
Linux课程总结
精简的Linux系统:影响程序运行的因素
精简的Linux系统模型
一个典型的Linux系统应该有四个组成部分,即内核,shell,文件系统和应用程序。而操作系统主要由内核,shell和文件系统组成,这几个部分之间的关系如下图所示:

在本文中,将通过对进程管理,内存管理和文件系统的展示来解释一个简单的Linux系统概念模型。
进程管理
1. 进程模型
Linux中的进程是用task_struct结构体进行描述并用pid结构体唯一表示的。task_struct结构体需要包含进程的状态,标识,调度信息与文件系统等部分。
使用下图对task_struct结构体中的内容进行简单描
 可以看到其中的mm_struct与内存管理相关,signal与信号相关。而在Linux内核中会保留一个大小为NR_TASKS的全局数组*task[NR_TASKS],其默认长度为512。这样每次创建新进程时都会从系统空间中分配一个结构体给进程使用。
可以看到其中的mm_struct与内存管理相关,signal与信号相关。而在Linux内核中会保留一个大小为NR_TASKS的全局数组*task[NR_TASKS],其默认长度为512。这样每次创建新进程时都会从系统空间中分配一个结构体给进程使用。
2. 进程状态
Linux系统的进程状态分为以下几种:
- TASK_RUNNING:可运行状态。进程正在运行或者准备运行,由run_list()将所有处于运行态的进程链接起来。
- TASK_INTERRUPTIBLE:可中断等待状态。进程排入等待队列中,可由其他进程通过信号或中断唤醒。
- TASK_UNINTERRUPTILBE:不可中断等待状态。只有当资源可用时才能被唤醒,通常意味着等待硬件条件。
- TASK_ZOMBIE:僵死状态。进程运行完成,但尚未释放task_struct结构体。
- TASK_STOPPED:暂停状态。因收到信号而暂停执行。
进程之间的状态转换关系如下图所示:

3. 进程调度
Linux系统中存在一个总的调度器类,可以容许不同的调度算法共存。从调度策略的角度来讲,可以区分为完全公平调度和实时调度。
完全公平调度会维护每一个进程的运行时间,并以此为依据计算vruntime值,每次再选择这个值最小的进程进行执行,其中的组织方法是红黑树。
实时调度主要使用SCHED_FIFO和SCHED_RR两种调度方法进行先来先服务的调度和时间片轮转调度。
内存管理
Linux内存管理主要包括物理地址到虚拟地址的映射,内核内存分配管理
1. 物理地址到虚拟地址的映射
Linux段式内存管理:
Linux的段式管理并不区分全局段描述符与内核段描述符,都使用了相同的段来对指令和数据寻址,只是用户空间的存储用户数据段和用户代码段,而内核空间存储内核代码段和内核数据段。
Linux页式内存管理:
Linux提供了一个四层页式管理架构,分别为:
- 页全局文件夹(PGD)
- 页上级文件夹(PUD)
- 页中间文件夹(PMD)
- 页表(PT)
四个部分分别对应了地址位模式的一部分,这样当需要寻址时就会将对应的位作为索引去不同的表中查找对应表项
2. 内核内存分配
内存管理方法应该实现两个目的:最小化管理内存所需要的时间,最小化内存管理开销
通常使用的内核内存管理方法有三种,分别为直接堆分配,伙伴算法和slab分配器
直接堆分配的方法会使用首次适应或者最佳适应的方法为用户寻找一块合适的内存空间,但是可能会有碎片的问题出现。
伙伴算法是将内存划分为2的幂次大小的块,并将大小相等的块连接起来。当请求空间时就会用最佳适应的方法分配空间,回收空间的时候会考察相邻的空间是否被释放,如果是的话就合并
slab分配器简单的说就是内核常常申请固定大小的一些内存空间,这些空间一般都是结构体。而这些结构体往往都会有一个共同的初始化行为,当这些结构体的空间被释放的时候,仅仅是让他回到刚刚分配好的状态而不真正释放,下次再申请的时候就能够节约初始化的时间。
文件管理
Linux系统以文件的方式对资源进行管理,也就是所谓的一切皆文件,首先从整个系统的角度来解释LInux系统操作文件的过程。
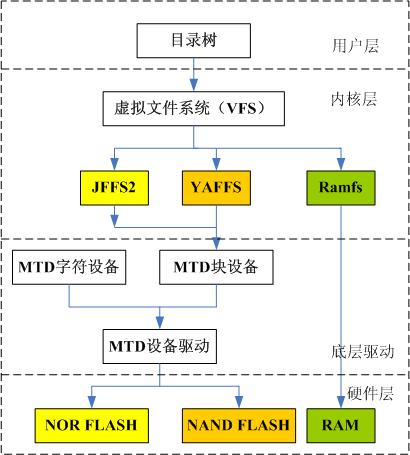
Linux系统通过VFS对目录树解析出的文件进行操作,所以实际上VFS也完成了对用户层面进行抽象的过程。
而文件最终还是要被进程使用的,所以这就涉及到进程与文件之间的关系,下图中展示了进程的task_struct中用于与操作文件的结构体。

