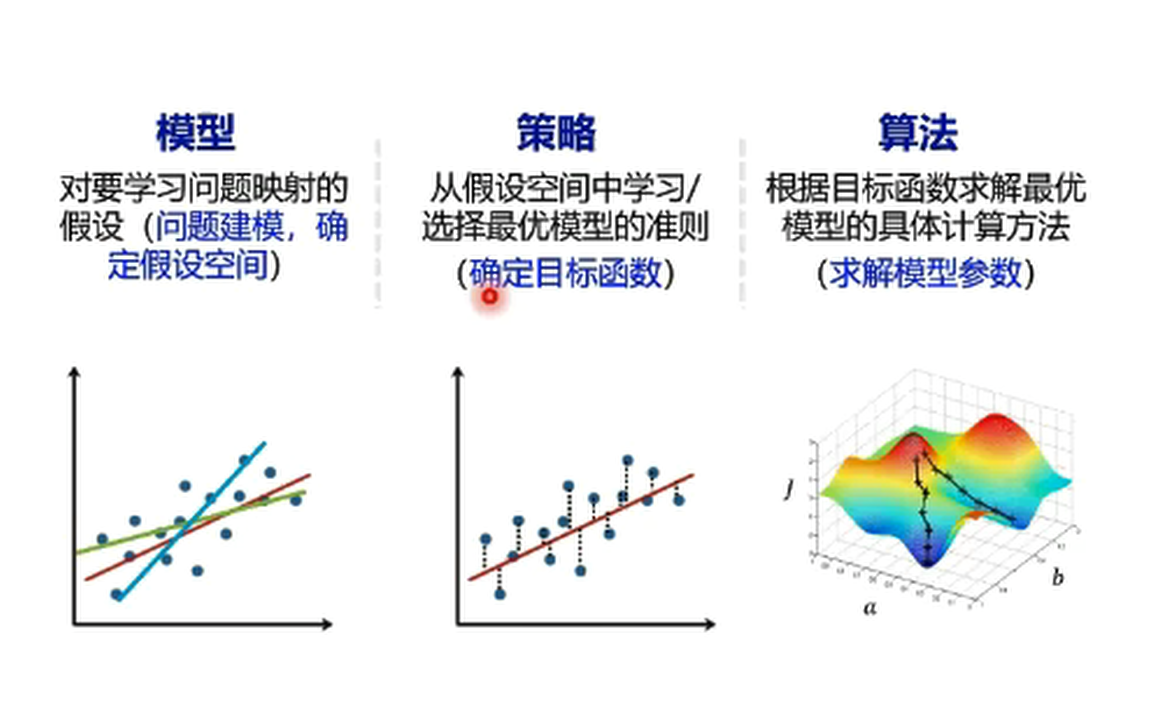
机器学习可应用在计算机视觉、语音技术、自然语言处理等领域。所谓机器学习,就是计算机系统能够利用经验提高自身的性能。机器学习有三个要素:
![]()
机器学习包含监督学习、无监督学习、半监督学习、强化学习。监督学习:样本数据具有标记(输出目标);从数据中学习标记分界面(输入—输出的映射函数),适用于预测数据标记。对数据要求高。
无监督学习:样本数据没有标记,从数据中学习模式,适用于描述数据。主要用于聚类算法。
半监督学习: 部分数据已知,标记样本难以获取,无标记样本相对低廉,思路:假设未标记样本与标记样本独立同分布—>包含关于数据分布的重要信息。
强化学习:数据标记未知,但知道与输出目标相关的反馈—决策类问题。算法复杂,但是对数据要求低。
-
神经网络基础
神经网络是一种模仿动物神经网络行为特征,进行分布式并行处理信息的算法模型。
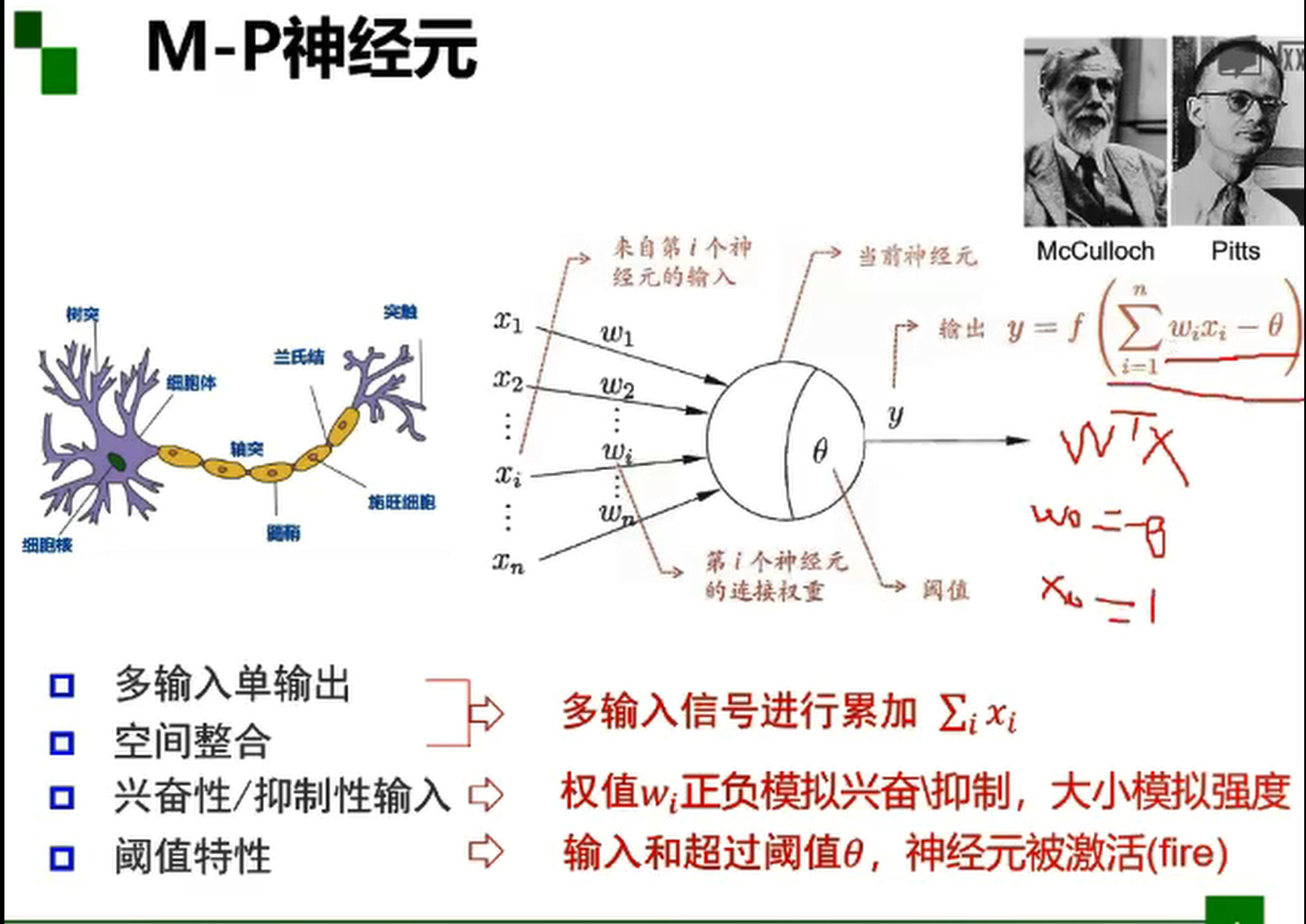
M-P神经元模型是模仿大脑神经元的最早示例。在M-P神经元模型中,神经元接收来自n个其他神经元传递过来的输入信号,再将接收到的输入信号按照某种权重叠加起来,叠加起来的刺激强度S可用公式
来表示。得到S后,要与当前神经元的阈值进行比较,然后通过激活函数向外表达输出。
![]()
M-P神经元模型是按照生物神经元的结构和工作原理构造出来的一个抽象和简化了的模型,实际上是对单个神经元的建模。
常用的激活函数

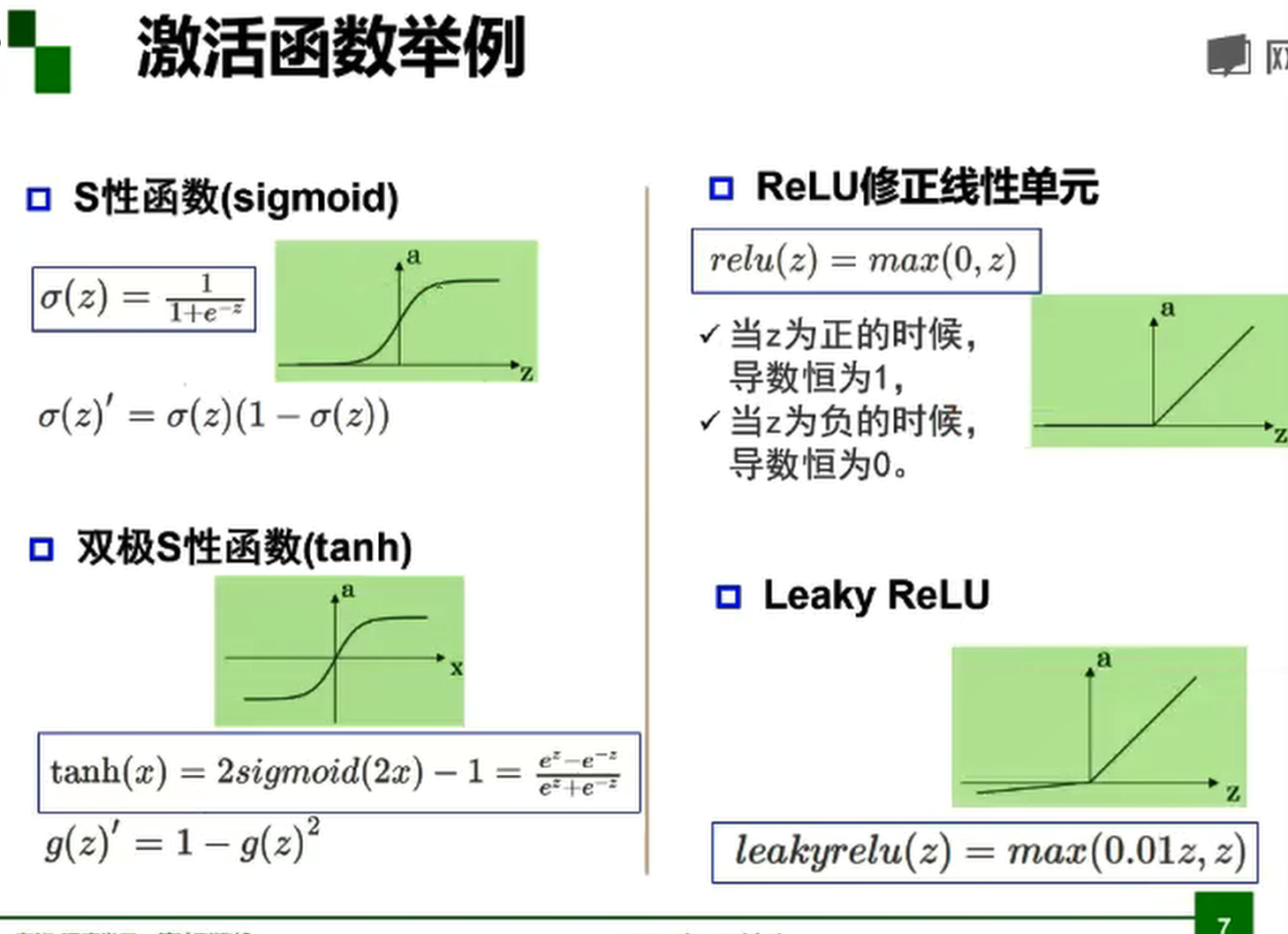
双极S形函数与S形函数主要区别在于函数的值域,双极S形函数值域是(−1,1),而S形函数值域是(0,1),
由于S形函数与双极S形函数都是可导的(导函数是连续函数),因此适合用在BP神经网络中。(BP算法要求激活函数可导),S形函数常用二分类问题。
感知器是最简单的神经网络结构,在1958年,美国心理学家Frank Rosenblatt提出一种具有单层计算单元的神经网络,称为感知器(Perceptron)。它其实就是基于M-P模型的结构。我们可以看看它的拓扑结构图。 这个图其实就是输入输出两层神经元之间的简单连接
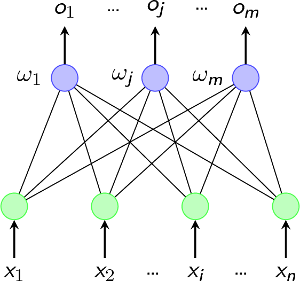
单层感知器仅对线性问题具有分类能力。
多层感知器就是在输入层和输出层之间加入隐层,以形成能够将样本正确分类的凸域。多层感知器的拓扑结构如下图所示。
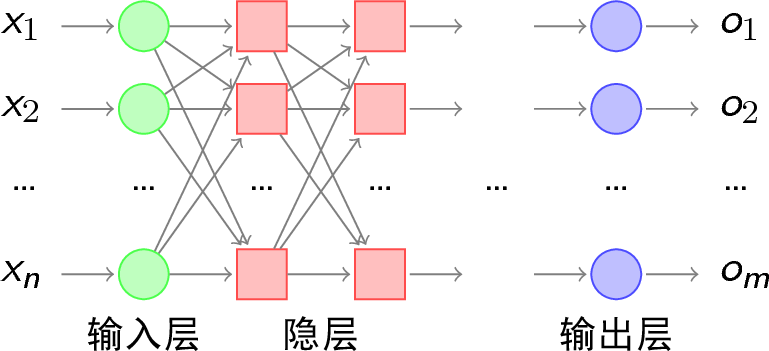
我们可以比较一下单层感知器和多层感知器的分类能力:
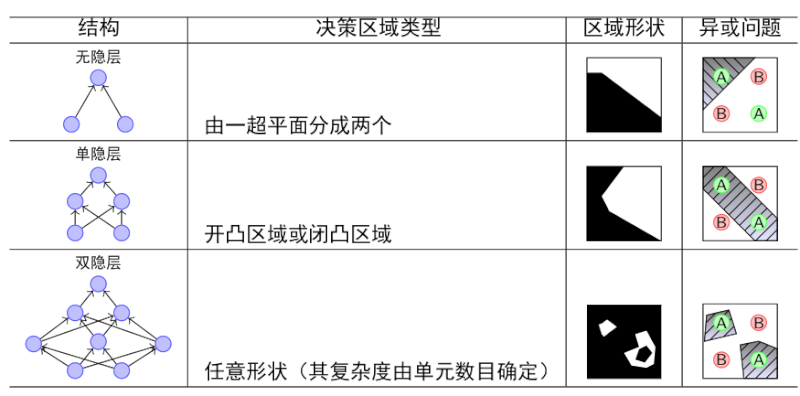
由上图可以看出,随着隐层层数的增多,凸域将可以形成任意的形状,因此可以解决任何复杂的分类问题。实际上,Kolmogorov理论指出:双隐层感知器就足以解决任何复杂的分类问题。

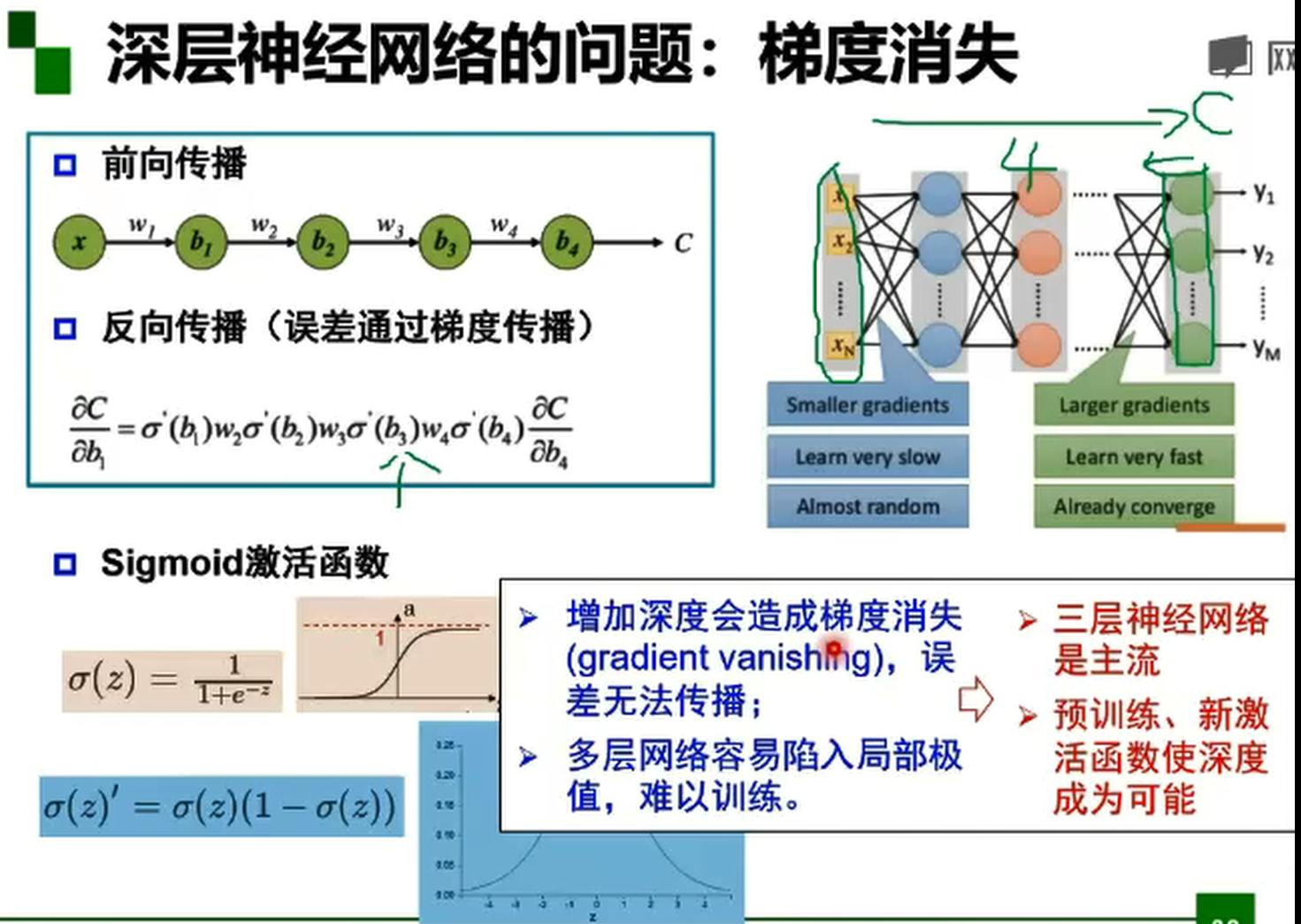
误差通过梯度反向传播,在反向传播过程中,到了某一层的梯度变成了零,这就是梯度消失。梯度消失使反向传播没有了意义,因为并没有实现参数的更新,而神经网络也并没有进行学习。使用ReLU函数时:gradient = 0 (if x < 0), gradient = 1 (x > 0)。不会产生梯度消失问题。
自编码器是一种旨在将它们的输入复制到的输出的神经网络。他们通过将输入压缩成一种隐藏空间表示,然后这种重构这种表示的输出进行工作。这种网络由两部分组成:
编码器:将输入压缩为潜在空间表示。可以用编码函数h = f(x)表示。
解码器:这部分旨在重构来自隐藏空间表示的输入。可以用解码函数r = g(h)表示。
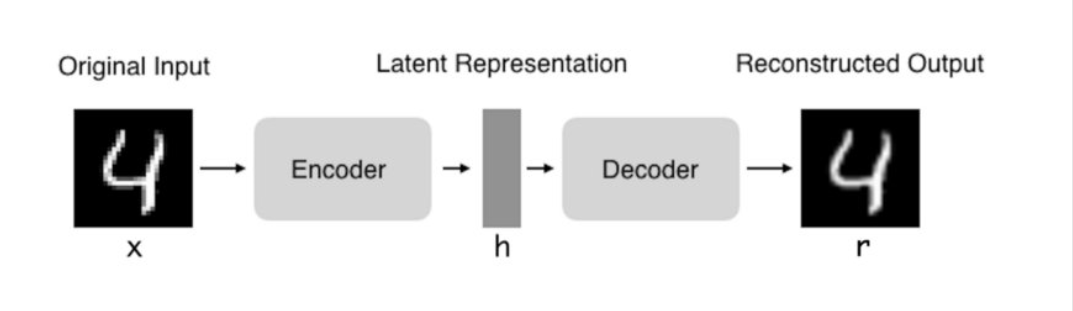
因此自编码器的整体可以用函数g(f(x))= r来描述,其中我们想要得到的r与原始输入x相近。如今,数据可视化的数据降噪和降维被认为是自编码器的两个主要的实际应用。使用适当的维度和稀疏性约束,自编码器可以得到比PCA或其他类似技术更好的数据投影。
Pytorch代码练习
- 图像处理基本练习
对老师发布的相关代码进行了练习,参考网上的相关资料对相关的知识进行了一些补充,后续慢慢的学习。
PIL(图像处理类库)提供了通用的图像处理功能,以及大量有用的基本图像操作,比如图像缩放、裁剪、旋转、颜色转换等。利用 PIL 中的函数,我们可以从大多数图像格式的文件中读取数据,然后写入最常见的图像格式文件中。PIL 中最重要的模块为 Image。要读取一幅图像,可以使用:
from PIL import Image
pil_im = Image.open('xxx.jpg')
上述代码的返回值 pil_im 是一个 PIL 图像对象。图像的颜色转换可以使用 convert() 方法来实现。要读取一幅图像,并将其转换成灰度图像,只需要加上 convert('L'),如下所示:
pil_im = Image.open('xxx.jpg').convert('L')
要调整一幅图像的尺寸,我们可以调用 resize() 方法。该方法的参数是一个元组,用来指定新图像的大小:
out = pil_im.resize((128,128))
要旋转一幅图像,可以使用逆时针方式表示旋转角度,然后调用 rotate() 方法:
out = pil_im.rotate(45)
Matplotlib 是个很好的类库,具有比 PIL 更强大的绘图功能。就像本书中的许多插图一样。Matplotlib 中的 PyLab 接口包含很多方便用户创建图像的函数。
from PIL import Image
from pylab import *
# 读取图像到数组中
im = array(Image.open('xxx.jpg'))
# 绘制图像
imshow(im)
# 一些点
x = [100,100,400,400]
y = [200,500,200,500]
# 使用红色星状标记绘制点
plot(x,y,'r*')
# 绘制连接前两个点的线
plot(x[:2],y[:2])
# 添加标题,显示绘制的图像
title('Plotting: "XXX.jpg"')
show()
上面的代码首先绘制出原始图像,然后在 x 和 y 列表中给定点的 x 坐标和 y 坐标上绘制出红色星状标记点,最后在两个列表表示的前两个点之间绘制一条线段(默认为蓝色)。show() 命令首先打开图形用户界面,然后新建一个图像窗口。该图形用户界面会循环阻断脚本,然后暂停,直到最后一个图像窗口关闭。在每个脚本里,你只能调用一次 show() 命令,而且通常是在脚本的结尾调用。注意,在 PyLab 库中,我们约定图像的左上角为坐标原点。图像的坐标轴是一个很有用的调试工具;但是,如果你想绘制出较美观的图像,加上下列命令可以使坐标轴不显示:
axis('off')
在绘图时,有很多选项可以控制图像的颜色和样式。
plot(x,y) # 默认为蓝色实线
plot(x,y,'r*') # 红色星状标记
plot(x,y,'go-') # 带有圆圈标记的绿线