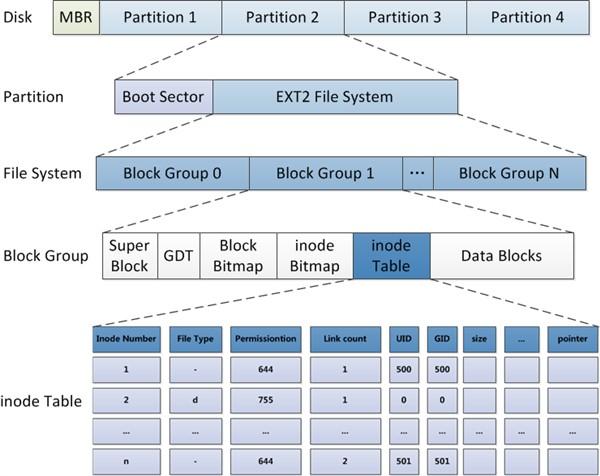
最后就是文件的存储形式,文件在磁盘中的存储方式是将inode和文件名存储在目录块,将多个inode存储在数据块中的方法进行保存。
影响程序运行的因素
Linux系统中影响程序运行的因素有很多,此处分析局部性原理对程序运行效率的影响。
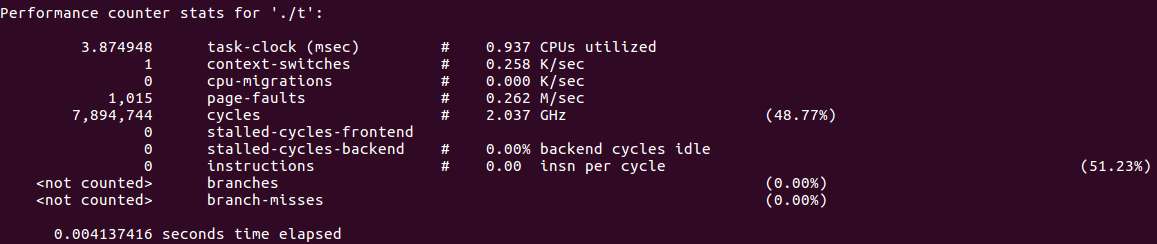
首先讨论如下代码,下面的代码充分利用了存储的局部性。
#include<stdio.h> int main(){ int matrix[1000][1000]; for(int i = 0; i < 1000; ++i){ for(int j = 0; j < 1000; ++j) matrix[i][j] = 1; } }
使用perf对程序运行过程的情况进行查看:
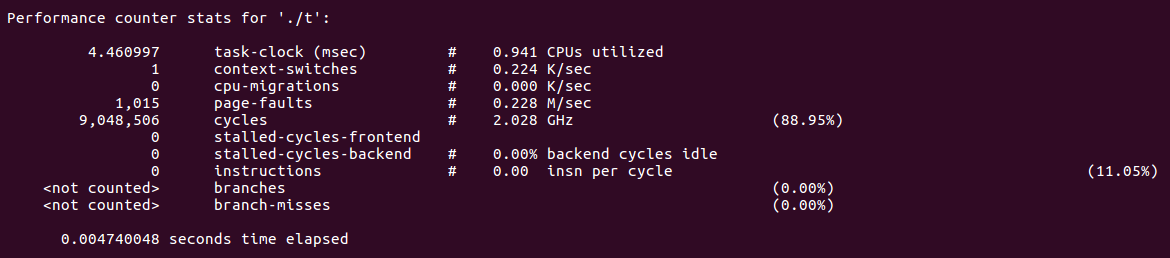
再讨论另一份代码
#include<stdio.h> int main(){ int matrix[1000][1000]; for(int i = 0; i < 1000; ++i) for(int j = 0; j < 1000; ++j) matirx[j][i] = 1; }
这份代码只是将行优先改为了列优先,这时存储的局部性没有得到充分的使用,所以预取运行效率应该小于行优先的情况。
使用perf工具进行查询,可以得到:
总结
通过本课我学习到了很多,孟宁老师和李春杰老师的课程都十分具有启发性,我受益良多。