plot(x,y,'ks:') # 带有正方形标记的黑色虚线
numpy是非常有名的 Python 科学计算工具包,其中包含了大量有用的思想,比如数组对象(用来表示向量、矩阵、图像等)以及线性代数函数。NumPy 中的数组对象可以帮助你实现数组中重要的操作,比如矩阵乘积、转置、解方程系统、向量乘积和归一化,这为图像变形、对变化进行建模、图像分类、图像聚类等提供了基础。具体的使用可以参考 基本的图像操作和处理
- pytorch基础练习
1.一般定义数据使用torch.Tensor , tensor的意思是张量,是数字各种形式的总称
#可以是一个数
import torch
x = torch.tensor(666)
print(x)
tensor(666)
#定义一维数组(向量)
x = torch.tensor([1,2,3,4,5,6])
print(x)
tensor([1, 2, 3, 4, 5, 6])
#可以是二维数组(矩阵)
x = torch.ones(2,3)
print(x)
tensor([[[1., 1., 1., 1.], [1., 1., 1., 1.], [1., 1., 1., 1.]], [[1., 1., 1., 1.], [1., 1., 1., 1.], [1., 1., 1., 1.]]])
#创建一个空张量
x = torch.empty(5,3)
print(x)
tensor([[7.9401e-36, 0.0000e+00, 3.3631e-44], [0.0000e+00, nan, 6.1657e-44], [1.1578e+27, 1.1362e+30, 7.1547e+22], [4.5828e+30, 1.2121e+04, 7.1846e+22], [9.2198e-39, 7.0374e+22, 0.0000e+00]])
#创建一个随机初始化的张量
x = torch.rand(5,3)
print(x)
tensor([[0.8308, 0.9795, 0.1960], [0.3875, 0.6873, 0.0711], [0.2183, 0.4397, 0.4779], [0.6162, 0.0932, 0.9897], [0.7111, 0.2970, 0.7503]])
# 创建一个全0的张量,里面的数据类型为 long
x = torch.zeros(5,3,dtype=torch.long)
print(x)
tensor([[0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0], [0, 0, 0]])
# 基于现有的tensor,创建一个新tensor,
# 从而可以利用原有的tensor的dtype,device,size之类的属性信息
y = x.new_ones(5,3) #tensor new_* 方法,利用原来tensor的dtype,device
print(y)
tensor([[1, 1, 1], [1, 1, 1], [1, 1, 1], [1, 1, 1], [1, 1, 1]])
2.定义操作 凡是用Tensor进行各种运算的,都是Function 最终,还是需要用Tensor来进行计算的,计算无非是 基本运算,加减乘除,求幂求余 布尔运算,大于小于,最大最小 线性运算,矩阵乘法,求模,求行列式 基本运算包括: abs/sqrt/div/exp/fmod/pow ,及一些三角函数 cos/ sin/ asin/ atan2/ cosh,及 ceil/round/floor/trunc 等.
# 创建一个 2x4 的tensor
m = torch.tensor([[2, 5, 3, 7],
[4, 2, 1, 9]])
print(m.size(0), m.size(1), m.size(), sep=' -- ')
2 -- 4 -- torch.Size([2, 4])
#返回m中的元素的数量
print(m.numel())
8
#返回第0行第二列的数
print(m[0][2])
tensor(3)
#返回 第一列的全部元素
print(m[:,1])
tensor([5, 2])
#创建1到5的数字张量
#注意这里结果是1到4,没有5
s = torch.arange(1,5)
print(s)
tensor([1, 2, 3, 4])
#Scalar product
m @ s
tensor([49, 47])
# Calculated by 1*2 + 2*5 + 3*3 + 4*7
m[[0], :] @ s
tensor([49])
m[[1],:] @ s #二维矩阵的第二行与s[1,2,3,4]相乘
tensor([47])
#在m中加入一个大小为2x4的随机张量
m + torch.rand(2, 4)
tensor([[2.5977, 5.8325, 3.9557, 7.8341], [4.3985, 2.8731, 1.6023, 9.9716]])
# 转置,由 2x4 变为 4x2
print(m.t())
# 使用 transpose 也可以达到相同的效果
print(m.transpose(0, 1))
tensor([[2, 4], [5, 2], [3, 1], [7, 9]]) tensor([[2, 4], [5, 2], [3, 1], [7, 9]])
# returns a 1D tensor of steps equally spaced points between start=3, end=8 and steps=20
torch.linspace(3, 8, 20)
tensor([3.0000, 3.2632, 3.5263, 3.7895, 4.0526, 4.3158, 4.5789, 4.8421, 5.1053, 5.3684, 5.6316, 5.8947, 6.1579, 6.4211, 6.6842, 6.9474, 7.2105, 7.4737, 7.7368, 8.0000])
from matplotlib import pyplot as plt
# matlabplotlib 只能显示numpy类型的数据,下面展示了转换数据类型,然后显示
# 注意 randn 是生成均值为 0, 方差为 1 的随机数
# 下面是生成 1000 个随机数,并按照 100 个 bin 统计直方图
plt.hist(torch.randn(1000).numpy(), 100);
# 当数据非常非常多的时候,正态分布会体现的非常明显
plt.hist(torch.randn(10**6).numpy(), 100);
# 创建两个 1x4 的tensor
a = torch.Tensor([[1, 2, 3, 4]])
b = torch.Tensor([[5, 6, 7, 8]])
# 在 0 方向拼接 (即在 Y 方各上拼接), 会得到 2x4 的矩阵
print( torch.cat((a,b), 0))
tensor([[1., 2., 3., 4.], [5., 6., 7., 8.]])
# 在 1 方向拼接 (即在 X 方各上拼接), 会得到 1x8 的矩阵
print( torch.cat((a,b), 1))
tensor([[1., 2., 3., 4., 5., 6., 7., 8.]])
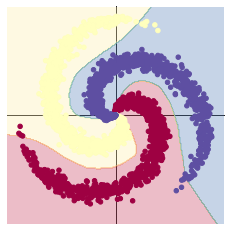
- 螺旋数据分类
import random
import torch
from torch import nn, optim
import math
from IPython import display
from plot_lib import plot_data, plot_model, set_default
# 因为colab是支持GPU的,torch 将在 GPU 上运行
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('device: ', device)
# 初始化随机数种子。神经网络的参数都是随机初始化的,
# 不同的初始化参数往往会导致不同的结果,当得到比较好的结果时我们通常希望这个结果是可以复现的,
# 因此,在pytorch中,通过设置随机数种子也可以达到这个目的
seed = 12345
random.seed(seed)
torch.manual_seed(seed)
N = 1000 # 每类样本的数量
D = 2 # 每个样本的特征维度
C = 3 # 样本的类别
H = 100 # 神经网络里隐层单元的数量
device: cuda:0
X = torch.zeros(N * C, D).to(device)
Y = torch.zeros(N * C, dtype=torch.long).to(device)
for c in range(C):
index = 0
t = torch.linspace(0, 1, N) # 在[0,1]间均匀的取10000个数,赋给t
# 下面的代码不用理解太多,总之是根据公式计算出三类样本(可以构成螺旋形)
# torch.randn(N) 是得到 N 个均值为0,方差为 1 的一组随机数,注意要和 rand 区分开
inner_var = torch.linspace( (2*math.pi/C)*c, (2*math.pi/C)*(2+c), N) + torch.randn(N) * 0.2
# 每个样本的(x,y)坐标都保存在 X 里
# Y 里存储的是样本的类别,分别为 [0, 1, 2]
for ix in range(N * c, N * (c + 1)):
X[ix] = t[index] * torch.FloatTensor((math.sin(inner_var[index]), math.cos(inner_var[index])))
Y[ix] = c
index += 1
print("Shapes:")
print("X:", X.size())
print("Y:", Y.size())
Shapes: X: torch.Size([3000, 2]) Y: torch.Size([3000])
# visualise the data
plot_data(X, Y)

# 构建线性模型分类
learning_rate = 1e-3
lambda_l2 = 1e-5
# nn 包用来创建线性模型
# 每一个线性模型都包含 weight 和 bias
model = nn.Sequential(
nn.Linear(D, H),
nn.Linear(H, C)
)
model.to(device) # 把模型放到GPU上
# nn 包含多种不同的损失函数,这里使用的是交叉熵(cross entropy loss)损失函数
criterion = torch.nn.CrossEntropyLoss()
# 这里使用 optim 包进行随机梯度下降(stochastic gradient descent)优化
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=lambda_l2)
# 开始训练
for t in range(1000):
# 把数据输入模型,得到预测结果
y_pred = model(X)
# 计算损失和准确率
loss = criterion(y_pred, Y)
score, predicted = torch.max(y_pred, 1)
acc = (Y == predicted).sum().float() / len(Y)
print('[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f' % (t, loss.item(), acc))
display.clear_output(wait=True)
# 反向传播前把梯度置 0
optimizer.zero_grad()
# 反向传播优化
loss.backward()
# 更新全部参数
optimizer.step()
[EPOCH]: 999, [LOSS]: 0.861541, [ACCURACY]: 0.504
print(y_pred.shape)
print(y_pred[10, :])
print(score[10])
print(predicted[10])
torch.Size([3000, 3]) tensor([-0.2245, -0.2594, -0.2080], device='cuda:0', grad_fn=
# Plot trained model
print(model)
plot_model(X, Y, model)
Sequential( (0): Linear(in_features=2, out_features=100, bias=True) (1): Linear(in_features=100, out_features=3, bias=True) )

#构建两层神经网络分类
learning_rate = 1e-3
lambda_l2 = 1e-5
# 这里可以看到,和上面模型不同的是,在两层之间加入了一个 ReLU 激活函数
model = nn.Sequential(
nn.Linear(D, H),
nn.ReLU(),
nn.Linear(H, C)
)
model.to(device)
# 下面的代码和之前是完全一样的,这里不过多叙述
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=lambda_l2) # built-in L2
# 训练模型,和之前的代码是完全一样的
for t in range(1000):
y_pred = model(X)
loss = criterion(y_pred, Y)
score, predicted = torch.max(y_pred, 1)
acc = ((Y == predicted).sum().float() / len(Y))
print("[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f" % (t, loss.item(), acc))
display.clear_output(wait=True)
# zero the gradients before running the backward pass.
optimizer.zero_grad()
# Backward pass to compute the gradient
loss.backward()
# Update params
optimizer.step()
[EPOCH]: 999, [LOSS]: 0.178408, [ACCURACY]: 0.949
# Plot trained model
print(model)
plot_model(X, Y, model)
Sequential( (0): Linear(in_features=2, out_features=100, bias=True) (1): ReLU() (2): Linear(in_features=100, out_features=3, bias=True) )
- 回归分析
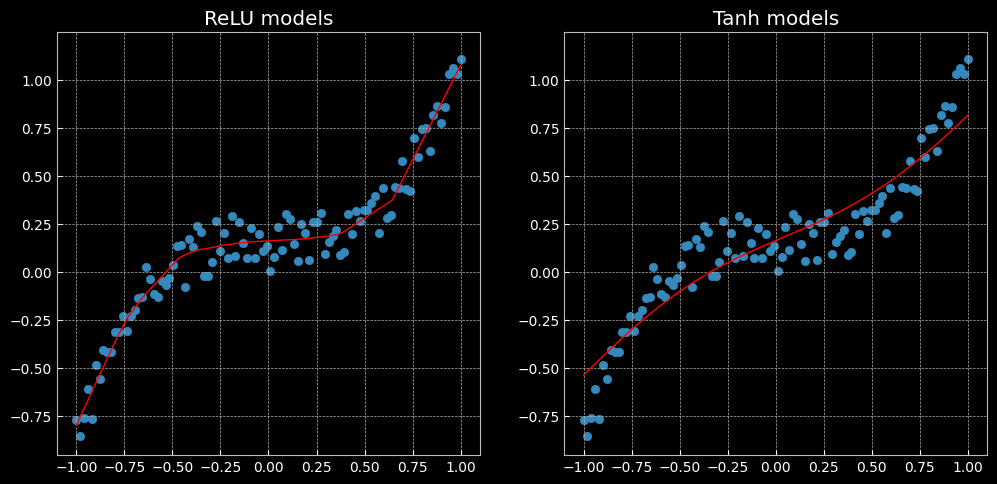
左侧是使用 ReLU 激活函数的网络得到的结果,右侧是使用 Tanh 激活函数的网络得到的结果。可以看到,效果是有所不同的,前者是分段线性函数,而后者是连续平稳回归。tanh类似于幅度增大sigmoid, 将输入值转换为-1至1之间。tanh的导数取值范围在0至1之间,优于sigmoid的0至1/4, 在一定程度上,减轻了梯度消失的问题。tanh的输出和输入能够保持非线性单调.上升和下降关系,符合BP 网络的梯度求解,容错性好,有界。Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,缓解了过拟合问题的发生,relu函数在负半区的导数为0 ,所以一旦神经元激活值进入负半区,那么梯度就会为0,也就是说这个神经元不会经历训练。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号